Korte samenvatting: ChatGPT is een doorbraak in natuurlijke taalverwerking en biedt geavanceerde mogelijkheden voor tekstgeneratie, sentimentanalyse, classificatie en conversationele AI via de GPT-architectuur van OpenAI. Gebouwd op transformermodellen die getraind zijn op enorme tekstcorpora, maakt het toepassingen mogelijk variërend van automatisering van klantenservice tot analyse van medische documentatie. Bedrijven kunnen ChatGPT gebruiken via de OpenAI API (vanaf 1 TP4T5 per miljoen inputtokens voor GPT-5.5) of via abonnementen variërend van 1 TP4T20 per maand voor ChatGPT Plus tot bedrijfsoplossingen.
Natuurlijke taalverwerking heeft zich de afgelopen jaren enorm ontwikkeld, en ChatGPT staat centraal in die transformatie. Wat begon als een experimenteel conversatiemodel is uitgegroeid tot een praktisch hulpmiddel voor bedrijven die zich bezighouden met uiteenlopende zaken, van klantenservice tot klinische documentatie.
De technologie is geen hype. Volgens onderzoek gepubliceerd op arXiv bedroeg de NLP-markt in 2022 1 TP4 T27,73 miljard en zal deze naar verwachting groeien met een samengesteld jaarlijks groeipercentage (CAGR) van 40,41 TP3 T van 2022 tot 2030. De rol van ChatGPT in die groei kan niet worden overschat: het heeft de toegang tot geavanceerde taalmodellen, waarvoor voorheen specialistische expertise vereist was, gedemocratiseerd.
Maar het punt is dit: begrijpen hoe ChatGPT daadwerkelijk werkt binnen het bredere NLP-landschap is essentieel als je het effectief wilt inzetten. Het gaat er niet om een model op een probleem los te laten en te hopen op resultaten. Het gaat erom te weten welke taken aansluiten bij de architectuur van ChatGPT, waar het in uitblinkt en waar traditionele NLP-methoden nog steeds voordelen bieden.
De plaats van ChatGPT in moderne NLP begrijpen
ChatGPT behoort tot een familie van grote taalmodellen (LLM's) die gebouwd zijn op de transformerarchitectuur. Deze modellen leren patronen uit enorme tekstdatasets, waardoor ze coherente, contextueel passende antwoorden kunnen genereren zonder expliciete programmering voor elke taak.
De transformerarchitectuur – voor het eerst geïntroduceerd in onderzoek dat de NLP fundamenteel veranderde – is gebaseerd op aandachtmechanismen die het belang van verschillende woorden in context afwegen. Volgens documentatie van Hugging Face verwerken transformers complete woordreeksen gelijktijdig in plaats van woord voor woord, waardoor ze sneller en contextbewuster zijn dan eerdere terugkerende modellen.
Het huidige vlaggenschipmodel van OpenAI, GPT-5.5, vertegenwoordigt de nieuwste evolutie van deze architectuur. Zoals vermeld in de officiële API-documentatie van OpenAI, is het specifiek ontworpen voor complexe redeneer- en codeertaken, met een contextvenster van 1 miljoen tokens en een maximale uitvoer van 128.000 tokens.
Hoe tekstgeneratiemodellen daadwerkelijk werken
Wanneer je een prompt naar ChatGPT stuurt, raadpleeg je geen database en worden er geen vooraf geschreven antwoorden geactiveerd. Het model berekent waarschijnlijkheidsverdelingen over de beschikbare woordenschat en voorspelt het meest waarschijnlijke volgende token op basis van alles wat eraan voorafging.
Volgens de documentatie over de belangrijkste concepten van OpenAI zijn deze generatieve, vooraf getrainde transformers getraind om zowel natuurlijke als formele taal te begrijpen. Het trainingsproces bestaat uit twee fasen: pre-training op grote tekstcorpora om taalpatronen te leren, en vervolgens fine-tuning op specifieke taken met menselijke feedback om de output af te stemmen op de intentie van de gebruiker.
Die verfijning is belangrijk. Vroege GPT-modellen konden vloeiende tekst genereren, maar dwaalden vaak af of gaven onbehulpzame antwoorden. Moderne ChatGPT maakt gebruik van reinforcement learning op basis van menselijke feedback (RLHF), waardoor het model wordt getraind om prioriteit te geven aan nuttige, accurate en veilige output.
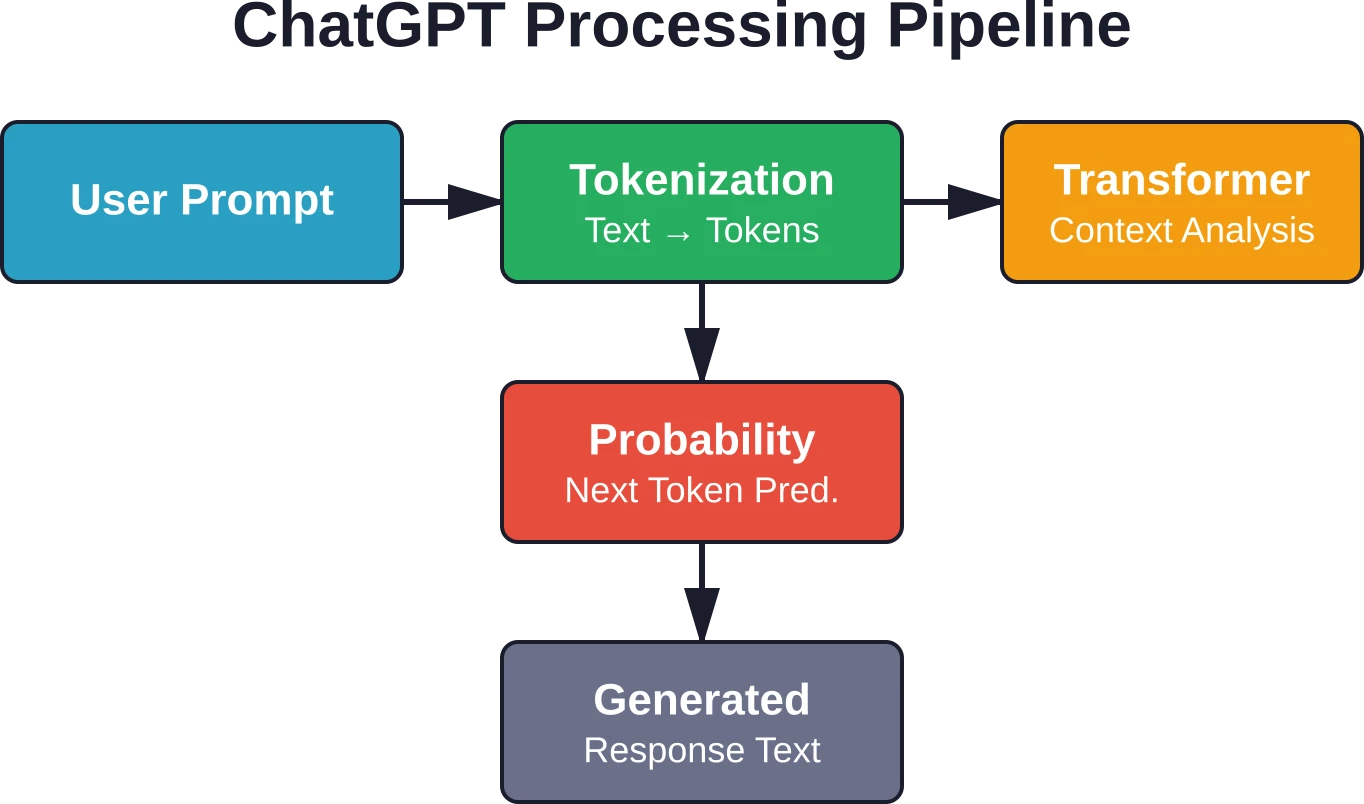
Kern-NLP-toepassingen waarin ChatGPT uitblinkt
Niet alle NLP-taken profiteren evenveel van de architectuur van ChatGPT. Het model blinkt uit in specifieke domeinen waar contextbegrip en generatieve mogelijkheden het belangrijkst zijn.
Tekstgeneratie en contentcreatie
Dit is ChatGPT's thuisbasis. Volgens de documentatie van OpenAI over tekstgeneratie kan het model bijna elk type tekstreactie genereren: code, wiskundige vergelijkingen, gestructureerde JSON-gegevens of mensachtige proza.
Bedrijven gebruiken ChatGPT voor het opstellen van e-mails aan klanten, het maken van productbeschrijvingen, het genereren van technische documentatie en het schrijven van marketingteksten. Het contextvenster van 1 miljoen tokens in GPT-5.5 zorgt ervoor dat het model de samenhang kan behouden, zelfs bij extreem lange documenten.
Eerlijk gezegd: de kwaliteit varieert afhankelijk van het ontwerp van de prompt. Generieke prompts leveren generieke resultaten op. Specifieke instructies met voorbeelden (few-shot learning) leveren consequent betere resultaten op.
Sentimentanalyse en opinieonderzoek
ChatGPT kan tekst classificeren op basis van emotionele toon en detecteren of klantfeedback overwegend positief, negatief of neutraal is. Volgens onderzoek naar de prestaties van ChatGPT in klinische systematische reviews behaalde ChatGPT 3.5 een sensitiviteit van 100% en een specificiteit van 50% (precisie = 65,2%) bij het screenen van onderzoeksartikelen. Dit duidt op een sterke recall, maar ook op af en toe valse positieven.
Voor klantenservice-applicaties betekent dit dat ChatGPT op betrouwbare wijze negatieve reacties kan signaleren voor escalatie naar een medewerker, terwijl routinematige positieve interacties automatisch worden afgehandeld. De afweging tussen precisie en recall is hier belangrijk: detecteer elke klacht (hoge sensitiviteit), zelfs als sommige neutrale berichten ook worden gesignaleerd (lagere specificiteit).
Tekstclassificatie en -categorisatie
Het routeren van supporttickets, het taggen van documenten en het identificeren van spam: ChatGPT voert deze classificatietaken uit via zero-shot of few-shot learning. Volgens onderzoek gepubliceerd op arXiv, waarin verschillende trainingsstrategieën werden geanalyseerd, vereist zero-shot learning $0 aan trainingskosten en biedt het de beste generalisatie voor taken buiten het domein.
Dat is belangrijk voor bedrijven zonder grote datasets met gelabelde voorbeelden. Traditionele classificatiemodellen hebben honderden of duizenden gelabelde voorbeelden nodig. ChatGPT kan classificeren met slechts een paar voorbeelden in de prompt, of zelfs zonder als de categorieën duidelijk zijn gedefinieerd.
Vraagbeantwoording en informatievergaring
Het vermogen van ChatGPT om informatie uit de context te synthetiseren, maakt het effectief voor het beantwoorden van vragen op basis van aangeleverde documenten. Het model matcht niet alleen trefwoorden, maar begrijpt ook de verbanden tussen concepten en kan antwoorden in natuurlijke taal uitleggen.
Medische toepassingen tonen deze mogelijkheid aan. Onderzoek naar generatieve taalmodellen in de geneeskunde wees uit dat ChatGPT een positieve voorspellende waarde behaalde die hoger lag dan die van 95% voor aandoeningen zoals hypertensie, dyslipidemie en beroerte bij de analyse van klinische tekst.
Named Entity Recognition en Information Extraction
Een andere sterke kant van ChatGPT is het extraheren van namen, datums, locaties, medische termen of productidentificaties uit ongestructureerde tekst. ChatGPT kan entiteiten identificeren en gestructureerde formaten zoals JSON uitvoeren, waardoor verdere verwerking eenvoudig is.
Volgens de documentatie van OpenAI ondersteunen de modellen gestructureerde uitvoer die garandeert dat het antwoord overeenkomt met een specifiek JSON-schema. Dit is cruciaal voor toepassingen die betrouwbare gegevensextractie vereisen.
| NLP-taak | ChatGPT-geschiktheid | Belangrijkste voordeel | Typisch gebruiksscenario |
|---|---|---|---|
| Tekst genereren | Uitstekend | Lange-vorm coherentie | Contentcreatie, documentatie |
| Sentiment analyse | Erg goed | Contextueel begrip | Analyse van klantfeedback |
| Classificatie | Erg goed | Nulschotmogelijkheid | Ticketroutering, documenttagging |
| Vraag beantwoorden | Uitstekend | Synthese van verschillende bronnen | Kennisbanken, ondersteuningsbots |
| Entiteitsextractie | Goed | Gestructureerde uitvoerondersteuning | Gegevensextractie, formulierverwerking |
| Vertaling | Erg goed | Meertalige training | Inhoudslokalisatie |
API-integratie en -implementatie
Om ChatGPT in een productieomgeving te implementeren, is het belangrijk om de API-structuur, het prijsmodel en de integratiepatronen van OpenAI te begrijpen.
API-prijsstelling en modelselectie
Volgens de officiële prijslijst van de OpenAI API is de kostenstructuur voor de belangrijkste modellen als volgt opgebouwd:
- GPT-5.5: $5 per miljoen inputtokens, $30 per miljoen outputtokens (gecacheerde input: $0.50)
- GPT-5.4: $2.50 per miljoen inputtokens, $15 per miljoen outputtokens (gecacheerde input: $0.25)
- GPT-5.4 mini: $0.75 per miljoen invoertokens, $4.50 per miljoen uitvoertokens (gecacheerde invoer: $0.075)
Batchverwerking biedt een korting van 50%, terwijl de vereisten voor dataresidentie 10% aan de kosten toevoegen. Voor applicaties die dagelijks miljoenen tokens verwerken, lopen deze verschillen snel op.
Volgens de richtlijnen van OpenAI voor modelselectie zouden teams moeten beginnen met GPT-5.5 voor complexe redeneringen en codering, of kiezen voor gpt-5.4-mini voor workloads met een lagere latentie en lagere kosten.
API-aanroepen uitvoeren
De Responses API biedt de primaire interface voor het genereren van tekst. Volgens de officiële documentatie ziet een basisimplementatie met de Python-client er als volgt uit:
from openai import OpenAI
client = OpenAI()
reactie = client.reacties.create(
model=”gpt-5.5″,
input=”Schrijf een verhaaltje voor het slapengaan van één zin over een eenhoorn.”
)
print(response.output_text)
De API ondersteunt drie berichttypen: ontwikkelaarsberichten (instructies van de applicatie, hoogste prioriteit), gebruikersberichten (instructies voor de eindgebruiker) en assistentberichten (door het model gegenereerde antwoorden). Het structureren van gesprekken met de juiste berichttypen verbetert de kwaliteit van de antwoorden.
ChatGPT-abonnementen voor verschillende gebruiksscenario's
Niet elke applicatie heeft API-toegang nodig. OpenAI biedt abonnementen aan voor direct gebruik van ChatGPT:
- ChatGPT Plus: $20/maand voor lichter gebruik met geavanceerde mogelijkheden zoals Codex en diepgaand onderzoek.
- ChatGPT Pro ($100-niveau): Ontworpen voor echte projecten met 5x hogere limieten dan Plus en 10x meer Codex-gebruik (tijdelijke aanbieding).
- ChatGPT Pro ($200-niveau): Voor zware workflows met 20x hogere limieten dan Plus en 25x hogere Codex-limieten van 5 uur ten opzichte van Plus (beperkte tijd).
Volgens de officiële ChatGPT Plus-helpdocumentatie omvat het Plus-abonnement prioriteitstoegang tijdens drukke perioden en toegang tot geavanceerdere GPT-modellen. Dit is handig voor teams die de mogelijkheden willen evalueren voordat ze overgaan tot API-integratie.


Ontwikkel ChatGPT- en NLP-applicaties met superieure AI.
Tools en NLP-toepassingen in de stijl van ChatGPT werken het beste wanneer ze zijn ontworpen rond specifieke bedrijfstaken, bedrijfsgegevens en daadwerkelijke gebruikersbehoeften. AI Superieur Wij bieden diensten aan op het gebied van AI-chatbotontwikkeling, generatieve AI-ontwikkeling, LLM-consulting, NLP, AI-softwareontwikkeling en AI-integratie. Deze mogelijkheden kunnen ondersteuning bieden aan klantenservice-assistenten, interne kenniszoekopdrachten, documentverwerking, tekstclassificatie, contentworkflows en LLM-gebaseerde functionaliteit binnen bestaande producten.
Relevante AI Superior-diensten omvatten:
- Het definiëren van ChatGPT- en NLP-gebruiksscenario's
- Het ontwikkelen van AI-chatbots en LLM-gebaseerde assistenten
- NLP-tools ontwikkelen voor tekst- en documentworkflows
- AI-tools koppelen aan bedrijfsgegevensbronnen.
- Integratie van AI voor taalgebruik in bestaande platforms
Neem contact op met AI Superior om ChatGPT- of NLP-toepassingen voor uw bedrijf, product of interne processen te bespreken.
Praktische toepassingen in diverse sectoren
Abstracte mogelijkheden zijn minder belangrijk dan concrete implementaties. En dat is waar de NLP-toepassingen van ChatGPT meetbare waarde leveren.
Gezondheidszorg en klinische documentatie
Medische professionals gebruiken ChatGPT voor het transcriberen van patiëntgesprekken, het afleiden van diagnoses uit patiëntendossiers en het opstellen van ontslagbrieven. Onderzoek naar de prestaties van ChatGPT in systematische literatuuronderzoeken toonde aan dat het model een hoge sensitiviteit behaalde bij het screenen van onderzoeksartikelen, hoewel menselijk toezicht essentieel bleef voor de uiteindelijke beslissingen.
Het vermogen van het model om medische terminologie te ontleden en de context in lange documenten te behouden, maakt het bijzonder nuttig voor documentatie – een van de meest tijdrovende aspecten van de klinische praktijk.
Automatisering van klantenondersteuning
Chatbots die gebruikmaken van ChatGPT behandelen routinematige vragen, waardoor menselijke medewerkers zich kunnen richten op complexere zaken. Het belangrijkste verschil met eerdere generaties chatbots? ChatGPT begrijpt de context in gesprekken die meerdere beurten beslaan en genereert antwoorden die zijn afgestemd op specifieke situaties, in plaats van te kiezen uit sjablonen.
Volgens brancheanalyses implementeren bedrijven ChatGPT voor ticketclassificatie, geautomatiseerde antwoorden op veelgestelde vragen, escalatie op basis van sentiment en het opstellen van gepersonaliseerde vervolgberichten. De combinatie van classificatie- en generatiemogelijkheden in één model vereenvoudigt de architectuur.
Inhoudsmoderatie en veiligheid
Platformen gebruiken ChatGPT om schadelijke inhoud te detecteren, beleidsschendingen te classificeren en materiaal te markeren voor handmatige beoordeling. De training van het model omvat afstemming op veiligheidsnormen, waardoor het effectief is in het identificeren van problematische inhoud in categorieën zoals haatspraak, desinformatie en schokkend materiaal.
De afweging tussen vals-positieve en vals-negatieve resultaten is hier van groot belang. Platformen zijn doorgaans afgestemd op een hoge recall (het detecteren van de meeste overtredingen) en accepteren een aantal vals-positieve resultaten die door menselijke moderators worden beoordeeld.
Codegeneratie en technische documentatie
Ontwikkelaars gebruiken ChatGPT om standaardcode te genereren, complexe functies uit te leggen, API-documentatie te schrijven en fouten op te sporen. De focus van GPT-5.5 op programmeertaken is terug te zien in de prestaties – volgens de modeldocumentatie van OpenAI is het specifiek ontworpen voor complexe redeneer- en programmeertoepassingen.
Het Codex-abonnement, beschikbaar via zakelijke abonnementen met een prijsmodel waarbij per gebruik wordt betaald, biedt AI-gestuurde softwareontwikkeling, geautomatiseerde codebeoordelingen en beveiligingsanalyses. Dit toont aan dat OpenAI erkent dat codegeneratie een unieke en waardevolle toepassing is.
Trainingsstrategieën en kostenoverwegingen
De manier waarop teams ChatGPT inzetten, heeft een aanzienlijke invloed op zowel de prestaties als de kosten. Onderzoek gepubliceerd op arXiv, waarin trainingsstrategieën voor grote taalmodellen werden geanalyseerd, identificeerde verschillende benaderingen met elk hun eigen afwegingen.
Zero-shot leren
De taken worden volledig in de prompt gedefinieerd, zonder voorbeelden. Volgens onderzoek vereist deze aanpak $0 aan trainingskosten en levert het de beste generalisatie naar taken buiten het domein op. Het model is volledig afhankelijk van de pre-training.
Zero-shot werkt goed wanneer taken nauw aansluiten bij de trainingsdistributie van ChatGPT, zoals standaard classificatie, samenvatting of vraagbeantwoording. De prestaties nemen af bij zeer gespecialiseerde of ongebruikelijke taken.
Leren met weinig schoten
De prompt bevat een paar voorbeelden (meestal 2-10) die het gewenste gedrag illustreren. De trainingskosten blijven $0, maar het ontwerpen van de prompt vergt meer inspanning. Few-shot verbetert doorgaans de nauwkeurigheid ten opzichte van zero-shot, terwijl de flexibiliteit behouden blijft.
Dit is de ideale middenweg voor de meeste zakelijke toepassingen: voldoende sturing om de resultaten vorm te geven, zonder de complexiteit en kosten van fijnafstelling.
Parameter-efficiënte fijnafstelling (PEFT)
Technieken zoals LoRA (Low-Rank Adaptation) verfijnen een kleine subset van modelparameters op aangepaste datasets. Volgens het onderzoek kosten PEFT-benaderingen $10-$1K aan trainingskosten – aanzienlijk minder dan volledige fine-tuning, terwijl ze vergelijkbare prestaties leveren op specifieke taken.
Fijnafstemming is zinvol wanneer consistent domeinspecifiek gedrag belangrijker is dan flexibiliteit, en wanneer er voldoende trainingsgegevens beschikbaar zijn (doorgaans duizenden voorbeelden).
Volledige parameterfijnafstelling
Het trainen van alle modelparameters op aangepaste data levert maximale prestaties op voor specifieke taken, maar vereist een tweemaal zo grote modelgrootte in geheugen en aanzienlijke rekenkracht. Voor de meeste teams wegen de kosten en complexiteit niet op tegen de marginale prestatiewinst ten opzichte van PEFT.
Beperkingen en praktische overwegingen
ChatGPT is geen universele oplossing. Inzicht in de beperkingen ervan voorkomt kostbare fouten.
Hallucinatie en feitelijke juistheid
Taalmodellen genereren plausibel klinkende tekst op basis van statistische patronen, niet op basis van feitelijke databases. ChatGPT produceert soms zelfverzekerd klinkende, maar onjuiste informatie – wat met name problematisch is voor toepassingen waar nauwkeurigheid cruciaal is.
Mitigatiestrategieën omvatten het genereren van informatie met behulp van brondocumenten (waarbij brondocumenten in de prompt worden aangeleverd), gestructureerde output met validatie en menselijke beoordelingsrondes voor belangrijke beslissingen.
Contextlengtebeperkingen
Ondanks het contextvenster van 1 miljoen tokens van GPT-5.5, hebben extreem lange contexten gevolgen voor zowel de prestaties als de kosten. De kosten van tokens schalen lineair, waardoor het herhaaldelijk verwerken van complete codebases of documentverzamelingen kostbaar wordt.
Slim applicatieontwerp maakt gebruik van embeddings voor de eerste zoekopdracht en geeft vervolgens alleen de relevante gedeelten door aan ChatGPT voor verwerking.
Privacy en gegevensbeveiliging
Volgens de privacyverklaring van OpenAI traint het platform geen modellen op basis van API-input en -output. Gevoelige gegevens blijven echter wel onder controle van de organisatie wanneer ze naar externe API's worden verzonden.
Enterprise-abonnementen pakken dit aan met SAML SSO, MFA, ondersteuning voor GDPR/CCPA-naleving en afstemming op SOC 2 Type 2. Voor sterk gereguleerde sectoren zijn deze beveiligingsfuncties niet optioneel.
Latentie en realtimevereisten
API-aanroepen naar ChatGPT introduceren latentie – doorgaans 1-3 seconden voor standaardverzoeken, langer voor complexe redeneertaken. Applicaties die reacties binnen een seconde vereisen, hebben mogelijk andere architecturen nodig.
Kleinere, snellere modellen zoals GPT-5.4-mini leveren wat capaciteit in voor een lagere latentie en lagere kosten. Volgens de prijsdocumentatie van OpenAI kost GPT-5.4-mini $0,75 per miljoen inputtokens, tegenover $5 voor GPT-5.5 – een significant verschil op grote schaal.
Alternatieve en complementaire benaderingen
ChatGPT maakt deel uit van een breder NLP-ecosysteem. Sommige taken profiteren van alternatieve of hybride benaderingen.
Traditionele NLP-methoden
Regelgebaseerde systemen, reguliere expressies en klassieke machine learning-modellen blijven relevant voor goed gedefinieerde taken met beperkte variabiliteit. Ze zijn sneller, goedkoper, voorspelbaarder en vereisen geen externe API-aanroepen.
Een hybride architectuur zou reguliere expressies kunnen gebruiken voor de eerste filtering, ChatGPT voor een meer gedetailleerde classificatie en vervolgens traditionele modellen voor batchverwerking met hoge doorvoer.
Open-source taalmodellen
Modellen die beschikbaar zijn via platforms zoals Hugging Face bieden alternatieven die lokaal draaien zonder kosten per token. Volgens de documentatie van Hugging Face omvat de transformer-modelfamilie honderden vooraf getrainde modellen voor specifieke talen en domeinen.
Het nadeel? Open-source modellen vereisen doorgaans meer technische expertise voor implementatie en onderhoud, en kleinere modellen presteren minder goed dan ChatGPT bij complexe redeneertaken.
Gespecialiseerde NLP-diensten
Cloudproviders bieden beheerde NLP-services aan voor specifieke taken, zoals entiteitsextractie, vertaling en sentimentanalyse. Deze services zijn vaak goedkoper dan algemene LLM's voor specifieke toepassingen.
Bij architectuurbeslissingen moeten de taakvereisten voorrang krijgen boven technologische voorkeuren. Soms is de beste oplossing een combinatie van meerdere benaderingen.
Toekomstige ontwikkelingen en opkomende patronen
Het NLP-landschap blijft zich snel ontwikkelen. Verschillende trends zullen bepalen hoe ChatGPT-toepassingen zich verder ontwikkelen.
Multimodale mogelijkheden
Volgens de modeldocumentatie van OpenAI ondersteunen de nieuwste modellen zowel tekst- als beeldinvoer – een aanzienlijke uitbreiding ten opzichte van pure taalverwerking. Multimodale modellen kunnen naast tekst ook schermafbeeldingen, diagrammen, grafieken en foto's analyseren.
Dit maakt toepassingen mogelijk zoals moderatie van visuele content, het begrijpen van documenten met complexe lay-outs en toegankelijkheidstools die afbeeldingen in natuurlijke taal beschrijven.
Functieaanroep en toolgebruik
GPT-acties, zoals beschreven in de ontwikkelaarsdocumentatie van OpenAI, stellen ChatGPT in staat om via RESTful API-aanroepen te communiceren met externe applicaties. Het model zet natuurlijke taal om in het JSON-schema dat nodig is voor API-aanroepen.
Dit transformeert ChatGPT van een tekstverwerker in een orchestratielaag die databases kan bevragen, tickets kan aanmaken, realtime gegevens kan ophalen en workflows kan activeren – waardoor de praktische toepassingen aanzienlijk worden uitgebreid.
Verbeterde redeneermodellen
De documentatie van OpenAI beschrijft redeneermodi waarbij modellen meer tijd besteden aan nadenken voordat ze een antwoord geven, waardoor ze ideaal zijn voor complexe problemen met meerdere stappen. Dit lost een belangrijk probleem op waarbij eerdere modellen soms te snel tot een antwoord kwamen zonder voldoende analyse.
Veelgestelde vragen
Wat is het verschil tussen ChatGPT en traditionele NLP-tools?
Traditionele NLP-tools richten zich doorgaans op specifieke taken zoals named entity recognition of sentimentclassificatie, waardoor voor elke functie aparte modellen nodig zijn. ChatGPT is een algemeen taalmodel dat meerdere taken afhandelt via instructies in natuurlijke taal in plaats van taakspecifieke training. Traditionele tools vereisen vaak gelabelde trainingsdata en maatwerkontwikkeling, terwijl ChatGPT zich door middel van prompt engineering kan aanpassen aan nieuwe taken. Traditionele tools bieden echter mogelijk betere prestaties en lagere kosten voor goed gedefinieerde taken met een hoog volume.
Wat zijn de kosten voor het gebruik van ChatGPT voor zakelijke toepassingen?
Volgens de officiële prijslijst van OpenAI bedragen de API-kosten voor GPT-5.5 $5 per miljoen inputtokens en $30 per miljoen outputtokens. Voor abonnementen kost ChatGPT Plus $20 per maand voor lichter gebruik, terwijl de Pro-abonnementen variëren van $100 per maand (5x hogere limieten dan Plus) tot $200 per maand voor zware workflows. Business- en Enterprise-abonnementen hanteren een prijsmodel op basis van gebruik, zonder vaste kosten per gebruiker. De werkelijke kosten zijn afhankelijk van het tokenvolume; een typisch klantenservicegesprek kan in totaal 1.000 tot 3.000 tokens gebruiken, wat met GPT-5.5 $0,01 tot 0,10 kost.
Kan ChatGPT menselijke klantenservicemedewerkers vervangen?
ChatGPT behandelt routinematige vragen effectief en kan potentieel 60-80% aan veelvoorkomende vragen over beleid, accountstatus of basisprobleemoplossing afhandelen. Het systeem heeft echter moeite met complexe uitzonderingen, emotioneel gevoelige situaties en taken die toegang tot realtime systemen vereisen. De meest effectieve implementaties gebruiken ChatGPT voor de eerste triage en routinematige antwoorden, terwijl complexere of belangrijke interacties worden doorverwezen naar menselijke medewerkers. Volledige vervanging is niet aan te raden; hybride benaderingen die de efficiëntie van AI combineren met menselijk oordeel, leiden tot een hogere klanttevredenheid.
Wat zijn de belangrijkste beperkingen bij het gebruik van ChatGPT voor NLP-taken?
ChatGPT kan plausibel klinkende, maar onjuiste informatie genereren, met name bij feitelijke vragen die buiten de trainingsdata vallen. De contextlengte is weliswaar groot, maar beperkt nog steeds de verwerking van extreem lange documenten. De API-latentie (doorgaans 1-3 seconden) maakt het ongeschikt voor toepassingen die onmiddellijke reacties vereisen. Het model heeft ook geen toegang tot realtime informatie, tenzij dit specifiek in de prompt wordt vermeld. Privacyproblemen ontstaan bij het verzenden van gevoelige gegevens naar externe API's. Inzicht in deze beperkingen helpt teams bij het ontwerpen van geschikte architecturen met risicobeheersingsstrategieën zoals retrieval-augmented generation en menselijke beoordelingscycli.
Hoe gaat ChatGPT om met meerdere talen?
Volgens de documentatie van OpenAI ondersteunen alle nieuwste modellen meertalige mogelijkheden die zijn getraind op tekst uit tientallen talen. ChatGPT kan vertalen tussen talen, vragen beantwoorden in andere talen dan Engels en input in gemengde talen verwerken. De prestaties variëren per taal: er is meer trainingsdata beschikbaar voor veelvoorkomende talen zoals Engels, Spaans, Frans, Duits en Chinees dan voor talen waarvoor minder data beschikbaar is. Voor kritische vertaaltoepassingen presteren gespecialiseerde vertaaldiensten mogelijk nog steeds beter dan algemene taalmodellen, maar ChatGPT kan de meeste meertalige taken competent uitvoeren.
Heb ik expertise op het gebied van machine learning nodig om ChatGPT te implementeren?
Voor een basisimplementatie via de OpenAI API zijn standaard softwareontwikkelingsvaardigheden nodig: HTTP-verzoeken doen, JSON-reacties verwerken en API-sleutels beheren. Voor eenvoudige toepassingen is geen specialistische machine learning-expertise vereist. Het optimaliseren van de prestaties door middel van prompt engineering, het implementeren van retrieval-augmented generation of het finetunen van modellen profiteert echter wel van inzicht in NLP-concepten. Teams kunnen beginnen met eenvoudige integraties en geleidelijk complexiteit toevoegen naarmate de vereisten veranderen. De documentatie van OpenAI biedt codevoorbeelden in Python en JavaScript die ontwikkelaars kunnen aanpassen zonder diepgaande kennis van machine learning.
Wat is de beste manier om met ChatGPT aan de slag te gaan voor NLP-toepassingen?
Begin met het ChatGPT Plus-abonnement ($20/maand) om de mogelijkheden te verkennen en prompts interactief te testen voordat u zich vastlegt op API-ontwikkeling. Zodra de use cases duidelijk zijn, maakt u een OpenAI API-account aan en implementeert u een eenvoudig proof-of-concept met behulp van de Responses API met een kleiner model zoals GPT-5.4-mini om de kosten te beheersen. Concentreer u op één enkele, goed gedefinieerde taak: sentimentclassificatie, het beantwoorden van veelgestelde vragen of het samenvatten van content. Meet de prestaties ten opzichte van basismethoden en verzamel feedback van gebruikers. Schaal de complexiteit geleidelijk op en voeg functies zoals functieaanroepen of verfijningen alleen toe wanneer de toegevoegde waarde de extra ontwikkelingsinspanning rechtvaardigt.
Conclusie
ChatGPT heeft de praktische toepasbaarheid van natuurlijke taalverwerking fundamenteel veranderd. Taken die voorheen gespecialiseerde modellen, uitgebreide trainingsdata en maandenlange ontwikkeling vereisten, kunnen nu dankzij snelle engineering binnen enkele uren worden geprototypeerd.
Maar technologie is geen toverkunst. Een effectieve implementatie vereist inzicht in de sterke punten van ChatGPT en de nog steeds zinvolle toepassing van traditionele methoden. Het vraagt om aandacht voor het ontwerp van prompts, inzicht in de kostenstructuur en realistische verwachtingen ten aanzien van beperkingen zoals hallucinaties en latentie.
De organisaties die er de meeste waarde in zien, beschouwen ChatGPT als één tool in een bredere NLP-toolkit – niet als een vervanging voor alles wat eraan voorafging. Ze bouwen hybride architecturen die de sterke punten van ChatGPT benutten en de zwakke punten ervan compenseren door middel van retrieval augmentation, menselijke beoordelingsrondes en taakgerichte modelselectie.
Naarmate modellen blijven verbeteren en de prijsstelling evolueert, zullen de praktische toepassingen zich uitbreiden. Multimodale mogelijkheden, functieaanroepen en verbeterde redenering wijzen nu al op ChatGPT-systemen die complete workflows orkestreren in plaats van alleen tekst te verwerken.
De vraag is niet of we ChatGPT moeten onderzoeken voor NLP-toepassingen, maar hoe we het strategisch kunnen implementeren voor maximale zakelijke waarde. Begin met een duidelijke use case, meet de resultaten objectief en schaal op basis van aantoonbaar rendement in plaats van hype.
Klaar om ChatGPT in productieomgevingen te implementeren? Raadpleeg de officiële OpenAI API-documentatie voor actuele prijzen en technische specificaties, of begin met een Plus-abonnement om de mogelijkheden te testen voordat u investeert in ontwikkelingsmiddelen.