Aperçu: Les coûts d'hébergement des modèles de langage (LLM) varient considérablement selon le modèle de déploiement, allant de 0,025 THB par million de jetons pour les services API comme GPT-5 Nano d'OpenAI à 1 500 à 5 000 THB par mois pour une infrastructure auto-hébergée. Les organisations traitant plus de 50 000 requêtes quotidiennes réalisent souvent des économies de 25 à 500 THB grâce à l'auto-hébergement, tandis que les structures plus petites bénéficient d'une tarification API à l'usage. Les exigences matérielles sont proportionnelles à la taille du modèle : les modèles à 7 milliards de paramètres nécessitent environ 3,5 Go de VRAM avec une quantification sur 4 bits, tandis que les modèles à 70 milliards de paramètres requièrent 35 Go ou une configuration multi-GPU.
Les dépenses des entreprises en modèles de langage complexes ont explosé. Le coût des API de ces modèles a doublé à lui seul pour atteindre 1 400 milliards de dollars en 2025, et la plupart des entreprises prévoient d'augmenter encore leurs budgets d'IA cette année.
Mais voilà le point essentiel : toutes les organisations ne devraient pas payer de la même manière. Le coût de l’hébergement LLM dépend entièrement de l’échelle, des habitudes d’utilisation et des exigences techniques. Les services API offrent une grande facilité d’utilisation, mais l’auto-hébergement peut réduire les coûts de 501 000 ₹ ou plus à grande échelle.
Ce guide détaille les coûts réels de chaque option d'hébergement majeure, des API commerciales aux infrastructures entièrement autogérées.
Coûts des programmes LLM basés sur une API : Tarification au jeton
Les services d'API commerciaux fonctionnent selon un modèle de paiement à l'usage, facturant en fonction des jetons d'entrée et de sortie traités. D'après la documentation tarifaire d'OpenAI (mise à jour 2026), les coûts varient considérablement d'un modèle à l'autre.
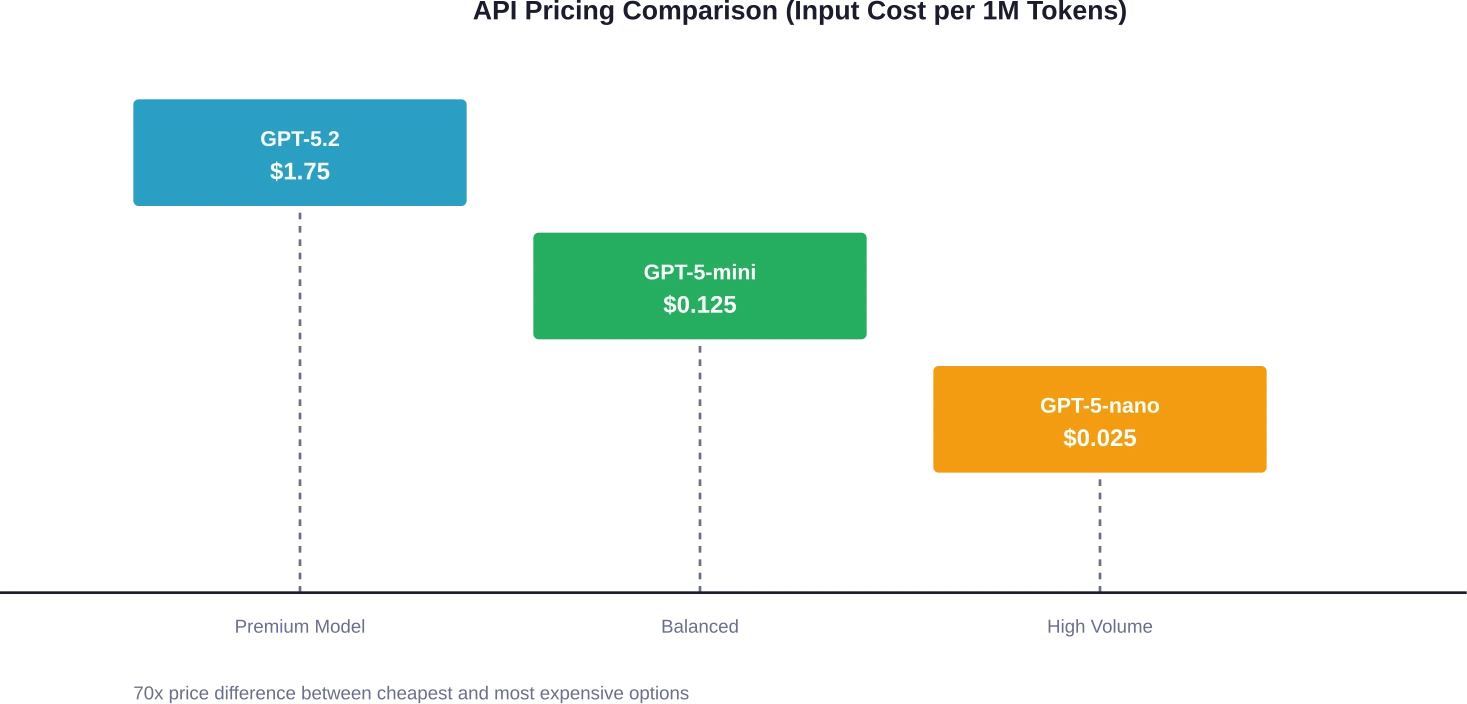
GPT-5.2 consomme $1,75 par million de jetons d'entrée et $14,00 par million de jetons de sortie. Il s'agit du modèle phare conçu pour les tâches complexes de raisonnement et de programmation. À titre de comparaison, GPT-5-mini consomme seulement $0,125 par million de jetons d'entrée et $1,00 par million de jetons de sortie, soit 14 fois moins cher pour les entrées et 14 fois moins cher pour les sorties.
La dernière version, GPT-5-nano, a encore réduit les coûts à $0,025 par million de jetons d'entrée et $0,20 par million de jetons de sortie. Pour les équipes exécutant des tâches simples et à volume élevé, cela représente une réduction de coût de 80% par rapport à GPT-5-mini.
Enregistrement des entrées mises en cache
OpenAI a introduit une tarification des entrées mises en cache qui ne facture que 10% des tarifs standard pour le contenu répétitif. Les entrées mises en cache de GPT-5.2 coûtent $0,175 par million de jetons au lieu de $1,75. Pour les applications comportant des invites système ou des documents de référence cohérents, cette optimisation est significative.
L'API Batch réduit les coûts de 50% pour les charges de travail non temps réel traitées de manière asynchrone en moins de 24 heures.
Tarification Anthropique et Google
La tarification de Google Vertex AI pour les modèles Gemini 3 (en février 2026) présente une structure similaire basée sur les jetons. Une tarification standard s'applique aux requêtes de moins de 200 000 jetons d'entrée, avec des tarifs distincts pour les contextes plus importants et les entrées mises en cache.
Ces services commerciaux ne facturent que les requêtes aboutissant à un code de réponse 200. Les requêtes infructueuses sont gratuites, ce qui permet d'éviter toute facturation liée à des erreurs.
Coûts d'hébergement de plateforme cloud
AWS SageMaker, Google Vertex AI et Azure Foundry proposent un hébergement LLM géré offrant un contrôle plus poussé que les services API classiques. Ces plateformes facturent les ressources de calcul plutôt que les jetons.
Structure tarifaire d'AWS SageMaker
D'après la documentation AWS mise à jour en février 2026, SageMaker facture les heures d'instance, le stockage et le transfert de données. L'offre gratuite d'AWS inclut 250 heures d'instances ml.t3.medium pendant les deux premiers mois, ainsi que 4 000 requêtes API gratuites par mois.
Pour les charges de travail de production, le prix des instances est proportionnel à la puissance du GPU. Les organisations qui exécutent des inférences sur des instances ml.g5.xlarge (GPU NVIDIA A10G) paient des tarifs différents selon la région et le niveau d'engagement.
Les instances réservées AWS permettent de réaliser des économies importantes par rapport à la tarification à la demande. Les engagements d'une durée d'un an peuvent réduire considérablement les coûts pour les charges de travail prévisibles.
Google Vertex AI Economics
La documentation tarifaire de Vertex AI de Google indique que les frais sont calculés en fonction des heures de calcul, du temps de déploiement du modèle et des requêtes de prédiction. Les modèles qui ne sont pas déployés ne sont pas facturés, et les échecs d'entraînement (sauf les annulations à l'initiative de l'utilisateur) ne sont pas facturés.
Ce modèle basé sur la consommation protège contre le paiement d'opérations ayant échoué, ce qui est important lors de l'expérimentation de configurations de modèles.
Coûts d'infrastructure d'un LLM auto-hébergé
L'auto-hébergement permet de transférer les coûts des frais d'utilisation variables vers un investissement fixe dans l'infrastructure. Pour les organisations traitant plus de 50 000 requêtes par jour, cette solution est souvent économiquement avantageuse.
Les exigences matérielles dépendent entièrement de la taille du modèle. En règle générale, il faut compter environ 0,5 Go de VRAM par milliard de paramètres avec une quantification sur 4 bits. La pleine précision (FP16) double ces exigences.
| Taille du modèle | Paramètres | VRAM (4 bits) | VRAM (FP16) | Matériel typique |
|---|---|---|---|---|
| Petit | 7B-13B | 3,5 à 6,5 Go | 14-26 Go | Simple A100/H100 |
| Moyen | 30B-40B | 15-20 Go | 60-80 Go | A100 80 Go |
| Grand | 70B+ | 35 Go+ | 140 Go+ | Configuration multi-GPU |
Si le modèle ne tient pas dans la VRAM, le système bascule sur le traitement par le CPU, qui est 10 à 100 fois plus lent. Ce n'est pas viable en production.
Coûts mensuels d'infrastructure par niveau
Une étude de l'Université Carnegie Mellon analysant les aspects économiques du déploiement de solutions LLM sur site fait apparaître des niveaux de coûts clairement distincts :
| Étage | Taille du modèle | Configuration matérielle | Gamme de coûts mensuels | Idéal pour |
|---|---|---|---|---|
| Entrée | 7B-13B | 1x A100/H100 | $1,500-$5,000 | Prototypes, outils internes |
| Milieu | 30B-70B | Cluster de 4 à 8 GPU | $8,000-$20,000 | Applications de production, échelle modérée |
| Entreprise | 70B+ | Cluster de plus de 8 GPU | $20,000-$50,000+ | Production à grand volume |
Ces chiffres incluent l'amortissement du matériel, la consommation électrique, le refroidissement et la maintenance courante. L'article de recherche d'arxiv.org sur l'analyse coûts-avantages indique que le coût horaire d'un GPU A800 80G est d'environ $0,79 €/heure selon les hypothèses courantes, se situant généralement entre $0,51 € et $0,99 €/heure.
Économies sur les instances réservées AWS EC2
L'analyse détaillée des coûts d'hébergement LLM de LinkedIn montre que les instances réservées AWS EC2 permettent de réaliser des économies substantielles par rapport à la tarification à la demande. Pour les instances g5.xlarge (adaptées aux modèles à 8 milliards de paramètres), un engagement d'un an permet de réduire les coûts mensuels d'environ $530 à des tarifs bien inférieurs.
Pour les modèles 8B, l'option la plus économique identifiée était Deep Infra à $5,40 €/mois, tandis qu'AWS SageMaker était la plus chère à $529,92 €/mois. Le coût médian se situait autour de $237 €/mois.

Connaître le coût de votre hébergement pour un LLM
L’hébergement de programmes LLM implique des choix en matière de latence, d’évolutivité, de sécurité et de budget. IA supérieure Ce service vous aide à choisir un modèle d'hébergement adapté (cloud, edge computing ou hybride), à estimer votre consommation de ressources et à calculer les coûts récurrents liés au trafic et aux performances. Son évaluation prend en compte le stockage, la surveillance, la mise à l'échelle et la maintenance. Vous obtenez ainsi une prévision fiable de vos dépenses d'hébergement.
Prêt à planifier votre budget d'accueil pour le LLM ?
Dialoguer avec une IA supérieure à :
- choisir l'architecture d'hébergement appropriée
- estimer les coûts des ressources et des opérations
- recevez un détail clair des coûts d'hébergement
👉 Demander un coût d'hébergement du LLM Estimation issue d'une IA supérieure.
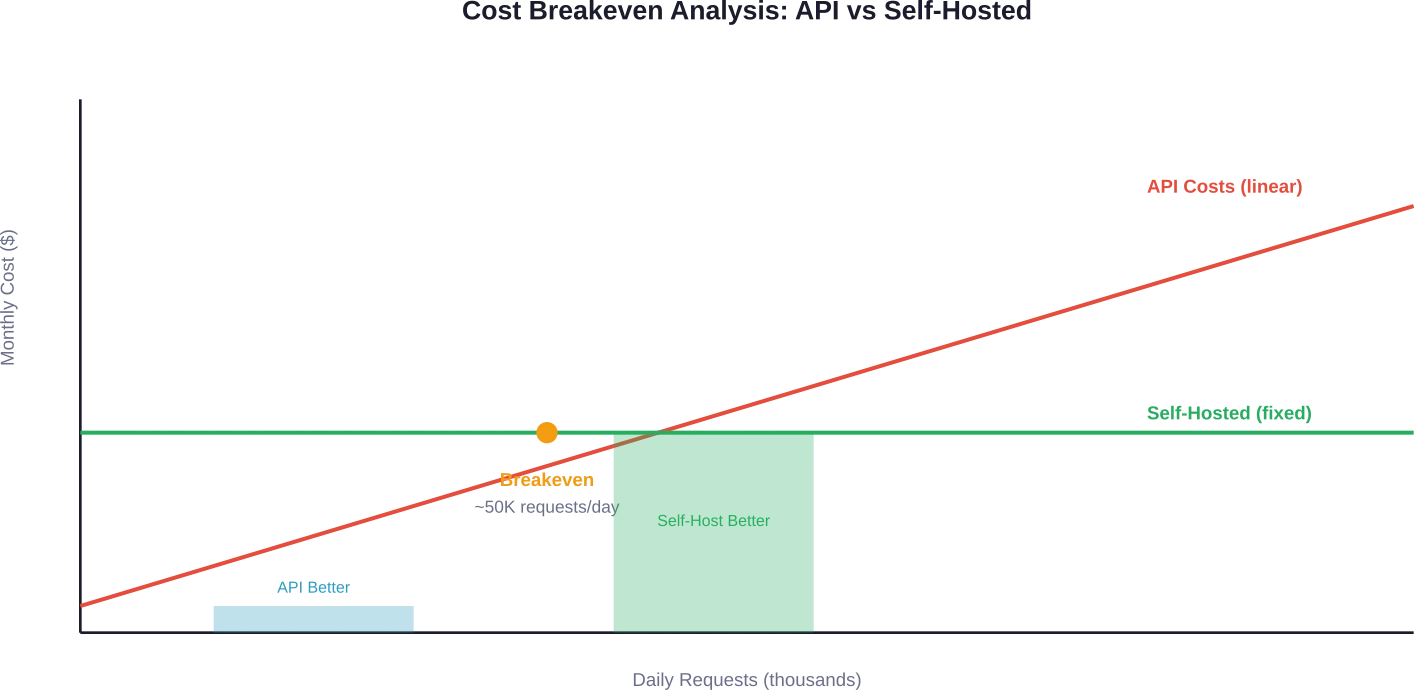
Atteindre le seuil de rentabilité : quand l’auto-hébergement est judicieux
Le seuil de rentabilité dépend du volume de requêtes. Les discussions au sein de la communauté et les analyses de coûts indiquent systématiquement que plus de 50 000 requêtes quotidiennes constituent le seuil à partir duquel l’auto-hébergement devient économiquement avantageux.
Voici pourquoi : les coûts de l’API augmentent proportionnellement à son utilisation. Les coûts fixes d’infrastructure restent constants quel que soit le volume de requêtes (dans les limites de capacité).
Une organisation traitant 50 000 requêtes par jour, chacune comportant 500 jetons d'entrée et 500 jetons de sortie, à l'aide de GPT-5-mini, dépenserait environ 1 TP4 T3 125 par mois rien que pour les appels d'API. Ce calcul ne tient pas compte de l'infrastructure applicative, des couches de cache ni de la supervision.
Un modèle 7B auto-hébergé sur du matériel d'entrée de gamme ($1 500 à $5 000/mois) gère des volumes similaires tout en offrant un contrôle total des données. La rentabilité s'améliore considérablement à partir de 100 000 requêtes quotidiennes.
Les coûts cachés dont personne ne parle
Le prix affiché ne révèle qu'une partie de la réalité. Les solutions basées sur une API ou hébergées sur site comportent toutes deux des frais cachés qui influent sur le coût total de possession.
Coûts cachés des services API
Les limitations de débit imposent des choix d'architecture. Lorsque les limites de débit sont atteintes, les applications nécessitent des systèmes de mise en file d'attente, une logique de nouvelle tentative et des mécanismes de repli. Cela engendre des coûts de développement et d'infrastructure.
Les frais de sortie de données peuvent rapidement s'accumuler pour les applications à fort volume de données. Si le traitement des jetons coûte $X, le transfert de gros volumes de données vers et depuis les fournisseurs d'API engendre des frais supplémentaires.
La dépendance vis-à-vis d'un fournisseur engendre des coûts de changement. Les applications conçues autour de formats de réponse API spécifiques, d'intégrations d'outils ou de techniques d'ingénierie spécifiques ne peuvent pas facilement changer de fournisseur.
Coûts cachés liés à l'auto-hébergement
Les coûts liés au DevOps sont importants. Il est indispensable de gérer les mises à jour des modèles, les correctifs de sécurité, la surveillance et la réponse aux incidents. Selon le rapport 2025 de Kong sur l'IA en entreprise, 441 030 organisations citent la confidentialité et la sécurité des données comme principaux obstacles ; l'auto-hébergement nécessite des ressources dédiées pour répondre efficacement à ces préoccupations.
Les coûts liés à la consommation d'énergie et au refroidissement dépassent les coûts de calcul bruts. Les centres de données indiquent que la consommation électrique réelle est 1,5 à 2 fois supérieure à la consommation nominale du GPU, compte tenu des pertes liées au refroidissement et à l'alimentation.
La mise à l'échelle n'est pas automatique. Augmenter la capacité implique des délais d'approvisionnement en matériel, des contraintes d'espace dans les racks et une planification de l'infrastructure réseau. Les services API, quant à eux, s'adaptent instantanément.
Stratégies d'optimisation qui fonctionnent réellement
Quel que soit le choix d'hébergement, plusieurs techniques permettent de réduire systématiquement les coûts LLM sans sacrifier les performances.
Sélection et quantification du modèle
Les modèles plus petits sont souvent plus performants que prévu sur des tâches spécifiques à un domaine. Selon une étude de Together AI, l'optimisation d'un modèle open source de 27 milliards d'octets sur des tâches spécialisées peut surpasser Claude Sonnet 4 de 60% tout en coûtant 10 à 100 fois moins cher.
La quantification sur 4 bits réduit de moitié les besoins en mémoire avec un impact minimal sur la qualité pour la plupart des applications. Cette technique permet d'exécuter des modèles plus volumineux sur le même matériel ou d'exécuter le même modèle sur du matériel moins coûteux.
Le traitement par lots
L'API Batch d'OpenAI permet d'économiser 501 000 téléchargements (TP3 T) sur les entrées et les sorties grâce au traitement asynchrone sur 24 heures. La documentation de l'API Batch de TogetherAI indique des économies similaires : les tâches ne nécessitant pas de réponses en temps réel doivent toujours utiliser les points de terminaison par lots.
Les recherches d'AWS sur l'optimisation de SageMaker démontrent que le traitement par lots des requêtes d'inférence améliore considérablement l'utilisation du GPU, réduisant ainsi le coût par prédiction.
Mise en cache et déduplication des requêtes
Les invites système, les documents de référence et les requêtes répétées engendrent des coûts inutiles. La mise en place d'un cache pour les invites au niveau applicatif permet d'éliminer le traitement redondant des jetons.
Pour les déploiements auto-hébergés, le middleware de déduplication des requêtes peut intercepter les requêtes identiques avant qu'elles n'atteignent le modèle, en servant à la place des réponses mises en cache.
Prévision du trafic et mise à l'échelle automatique
Les recherches de Microsoft sur l'efficacité du service LLM (SageServe) ont permis de réaliser jusqu'à 251 030 000 $ d'économies en heures GPU grâce à une mise à l'échelle automatique basée sur les prévisions, avec des économies mensuelles potentielles pouvant atteindre 1 040 025 000 $. Le système analyse l'historique des requêtes et ajuste la capacité de manière proactive.
Cela réduit le gaspillage d'heures GPU dû à une mise à l'échelle automatique inefficace jusqu'à 80% par rapport aux approches de mise à l'échelle réactive.
Variations régionales des coûts
Les coûts d'hébergement LLM varient considérablement selon la région géographique. AWS, Google Cloud et Azure appliquent tous une tarification régionale qui tient compte des coûts d'infrastructure locaux, des prix de l'énergie et des conditions du marché.
L'analyse de données de production réelles portant sur 10 millions de requêtes réparties sur plusieurs régions révèle des variations de coûts selon les régions. Pour les services API, ces différences sont généralement masquées. En revanche, pour une infrastructure auto-hébergée, le choix de la région a un impact considérable sur les coûts mensuels.
Pour les services API, ces différences sont généralement masquées. Mais pour une infrastructure auto-hébergée, le choix de la région a un impact considérable sur les coûts mensuels.
Tendances des coûts en 2026
Plusieurs facteurs contribuent à la baisse des coûts d'hébergement des programmes LLM cette année.
Les gains d'efficacité algorithmique sont plus importants que les progrès matériels. Selon une étude du MIT FutureTech sur l'efficacité algorithmique, les améliorations en termes de complexité spatiale pour les problèmes de grande taille (n=1 milliard) ont surpassé les améliorations de la DRAM dans 201 000 000 cas analysés.
Les nouvelles architectures de modèles, comme le modèle Mixture-of-Experts (MoE), engendrent des profils de coûts différents. Les recherches analysant la charge de ces modèles montrent qu'ils présentent des inefficacités spécifiques : un déséquilibre de charge lors du préremplissage et une augmentation des transferts de mémoire lors du décodage. Cependant, les implémentations optimisées de MoE peuvent offrir un meilleur rapport coût-performance que les modèles denses.
AWS a annoncé en 2023 de nouveaux conteneurs d'inférence de modèles volumineux (LLM) qui ont permis de réduire la latence de 331 TP3T pour les charges de travail Llama-2 70B. Les versions mises à jour continuent d'améliorer l'efficacité. Pour Llama-2 70B avec une concurrence de 16, la latence a été réduite de 281 TP3T et le débit augmenté de 441 TP3T grâce aux conteneurs TensorRT-LLM.
FAQ
Quelle est la solution la plus économique pour organiser un LLM en 2026 ?
Pour une utilisation à faible volume (moins de 10 000 requêtes par jour), GPT-5-nano d'OpenAI, à $0,025 par million de jetons d'entrée, offre la solution la plus accessible, sans aucun coût d'infrastructure. Pour une production à volume élevé (plus de 50 000 requêtes par jour), l'hébergement sur place de modèles de 7 à 13 milliards de paramètres sur du matériel d'entrée de gamme ($1 500 à $5 000 par mois) est généralement moins coûteux que l'utilisation d'une API équivalente.
De combien de VRAM ai-je besoin pour exécuter un modèle à 70 milliards de paramètres ?
Un modèle à 70 milliards de paramètres nécessite environ 35 Go de VRAM avec une quantification sur 4 bits, ou 140 Go avec une précision FP16 complète. Cela implique généralement soit un GPU A100 de 80 Go (limite atteinte avec la quantification), soit une configuration multi-GPU pour un fonctionnement optimal. En l'absence de VRAM suffisante, le modèle est traité par le CPU à une vitesse 10 à 100 fois inférieure.
Les instances réservées AWS sont-elles intéressantes pour l'hébergement de programmes LLM ?
Les instances réservées sont pertinentes pour les charges de travail prévisibles et continues fonctionnant 24 h/24 et 7 j/7. Les engagements d'un an pour les instances réservées AWS EC2 permettent de réaliser des économies importantes par rapport à la tarification à la demande pour les instances GPU. Toutefois, cet engagement bloque la capacité ; les organisations dont l'utilisation est variable risquent de payer trop cher pendant les périodes de faible demande.
Les petites organisations peuvent-elles se permettre des LLM auto-hébergés ?
L'hébergement indépendant d'entrée de gamme coûte environ 1 400 à 5 000 TP4 T par mois pour les modèles comportant de 7 à 13 milliards de paramètres. Les organisations traitant plus de 50 000 requêtes par jour atteignent souvent le seuil de rentabilité par rapport aux coûts des API à cette échelle. En deçà de ce seuil, les services API coûtent généralement moins cher si l'on prend en compte les coûts liés au DevOps, à la maintenance et à la gestion.
Quelle est la différence de coût réelle entre GPT-5.2 et GPT-5-mini ?
D'après les tarifs d'OpenAI pour 2026, GPT-5.2 coûte $1,75 par million de jetons d'entrée et $14,00 par million de jetons de sortie, tandis que GPT-5-mini coûte $0,125 en entrée et $1,00 en sortie, soit une différence de 14 fois sur les deux. Pour une application classique traitant 1 million de jetons par jour (500 000 en entrée, 500 000 en sortie), GPT-5.2 coûte environ $7 875 par mois, contre $562,50 pour GPT-5-mini.
La mise en cache permet-elle réellement de réaliser des économies sur les coûts des masters en droit (LLM) ?
Oui, de façon spectaculaire. La tarification des entrées mises en cache d'OpenAI ne facture que 10% de frais par rapport aux tarifs standard pour le contenu répétitif. Pour les applications avec des invites système ou des documents de référence cohérents, cela signifie que les entrées mises en cache par GPT-5.2 coûtent $0,175 par million de jetons au lieu de $1,75. Les applications avec 50% de contenu pouvant être mis en cache peuvent réduire leurs coûts d'API d'environ 45%.
Comment savoir quand passer d'une API à une solution auto-hébergée ?
Calculez les coûts mensuels actuels des API et la croissance du projet. Comparez-les à une infrastructure d'hébergement interne d'entrée de gamme (1 500 à 5 000 €/mois) plus les frais généraux DevOps (généralement 0,25 à 0,5 ETP de temps d'ingénierie). Si les coûts des API dépassent 5 000 € par mois et que l'utilisation est prévisible, l'hébergement interne est généralement plus avantageux économiquement. Les exigences en matière de confidentialité des données, de conformité et de personnalisation sont également des facteurs déterminants, au-delà du simple coût.
Réflexions finales
Les coûts d'hébergement LLM ne sont pas standardisés. Le choix optimal dépend du volume de requêtes, des exigences de performance, de la sensibilité des données et des capacités techniques.
Les services API sont idéaux pour une prise en main rapide, la gestion de charges de travail variables et l'absence de gestion d'infrastructure. Ils sont presque toujours moins chers pour moins de 50 000 requêtes quotidiennes.
L'auto-hébergement est économiquement avantageux à grande échelle, notamment lorsque la confidentialité des données est cruciale ou lorsqu'un paramétrage précis spécifique au domaine offre de meilleurs résultats que les modèles généralistes. Cependant, il exige un engagement DevOps et un investissement initial dans l'infrastructure.
La meilleure approche ? Commencer par des API pour valider l’adéquation produit-marché, puis envisager l’auto-hébergement une fois que les habitudes d’utilisation se stabilisent et que les coûts justifient l’investissement dans l’infrastructure. De nombreuses organisations utilisent des déploiements hybrides : des API pour l’expérimentation et la gestion des pics d’activité, et une infrastructure auto-hébergée pour les charges de travail de production critiques.
Quel que soit le chemin le plus adapté aux besoins actuels, privilégiez la flexibilité. L'économie et les capacités d'hébergement des programmes de maîtrise en droit (LLM) évoluent rapidement.