Korte samenvatting: De beste LLM-analyseplatforms voor kosten- en kwaliteitsbewaking in 2026 zijn onder andere Confident AI voor evaluatiegerichte monitoring met prijsstelling op basis van gebruik, Langfuse voor open-source observability met sessietracking en Datadog LLM Observability voor tracering op bedrijfsniveau. MiniMax M2.5 is het meest kostenefficiënte model met een sterke analytische kwaliteit, terwijl AgServe-frameworks aantonen hoe sessiebewuste servering een GPT-40-equivalent kwaliteit kan bereiken tegen 16,51 TP3T aan kosten.
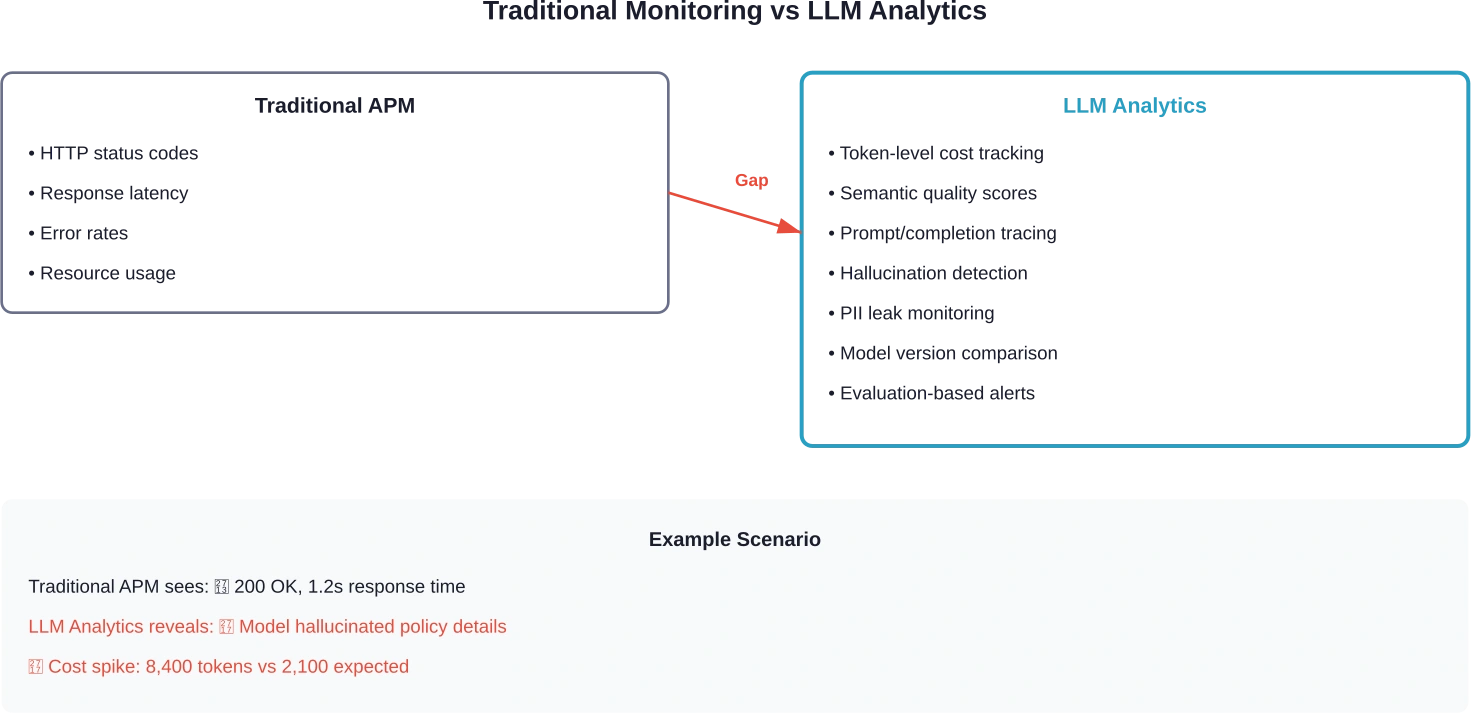
Traditionele monitoring detecteert geen fouten in AI. Een APM-dashboard kan weliswaar een 200-respons binnen 1,2 seconden weergeven, maar het laat niet zien dat het model een beleidsdetail verkeerd heeft begrepen, gevoelige informatie heeft gelekt of halverwege het gesprek van het onderwerp is afgedwaald.
Dat is de leemte die LLM-analysetools opvullen. Ze traceren prompts en voltooide verzoeken, berekenen de tokenkosten per verzoek, detecteren kwaliteitsverschillen tussen modelversies en brengen faalpatronen aan het licht die standaard observatieplatforms volledig missen.
Naarmate LLM-applicaties schalen van prototype naar productie, kunnen de tokenkosten snel oplopen. Een enkele niet-geoptimaliseerde promptketen kan de kosten vertienvoudigen. Zonder realtime inzicht in gebruikspatronen ontdekken teams budgetoverschrijdingen vaak pas nadat de schade al is aangericht.
Deze gids beschrijft de beste LLM-analyseplatforms voor het bijhouden van zowel kosten als kwaliteit. We bespreken de verschillen tussen de tools, hoe de prijzen van de verschillende aanbieders zich verhouden en welke platforms het meest geschikt zijn voor specifieke implementatiescenario's.
Waarom het bijhouden van kosten en kwaliteit van een LLM-opleiding belangrijk is
AI-systemen die in productie worden genomen, falen op een andere manier dan traditionele software. Een webserver retourneert gegevens of geeft een foutmelding. Maar een LLM kan perfect geformatteerde JSON retourneren die volledig verzonnen informatie bevat.
Kostenbeheersing vormt een andere uitdaging. Prijsstelling op basis van tokens betekent dat elke wijziging aan een prompt de economische aspecten beïnvloedt. Het toevoegen van context om de kwaliteit te verbeteren kan de kosten per verzoek verdrievoudigen. Overstappen van GPT-4 naar een kleiner model kan de kosten met 90% verlagen, maar de nauwkeurigheid van de output kan daardoor onder een acceptabel niveau dalen.
Volgens onderzoek naar agentserving-systemen missen bestaande modelserving-platformen sessiebewustzijn, wat leidt tot onnodige compromissen tussen kosten en kwaliteit. Het AgServe-framework laat zien dat sessiebewust KV-cachebeheer en kwaliteitsgebaseerde modelcascadering een responskwaliteit kunnen bereiken die vergelijkbaar is met GPT-40, tegen slechts 16,5% aan kosten.
Dit is wat een goede LLM-analyse mogelijk maakt:
- Kostenattributie op tokenniveau over prompts, gebruikers, functies en modelversies heen
- Kwaliteitsafwijkingsdetectie via geautomatiseerde evaluatiescores en menselijke feedbackloops
- Latentiebewaking dat de responstijd van de API scheidt van de verwerkingstijd van het model.
- Analyse van faalpatronen dat veelvoorkomende hallucinatie-triggers of opmaakfouten aan het licht brengt
- Veiligheidsmonitoring voor het lekken van persoonsgegevens, pogingen tot snelle gegevensinjectie en schendingen van het inhoudsbeleid.
Zonder deze mogelijkheden opereren teams in het duister. Ze kunnen geen snelle technische beslissingen optimaliseren, de ROI niet aantonen aan belanghebbenden en kwaliteitsvermindering niet signaleren voordat deze de gebruikers treft.
Wat maakt LLM Analytics anders dan standaard Observability?
Standaard APM-tools registreren verzoeken, fouten en latentie. Dat is noodzakelijk, maar onvoldoende voor LLM-toepassingen.
Het fundamentele verschil: LLM-analyse moet de volgende zaken evalueren semantische kwaliteit Het gaat om de output, niet alleen of de API-aanroep is geslaagd. Een statuscode 200 zegt niets over de nauwkeurigheid, relevantie of veiligheid van het advies van het model.
Drie mogelijkheden onderscheiden LLM-specifieke analyses van traditionele monitoring:
Kostenberekening op basis van tokens
Elke API-aanroep verbruikt invoertokens (de prompt) en uitvoertokens (de voltooiing). De kosten variëren per model, per tokentype en soms per tijdstip. Voor een correcte kostenregistratie is het nodig om de gebruiksgegevens uit elk API-antwoord te analyseren en aan het juiste kostenplaats toe te wijzen.
Volgens de documentatie van Anthropic over kostenbeheer biedt het commando /cost gedetailleerde statistieken over tokengebruik, waaronder de totale kosten, API-duur, werkelijke gebruiksduur en codewijzigingen. Deze gedetailleerde tracking stelt teams in staat om kostbare bewerkingen te identificeren voordat ze worden opgeschaald.
Evaluatiegebaseerde kwaliteitsindicatoren
De kwaliteit kan niet worden afgeleid uit HTTP-statuscodes. Analyseplatforms lossen dit op door geautomatiseerde evaluaties uit te voeren bij elke voltooide aanvraag. Deze evaluaties controleren op hallucinaties, meten de relevantie ten opzichte van de verwachte resultaten, verifiëren de conformiteit van de opmaak en signaleren mogelijke veiligheidsrisico's.
Het onderzoek van Anthropic naar agentevaluatie benadrukt dat goede evaluaties teams helpen om AI-agents met meer vertrouwen te lanceren. Zonder evaluaties raken teams verstrikt in reactieve processen, waarbij problemen pas in productie worden opgemerkt en het oplossen van één fout weer nieuwe fouten veroorzaakt.
Aanwijzingen en voltooiing traceren
Standaardlogboeken leggen eindpunten en statuscodes vast. LLM-tracering legt de volledige prompt-voltooiingscyclus vast, inclusief systeemberichten, gebruikersinvoer, functieaanroepen, modelparameters en de uiteindelijke uitvoer. Deze context is essentieel voor het debuggen van kwaliteitsproblemen en het optimaliseren van prompts.
De richtlijnen van OpenAI voor evaluatie met Langfuse laten zien hoe het traceren van de interne stappen van agentworkflows zowel online als offline evaluatiestrategieën mogelijk maakt die teams gebruiken om agents op een betrouwbare manier in productie te nemen.
De beste LLM-analyseplatforms voor 2026
De markt voor LLM-analyses is aanzienlijk volwassener geworden. Platformen vallen nu in drie categorieën: evaluatiegerichte tools, open-source observatiekaders en monitoringsuites voor bedrijven.
Hieronder een vergelijking van de belangrijkste platforms:
Zelfverzekerde AI
Confident AI richt zich bij de kwaliteitsbewaking van LLM's op evaluaties en gestructureerde kwaliteitsindicatoren in plaats van op observability in APM-stijl. Het combineert geautomatiseerde evaluatiescores, LLM-tracering, kwetsbaarheidsdetectie en menselijke feedback in één platform.
Deze tool blinkt uit voor teams die kwaliteitsborging boven algemene observeerbaarheid stellen. Elke trace wordt automatisch geëvalueerd aan de hand van configureerbare criteria zoals relevantie, hallucinatiepercentage en conformiteit met de opmaak.
Belangrijkste kenmerken:
- Ingebouwde evaluatiebibliotheek met meer dan 20 kwaliteitsindicatoren.
- Aangepaste evaluatieondersteuning voor domeinspecifieke kwaliteitscontroles
- Integratie van menselijke feedback voor RLHF-workflows
- Kwetsbaarheidsscans voor snelle injectie en lekkage van persoonsgegevens.
- Versiebeheer van datasets voor regressietesten
Prijzen: Gebruiksgebaseerd met prijsstelling op basis van gebruik, waardoor het een toegankelijke optie is voor teams met een gemiddeld tracevolume. Kostenprognoses moeten tijdens de onboardingperiode worden geëvalueerd.
Het meest geschikt voor: Teams die zich richten op kwaliteitsborging en evaluatiegestuurde ontwikkelingscycli.
Langfuse
Langfuse biedt open-source LLM-observatie met volledige tracering van voltooide transacties, kostenregistratie op tokenniveau en kwaliteitsbewaking. Het platform ondersteunt zowel zelfgehoste als cloudimplementatiemodellen.
Volgens de handleiding van OpenAI voor het evalueren van agents met Langfuse, monitort het platform interne agentstappen en maakt het zowel online als offline evaluatiemetrieken mogelijk die teams kunnen gebruiken om agents op een betrouwbare manier in productie te nemen.
Langfuse blinkt uit in sessiebewuste tracking, waarbij gerelateerde traceringen worden gegroepeerd in sessies voor eenvoudigere analyse van gesprekken met meerdere beurten en agentische workflows.
Belangrijkste kenmerken:
- Onbeperkt aantal trace-bereiken met het Pro-abonnement.
- Sessiegebaseerde gespreksregistratie
- Realtime evaluatiescore
- Kostentoewijzing per gebruiker, functie of model
- Open-source kern met optie voor zakelijke cloud
Prijzen: Langfuse Cloud biedt een Hobby-abonnement (50.000 eenheden/maand gratis), een Core-abonnement ($29/maand + gebruik) en een Pro-abonnement ($199/maand + gebruik). Beide betaalde abonnementen omvatten 100.000 eenheden, met extra gebruik vanaf $8/100.000 eenheden.
Het meest geschikt voor: Teams die de flexibiliteit van open source met optionele cloudhosting willen, met name voor conversatietoepassingen met meerdere beurten.
Helicone
Helicone biedt lichtgewicht LLM-observatie met de nadruk op kostenoptimalisatie. Het platform fungeert als een proxy-laag tussen applicaties en LLM-API's en legt elk verzoek vast zonder dat codeaanpassingen nodig zijn.
De proxy-architectuur maakt implementatie eenvoudig. Wijzig het API-eindpunt en Helicone begint direct met het loggen van verzoeken. Deze eenvoud brengt echter wel nadelen met zich mee: minder flexibiliteit voor aangepaste evaluaties en geen ingebouwde kwaliteitsmetrieken.
Belangrijkste kenmerken:
- Integratie zonder code via API-proxy
- Het bijhouden van tokengebruik in verschillende modellen.
- Kostenbewaking en budgetwaarschuwingen
- Latentieanalyse en cachinglaag
- Ondersteuning voor meer dan 10 aanbieders van LLM-programma's
Prijzen: Het gratis abonnement omvat 10.000 aanvragen per maand. Het Pro-abonnement begint bij $79 per maand en is gebaseerd op gebruik.
Het meest geschikt voor: Teams die snel inzicht in de kosten nodig hebben, zonder uitgebreide evaluatievereisten.
Datadog LLM Observability
Datadog heeft zijn platform voor bedrijfsmonitoring uitgebreid met ondersteuning voor LLM-applicaties. Dankzij deze integratie worden LLM-traceringen in hetzelfde dashboard weergegeven als infrastructuurstatistieken, APM-gegevens en logbestanden.
Dit uniforme overzicht helpt teams de prestaties van LLM te correleren met het onderliggende systeemgedrag. Trage voltooiingen kunnen samenhangen met databaselatentie. Kostenstijgingen kunnen samenvallen met specifieke feature-releases.
Belangrijkste kenmerken:
- Geïntegreerde monitoring over de gehele infrastructuur en LLM-laag.
- Realtime kostenbewaking en detectie van afwijkingen
- Overzicht van tokengebruik per eindpunt en gebruiker
- Ondersteuning voor aangepaste meetwaarden voor domeinspecifieke KPI's
- Beveiligings- en compliancefuncties voor bedrijven
Prijzen: Geïntegreerd met het bestaande Datadog-abonnement. Bekijk de officiële website voor de actuele abonnementen die zijn afgestemd op de behoeften van LLM-observatie.
Het meest geschikt voor: Bedrijfsteams die Datadog al gebruiken en LLM-monitoring willen integreren in hun bestaande observability-stack.
Gewichten en schuine weefstructuur
Weave breidt de mogelijkheden van W&B voor het volgen van experimenten uit naar LLM-toepassingen. Het traceert prompt-templates, modelparameters en outputs over verschillende experimenten heen, waardoor het gemakkelijker wordt om promptvariaties en modelconfiguraties te vergelijken.
Het platform blinkt uit in offline evaluatie. Teams kunnen productietraces vastleggen, deze afspelen met verschillende modellen of prompts en kwaliteitsverschillen meten voordat ze wijzigingen implementeren.
Belangrijkste kenmerken:
- Experimentgerichte workflow voor snelle optimalisatie
- Offline evaluatie met trace-replay
- Kostenregistratie per experiment en modelvariant
- Integratie met de ML-levenscyclustools van W&B
- Datasetbeheer voor benchmarktests
Prijzen: Gratis versie beschikbaar. Team- en bedrijfsabonnementen met prijsstelling op basis van gebruik — bekijk de officiële website voor de actuele tarieven.
Het meest geschikt voor: ML-teams die uitgebreide prompt-optimalisatie-experimenten uitvoeren en offline evaluatiemogelijkheden nodig hebben.
| Platform | Kostenregistratie | Kwaliteitsindicatoren | Sessiebewustzijn | Startprijs
|
|---|---|---|---|---|
| Zelfverzekerde AI | Ja | Meer dan 20 ingebouwde evaluaties | Basis | Gebruiksgebaseerd |
| Langfuse | Ja | Aangepaste beoordelaars | Geavanceerd | Gratis / $249/maand |
| Helicone | Ja | Beperkt | Nee | Gratis / $79/maand |
| Datadog LLM | Ja | Aangepaste meetwaarden | Basis | Enterprise-prijzen |
| W&B Weefsel | Ja | Experimentgericht | Offline herhaling | Gratis versie beschikbaar |

Bouw LLM-systemen met duidelijke kosten- en kwaliteitsbewaking.
LLM-applicaties hebben inzicht nodig in hoe modellen in de praktijk presteren. Het bijhouden van prompts, reacties, tokengebruik en systeemgedrag helpt teams de kwaliteit te waarborgen en te begrijpen hoe hun AI-systemen daadwerkelijk worden gebruikt. AI Superieur Het bedrijf ontwikkelt AI-platforms waarin taalmodellen zijn geïntegreerd met backend-systemen, datapijplijnen en analysetools. Hun engineers bouwen AI-software die logging, evaluatie en monitoring ondersteunt, zodat LLM-applicaties betrouwbaar in productie beheerd kunnen worden.
Een LLM-applicatie in productie nemen?
Praat met AI die superieur is aan:
- LLM-gebaseerde applicaties en NLP-tools ontwikkelen
- Integreer workflows voor monitoring en analyse.
- AI-systemen implementeren binnen bestaande softwareplatformen.
👉 Contact AI Superieur om uw AI-ontwikkelingsproject te bespreken.
Het juiste model kiezen voor kostenefficiënte analyses
De platformkeuze is belangrijk, maar de modelselectie bepaalt uiteindelijk de kosten en de kwaliteit. Recente benchmarks tonen aanzienlijke verschillen aan in hoe goed modellen analytische workloads aankunnen.
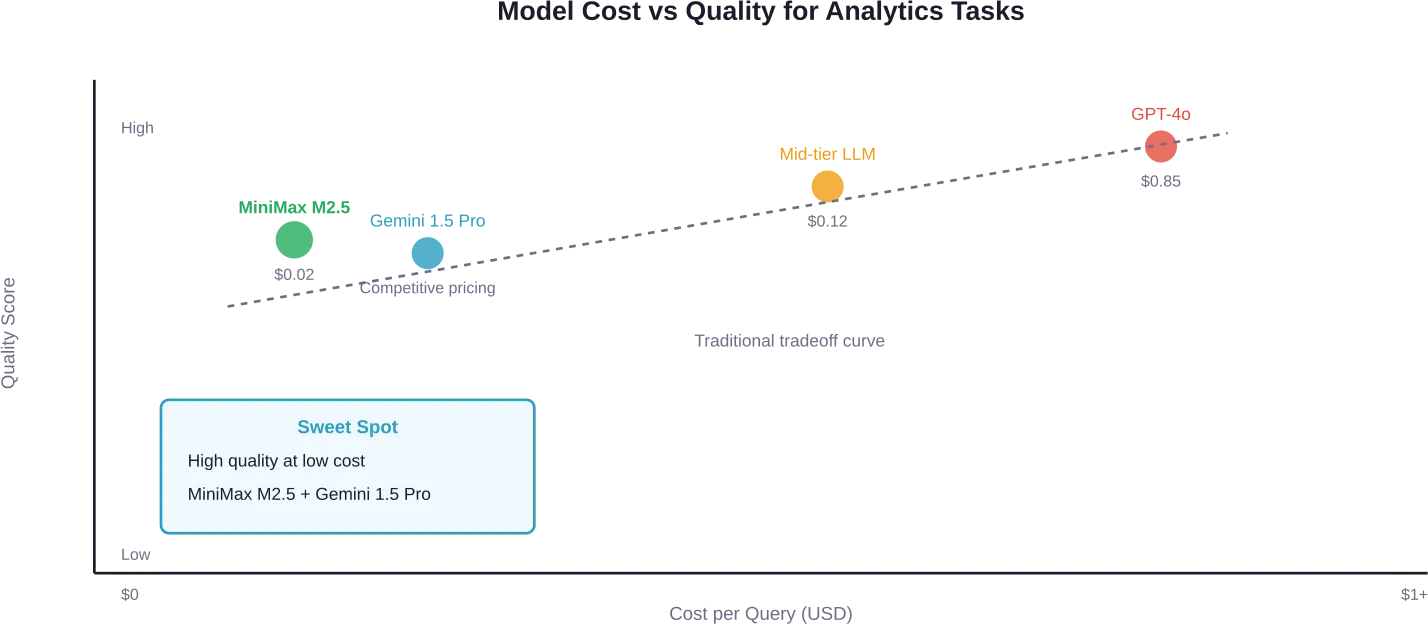
Volgens tests met echte Google Analytics-gegevens leverde MiniMax M2.5 uitstekende kwaliteit in meerdere testruns, kostte $0.02 per query en behaalde een gemiddelde voltooiingstijd van 70 seconden.
De benchmark evalueerde modellen op verschillende dimensies:
- Kwaliteitsbeoordeling: Leverde het model bruikbare inzichten op die verder gingen dan de ruwe data?
- Nauwkeurigheidsscore: In hoeverre werden de werkelijke GA4-dimensies en -statistieken correct gebruikt?
- Kosten per zoekopdracht: Totale API-kosten voor het voltooien van de analytische taak
- Latentie: Tijd vanaf het moment van indiening tot voltooiing
Voor strategische analyses die een diepere onderbouwing vereisen, presteerde Gemini 1.5 Pro uitstekend. Het identificeerde direct gebrekkige attributietracking in testdata en schakelde over naar bruikbare conversieanalyses. Met deze prijs kunnen teams dagelijks honderden query's uitvoeren tegen minimale kosten.
Onderzoek naar de selectie van LLM's voor complexe taken met meerdere stappen bevestigt deze bevindingen. Het MixLLM-framework toonde aan dat adaptieve modelselectie, vergeleken met het gebruik van één krachtige commerciële LLM, de kwaliteit van de resultaten verbetert met 1-16% en tegelijkertijd de inferentiekosten verlaagt met 18-92%.
Kader voor de afweging tussen kosten en kwaliteit
Onderzoek naar het overstijgen van de afweging tussen kosten en kwaliteit bij agent-serving laat zien dat sessiebewuste architecturen de traditionele afwegingscurve kunnen doorbreken. AgServe bereikt een vergelijkbare responskwaliteit als GPT-40 tegen 16,5% aan kosten dankzij twee innovaties:
- Sessiebewust KV-cachebeheer: Het framework maakt gebruik van op Estimated-Time-of-Arrival gebaseerde verwijdering en in-place positionele embedding-kalibratie om de hergebruiksfrequentie van de cache aanzienlijk te verhogen. Dit vermindert overbodige berekeningen tijdens sessies die meerdere beurten omvatten.
- Kwaliteitsbewuste modelcascadering: In plaats van zich voor een hele sessie aan één model te binden, voert AgServe realtime kwaliteitsbeoordelingen uit en worden modellen halverwege de sessie indien nodig geüpgraded. Hierdoor kan er gestart worden met goedkopere modellen en pas worden overgeschakeld naar een geavanceerder model wanneer de kwaliteit dit vereist.
Het onderzoek toont een kwaliteitsverbetering van 1,8 keer ten opzichte van de traditionele kosten-kwaliteitsafwegingscurve, waarmee effectief wordt bewezen dat de juiste architectuurkeuzes betere resultaten kunnen opleveren tegen lagere kosten.
Belangrijke meetbare indicatoren om bij te houden
Effectieve LLM-analyses vereisen het bijhouden van de juiste statistieken. Te veel teams focussen zich uitsluitend op kosten of latentie, terwijl ze kwaliteitsindicatoren negeren die de gebruikerstevredenheid voorspellen.
Kostenmetrieken
- Tokenverbruik per verzoek: Meet zowel de invoer- als de uitvoertokens afzonderlijk. Optimalisatiestrategieën verschillen: het verminderen van invoertokens vereist snelle technische aanpassingen, terwijl het beheersen van uitvoertokens betere steekproefparameters of formaatbeperkingen vereist.
- Kosten per gebruikersinteractie: Bereken de totale tokenkosten voor alle API-aanroepen die nodig zijn om één gebruikerstaak te voltooien. Een enkele gebruikersvraag kan meerdere modelaanroepen activeren (ophalen, redeneren, formatteren), en de totale kosten zijn belangrijker dan de kosten van de afzonderlijke aanroepen.
- Kosten per functie of eindpunt: Attributie maakt ROI-analyse mogelijk. Welke functies genereren waarde die de LLM-kosten rechtvaardigt? Welke functies leveren onnodig veel tokens op zonder evenredig gebruikersvoordeel?
De documentatie van Anthropic over kostenbeheer benadrukt het bijhouden van gebruikspatronen met het commando /stats, dat inzicht biedt op sessieniveau in tokengebruik, API-duur, verstreken tijd en codewijzigingen.
Kwaliteitsindicatoren
- Hallucinatiepercentage: Percentage van ingevulde teksten met verzonnen informatie die niet wordt ondersteund door de verstrekte context. Dit vereist geautomatiseerde feitencontrole aan de hand van brondocumenten of kennisbanken.
- Relevantiescore: Hoe goed beantwoordt de aanvulling de daadwerkelijke vraag van de gebruiker? De semantische gelijkenis tussen vraag en antwoord is een goede indicatie.
- Formaatconformiteit: Voor gestructureerde uitvoer (JSON, CSV, SQL), welk percentage van de suggesties wordt succesvol en zonder fouten verwerkt?
- Veiligheidsvoorschriften die zijn overtreden: Frequentie van outputs die persoonsgegevens, aanstootgevende inhoud of reacties op prompt-injectiepogingen bevatten.
Onderzoek naar de evaluatie van de kwaliteit van de gedachtegang bij codegeneratie heeft aangetoond dat externe factoren verantwoordelijk zijn voor 53,601 TP3T (voornamelijk onduidelijke eisen en ontbrekende context), terwijl interne factoren verantwoordelijk zijn voor 40,101 TP3T (voornamelijk inconsistenties tussen redenering en prompts). Dit suggereert dat het monitoren van zowel de inputkwaliteit als de redeneerpatronen van het model van belang is voor het handhaven van de outputstandaarden.
Prestatie-indicatoren
- Tijd tot eerste token (TTFT): De latentie voordat het model begint met het streamen van uitvoer. Cruciaal voor de waargenomen responsiviteit in chatinterfaces.
- Tokens per seconde: De generatiesnelheid neemt toe zodra het streamen begint. Lagere snelheden frustreren gebruikers die lang moeten wachten op de voltooiing.
- End-to-end latentie: Totale tijd vanaf het moment dat de gebruiker een verzoek indient tot het moment dat het antwoord compleet is, inclusief het ophalen van gegevens, voorbewerking, modelinferentie en nabewerking.
| Metrische categorie | Kernindicatoren | Waarom het belangrijk is
|
|---|---|---|
| Kosten | Tokengebruik, kosten per interactie, kosten per functie | Beheert de uitgaven en maakt ROI-analyse mogelijk. |
| Kwaliteit | Hallucinatiepercentage, relevantiescore, conformiteit aan format | Garandeert nauwkeurige resultaten en gebruikerstevredenheid. |
| Prestatie | TTFT, tokens/seconde, end-to-end latency | Behoudt een responsieve gebruikerservaring. |
| Veiligheid | PII-lekkage, snelle injectiepogingen, beleidsschendingen | Voorkomt beveiligingsincidenten en problemen met de naleving van regelgeving. |
Implementatiestrategieën
Om waarde te halen uit LLM-analyses is meer nodig dan alleen het installeren van een monitoringtool. Teams hebben gestructureerde benaderingen nodig voor instrumentatie, evaluatieontwerp en waarschuwingssystemen.
Begin met traceren
Instrumenteer LLM API-aanroepen om alle aanvraag- en antwoordgegevens vast te leggen.
Log minimaal:
- Tijdstempel en aanvraag-ID
- Modelnaam en parameters
- Volledige prompt (systeembericht, gebruikersinvoer, context)
- Volledige voltooiingstekst
- Aantal tokens (invoer, uitvoer, totaal)
- Uitsplitsing van de latentie (API-tijd, verwerkingstijd)
- Kostenberekening
De meeste analyseplatformen bieden SDK's die dit automatisch afhandelen. Maar zelfs eenvoudige, aangepaste logging in een gestructureerd formaat maakt post-hoc analyse mogelijk.
Definieer kwaliteitsnormen
Onderzoek naar het vereenvoudigen van evaluaties voor AI-agenten benadrukt dat evaluatiestrategieën moeten aansluiten bij de complexiteit van het systeem. Codegebaseerde beoordelaars (stringvergelijking, binaire tests, statische analyse) werken voor deterministische resultaten. LLM-gebaseerde beoordelaars behandelen semantische evaluatie wanneer exacte overeenkomst tekortschiet.
Stel een benchmarkdataset samen met representatieve prompts en verwachte outputs. Test nieuwe modelversies of prompttemplates op deze dataset voordat u ze implementeert. Houd de kwaliteitsstatistieken in de loop van de tijd bij om achteruitgang te signaleren.
Volgens de richtlijnen van OpenAI voor agentevaluatie met Langfuse, omvat offline evaluatie doorgaans het gebruik van een benchmarkdataset met prompt-outputparen, het uitvoeren van de agent op die dataset en het vergelijken van de outputs met behulp van aanvullende scoremechanismen.
Stel kostenwaarschuwingen in
Budgetoverschrijdingen komen snel voor bij op tokens gebaseerde prijsstelling.
Stel waarschuwingen in voor:
- Dagelijkse kosten die de basislijn met 25%+ overschrijden.
- Individuele verzoeken verbruiken 10 keer het normale aantal tokens.
- Specifieke gebruikers of kenmerken die onevenredig hoge kosten veroorzaken
- Onverwachte wijzigingen in modelversies leiden tot hogere uitgaven.
Waarschuwingen moeten aanleiding geven tot onderzoek, niet tot paniek. Kostenstijgingen duiden vaak op productsucces (toegenomen gebruik) in plaats van problemen. Inzicht in de kosten maakt het echter mogelijk om groei te onderscheiden van inefficiëntie.
Implementeer feedbackloops
Geautomatiseerde statistieken leggen niet alles vast wat gebruikers belangrijk vinden. Voeg expliciete feedbackmechanismen toe:
- Duim omhoog/omlaag voor voltooide projecten
- Gedetailleerde rapportage van problemen met tegenvallende resultaten.
- Tevredenheidsonderzoeken op sessieniveau
Koppel gebruikersfeedback aan geautomatiseerde kwaliteitsscores. Als mensen consequent hoogwaardige resultaten slecht beoordelen, moeten de geautomatiseerde meetmethoden worden bijgesteld.
Geavanceerde optimalisatietechnieken
Zodra de basismonitoring operationeel is, kunnen diverse geavanceerde technieken de kosten-kwaliteitverhouding aanzienlijk verbeteren.
Sessiebewuste modelcascade
Onderzoek naar agent-serving toont aan dat sessiebewuste modelselectie aanzienlijke verbeteringen oplevert. In plaats van zich voor een heel gesprek aan één model te binden, begint het systeem met een goedkoper model en wordt er halverwege de sessie geüpgraded wanneer de kwaliteit dat vereist.
Het AgServe-framework behaalt een GPT-40-equivalent kwaliteit tegen 16,51 TP3T aan kosten door dynamisch modellen te selecteren en te upgraden gedurende de sessieduur op basis van realtime kwaliteitsbeoordeling.
Voor de implementatie is het volgende vereist:
- Kwaliteitsbeoordeling na elke modelreactie
- Drempelwaarden die aanvaardbare kwaliteitsniveaus definiëren
- Logica om over te schakelen naar krachtigere (en duurdere) modellen wanneer dat nodig is.
- KV-cachebeheer voor hergebruik van context bij het wisselen tussen modellen.
Snelle optimalisatie op basis van analyses
Analyses tonen aan welke promptpatronen correleren met kwaliteitsproblemen of kostenoverschrijdingen. Veelvoorkomende problemen zijn onder andere:
- Overmatige contextvulling: Het toevoegen van complete documenten aan prompts, terwijl gerichte fragmenten voldoende zouden zijn, wordt door analyses aangetoond. Analysegegevens die een hoog aantal invoertokens met een lage relevantiescore laten zien, wijzen op dit probleem.
- Vage instructies: Algemene aanwijzingen zoals "analyseer deze gegevens" leiden tot onsamenhangende en ongerichte resultaten. Analyses die een lage naleving van de formatrichtlijnen of een grote variatie in de lengte van de uitvoer laten zien, duiden op problemen met de duidelijkheid van de instructies.
- Ontbrekende beperkingen: Het niet specificeren van de uitvoerlengte of het uitvoerformaat leidt tot onnodig lange voltooiingstijden. Analyse van het tokengebruik brengt dit snel aan het licht.
Cachingstrategieën
Veel LLM-applicaties verwerken herhaaldelijk vergelijkbare contexten. Analyses die veelvoorkomende promptvoorvoegsels identificeren, maken gerichte cachingstrategieën mogelijk.
Semantische caching slaat embeddings van recente prompts op. Wanneer een nieuwe prompt semantisch vergelijkbaar is met een prompt uit de cache, retourneer dan de aanvulling uit de cache in plaats van de API aan te roepen. Dit werkt goed voor FAQ-achtige applicaties waar veel gebruikers vergelijkbare vragen stellen.
Door promptprefixen in de cache op te slaan, wordt de verwerking van veelvoorkomende systeemberichten en context hergebruikt. Als 80% prompts dezelfde prefix van 2000 tokens delen, bespaart het opslaan van die berekening in de cache aanzienlijke kosten.
Veelvoorkomende valkuilen en hoe je ze kunt vermijden
Zelfs teams met een monitoringinfrastructuur maken voorspelbare fouten die de effectiviteit van analyses ondermijnen.
Het bijhouden van ijdelheidsstatistieken
Statistieken zoals het totale aantal API-aanroepen of het totale aantal tokens zijn niet bepalend voor beslissingen. Ze stijgen naarmate het product succesvoller wordt. Houd statistieken bij die problemen aangeven: kosten per geleverde waarde, kwaliteitsvermindering en afwijkende latentie.
Het negeren van statistische significantie
De resultaten van LLM zijn willekeurig. Een enkele mislukte opdracht wijst niet op structurele problemen. Teams reageren echter vaak overdreven op incidentele mislukkingen in plaats van trends te analyseren.
Er zijn voldoende grote steekproeven nodig voordat geconcludeerd kan worden dat er sprake is van een kwalitatieve regressieanalyse. Onderzoek naar LLM-selectie voor meerfasige taken legt de nadruk op het ontwerpen van systemen die prestatiefluctuaties als gevolg van LLM-stochastiek kunnen verdragen.
Optimaliseren puur op basis van kosten.
Kostenbesparingen van 50% hebben geen zin als de kwaliteit zodanig daalt dat de gebruikerservaring eronder lijdt. Het doel is een optimale prijs-kwaliteitverhouding, niet de laagste kosten.
Analyses moeten beide dimensies gelijktijdig bijhouden. Onderzoek naar sessiebewuste servering toont aan dat een goede architectuur de kwaliteit kan verbeteren. terwijl Kosten verlagen en de traditionele afweging overstijgen.
Niet getest in productie
Offline evaluatie met benchmarkdatasets is belangrijk, maar het gedrag in de productieomgeving verschilt. Gebruikers formuleren query's anders dan testontwerpers verwachten. Uitzonderlijke praktijkgevallen komen niet voor in samengestelde datasets.
Voer continue productiemonitoring uit en gebruik de resultaten om offline benchmarks te verfijnen. De benchmark moet evolueren om de werkelijke gebruikspatronen te weerspiegelen.
Veelgestelde vragen
Wat is het verschil tussen LLM-monitoring en LLM-observeerbaarheid?
Monitoring houdt vooraf gedefinieerde meetwaarden bij en geeft waarschuwingen wanneer deze drempelwaarden overschrijden. Observability maakt het mogelijk om het systeemgedrag te onderzoeken door middel van willekeurige query's op gedetailleerde traceergegevens. De meeste moderne platforms combineren beide benaderingen: gestructureerde meetwaarden voor dashboards en waarschuwingen, en gedetailleerde traceringen voor het debuggen van specifieke problemen.
Wat zijn de gemiddelde kosten van een LLM-analyse?
De prijsmodellen variëren aanzienlijk. Platforms op basis van gebruik rekenen kosten aan op basis van het tracevolume. Abonnementsplatforms zoals Langfuse Pro kosten $249 per maand voor onbeperkte traces. Enterprise-suites zoals Datadog integreren LLM-monitoring in bestaande contracten.
Kunnen analysetools mijn LLM-kosten verlagen?
Analyses verlagen de kosten niet direct, maar ze maken wel optimalisatiebeslissingen mogelijk die dat wél doen. Onderzoek naar sessiebewuste servering toont aan dat kostenbesparingen van meer dan 80% mogelijk zijn met architectonische verbeteringen.
Welke kwaliteitsindicatoren zijn het belangrijkst voor LLM-toepassingen in de praktijk?
De mate van hallucinatie en de relevantiescore zijn cruciaal voor de feitelijke nauwkeurigheid. Formatconformiteit is belangrijk voor gestructureerde output. Veiligheidsstatistieken (lekken van persoonsgegevens, weerstand tegen promptinjectie) voorkomen beveiligingsincidenten. De specifieke statistieken zijn afhankelijk van het gebruiksscenario — klantondersteuningsapplicaties geven prioriteit aan andere kwaliteitsaspecten dan tools voor codegeneratie.
Moet ik open-source of commerciële LLM-analysetools gebruiken?
Open-source tools zoals Langfuse bieden flexibiliteit bij de implementatie en geen vendor lock-in, maar vereisen wel infrastructuurbeheer. Commerciële platforms bieden managed hosting, snellere feature-ontwikkeling en dedicated support. Teams met sterke infrastructuurvaardigheden geven vaak de voorkeur aan open-source. Teams die zich richten op applicatieontwikkeling in plaats van operationeel beheer kiezen doorgaans voor managed solutions.
Hoe meet ik het rendement op investeringen in data-analyse voor een LLM-opleiding?
Houd drie dimensies in de gaten: kostenbesparingen door optimalisatie (minder tokenverbruik), kwaliteitsverbeteringen (betere gebruikersbeoordelingen, minder supporttickets) en ontwikkelsnelheid (sneller debuggen, veiligere implementaties). De meeste teams zien binnen 2-3 maanden een positief rendement op hun investering, alleen al door kostenoptimalisatie, nog voordat de voordelen op het gebied van kwaliteit en snelheid worden meegerekend.
Wat is de minimaal vereiste analytische configuratie voor een nieuwe LLM-aanvraag?
Begin met basisregistratie die elke prompt, voltooiing, tokenaantal en kosten vastlegt. Voeg een eenvoudige kwaliteitsindicator toe die relevant is voor het domein (conformiteit van de opmaak voor gestructureerde output, relevantiescore voor chattoepassingen). Stel kostenwaarschuwingen in voor budgetoverschrijdingen. Deze minimale configuratie is in 1-2 dagen te implementeren en voorkomt de meest voorkomende productieproblemen.
Conclusie
LLM-analyse is geëvolueerd van een handige extra naar een noodzakelijke vereiste voor de productie. Zonder inzicht in tokenkosten, kwaliteitsstatistieken en prestatiekenmerken werken teams in het duister.
Het platformlandschap biedt sterke opties voor diverse behoeften. Confident AI is toonaangevend voor kwaliteitsbewaking gericht op evaluatie. Langfuse biedt flexibiliteit vanuit open source met robuuste sessietracking. Helicone zorgt voor snel inzicht in de kosten dankzij implementatie via proxy's. Datadog breidt de bedrijfsbrede observability uit naar LLM-workloads.
Maar de juiste tools alleen garanderen geen succes. Effectieve analyses vereisen het bijhouden van de juiste statistieken, het opstellen van kwaliteitsnormen, het implementeren van feedbackloops en het gebruiken van inzichten om optimalisatiebeslissingen te nemen.
Onderzoek toont aan dat sessiebewuste architecturen de traditionele afweging tussen kosten en kwaliteit kunnen overstijgen. AgServe behaalt een GPT-40-kwaliteitsniveau tegen 16,51 TP3T aan kosten door intelligent KV-cachebeheer en dynamische modelselectie. Deze technieken werken omdat ze de systeemarchitectuur afstemmen op de unieke kenmerken van LLM-workloads.
De teams die de beste resultaten behalen, hanteren dezelfde werkwijzen. Ze implementeren vanaf dag één uitgebreide meetinstrumenten. Ze definiëren vroegtijdig kwaliteitsnormen en volgen de achteruitgang continu. Ze optimaliseren op basis van data in plaats van intuïtie. En ze beschouwen analyses als een feedbacksysteem dat in de loop der tijd verbetert, niet als een eenmalige implementatie.
Begin met het implementeren van basisfunctionaliteit voor tracering en kostenbewaking. Voeg kwaliteitsstatistieken toe die relevant zijn voor de use case. Stel waarschuwingen in die problemen signaleren voordat ze gebruikers beïnvloeden. Gebruik vervolgens de verkregen inzichten om stapsgewijze verbeteringen door te voeren in prompts, modelselectie en systeemarchitectuur.
Het verschil tussen teams die succesvol LLM-toepassingen in productie brengen en teams die daarin falen, komt vaak neer op analyses. Meten leidt tot optimalisatie. Optimalisatie leidt tot duurzame economie. En duurzame economie maakt het mogelijk om echt nuttige AI-producten te bouwen.