Korte samenvatting: Het finetunen van een LLM kost doorgaans tussen de 1 TP4T5 en 1 TP4T10.000, afhankelijk van de modelgrootte, de gebruikte techniek en de infrastructuur. Kleinere modellen (2-8 miljard parameters) met parameter-efficiënte methoden zoals LoRA kunnen voor minder dan 1 TP4T10 op cloud-GPU's worden gefinetuned, terwijl het volledig finetunen van grotere modellen op premium infrastructuur meer dan 1 TP4T10.000 kan kosten. Inzicht in de kostenfactoren – rekenkracht, volume van de trainingsdata, modelarchitectuur en techniekkeuze – helpt teams om effectief te budgetteren.
De kosten voor het finetunen van grote taalmodellen overvallen de meeste teams. Trainen vanaf nul kan miljoenen kosten – Google's Gemini Ultra zou naar verluidt 191 miljoen dollar hebben gekost, terwijl GPT-4 rond de 78 miljoen dollar kostte – maar het finetunen van bestaande modellen is een heel ander verhaal.
Het probleem is echter dat de kosten voor finetuning enorm variëren. Een onderzoeksteam van Stanford heeft Qwen3-8B-Base voor minder dan $5 gefinetuned met behulp van LoRA-adapters op de beheerde service van Together AI. Volledige finetuning op bedrijfsinfrastructuren kost daarentegen doorgaans tussen de $3.000 en $10.000.
Inzicht in waar je geld naartoe gaat, is belangrijker dan de prijs op het prijskaartje.
Wat drijft de kosten van fijnafstelling op?
Vier hoofdfactoren bepalen wat fijnafstelling daadwerkelijk kost.
Computerinfrastructuur
De keuze van de GPU zorgt voor de grootste prijsverschillen. Cloudproviders rekenen per uur en de tarieven variëren sterk afhankelijk van de hardwareklasse.
Een NVIDIA A10G – een middenklasse grafische kaart volgens de huidige maatstaven – kost ongeveer $1,50 tot $2,50 per uur op de belangrijkste cloudplatformen. De eerder genoemde finetuning-taak die minder dan $10 kostte, duurde vier uur op één enkele A10G.
Maar opschalen wordt al snel duur. Premium GPU's zoals de A100 of H100 verwerken $4 tot $8 per uur op AWS of Google Cloud. Multi-GPU-configuraties voor grotere modellen vermenigvuldigen deze kosten lineair.
Zelf hosten brengt een andere berekening met zich mee. Een RTX 4090 kost ongeveer 1.600 euro aan aanschafkosten, maar elimineert terugkerende uurkosten. Volgens discussies op LinkedIn verdient één GPU zichzelf binnen enkele weken terug, vergeleken met 2.500 euro aan maandelijkse abonnementskosten voor een GPU-node in de cloud – mits het gebruik constant hoog blijft.
Modelgrootte en architectuur
Het aantal parameters heeft direct invloed op de geheugenvereisten en de trainingsduur.
| Modelmaat | VRAM (volledige fijnafstelling) | VRAM (4-bits LoRA) | Typisch kostenbereik |
|---|---|---|---|
| 2-3B parameters | 6-8 GB | 2-3 GB | $300-$700 |
| 7-8B parameters | 14-16 GB | 6-8 GB | $1.000-$3.000 (LoRA) Tot $12.000 (volledig) |
| 12-13B parameters | 24-28 GB | 10-12 GB | $5,000-$15,000 |
Phi-2 (2,7 miljard parameters) met LoRA kost doorgaans tussen de $300 en $700. Mistral 7B-modellen kosten tussen de $1.000 en $3.000 met LoRA, maar volledige fine-tuning kan de kosten opdrijven tot $12.000.
De geheugenvereisten verklaren dit. Bij volledige finetuning worden de gradiënten voor elke parameter opgeslagen. Een 7B-model heeft ongeveer 28 GB VRAM nodig om alleen al de gewichten met 16-bits precisie te laden – nog voordat rekening wordt gehouden met gradiënten, optimizer-statussen en activatiegeheugen tijdens de training.
Selectie van trainingstechnieken
De gekozen methode voor fijnafstelling heeft een drastische invloed op zowel de kosten als de benodigde middelen.
- Volledige fijnafstelling Deze methode werkt elke modelparameter bij. Het biedt maximale controle en aanpassingsmogelijkheden, maar vereist aanzienlijk veel VRAM. Het geheugenverbruik schaalt lineair met de modelgrootte, waardoor volledige finetuning van modellen met meer dan 13 miljard parameters onpraktisch is zonder multi-GPU-configuraties.
- Parameter-efficiënte fijnafstelling (PEFT) Technieken werken slechts een kleine subset van gewichten bij. LoRA (Low-Rank Adaptation) voegt trainbare adaptermodules in tussen de transformerlagen, terwijl het basismodel bevroren blijft. Volgens onderzoek op arXiv naar resource-efficiënte methoden vermindert LoRA het trainingsgeheugen aanzienlijk, terwijl de nauwkeurigheid vergelijkbaar blijft met volledige fine-tuning.
Impact in de praktijk? Onderzoekers van Stanford behaalden een nauwkeurigheid van 0,78 bij het finetunen van Qwen3-8B met LoRA (rang=32) tegenover een nauwkeurigheid van 0,41 op het basismodel – en dat voor minder dan $5 aan rekenkosten. Deze prestatiewinst tegen minimale kosten laat zien waarom PEFT-technieken de boventoon voeren in praktische toepassingen.
- Kwantisatie Dit verlaagt de kosten verder. Training met 4-bits kwantisering via bitsandbytes zorgde ervoor dat het geheugenverbruik voor de LoRA-finetuning van FLUX.1-dev daalde van ongeveer 60 GB piekgeheugen naar circa 37 GB, volgens de documentatie van Hugging Face. De kwaliteitsvermindering bleef verwaarloosbaar.

Omvang van de dataset en trainingsduur
Meer trainingsdata betekent niet altijd betere resultaten, maar het betekent wel degelijk hogere kosten.
Het aantal tokens bepaalt de rekentijd. De finetuning-API van OpenAI, die factureert op basis van trainingstokens in plaats van de werkelijke tijd, maakt dit verband expliciet. In discussies binnen de community wordt aangegeven dat het bijhouden van kosten het monitoren van getrainde tokens vereist, aangezien de facturering niet langer gebaseerd is op de kernstatistieken van de trainingstijd.
De kwaliteit van de data is belangrijker dan de kwantiteit. Teams behalen vaak betere resultaten met 500 zorgvuldig geselecteerde voorbeelden dan met 5.000 ruisende voorbeelden. Slechte datakwaliteit verlengt de trainingsduur, omdat het model moeite heeft om consistente patronen te vinden, waardoor de kosten stijgen zonder dat de resultaten verbeteren.

Implementeer op maat gemaakte LLM-oplossingen met superieure AI.
Het verfijnen van een groot taalmodel vereist de juiste dataset, trainingsinfrastructuur en evaluatieproces. In veel gevallen kunnen ook aangepaste modelaanpassingen of op retrieval gebaseerde systemen worden overwogen.
AI Superieur Ontwikkelt maatwerk LLM-oplossingen voor bedrijven die domeinspecifieke AI-functionaliteiten nodig hebben.
Hun expertise omvat:
- voorbereiding en annotatie van de dataset
- fijnafstemming en evaluatie van het model
- RAG- en hybride architecturen
- implementatie van LLM-systemen in productieomgevingen
Als u een op maat gemaakte LLM-oplossing nodig heeft die is afgestemd op uw gegevens en workflows, AI Superieur kan het ontwikkelingsproces ondersteunen.
Verborgen kosten die bij elkaar optellen
De factuur van uw cloudprovider geeft niet het volledige beeld.
Gegevensvoorbereiding
Het opschonen, formatteren en valideren van trainingsdata kost veel tijd van de ontwikkelaars. Inconsistenties in datasets beperken de modelprestaties direct – onderzoek naar finetuning voor geautomatiseerde programmareparatie (arXiv:2507.19909) wijst erop dat de mate van overeenstemming tussen menselijke annotaties de haalbare nauwkeurigheid beperkt.
Als annotatoren slechts 701% van de tijd overeenstemming bereiken, kan het model, ongeacht de trainingsinvestering, de nauwkeurigheid van 701% niet betrouwbaar overtreffen.
Experimentatiekosten
Fijnafstelling lukt zelden bij de eerste poging. Het afstemmen van hyperparameters – zoals de leerfrequentie, batchgrootte en het aantal epochs – vereist meerdere trainingsrondes.
Reserveer minimaal 3-5 iteraties. Elke experimentele run kost evenveel als de training voor de productieomgeving.
Validatie en evaluatie
Bij reinforcement finetuning-methoden brengt validatie tijdens de training extra kosten met zich mee. De richtlijnen van OpenAI voor RFT-facturering vermelden expliciet dat de validatiefrequentie een kostenfactor is: hoe vaker gevalideerd, hoe hoger de kosten.
Ook de keuze van het beoordelingsmodel is belangrijk. Het gebruik van een groter model om trainingspunten te evalueren kost meer per validatiecyclus dan het gebruik van kleinere, snellere modellen.
Opslag en implementatie
Modelcontroles nemen opslagruimte in beslag. Een model met 7 miljard parameters en een precisie van 16 bits vereist ongeveer 14 GB schijfruimte per controlepunt. Het opslaan van controlepunten bij elke epoch, verspreid over meerdere experimenten, loopt flink op.
De implementatie-infrastructuur brengt doorlopende kosten met zich mee. Zelfhosting vereist dat GPU-nodes 24/7 operationeel blijven. API-gebaseerde implementatie verschuift de kosten naar een prijsmodel per token voor inferentie.
Kostenanalyse van cloud versus zelfhosting
De beslissing om zelf te bouwen of te kopen hangt af van het gebruikspatroon en de schaal.
Prijzen van cloudproviders
Grote cloudplatformen bieden beheerde finetuning-services en pure GPU-rekenkracht. Beheerde services vereenvoudigen de complexiteit van de infrastructuur, maar voegen wel kosten toe. Volgens de documentatie over onderzoekscomputerbronnen van Stanford leverde de beheerde trainingsservice van Together AI het onderstaande finetuning-voorbeeld ($5) aanzienlijk goedkoper op dan een zelfbeheerde equivalente infrastructuur.
Het huren van losse GPU's biedt meer controle. AWS g5.xlarge-instances (NVIDIA A10G) beginnen bij ongeveer $1,50 per uur. Multi-GPU-instances voor grotere modellen schalen proportioneel mee: een g5.12xlarge met 4x A10G GPU's kost ongeveer $6 per uur.
Economie van zelfhosting
Consumenten-GPU's maken lokale finetuning mogelijk voor kleinere modellen. Een RTX 4060 Ti 16GB kan 7B-modellen aan met LoRA en kwantisering. De aanschafprijs ligt tussen de 1200 en 1600 euro, maar er zijn geen terugkerende kosten.
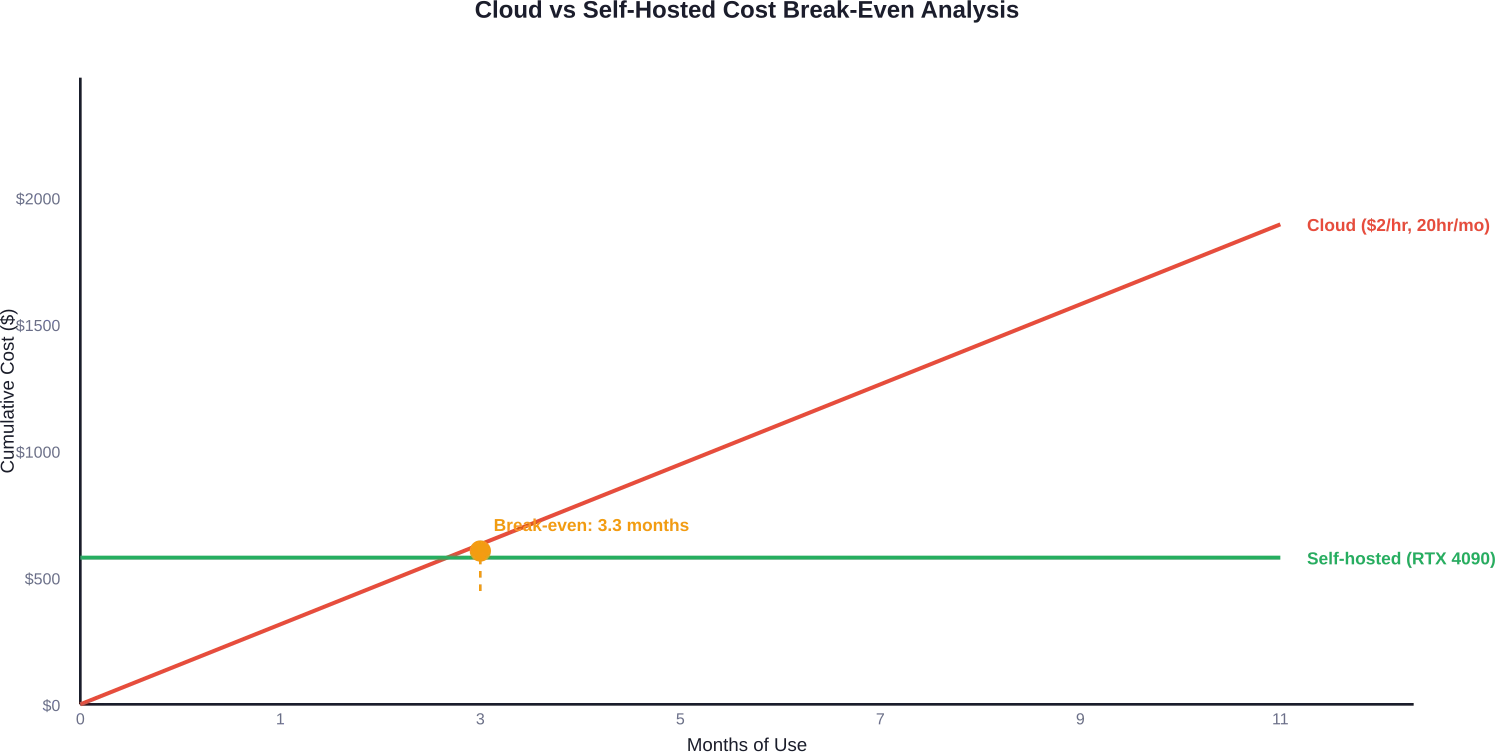
De berekeningen geven de voorkeur aan zelfhosting wanneer het gebruik meer dan 15-20 uur per maand bedraagt. Bij cloudtarieven van $2 per uur kost 20 uur per maand $480, wat betekent dat een GPU van $1600 zichzelf in minder dan vier maanden bij constant gebruik terugverdient.
Maar de cloud biedt flexibiliteit voor sporadische workloads. Het uitvoeren van één fijnafstemmingstaak per maand gedurende vier uur ($8-$10 in de cloud) rechtvaardigt de aanschaf van een GPU niet.
Wanneer fijnafstelling financieel zinvol is
Niet elk gebruiksscenario rechtvaardigt investeringen in fijnafstelling.
Bereken uw basislijn
Vergelijk de kosten van finetuning met API-alternatieven. Als een taak maandelijks 10 miljoen inferentietokens vereist, bedragen de API-kosten $0,001 per 1000 tokens, wat neerkomt op $10.000 per jaar. Een eenmalige investering van $2.000 in finetuning, die goedkopere inferentie met kleinere modellen mogelijk maakt, levert binnen enkele maanden een rendement op.
Maar als snelle engineering met een basismodel acceptabele resultaten oplevert, is fijnafstemming een verspilling van middelen.
Contextvensters De berekening wijzigen
Moderne modellen ondersteunen contextvensters met 200.000 tot 1 miljoen tokens. Door domeinkennis in prompts te verwerken, is fijnafstemming voor veel toepassingen overbodig. Wanneer er elke 4-6 maanden nieuwe basismodellen verschijnen, worden de kosten voor het onderhouden van verfijnde versies een terugkerende uitgave.
Discussies binnen de community benadrukken deze verschuiving: teams geven steeds vaker de voorkeur aan grote contextvensters met goed ontworpen prompts boven aangepaste finetuning, omdat overschakelen naar verbeterde basismodellen geen hertraining vereist.
Fijn afstellen levert winst op voor
In specifieke scenario's is fijnafstelling nog steeds wenselijk:
- Consistente uitvoeropmaak die met prompts niet betrouwbaar kan worden afgedwongen.
- Gespecialiseerde domeinkennis die niet aanwezig is in de trainingsgegevens van het basismodel.
- Toepassingen waarbij latency cruciaal is en waar kleinere, fijn afgestelde modellen beter presteren dan grotere basismodellen.
- Inferentie met een hoog volume, waarbij de API-kosten per token hoger zijn dan de eenmalige investering in training.
- Privacyvereisten die het gebruik van externe API's belemmeren
Lagere kosten voor fijnafstelling zonder kwaliteitsverlies.
Verschillende strategieën verlagen de kosten met behoud van prestaties.
Begin klein.
Begin met het kleinste model dat mogelijk werkt. Verfijn een model met 3 miljard parameters voordat u varianten met 7 of 13 miljard parameters probeert. De prestaties zijn wellicht voldoende, en de kosten blijven onder de $500.
Volgens onderzoek op arXiv naar het finetunen van lichtgewicht LLM's voor de classificatie van financieel sentiment (arXiv:2512.00946) worden modellen met 7-8 miljard parameters, waaronder DeepSeek-LLM 7B, Llama3 8B Instruct en Qwen3 8B, vergeleken met FinBERT op financiële datasets. Kleinere modellen leveren resultaten van productiekwaliteit voor taken met een duidelijke focus.
Gebruik LoRA standaard
Begin elk finetuningproject met LoRA, tenzij dwingende redenen een volledige finetuning vereisen. De kwaliteitsbehoud van 80-95% ten opzichte van de kostenbesparing van 70-95% maakt LoRA de voor de hand liggende standaardkeuze.
Het afstemmen van de rangparameter biedt verdere optimalisatiemogelijkheden. Lagere LoRA-rangen (8-16) verlagen de kosten ten opzichte van hogere rangen (32-64) met minimale impact op de nauwkeurigheid voor veel taken.
Optimaliseer de trainingsduur
Meer iteraties garanderen geen betere resultaten. Monitor het validatieverlies en stop de training wanneer de verbetering stabiliseert. Vroegtijdig stoppen voorkomt verspilling van rekenkracht aan marginale winsten.
Het onderzoek van het MIT-IBM Watson AI Lab naar schaalwetten wijst uit dat een ARE van 4 procent ongeveer de best haalbare nauwkeurigheid is vanwege de willekeurige zaadruis. Dit vereist een zorgvuldige toewijzing van het rekenbudget, maar verder gaan dan dat levert afnemende meeropbrengsten op tegen exponentieel hogere kosten.
Verzamel en beheer trainingsgegevens op een proactieve manier.
Vijfhonderd hoogwaardige voorbeelden zijn beter dan vijfduizend middelmatige. Investeer vooraf tijd in datakwaliteit om het aantal benodigde trainingsiteraties te verminderen.
Verwijder duplicaten, corrigeer inconsistenties in de opmaak en valideer labels. Schone data zorgt voor snellere trainingen en betere resultaten, wat zowel tijd als kosten bespaart.
Overweeg beheerde services.
Platformimplementatie kost soms minder dan de ontwikkeltijd. Managed services verzorgen de infrastructuurvoorziening, monitoring en checkpointbeheer. Voor teams zonder expertise in ML-infrastructuur bieden managed platforms zoals Together AI of Hugging Face AutoTrain snellere resultaten tegen lagere totale kosten.
Veelgestelde vragen
Wat zijn de kosten voor het finetunen van GPT-3.5 of GPT-4?
OpenAI berekent de kosten op basis van trainingstokens. Finetuning met GPT-3.5-turbo kost ongeveer $0.008 per 1000 trainingstokens. Het trainen van een dataset met 100.000 trainingstokens kost ongeveer $0.80. Finetuning met GPT-4 is aanzienlijk duurder; raadpleeg de officiële prijslijst van OpenAI voor de actuele tarieven, aangezien deze periodiek wijzigen.
Kan ik LLM's op een laptop finetunen?
Kleinere modellen (2-3 miljard parameters) werken op krachtige laptops met 16 GB of meer aaneengesloten geheugen of dedicated VRAM met 4-bits kwantisering en LoRA. Houd rekening met zeer trage training – uren tot dagen, afhankelijk van de grootte van de dataset. Cloud-GPU's blijven in de meeste gevallen praktischer, maar finetuning op een laptop is technisch haalbaar voor experimenten.
Is finetuning op de lange termijn goedkoper dan het gebruik van API-aanroepen?
Het hangt af van het inferentievolume. Bereken de maandelijkse API-kosten bij huidig gebruik en vergelijk deze met de eenmalige investering in finetuning plus de inferentiekosten van uw gefinetunede model. Voor toepassingen met een hoog volume (miljoenen tokens per maand) levert finetuning vaak binnen enkele maanden een ROI op. Voor toepassingen met een laag volume of experimenteel gebruik zijn API's goedkoper.
Hoe vaak moet ik mijn model opnieuw afstellen?
Voer een nieuwe fine-tuning uit wanneer de basismodellen aanzienlijk verbeteren of wanneer de prestaties verslechteren bij nieuwe datapatronen. Veel teams slaan de fine-tuning helemaal over bij moderne modellen met een grote context, en werken in plaats daarvan de prompts bij wanneer ze overschakelen naar nieuwere basismodellen. Evalueer of de voordelen van fine-tuning blijven bestaan naarmate de contextvensters groter worden en de mogelijkheden van de basismodellen verbeteren.
Wat is het verschil tussen fine-tuningkosten en inferentiekosten?
Finetuning is een eenmalige trainingskost om het model aan te passen. Inferentiekosten verwijzen naar de doorlopende kosten telkens wanneer het model voorspellingen genereert. Zelfgehoste modellen verschuiven de inferentiekosten naar vaste infrastructuur, terwijl API-gebaseerde modellen kosten in rekening brengen per verwerkt token. Houd rekening met beide bij het berekenen van de totale eigendomskosten.
Heb ik meerdere GPU's nodig om LLM's nauwkeurig af te stellen?
Niet geschikt voor modellen met minder dan 13 miljard parameters bij gebruik van LoRA en kwantisatie. Een enkele consumenten-GPU (RTX 3060 12GB of beter) kan modellen met 7-8 miljard parameters aan met PEFT-technieken. Volledige finetuning van grotere modellen of training met meer dan 13 miljard parameters vereist doorgaans multi-GPU-configuraties, tenzij extreme kwantisatie acceptabel is.
Hoe schat ik de kosten voor het finetunen in voordat ik begin?
Bepaal de modelgrootte, kies de trainingstechniek (volledig of LoRA), schat de trainingsduur op basis van de datasetgrootte en bereken het benodigde aantal GPU-uren. Vermenigvuldig het aantal GPU-uren met de tarieven van de cloudprovider. Voeg 30-401 TP3T buffer toe voor experimenten. Begin met kleine proefruns om de schattingen te valideren voordat u zich vastlegt op het volledige trainingsbudget.
De beslissing nemen om de fijnafstelling te perfectioneren
De kosten voor het finetunen kunnen twee ordes van grootte verschillen, afhankelijk van de keuzes die vooraf worden gemaakt.
Succesvolle teams beginnen met de vraag of fine-tuning nodig is. Grotere contextvensters en betere basismodellen lossen problemen op die slechts enkele maanden geleden nog fine-tuning vereisten. Wanneer fine-tuning noodzakelijk blijkt, maken parameter-efficiënte technieken zoals LoRA aangepaste modellen toegankelijk voor budgetten onder de $100 voor de meeste toepassingen.
De kostbare mislukkingen vertonen gemeenschappelijke patronen: het overslaan van datakwaliteitsvalidatie, het kiezen van te grote modellen en het uitvoeren van volledige fine-tuning terwijl LoRA voldoende zou zijn.
Eerlijk gezegd: reserveer budget voor experimenten. De eerste trainingssessie levert zelden resultaten op die direct geschikt zijn voor productie. Plan 3-5 iteraties in, houd de kosten nauwlettend in de gaten en optimaliseer agressief.
Klaar om binnen budget te beginnen met finetunen? Begin met het kleinst mogelijke model, gebruik standaard LoRA en valideer de datakwaliteit voordat je investeert in rekenkracht. Je eerste succesvolle finetuning leert je meer dan welke handleiding ook.