Résumé rapide : La reconnaissance optique de caractères (OCR) révolutionne l'automatisation des processus métier en convertissant les documents imprimés et manuscrits en données exploitables par machine, permettant ainsi le traitement automatisé des factures, contrats et formulaires. Les systèmes OCR modernes atteignent une précision de 99,91 % lorsqu'ils sont associés à la validation par intelligence artificielle, réduisant la saisie manuelle de données jusqu'à 801 % et libérant les équipes pour des tâches stratégiques. Les entreprises obtiennent un retour sur investissement optimal lorsque l'OCR est intégrée à des flux de travail repensés, et non simplement ajoutée aux processus manuels existants.
La saisie manuelle des données issues des factures, des contrats et des CV constitue un goulot d'étranglement opérationnel majeur. Ce processus est lent, source d'erreurs et détourne les équipes qualifiées de tâches à forte valeur ajoutée.
Certaines équipes financières perdent jusqu'à 72 jours de travail par an à cause du seul traitement manuel des factures. Cela représente près de trois mois de productivité perdus en saisie et validation fastidieuses.
La technologie OCR change complètement la donne. En extrayant automatiquement le texte des documents numérisés, des PDF et des images, l'OCR permet un traitement automatisé de bout en bout qui élimine la plupart des interventions manuelles.
Ce guide explique ce que les entreprises doivent savoir sur l'automatisation de la reconnaissance optique de caractères (OCR) en 2026 : comment fonctionne cette technologie, où elle apporte le plus de valeur et ce qui distingue les outils de numérisation de base des plateformes d'automatisation de niveau entreprise.
Qu'est-ce que la reconnaissance optique de caractères (OCR) et comment permet-elle l'automatisation des processus métier ?
La reconnaissance optique de caractères (OCR) analyse les images de texte dans les documents, identifie les motifs de caractères et les convertit en texte brut lisible par machine. Cette technologie existe depuis le début du XXe siècle, mais les implémentations modernes diffèrent considérablement de leurs prédécesseurs.
La reconnaissance optique de caractères (OCR) traditionnelle fonctionnait assez bien pour les textes imprimés aux formats standardisés. Mais avec l'écriture manuscrite, une mauvaise qualité de numérisation ou des mises en page non standardisées, les taux de précision chutaient à 50%, voire moins.
En 2026, les plateformes OCR avancées combineront la reconnaissance de caractères avec l'intelligence artificielle, l'apprentissage automatique et le traitement automatique du langage naturel. Il en résultera des systèmes capables de traiter des notes manuscrites avec une précision d'environ 90%, de gérer des documents dans plus de 200 langues et d'apprendre des corrections apportées au fil du temps.
La véritable valeur ajoutée se révèle lorsque la reconnaissance optique de caractères (OCR) est intégrée à l'automatisation complète des flux de travail. Selon une étude du MIT Sloan, l'IA est plus efficace lorsque les organisations repensent leurs flux de travail plutôt que de se contenter d'automatiser des tâches individuelles.
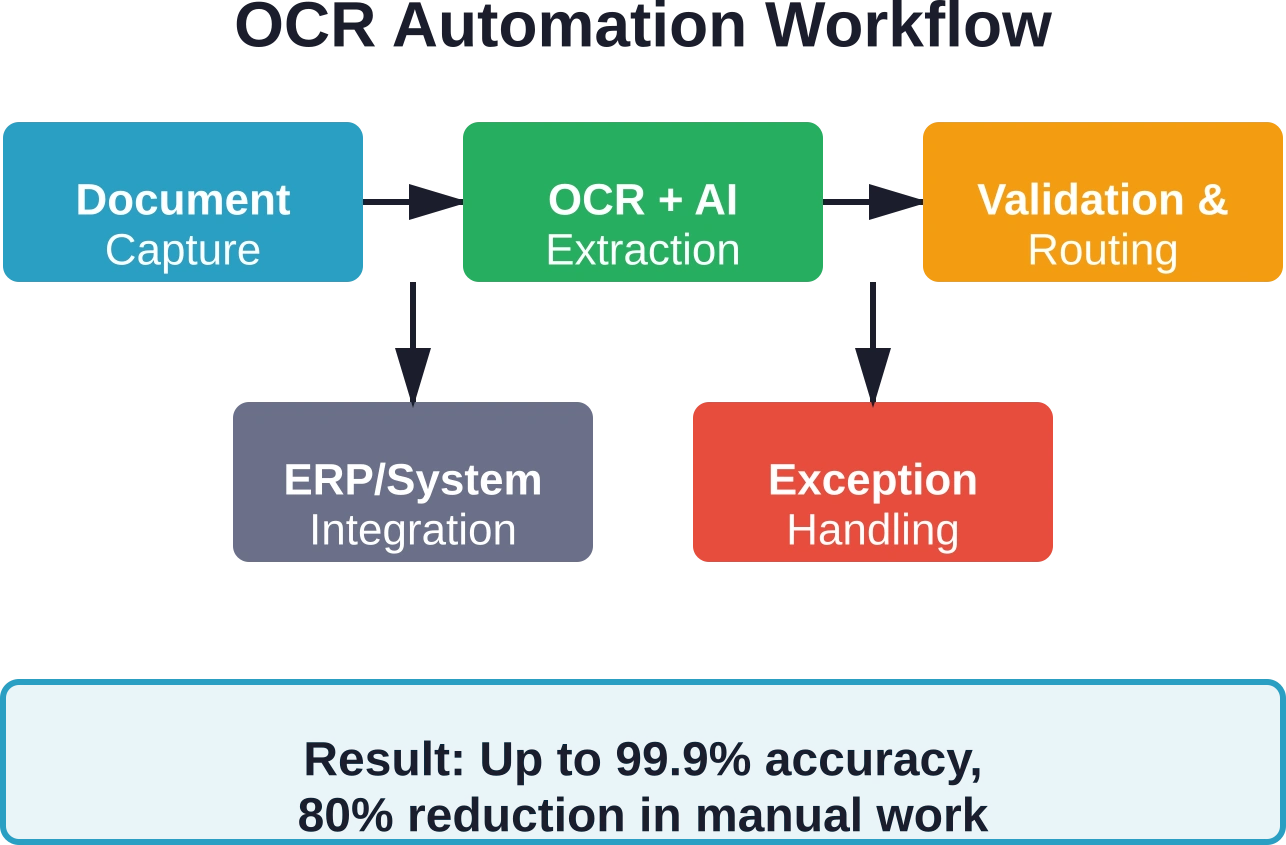
OCR traditionnel vs. OCR avancé : qu’est-ce qui a changé ?
L'écart entre les systèmes OCR traditionnels et avancés s'est considérablement creusé. Comprendre ces différences est essentiel pour évaluer les solutions d'automatisation des processus métier.
| Fonctionnalité | OCR traditionnel | OCR avancé |
|---|---|---|
| Assistance linguistique | Environ 120 langues | Plus de 200 langues avec prise en charge des dialectes |
| Reconnaissance de l'écriture manuscrite | Précision aussi faible que 50% | Précision d'environ 90% |
| Capacité d'apprentissage | Traitement statique basé sur des règles | IA auto-apprenante |
| Agencements complexes | Nécessite des modèles standardisés | Gère les formats variables |
Les plateformes modernes combinent la reconnaissance optique de caractères (OCR), l'intelligence artificielle (IA) et des contrôles automatisés pour atteindre une précision de 99,91 % (TP3T). Ce niveau de précision rend le traitement automatisé viable pour les opérations à haut volume.
L'équipe du service de gestion documentaire de l'Université du Colorado souligne que la reconnaissance optique de caractères (OCR) avec capacités de traitement par lots aide les départements à éliminer les inefficacités liées au papier tout en garantissant la conformité aux réglementations telles que FERPA et HIPAA.
Là où la reconnaissance optique de caractères (OCR) offre la plus grande valeur commerciale
L'automatisation de la reconnaissance optique de caractères (OCR) ne profite pas de la même manière à tous les processus documentaires. Trois domaines affichent systématiquement le meilleur retour sur investissement : le traitement des factures, la gestion des contrats et l'intégration des clients.
Automatisation des factures et des comptes fournisseurs
Les services de comptabilité fournisseurs traitent des milliers de factures chaque mois, chacune nécessitant l'extraction, la validation, le codage, le circuit d'approbation et le paiement des données.
Les principales plateformes automatisent le traitement des factures avec une précision allant jusqu'à 99,9% lorsqu'elles sont combinées à la validation par IA et réduisent la saisie manuelle de données jusqu'à 80%, ce qui séduit les équipes de comptabilité fournisseurs soucieuses de cycles de clôture plus rapides.
Le flux de travail comprend généralement la capture automatique à partir des e-mails ou des portails, l'extraction des champs, la correspondance à trois voies avec les bons de commande, le routage automatisé pour approbation et la publication directe dans les systèmes ERP.
Analyse et gestion des contrats
Les équipes juridiques et d'approvisionnement traitent des contrats qui arrivent souvent sous forme de PDF scannés ou de documents papier. Extraire manuellement les clauses essentielles, les dates, les obligations et les clauses de renouvellement est une tâche longue et risquée.
Selon l'étude de WashU Law sur les logiciels de rédaction de documents juridiques basés sur l'IA (publiée le 20 août 2025), les processus manuels traditionnels de rédaction de documents présentent des vulnérabilités liées aux erreurs humaines, aux incohérences et à la perte de temps que les systèmes modernes permettent de corriger.
Intégration des clients et KYC
Les services financiers, les secteurs de la santé et les industries réglementées sont soumis à des exigences de documentation importantes pour les nouveaux clients.
La reconnaissance optique de caractères (OCR) permet la capture de documents mobiles : les clients photographient leur permis de conduire ou leur passeport, et le système extrait et valide instantanément les informations. Associée à la détection de présence et à la vérification dans les bases de données, cette technologie offre une expérience d'intégration fluide tout en garantissant la conformité aux normes.

Automatisez vos flux de travail OCR grâce à l'IA supérieure
La reconnaissance optique de caractères (OCR) prend toute sa valeur lorsqu'elle est intégrée aux processus métier plutôt que d'être utilisée uniquement pour extraire du texte à partir de fichiers numérisés. IA supérieure Cette entreprise propose des services de vision par ordinateur, d'apprentissage automatique, de traitement de données, de conseil en IA et de développement de logiciels d'IA sur mesure pour les flux de travail impliquant un grand nombre de documents. Ces compétences permettent aux organisations d'extraire, de structurer et d'exploiter les informations contenues dans des documents numérisés, des images, des formulaires et des enregistrements. Elles offrent des solutions intelligentes de traitement de documents dans le cadre de leurs services de vision par ordinateur.
AI Superior peut prendre en charge l'automatisation de la reconnaissance optique de caractères (OCR) grâce à :
- définition du cas d'utilisation du traitement de documents
- Extraction de données à partir de documents et d'images numérisés
- Vision par ordinateur et apprentissage automatique pour les flux de travail documentaires
- Logiciel d'IA personnalisé pour l'automatisation des processus
👉Contactez l'IA supérieure pour discuter de l'automatisation de la reconnaissance optique de caractères (OCR) pour les flux de travail documentaires, l'optimisation de la saisie de données ou l'amélioration des processus internes.
Choisir un logiciel de reconnaissance optique de caractères (OCR) : ce qui compte vraiment
Les listes de fonctionnalités et les démonstrations des fournisseurs révèlent rarement l'essentiel. Voici ce qui distingue les plateformes OCR efficaces des outils qui créent plus de problèmes qu'ils n'en résolvent.
Évaluation de la précision et de la confiance
Les pourcentages de précision bruts sont peu significatifs sans contexte. L'indicateur pertinent est le taux de traitement automatisé de bout en bout, c'est-à-dire le pourcentage de documents traités intégralement sans intervention humaine.
Recherchez les plateformes qui fournissent des scores de confiance au niveau des champs. Si le système extrait un total de facture avec un niveau de confiance de 99,8% mais un nom de fournisseur avec un niveau de confiance de seulement 72%, il devrait signaler uniquement ce champ pour vérification au lieu de rejeter le document entier.
Architecture d'intégration
La reconnaissance optique de caractères (OCR) non connectée aux systèmes en aval génère des tâches répétitives et fastidieuses, au lieu d'automatiser les processus. La plateforme devrait proposer des API REST pour une intégration personnalisée, des connecteurs prédéfinis pour les systèmes ERP et de gestion courants, la prise en charge des webhooks pour les flux de travail événementiels et l'exportation en masse aux formats standard.
Formation et adaptabilité
Aucun système de reconnaissance optique de caractères (OCR) ne gère parfaitement tous les formats de documents dès sa mise en service. La question est de savoir dans quelle mesure il s'adapte facilement aux documents spécifiques à une organisation.
Les plateformes de pointe utilisent une IA auto-apprenante qui s'améliore grâce aux corrections. Lorsqu'un utilisateur corrige une erreur d'extraction, le système intègre cette correction et l'applique automatiquement aux documents similaires.
Modèles d'implémentation qui fonctionnent
Les capacités techniques importent moins que la méthode de mise en œuvre. Les organisations qui réussissent en matière d'automatisation de la reconnaissance optique de caractères (OCR) suivent des schémas bien précis.
Commencez par les processus les plus standardisés et à plus fort volume.
La première implémentation d'un système de reconnaissance optique de caractères (OCR) ne doit pas s'attaquer au problème le plus complexe. Commencez par des processus à volume élevé utilisant des documents relativement standardisés. Les factures des principaux fournisseurs, les documents d'expédition ou les formulaires récurrents conviennent parfaitement.
Cela renforce la confiance, démontre rapidement le retour sur investissement et donne le temps de comprendre la technologie avant de s'attaquer aux cas particuliers.
Repensez le flux de travail, ne vous contentez pas de le numériser.
Mais voilà le point crucial : les recherches du MIT montrent que l’IA apporte un maximum de valeur lorsque les organisations repensent leurs flux de travail plutôt que d’automatiser des tâches au sein des processus existants.
Si le processus actuel implique la réception d'une facture papier, sa numérisation, la saisie manuelle des données dans une feuille de calcul, l'envoi de cette feuille de calcul par courriel aux approbateurs, et enfin la saisie des données approuvées dans le système ERP, l'ajout de la reconnaissance optique de caractères (OCR) ne transforme pas ce flux de travail.
Meilleure approche : repenser le processus autour d’un traitement automatisé de bout en bout. Les factures arrivent par e-mail ou via un portail ; la reconnaissance optique de caractères (OCR) extrait les données directement dans l’ERP sous forme de brouillons ; des règles automatisées acheminent les demandes d’approbation en fonction du montant et du code comptable, et les tâches sont approuvées directement depuis une file d’attente dans l’ERP.
Prévoyez les exceptions dès le premier jour
Soyons réalistes : aucun système d’automatisation ne garantit une précision absolue. Les systèmes OCR avancés peuvent apprendre de leurs erreurs, mais la gestion des exceptions doit être intégrée dès la conception.
Une gestion efficace des exceptions comprend des seuils de confiance clairs pour le traitement automatique, des interfaces de révision intuitives mettant en évidence les champs incertains, des voies d'escalade pour les documents que le système ne peut pas traiter et des boucles de rétroaction permettant aux corrections d'entraîner l'IA.
Mesurez les résultats du processus, et pas seulement les indicateurs des outils.
Les tableaux de bord des fournisseurs affichent la précision de l'extraction, la vitesse de traitement et le débit. Ces données sont importantes, mais l'entreprise s'intéresse à d'autres indicateurs : le délai de clôture, le coût par facture traitée, le délai d'approbation et le taux d'erreur dans les rapports financiers.
| Métrique d'outil | Indicateur d'impact commercial |
|---|---|
| taux de précision de l'OCR | Taux d'erreur dans les états financiers |
| Documents traités par heure | Jours avant la clôture financière |
| Traitement direct % | Coût par facture traitée |
| Temps de traitement des exceptions | Heures du personnel saisies manuellement |
OCR et RPA : mieux ensemble
La reconnaissance optique de caractères (OCR) extrait les données. L'automatisation robotisée des processus (RPA) les traite. Leur combinaison permet une automatisation de bout en bout, impossible à réaliser individuellement.
Prenons l'exemple du traitement des commandes. La reconnaissance optique de caractères (OCR) extrait les données des courriels de confirmation des fournisseurs. L'automatisation robotisée des processus (RPA) valide ensuite ces données par rapport à la commande d'origine dans le système d'approvisionnement, met à jour les dates de livraison, déclenche des notifications d'entrepôt et ajuste les prévisions de la demande dans le système de planification.
Lors de la mise en œuvre conjointe de l'OCR et de la RPA, concevez l'intégralité du flux de travail avant toute construction, identifiez les points de décision nécessitant des règles métier, assurez-vous que le format de sortie de l'OCR corresponde aux exigences d'entrée de la RPA et prévoyez une gestion des exceptions pour les échecs de l'OCR et les erreurs de la RPA.
Erreurs courantes de mise en œuvre de la reconnaissance optique de caractères (OCR)
Plusieurs schémas conduisent à des projets OCR infructueux ou décevants.
Sous-estimation des exigences en matière de qualité des données
Même les systèmes de reconnaissance optique de caractères (OCR) les plus avancés peinent à traiter des données d'entrée de mauvaise qualité. Les documents faxés, les photocopies de quatrième génération et les images prises dans de mauvaises conditions d'éclairage génèrent des erreurs d'extraction qu'aucune intelligence artificielle ne peut totalement corriger.
Améliorez la qualité des sources lorsque cela est possible. Incitez les fournisseurs à envoyer les factures au format PDF plutôt que de les numériser. Proposez des applications mobiles avec retour d'information sur la qualité d'image pour la capture de documents par les clients.
Ignorer la gestion du changement
La reconnaissance optique de caractères (OCR) transforme les méthodes de travail. Les employés du service comptabilité fournisseurs, qui saisissaient manuellement les factures depuis des années, examinent désormais les exceptions et gèrent les escalades. Cela requiert des compétences différentes et une formation adaptée.
Passer outre la phase pilote
Déployer la solution à grande échelle sans phase pilote augmente inutilement les risques. Réalisez un projet pilote ciblé sur un seul type de document ou une seule unité opérationnelle. Validez l'exactitude des données, testez les intégrations, formez les utilisateurs et optimisez le flux de travail avant tout déploiement à plus grande échelle.
Questions fréquemment posées
Quel taux de précision les entreprises peuvent-elles attendre des logiciels OCR modernes ?
Les plateformes OCR avancées atteignent une précision de 99,91 TP3T pour le texte imprimé sur des documents propres, grâce à l'intégration de règles de validation par IA. Le texte manuscrit atteint généralement une précision d'environ 901 TP3T avec les solutions leaders du marché. Les résultats réels dépendent de la qualité du document, de la complexité de sa mise en page et de l'utilisation ou non de modèles spécifiques à l'organisation pour l'entraînement du système.
Dans quelle mesure la reconnaissance optique de caractères (OCR) peut-elle réduire la charge de travail liée à la saisie manuelle de données ?
Les données sectorielles montrent que l'automatisation de la reconnaissance optique de caractères (OCR) peut réduire la saisie manuelle de données jusqu'à 801 000 tâches pour les processus documentaires à volume élevé, comme le traitement des factures. La réduction exacte dépend de la normalisation des documents, des exigences en matière de gestion des exceptions et de la conception du flux de travail. Les organisations qui repensent leurs processus autour de l'automatisation constatent des gains plus importants que celles qui se contentent d'ajouter l'OCR à leurs flux de travail manuels existants.
La reconnaissance optique de caractères (OCR) fonctionne-t-elle avec les documents manuscrits ?
Oui, mais la précision varie considérablement. Les systèmes OCR traditionnels peinaient à traiter l'écriture manuscrite, avec des taux de précision pouvant descendre jusqu'à 501 TP3T. Les plateformes OCR avancées dotées d'IA atteignent une précision d'environ 901 TP3T sur les textes manuscrits. Les performances dépendent de la lisibilité de l'écriture, de la langue et de la prise en charge de l'écriture cursive ou d'écriture imprimée par le système.
La reconnaissance optique de caractères (OCR) peut-elle s'intégrer aux systèmes d'information existants tels que les progiciels de gestion intégrée (ERP) et les systèmes de gestion de la relation client (CRM) ?
Les plateformes OCR de niveau entreprise offrent des API REST, des webhooks et des connecteurs préconfigurés pour les systèmes d'entreprise courants, notamment les principales plateformes ERP, comptables et CRM. L'architecture d'intégration est un critère d'évaluation essentiel : une solution OCR qui exporte des fichiers nécessitant un chargement manuel ne permet pas une véritable automatisation.
Quels types de documents bénéficient le plus de l'automatisation de la reconnaissance optique de caractères (OCR) ?
Les documents semi-standardisés à volume élevé offrent le meilleur retour sur investissement : factures fournisseurs, bons de commande, contrats, documents d’expédition, déclarations de sinistre, demandes de prêt et formulaires fiscaux. Les solutions idéales combinent un volume de traitement important (plus de 1 000 documents par mois), une mise en forme relativement homogène provenant des principales sources et une intégration claire avec les flux de travail en aval.
Combien de temps prend généralement la mise en œuvre d'un système OCR ?
Un projet pilote ciblé sur un seul type de document prend généralement de 6 à 8 semaines, de la configuration initiale à l'optimisation. Le déploiement complet en production, pour plusieurs types de documents et unités opérationnelles, nécessite généralement de 3 à 4 mois. Le calendrier de mise en œuvre dépend de la complexité de l'intégration, du nombre de variantes de documents, des exigences en matière de gestion des changements et du choix de l'organisation : refonte des flux de travail ou simple automatisation des processus existants.
Passer à l'étape suivante avec l'automatisation de la reconnaissance optique de caractères (OCR)
La technologie OCR a atteint un niveau de maturité tel qu'elle apporte une véritable valeur ajoutée aux entreprises – non pas de simples améliorations progressives, mais des changements transformationnels dans la manière dont les organisations gèrent les processus impliquant de nombreux documents.
Les organisations qui obtiennent les meilleurs résultats partagent des caractéristiques communes. Elles privilégient les processus standardisés à haut volume, repensent les flux de travail plutôt que de simplement numériser les étapes existantes et intègrent la gestion des exceptions dès les premières implémentations.
Pour les organisations prêtes à aller de l'avant, la voie est simple : identifier le processus documentaire le plus volumineux créant des goulots d'étranglement, cartographier le flux de travail complet depuis la réception du document jusqu'à sa saisie finale dans le système, sélectionner une plateforme dotée de capacités de précision et d'intégration appropriées, mener un projet pilote ciblé, puis étendre la solution en fonction des résultats obtenus.
L'alternative – le maintien du traitement manuel des documents – devient de moins en moins viable à mesure que les volumes d'activité augmentent et que la concurrence s'intensifie. Les équipes qui éliminent la saisie manuelle de données (tâche 80%) peuvent ainsi se consacrer à des activités stratégiques qui permettent à l'organisation de se démarquer.