Korte samenvatting: Het trainen van een LLM (Large-Library Model) vanaf nul kost tussen de 1 TP4 TB 78 miljoen en 1 TP4 TB 192 miljoen voor geavanceerde modellen zoals GPT-4 en Gemini Ultra 1.0, vanwege de enorme GPU-clusters, elektriciteit, data-acquisitie en de benodigde technische expertise. Kleinere modellen kunnen getraind worden voor 1 TP4 TB 50.000 tot 1 TP4 TB 500.000 met behulp van cloudinfrastructuur of voor minder dan 1 TP4 TB met efficiënte optimalisatietechnieken, maar organisaties worden geconfronteerd met doorlopende kosten voor inferentie, opslag en onderhoud die vaak hoger liggen dan de trainingskosten.
Grote taalmodellen hebben onze interactie met technologie ingrijpend veranderd. Maar wat de meeste mensen zich niet realiseren, is dat het creëren van deze modellen astronomisch duur is.
Volgens het Stanford AI Index Report 2025 zijn de trainingskosten voor geavanceerde modellen dramatisch gestegen. De training van GPT-4 kostte ergens tussen de $78 miljoen en $100 miljoen. De trainingskosten voor Gemini Ultra worden geschat op ongeveer $191 miljoen, aldus het Stanford AI Index Report 2024. Deze bedragen vertegenwoordigen een stijging van 287.000 keer ten opzichte van de kosten voor het trainen van een Transformer-model in 2017, die slechts $670 bedroegen.
Waar komen deze enorme kosten vandaan? En, nog belangrijker, wat kost het nu eigenlijk als je overweegt om je eigen model helemaal vanaf nul te trainen?
De werkelijke kosten van een LLM-opleiding ontrafeld
Het trainen van een groot taalmodel vanaf nul is niet alleen duur, maar ook een veelzijdige financiële investering die hardware, energie, data en menselijk kapitaal omvat.
Computerinfrastructuur: de grootste kostenpost
De rekenkosten domineren alles. Krachtige GPU's zoals de NVIDIA H100 kunnen $30.000 per stuk kosten. Maar dat is nog maar het begin.
Ter context: het trainen van geavanceerde modellen vereist duizenden GPU's die weken of maandenlang continu draaien. Onderzoek van arXiv naar de economische aspecten van GPU's toonde aan dat een A800 80G GPU een basiskostprijs heeft van ongeveer $0,79 per uur, met typische prijzen tussen $0,51 en $0,99 per uur, afhankelijk van de configuratie en de prijsstelling van het cloudplatform.
OpenAI heeft naar verluidt meer dan 1,4 biljoen dollar uitgegeven aan het trainen van GPT-4, waarvan een aanzienlijk deel is besteed aan cloudcomputingkosten. De omvang is moeilijk te bevatten.
| Model | Geschatte trainingskosten | Bron |
|---|---|---|
| GPT-4 | $78M-$100M+ | Wall Street Journal, Stanford AI Index 2025 |
| Gemini Ultra 1.0 | $191M | Stanford AI Index Rapport 2024 |
| GPT-4o | ~$100M | Schattingen van de sector |
| Transformer (2017) | $670 | Stanford AI Index Rapport 2025 |
Energieverbruik en milieukosten
Het continu laten draaien van duizenden GPU's verbruikt enorme hoeveelheden elektriciteit. Onderzoek gepubliceerd in de Springer-studie uit 2025 over energie-efficiëntie in grote taalmodellen laat zien dat de dynamiek van het energieverbruik rechtstreeks samenhangt met de modelgrootte en de batchconfiguratie.
De milieu-impact reikt verder dan alleen de trainingsfase. Naarmate de rekenkracht toeneemt, groeit ook de bezorgdheid over duurzaamheid en de CO2-uitstoot.
Gegevensverzameling en -voorbereiding
Een aspect dat onvoldoende aandacht krijgt, is de menselijke arbeid die nodig is voor het trainen van data. Deze arbeid wordt aanzienlijk ondergewaardeerd. In een position paper, gepubliceerd op Hugging Face in april 2025, wordt betoogd dat de productiekosten van data gelijk zouden moeten zijn aan, of zelfs hoger zouden moeten liggen dan, de rekenkosten van de training.
Kwalitatief hoogwaardige datasets ontstaan niet zomaar uit het niets. Ze vereisen:
- Kosten voor gegevensverzameling en licenties
- Handmatige reiniging en annotatie
- Naleving van auteursrecht en juridische toetsing
- Doorlopende updates en onderhoud
Het artikel beargumenteert overtuigend dat trainingsdata het duurste – en meest onderbetaalde – onderdeel van de ontwikkeling van LLM-modellen vormen.
Technisch talent en operationele overheadkosten
Het opbouwen van een LLM-programma vereist specialistische expertise. Machine learning-engineers, datawetenschappers, infrastructuurspecialisten en onderzoekswetenschappers zijn niet goedkoop. Salarissen voor deze functies variëren doorgaans van 150.000 tot meer dan 500.000 euro per jaar in grote technologiecentra.
Naast salarissen zijn er operationele overheadkosten: projectmanagement, het bijhouden van experimenten, modelversiebeheer, beveiliging en de infrastructuur voor naleving van regelgeving.
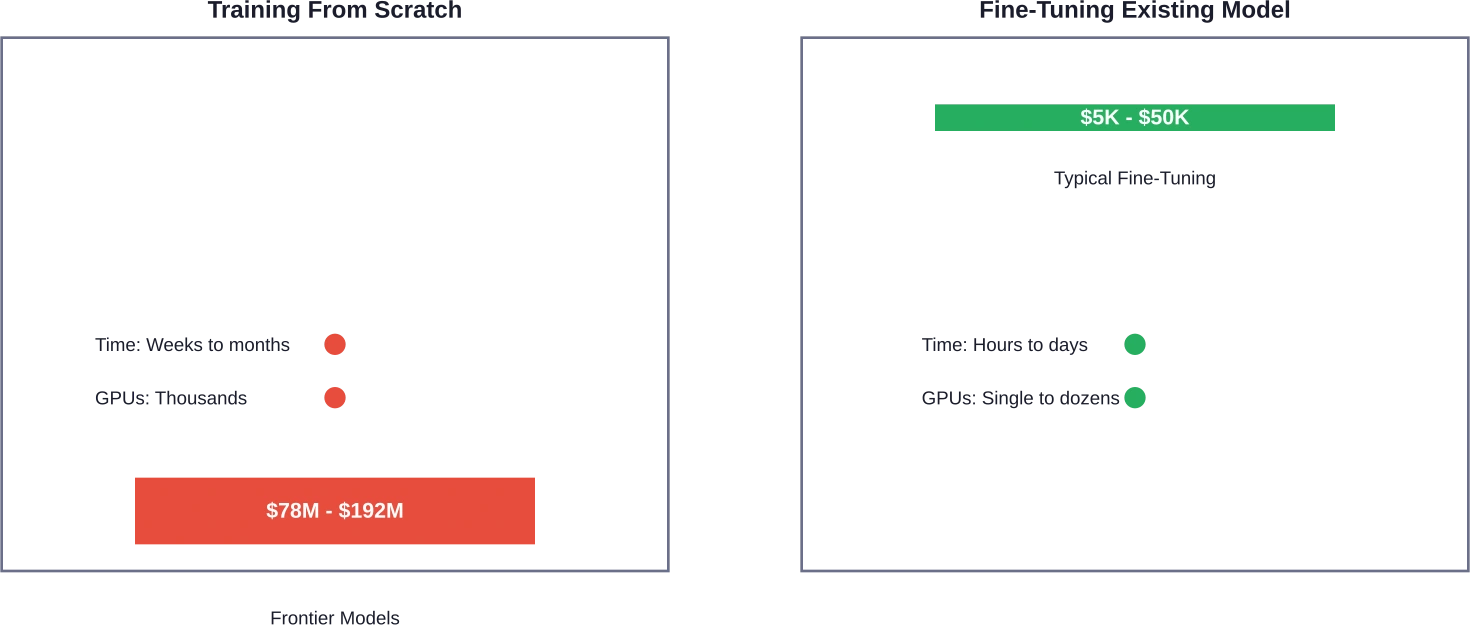
Van nul af aan trainen versus finetunen: een kostenvergelijking
Niet iedereen hoeft GPT-5 te bouwen. De keuze tussen helemaal vanaf nul trainen en een bestaand model verfijnen kan organisaties 60 tot 90 biljoen dollar besparen op hun AI-budget.
Wanneer het zinvol is om vanaf nul te beginnen met trainen
Een volledige voorbereiding vanaf nul is doorgaans zinvol wanneer:
- Uw vakgebied vereist fundamenteel andere taalpatronen dan algemene modellen.
- Privacyregelgeving verbiedt het gebruik van commerciële modellen.
- Je hebt volledige controle nodig over de architectuur en het gedrag van het model.
- Uw organisatie beschikt over het budget en de expertise om de ontwikkeling van een langetermijnmodel te ondersteunen.
Het alternatief voor fijnafstelling
Finetuning neemt een voorgegetraind model en past het aan specifieke taken of domeinen aan. Het kostenverschil is aanzienlijk. Terwijl het trainen van GPT-4 vanaf nul bijna 100 miljoen kostte, kan het finetunen ervan voor gespecialiseerde toepassingen 15.000 tot 50.000 kosten.
Onderzoek van de Universidad Nacional de Colombia heeft aangetoond dat efficiënte fine-tuningstrategieën mogelijk zijn met behulp van LoRA (Low-Rank Adaptation). Uit hun experimenten bleek dat een basismodel, gekwantiseerd op 8 bits, in ongeveer 7 uur kon worden gefinetuned op een enkele NVIDIA T4 GPU met 16 GB VRAM – hardware die op grote cloudplatformen ongeveer 1 TP4T2-4 per uur kost.
Budgetvriendelijke training: Kan het voor minder dan 1.100.000 euro?
Het antwoord is ja, maar wel met aanzienlijke compromissen wat betreft modelgrootte en mogelijkheden.
Een arXiv-artikel getiteld "FLM-101B: An Open LLM and How to Train It with $100K Budget" toonde aan dat kleinschalige LLM-opleidingen haalbaar zijn met zorgvuldig resourcebeheer. De belangrijkste strategieën zijn:
- Het gebruik van kleinere modelarchitecturen (1-20 miljard parameters in plaats van meer dan 175 miljard)
- Gebruikmaken van open-source frameworks en bestaande codebases
- Het optimaliseren van trainingsruns met efficiënte hyperparameterselectie.
- Gebruikmakend van trainings- en kwantiseringstechnieken met gemengde precisie
Onderzoek van het Fraunhofer Instituut vergeleek drie optimalisatiealgoritmen – AdamW, Lion en een derde variant – voor het voorbereiden van lineaire lineaire modellen (LLM's) met een beperkt budget. Hun experimenten maakten gebruik van twee clusterknooppunten met meerdere GPU's en toonden aan dat de keuze van het optimalisatiealgoritme een aanzienlijke invloed heeft op zowel de trainingstijd als de uiteindelijke modelprestaties.
Het alternatief met open gewicht
De release van gpt-oss-120b en gpt-oss-20b door OpenAI in augustus 2025 veranderde de spelregels. Deze open-weight modellen, uitgebracht onder de Apache 2.0-licentie, leveren sterke prestaties in de praktijk tegen aanzienlijk lagere kosten dan training vanaf nul.
Organisaties kunnen deze modellen nu downloaden en aanpassen aan specifieke gebruikssituaties, waardoor de enorme initiële trainingskosten volledig worden omzeild.
Cloud versus on-premise: wat is op de lange termijn goedkoper?
Onderzoekers van Carnegie Mellon publiceerden een kosten-batenanalyse waarin werd onderzocht wanneer een on-premise LLM-implementatie evenveel voordeel oplevert als commerciële clouddiensten. Hun bevindingen zetten de gangbare opvattingen op de proef.
Kosten van cloudinfrastructuur
Cloudplatforms bieden flexibiliteit, maar rekenen hoge tarieven voor GPU-tijd. Grote aanbieders rekenen doorgaans:
- $2-8 per uur voor krachtige GPU-instanties
- Kosten voor gegevensoverdracht (vaak over het hoofd gezien, maar aanzienlijk bij grote schaal)
- Opslagkosten voor modelcontrolepunten en trainingsgegevens
- API-aanroepkosten bij gebruik van beheerde services
Het voordeel? Geen investeringskosten vooraf en de mogelijkheid om naar behoefte op te schalen.
Investeringen in infrastructuur op locatie
De aanschaf van hardware vereist een aanzienlijk kapitaal, maar elimineert terugkerende cloudkosten. Een cluster van NVIDIA H100 GPU's kan 1.500.000 tot 1.400.200.000 euro kosten, maar die investering wordt over 3-5 jaar afgeschreven.
Uit de analyse van Carnegie Mellon bleek dat organisaties met aanhoudende, voorspelbare AI-workloads vaak binnen 12-18 maanden de kosten terugverdienen wanneer ze kiezen voor een on-premise implementatie in plaats van cloudservices.
Maar er is een addertje onder het gras: infrastructuur op locatie vereist speciaal personeel voor onderhoud, koelsystemen, stroomvoorziening en beveiliging – kosten die in veel budgetanalyses over het hoofd worden gezien.
Waardoor stijgen de kosten van een LLM-opleiding?
Verschillende factoren bepalen of uw opleidingsbudget dichter bij $50.000 of $50 miljoen uitkomt.
Modelgrootte en architectuur
De relatie tussen parameters en kosten is niet lineair, maar exponentieel. Het verdubbelen van de modelgrootte leidt tot meer dan een verdubbeling van de trainingskosten, vanwege:
- Toegenomen geheugenvereisten dwingen tot parallel gebruik van meerdere GPU's.
- Langere trainingstijden naarmate de convergentie vertraagt met de schaalvergroting.
- Grotere datavereisten voor het correct trainen van grotere architecturen.
Trainingsduur en convergentie
Trainingsruns die niet convergeren, verspillen enorme hoeveelheden resources. Efficiënte hyperparameter-tuning kan een dramatisch effect hebben op hoe snel een model leert. Een goed afgestelde trainingsrun kan de gewenste nauwkeurigheid in de helft van de tijd bereiken in vergelijking met een slecht geconfigureerde run.
Hier komt expertise echt van pas. Ingenieurs die verstand hebben van leersnelheidsschema's, batchgrootteoptimalisatie en regularisatietechnieken besparen organisaties miljoenen aan verspilde rekenkracht.
Kwaliteit en kwantiteit van de gegevens
Trainen met data van lage kwaliteit leidt tot modellen van lage kwaliteit, maar het verkrijgen van data van hoge kwaliteit kost geld. Sommige organisaties besteden meer aan databeheer dan aan computerinfrastructuur.
De groeiende consensus, zoals verwoord in het position paper van Hugging Face over de economische aspecten van trainingsdata, is dat data de duurste component van LLM-ontwikkeling zou moeten zijn. Momenteel wordt de waarde ervan onderschat.
Verborgen kosten die verder gaan dan de trainingskosten
Hier gaat het vaak mis met budgetramingen: opleidingskosten zijn nog maar het begin.
Inferentie-infrastructuur
Het WiNGPT-team introduceerde een raamwerk voor de "economie van inferentie" dat LLM-inferentie beschouwt als een computergestuurde productieactiviteit. Uit hun analyse bleek dat de inferentiekosten gedurende de operationele levensduur van het model vaak hoger uitvallen dan de trainingskosten.
Elke query die naar uw model wordt gestuurd, verbruikt rekenkracht. Op grote schaal kunnen de kosten van inferentie-infrastructuur oplopen tot honderdduizenden euro's per maand.
Modelupdates en hertraining
Taal evolueert. Feitelijke informatie verandert. Bedrijfseisen verschuiven. Modellen die in 2024 zijn getraind, zijn in 2026 verouderd.
Periodieke omscholing of continue leertrajecten vertegenwoordigen doorlopende kosten die veel organisaties tijdens de initiële planning onderschatten.
Opslag en gegevensbeheer
Modelcontrolepunten, trainingsdatasets, experimentlogboeken en versiebeheersystemen verbruiken allemaal opslagruimte. Voor grensverleggende modellen hebben we het over petabytes aan data. Opslagkosten lopen ongemerkt maar aanzienlijk op.
Monitoring en onderhoud
Machine learning-systemen in productie vereisen constante monitoring op de volgende punten:
- Prestatievermindering
- Opsporing en beperking van vooringenomenheid
- Beveiligingslekken
- API-betrouwbaarheid en beschikbaarheid
Deze operationele kosten blijven bestaan zolang het model in productie blijft.
| Kostencategorie | Eenmalig | Terugkerend | Typisch bereik |
|---|---|---|---|
| Initiële training | ✓ | $50K – $192M | |
| Inferentie-infrastructuur | ✓ | $10K – $500K/maand | |
| Model omscholing | ✓ | 20-50% aan initiële kosten/jaar | |
| Opslag | ✓ | $5K – $50K/maand | |
| Ingenieursteam | ✓ | $500K – $5M/jaar | |
| Gegevensverwerving | ✓ | ✓ | $100K – $10M+ |
Strategieën om de kosten van een LLM-opleiding te verlagen
Slimme organisaties gebruiken meerdere tactieken om de kosten onder controle te houden zonder dat dit ten koste gaat van de prestaties van hun modellen.
Transferleren en progressieve training
Begin in plaats van helemaal vanaf nul te trainen met een bestaand open-gewichtmodel en pas dit geleidelijk aan. Deze aanpak, gedocumenteerd in onderzoek van de Universidad Nacional de Colombia, verkort de trainingstijd met 80-90%.
Efficiënte optimalisatietechnieken
Uit onderzoek van het Fraunhofer Instituut, waarin AdamW, Lion en alternatieve optimalisatiealgoritmen werden vergeleken, bleek dat de keuze van het optimalisatiealgoritme een aanzienlijke invloed heeft op zowel de trainingssnelheid als het resourceverbruik. Door het juiste optimalisatiealgoritme voor uw specifieke toepassing te kiezen, kunt u 20 tot 301 TP3T besparen op de trainingskosten.
Kwantisatie en compressie
Trainen met gemengde precisie (een combinatie van 16-bits en 32-bits drijvende-komma-bewerkingen) vermindert het geheugenverbruik en versnelt de berekeningen. Kwantisering na de training naar 8-bits of zelfs 4-bits representaties verkleint de modelgrootte voor implementatie zonder catastrofaal prestatieverlies.
De experimenten van de Universidad Nacional de Colombia toonden aan dat LoRA-training succesvol was op modellen die gekwantiseerd waren tot 8 bits, waarbij voorgekwantiseerde 4-bits modellen acceptabele prestaties lieten zien op consumentenhardware.
Slimme toewijzing van middelen
Door computerbronnen efficiënt te gebruiken en te beheren, voorkomt u dat u betaalt voor inactieve tijd. Strategieën omvatten:
- Spot instance bidding op cloudplatformen voor niet-kritieke trainingssessies
- Pijplijnparallellisatie om het GPU-gebruik te maximaliseren.
- Gradiëntaccumulatie om grotere batchgroottes te simuleren op hardware met beperkte mogelijkheden.
- Mogelijkheid tot herstarten via checkpoint om te herstellen van onderbrekingen.
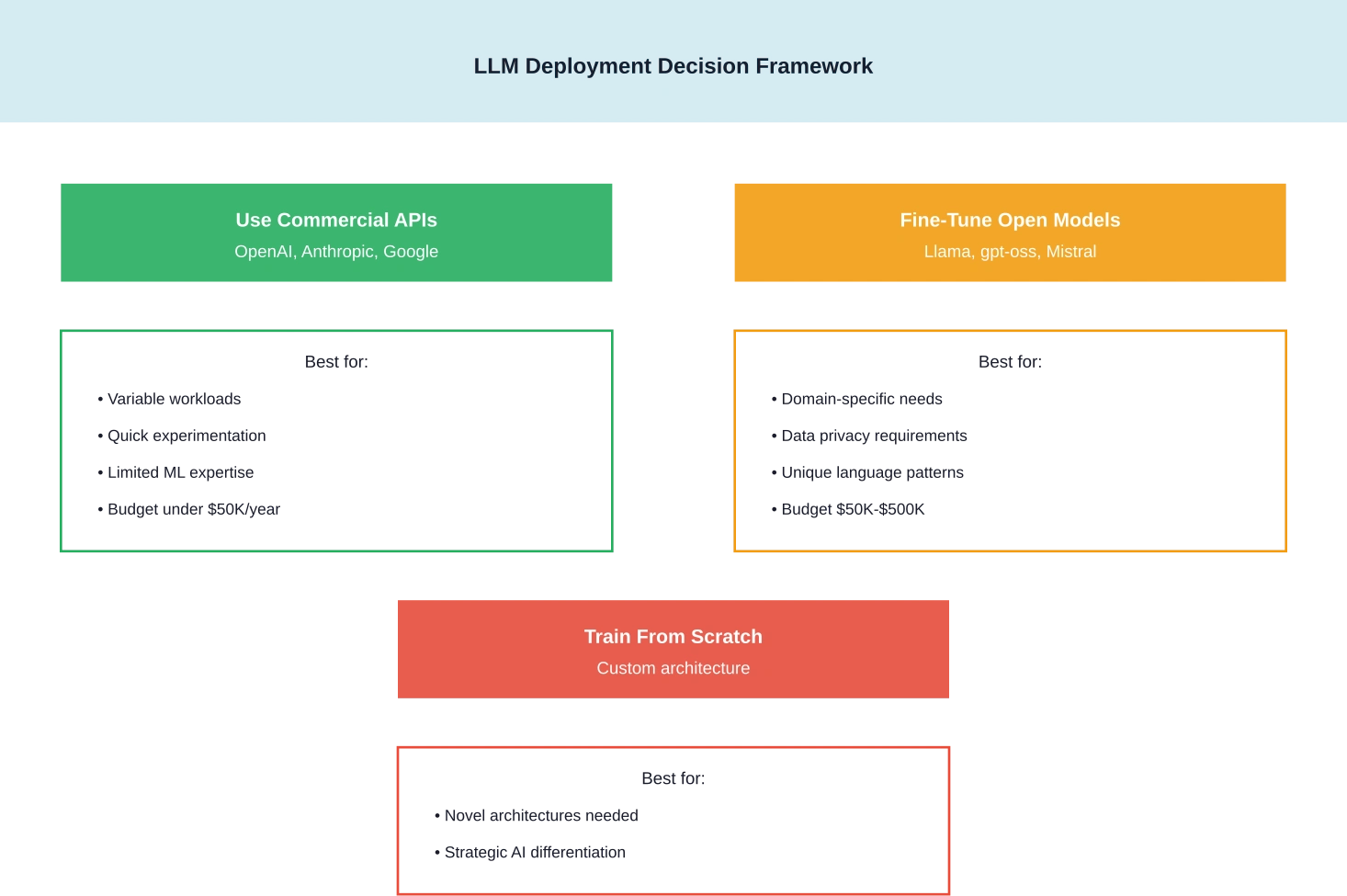
Moet je in 2026 je eigen LLM-opleiding volgen?
Het besluitvormingskader is drastisch veranderd door de opkomst van krachtige open-weight modellen.
Voor de meeste organisaties is het antwoord nee, althans niet vanaf nul. De gpt-oss-modellen van OpenAI, de Llama 3-serie van Meta en andere open-source alternatieven bieden prestaties die tientallen miljoenen zouden kosten om te repliceren.
Maar het verfijnen van bestaande modellen? Dat is een ander verhaal. Organisaties met unieke domeinvereisten, specifieke compliance-eisen of eigen data hebben er vaak baat bij om bestaande modellen te verfijnen in plaats van uitsluitend te vertrouwen op algemene commerciële API's.
Wanneer training op locatie zinvol is
De kosten-batenanalyse van Carnegie Mellon heeft specifieke scenario's geïdentificeerd waarin de implementatie en training van LLM op locatie economisch haalbaar blijken:
- Aanhoudende werkbelastingen van meer dan 10.000 GPU-uren per jaar.
- Strikte eisen ten aanzien van de opslag van gegevens, waardoor het gebruik van de cloud wordt verboden.
- Strategische AI-initiatieven voor de lange termijn, met een looptijd van 3 jaar of langer.
- Beschikbaarheid van interne expertise op het gebied van machine learning-infrastructuur
Wanneer cloudservices winnen
Voor experimentele projecten, variabele werklasten of organisaties zonder expertise op het gebied van machine learning-infrastructuur bieden cloudoplossingen en API-services een betere prijs-kwaliteitverhouding. De flexibiliteit om af te schalen – of volledig uit te schakelen – elimineert het risico van ongebruikt kapitaal.

Verlaag de kosten van je LLM-opleiding voordat je begint.
Het helemaal vanaf nul trainen van een LLM is duur, niet alleen vanwege de rekenkracht, maar ook vanwege de voorbereiding van de data, de keuzes in modelarchitectuur en de trainingsstrategie. AI Superieur Het bedrijf werkt aan deze technische laag en helpt bedrijven bij het ontwerpen van aangepaste LLM's, het voorbereiden van trainingsdatasets en het optimaliseren van trainingspipelines, zodat modellen vanaf het begin efficiënt worden opgebouwd.
Als u de werkelijke kosten van een LLM-opleiding in 2026 wilt inschatten, is het verstandig om de technische infrastructuur te bekijken voordat u grote budgetten voor computergebruik vastlegt. Neem contact op. AI Superieur Om uw trainingsarchitectuur te evalueren en te bepalen waar kosten kunnen worden bespaard, nog voordat het trainingsproces begint.
De toekomst van de LLM-opleiding Economie
Verschillende trends veranderen het kostenlandschap.
De door OpenAI in februari 2026 uitgebrachte GPT-5.3-Codex (aangekondigd op 5 februari 2026) toonde een 25% hogere efficiëntie dan zijn voorganger. Naarmate modelarchitecturen verbeteren, neemt de benodigde rekenkracht voor vergelijkbare prestaties af.
Ook op het gebied van hardware blijven de ontwikkelingen zich voortzetten. De opeenvolgende GPU-generaties van NVIDIA leveren aanzienlijke verbeteringen in prestaties per watt, waardoor zowel de investerings- als de operationele kosten dalen.
Maar misschien wel het belangrijkste is dat de democratisering van de toegang via open-weight modellen fundamenteel verandert wie kan deelnemen aan de ontwikkeling van LLM-programma's. Wat in 2023 100 miljoen dollar aan financiering vereiste voor 100 miljoen dollar aan financiering voor 4 miljard ton, zou in 2026 haalbaar kunnen zijn voor 100.000 dollar aan financiering voor 4 miljard ton door slim gebruik te maken van transfer learning en efficiënte trainingstechnieken.
Veelgestelde vragen
Hoeveel kost het om GPT-4 vanaf nul te trainen?
Volgens het Stanford AI Index Report 2024 en berichtgeving van The Wall Street Journal bedragen de trainingskosten van GPT-4 tussen de $78 miljoen en $100 miljoen. Dit omvat de kosten voor computerinfrastructuur, energie, dataverzameling en technische middelen gedurende de trainingsperiode. De trainingskosten van Gemini Ultra worden geschat op ongeveer $191 miljoen, eveneens volgens het Stanford AI Index Report 2024.
Kun je een LLM-opleiding volgen voor minder dan $100.000?
Ja, maar met aanzienlijke beperkingen qua modelgrootte en -mogelijkheden. Onderzoek gedocumenteerd in het FLM-101B-artikel toonde aan dat het trainen van kleinere modellen (1-20 miljard parameters) binnen een budget van $100.000 mogelijk is door gebruik te maken van efficiënte architecturen, geoptimaliseerde trainingsprocedures en zorgvuldig resourcebeheer. Het finetunen van bestaande open-weight modellen is voor de meeste toepassingen veel kosteneffectiever.
Wat is goedkoper: een LLM-opleiding in de cloud of op locatie?
Het hangt af van het gebruikspatroon. Onderzoek van Carnegie Mellon toonde aan dat on-premise implementaties doorgaans binnen 12-18 maanden de kosten van de cloud terugverdienen voor organisaties met een constante, voorspelbare werkbelasting van meer dan 10.000 GPU-uren per jaar. Cloudservices blijken kosteneffectiever te zijn voor variabele werkbelastingen, experimentele projecten of organisaties die niet over de nodige infrastructuurexpertise beschikken.
Hoeveel kost LLM-inferentie in vergelijking met training?
Onderzoek van het WiNGPT-team wijst uit dat de inferentiekosten gedurende de operationele levensduur van een model vaak hoger uitvallen dan de trainingskosten. Training is een eenmalige uitgave (met periodieke hertraining), terwijl inferentie continu plaatsvindt zolang het model gebruikers bedient. Applicaties met veel verkeer kunnen maandelijks honderdduizenden euro's aan inferentiekosten met zich meebrengen.
Is finetuning goedkoper dan helemaal opnieuw trainen?
Aanzienlijk goedkoper. Fine-tuning kan 60 tot 90 biljoen TP3T minder kosten dan training vanaf nul. Terwijl geavanceerde modellen zoals GPT-4 78 tot 100 miljoen TP4T kosten om te trainen, kost het fine-tunen van diezelfde modellen voor specifieke toepassingen doorgaans 5.000 tot 50.000 TP4T. Onderzoek van de Universidad Nacional de Colombia toonde aan dat effectieve fine-tuning in slechts 7 uur mogelijk is op een enkele NVIDIA T4 GPU.
Welke GPU is het meest geschikt voor een budgetvriendelijke LLM-opleiding?
Voor budgetvriendelijke trainingen bieden NVIDIA T4 GPU's (16 GB VRAM) een redelijk instapniveau met 1 TP4T2-4 per uur op cloudplatformen. Voor serieuzere projecten bieden A100- of H100-GPU's betere prestaties per dollar, ondanks hogere uurtarieven. De A800 80G heeft basiskosten van ongeveer 1 TP4T0,79 per uur volgens onderzoek van arXiv naar de economie van GPU's.
Hoe beïnvloeden open-weight modellen zoals gpt-oss de economie?
De release van gpt-oss-120b en gpt-oss-20b door OpenAI in maart 2026 onder de Apache 2.0-licentie verandert de kostenstructuur fundamenteel. Organisaties kunnen nu state-of-the-art modellen downloaden en deze verfijnen voor specifieke behoeften, waardoor ze de tientallen miljoenen kostende training van een volledig nieuwe module kunnen omzeilen. Dit democratiseert de toegang tot geavanceerde modelmogelijkheden voor organisaties met een bescheiden budget.
De trainingsbeslissing nemen
Het van nul af aan opleiden van een LLM-specialist is een enorme financiële investering die alleen zinvol is voor organisaties met unieke behoeften, aanzienlijke budgetten en langetermijnstrategische AI-initiatieven.
Voor de overgrote meerderheid van de toepassingen levert het finetunen van open-weight modellen 80-90% aan waarde op tegen 5-10% aan kosten. De toename van hoogwaardige open modellen van OpenAI, Meta, Mistral en anderen heeft de ontwikkeling van aangepaste LLM-modellen toegankelijk gemaakt voor organisaties die dit drie jaar geleden nog niet hadden kunnen overwegen.
De echte vraag is niet of je het je kunt veroorloven om helemaal vanaf nul te beginnen met trainen, maar of je het je kunt veroorloven om geen gebruik te maken van de miljarden dollars die al zijn geïnvesteerd in basismodellen voor gewichtheffen.
Bent u klaar om de implementatie van LLM voor uw organisatie te onderzoeken? Begin met het evalueren van bestaande open-weight modellen aan de hand van uw specifieke vereisten. Bereken uw verwachte inferentiekosten met behulp van tools zoals de beschikbare tools voor het berekenen van de trainingskosten van LLM. En het allerbelangrijkste: begin met kleinschalige finetuning-experimenten voordat u grotere investeringen in infrastructuur doet.