Résumé rapide : Les coûts d'inférence des modèles de raisonnement logique (LLM) ont été divisés par 10 chaque année depuis 2021. Les performances équivalentes à celles de GPT-4 coûtent désormais $0,40 par million de jetons, contre $30 par million de jetons d'entrée et $60 par million de jetons de sortie en mars 2023. Cependant, les modèles de raisonnement peuvent consommer jusqu'à 100 fois plus de jetons en interne qu'ils n'en produisent, créant ainsi un paradoxe : une tarification par jeton plus avantageuse se traduit par des factures totales plus élevées. Il est donc essentiel, pour une économie de l'IA durable, de comprendre les coûts réels de l'infrastructure, les techniques d'optimisation et le choix entre les services API et les déploiements auto-hébergés.
L'économie de l'intelligence artificielle est entrée dans une phase qui défie toute logique conventionnelle. Alors que les gros titres s'enthousiasment pour la chute vertigineuse des cours des jetons, les entreprises du secteur de l'IA découvrent une vérité dérangeante : leurs coûts ne cessent d'augmenter.
Ce qui coûtait $60 par million de jetons en novembre 2021 coûte désormais entre $0,06 et $0,40 par million de jetons pour des performances équivalentes avec GPT-4, soit une réduction de 150 à 1 000 fois selon le modèle. Pourtant, de nombreuses startups qui s'appuient sur de grands modèles de langage font état de coûts d'infrastructure qui absorbent entre 40 et 60 TP3T de leur chiffre d'affaires.
Le coupable ? Un changement fondamental dans la façon dont les modèles d'IA modernes génèrent des réponses, et un mode de consommation de jetons que personne n'avait vu venir.
La baisse spectaculaire des prix de l'inférence LLM
Les coûts d'inférence LLM ont chuté plus rapidement que pour presque tous les autres produits informatiques de l'histoire. Selon une étude analysant les tendances tarifaires, le rythme de cette baisse varie considérablement selon le niveau de performance visé, allant d'un facteur 9 à 900 par an.
Le rythme de déclin varie considérablement selon la tâche. Pour certains indicateurs, les prix ont été divisés par neuf par an. Pour d'autres, la baisse a atteint un facteur de 900 par an, même si ces chutes extrêmes se sont produites principalement en 2024 et pourraient ne pas se maintenir.
Voici ce que cela donne concrètement. Lorsque GPT-3 est devenu accessible au public en novembre 2021, il était le seul modèle à atteindre un score MMLU de 42. Son coût ? $60 par million de jetons. D'ici mars 2026, plusieurs modèles auront dépassé ce seuil à $0,06 par million de jetons, voire moins.
La solution Gemini Flash-Lite 3.1 de Google propose les tarifs les plus compétitifs, à $0,25 par million de jetons d'entrée et $1,50 par million de jetons de sortie. Les solutions open source, comme celles proposées par Together.ai, offrent des prix encore plus bas : Llama 3.2 3B, par exemple, est disponible à $0,06 par million de jetons d'entrée.
Pourquoi les prix ont-ils chuté si vite ?
Plusieurs facteurs expliquent ces réductions de coûts. Grâce à l'amélioration des techniques d'entraînement, les modèles sont plus compacts tout en conservant leurs performances. Un modèle à 13 milliards de paramètres peut désormais atteindre 95% du score MMLU de GPT-3, avec une empreinte mémoire considérablement réduite.
Le coût du matériel par unité de calcul continue de baisser. Les prix du Cloud H100 se sont stabilisés entre $2,85 et $3,50 par heure après avoir chuté par rapport aux pics de 2023. Selon une étude d'arXiv, le coût horaire de base par carte A800 80G est d'environ $0,79 €/heure, se situant généralement entre $0,51 et $0,99 €/heure.
Les techniques d'optimisation telles que la quantification, le traitement par lots continu et PagedAttention ont transformé les capacités de débit. Les systèmes du benchmark MLPerf Inference v5.1 ont enregistré une amélioration allant jusqu'à 501 TP3T par rapport au meilleur système de la version 5.0 sortie six mois auparavant (septembre 2025).
Mais il y a un hic.
Le paradoxe de la consommation symbolique
La baisse du prix par jeton n'explique que la moitié du problème. L'autre moitié concerne le nombre de jetons réellement consommés par les modèles modernes.
Les modèles de langage traditionnels génèrent des réponses de manière linéaire : on pose une question, on obtient une réponse. Le nombre de jetons utilisés correspond approximativement à la longueur du texte. Une réponse de 200 mots consomme environ 250 à 300 jetons.
Les modèles de raisonnement fonctionnent différemment. Ils “ réfléchissent ” aux problèmes en interne avant de produire un résultat. Ce processus de raisonnement interne consomme des jetons — et en grande quantité.
Des exemples concrets révèlent l'ampleur de ce changement. Une question simple peut utiliser 10 000 jetons de raisonnement en interne, alors que la réponse n'en contient que 200. Cela représente 50 fois plus de jetons que ce que suggère le résultat affiché.
Dans des cas extrêmes signalés par les utilisateurs, certains modèles de raisonnement ont consommé plus de 600 jetons pour générer seulement deux mots en sortie. Une requête simple qui utiliserait 50 jetons avec un modèle standard peut en consommer plus de 30 000 lorsque le raisonnement agressif est activé.
L'impact sur l'entreprise
Cela crée ce que certains appellent le “ paradoxe du coût LLM ”. Le prix par jeton a été divisé par 10, mais la consommation de jetons a été multipliée par 100 pour certaines charges de travail. Les calculs ne sont pas à l'avantage des entreprises spécialisées en IA.
Les startups qui ont bâti leurs modèles de tarification sur l'économie des jetons traditionnels subissent une compression de leurs marges. Un client payant $20 par mois pourrait générer entre $18 et $25 en coûts d'inférence lors de tâches de raisonnement complexes. Le modèle économique n'est tout simplement plus viable.
Certains fournisseurs ont réagi en plafonnant le nombre de jetons de raisonnement, limitant ainsi la capacité de traitement interne des modèles. D'autres ont mis en place une tarification à plusieurs niveaux, les requêtes nécessitant un raisonnement intensif étant plus coûteuses. Cependant, ces solutions engendrent des frictions et une complexité accrue.
Comprendre les véritables coûts des infrastructures
Au-delà du prix de l'API, les équipes envisageant un déploiement auto-hébergé doivent comprendre l'ensemble de la structure des coûts. Les chiffres révèlent dans quels cas l'auto-hébergement est économiquement avantageux, et dans quels cas il ne l'est pas.
Économie de l'infrastructure GPU
Selon les recommandations de NVIDIA en matière d'analyse comparative publiées en juin 2025, le calcul des coûts d'inférence réels nécessite de prendre en compte l'acquisition du matériel, la consommation d'énergie, le refroidissement, la bande passante réseau et les frais généraux d'exploitation.
Les instances Cloud H100 coûtent entre $2,85 et $3,50 par heure, selon le fournisseur et la durée d'engagement. Les instances H100 auto-hébergées nécessitent un investissement initial et des coûts récurrents. Le seuil de rentabilité dépend du taux d'utilisation.
Les recherches montrent que l'infrastructure auto-hébergée devient viable lorsque l'utilisation du GPU dépasse durablement 501 TP3T. En dessous de ce seuil, les services API offrent généralement une meilleure rentabilité.
| Composante de coût | Fournisseur de cloud | Auto-hébergé |
|---|---|---|
| Coût du GPU | $2,85-3,50/heure | $30 000-40 000 (H100) |
| Puissance (par GPU) | Compris | $0,40-0,60/heure |
| Refroidissement | Compris | $0,15-0,25/heure |
| Réseau | Sortie $0.08-0.12/GB | Forfait mensuel |
| Opérations | Minimal | 1 à 2 ingénieurs à temps plein |
| Seuil de rentabilité | — | Utilisation du 50%+ |
L'équation d'utilisation
Le taux d'utilisation est déterminant. Un GPU fonctionnant à 301 TP3T coûte 3,3 fois plus cher par inférence qu'un GPU fonctionnant à 1001 TP3T. Cependant, atteindre un taux d'utilisation élevé nécessite un volume de charge de travail constant et des stratégies de traitement par lots sophistiquées.
Le traitement par lots peut réduire le coût par jeton de sortie jusqu'à 30% par rapport au traitement par requête unique. Des techniques comme le traitement par lots continu, où le moteur d'inférence combine dynamiquement les requêtes à mesure qu'elles arrivent, optimisent le débit.
L'optimisation des modèles grâce à la quantification, aux architectures Mixture of Experts et à l'élagage des données permet d'améliorer les coûts de 2 à 5 fois sans compromettre la qualité. Selon les informations fournies par Together.ai, l'architecture MoE de DeepSeek est conçue pour offrir des performances équivalentes à celles de GPT-4 à un coût avantageux.
Structure des coûts selon la taille du modèle
La taille du modèle influe directement sur les coûts d'inférence, mais cette relation n'est pas linéaire. Des modèles plus petits n'impliquent pas toujours des coûts proportionnellement plus faibles, et des modèles plus grands peuvent parfois s'avérer plus avantageux pour les tâches complexes.
Petits modèles (paramètres 3B-7B)
Les modèles de cette gamme offrent un excellent rapport coût-efficacité pour les tâches simples. Llama 3.2 3B coûte environ $0,06 par million de jetons. Ces modèles gèrent efficacement la classification, la réponse à des questions simples et l'extraction de données structurées.
Le compromis réside dans les capacités. Les petits modèles peinent à effectuer des raisonnements complexes, à comprendre les nuances du langage et à accomplir des tâches exigeant une connaissance approfondie du monde. Pour de nombreuses charges de travail en production, cela reste acceptable.
Modèles moyens (paramètres 13B-70B)
Cette fourchette représente le point idéal pour de nombreuses applications. Un modèle de 13 milliards d'éléments atteignant un score MMLU de 95% (équivalent à celui de GPT-3) pourrait coûter $0,25 par million de jetons, soit plus cher que les modèles de petite taille, mais avec des capacités de raisonnement nettement supérieures.
Les modèles de classe 70B, comme le Llama 3.1 70B, offrent des performances quasi optimales avec un coût unitaire d'environ $0,80 par million de jetons. Pour les applications nécessitant une puissance de calcul importante sans pour autant exiger des capacités de pointe absolues, ces modèles offrent un excellent rapport qualité-prix.
Modèles de grande taille (plus de 175 milliards de paramètres)
Les modèles de pointe comme GPT-4, Claude et Gemini Ultra coûtent entre $2 et 15 par million de jetons, selon le modèle et le fournisseur. Ils excellent dans le raisonnement complexe, les tâches créatives et les problèmes nécessitant une connaissance approfondie du domaine.
Le coût plus élevé par jeton devient économique lorsque le modèle accomplit des tâches en moins d'itérations, fournit des réponses plus précises ou permet des cas d'utilisation que les modèles plus petits ne peuvent tout simplement pas gérer.

Besoin d'aide pour concevoir et déployer un système LLM ?
Si vous prévoyez d'exécuter un modèle de langage de grande envergure en production, il est utile de travailler avec une équipe qui conçoit et déploie des systèmes d'IA au quotidien. IA supérieure Cette entreprise développe des applications d'IA sur mesure, basées sur l'apprentissage automatique et les modèles LLM, de l'analyse de faisabilité initiale au déploiement et à l'intégration. Son équipe de data scientists et d'ingénieurs travaille sur le développement de modèles, les systèmes de traitement automatique du langage naturel (TALN), les pipelines de données et le déploiement en production. Elle aide également à déterminer si un cas d'usage nécessite réellement un modèle LLM et comment structurer le système pour un fonctionnement optimal.
Prêt à planifier la mise en œuvre de votre LLM ?
Dialoguer avec une IA supérieure à :
- Évaluez votre cas d'utilisation et vos exigences techniques en matière de LLM
- concevoir et construire des systèmes d'IA ou de NLP personnalisés
- déployer des modèles et les intégrer aux logiciels existants
👉 Demandez une consultation en IA avec IA supérieure pour discuter de votre projet de maîtrise en droit.
Services API vs Économies d'hébergement sur site
Le choix entre les services API et une infrastructure auto-hébergée dépend de l'échelle, des modèles d'utilisation et des capacités techniques. Aucune option ne s'impose de manière universelle.
Quand les services API gagnent
Les services API d'OpenAI, d'Anthropic, de Google et de fournisseurs comme Together.ai offrent des solutions économiques très avantageuses dans de nombreux cas de figure. L'absence de gestion d'infrastructure permet aux équipes de se concentrer sur la logique applicative plutôt que sur l'orchestration des GPU.
Les coûts sont proportionnels à l'utilisation. Les mois de faible utilisation coûtent proportionnellement moins cher que les mois de forte utilisation. Il n'y a pas d'investissement initial, pas de capacité inutilisée pendant les périodes de faible demande, ni de frais généraux d'exploitation pour l'infrastructure de service du modèle.
Pour les applications présentant des schémas de trafic variables, une demande saisonnière ou des trajectoires de croissance imprévisibles, les API offrent généralement une meilleure rentabilité, sauf si le débit soutenu dépasse un seuil relativement élevé.
Quand l'auto-hébergement est judicieux
L'auto-hébergement devient économiquement viable lorsque l'utilisation du GPU peut dépasser durablement 501 TP3T. Selon les données de référence, cela nécessite un volume de charge de travail constant : environ plus de 10 millions de jetons par jour pour une configuration à GPU unique.
Au-delà des considérations purement économiques, certaines organisations optent pour un hébergement interne afin de garantir la confidentialité des données, de répondre à des exigences de personnalisation ou de minimiser la latence. Les applications des secteurs de la finance, de la santé et des administrations publiques ne peuvent souvent pas envoyer de données à des API tierces, même en cas d'avantages financiers.
Les moteurs d'inférence open source comme vLLM permettent des déploiements auto-hébergés hautes performances. Les techniques PagedAttention et de traitement par lots continu de vLLM optimisent l'utilisation du GPU, rendant l'auto-hébergement plus compétitif sur le plan économique.
| Facteur | Favorise les API | Favorise l'auto-hébergement |
|---|---|---|
| Volume | <10 millions de jetons/jour | >50 millions de jetons/jour |
| Schéma de circulation | Variable/pointu | Cohérent/prévisible |
| Besoins en latence | Flexible | ultra-faible requis |
| Sensibilité des données | Standard | Très sensible |
| Personnalisation | Modèles standard OK | Besoin de modèles personnalisés |
| Capacités techniques | Opérations ML limitées | Équipe d'opérations ML solide |
Techniques d'optimisation qui transforment l'économie
Plusieurs techniques permettent de réduire les coûts d'inférence de 2 à 10 fois sans compromettre la qualité. Ces optimisations fonctionnent aussi bien avec des API qu'en auto-hébergement.
Quantification
La quantification réduit la précision du modèle, passant de nombres à virgule flottante 16 ou 32 bits à des entiers 8 ou même 4 bits. Cela diminue l'empreinte mémoire et accélère l'inférence.
Les méthodes de quantification modernes préservent remarquablement bien la qualité. Selon des recherches sur l'entraînement FP8, la plupart des variables utilisées pour l'entraînement et l'inférence des modèles linéaires à longue portée (LLM) peuvent être quantifiées à faible précision sans compromettre l'exactitude. Des fournisseurs comme Together.ai proposent des modèles quantifiés à prix réduit tout en garantissant la qualité.
Optimisation rapide
La longueur des invites a un impact direct sur les coûts. Une invite de 5 000 jetons traitée 1 000 fois coûte autant que 5 millions de jetons d'inférence. Optimiser les invites pour qu'elles soient concises tout en conservant leur efficacité permet de réduire immédiatement les coûts.
Les recherches montrent que l'optimisation des invites peut améliorer la précision des tâches tout en réduisant la consommation de jetons. Des invites bien structurées guident les modèles plus efficacement, réduisant ainsi le nombre de jetons de raisonnement nécessaires pour parvenir aux bonnes réponses.
Mise en cache des réponses
De nombreuses applications effectuent des requêtes similaires ou identiques de manière répétée. La mise en cache des réponses aux requêtes courantes élimine totalement les coûts d'inférence redondants.
Les stratégies de mise en cache intelligentes prennent en compte la similarité des requêtes, et non seulement les correspondances exactes. La mise en cache sémantique compare le sens des requêtes et renvoie des réponses mises en cache pour les requêtes suffisamment similaires, même si la formulation diffère.
Routage du modèle
Toutes les requêtes ne nécessitent pas le modèle le plus puissant. Acheminer les requêtes simples vers des modèles légers et rapides, et les requêtes complexes vers des modèles plus volumineux, optimise le compromis coût-qualité.
Cela nécessite une logique préalable pour classifier la complexité des requêtes, mais les avantages économiques justifient souvent l'investissement. Acheminer 701 TP3T de trafic vers un modèle de jeton à 1 TP4T0,10/million et 301 TP3T vers un modèle à 1 TP4T3/million permet d'obtenir un coût moyen de 1 TP4T0,97/million, soit nettement inférieur à celui obtenu en utilisant le modèle le plus coûteux pour l'ensemble du trafic.
Paysage des fournisseurs en 2026
Le marché des fournisseurs de services d'inférence a considérablement évolué. Plusieurs catégories de fournisseurs répondent désormais à différents besoins.
API du modèle Frontier
OpenAI, Anthropic et Google proposent des solutions de pointe à un prix élevé. Les modèles de type GPT-4 coûtent entre $2 et 15 par million de jetons, selon les variantes. Ces fournisseurs investissent massivement dans la sécurité, la fiabilité et les technologies de pointe.
Les modèles o3 et o4-mini d'OpenAI, publiés en 2025, représentent des avancées significatives en matière de raisonnement. D'après les évaluations d'OpenAI, o3 commet moins d'erreurs majeures que o1 sur des tâches complexes du monde réel, et excelle particulièrement dans les applications de programmation et de conseil en gestion.
Plateformes modèles open source
Des fournisseurs comme Together.ai, Fireworks et Replicate proposent des modèles open source à des prix nettement inférieurs. Les modèles DeepSeek sur Together.ai permettent de réaliser des économies de 70 à 901 TP3T par rapport aux solutions propriétaires, tout en offrant des performances de pointe.
Ces plateformes combinent des modèles open source courants avec une infrastructure de diffusion propriétaire. Résultat : d’excellentes performances à des prix nettement inférieurs, même si le filtrage de sécurité et la modération de contenu sont parfois moins poussés.
Services d'IA des fournisseurs de cloud
AWS, Azure et Google Cloud proposent leurs propres modèles ainsi que des modèles tiers via des API unifiées. Les prix varient, mais les fournisseurs de cloud appliquent généralement une marge par rapport à un accès direct via API, tout en offrant des fonctionnalités destinées aux entreprises telles que les SLA, les certifications de conformité et l'intégration avec l'infrastructure cloud existante.
Fournisseurs d'inférences spécialisés
Des entreprises comme Groq se concentrent spécifiquement sur l'optimisation de l'inférence. Groq se concentre sur l'optimisation de l'inférence grâce à des puces personnalisées pour des performances à faible latence.
Évolution future des coûts
Quelle sera l'évolution des coûts d'inférence à partir de maintenant ? Plusieurs tendances influencent les anticipations.
Les taux de réduction des coûts de 10 fois par an observés entre 2021 et 2025 ne devraient pas se maintenir au même rythme. Les optimisations les plus faciles à mettre en œuvre ont déjà été réalisées. Les améliorations matérielles se poursuivent, mais à un rythme plus modéré. Les innovations en matière d'architecture de modèles se poursuivent, mais moins fréquemment que durant la période de forte croissance de 2022 à 2024.
Une prévision plus réaliste table sur des réductions annuelles de 3 à 5 fois jusqu'en 2027, puis un ralentissement à 1,5-2 fois par an. Cela représente tout de même une amélioration considérable, même si le rythme n'est pas aussi soutenu que ces dernières années.
Le défi que représente la consommation de jetons de raisonnement stimulera les innovations architecturales. Les modèles capables d'un raisonnement performant avec une faible surcharge de jetons domineront le marché. Il faut s'attendre à la poursuite des recherches sur les mécanismes de raisonnement efficaces.
La concurrence reste féroce. L'arrivée de DeepSeek a bouleversé les prix sur l'ensemble du marché, obligeant les acteurs historiques à baisser leurs tarifs ou à se différencier autrement. D'autres perturbations sont susceptibles de provenir de sources inattendues : des startups aux architectures novatrices ou des acteurs régionaux aux structures économiques différentes.
Construire une économie de l'IA durable
Les organisations qui s'appuient sur des LLM ont besoin de stratégies efficaces quelles que soient les fluctuations de prix. Plusieurs principes permettent une rentabilité durable.
- Tout d'abord, concevez une architecture flexible. Évitez d'imposer des dépendances à des fournisseurs ou des modèles spécifiques. Abstractionnez l'inférence derrière des interfaces permettant de changer de fournisseur en fonction de l'évolution du marché.
- Deuxièmement, instrumentez tout. Mesurez la consommation de jetons, le coût par requête et le coût par résultat commercial. De nombreuses organisations constatent que 201 000 milliards de dollars de cas d’utilisation engendrent 801 000 milliards de dollars de coûts, et que certains cas d’utilisation coûteux n’apportent qu’une valeur minime.
- Troisièmement, investissez dans l'optimisation. Les techniques évoquées précédemment (quantification, mise en cache, routage, optimisation des prompts) ont un effet cumulatif. Une amélioration de 2x peut paraître modeste, mais elle se traduit par une réduction des coûts de 50% chaque mois.
- Quatrièmement, adaptez les capacités du modèle aux exigences de la tâche. Utiliser des modèles de pointe pour chaque tâche est un gaspillage de ressources. Mettre en place une logique de classification qui achemine les requêtes de manière appropriée est rentable.
- Enfin, prévoyez une visibilité sur la consommation de jetons. Le problème des jetons de raisonnement prend souvent les équipes au dépourvu lorsqu'elles ne surveillent pas leur consommation interne. Les fournisseurs proposent de plus en plus de données télémétriques affichant l'utilisation cachée des jetons ; utilisez-les.
Questions fréquemment posées
Quel est le coût par requête d'inférence LLM ?
Les coûts d'inférence des modèles linéaires à grande échelle (LLM) varient considérablement en fonction de la taille du modèle et de la complexité des requêtes. Les requêtes simples pour les petits modèles (3 à 7 milliards de paramètres) coûtent quelques centimes, soit environ $0,01 à 0,05 pour 1 000 requêtes. Les modèles de taille moyenne (13 à 70 milliards de paramètres) coûtent entre $0,10 et 0,80 pour 1 000 requêtes. Les grands modèles de pointe (plus de 175 milliards de paramètres) coûtent entre $2 et 15 pour 1 000 requêtes. Cependant, les modèles de raisonnement peuvent consommer 50 à 100 fois plus de jetons que ne le suggère la longueur de la sortie, ce qui augmente considérablement les coûts réels.
L'auto-hébergement est-il moins cher que l'utilisation de services API ?
L'auto-hébergement devient plus économique que les API lorsque l'utilisation du GPU dépasse environ 501 TP3T de manière constante. Cela nécessite généralement le traitement de plus de 10 millions de jetons par jour et par GPU. En dessous de ce seuil, les API sont généralement plus avantageuses car elles permettent d'éviter les dépenses d'investissement et de ne pas payer pour une capacité inutilisée. L'auto-hébergement requiert également une expertise en opérations d'apprentissage automatique et une gestion d'infrastructure conséquente.
Pourquoi les modèles de raisonnement sont-ils si chers ?
Les modèles de raisonnement génèrent une quantité importante de jetons de “ réflexion ” internes avant de produire un résultat. Une réponse comportant 200 jetons visibles peut consommer entre 10 000 et 30 000 jetons au total lors du raisonnement. Cette consommation interne de jetons est facturée, mais reste invisible dans le résultat, ce qui peut donner l'impression d'un faible coût par jeton alors que le coût total est élevé. Certaines requêtes de raisonnement consomment plus de 600 jetons pour générer des réponses de deux mots.
Comment puis-je réduire les coûts d'inférence LLM ?
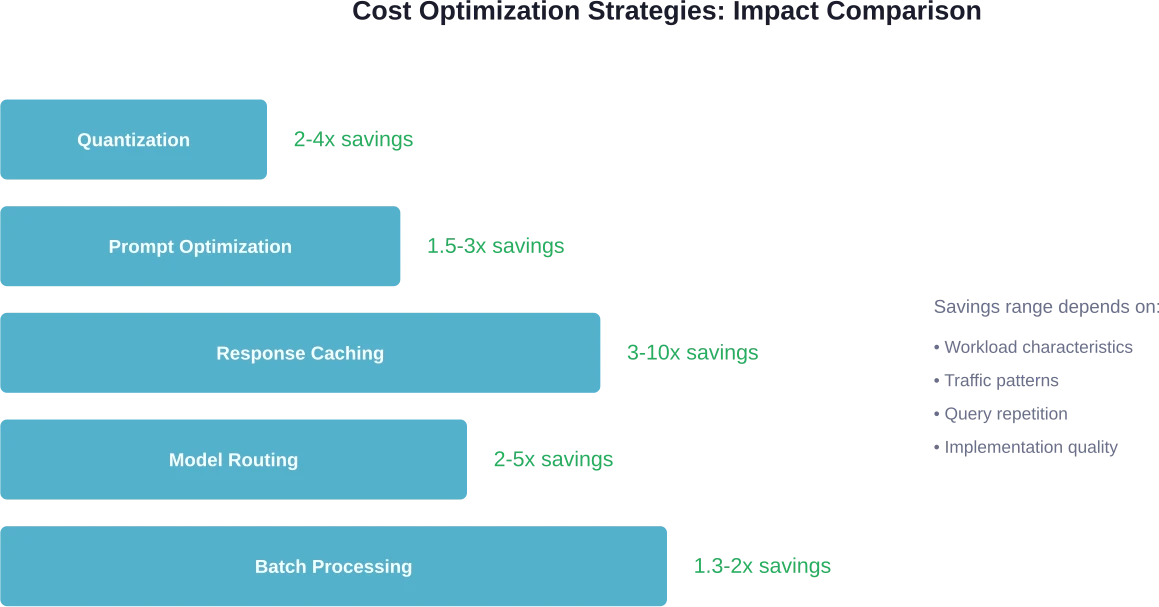
Cinq stratégies principales permettent de réduire les coûts d'inférence : la quantification (économies de 2 à 4 fois), la mise en cache des réponses pour les requêtes répétées (économies de 3 à 10 fois), l'optimisation des prompts pour réduire l'utilisation des jetons (économies de 1,5 à 3 fois), le routage des modèles pour utiliser des modèles plus petits pour les tâches simples (économies de 2 à 5 fois) et le traitement par lots pour les charges de travail axées sur le débit (économies de 1,3 à 2 fois). L'efficacité de ces techniques est décuplée lorsqu'elles sont combinées efficacement.
Quel est le coût actuel pour des performances équivalentes à celles de GPT-4 ?
En mars 2026, atteindre les performances de GPT-4 coûtera environ $0,40 à $0 par million de jetons en utilisant des alternatives concurrentes comme DeepSeek V3 ou des modèles de milieu de gamme proposés par les principaux fournisseurs. Le modèle GPT-4 d'OpenAI coûte actuellement entre $2 et $15 par million de jetons, selon la variante. Cela représente une baisse considérable par rapport à fin 2022, où des performances équivalentes coûtaient plus de $20 par million de jetons.
Comment se comparent les coûts des GPU cloud chez différents fournisseurs ?
Début 2026, le prix des GPU Cloud H100 s'est stabilisé entre 2,85 et 3,50 TP4T chez les principaux fournisseurs. Certains fournisseurs régionaux proposent des tarifs inférieurs (2,20 à 2,60 TP4T) assortis de SLA réduits. Les cartes A800, courantes dans certaines régions, coûtent environ 0,79 TP4T par heure, en fonction de l'économie d'infrastructure. Les configurations multi-GPU bénéficient généralement de remises sur volume de 10 à 20 TP3T.
Les coûts d'inférence LLM vont-ils continuer à baisser ?
Les coûts d'inférence devraient continuer de diminuer, mais à un rythme moins soutenu que les réductions annuelles d'un facteur 10 observées entre 2021 et 2025. On peut raisonnablement s'attendre à des réductions annuelles d'un facteur 3 à 5 jusqu'en 2027, puis à un ralentissement à un facteur 1,5 à 2 à mesure que les opportunités d'optimisation se raréfient. Les améliorations matérielles et les innovations architecturales maintiendront cette baisse, mais le rythme exceptionnel de ces dernières années ne devrait pas se maintenir indéfiniment.
Leçons stratégiques à tirer des applications basées sur l'IA
Comprendre l'économie de l'inférence LLM est plus important que jamais. L'écart entre une implémentation naïve et un déploiement optimisé peut représenter des différences de coût de 5 à 10 fois supérieures, suffisantes pour déterminer la viabilité économique de l'opération.
Le prix des jetons ne donne qu'une vision partielle de la situation. La consommation totale de jetons, y compris les jetons de justification cachés, détermine les coûts réels. Le suivi et le contrôle de cette consommation sont essentiels à la pérennité des opérations.
Le choix entre les services API et l'auto-hébergement dépend de l'échelle, des habitudes d'utilisation et des capacités organisationnelles. Aucune option ne s'impose systématiquement. Analysez votre situation spécifique plutôt que de suivre aveuglément les tendances du secteur.
Les techniques d'optimisation sont cumulatives. La quantification, la mise en cache, l'ingénierie des requêtes et le routage des modèles, combinés, peuvent réduire les coûts d'un facteur 10, voire plus, par rapport aux implémentations de base. Investir dans ces optimisations génère des bénéfices durables.
Le marché continue d'évoluer rapidement. De nouveaux fournisseurs, modèles et structures tarifaires apparaissent régulièrement. La mise en place d'architectures flexibles, capables de s'adapter à l'évolution du marché, permet de se prémunir contre l'inflation des coûts et les opportunités manquées offertes par des alternatives plus performantes.
Soyons francs : les coûts d’inférence LLM ont chuté de façon spectaculaire, mais cela ne signifie pas pour autant que l’infrastructure d’IA est bon marché. Cela signifie simplement que le rapport économique est passé d’un coût prohibitif à un coût gérable grâce à une optimisation rigoureuse. Les équipes qui comprennent ces enjeux économiques et conçoivent leurs architectures en conséquence bâtiront des entreprises d’IA pérennes. Celles qui considèrent l’inférence comme un simple produit de base, sans en comprendre les facteurs de coût sous-jacents, auront des difficultés.
Prêt à optimiser vos coûts d'inférence LLM ? Commencez par mesurer votre consommation actuelle de jetons, y compris les jetons de raisonnement cachés. Identifiez vos cas d'utilisation les plus coûteux et évaluez si le routage des modèles ou l'optimisation des prompts pourraient réduire vos dépenses. Comparez votre volume actuel au seuil de rentabilité de l'auto-hébergement pour déterminer la pertinence d'un investissement dans l'infrastructure. Les enseignements tirés auront un impact direct sur votre rentabilité.