Korte samenvatting: LLM-kostenbewaking helpt organisaties het tokengebruik te volgen, budgetoverschrijdingen te voorkomen en de uitgaven voor AI-workloads te optimaliseren. Door realtime inzicht te bieden in gebruikspatronen van modellen, kunnen teams kostbare inefficiënties identificeren voordat ze uit de hand lopen. De juiste monitoringoplossing biedt gedetailleerde kostenoverzichten, gebruiksanalyses en beheertools die essentieel zijn voor implementaties in productieomgevingen.
Grote taalmodellen zijn geëvolueerd van experimentele projecten naar productiesystemen die alles aandrijven, van klantenservice tot contentgeneratie. Maar er is een probleem: zonder goede monitoring kunnen de kosten van de ene op de andere dag enorm oplopen.
Een enkele, niet-geoptimaliseerde promptketen kan de kosten tot wel tien keer zo hoog maken. Teams ontdekken deze budgetoverschrijdingen vaak pas na afloop van de facturatiecyclus, wanneer de schade al is aangericht.
Het gaat hier niet alleen om geld besparen. Kostenbewaking biedt het inzicht dat nodig is om weloverwogen beslissingen te nemen over modelselectie, snelle ontwikkeling en infrastructuurkeuzes. Organisaties die AI-workloads op grote schaal implementeren, hebben uitgebreide tracking nodig als een ononderhandelbare operationele vereiste.
Waarom kostenbewaking belangrijk is bij LLM-implementaties
Bij prijsstelling op basis van tokens brengt elke API-aanroep kosten met zich mee. In tegenstelling tot traditionele software, waarbij de rekenkosten relatief voorspelbaar blijven, variëren de uitgaven voor LLM aanzienlijk, afhankelijk van gebruikspatronen, complexiteit van prompts en modelselectie.
De overgang van prototype naar productie vergroot deze uitdaging. Wat tijdens het testen met een handvol query's prima werkte, blijkt financieel onhoudbaar op grote schaal. Zonder continue zichtbaarheid wordt optimalisatie een kwestie van gissen.
Implementatiescenario's in de praktijk brengen extra complexiteit met zich mee. Verschillende teams kunnen bijvoorbeeld verschillende modellen gebruiken voor diverse applicaties. Sommige workflows omvatten gekoppelde aanroepen waarbij de output van het ene LLM-model de output van een ander model voedt. RAG-pipelines halen gegevens uit vectordatabases voordat ze responsen genereren, wat de rekenkosten verhoogt.
Kostenbewaking lost drie cruciale problemen op. Ten eerste voorkomt het onverwachte rekeningen door uitgaven in realtime te volgen in plaats van achteraf. Ten tweede identificeert het optimalisatiemogelijkheden door te onthullen welke prompts, modellen of gebruikers de meeste tokens verbruiken. Ten derde maakt het governance mogelijk door budgetten en waarschuwingen in te stellen op project-, team- of organisatieniveau.
Belangrijke meetgegevens voor het bijhouden van LLM-kosten
Effectieve monitoring vereist het bijhouden van de juiste statistieken. Tokenverbruik vormt de basis – zowel inputtokens (de prompt) als outputtokens (de gegenereerde respons). Verschillende modellen hanteren verschillende tarieven per token, dus het pure aantal tokens geeft geen volledig beeld.
De kosten per aanvraag bieden een genormaliseerd beeld. Deze maatstaf helpt bij het vergelijken van de financiële efficiëntie van verschillende benaderingen. Een aanvraag die gebruikmaakt van een duurder model maar minder tokens genereert, kan goedkoper zijn dan een goedkoper model met uitgebreidere uitvoer.
Gebruikspatronen onthullen belangrijke trends. Piektijden, het aantal aanvragen per applicatie en het tokenverbruik per gebruiker of team laten zien waar de uitgaven zich concentreren. Deze patronen brengen vaak onverwachte inefficiënties aan het licht.
Modelkeuze heeft directe invloed op de kosten. Nieuwere modellen zijn over het algemeen duurder dan oudere. Open-source modellen die lokaal worden geïmplementeerd, brengen infrastructuurkosten met zich mee in plaats van kosten per token. Door bij te houden welke modellen welke workloads verwerken, worden optimalisatiemogelijkheden zichtbaar.
Foutpercentages zijn belangrijker dan de meeste teams beseffen. Mislukte API-aanroepen verbruiken nog steeds tokens én budget. Hoge foutpercentages duiden op integratieproblemen, maar ze vertegenwoordigen ook verspilde uitgaven die voorkomen hadden kunnen worden door betere foutafhandeling.
LLM-diensten op locatie versus commerciële LLM-diensten
Organisaties staan voor een fundamentele keuze: zich abonneren op commerciële diensten of modellen implementeren op hun eigen infrastructuur. Volgens onderzoek naar deze afweging spelen er meerdere kostenfactoren een rol, die verder gaan dan alleen de prijs per token.
Commerciële diensten van aanbieders zoals OpenAI, Anthropic en Google bieden aantrekkelijke eenvoud. Teams betalen voor gebruikte tokens zonder zich zorgen te hoeven maken over infrastructuur, modelupdates of operationele overhead. Deze aanpak is gemakkelijk schaalbaar, maar de kosten lopen lineair op met het gebruik.
Een on-premise implementatie vereist een initiële investering in infrastructuur. Op basis van kosten-batenanalyses moeten organisaties rekening houden met de aanschaf van hardware, energieverbruik, koeling, onderhoud en personeel. Het break-evenpunt hangt af van het gebruiksvolume: bij grote volumes is een on-premise oplossing vaak voordeliger, terwijl bij kleinere volumes commerciële API's de voorkeur genieten.
Onderzoek naar kosten-batenanalyses van on-premise LLM-implementaties stelt criteria vast voor modelselectie, waaronder prestatiegelijkheid binnen 20% van de beste commerciële modellen. Deze drempel weerspiegelt de normen binnen bedrijven, waar kleine nauwkeurigheidsverschillen worden gecompenseerd door kostenbesparingen, beveiligingsvoordelen en flexibiliteit bij integratie.
Verborgen kosten bij beide benaderingen
Commerciële diensten brengen verborgen kosten met zich mee die verder gaan dan de tokenprijs. Limieten voor het aantal dataverbruik kunnen upgrades naar premium-abonnementen afdwingen. Kosten voor data-uitvoer zijn van toepassing bij het verwerken van grote hoeveelheden data. Meerdere teamleden die toegang nodig hebben, verhogen de abonnementskosten.
Implementaties op locatie brengen hun eigen verborgen kosten met zich mee. Het finetunen van modellen vereist datawetenschappers. De infrastructuur moet redundant zijn voor betrouwbaarheid. Updates en patches vergen voortdurende aandacht. De overhead voor beveiliging en compliance neemt toe bij zelfgehoste oplossingen.
Monitoring is essentieel, ongeacht de gekozen implementatiemethode. Commerciële API's moeten worden bijgehouden om uit de hand gelopen kosten te voorkomen. On-premise systemen vereisen monitoring om het gebruik van resources te optimaliseren en investeringen in infrastructuur te rechtvaardigen.
Essentiële hulpmiddelen en technologieën
Er zijn diverse monitoringoplossingen ontwikkeld om de kosten van LLM (Low-Level Management) te volgen. Deze tools verschillen in functionaliteit, complexiteit en ideale toepassingsmogelijkheden.
LiteLLM biedt een uniforme interface voor meerdere LLM-aanbieders. Het standaardiseert API-aanroepen en houdt tokens en kosten centraal bij. Teams die met verschillende aanbieders werken, profiteren van geconsolideerde monitoring in plaats van meerdere dashboards te moeten raadplegen.
Langfuse biedt open-source observability, specifiek ontworpen voor LLM-toepassingen. Het platform volgt kosten en kwaliteitsmetrieken en biedt inzicht in de relatie tussen uitgaven en outputkwaliteit. Het platform ondersteunt complexe workflows, waaronder RAG-pipelines en agentketens met meerdere stappen.
Datadog LLM Observability breidt bestaande infrastructuurmonitoring uit naar AI-workloads. Organisaties die Datadog al gebruiken, kunnen LLM-tracking toevoegen zonder nieuwe tools te hoeven introduceren. De integratie koppelt kostengegevens aan bredere systeemprestatiegegevens.
| Oplossingstype | Het beste voor | Belangrijkste sterkte | Overweging |
|---|---|---|---|
| Geünificeerde proxy | Configuraties met meerdere providers | Eén interface voor alle LLM's | Voegt een latentielaag toe |
| Open-source platform | Aanpassingsbehoeften | Volledige controle en transparantie | Vereist zelfhosting. |
| Observeerbaarheid van de onderneming | Grote organisaties | Integreert met bestaande tools | Hogere kostenstructuur |
| Provider Native API | Gebruik door één enkele leverancier | Meest nauwkeurige gegevens | Beperkt overzicht van alle aanbieders |
Providerspecifieke oplossingen bieden programmatische toegang tot API-gebruiks- en kostengegevens van een organisatie. Deze aanpak werkt goed bij standaardisatie op één provider, maar creëert blinde vlekken in omgevingen met meerdere leveranciers.

Bouw LLM-systemen met duidelijke gebruiksmonitoring.
Applicaties die gebruikmaken van LLM vereisen adequate monitoring en infrastructuur om aanvragen, gebruik en systeemprestaties te beheren. AI Superieur Ze ontwikkelen AI-platformen waarin grote taalmodellen worden geïntegreerd met backend-services, datapijplijnen en analysetools. Hun engineers bouwen systemen die betrouwbare modelimplementatie, logging en prestatiebewaking in productieomgevingen ondersteunen.
Een LLM-systeem in productie nemen?
Praat met AI die superieur is aan:
- Ontwerp de LLM-infrastructuur en de bijbehorende backendservices.
- Ontwikkel NLP-applicaties op basis van taalmodellen.
- Integreer monitoring en analyses in AI-systemen.
👉 Contact AI Superieur om uw AI-ontwikkelingsproject te bespreken.
Realtime kostenbewaking implementeren
Realtime monitoring biedt direct inzicht in plaats van analyse achteraf. Deze mogelijkheid maakt proactief kostenbeheer mogelijk in plaats van reactieve schadebeperking.
De implementatie bestaat doorgaans uit drie componenten. Ten eerste registreert de instrumentatie het aantal tokens van elke LLM-aanroep. Ten tweede aggregeert een centrale database deze gegevens met bijbehorende metadata zoals gebruiker, applicatie en tijdstempel. Ten derde visualiseren dashboards de bestedingspatronen en activeren ze waarschuwingen wanneer drempelwaarden worden overschreden.
PostgreSQL-databases worden vaak gebruikt als opslaglaag voor kostenbewakingssystemen. De database bevat tokenaantallen, kostenberekeningen en gebruiksgegevens. Deze aanpak biedt flexibiliteit voor aangepaste query's en kan tegelijkertijd de schrijfbelasting van productieapplicaties aan.
Ingebouwde dashboards zetten ruwe data om in bruikbare inzichten. Effectieve dashboards tonen de huidige uitgaven, vergelijken deze met budgetten, zetten de belangrijkste afnemers in kaart en onthullen trends in de loop van de tijd. De beste implementaties maken het mogelijk om in te zoomen van een overzicht op organisatieniveau tot details van individuele aanvragen.
Waarschuwingen en budgetten instellen
Een goede waarschuwingsconfiguratie voorkomt budgetverrassingen. Teams moeten meerdere waarschuwingsniveaus instellen: drempelwaarden die wijzen op verhoogde uitgaven en kritieke limieten die ingrijpen noodzakelijk maken.
Budgettoewijzing werkt het beste hiërarchisch. Organisatiebrede budgetten stellen algemene limieten vast. Afdelings- of projectbudgetten bieden gedetailleerdere controle. Limieten per gebruiker of per applicatie voorkomen dat de kosten door geïsoleerde problemen de pan uit rijzen.
Waarschuwingskanalen zijn belangrijk. E-mailnotificaties werken voor niet-urgente waarschuwingen. Integraties met Slack of Teams zorgen voor teambewustzijn. PagerDuty of vergelijkbare systemen behandelen kritieke budgetoverschrijdingen die onmiddellijke actie vereisen.
Kosten optimaliseren door middel van monitoringinzichten
Kostenbewaking genereert data. Optimalisatie zet die data om in besparingen.
Prompt engineering blijkt een belangrijk optimalisatiemiddel te zijn. Monitoring onthult welke prompts buitensporig veel tokens verbruiken. Kortere, meer gerichte prompts verlagen de inputkosten. Het beperken van de lengte van de output voorkomt langdradige antwoorden die budget verspillen.
Modelselectieoptimalisatie maakt gebruik van kostengegevens om workloads te koppelen aan geschikte modellen. Voor eenvoudige taken zijn niet de krachtigste (en duurste) modellen nodig. Monitoring identificeert mogelijkheden om verzoeken door te sturen naar goedkopere alternatieven zonder kwaliteitsverlies.
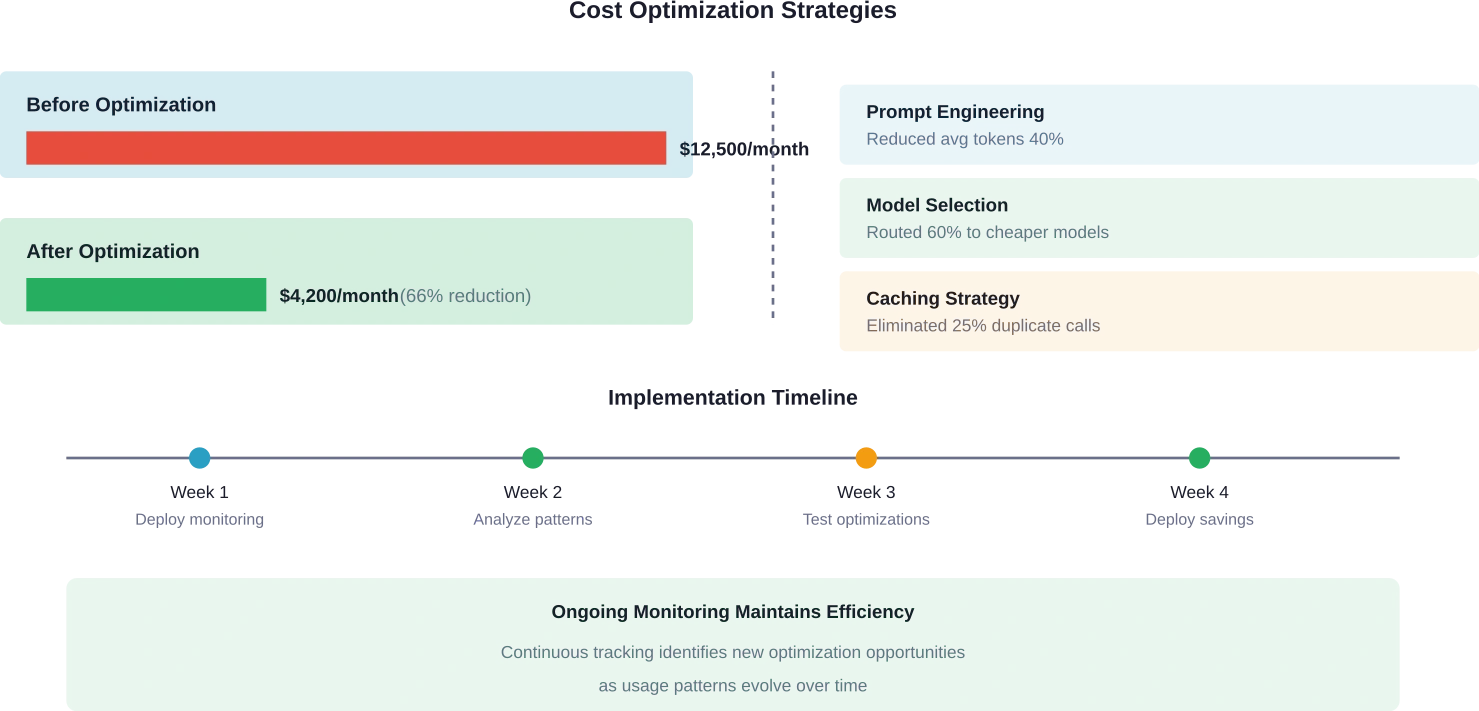
Cachestrategieën voorkomen dubbele verwerking. Als meerdere gebruikers vergelijkbare vragen stellen, voorkomt het cachen van het eerste antwoord dat identieke inhoud opnieuw wordt gegenereerd. Monitoring identificeert veelgebruikte vragen die het meest baat hebben bij caching.
Door verzoeken te bundelen, kunnen meerdere bewerkingen waar mogelijk worden gecombineerd. Sommige workflows maken veel kleine API-aanroepen die kunnen worden samengevoegd. Het monitoren van gebruikspatronen onthult mogelijkheden voor bundeling die zowel de kosten als de latentie verlagen.
Beheer- en gebruiksbeperkingen
Kostenbewaking maakt bestuur mogelijk dat verder gaat dan eenvoudige registratie. Organisaties hebben controlemechanismen nodig om beleid af te dwingen en ongeoorloofde uitgaven te voorkomen.
Op rollen gebaseerd toegangsbeheer bepaalt wie welke modellen mag gebruiken. Ontwikkelteams hebben mogelijk toegang tot dure modellen voor testdoeleinden, terwijl productieapplicaties gebruikmaken van kostengeoptimaliseerde alternatieven. Monitoring controleert of aan dit beleid wordt voldaan.
Snelheidsbeperking voorkomt dat misbruik of verkeerde configuratie tot budgetproblemen leidt. Snelheidslimieten per gebruiker of per applicatie beperken het maximale tokenverbruik binnen specifieke tijdsvensters. Deze controles beschermen tegen oneindige lussen of onverwachte pieken in het gebruik.
Goedkeuringsworkflows zorgen voor extra complexiteit bij kostbare processen. Onderzoekstoepassingen die nieuwe gebruiksscenario's verkennen, vereisen mogelijk expliciete goedkeuring voordat toegang tot premiummodellen mogelijk is. Monitoring levert de gebruiksgegevens die nodig zijn om deze verzoeken te beoordelen.
Nalevings- en auditvereisten
Veel sectoren worden geconfronteerd met wettelijke eisen rondom het gebruik van AI. Financiële instellingen moeten aantonen dat ze AI op een verantwoorde manier inzetten. Zorginstellingen moeten voldoen aan de regelgeving inzake gegevensbescherming.
Kostenbewaking genereert auditsporen die laten zien welke gebruikers welke modellen met welke gegevens hebben geraadpleegd. Deze documentatie ondersteunt nalevingsinspanningen en maakt tevens forensische analyses mogelijk wanneer er problemen optreden.
Beleid voor gegevensbewaring bepaalt hoe lang gebruiksgegevens worden bewaard. Langere bewaartermijnen ondersteunen trendanalyses, maar verhogen de opslagkosten. Organisaties wegen deze overwegingen tegen elkaar af op basis van hun specifieke compliance-vereisten.
Integratie met contactcenteranalyse
Contactcenters zijn voorbeelden van grootschalige implementatiescenario's voor taalmodellen. Volgens onderzoek naar het extraheren van inzichten uit taalmodellen voor contactcenteranalyses, zetten organisaties taalmodellen in voor zelfservicetools, administratieve automatisering en het verbeteren van de productiviteit van medewerkers.
Deze implementaties genereren een enorm tokenverbruik. Monitoring is daarom cruciaal voor een kosteneffectieve bedrijfsvoering. Het onderzoek beschrijft systemen die automatisch inzichten uit klantinteracties halen en tegelijkertijd de implementatiekosten beheersen.
Nulpuntberekeningen met modellen zoals GPT-3.5-turbo bieden een goed uitgangspunt voor contactcenterapplicaties. Nauwkeuriger afgestelde modellen bieden een hogere nauwkeurigheid, maar vereisen extra infrastructuur en onderhoud. Kostenbewaking helpt bij het evalueren van deze afwegingen door de financiële impact van elke aanpak te volgen.
Het onderzoek legt de nadruk op end-to-end topicmodelleringsexperimenten die optimale schaalfactoren bepalen. Deze experimenten zijn gebaseerd op uitgebreide kostenregistratie om de verbetering van de nauwkeurigheid af te wegen tegen de toegenomen uitgaven.
Overwegingen met betrekking tot de integratie van de financiële sector
Financiële instellingen staan voor unieke uitdagingen bij de integratie van taalmodellen. Onderzoek naar strategische kaders voor de integratie van taalmodellen in de financiële sector laat zien hoe organisaties taalmodellen gebruiken voor kredietbeoordelingen, adviesdiensten aan klanten en de automatisering van taalintensieve processen.
Effectieve implementatie vereist verantwoorde innovatie die een evenwicht vindt tussen capaciteit en risicobeheer. Kostenbewaking ondersteunt dit evenwicht door inzicht te geven in gebruikspatronen en uitgavenpatronen.
Financiële organisaties hanteren doorgaans strengere governance-regels dan andere sectoren. Monitoringtools moeten gedetailleerde auditsporen, op rollen gebaseerde toegangscontroles en compliance-rapportage ondersteunen. Integratie met bestaande risicomanagementsystemen is daarbij essentieel.
Het onderzoek wijst uit dat financiële instellingen van alle groottes steeds vaker LLM's (Large-Led Monitoring Systems) inzetten. Kleinere organisaties hebben behoefte aan kosteneffectieve monitoringoplossingen. Grotere instellingen vereisen governance en schaalbaarheid op bedrijfsniveau.
De juiste monitoringoplossing kiezen
De keuze voor een monitoringtool hangt af van de specifieke behoeften van een organisatie. Verschillende factoren spelen een rol bij deze beslissing.
Ondersteuning door meerdere aanbieders is belangrijk bij het gebruik van meerdere LLM-leveranciers. Organisaties die standaardiseren op één enkele aanbieder geven mogelijk de voorkeur aan een diepere integratie boven brede compatibiliteit.
Flexibiliteit in de implementatie heeft invloed op zowel de kosten als de controle. Cloudgebaseerde oplossingen minimaliseren de operationele overhead. Zelfgehoste opties bieden meer aanpassingsmogelijkheden en datasoevereiniteit.
Integratiemogelijkheden bepalen hoe monitoringgegevens in bestaande systemen worden geïntegreerd. API-toegang maakt aangepaste dashboards mogelijk. Webhooks ondersteunen gebeurtenisgestuurde automatisering. Voorgebouwde connectoren vereenvoudigen de integratie met populaire tools.
| Functie | Start-up behoefte | Bedrijfsbehoeften |
|---|---|---|
| Kostenregistratie | Basis token telling | Multidimensionale analyse |
| Bestuur | Eenvoudige budgetten | Complexe goedkeuringsworkflows |
| Integratie | Zelfstandig dashboard | Connectiviteit van bedrijfstools |
| Steun | Gemeenschapsforums | Toegewijde assistentie |
| Inzet | Voorkeur voor cloudhosting | On-premise optie vereist |
Schaalbaarheidseisen variëren afhankelijk van de omvang en groeiprognose van de organisatie. Tools die prima werken voor tientallen verzoeken per dag, kunnen problemen ondervinden bij duizenden verzoeken per minuut. Inzicht in het verwachte volume voorkomt dat de monitoringinfrastructuur ontoereikend wordt.
Het budget voor de monitoringoplossing zelf vormt een overkoepelende uitdaging. Buitensporig veel geld uitgeven aan monitoring ondermijnt het doel. Kosteneffectieve oplossingen zouden slechts een minimaal deel van de totale AI-uitgaven moeten uitmaken.
Toekomstige trends in kostenbeheer voor LLM-opleidingen
Kostenbewaking blijft zich ontwikkelen, parallel aan het bredere ecosysteem van levensonderhoudsmanagement (LLM). Verschillende trends veranderen de manier waarop organisaties hun uitgaven beheren.
- Voorspellende kostenmodellen gebruiken historische gegevens om toekomstige uitgaven te voorspellen. Machine learning-algoritmen identificeren patronen en projecteren kosten onder verschillende scenario's. Deze mogelijkheid maakt proactief budgetteren mogelijk in plaats van reactief bijsturen.
- Geautomatiseerde optimalisatie gebruikt inzichten uit monitoring om verbeteringen door te voeren zonder handmatige tussenkomst. Systemen routeren verzoeken automatisch naar kostenefficiënte modellen, passen cacheparameters aan en comprimeren prompts met behoud van kwaliteit.
- Kostenarbitrage tussen verschillende aanbieders houdt de prijzen van meerdere leveranciers in de gaten en stuurt aanvragen door naar de meest kosteneffectieve optie voor elke workload. Deze aanpak vereist realtime kostengegevens en geavanceerde routeringslogica.
- Het bijhouden van de CO2-voetafdruk gaat verder dan alleen financiële kosten en richt zich ook op de impact op het milieu. Nu organisaties steeds meer onder druk staan op het gebied van duurzaamheid, wordt inzicht in het energieverbruik van AI-workloads steeds belangrijker.
Veelgestelde vragen
Hoeveel bespaart LLM-kostenmonitoring doorgaans op de uitgaven?
Organisaties die uitgebreide monitoring en optimalisatie implementeren, kunnen de kosten van LLM aanzienlijk verlagen. De exacte besparing hangt af van hoe geoptimaliseerd de initiële implementatie was. Teams zonder voorafgaande monitoring zien vaak de grootste besparing. De winst komt voornamelijk voort uit snelle engineering, optimalisatie van de modelselectie en het elimineren van onnodige dubbele aanroepen.
Kunnen monitoringtools gebruikt worden bij verschillende aanbieders van LLM-programma's?
Ja, diverse monitoringoplossingen ondersteunen omgevingen met meerdere leveranciers. Tools zoals LiteLLM creëren een uniforme interface voor OpenAI, Anthropic, Google en andere leveranciers. Deze oplossingen standaardiseren API-aanroepen en houden de kosten centraal bij. Monitoring met één leverancier biedt doorgaans gedetailleerdere statistieken, maar creëert blinde vlekken bij gebruik van meerdere leveranciers.
Wat is het verschil tussen kostenbewaking en LLM-observabiliteit?
Kostenbewaking richt zich specifiek op het bijhouden van tokengebruik en -uitgaven. LLM-observability omvat een bredere reeks meetwaarden, waaronder kwaliteit, latentie, foutpercentages en gebruikerstevredenheid, naast de kosten. Observability-platformen bieden een holistisch inzicht in de gezondheid van LLM-applicaties. Kostenbewaking is een cruciaal onderdeel van observability, maar geeft niet het volledige beeld.
Hoe wordt kostenbewaking bij on-premise implementaties anders aangepakt?
Bij on-premise implementaties worden de infrastructuurkosten bijgehouden in plaats van de kosten per token. De monitoring richt zich op GPU-gebruik, stroomverbruik en doorvoer. Het doel verschuift van het minimaliseren van tokengebruik naar het maximaliseren van de hardware-efficiëntie. Teams moeten de interne kosten per token berekenen op basis van de infrastructuurkosten om deze te kunnen vergelijken met commerciële alternatieven.
Moet elke organisatie realtime monitoring implementeren of is batchanalyse voldoende?
Realtime monitoring wordt essentieel bij grote schaal of wanneer budgetten beperkt zijn. Organisaties die dagelijks duizenden aanvragen verwerken, hebben direct inzicht nodig om uit de hand gelopen kosten te voorkomen. Kleinere implementaties met voorspelbaar gebruik kunnen volstaan met batchanalyses van dagelijkse of wekelijkse uitgaven. De complexiteit en overhead van realtime systemen zijn alleen zinvol wanneer het risico op budgetoverschrijdingen de investering rechtvaardigt.
Welke invloed heeft caching op de nauwkeurigheid van kostenbewaking?
Caching vermindert het aantal daadwerkelijke LLM API-aanroepen, maar monitoring moet zowel gecachede als niet-gecachede verzoeken bijhouden. Effectieve monitoring maakt onderscheid tussen cachehits en cachemissers om de werkelijke kostenbesparingen te berekenen. Zonder dit onderscheid zouden teams de werkelijke uitgaven kunnen overschatten. Cachehitpercentages worden, naast tokenverbruik, een belangrijke optimalisatiemaatstaf.
Welke rol speelt monitoring in het bestuur van LLM-programma's?
Monitoring vormt de databasis voor governancebeleid. Gebruiksregistratie maakt budgethandhaving, snelheidsbeperking en toegangscontrole mogelijk. Auditsporen van monitoringsystemen tonen aan dat intern beleid en externe regelgeving worden nageleefd. Governancebeleid zonder monitoringgegevens wordt slechts een richtlijn in plaats van een daadwerkelijke controle.
De controle over de uitgaven voor LLM-opleidingen overnemen
Kostenbewaking transformeert LLM-implementaties van onvoorspelbare kostenposten in beheersbare, geoptimaliseerde systemen. De inzichten die het biedt, maken weloverwogen beslissingen mogelijk over modelselectie, snelle engineering en infrastructuurkeuzes.
Organisaties die AI-workloads in productie nemen, kunnen deze stap niet overslaan. Er bestaan tegenwoordig tools en technieken om uitgaven te volgen, overschrijdingen te voorkomen en de kosten continu te optimaliseren. De implementatie-inspanning betaalt zich binnen enkele weken terug door lagere kosten.
Begin met eenvoudige tokenregistratie als uitgebreide monitoring overweldigend lijkt. Zelfs een simpel inzicht in welke applicaties en gebruikers de meeste tokens verbruiken, biedt mogelijkheden voor optimalisatie. Bouw geleidelijk uit naar realtime monitoring, geautomatiseerde waarschuwingen en beheermogelijkheden naarmate de implementaties opschalen.
Het concurrentievoordeel ligt bij teams die AI effectief inzetten en tegelijkertijd de kosten verantwoord beheren. Monitoring biedt beide mogelijkheden: het maakt een snelle implementatie mogelijk zonder roekeloze uitgaven. Organisaties die kostenbewaking beheersen, kunnen vol vertrouwen nieuwe LLM-toepassingen onderzoeken, wetende dat ze de financiële controle behouden.