Korte samenvatting: LLM-benchmarks meten de inferentieprestaties aan de hand van doorvoer, latentie en kostenefficiëntie. Benchmarkingtools zoals MLPerf, vLLM en GuideLLM helpen organisaties bij het evalueren van implementatieopties. Zelfgehoste kleine modellen (7-14 miljard parameters) kosten 95-991 TP3T minder dan commerciële API's, terwijl ze voor veel toepassingen vergelijkbare prestaties leveren.
De hoge kosten van de implementatie van taalmodellen kunnen een AI-project maken of breken. Volgens AWS en andere brancherapporten verbruikt inferentie in productieomgevingen meer dan 901 TP3T aan totale energie voor taalmodellen. Dat is een enorme operationele kostenpost die zorgvuldige meting vereist.
Bij het benchmarken van de prestaties van LLM-servers draait het niet langer alleen om snelheid. Kostenefficiëntie is de belangrijkste overweging geworden voor organisaties die AI-toepassingen opschalen. De vraag is niet of een model verzoeken kan verwerken, maar of het dat winstgevend kan doen.
Het probleem is echter dat de meeste teams geen systematische aanpak hebben om zowel prestaties als kosten tegelijkertijd te meten. Ze optimaliseren voor één meetwaarde en zien de uitgaven vervolgens uit de hand lopen.
Inzicht in de prestatienormen van LLM
Prestatiebenchmarks meten hoe LLM's zich gedragen onder specifieke omstandigheden. In tegenstelling tot ranglijsten voor modelkwaliteit, die het redeneervermogen rangschikken, richten servicebenchmarks zich op operationele statistieken: doorvoer, latentie, resourcegebruik en uiteindelijk de kosten per inferentie.
De MLCommons MLPerf Inference benchmarksuite is de industriestandaard voor het meten van de prestaties van ML- en AI-workloads. Met de release van MLPerf Inference 5.1 werd Llama3.1-8B geïntroduceerd als benchmarkmodel, met een contextlengte van 128.000 tokens die aansluit bij de praktijkvereisten van bedrijven.
Maar wacht eens even – wat is nu eigenlijk belangrijk bij een benchmark?
Belangrijkste prestatie-indicatoren
Doorvoer meet het aantal verwerkte verzoeken per seconde. Een hogere doorvoer betekent dat er meer gebruikers met dezelfde hardware bediend kunnen worden. GuideLLM berekent uitgebreide percentielen, waaronder het 0,1e, 1e, 5e, 10e, 25e, 75e, 90e, 95e en 99e percentiel voor doorvoer en andere statistieken.
Latentie meet de reactietijd. MLPerf definieert specifieke latentiebeperkingen voor verschillende scenario's. Scenario's met één datastroom meten de latentie op het 90e percentiel, terwijl serverscenario's gericht zijn op reactietijden van minder dan een seconde voor interactieve applicaties.
De tijd tot het eerste token (TTFT) is belangrijk voor de gebruikerservaring. Eerlijk gezegd: gebruikers merken het als het langer dan 200-300 ms duurt voordat een reactie verschijnt. Deze waarde heeft een directe invloed op de ervaren responsiviteit van de applicatie.
De doorvoer van tokengeneratie verschilt van de doorvoer van verzoeken. Het meet het aantal geproduceerde tokens per seconde, wat direct correleert met de voor de gebruiker zichtbare uitvoersnelheid. Recent onderzoek naar het gebruik van redeneertaalmodellen voor inferentie laat aanzienlijke geheugenfluctuaties zien tijdens de tokengeneratie, die deze metriek beïnvloeden.
Standaard benchmarkscenario's
MLPerf definieert vier primaire scenario's. Elk scenario simuleert verschillende toepassingspatronen met specifieke belastingseigenschappen.
| Scenario | Querygeneratie | Latentiebeperking | Prestatie-indicator |
|---|---|---|---|
| Enkele stroom | Sequentiële zoekopdrachten | 90e percentiel | 90%-ile latentie |
| Meerdere streams | Vaste intervalbatches | 99e percentiel | Maximale streams |
| Server | Poisson-verdeling | 99e percentiel | Query's per seconde |
| Offline | Alle zoekopdrachten tegelijk | Geen | Totale doorvoer |
Serverscenario's simuleren API-belastingen in een productieomgeving met Poisson-verdeelde verzoeken. Dit patroon weerspiegelt realistisch gebruikersgedrag, waarbij verzoeken willekeurig binnenkomen in plaats van met vaste tussenpozen.
Het meten van LLM-inferentiekosten
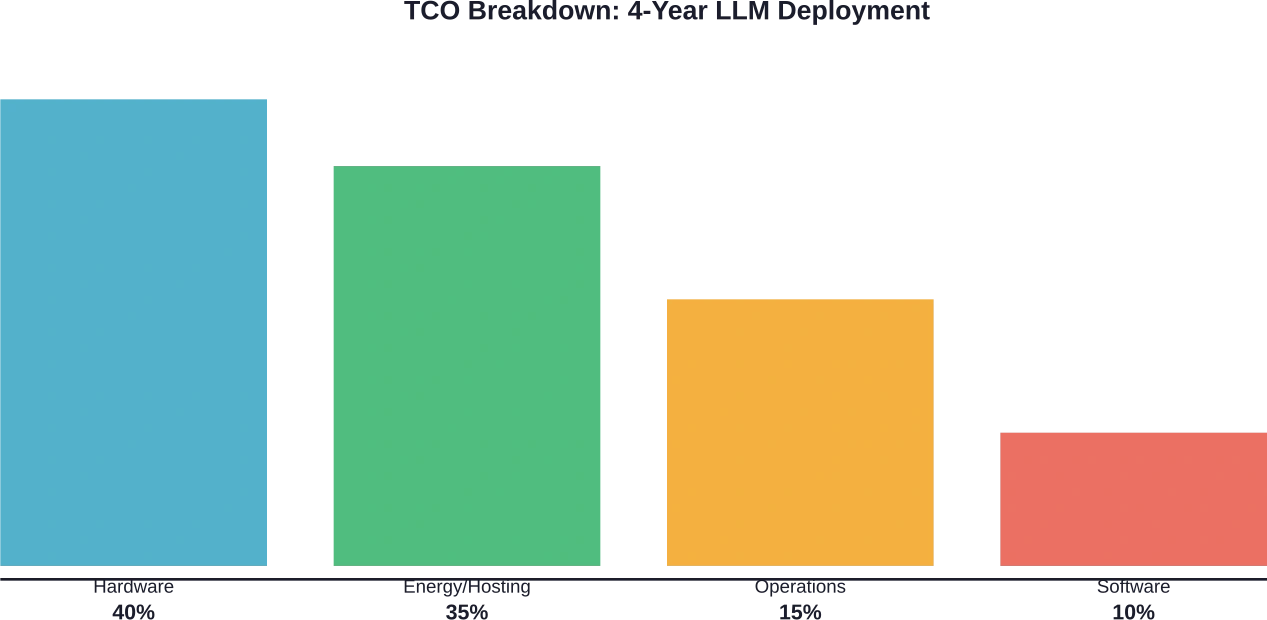
Kostenanalyse vereist inzicht in zowel directe als indirecte kosten. Afschrijving van hardware, energieverbruik, hostingkosten en operationele overhead dragen allemaal bij aan de totale eigendomskosten.
Volgens het economische inferentiekader van het WiNGPT-team moet LLM-inferentie worden beschouwd als computergestuurde intelligente productie. De A800 80G GPU heeft bijvoorbeeld een basiskostprijs van ongeveer $0,79 per uur, die onder gangbare operationele omstandigheden doorgaans tussen de $0,51 en $0,99 per uur ligt.
Totale kosten van de eigendomscomponenten
De hardwarekosten beginnen bij de aanschaf. Serverconfiguraties met 8 GPU's kunnen $320.000 of meer kosten, afhankelijk van het GPU-model. Afschrijvingen worden doorgaans over een periode van vier jaar berekend voor implementaties in bedrijfsomgevingen.
De kosten voor het inrichten van de infrastructuur omvatten hostingkosten, stroomverbruik, koeling en rackruimte. Deze operationele kosten lopen in de loop der tijd op. Bij cloudimplementaties variëren de instantieprijzen aanzienlijk, afhankelijk van het GPU-type en de regio.
Softwarelicenties en -onderhoud brengen terugkerende kosten met zich mee. Open-source serverframeworks zoals vLLM elimineren licentiekosten, maar commerciële oplossingen rekenen per implementatie of per verwerkt token.
Kostenvergelijking tussen zelfhosting en API
Kostenverhoudingen laten dramatische verschillen zien tussen implementatiemethoden. Onderzoek gepubliceerd door FinAI toont aan dat kleinere modellen aanzienlijke besparingen opleveren in vergelijking met commerciële API's.
| Model | Parameters | Kosten versus GPT-4.1 | Kosten versus GPT-4.1 Mini | Kosten versus Sonnet 3.7 |
|---|---|---|---|---|
| Gemma 3 4B | 4B | 0.04 | 0.20 | 0.01 |
| DeepSeek Lama 8B | 8B | 0.05 | 0.27 | 0.01 |
| Qwen 3 14B | 14B | 0.05 | 0.27 | 0.01 |
| Gemma 3 27B | 27B | 0.34 | 1.71 | 0.08 |
| DeepSeek Lama 70B | 70B | 1.70 | 8.49 | 1.10 |
| Qwen 3 235B | 235B | 2.17 | 10.83 | 1.40 |
Kleinere modellen met parameters onder de 14B-norm kosten aanzienlijk minder dan modellen van de GPT-4-klasse. Onderzoek toont aan dat de kosten 0,04 tot 0,05 keer lager liggen dan die van GPT-4.1. Dit is een revolutionaire ontwikkeling voor grootschalige toepassingen waar de kwaliteitseisen het gebruik van kleinere modellen toelaten.
Salesforce Engineering heeft gedocumenteerd dat ze jaarlijks meer dan 1.400.500.000 dollar besparen door live LLM-afhankelijkheden te vervangen door een mockservice voor ontwikkelings- en benchmarkworkflows. Hierdoor werd het tokenverbruik voor niet-productietests geëlimineerd, terwijl de validatiemogelijkheden behouden bleven met 16.000 aanvragen per minuut en een piekcapaciteit van meer dan 24.000 aanvragen per minuut.
Benchmarkingtools en -frameworks
Er bestaan meerdere raamwerken die systematische LLM-benchmarks ondersteunen. Elk raamwerk biedt verschillende mogelijkheden voor het meten van prestaties en kostenefficiëntie.
vLLM Benchmarking Suite
Het vLLM-project biedt ingebouwde benchmarktools voor het meten van doorvoer en latentie. Het framework ondersteunt diverse datasets, waaronder ShareGPT, BurstGPT en synthetische willekeurige data gegenereerd door modeltokenizers.
Belangrijke benchmarkparameters voor vLLM zijn onder andere de maximale gelijktijdigheidslimieten, de aanvraagsnelheid en de datasetselectie. Door de maximale gelijktijdigheid op 10 in te stellen, verwerkt de server maximaal 10 aanvragen tegelijk en worden extra aanvragen in de wachtrij geplaatst totdat er capaciteit beschikbaar komt.
De benchmarks van vLLM-ascend v0.7.3 lieten de prestaties zien met de modellen Qwen2.5-7B-Instruct en Qwen2.5-VL-7B-Instruct bij QPS-waarden van 1, 4, 16 en oneindig (onbeperkt). Voor de tests werden 200 willekeurig geselecteerde prompts uit de datasets ShareGPT en vision-arena gebruikt, met vaste willekeurige startwaarden voor reproduceerbaarheid.
GuideLLM voor productiebenchmarking
GuideLLM, onderdeel van het vLLM-project, is gespecialiseerd in het evalueren van inferentiepatronen in de praktijk. Het simuleert verschillende verkeerspatronen door middel van configureerbare belastingprofielen.
Belastingstesten op basis van aanvraagsnelheden ondersteunen constante aanvraagsnelheden. Door 20 seconden lang 10 aanvragen per seconde te verwerken met synthetische data van 128 prompt-tokens en 256 output-tokens, worden basismetingen van de doorvoer verkregen. De tool berekent uitgebreide percentielverdelingen, inclusief de 0,1e, 1e, 5e, 10e, 25e, 50e, 75e, 90e, 95e, 99e en 99,9e percentielen voor elke metriek.
Belastingspatronen zijn belangrijk omdat verschillende applicaties verschillende verkeerspatronen genereren. Bursttesten onthullen het systeemgedrag bij plotselinge piekbelastingen, terwijl continue testen de prestaties in een stabiele toestand meten.
MLPerf-inferentiebenchmarks
MLPerf Inference is de toonaangevende industriestandaard. De benchmarksuite omvat datacenter- en mobiele scenario's met gestandaardiseerde workloads op het gebied van beeld-, spraak- en taalverwerking.
Voor datacenterscenario's meet MLPerf het aantal query's per seconde onder specifieke latentiebeperkingen. Benchmarks voor serverscenario's gebruiken querypatronen met een Poisson-verdeling en latentiedoelen van het 99e percentiel. Offline scenario's maximaliseren de doorvoer zonder latentiebeperkingen.
De MLPerf Inference 5.1-release introduceerde Llama3.1-8B met ondersteuning voor 128.000 tokencontexten. Deze benchmark weerspiegelt de moderne bedrijfsvereisten voor taken met betrekking tot het begrijpen en genereren van lange contexten.
Afweging tussen kosten en prestaties van GPU's
De hardwarekeuze heeft een enorme impact op zowel de prestaties als de kostenefficiëntie. Onderzoek naar de kostenefficiëntie van LLM-servers die gebruikmaken van heterogene GPU's laat zien dat verschillende GPU-typen aansluiten bij verschillende workloadkenmerken.
| GPU-type | Piek FP16 FLOPS | Geheugenbandbreedte | Geheugenlimiet | Prijs per uur |
|---|---|---|---|---|
| A6000 | 91 TFLOPS | 768 GB/s | 48 GB | $0.83 |
| A40 | 150 TFLOPS | 696 GB/s | 48 GB | $0.55 |
| L40 | 181 TFLOPS | 864 GB/s | 48 GB | $1.15 |
De geheugenbandbreedte is vaak belangrijker dan de rekenkracht voor LLM-inferentie. Het genereren van tokens is geheugenintensief, omdat de modelgewichten herhaaldelijk vanuit het GPU-geheugen worden geladen. De A6000 heeft een geheugenbandbreedte van 768 GB/s, wat lager is dan die van de L40 (864 GB/s) en aanzienlijk lager dan die van de H100 of A100 (2-3 TB/s).
Heterogene GPU-implementaties optimaliseren de kostenefficiëntie door de GPU-capaciteiten af te stemmen op de kenmerken van de aanvragen. Rekenintensieve aanvragen worden doorgestuurd naar GPU's met een hoge FLOPS-capaciteit, terwijl geheugenintensieve aanvragen de voorkeur geven aan opties met een hoge bandbreedte. Deze aanpak verbetert het gebruik van resources voor diverse aanvraagpatronen.
Modelgrootte en hardwarevereisten
Het aantal parameters bepaalt direct de minimale geheugenvereisten. FP16-precisie vereist ongeveer 2 bytes per parameter, terwijl 4-bits kwantisering dit reduceert tot ongeveer 0,5 bytes per parameter.

De mogelijkheden en kosten van cloud-GPU's lopen sterk uiteen. AWS g4dn.xlarge-instances ondersteunen basisworkloads met GPU's voor consumenten. AWS g5.xlarge biedt betere prestaties voor modellen van 7-8 miljard. Grotere modellen vereisen configuraties met meerdere GPU's of gespecialiseerde instances met veel geheugen.
Kostenefficiëntie optimaliseren
Kostenoptimalisatie vereist een evenwicht tussen meerdere factoren tegelijk. Afwegingen tussen prestaties, kwaliteit en kosten vereisen systematische meting en iteratie.
Impact van kwantisering
4-bits kwantisering vermindert de geheugenvereisten en verhoogt de doorvoer met minimale kwaliteitsvermindering. De meeste toepassingen tolereren kwantisering zonder merkbaar prestatieverlies. 4-bits kwantisering vermindert de geheugenvereisten met ongeveer 75% in vergelijking met FP16-precisie, terwijl de verbeteringen in doorvoer behouden blijven.
8-bits kwantisering biedt een middenweg, met een betere kwaliteitsbehoud en een bescheiden geheugenbesparing. Voor kwaliteitsgevoelige toepassingen is 8-bits een veiligere keuze dan de agressievere 4-bits kwantisering.
Batchgrootte afstemmen
Grotere batchgroottes verbeteren het GPU-gebruik en de doorvoer. Het gelijktijdig verwerken van 32 verzoeken levert een betere hardware-efficiëntie op dan het sequentieel verwerken ervan. Grotere batches verhogen echter de latentie voor individuele verzoeken.
Dynamische batchverwerking optimaliseert deze afweging door verzoeken die binnen een bepaald tijdsvenster binnenkomen te groeperen. Wanneer verzoeken sporadisch binnenkomen, zorgen kleinere effectieve batchgroottes voor een lage latentie. Tijdens piekbelasting maximaliseert automatische batchverwerking de doorvoer.
Aanvraagrouteringsstrategieën
Intelligente routering van verzoeken naar verschillende GPU-typen verbetert de kostenefficiëntie. Korte verzoeken met kleine batchgroottes worden doorgestuurd naar GPU's die geoptimaliseerd zijn voor rekenkracht. Langere verzoeken vereisen aanzienlijke geheugentoegang tot hardware die geoptimaliseerd is voor bandbreedte.
Load balancing over replica's voorkomt knelpunten en verbetert de algehele benutting. Round-robin routing werkt goed voor homogene workloads, maar request-aware routing levert betere resultaten op voor diverse aanvraagpatronen.
Een TCO-calculator bouwen
Een nauwkeurige kostenraming vereist een systematische registratie van alle kostencomponenten. Organisaties moeten inzicht hebben in de werkelijke kosten per aanvraag om weloverwogen beslissingen te kunnen nemen over de inzet van diensten.
Hardwarekosten zijn onder te verdelen in aanschaf- en afschrijvingskosten. Een server met 8 GPU's kost $320.000 en heeft een afschrijvingsperiode van 4 jaar, wat neerkomt op $80.000 per jaar of ongeveer $9,13 per uur bij continu gebruik (24/7).
De operationele kosten omvatten hostingkosten, stroomverbruik en onderhoud. Cloudimplementaties vereenvoudigen deze berekening, aangezien de kosten per uur voor de instantie de meeste operationele kosten omvatten. Bij zelfgehoste implementaties is het nodig om de kosten voor de infrastructuur, de stroomkosten (tegen typische tarieven van $0,10-0,15 per kWh) en de administratieve overhead apart bij te houden.
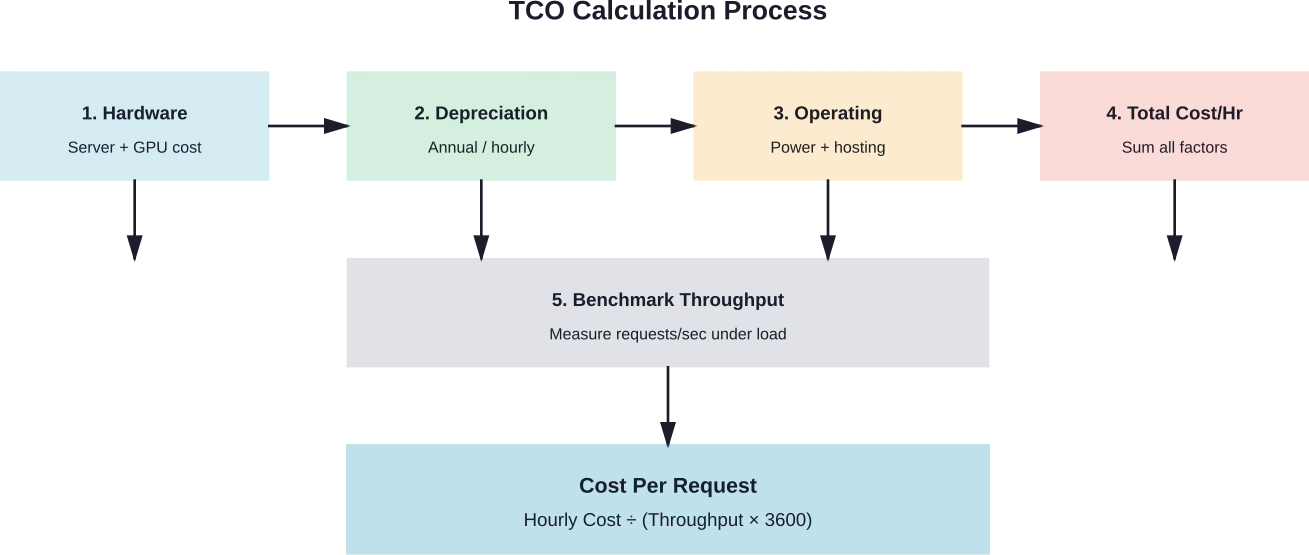
De formule voor de kosten per aanvraag combineert de uurkosten met de gemeten doorvoer:
Kosten per aanvraag = Uurkosten ÷ (Aanvragen per seconde × 3600)
Voor een implementatie die $10 per uur kost en 50 verzoeken per seconde verwerkt, bedragen de kosten per verzoek $0,0000556 of ongeveer $0,056 per 1.000 verzoeken.

Verlaag de kosten voor LLM-opleidingen met slimmere modelontwikkeling.
Bij benchmarks voor dienstverlening ligt de focus vaak op tokens, GPU's en infrastructuurkosten. Maar de werkelijke kostenverschillen komen meestal voort uit de manier waarop het model is ontworpen en geïmplementeerd. AI Superieur Werkt aan de technische laag – het bouwen van aangepaste LLM's, het optimaliseren van trainingspipelines en het structureren van implementaties zodat modellen efficiënt in productie draaien.
Als uw benchmarks hoge serverkosten laten zien, kan het probleem in de architectuur of de inferentie-instellingen liggen. Neem contact op met AI Superieur Uw LLM-systeem evalueren en praktische manieren vinden om de dienstverleningskosten te verlagen.
Praktische benchmarkworkflow
Systematische benchmarking volgt een herhaalbaar proces. Door te beginnen met representatieve werklasten wordt ervoor gezorgd dat de metingen de productieomstandigheden weerspiegelen.
Datasetselectie
ShareGPT biedt realistische gesprekspatronen met gevarieerde promptlengtes en antwoordvereisten. De dataset bevat daadwerkelijke gebruikersinteracties, waardoor deze waardevol is voor testen in een productieomgeving. Door willekeurig 200-500 prompts te selecteren met een vaste willekeurige seed worden reproduceerbare resultaten gegarandeerd.
Synthetische datasets maken gecontroleerde tests van specifieke scenario's mogelijk. Door willekeurige tokengeneratie ontstaan prompts met vooraf bepaalde lengteverdelingen. Deze aanpak test randgevallen zoals de maximale contextlengte of ongebruikelijke tokenpatronen.
Configuratie van het laadpatroon
Testen met een constante datasnelheid meet de prestaties in een stabiele toestand. Door 60 seconden lang op 10 QPS te draaien, worden de basisdoorvoer- en latentiekarakteristieken vastgesteld. Door de snelheid stapsgewijs te verhogen, wordt de maximaal haalbare belasting bepaald voordat de latentie afneemt.
Bursttesten onthullen het gedrag bij plotselinge verkeerspieken. Het opvoeren van 1 QPS naar 100 QPS in 10 seconden en het meten van de hersteltijd toont de veerkracht van het systeem aan. Productiesystemen vertonen vaak piekbelastingen tijdens de piekuren.
Resultaten analyseren
Percentielverdelingen onthullen afwijkend gedrag dat gemiddelden verbergen. Hoewel een latentie in het 50e percentiel acceptabel kan zijn, laten waarden in het 99e percentiel de slechtst mogelijke gebruikerservaring zien. GuideLLM berekent automatisch percentielen van 0,1% tot en met 99,9% voor een uitgebreide analyse.
Een afname van de doorvoer bij aanhoudende belasting duidt op resourceconflicten. Een stabiele doorvoer gedurende de testduur toont aan dat de schaalbaarheid correct is. Een dalende doorvoer suggereert geheugenlekken, thermische throttling of andere systeemproblemen.
Energie- en stroomoverwegingen
Energieverbruik heeft een directe invloed op de operationele kosten en de duurzaamheid van het milieu. Onderzoek van TokenPowerBench benadrukt dat het energieverbruik voor inferentie de trainingskosten met een factor 10 of meer overschrijdt voor productiesystemen die dagelijks miljarden query's verwerken.
Uit benchmarkgegevens van ML.ENERGY blijkt dat energie een kritieke knelpuntfactor is geworden. Toegang krijgen tot voldoende stroominfrastructuur voor GPU-vloten kost meer en duurt langer dan de aanschaf van hardware in veel regio's.
Stroommeting tijdens benchmarks biedt inzicht in de kosten. Het typische stroomverbruik van GPU's varieert van 250W voor energiezuinige kaarten tot 700W voor krachtige accelerators. Bij een tarief van $0,12 per kWh kost een GPU van 400W ongeveer $0,048 per uur aan elektriciteit.
Door de energiekosten te vermenigvuldigen met het aantal GPU's en de overheadkosten van de faciliteit erbij op te tellen, verkrijgt men de totale energiekosten. Voor een server met 8 GPU's die 3200W verbruikt, plus overheadkosten, bedragen de energiekosten ongeveer $0,40-0,50 per uur, afhankelijk van de lokale elektriciteitstarieven en de efficiëntie van de koeling.
Veelgestelde vragen
Wat is de meest kosteneffectieve modelgrootte voor implementatie in een productieomgeving?
Modellen met 7 tot 14 miljard parameters bieden een sterke kostenefficiëntie voor bedrijfsapplicaties. Onderzoek van FinAI toont aan dat deze modellen ongeveer 0,05 keer zo duur zijn als modellen van de GPT-4-klasse, terwijl ze een acceptabele kwaliteit behouden voor taken zoals klantenservice, contentclassificatie en het extraheren van gestructureerde data. Kleinere modellen met 1 tot 3 miljard parameters zijn geschikt voor eenvoudige classificatietaken, terwijl modellen met 70 miljard parameters of meer gereserveerd moeten worden voor applicaties die maximale redeneercapaciteit vereisen.
Welke invloed heeft de batchgrootte op de servicekosten van LLM?
Grotere batchgroottes verbeteren het GPU-gebruik en verlagen de kosten per aanvraag door meerdere query's tegelijk te verwerken. Het verdubbelen van de batchgrootte van 8 naar 16 verhoogt de doorvoer doorgaans met 40-601 TP3T zonder evenredige stijging van de hardwarekosten. Een grotere batchgrootte verhoogt echter de latentie voor individuele aanvragen. Dynamische batchstrategieën balanceren deze afwegingen door de batchgrootte aan te passen aan de huidige belasting, waardoor de doorvoer tijdens piekuren wordt gemaximaliseerd en de latentie tijdens daluren laag blijft.
Moeten organisaties hun LLM-systemen zelf hosten of commerciële API's gebruiken?
Het zelf hosten van kleinere modellen kan kosteneffectief zijn voor grootschalige implementaties, waarbij het break-evenpunt varieert afhankelijk van de modelgrootte en hardwareconfiguratie. Onder deze drempel blijven de prijzen van commerciële API's concurrerend, rekening houdend met de operationele overhead. Zelf gehoste implementaties kunnen aanzienlijke kostenbesparingen opleveren ten opzichte van commerciële API's, afhankelijk van de modelgrootte en de implementatieconfiguratie. Organisaties moeten ook rekening houden met de vereiste technische expertise, aangezien zelfhosting mogelijkheden vereist voor infrastructuurbeheer, monitoring en prestatieoptimalisatie die commerciële API's automatisch afhandelen.
Welke benchmarkinstrumenten werken het beste om de prestaties van LLM-medewerkers te meten?
GuideLLM blinkt uit in realistische productiebenchmarking met configureerbare belastingpatronen en uitgebreide meetwaarden. De vLLM-benchmarksuite biedt uitstekende integratie voor teams die vLLM al gebruiken voor serverbeheer. MLPerf Inference biedt gezaghebbende, gestandaardiseerde benchmarks voor vergelijkingen tussen verschillende hardware- en softwareconfiguraties. Meerdere benchmarkingtools dienen verschillende doeleinden: MLPerf voor gestandaardiseerde vergelijkingen, GuideLLM voor realistische productiepatronen en vLLM-tools voor framework-geïntegreerde testen.
Hoeveel VRAM is er nodig voor verschillende modelformaten?
FP16-precisie vereist ongeveer 2 bytes per parameter: 7B-modellen hebben 14-16 GB nodig, 13B-modellen 26-28 GB en 70B-modellen 140 GB. 4-bits kwantisering vermindert de vereisten met 751 TP3T: 7B-modellen werken met 6-8 GB, 13B-modellen met 10-12 GB en 70B-modellen met 35-40 GB. Voeg daar nog 20-301 TP3T overhead aan toe voor KV-cache en activeringsgeheugen. Een 7B-model met 4-bits kwantisering draait probleemloos op consumenten-GPU's met 8 GB VRAM, terwijl 70B-modellen professionele GPU's met 40 GB of meer of multi-GPU-configuraties vereisen.
Wat veroorzaakt de variabiliteit in latentie bij LLM-inferentie?
Beperkingen in de geheugenbandbreedte vormen de belangrijkste latency-bottleneck. Het genereren van tokens laadt herhaaldelijk modelgewichten uit het GPU-geheugen, waardoor inferentie geheugengebonden is in plaats van rekenkrachtgebonden. Het in de wachtrij plaatsen van verzoeken tijdens hoge belasting zorgt voor variabele wachttijden. De grootte van de KV-cache groeit met de contextlengte, wat de geheugendruk verhoogt en de verwerking van volgende tokens vertraagt. Onderzoek naar inferentie met redeneertaalmodellen toont aanzienlijke geheugenfluctuaties die de consistentie van de prestaties beïnvloeden. Monitoring van de latentie in het 99e percentiel onthult deze variaties beter dan gemiddelde metingen.
Hoe verbeteren heterogene GPU-implementaties de kostenefficiëntie?
Verschillende GPU-typen blinken uit in verschillende workloadkenmerken. GPU's met een hoge bandbreedte, zoals de A6000 (768 GB/s), optimaliseren het genereren van geheugengebonden tokens, terwijl GPU's met een hoge rekenkracht, zoals de A40 (150 TFLOPS), uitblinken in rekenintensieve bewerkingen. Onderzoek gepubliceerd op ICML 2025 toont aan dat het routeren van verzoeken op basis van reken- en geheugenvereisten de benutting van heterogene GPU-vloten verbetert. Heterogene GPU-implementaties kunnen de kostenefficiëntie aanzienlijk optimaliseren ten opzichte van homogene benaderingen door de kenmerken van verzoeken af te stemmen op de juiste GPU-typen, in plaats van één type GPU te overprovisioneren.
Conclusie
LLM-benchmarks bieden essentieel inzicht in de afwegingen tussen prestaties en kosten die de haalbaarheid van een implementatie bepalen. Organisaties die systematisch de doorvoer, latentie en totale eigendomskosten meten, kunnen weloverwogen beslissingen nemen over zelfhosting versus commerciële API's, de keuze van de modelgrootte en de hardwarevoorziening.
De data laten duidelijke patronen zien. Kleinere modellen met 7 tot 14 parameters leveren een kostenbesparing op van 95-991 TP3T ten opzichte van de nieuwste commerciële modellen, terwijl de kwaliteit acceptabel blijft voor veel zakelijke toepassingen. De kosteneffectiviteit van zelfhosting hangt af van het dagelijkse tokenvolume, de hardwarekosten en de operationele overhead die specifiek zijn voor elke organisatie. 4-bits kwantisering reduceert de geheugenvereisten met 751 TP3T met minimale impact op de kwaliteit.
Maar dit is het belangrijkste: benchmarking is geen eenmalige activiteit. Prestatiekenmerken veranderen met modelupdates, verbeteringen aan het serverframework en veranderende werkbelastingspatronen. Organisaties die continue benchmarkworkflows implementeren, behouden kostenefficiëntie naarmate hun AI-implementaties schalen.
Begin met representatieve workloads uit productieomgevingen. Meet uitgebreid de doorvoer, latentiepercentielen en resourcegebruik. Bereken de werkelijke totale eigendomskosten (TCO), inclusief afschrijving van hardware, energieverbruik en operationele overhead. Test meerdere implementatieconfiguraties om de optimale kosten-prestatieverhouding voor specifieke gebruiksscenario's te bepalen.
De tools bestaan al – MLPerf, vLLM, GuideLLM en andere bieden robuuste benchmarkmogelijkheden. De methodologieën zijn bewezen door toepassing in de industrie en academisch onderzoek. Wat nu nog resteert, is de systematische toepassing van deze frameworks op de unieke behoeften en beperkingen van elke organisatie. Benchmark nauwgezet, optimaliseer continu en zie hoe de kosten voor LLM-diensten op grote schaal duurzaam worden.