Belangrijkste punten: De kosten voor het finetunen van LLM-modellen variëren doorgaans van $300 tot $12.000 of meer, afhankelijk van de modelgrootte, de gebruikte techniek en de infrastructuur. Kleine modellen (2-3 miljard parameters) met LoRA kosten $300-$700, terwijl grotere modellen (7 miljard parameters) $1.000-$3.000 kosten met LoRA of tot $12.000 voor volledige finetuning. Verborgen kosten, zoals datavoorbereiding, opslag, rekenkosten en doorlopend onderhoud, kunnen de initiële schattingen verdubbelen.
Het probleem ontstaat wanneer grote taalmodellen worden verfijnd. Wat begint als een veelbelovend AI-project, mondt al snel uit in een budgetbespreking die CFO's nerveus maakt.
De kosten voor finetuning gaan niet alleen over GPU-uren. De werkelijke kosten omvatten data-voorbereiding, opslag, mislukte experimenten en infrastructuurkosten die teams onverwacht treffen. Discussies binnen de community laten zien dat eenvoudige finetuning-taken $3.000 tot $10.000 kosten – en dat is nog voordat de verborgen kosten zijn meegerekend.
Hieronder leggen we uit wat die kosten nu eigenlijk veroorzaakt en hoe je ze beheersbaar kunt houden.
Een analyse van de werkelijke kosten voor fijnafstelling
De omvang van een model is belangrijker dan de meeste teams denken. Het aantal parameters heeft direct invloed op de benodigde rekenkracht en uiteindelijk op de factuur.
Op basis van de beschikbare gegevens, dit zijn de werkelijke kosten van de verschillende modelformaten:
| Modelmaat | Fijnafstemmingsmethode | Typisch kostenbereik | Trainingstijd |
|---|---|---|---|
| Phi-2 (2,7 miljard parameters) | LoRA | $300 – $700 | Enkele uren |
| Mistral 7B | LoRA | $1.000 – $3.000 | 6-12 uur |
| Mistral 7B | Volledige fijnafstelling | Tot $12.000 | 24-48 uur |
| Lama 2 7B | LoRA | $1.200 – $3.500 | 8-16 uur |
De gebruikte techniek is net zo belangrijk als de modelgrootte. Low-Rank Adaptation (LoRA) verlaagt de kosten aanzienlijk door slechts een kleine subset van parameters bij te werken in plaats van het hele model. LoRA-methoden behaalden een gemiddelde nauwkeurigheidsverbetering van 36% ten opzichte van basismodellen volgens benchmarks op financiële datasets, terwijl de kosten beheersbaar bleven.
Maar die cijfers vertellen slechts een deel van het verhaal.

Ontvang een duidelijke kostenraming voor LLM-finetuning van AI Superior.
De kosten voor het finetunen van LLM variëren afhankelijk van de omvang van de dataset, de modelkeuze, de infrastructuur en de evaluatievereisten. AI Superieur Het helpt organisaties te beoordelen of fijnafstemming nodig is of dat snelle technische oplossingen of oplossingen op basis van gegevensherstel kosteneffectiever zijn.
Hun aanpak omvat:
- Strategie voor gegevensbeoordeling en -voorbereiding
- Modelselectie en configuratie van de trainingspipeline
- Prestatie-evaluatie en benchmarking
- Implementatie en monitoring instellen
Als u uw LLM-traject wilt optimaliseren, raadpleeg dan AI Superieur voor een kosten-batenanalyse die aansluit op uw verwachte rendement op investering (ROI).
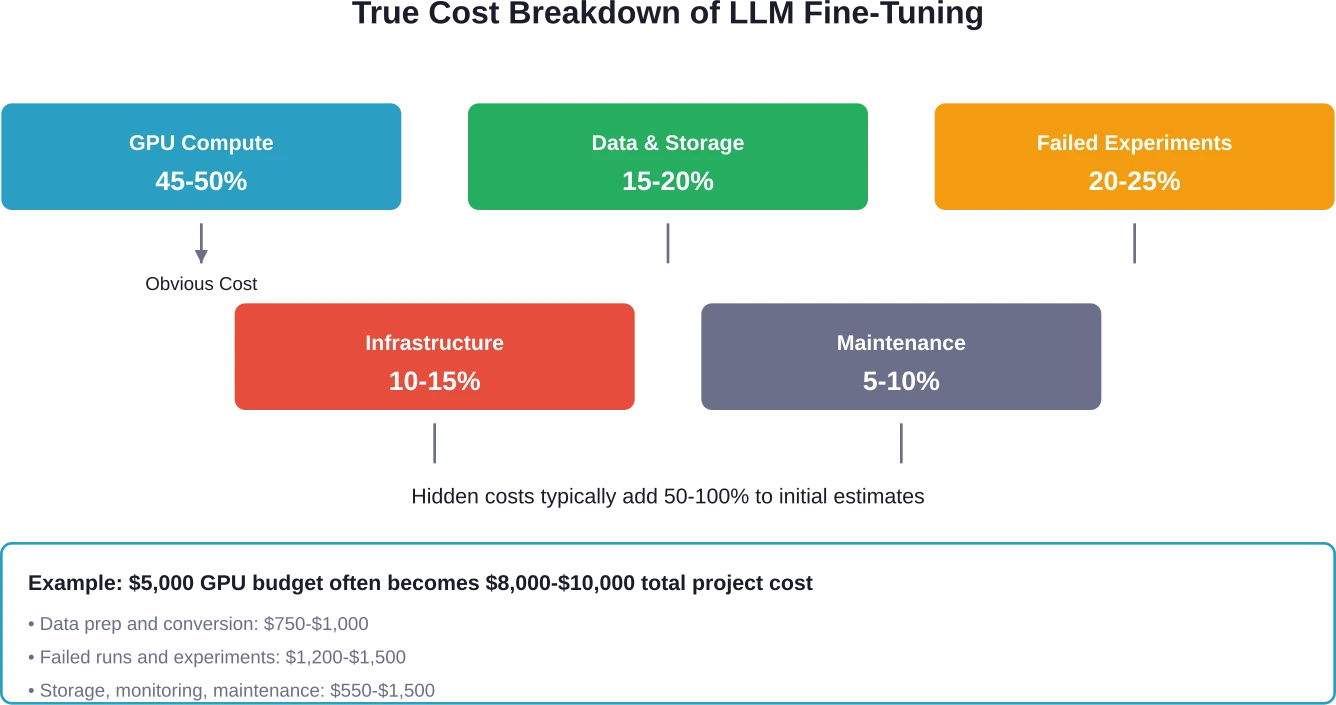
De verborgen kosten waar niemand je voor waarschuwt
De prijs die op het prijskaartje staat voor GPU-tijd vertegenwoordigt misschien de helft van de werkelijke kosten. De rest duikt op op plekken waar teams in eerste instantie geen rekening mee houden in hun budget.
Gegevensvoorbereiding en -opslag
Ruwe data is niet geschikt voor finetuning. Het converteren van datasets naar het juiste formaat – meestal JSONL voor de meeste platforms – kost tijd van ontwikkelaars. Communityleden die werken met 400.000 trainingsvoorbeelden en 2.000 testvoorbeelden melden aanzienlijke overhead bij de voorbewerking.
Opslagkosten lopen snel op. Trainingsdatasets, validatiesets, modelcontrolepunten en meerdere experimentele versies vereisen allemaal opslagruimte. AWS en andere cloudproviders brengen hiervoor aparte kosten in rekening, en die lopen in de loop van maanden flink op.
Mislukte experimenten en iteratie
De eerste finetuning-ronde levert zelden productieklare resultaten op. Teams blijven iteratief werken aan hyperparameters, datakwaliteit en trainingsmethoden. Elke iteratie kost geld.
Onderzoek naar data-efficiëntie toont aan dat complexiteitsbewuste fine-tuning dezelfde nauwkeurigheid behaalde met slechts 111 TP3T aan originele data en andere methoden gemiddeld met 4,71 TP3T overtrof. Maar het vinden van de optimale aanpak vereist experimenten, en mislukte experimenten kosten net zoveel als succesvolle.
Infrastructuurkosten
Zelf hosten brengt extra kosten met zich mee, bovenop de rekenkracht. Multi-GPU-clusters, netwerken, monitoring en onderhoud vereisen allemaal resources. Basis GPU-nodes kosten al snel $2.500 per maand, en onderbenutting betekent geldverspilling aan ongebruikte hardware.
OpenAI Fine-Tuning: API-gebaseerde prijsstelling
OpenAI biedt fine-tuning aan als een beheerde service, waarbij per token in plaats van per infrastructuur wordt gefactureerd. Het factureringsmodel verschilt aanzienlijk van zelfgehoste oplossingen.
De trainingskosten worden berekend door het aantal tokens te vermenigvuldigen met het aantal epochs. Voor GPT-3.5-turbo kost een volledige finetuning met typische trainingsdatasets van ongeveer 90.000-100.000 tokens enkele honderden dollars. Validatiesets brengen extra tokenkosten met zich mee.
Maar hier wordt het lastig. De API schat vooraf het maximaal mogelijke tokenverbruik in, inclusief afbeeldingstokens en overheadkosten voor functieaanroepen. Afbeeldingen kunnen tot 1.105 tokens verbruiken voor standaardresolutie of 36.835 tokens voor hoge resolutie per epoch – kosten die ontwikkelaars die de kleine lettertjes niet lezen, zullen verrassen.
Reinforcement Fine-Tuning (RFT) voor redeneermodellen maakt gebruik van een compleet andere factureringsmethode. In plaats van tokengebaseerde prijsstelling, berekent RFT de kosten op basis van de tijd die wordt besteed aan het uitvoeren van de kerntaken van machine learning. De facturering is afhankelijk van de instellingen van compute_multiplier, de validatiefrequentie en de selectie van het grader-model.
AWS- en cloudplatformkosten
Amazon Bedrock en SageMaker bieden beheerde finetuning met een pay-as-you-go prijsmodel. De kosten variëren per modelaanbieder, modaliteit en instantietype.
De prijs van SageMaker is afhankelijk van de gekozen instantie. De ml.g5.12xlarge-instantie, die doorgaans wordt gebruikt voor het finetunen van 7B-modellen, verbruikt ongeveer $7-$8 per uur. Een typische finetuning-taak die 8-12 uur duurt, kost alleen al aan rekenkracht $60-$100.
De prijsstelling van Amazon Bedrock varieert aanzienlijk per model. Titan-modellen, Claude-varianten en Llama-modellen hebben elk verschillende tarieven. Het finetunen van een ingebed model is doorgaans goedkoper dan het finetunen van een generatief model.
Opslag op AWS brengt extra kosten met zich mee. S3-opslag voor datasets, modelartefacten en checkpoints, plus EBS-volumes voor instanties, brengen kosten met zich mee. Voor een project met 1.000 gebruikers die dagelijks 10 verzoeken uitvoeren met 2.000 input-tokens en 1.000 output-tokens, kunnen de opslag- en gegevensoverdrachtskosten na verloop van tijd de rekenkosten overstijgen.
De keuze tussen zelfhosting en de cloud.
Zelf hosten lijkt in eerste instantie duur, maar kan op grotere schaal goedkoper uitvallen. De cloud lijkt in eerste instantie goedkoop, maar de kosten lopen na verloop van tijd op.
| Factor | Zelf gehost | Cloud/API |
|---|---|---|
| Initiële investering | Hoog ($5.000-$15.000) | Geen |
| Maandelijkse bedrijfskosten | Alleen elektriciteit (~$100-$300) | $500-$5,000+ |
| Schaalbaarheid | Beperkt door hardware | Vrijwel onbeperkt |
| Onderhoudslast | Hoog (intern team) | Geen |
| Gegevensprivacy | Volledige controle | Afhankelijk van de aanbieder |
| Break-evenpunt | 3-6 maanden | Niet van toepassing |
Een RTX 4090 kost 1.600 euro als eenmalige aankoop, vergeleken met 2.500 euro per maand voor cloud-GPU's. De hardware verdient zichzelf binnen enkele weken terug voor teams met een constante werkbelasting.
Maar de cloud is wel zinvol voor experimenten en variabele werkbelastingen. Het opstarten van een fijnafstellingsproces wanneer nodig is, is beter dan het inactief houden van hardware.
Kostenbesparende strategieën die daadwerkelijk werken
Het verlagen van de kosten voor fijnafstelling hoeft niet ten koste te gaan van de resultaten. Verschillende beproefde technieken verlagen de kosten aanzienlijk.
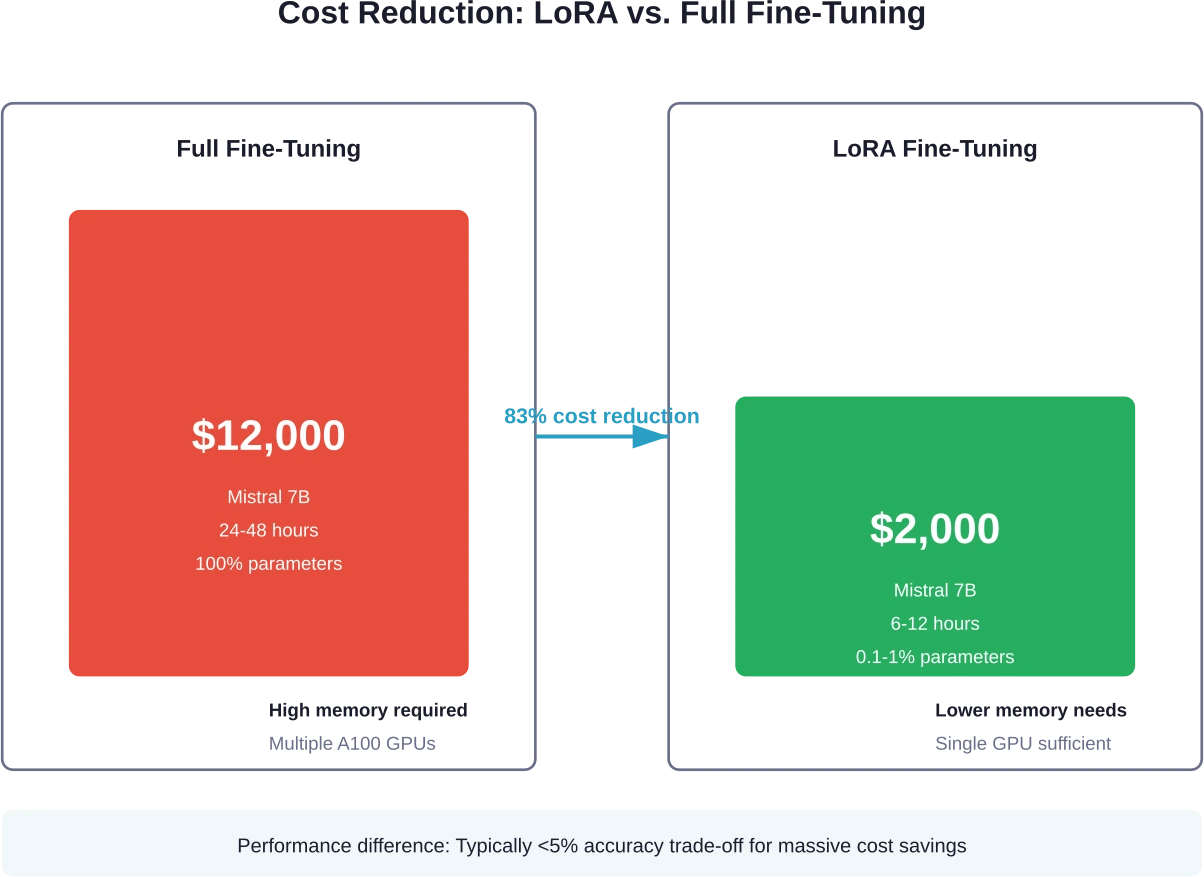
Gebruik LoRA in plaats van volledige fijnafstelling.
LoRA behaalt vergelijkbare resultaten met slechts 0,1-1% aan modelparameters. De vermindering van het aantal trainbare parameters vertaalt zich direct in lagere rekenkracht en snellere trainingstijden.
LoRA-methoden kosten ongeveer 4 tot 10 keer minder dan volledige fine-tuning voor hetzelfde model. Mistral 7B draait met LoRA $1.000-$3.000, vergeleken met $12.000 voor volledige fine-tuning – hetzelfde model, dramatisch verschillende kosten.
Maak gebruik van rekenkracht buiten de piekuren
Sommige aanbieders bieden incidentele tarieven of dalurenprijzen aan. Discussies binnen de community wijzen op interesse in goedkopere opties voor fijnafstelling, waarbij sommigen potentiële kostenbesparingen voor de 70% noemen via verschillende optimalisatiemethoden.
Optimaliseer de kwaliteit van de gegevens boven de kwantiteit.
Meer trainingsdata betekent niet altijd betere resultaten. Onderzoek naar complexiteitsbewuste finetuning toont aan dat gerichte dataselectie dezelfde nauwkeurigheid oplevert met 11% aan originele data.
Het selecteren van hoogwaardige voorbeelden vermindert het aantal tokens en de trainingstijd. In plaats van 1 miljoen tokens op het model af te vuren, presteren 100.000 zorgvuldig geselecteerde tokens vaak net zo goed – tegen 10% van de kosten.
Slimme keuzes voor hyperparameters
Agressieve leersnelheden en minder trainingsrondes verkorten de trainingstijd zonder dat dit ten koste gaat van de prestaties. Het vinden van de optimale balans vereist wat experimenteren, maar de besparingen lopen snel op.
Ook de validatiefrequentie is belangrijk. Het verlagen van de validatiefrequentie (bijvoorbeeld elke 100 stappen in plaats van elke 10 stappen) verlaagt de rekenkosten voor validatie evenredig. Voor het finetunen van versterkingsoefeningen geldt dat het kiezen van efficiënte beoordelingsmodellen en het vermijden van overmatige validatieruns de kosten direct verlaagt.
Wanneer fijnafstelling financieel zinvol is
Niet elk gebruiksscenario rechtvaardigt kosten voor fijnafstelling. Het moet economisch haalbaar zijn.
Fijn afstellen is zinvol wanneer:
- Domeinspecifieke nauwkeurigheid is belangrijker dan kosten. Medische, juridische of financiële toepassingen waarbij fouten daadwerkelijke gevolgen hebben, rechtvaardigen de investering.
- Het grote volume aan API-aanroepen maakt ze kostbaar. Bij applicaties met een hoge doorvoer die maandelijks miljoenen tokens verwerken, is het vaak goedkoper om de prestaties te verfijnen dan om herhaaldelijk API-aanroepen te doen.
- Gegevensbescherming vereist lokale controle. Gevoelige gegevens die de infrastructuur niet mogen verlaten, vereisen zelfgehoste, nauwkeurig afgestelde modellen.
- Er zijn specifieke formaten of uitvoerformaten vereist. Wanneer het geven van aanwijzingen alleen niet volstaat om de gewenste uitvoerstructuur of gedragsconsistentie te bereiken.
Fijn afstellen heeft geen zin wanneer:
- Snelle engineering levert vergelijkbare resultaten op. Contextvensters ondersteunen nu 200.000 tot 1 miljoen tokens. Veel taken werken prima met uitgebreide systeemprompts.
- Modellen veranderen sneller dan implementatiecycli. Elke 4-6 maanden komen er betere modellen uit. Het verfijnen van de Mistral 4B wordt overbodig wanneer de Qwen of Llama 3 enkele weken later verschijnt.
- Het volume rechtvaardigt de initiële kosten niet. Applicaties met weinig verkeer die $100 per maand aan API-kosten betalen, kunnen de kosten van $5.000 aan fine-tuning niet rechtvaardigen.
De berekening komt neer op een break-evenanalyse. Als finetuning $8.000 kost en $500 per maand aan API-kosten bespaart, is de terugverdientijd 16 maanden. Dat is redelijk voor stabiele, langetermijnapplicaties. Het is echter rampzalig voor experimentele projecten of snel veranderende gebruiksscenario's.
De economie van het fijn afstellen van versterking
Het finetunen van reinforcement learning brengt andere kostendynamieken met zich mee. In tegenstelling tot supervised finetuning, waarbij tokens worden gebruikt, brengt RFT kosten in rekening voor de rekentijd die wordt besteed aan de kerntaken van de training.
De RFT API van OpenAI factureert op basis van de trainingsduur, niet op basis van de grootte van de dataset. De kosten worden onder andere veroorzaakt door:
- Bereken vermenigvuldigingsfactoren die de trainingssnelheid bepalen.
- Validatiefrequentie en selectie van beoordelingsmodellen
- Lengte van de aflevering en complexiteit van de taak
Het optimaliseren van de RFT-kosten betekent het kiezen van het kleinste sorteermodel dat aan de kwaliteitseisen voldoet, het vermijden van overbodige validatieruns en het efficiënt houden van de aangepaste evaluatiecode.
Onderzoek naar het optimaliseren van de data-efficiëntie van reinforcement learning (RL) toont aan dat gerichte online dataselectie en rollout replay de trainingstijd verkorten met 231 TP3T tot 621 TP3T, terwijl de prestaties behouden blijven. Dit vertaalt zich direct in kostenbesparingen die evenredig zijn aan de tijdsbesparing.
Het monitoren en beheren van lopende kosten
Fijn afstellen is geen eenmalige uitgave. Modellen verschuiven, data verandert en hertraining wordt noodzakelijk.
Het bijhouden van kosten per klant of project maakt een transparante kostenverdeling mogelijk. Voor teams die meerdere klanten via één account bedienen, biedt het ophalen van projectdetails via een API en het berekenen van kosten op basis van getrainde tokens en modeltype een benaderende manier om de kosten bij benadering bij te houden.
Het instellen van strikte limieten voorkomt ongebreidelde uitgaven. OpenAI en cloudproviders ondersteunen bestedingslimieten die trainingstaken stoppen wanneer drempelwaarden worden bereikt. Dit beschermt tegen verkeerd geconfigureerde taken die duizenden GPU-uren verbruiken.
Monitoring via een dashboard is belangrijk. Door de voortgang van trainingen te volgen, kunnen slecht presterende taken worden gepauzeerd of geannuleerd voordat er nog meer middelen worden verspild. De meeste platforms tonen realtime statistieken en de opgebouwde kosten.
Veelgestelde vragen
Wat zijn de kosten voor het finetunen van een model met 7 miljard parameters?
Het finetunen van een 7B-model zoals Mistral of Llama kost doorgaans tussen de 1.000 en 3.000 TP4T met behulp van LoRA-technieken, of tot 12.000 TP4T voor volledige finetuning. De exacte kosten zijn afhankelijk van de grootte van de dataset, de trainingsduur en de gekozen infrastructuur (cloud versus zelfhosting).
Is LoRA net zo effectief als volledige fine-tuning?
LoRA behaalt voor de meeste toepassingen vergelijkbare prestaties als volledige fine-tuning, met een nauwkeurigheidsverschil van doorgaans minder dan 5%. LoRA werkt slechts 0,1-1% aan parameters bij en levert vergelijkbare resultaten tegen 4-10 keer lagere kosten en met snellere trainingstijden.
Wat zijn de verborgen kosten van het finetunen van LLM?
Verborgen kosten omvatten datavoorbereiding en -conversie (10-151 TP3T van het budget), mislukte experimenten en iteratie (20-251 TP3T), opslag van datasets en checkpoints (5-101 TP3T), infrastructuurkosten voor zelfgehoste setups (10-151 TP3T) en doorlopend onderhoud en hertraining (5-101 TP3T). Deze kosten kunnen de initiële GPU-kostenraming verdubbelen.
Wanneer moet ik API-finetuning gebruiken in plaats van zelf hosten?
API-finetuning is zinvol voor variabele workloads, experimenten en teams zonder ML-infrastructuur. Zelfhosting wordt kosteneffectief voor consistente workloads met een hoog volume, waarbij een eenmalige hardware-investering ($5.000-$15.000) zich binnen 3-6 maanden terugbetaalt, in tegenstelling tot de doorlopende cloudkosten.
Hoe kan ik de kosten voor het finetunen van de 70% verlagen?
Gebruik LoRA in plaats van volledige fine-tuning, maak gebruik van spot-instances of tarieven buiten de piekuren voor rekenkracht, optimaliseer de datakwaliteit om de datasetgrootte met 80-901 TP3T te verkleinen, verlaag de validatiefrequentie en kies efficiënte hyperparameters die de trainingstijd verkorten. Door deze strategieën te combineren kunnen de kosten met 701 TP3T of meer worden verlaagd.
Is fijnafstelling zinvol bij grote contextvensters?
Grote contextvensters (200.000 tot 1 miljoen tokens) verminderen in veel gevallen de noodzaak tot fijnafstelling. Als uitgebreide prompting acceptabele resultaten oplevert, is dit vaak goedkoper dan fijnafstelling. Fijnafstelling blijft zinvol voor consistent gedrag, specifieke uitvoerformaten of wanneer herhaalde API-aanroepen de kosten van fijnafstelling overschrijden.
Hoe vaak moeten verfijnde modellen opnieuw getraind worden?
De frequentie van het opnieuw trainen van modellen hangt af van data-drift en de levenscyclus van het model. Productiemodellen moeten doorgaans elke 3-6 maanden worden bijgewerkt, omdat de onderliggende data verandert of er betere basismodellen beschikbaar komen. Voor veeleisende applicaties kan maandelijks opnieuw trainen nodig zijn, terwijl in stabiele domeinen de frequentie kan oplopen tot jaarlijks.
Het nemen van de investeringsbeslissing
Fijn afstellen kost echt geld. De beslissing om door te gaan mag niet lichtzinnig genomen worden.
Begin met te controleren of fijnafstelling nodig is. Test eerst uitgebreide prompts met het basismodel. Veel teams ontdekken dat 90% voor hun specifieke gebruikssituatie werkt zonder fijnafstelling.
Bereken de totale eigendomskosten, niet alleen de GPU-uren. Neem datavoorbereiding, experimentbudget, opslag en onderhoud mee. Voeg 50-100% toe aan de initiële schattingen voor verborgen kosten.
Vergelijk dit met de API-kosten bij het verwachte volume. Als de huidige uitgaven $200 per maand zijn en de kosten voor finetuning $8.000, dan ligt het break-evenpunt op 40 maanden. Die berekening gaat voor de meeste projecten niet op.
Houd rekening met de levensduur van het model. Het verfijnen van een model dat over 4 maanden alweer verouderd is, is een verspilling van middelen. Door de snelle evolutie van modelfamilies is verfijnen minder aantrekkelijk dan het lijkt.
Maar wanneer domeinexpertise, gegevensbescherming of schaalvoordelen dit rechtvaardigen, levert fijnafstemming waarde op die generieke modellen niet kunnen evenaren. De sleutel is om de cijfers eerlijk te analyseren voordat er budget wordt vrijgemaakt.
De teams die succesvol zijn met LLM-finetuning beschouwen het als een investeringsbeslissing, niet als een technische keuze. Ze meten de kosten, stellen duidelijke prestatiedoelen vast en kennen hun break-evenpunt al voordat de eerste GPU in gebruik wordt genomen.
Bent u klaar om uw kosten voor AI-ontwikkeling te optimaliseren? Begin dan met het nauwkeurig meten van uw huidige API-uitgaven en het projecteren van de volumegroei. Deze basislijn bepaalt of fijnafstemming financieel zinvol is voor uw specifieke situatie.