Korte samenvatting: Asynchrone code kan de kosten van LLM aanzienlijk verlagen als deze correct wordt geïmplementeerd, maar veelvoorkomende valkuilen zoals het direct versturen van verzoeken kunnen de besparingen tenietdoen. Strategische asynchrone patronen, gecombineerd met technieken zoals prompt caching, batchverwerking en gecontroleerde gelijktijdigheid, kunnen de kosten met 60-901 TP3T verlagen met behoud van prestaties. De prijsstelling van het o3-model van OpenAI daalde met 801 TP3T naar 1 TP4T2-8 per miljoen tokens per juni 2025, waardoor een correcte asynchrone implementatie nog kosteneffectiever is geworden.
De kosten voor LLM kunnen sneller uit de hand lopen dan de meeste teams verwachten. Wat begint als een paar validatiescripts of agentworkflows, mondt al snel uit in duizenden API-aanroepen die budgetten in een alarmerend tempo opslokken.
Maar er is een probleem: asynchroon programmeren belooft alles sneller en efficiënter te maken. Maar bij een verkeerde implementatie kan het juist averechts werken. toename uw kosten verlagen en tegelijkertijd de illusie van optimalisatie wekken.
De boosdoener? Subtiele patronen in asynchrone code die alle verzoeken direct versturen, zelfs wanneer processen verderop in de code vroegtijdig stoppen of slechts gedeeltelijke resultaten nodig hebben. Volgens discussies op de OpenAI-ontwikkelaarsforums ondervinden ontwikkelaars die overstappen van synchrone naar asynchrone implementaties vaak onverwachte kostenstijgingen, ondanks snellere uitvoeringstijden.
De verborgen kostenval in asynchrone LLM-code
Asynchrone code lijkt de meest voor de hand liggende keuze voor LLM-applicaties. Verstuur meerdere verzoeken tegelijk, verwerk de resultaten zodra ze binnenkomen en ga verder. Snellere uitvoering, tevredener gebruikers.
Maar er schuilt een valkuil in de meest voorkomende asynchrone patronen.
Wanneer asynchrone functies al hun API-aanroepen vooraf genereren – door ze in taken of promises te verpakken voordat de verwerkingslogica wordt uitgevoerd – bereikt elk verzoek de servers van de LLM-provider. Zelfs als uw validatielogica stopt na de eerste fout. Zelfs als de gebruiker halverwege annuleert. Zelfs als u slechts drie resultaten nodig had, maar er vijftig in de wachtrij hebt gezet.
De aanvragen zijn al verzonden. De tokens worden al verwerkt. De rekening loopt al op.
Hoe werkt ontslag op verzoek?
Neem bijvoorbeeld een validatiescript dat LLM-reacties controleert aan de hand van kwaliteitscriteria. Een eenvoudige asynchrone implementatie zou er als volgt uit kunnen zien:
| async def validate_responses(prompts): taken = [call_llm_api(prompt) for prompt in prompts] voor taak in taken: resultaat = wacht op taak als het resultaat niet aan de criteria voldoet: retourneer False retourneer Waar |
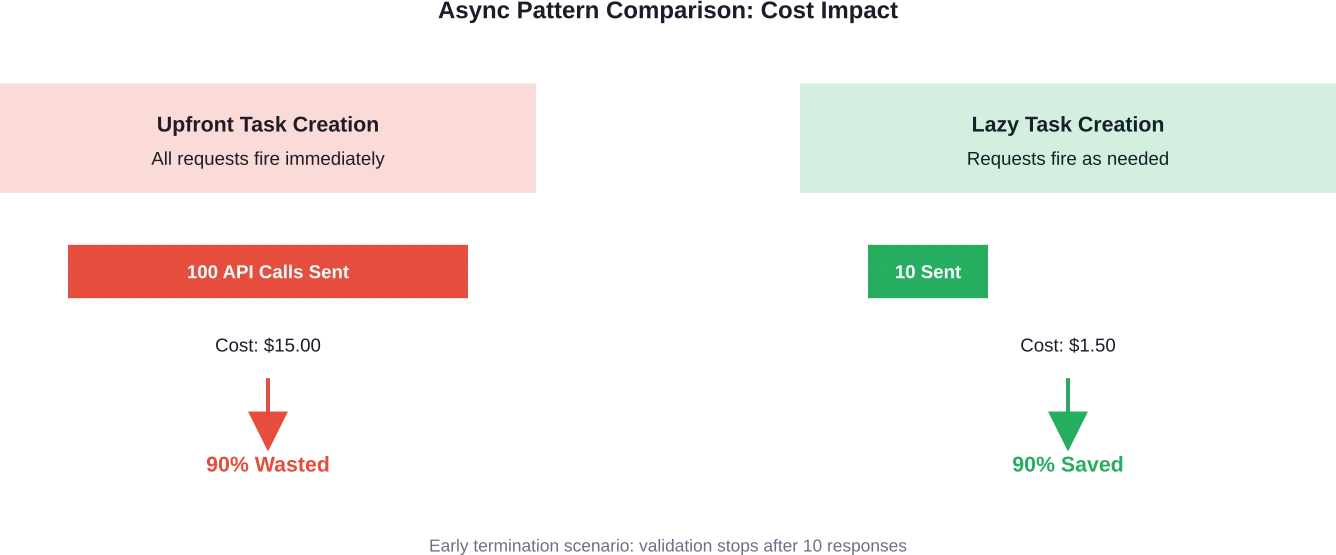
Zie je het probleem? Die list comprehension op regel 2 creëert meteen alle API-aanroeptaken. Nog voordat de lus begint. Voordat er enige validatie plaatsvindt.
Als het eerste resultaat de validatie niet doorstaat, retourneert de functie False, maar er zijn al negenenveertig andere API-aanroepen gaande die al tokens verbruiken en kosten genereren.
Impact op de werkelijke kosten
Een ontwikkelteam ontdekte dit probleem toen hun LLM-validatiescript weliswaar snel werkte, maar onverwacht hoge facturen genereerde. Ondanks het implementeren van ogenschijnlijk efficiënte asynchrone code, verwerkten ze tien keer meer tokens dan nodig.
De oplossing? Vijf regels code die de manier waarop taken werden aangemaakt en afgewacht, herstructureerden. In plaats van alle taken vooraf aan te maken, werd het aanmaken van taken binnen de lus geplaatst, waardoor vroegtijdige beëindiging onnodige API-aanroepen kon voorkomen.
Resultaat: kostenbesparing bij de 90% met vrijwel geen verlies aan snelheid of functionaliteit.
Gecontroleerde gelijktijdigheid: de semafooroplossing
Het oplossen van het probleem met het vooraf versturen van verzoeken is de eerste stap. Maar er is nog een ander asynchroon patroon dat zowel de kosten als de prestaties beïnvloedt: ongecontroleerde gelijktijdigheid.
Wanneer applicaties honderden of duizenden LLM-verzoeken tegelijk versturen, ontstaan er verschillende problemen:
- Snelheidsbeperking die herhaalpogingen en vertragingen veroorzaakt.
- Inconsistente latentie doordat de infrastructuur van de provider moeite heeft met piekbelastingen.
- Mislukte verzoeken die opnieuw verwerkt moeten worden, waardoor de kosten verdubbelen.
- Geheugenbelasting door het beheren van te veel gelijktijdige verbindingen
De oplossing maakt gebruik van asyncio-semaphores – een mechanisme voor gelijktijdige uitvoering dat het aantal gelijktijdig uitgevoerde verzoeken beperkt.
Implementatie van snelheidsbeperking op basis van semaforen
Volgens discussies binnen de OpenAI-community ervaren ontwikkelaars die gelijktijdigheidscontrole implementeren met behulp van een asyncio-semaphore met een limiet van 5 gelijktijdige aanroepen, consistentere prestaties. Hoewel dit het tokengebruik niet direct vermindert, voorkomt het wel de opeenvolging van fouten en herhaalpogingen die de kosten opdrijven.
| import asyncio async def controlled_llm_call(semaphore, prompt): asynchroon met semaphore: return await call_llm_api(prompt) async def process_batch(prompts): semaphore = asyncio.Semaphore(5) taken = [gecontroleerde_llm_aanroep(semaphore, p) voor p in prompts] return await asyncio.gather(*tasks) |
Dit patroon zorgt ervoor dat er slechts vijf verzoeken tegelijk worden uitgevoerd, waardoor het aantal overschrijdingen van de snelheidslimiet wordt verminderd en de latentie stabiel blijft.
Maar wacht even – we hebben nog steeds het probleem van het vooraf aanmaken van taken. De takenlijst wordt aangemaakt voordat er enige verwerking plaatsvindt. Om de kosten te optimaliseren, combineer gecontroleerde gelijktijdigheid met het lui aanmaken van taken.
Promptcaching: Het geheim van kostenbesparing bij de 60%
Laten we het nu hebben over een ander soort optimalisatie, een die werkt ongeacht je asynchrone implementatie.
Prompt caching maakt gebruik van het feit dat veel LLM-applicaties dezelfde context herhaaldelijk versturen. Onderzoeksartikelen, documentatie, systeeminstructies, voorbeeldgegevenssets – inhoud die constant blijft bij meerdere query's.
Wanneer caching is ingeschakeld, verwerkt en bewaart de LLM-provider deze herhaalde inhoud. Bij volgende verzoeken die de gecachte inhoud hergebruiken, worden alleen de nieuwe tokens betaald, niet de volledige prompt.
Hoe werkt promptcaching?
De meeste grote aanbieders van LLM-programma's bieden tegenwoordig snelle caching aan met vergelijkbare mechanismen:
- Markeer bepaalde delen van uw prompt als cachebaar.
- Het eerste verzoek verwerkt en cachet die inhoud.
- Bij volgende verzoeken binnen een bepaald tijdsvenster wordt de cache hergebruikt.
- U betaalt lagere tarieven voor gecachede tokens.
De cache (Prompt Caching) blijft doorgaans 5 tot 10 minuten geldig bij inactiviteit. Als de inhoud binnen die tijd opnieuw wordt gebruikt, levert dat aanzienlijke besparingen op.
Eerlijk gezegd: als je een onderzoeksrapport van 30.000 tokens hebt en je wilt er tien verschillende vragen over stellen, dan verandert caching de economie compleet.
Zonder caching verwerkt de LLM alle 30.000 tokens voor elke vraag – dat zijn in totaal 300.000 tokens. Met caching betaalt u de volledige prijs voor het eerste verzoek, en vervolgens een gereduceerd tarief voor het gecachede gedeelte bij de volgende negen verzoeken.
| Scenario | Totaal aantal verwerkte tokens | Kostenreductie
|
|---|---|---|
| Geen caching (10 query's) | 300.000 tokens | Basislijn |
| Met caching (10 query's) | ~120.000 tokens | 60% besparingen |
| Met caching (50 query's) | ~180.000 tokens | 88% besparingen |
Het combineren van caching met asynchrone patronen
En hier wordt het interessant. Wanneer je een goede asynchrone implementatie combineert met promptcaching, lopen de kostenbesparingen enorm op.
Asynchrone code bundelt van nature vergelijkbare verzoeken in de tijd – precies wat caching nodig heeft om effectief te zijn. Verzoeken die binnen de geldigheidsperiode van de cache binnenkomen, profiteren allemaal van dezelfde gecachte inhoud.
Maar als je asynchrone implementatie onnodige verzoeken verstuurt, verbruiken die extra aanroepen je budget voor gecachede content zonder waarde toe te voegen. De besparing van 60% door caching wordt tenietgedaan door de vertienvoudiging van het aantal onnodige verzoeken.
Als je beide goed aanpakt, verandert de economie compleet.
Batch API: tijd inruilen voor enorme kostenbesparingen
De Batch API van OpenAI is een andere asynchroonvriendelijke strategie om kosten te besparen. Zoals besproken in de OpenAI-ontwikkelaarscommunity, verplaatsen ontwikkelaars ongeveer 4200 synchrone aanroepen naar de Batch API om te profiteren van het verwerkingsvenster van 24 uur en de bijbehorende kostenbesparingen.
De afweging is eenvoudig: langere verwerkingstijden accepteren in ruil voor aanzienlijk lagere kosten.
Wanneer batchverwerking zinvol is
Batch-API's werken het beste voor:
- Verwerking en analyse van datasets
- Pipelines voor contentgeneratie
- Evaluatie- en testworkflows
- Elke taak waarbij onmiddellijke resultaten niet cruciaal zijn.
Het asynchrone patroon is hier anders. In plaats van gelijktijdige verzoeken af te handelen, dient de applicatie een batchtaak in en controleert deze op voltooiing. De LLM-provider optimaliseert de verwerking achter de schermen door verzoeken vaak door te sturen naar minder belaste infrastructuur of door ze tijdens daluren te verwerken.
| # Batch API asynchroon patroon async def submit_batch_job(requests): batch = await client.batches.create( input_file=upload_batch_file(requests), eindpunt=”/v1/chat/completions” ) retourneer batch.id async def poll_batch_status(batch_id): terwijl Waar: batch = await client.batches.retrieve(batch_id) als batch.status == “completed”: return await retrieve_batch_results(batch_id) wacht asyncio.sleep(60) |
De kostenbesparing komt voort uit het vermogen van de dienstverlener om de beschikbare middelen optimaal te benutten. Wanneer u geen onmiddellijke reacties vereist, kunnen zij uw verzoeken efficiënter verwerken.

Verlaag de kosten van een LLM-opleiding met de juiste architectuur.
De kosten van LLM worden vaak veroorzaakt door inefficiënte gebruikspatronen, grote prompts en slecht gestructureerde inferentiepipelines. Samenwerken met een ervaren AI-engineeringteam zoals AI Superieur kan helpen om te achterhalen waar de kosten daadwerkelijk vandaan komen. Het bedrijf ontwikkelt op maat gemaakte AI-systemen en LLM-gebaseerde applicaties, waaronder NLP-tools, chatbots en data-analyseplatforms. Hun engineers ontwerpen modelpipelines, optimaliseren de infrastructuur en structureren implementaties zodat systemen schaalbaar zijn zonder onnodige rekenkosten.
Wil je de kosten van je LLM-opleiding verlagen?
Praat met AI die superieur is aan:
- Ontwerp LLM-pipelines en backend-architectuur.
- NLP-systemen en AI-gestuurde applicaties ontwikkelen
- Modellen implementeren en integreren in bestaande software.
👉 Vraag een AI-consult aan bij AI Superieur om je LLM-project te bespreken.
Huidige prijsstelling voor LLM-opleidingen in 2026
Om kostenoptimalisatie te begrijpen, is het belangrijk de huidige prijzen te kennen. OpenAI kondigde in juni 2025 aanzienlijke prijsverlagingen aan voor hun o3-model: een daling van 80% ten opzichte van de vorige prijs.
De nieuwe prijsstructuur van o3:
- Invoertokens: $2 per 1 miljoen tokens
- Uitvoertokens: $8 per 1 miljoen tokens
Volgens onderzoek naar Mixture-of-Experts-architecturen rekende GPT-4.5 $150 voor het genereren van 1 miljoen tokens, wat het voor veel toepassingen onbetaalbaar maakte. De drastische prijsverlaging in nieuwere modellen verandert de kosten-batenafweging voor optimalisatietechnieken.
Desondanks kunnen zelfs bij lagere kosten per token, verspillende asynchrone patronen op grote schaal nog steeds aanzienlijke kosten met zich meebrengen. Een miljoen onnodige API-aanroepen tegen 1 TP4T2 per miljoen inputtokens betekent nog steeds 1 TP4T2.000 verspilde tokens.
Geavanceerde asynchrone patronen voor LLM-kostenbeheer
Naast de basisprincipes bieden verschillende geavanceerde asynchrone patronen extra mogelijkheden voor kostenoptimalisatie.
Asynchrone KV-cache-voorafhaling
Onderzoek naar het versnellen van de inferentiesnelheid van LLM's via asynchrone KV-cache-prefetching laat aanzienlijke prestatieverbeteringen zien. Op NVIDIA H20 GPU's behaalt deze methode een end-to-end inferentieversnelling tot wel 1,97x op gangbare open-source LLM's.
Hoewel deze techniek zich primair richt op het verminderen van latentie in plaats van directe kostenbesparingen, betekent snellere inferentie een hogere doorvoer per GPU, waardoor de infrastructuurkosten per aanvraag dalen.
Asynchrone RLHF-training
Voor organisaties die aangepaste modellen trainen, biedt asynchroon RLHF (Reinforcement Learning from Human Feedback) aanzienlijke voordelen op het gebied van rekenkracht. Onderzoek toont aan dat asynchrone benaderingen van RLHF modellen ongeveer 40% sneller kunnen trainen dan traditionele synchrone methoden.
De kostenbesparingen komen voort uit een kortere trainingstijd en een efficiënter gebruik van de GPU. Asynchrone trainingsframeworks zoals AsyncFlow laten op grote schaal een doorvoerverbetering zien van 1,76 tot 1,82 keer ten opzichte van standaardimplementaties.
Streamingreacties met vroegtijdige beëindiging
Het streamen van API-reacties maakt een ander kostenoptimalisatiepatroon mogelijk: vroegtijdige beëindiging op basis van de kwaliteit van de reactie.
In plaats van te wachten op het volledige antwoord, kunnen applicaties de gestreamde tokens in realtime evalueren en het verzoek annuleren als de output niet aan de kwaliteitsdrempels voldoet. Dit voorkomt dat tokens worden verspild aan antwoorden die uiteindelijk toch worden weggegooid.
| async def stream_with_quality_check(prompt): stream = await client.chat.completions.create( model=”gpt-4″, berichten=[{“rol”: “gebruiker”, “inhoud”: prompt}], stream=True ) geaccumuleerd = “” asynchroon voor chunk in stream: geaccumuleerd += chunk.choices[0].delta.content of “” als should_terminate_early(accumulated): wacht op stream.sluiten() return None opgebouwd rendement |
De sleutel is het definiëren van geschikte kwaliteitscontroles die snel genoeg verlopen om waarde te leveren – controles op verboden inhoud, irrelevante reacties of schendingen van de opmaak.
Het meten en bewaken van de kostenefficiëntie van asynchrone processen
Optimalisatie zonder meting is giswerk. Effectieve kostenbeheersing vereist het bijhouden van de juiste meetgegevens.
Belangrijke meetwaarden om te monitoren
| Metrisch | Wat het onthult | Doel
|
|---|---|---|
| Tokens per aanvraag | Snelle efficiëntie en korte reactietijden | Minimaliseer zonder kwaliteitsverlies |
| Cache-hitpercentage | Hoe vaak wordt in de cache opgeslagen inhoud hergebruikt? | Boven de 70% voor repetitieve werkzaamheden |
| Mislukte aanvraagfrequentie | Herhaalpogingen kosten als gevolg van fouten en throttling. | Onder 2% |
| Percentage vroegtijdige beëindiging | Hoe vaak worden verzoeken gestopt voordat ze zijn voltooid? | Vergelijk de kostenbesparingen |
| Aantal gelijktijdige verzoeken | Belasting van de infrastructuur van de provider | Overeenkomstige semafoorlimieten |
| Kosten per succesvolle output | Werkelijke kosten, inclusief mislukkingen en herhaalpogingen | Primair optimalisatiedoel |
Het implementeren van kostenbewaking
De meeste LLM-aanbieders bieden dashboards met gebruiksgegevens, maar deze tonen doorgaans geaggregeerde data. Voor gedetailleerde optimalisatie kunt u tracking op aanvraagniveau in uw applicatie implementeren.
Uit discussies binnen de community over API-gebruik blijkt dat het bekijken van kosten per regelitem belangrijke patronen aan het licht brengt. Sommige ontwikkelaars ontdekten onverklaarbare variaties in tokengebruik die pas zichtbaar werden door gedetailleerde tracking.
Voorzie je API-aanroepen van instrumentatie die de volgende gegevens registreert:
- Tijdstempel en latentie van het verzoek
- Aantal invoer- en uitvoertokens
- Cache hit/miss-status
- Fouttypen en herhaalpogingen
- Werkelijke kosten gebaseerd op de huidige prijzen.
Deze gegevens maken het mogelijk om kostenafwijkingen te identificeren voordat ze budgetproblemen worden.
Praktische implementatie: een stapsgewijze aanpak
Oké, maar hoe implementeer je deze kostenoptimalisaties nu daadwerkelijk in een echte applicatie?
Begin met een audit van de huidige asynchrone patronen. Let op de volgende waarschuwingssignalen:
- Lijstcomprehensies creëren alle taken vóórdat er await-instructies worden gegeven.
- asyncio.gather() aanroepen zonder gelijktijdigheidslimieten
- Geen prompt-cachingconfiguratie ondanks herhalende inhoud
- Synchrone batchtaken die mogelijk overgezet kunnen worden naar batch-API's.
- Ontbrekende foutafhandeling leidt tot kostbare herhaalpogingen.
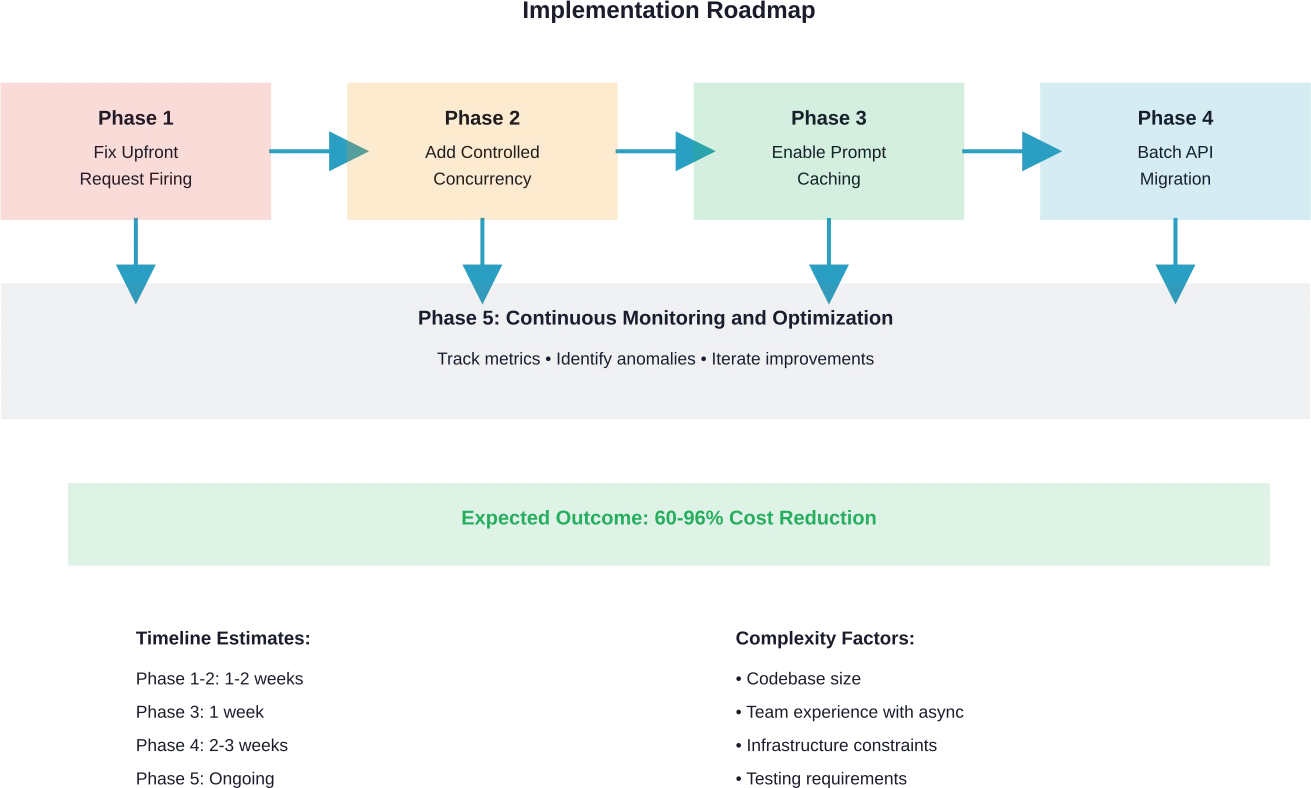
Fase 1: Het probleem met het vooraf activeren van verzoeken oplossen
Identificeer functies die alle taken aanmaken voordat de verwerking begint. Herstructureer de code naar een luie taakcreatie:
| # Voorheen: Alle taken vooraf aangemaakt async def process_items(items): taken = [proces_item(item) voor item in items] voor taak in taken: resultaat = wacht op taak als het resultaat niet gevalideerd wordt: retourneer False # Nadien: Taken aangemaakt indien nodig async def process_items(items): voor item in items: resultaat = wacht op proces_item(item) als het resultaat niet gevalideerd wordt: retourneer False |
Deze ene wijziging kan 50-90% aan onnodige verzoeken in workflows met vroegtijdige beëindigingslogica elimineren.
Fase 2: Gecontroleerde gelijktijdigheid toevoegen
Implementeer semaforen om problemen met snelheidslimieten te voorkomen:
| klasse LLMClient: def __init__(self, max_concurrent=5): self.semaphore = asyncio.Semaphore(max_concurrent) self.client = OpenAI() async def call(self, prompt): asynchroon met self.semaphore: return await self.client.chat.completions.create( model=”gpt-4″, berichten=[{“rol”: “gebruiker”, “inhoud”: prompt}] ) |
Fase 3: Promptcaching inschakelen
Structureer je content zo dat je de cache maximaal kunt hergebruiken. Plaats statische content vooraan en markeer deze als cachebaar volgens de API van je provider.
Fase 4: Geschikte taken overzetten naar batchverwerking
Evalueer welke workflows vertraagde reacties kunnen verdragen. Dataverwerking, contentgeneratie en evaluatieprocessen zijn hiervoor uitstekende kandidaten.
Fase 5: Implementatie van monitoring
Voeg kostenregistratie toe om de impact van optimalisaties te meten en nieuwe kansen te identificeren.
Veelvoorkomende valkuilen en hoe je ze kunt vermijden
Zelfs met de beste bedoelingen kan asynchrone kostenoptimalisatie mislukken. Hier zijn de meest voorkomende valkuilen.
Overoptimalisatie ten koste van latentie
Het te drastisch verlagen van het aantal gelijktijdige aanvragen lost weliswaar problemen met snelheidslimieten op, maar verhoogt de totale uitvoeringstijd aanzienlijk. Een semaphore-limiet van 1 kan throttling elimineren, maar zorgt er ook voor dat alle aanvragen geserialiseerd worden.
Vind de optimale instelling door te experimenteren. Begin met conservatieve limieten en verhoog deze geleidelijk, terwijl u de foutpercentages in de gaten houdt.
Verwarring rondom cache-invalidatie
Het direct cachen van gegevens werkt uitstekend totdat de opgeslagen inhoud verouderd raakt. Applicaties die referentiedocumenten of systeeminstructies bijwerken, hebben strategieën nodig om de cache ongeldig te maken.
De meeste aanbieders regelen dit automatisch via een tijdsgebonden vervaldatum, maar houd rekening met deze periode. Als belangrijke content verandert, is het wachten van 10 minuten tot de cache verloopt mogelijk onacceptabel.
Kosten voor mislukte verzoeken negeren
Veel asynchrone implementaties richten zich op succesvolle verzoeken, terwijl ze de kosten van mislukkingen negeren. Fouten bij het overschrijden van de limiet voor het aantal verzoeken, time-outs en validatiefouten leiden vaak tot herhaalde pogingen die de kosten verhogen.
Registreer mislukte verzoeken afzonderlijk en implementeer exponentiële backoff met maximale herhalingslimieten.
Voortijdige batch-API-migratie
Het overzetten van workloads naar batchverwerking voordat de latentievereisten duidelijk zijn, leidt tot problemen met de gebruikerservaring. Niet alle 'niet-kritieke' workloads kunnen een vertraging van 24 uur verdragen.
Begin met echt asynchrone taken, zoals het verwerken van datasets 's nachts, voordat je iets aanraakt dat door gebruikers wordt gezien.
Veelgestelde vragen
In hoeverre kunnen asynchrone optimalisaties de LLM-kosten realistisch verlagen?
Kostenbesparing is sterk afhankelijk van de huidige implementatiepatronen. Applicaties met logica voor het direct versturen van verzoeken en het vroegtijdig beëindigen ervan kunnen een besparing van 60-901 TP3T realiseren. Applicaties die al efficiënte asynchrone patronen gebruiken, kunnen alleen al door caching en batchverwerking een besparing van 20-401 TP3T behalen. De sleutel is het identificeren van de plekken in de huidige workflow waar onnodige verzoeken voorkomen.
Werkt promptcaching met alle LLM-aanbieders?
De meeste grote aanbieders bieden tegenwoordig prompt caching of vergelijkbare functies aan, maar de implementatiedetails variëren. Raadpleeg de documentatie van de aanbieder voor specifieke vereisten met betrekking tot minimale cachegroottes, cacheduur en prijsstructuren. Sommige aanbieders cachen automatisch, terwijl andere expliciete configuratie vereisen.
Welke gelijktijdigheidslimiet moet ik gebruiken met semaforen?
Begin met 5-10 gelijktijdige verzoeken en houd fouten als gevolg van de snelheidslimiet in de gaten. Als u consistent throttling constateert, verlaag dan de limiet. Als het foutpercentage laag is en de latentie acceptabel, verhoog de limiet dan geleidelijk. De optimale limiet hangt af van de snelheidslimieten van uw provider, de omvang van de verzoeken en de latentievereisten van uw applicatie. Uit discussies in de community blijkt dat limieten tussen 5 en 10 goed werken voor de meeste applicaties.
Kan ik streamingreacties combineren met promptcaching?
Ja, streaming en caching vullen elkaar aan. Gecachede promptinhoud vermindert het aantal tokens dat verwerkt moet worden, terwijl streaming vroegtijdige toegang tot resultaten biedt en vroegtijdige beëindiging mogelijk maakt. Deze combinatie biedt voordelen op het gebied van kostenbesparing en lagere latentie.
Hoe meet ik of optimalisaties daadwerkelijk geld besparen?
Implementeer kostenregistratie op aanvraagniveau die het aantal tokens registreert en de kosten berekent op basis van de huidige prijzen. Vergelijk de kosten vóór en na optimalisatiewijzigingen over vergelijkbare werkbelastingsperioden. Volgens aanbevelingen vanuit de community onthult het bekijken van gebruik gegroepeerd per regelitem in dashboards van aanbieders gedetailleerde kostenpatronen die in geaggregeerde weergaven niet zichtbaar zijn.
Moet ik eerst optimaliseren voor kosten of latentie?
Dit hangt af van de toepassingsvereisten. Gebruikersgerichte functies geven doorgaans prioriteit aan een lage latentie, terwijl de kosten acceptabel blijven. Achtergrondprocessen kunnen een hogere latentie tolereren om kosten te besparen. Begin met het elimineren van verspilling: onnodige verzoeken die geen waarde opleveren, ongeacht de snelheid. Breng vervolgens de kosten en latentie tegen elkaar in balans op basis van specifieke gebruiksscenario's.
Wat gebeurt er met lopende verzoeken als mijn applicatie vastloopt?
Asynchrone verzoeken die naar LLM-providers worden verzonden, blijven verwerkt worden, zelfs als uw applicatie wordt afgesloten. De provider brengt nog steeds kosten in rekening voor voltooide verzoeken. Implementeer de juiste afsluithandlers die lopende verzoeken annuleren en asynchrone gebeurtenisloops netjes afsluiten om te voorkomen dat er verzoeken achterblijven die kosten genereren zonder resultaten te leveren.
Tot slot: hoe je asynchroon programmeren kunt laten werken binnen je budget.
Asynchroon programmeren is niet per se goed of slecht voor de kosten van LLM; het is een hulpmiddel dat zorgvuldige implementatie vereist.
De patronen die ervoor zorgen dat code sneller wordt uitgevoerd, kunnen er ook voor zorgen dat de kosten sneller oplopen als er onnodig veel verzoeken worden gedaan. Maar als asynchroon programmeren correct wordt geïmplementeerd, maakt het kostenoptimalisatiestrategieën mogelijk die synchrone code simpelweg niet kan evenaren.
Begin met een eerlijke audit van de huidige asynchrone patronen. Zoek naar het vroegtijdig aanmaken van taken, ongecontroleerde gelijktijdigheid en gemiste kansen voor caching. Pak eerst de grootste problemen aan – meestal het vroegtijdig uitvoeren van verzoeken in workflows die vroegtijdig worden beëindigd.
Voeg daar vervolgens nog extra optimalisaties aan toe: prompt caching voor repetitieve content, batchverwerking voor niet-urgente taken en streaming met kwaliteitscontroles voor realtime functionaliteiten.
En, cruciaal, meet alles. Houd tokens, kosten, latentie en foutpercentages bij op aanvraagniveau. De data zullen optimalisatiemogelijkheden aan het licht brengen die niet direct opvallen bij een simpele code-inspectie.
Het kostenlandschap van LLM blijft zich ontwikkelen. De prijsverlaging van OpenAI's 80% voor o3-modellen in juni 2025 heeft de economische situatie aanzienlijk veranderd. Maar zelfs bij lagere kosten per token blijft efficiëntie belangrijk op grote schaal.
Klaar om je LLM-kosten te verlagen? Begin vandaag nog met het herzien van je asynchrone implementatiepatronen. De vijf regels code die onnodige verzoeken elimineren, leveren vaak het grootste resultaat op met de minste inspanning.