Korte samenvatting: Het trainen van een groot taalmodel kost tussen de 1 TP4 TB 50.000 en meer dan 1 TP4 TB 500 miljoen, afhankelijk van de modelgrootte, de infrastructuur en de trainingsduur. Kleinere modellen met 20 miljard parameters kosten mogelijk 1 TP4 TB 50.000 tot 1 TP4 TB 100.000, terwijl gigantische systemen zoals GPT-4 of Gemini meer dan 1 TP4 TB 100 miljoen kunnen kosten. De grootste kostenposten zijn de rekentijd van de GPU, de voorbereiding van de data en de cloudinfrastructuur.
De economische aspecten van het trainen van grote taalmodellen zijn een bepalende factor geworden in de ontwikkeling van AI. Organisaties staan nu voor cruciale beslissingen: zelf modellen bouwen of gebruikmaken van commerciële diensten.
En de cijfers? Die zijn verbijsterend.
Volgens onderzoek van Epoch AI hebben zowel GPT-4 als Google's Gemini honderden miljoenen dollars gekost om te trainen. Dit zijn niet zomaar kleine verbeteringen ten opzichte van eerdere modellen; de financiële drempel is de afgelopen jaren enorm gestegen.
Maar er is iets belangrijks om te weten: niet elke organisatie heeft een grensverleggend model nodig. Inzicht in de kostenstructuur helpt bij het bepalen van de juiste aanpak voor specifieke toepassingen.
Wat drijft de trainingskosten voor grote taalmodellen?
De kosten voor een opleiding zijn onderverdeeld in verschillende hoofdcategorieën, die elk een aanzienlijk deel van het totaalbedrag uitmaken.
Computerinfrastructuur
GPU-hardware is het grootste kostenpost. Modellen met zo'n 100 miljard parameters vereisen geavanceerde GPU-hardware, zoals de A100 GPU's van NVIDIA. Voor een model met 20 miljard parameters heeft de infrastructuur doorgaans 8 tot 16 A100 80GB GPU's nodig.
De rekenkosten alleen al bedragen $50.000-$100.000 voor een kleiner model. Die basisberekening – ongeveer $22.000 (16 A100's × $2,75/uur × 500 uur) – vertegenwoordigt slechts de succesvolle trainingsrun.
Maar wacht even.
Mislukte runs en experimenten verdubbelen of verdrievoudigen dat aantal gemakkelijk. Het trainen van grote taalmodellen is geen eenmalig proces. Hyperparameteroptimalisatie, architectuurexperimenten en het oplossen van problemen kosten allemaal extra rekentijd.
Tijd en duur
De trainingsduur is afhankelijk van de grootte en complexiteit van het model. Een model met 20 miljard parameters kan 500 tot 1000 uur trainen. Grotere modellen met meer dan 120 miljard parameters kunnen duizenden GPU-uren in beslag nemen.
De kosten voor cloudinfrastructuur lopen elk uur op. Dit betekent dat elke optimalisatie die de trainingstijd verkort, direct tot kostenbesparingen leidt. Efficiënte hyperparameterselectie, een beter ontwerp van de datapipeline en minder ongebruikte GPU-tijd zijn financieel gezien allemaal van belang.
Gegevensvoorbereiding en -beheer
Hoogwaardige trainingsdata ontstaan niet zomaar. Organisaties investeren fors in het verzamelen, opschonen, labelen en beheren van data. De geleidelijke afname van hoogwaardige, publiekelijk beschikbare data heeft deze uitdaging nog nijpender gemaakt.
Ook de kosten voor dataopslag en -overdracht lopen op. Het verplaatsen van enorme datasets tussen opslagsystemen en computerclusters brengt bandbreedte- en opslagkosten met zich mee die in veel initiële budgetten worden onderschat.

Begrijp de werkelijke kosten van een LLM-opleiding.
Het trainen van een groot taalmodel vereist veel meer dan alleen rekenkracht. Data-engineering, model-experimenten, evaluatie en de implementatie-infrastructuur hebben ook invloed op de totale kosten.
AI Superieur Het helpt organisaties te beoordelen of het trainen van een model vanaf nul gerechtvaardigd is, of dat alternatieve benaderingen zoals modelaanpassing of API-integratie praktischer zijn.
Hun diensten omvatten:
- ontwerp van het trainingsprogramma
- datasetstrategie en validatie
- infrastructuurplanning
- kosten-batenanalyse van maatwerkmodellen
Als u de mogelijkheden van een op maat gemaakt LLM-programma onderzoekt, kan een haalbaarheidsanalyse helpen om onnodige opleidingskosten te voorkomen.
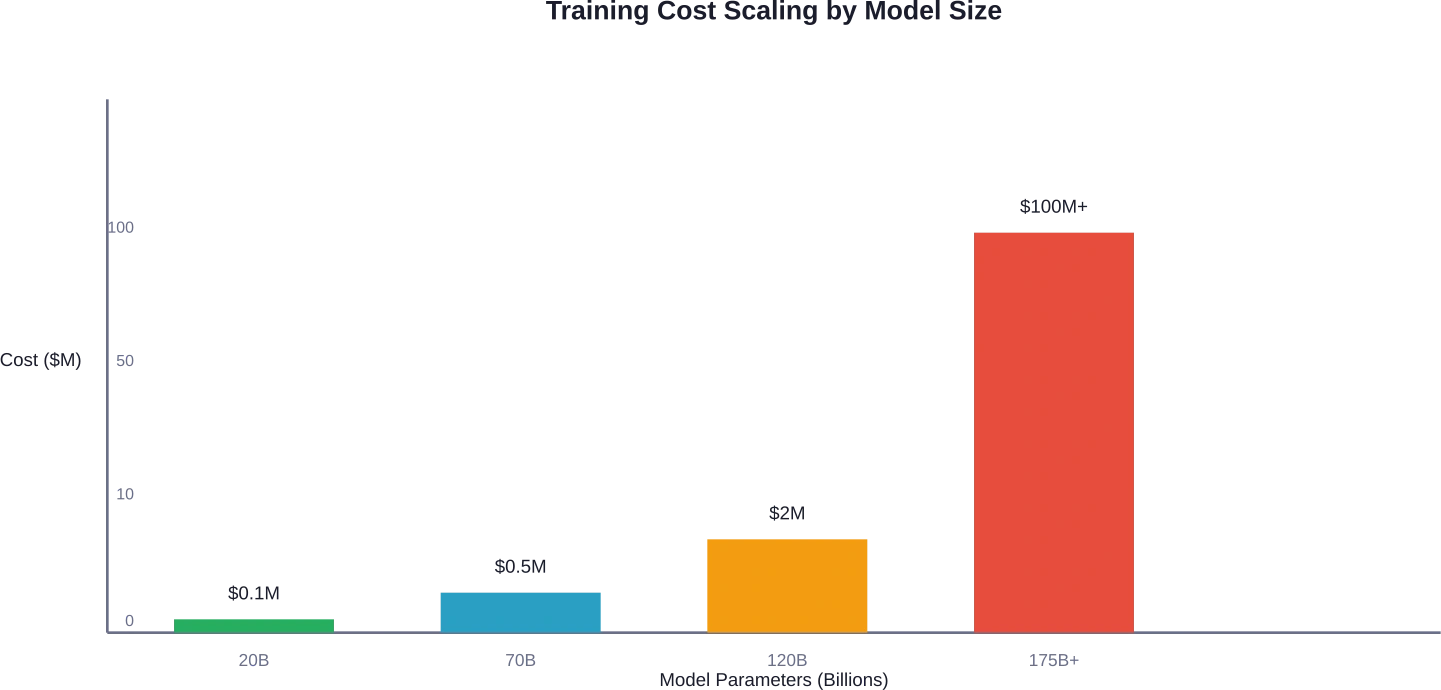
Vergelijking van reële kosten: parameters van 20 miljard tot 120 miljard
Laten we de werkelijke kostenbereiken voor verschillende modelgroottes eens nader bekijken.
| Modelmaat | GPU-vereisten | Basiskosten voor berekening | Totale geschatte kosten |
|---|---|---|---|
| 20B-parameters | 8-16 A100 80GB | $22,000-$50,000 | $50,000-$100,000 |
| 70B-parameters | 32-64 A100 80GB | $100,000-$250,000 | $200,000-$500,000 |
| 120B+ parameters | 64-128+ A100 80GB | $300,000-$800,000 | $500,000-$2,000,000 |
| Frontier-modellen (175B+) | Meer dan 1000 GPU's | $50M-$200M+ | $100M-$500M+ |
Het verschil tussen kleine en grote modellen is niet lineair, maar exponentieel. Een model met 120 miljard parameters kost ongeveer 5 tot 20 keer meer dan een model met 20 miljard parameters, niet alleen vanwege het aantal parameters, maar ook vanwege de complexiteit van de training, langere convergentietijden en de overheadkosten voor de infrastructuur.
Het Frontier-model Premium
Systemen zoals GPT-4 en Gemini opereren in een compleet andere kostencategorie. Volgens gegevens van Epoch AI heeft de ontwikkeling van deze modellen honderden miljoenen dollars gekost.
Waarom zulke astronomische getallen?
Frontier-modellen vereisen enorme GPU-clusters die maandenlang draaien. Ze omvatten uitgebreide experimenten, meerdere trainingssessies, veiligheidstests en afstemmingswerk. Alleen al de infrastructuur – het gelijktijdig beheren van duizenden GPU's – vereist geavanceerde orchestratiesystemen.
Uitsplitsing van infrastructuurkosten
Infrastructuurkosten gaan verder dan alleen de huur van GPU's. Organisaties moeten rekening houden met de complete infrastructuur.
GPU-hardwareopties
De A100 GPU's van NVIDIA blijven de standaard voor LLM-training, hoewel de nieuwere H100- en H200-varianten betere prestaties bieden tegen een hogere prijs. De keuze hangt af van beschikbaarheid, budget en planning.
Cloudproviders hanteren verschillende tarieven. AWS, Google Cloud en Microsoft Azure hebben elk een eigen prijsstructuur voor GPU-instanties. Gespecialiseerde providers die zich richten op AI-workloads bieden soms betere tarieven voor langdurig gebruik.
Opslag en netwerken
Modelcontrolepunten, trainingsgegevens en logbestanden nemen aanzienlijke opslagruimte in beslag. Een model met 120 miljard parameters genereert controlepuntenbestanden van meer dan 500 GB per stuk. Organisaties slaan doorgaans meerdere controlepunten op tijdens de training voor herstel en analyse.
Netwerkbandbreedte is ook belangrijk. Gegevensoverdracht tussen opslag en rekenkracht, met name bij gedistribueerde training over meerdere knooppunten, kan duizenden dollars extra kosten per maand.
Hosting en implementatie
Trainingskosten zijn nog maar het begin. Het hosten van deze modellen voor inferentie brengt doorlopende kosten met zich mee. Voor modellen met ongeveer 100 miljard parameters variëren de hostingkosten van 1 tot 4,50 tot 1 tot 4,500 tot 500 miljoen per jaar, afhankelijk van de modelgrootte en het gebruikspatroon.
De veelgenoemde ontwikkelingskosten voor vereenvoudigde modellen zoals DeepSeek-V3 sluiten mogelijk de kosten uit voor het trainen van krachtigere modellen waaruit ze zijn afgeleid. Dit illustreert hoe boekhoudkundige methoden de totale ontwikkelingsinvesteringen kunnen verhullen.
Optimalisatiestrategieën om de trainingskosten te verlagen
Er zijn verschillende technieken waarmee de trainingskosten drastisch verlaagd kunnen worden zonder dat dit ten koste gaat van de modelkwaliteit.
Kwantisatie en gemengde precisie
FP4-kwantiseringsframeworks voor LLM's hebben aangetoond dat ze een nauwkeurigheid kunnen bereiken die vergelijkbaar is met BF16 en FP8, met minimale kwaliteitsvermindering bij grootschalige modellen. Deze technologie vermindert de geheugenvereisten en versnelt de berekeningen, waardoor de benodigde GPU-tijd direct afneemt.
Training met gemengde precisie is de standaardpraktijk geworden. Door voor bepaalde handelingen een lagere precisie te gebruiken en voor andere taken een hogere precisie aan te houden, wordt een goede balans tussen snelheid en nauwkeurigheid bereikt.
Trainingsmethoden voor lage rangen
Het toepassen van laag-rang parametrisatie op Transformer-gebaseerde LLM's verlaagt de rekenkosten en kan in sommige gevallen zelfs de prestaties verbeteren. Deze methoden comprimeren de parameterruimte met behoud van de expressiviteit van het model.
Efficiënte datastrategieën
Onderzoek naar Chinchilla-optimale schaalwetten wijst uit dat een LLM-ontwikkelaar die een 13B-model traint met een verwachte inferentievraag van 2 biljoen tokens, de totale rekenkracht potentieel met ongeveer 1,7 × 10²² FLOPs (171 TP3T) zou kunnen verminderen door kleinere modellen langer te trainen.
De belangrijkste conclusie? Door iets langer te trainen met meer data kunnen de inferentiekosten later lager uitvallen als het model veel verzoeken moet verwerken. De totale eigendomskosten zijn belangrijker dan alleen de trainingskosten.

Spot-instances en preemptible VM's
Cloudproviders bieden spot-instances met korting aan die onderbroken kunnen worden. Voor fouttolerante trainingsworkflows met regelmatige checkpoints verlagen spot-instances de kosten met 40-70% in vergelijking met on-demand prijzen.
Het nadeel? De training kan langer duren vanwege onderbrekingen. Maar met een goede planning van de controlepunten wegen de besparingen meestal op tegen de complexiteit.
De keuze tussen zelf bouwen en kopen.
Organisaties staan voor een fundamentele keuze: hun eigen model trainen of gebruikmaken van commerciële diensten.
Wanneer commerciële diensten zinvol zijn
Voor de meeste toepassingen is het voordeliger om je te abonneren op commerciële LLM-diensten. API's van OpenAI, Anthropic en Google bieden toegang tot geavanceerde modellen zonder dat je vooraf hoeft te investeren.
Volgens onderzoek naar kosten-batenanalyses hebben organisaties aanzienlijk en langdurig gebruik nodig om quitte te spelen met commerciële diensten. Studies suggereren dat prestatiegelijkheidsdrempels rond de 20% van toonaangevende commerciële modellen een haalbaar break-evenpunt vormen voor investeringen in infrastructuur.
Wanneer training zinvol is
Maatwerktraining wordt aantrekkelijk wanneer:
- Domeinspecifieke vereisten vragen om gespecialiseerde trainingsgegevens.
- Privacyregelgeving verhindert het verzenden van informatie naar API's van derden.
- Het verwachte inferentievolume overstijgt maandelijks miljoenen verzoeken.
- Het verfijnen van commerciële modellen blijkt onvoldoende voor dit specifieke gebruiksscenario.
Organisaties die een intensief en langdurig gebruik gedurende meerdere jaren verwachten, kunnen met zelfgehoste modellen lagere totale eigendomskosten realiseren. Het omslagpunt hangt af van de modelgrootte, het aanvraagvolume en de vereiste prestatieniveaus.
Overwegingen met betrekking tot berekeningen tijdens de test
Recent onderzoek naar de toewijzing van rekenkracht tijdens testfasen onthult een andere kostenfactor. De inferentiekosten kunnen de trainingskosten voor veelgebruikte modellen overstijgen.
Adaptieve toewijzingsstrategieën die dynamisch rekenkracht toewijzen op basis van de moeilijkheidsgraad van de query, verbeteren de efficiëntie aanzienlijk. Moeilijkheidsgraad-indicatoren die niet hoeven te worden getraind, helpen bij het verdelen van vaste rekenbudgetten over testqueries, waardoor het aantal opgeloste instanties wordt gemaximaliseerd met inachtneming van budgetbeperkingen.
Onderzoek naar efficiënte agenten toont aan dat een optimaal frameworkontwerp enorm belangrijk is. Een studie vond een framework dat de prestaties van 96,71 TP3T van een toonaangevende open-source agent behield, terwijl de operationele kosten werden verlaagd van 0,398 naar 0,228 – een verbetering van 28,41 TP3T in de kosten per doorgang.
Boekhoudkundige principes voor de ontwikkelingskosten van AI
Beleidsmakers gebruiken ontwikkelingskosten en rekenkracht steeds vaker als indicatoren voor de mogelijkheden en risico's van AI. Recent ingevoerde wetgeving introduceert regelgevende eisen die afhankelijk zijn van specifieke kostendrempels.
Maar hier zit het probleem: technische onduidelijkheden in de kostenberekening creëren mazen in de wet. Een beperkte boekhouding kan de totale ontwikkelingskosten van een model verhullen. De veel geciteerde ontwikkelingskosten voor vereenvoudigde modellen zoals DeepSeek-V3 sluiten mogelijk de kosten uit van het trainen van krachtigere modellen, waarvan ze zijn afgeleid.
Organisaties dienen een alomvattende boekhouding te hanteren die het volgende omvat:
- Alle trainingsruns, inclusief mislukte experimenten.
- Kosten voor dataverwerving, -opschoning en -voorbereiding
- Infrastructuurkosten en netwerkbeheer
- Engineeringtijd voor architectuurontwikkeling
- Veiligheidstests en uitlijningswerkzaamheden
- Kosten van docentmodellen voor distillatiebenaderingen
| Kostencategorie | Typische % van het totaal | Wordt vaak over het hoofd gezien? |
|---|---|---|
| GPU-berekening (succesvolle uitvoering) | 30-40% | Nee |
| Mislukte experimenten | 15-25% | Ja |
| Data voorbereiding | 10-15% | Ja |
| Opslag en netwerken | 5-10% | Ja |
| Technische arbeidskrachten | 20-30% | Soms |
| Veiligheid en uitlijning | 5-10% | Ja |
Toekomstige kostentrends
Verschillende factoren zullen de opleidingskosten in de komende jaren beïnvloeden.
GPU-hardware blijft zich ontwikkelen. NVIDIA's Blackwell-architectuur – inclusief de B100-, B200- en GB200-varianten – belooft betere prestaties per euro. Maar de vraag houdt de prijzen hoog.
De kosten voor data stijgen. Naarmate hoogwaardige openbare data schaarser worden, investeren organisaties meer in eigen datasets, het genereren van synthetische data en datalicentieovereenkomsten.
Desondanks compenseren verbeteringen in algoritmes en de toename in trainingsefficiëntie de hardwarekosten gedeeltelijk. De onderzoeksgemeenschap ontwikkelt voortdurend betere optimalisatiemethoden, schaalwetten en architectuurontwerpen.
Veelgestelde vragen
Wat zijn de kosten voor het trainen van een model met 70 miljard parameters?
Het trainen van een model met 70 miljard parameters kost doorgaans tussen de $200.000 en $500.000. Dit omvat de basiskosten voor de berekeningen van $100.000 tot $250.000 voor 32-64 A100 GPU's, plus extra kosten voor mislukte runs, experimenten, datavoorbereiding en infrastructuuroverhead.
Kunnen kleinere organisaties het zich veroorloven om grote taalmodellen te trainen?
Kleinere organisaties kunnen modellen van bescheiden omvang (1-20 miljard parameters) trainen voor $10.000-$100.000 met behulp van cloud-GPU-resources en optimalisatietechnieken. Voor de meeste toepassingen is het echter kosteneffectiever om commerciële API-services te gebruiken of bestaande open-source modellen te verfijnen dan om helemaal opnieuw te trainen.
Wat is het duurste onderdeel van een LLM-opleiding?
GPU-rekentijd vertegenwoordigt 30-401 TP3T van de totale kosten voor de meeste projecten. Echter, wanneer mislukte experimenten en hyperparameteroptimalisatie worden meegerekend, overschrijden de rekenkosten vaak 501 TP3T van het totale budget. De arbeidskosten voor engineering bedragen doorgaans nog eens 20-301 TP3T.
Hoe lang duurt het om een groot taalmodel te trainen?
De trainingsduur varieert sterk afhankelijk van de modelgrootte. Een model met 20 miljard parameters kan in 500-1000 GPU-uren getraind worden (ongeveer 3-6 weken op een cluster met 16 GPU's). Grotere modellen met 120 miljard parameters of meer kunnen duizenden GPU-uren vereisen, waardoor de training 2-4 maanden kan duren. Grensverleggende modellen met 175 miljard parameters of meer trainen vaak maandenlang op enorme clusters.
Is het goedkoper om eenmalig te trainen of om op de lange termijn API-aanroepen te gebruiken?
Dit hangt volledig af van het gebruiksvolume. Voor applicaties die minder dan 10 miljoen API-aanroepen per maand doen, zijn commerciële diensten doorgaans goedkoper. Organisaties met een constant hoog gebruiksvolume – met name organisaties die gespecialiseerde modellen nodig hebben of te maken hebben met eisen op het gebied van gegevensbescherming – kunnen zelfstudie op de lange termijn (over meerdere jaren) voordeliger vinden.
Wat is het verschil tussen trainingskosten en inferentiekosten?
Trainingskosten zijn de eenmalige uitgaven voor de ontwikkeling van het model, variërend van duizenden tot honderden miljoenen dollars. Inferentiekosten zijn de doorlopende kosten voor het uitvoeren van het model om voorspellingen te doen, die per verzoek of token in rekening worden gebracht. Bij veelgebruikte modellen overstijgen de totale inferentiekosten gedurende de levensduur van het model vaak de trainingskosten.
Hoe kan ik de kosten van een LLM-opleiding verlagen?
Belangrijke strategieën voor kostenreductie zijn onder meer het gebruik van kwantisering (FP4/FP8-training), het benutten van spot-instances voor een besparing van 40-701 TP3T, het implementeren van efficiënte checkpointing om verspilde rekenkracht te minimaliseren, het optimaliseren van datapijplijnen om de inactieve GPU-tijd te verminderen en, indien van toepassing, het overwegen van modeldestillatie vanuit grotere leraarmodellen.
Het nemen van de investeringsbeslissing
Het trainen van grote taalmodellen blijft duur, maar de kosten variëren. Organisaties staan niet voor een binaire keuze tussen geavanceerde modellen en helemaal niets.
Een realistische beoordeling begint met de vereisten van de use case. Welk prestatieniveau lost het bedrijfsprobleem daadwerkelijk op? Vereist de applicatie geavanceerde mogelijkheden, of zou een kleiner, gespecialiseerd model volstaan?
Voor veel toepassingen leveren modellen met 7 tot 20 miljard parameters uitstekende resultaten tegen beheersbare kosten. Deze systemen kunnen worden getraind voor $50.000 tot $200.000, waardoor ze toegankelijk zijn voor middelgrote organisaties met specifieke domeinbehoeften.
De race om de meest geavanceerde modellen – met een focus op 175 miljard parameters en meer – is vooral interessant voor bedrijven die algemene AI-platforms bouwen. Voor alle anderen ligt de ideale oplossing vaak in kleinere, gespecialiseerde modellen die geoptimaliseerd zijn voor specifieke taken.
Kijk naar de totale eigendomskosten. Training is slechts het begin. Houd rekening met hosting, inferentiekosten, doorlopend onderhoud en het technische team dat nodig is om het systeem te ondersteunen.
De economische aspecten van LLM-ontwikkeling blijven zich ontwikkelen. Hardware verbetert, algoritmes worden efficiënter en er verschijnen regelmatig nieuwe trainingstechnieken. Wat vandaag $500.000 kost, kan over twee jaar $200.000 kosten – of driemaal betere prestaties leveren voor dezelfde prijs.
Organisaties die deze markt betreden, moeten klein beginnen, zorgvuldig meten en opschalen op basis van bewezen waarde. De technologie is inmiddels zo ver ontwikkeld dat experimenteren geen enorme investeringen vooraf meer vereist. Prototypeer met kleinere modellen, valideer de aanpak en beslis vervolgens of opschalen of vasthouden aan commerciële API's meer zinvol is.
De AI-revolutie versnelt voortdurend, maar slimme implementatie is belangrijker dan pure schaalvergroting. Inzicht in deze kostenstructuren helpt organisaties weloverwogen beslissingen te nemen in plaats van benchmarks na te jagen die mogelijk niet relevant zijn voor hun specifieke toepassingen.