Korte samenvatting: De snelste LLM-inferentie-API's in 2026 zijn afkomstig van aanbieders zoals Groq, SiliconFlow en Hugging Face, met een latentie van minder dan 2 seconden en een doorvoer van meer dan 100 tokens per seconde. De prijzen variëren sterk – van DeepSeek's $0,28 per miljoen inputtokens tot OpenAI's GPT-5.2 Pro voor $21,00. Kosteneffectieve inferentie vereist een balans tussen snelheid, prijs en modelcapaciteit voor uw specifieke workload.
Snelheid is cruciaal bij het grootschalig implementeren van grote taalmodellen. Maar de snelste inferentie-API is niet altijd de goedkoopste, en de goedkoopste is niet altijd snel genoeg.
Begin 2026 is de markt voor LLM-inferentie opgesplitst in verschillende segmenten. Premium aanbieders zoals OpenAI vragen de hoogste prijzen voor geavanceerde modellen. Tegelijkertijd bieden agressieve nieuwkomers zoals DeepSeek lagere prijzen dan de gevestigde spelers, met een verschil van 90% of meer.
Deze gids geeft een overzicht van de werkelijke cijfers. Prijzen per miljoen tokens, daadwerkelijke latentiemetingen, doorvoerbenchmarks en de verborgen kosten die niet op prijspagina's worden vermeld.
Inzicht in de snelheidsmetrieken van LLM-inferentie
Voordat je aanbieders met elkaar vergelijkt, is het belangrijk om te begrijpen wat "snel" nu eigenlijk betekent in de context van LLM API's.
Drie meetwaarden zijn het belangrijkst:
- Latentie Deze meting meet de tijd tot het eerste token: hoe snel het model begint te reageren na ontvangst van uw verzoek. Volgens de statistieken van Hugging Face's inferentieprovider behalen de best presterende modellen een latentie van minder dan 1,5 seconde. Groq wordt in benchmarks van derden en in Groq's eigen benchmarkrapporten steevast genoemd als extreem snel (tokens/sec).
- Doorvoer Het systeem registreert het aantal gegenereerde tokens per seconde zodra het model begint te reageren. Uit data van Hugging Face blijkt dat toonaangevende aanbieders 127 tokens per seconde of meer halen voor modellen zoals Qwen3.5-35B-A3B.
- Contextvenster Dit bepaalt hoeveel tekst het model in één verzoek kan verwerken. Moderne modellen ondersteunen tokens van 128.000 tot 262.000, hoewel langere contexten zowel de latentie als de kosten kunnen verhogen.
- Het punt is echter dat de snelheid sterk varieert afhankelijk van de kenmerken van de werklast. Korte zoekopdrachten met beknopte antwoorden worden sneller verwerkt dan redeneertaken met een lange context. Batchverwerking ruilt een snelle reactietijd in voor een hogere doorvoer en lagere kosten.
Snelste LLM-inferentieproviders op basis van latentie
Als pure snelheid de prioriteit heeft, presteren een handvol aanbieders consequent beter dan de concurrentie.
Groq: Speciaal ontworpen voor snelheid
Groq maakt gebruik van op maat gemaakte Language Processing Unit (LPU)-hardware die specifiek is ontworpen voor LLM-inferentie. Discussies binnen de community en Groq's eigen benchmarks positioneren het systeem als "extreem snel" voor inferentiesnelheid, met tokens-per-seconde-metingen die consistent toonaangevend zijn in de markt.
Het bedrijf heeft nieuwe benchmarks gepubliceerd voor Llama 3.3 70B, waaruit blijkt dat het bedrijf toonaangevende inferentieprestaties levert. Voor toepassingen waarbij een reactietijd van minder dan een seconde cruciaal is – zoals chatbots, realtime assistenten en interactieve tools – biedt de architectuur van Groq meetbare voordelen.
De prijzen worden niet voor alle modellen openbaar vermeld, dus ontwikkelaars moeten de officiële documentatie van Groq raadplegen voor de actuele tarieven.
SiliconFlow: Snelheid en betaalbaarheid in één
SiliconFlow behaalde in recente benchmarktests tot 2,3 keer snellere inferentiesnelheden en 32% lagere latentie in vergelijking met toonaangevende AI-cloudplatforms, met behoud van consistente nauwkeurigheid. Het platform biedt zowel serverloze pay-per-use-opties als gereserveerde GPU's.
Deze combinatie van snelheid en kostenbeheersing maakt SiliconFlow aantrekkelijk voor productieomgevingen waar beide aspecten van belang zijn. Het platform ondersteunt meerdere open-source modellen met transparante prijsstelling en flexibele infrastructuuropties.
Aanbieders van gezichtsuitdrukkingen omhelzen
Hugging Face bundelt meerdere inferentieproviders via een uniforme API en volgt de prestaties van verschillende model-providercombinaties. De interface stelt ontwikkelaars in staat om verzoeken automatisch door te sturen naar de snelste of goedkoopste provider voor elk model. Omdat de router OpenAI-compatibele aanroepen ondersteunt, is migratie eenvoudig voor gebruikers van bestaande integraties.

Ontwikkel LLM-applicaties die geoptimaliseerd zijn voor snelle inferentie.
Snelle LLM-respons is afhankelijk van de juiste architectuur, modelconfiguratie en infrastructuur. AI Superieur Ze ontwikkelen AI-software en NLP-systemen die grote taalmodellen integreren in praktische toepassingen zoals chatbots, automatiseringstools en data-analyseplatforms. Hun team ontwerpt modelpipelines, backendservices en implementatieomgevingen, zodat LLM-functionaliteiten betrouwbaar werken in productiesystemen.
Een product ontwikkelen dat gebruikmaakt van LLM API's?
Praat met AI die superieur is aan:
- Het ontwerpen en bouwen van LLM-applicaties.
- NLP-systemen en AI-software ontwikkelen
- Taalmodellen implementeren binnen bestaande platforms.
👉 Vraag een AI-consult aan bij AI Superieur om uw project te bespreken.
LLM-inferentieprijzen: Marktoverzicht 2026
De prijsstructuren verschillen enorm tussen aanbieders. Sommige rekenen hoge tarieven voor propriëtaire modellen. Anderen concurreren agressief op basis van de prijs van open-source modellen.
Dit is de stand van de markt begin 2026:
Premiumcategorie: OpenAI en Anthropic
OpenAI lanceerde GPT-5.2 Pro in februari 2026 voor $21,00 per miljoen inputtokens en $168,00 per miljoen outputtokens. Het standaard GPT-5.2-model kost $8,00 input / $32,00 output per miljoen tokens.
De Claude-modellen van Anthropic bevinden zich in een vergelijkbaar premium prijssegment. Deze fabrikanten rechtvaardigen de hogere kosten met geavanceerde mogelijkheden, betrouwbaarheid en uitgebreide veiligheidstests.
Middensegment: Google Gemini en anderen
De Gemini-modellen van Google bieden concurrerende prijzen voor krachtige modellen. Het bredere middensegment omvat aanbieders zoals Mistral AI, die prestaties combineren met een toegankelijker prijskaartje dan premium aanbieders.
Budgetcategorie: DeepSeek Disruption
DeepSeek heeft de concurrentie agressief onderboden met zijn V3.2-Exp "denkende" modellen, die slechts $0,28 per miljoen inputtokens (cache-miss) en $0,42 per miljoen outputtokens kosten. Dit vertegenwoordigt een korting van meer dan 90% ten opzichte van premium aanbieders.
De Grok-reeks van xAI is eveneens gericht op kostenbewuste ontwikkelaars. Grok 4 Fast en Grok 4.1 Fast hebben beide een prijs van $0.20 input / $0.50 output per miljoen tokens.
| Aanbieder | Voorbeeldmodel | Invoer ($/M tokens) | Uitvoer ($/M tokens) | Prestatieniveau |
|---|---|---|---|---|
| Open AI | GPT-5.2 Pro | $21.00 | $168.00 | Premie |
| Open AI | GPT-5.2 | $8.00 | $32.00 | Premie |
| xAI | Grok 4 | $3.00 | $15.00 | Middenklasse |
| xAI | Grok 4 Snel | $0.20 | $0.50 | Begroting |
| Diepzoeken | V3.2-Exp | $0.28 | $0.42 | Begroting |
| Novita (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | Begroting |
Verborgen kosten die verder gaan dan de tokenprijs
De catalogusprijs per miljoen tokens vertelt slechts een deel van het verhaal over de kosten.
Verschillende verborgen factoren hebben een aanzienlijke invloed op de daadwerkelijke uitgaven:
Contextcaching en hergebruik
Sommige aanbieders bieden korting op gecachede context die herhaaldelijk wordt gebruikt bij verschillende verzoeken. Het tarief van DeepSeek ($0.28) geldt voor verzoeken waarbij de cache wordt gemist; de prijs voor verzoeken waarbij de cache wordt gevonden, ligt lager. Als uw applicatie herhaaldelijk vergelijkbare contexten verwerkt, kan caching de kosten aanzienlijk verlagen.
Batchprijsberekening versus realtimeprijsberekening
OpenAI en Google bieden API's voor batchverwerking aan met gereduceerde tarieven – soms wel 50% korting op realtime tarieven. Volgens discussies binnen de Hugging Face-community bestaat er geen direct equivalent van de Batch API van OpenAI met speciale korting op de serverloze endpoints van Hugging Face.
Batch-inferentie werkt voor taken die niet tijdsgevoelig zijn: gegevensverwerking, contentgeneratie en analysetaken. De keerzijde is een langere voltooiing in ruil voor lagere kosten.
Output Token Economie
Uitvoertokens kosten doorgaans 4 tot 8 keer meer dan invoertokens. Een model dat uitgebreide antwoorden genereert, verbruikt budget sneller dan een model dat beknopt antwoordt.
Om de kosten te optimaliseren, voorkomt het beperken van de maximale uitvoerlengte een ongebreideld tokengebruik. Te lage limieten kunnen reacties afkappen voordat volledige antwoorden worden geleverd, dus de configuratie vereist een afweging tussen volledigheid en kostenbeheersing.
Infrastructuur- en schaalkosten
Serverless API's rekenen per token af zonder overheadkosten voor de infrastructuur. Modellen met gereserveerde capaciteit, zoals de gereserveerde GPU-opties van SiliconFlow, vereisen een voorafgaande toezegging, maar bieden betere kosten per token bij grotere schaal.
Onderzoek naar de inzet van heterogene GPU's toont aan dat de kostenefficiëntie sterk varieert afhankelijk van de kenmerken van de workload. Volgens een analyse van LLM-servers die gebruikmaken van heterogene GPU's, verbetert het afstemmen van aanvraagtypen op de juiste hardware het resourcegebruik en verlaagt het de effectieve kosten.
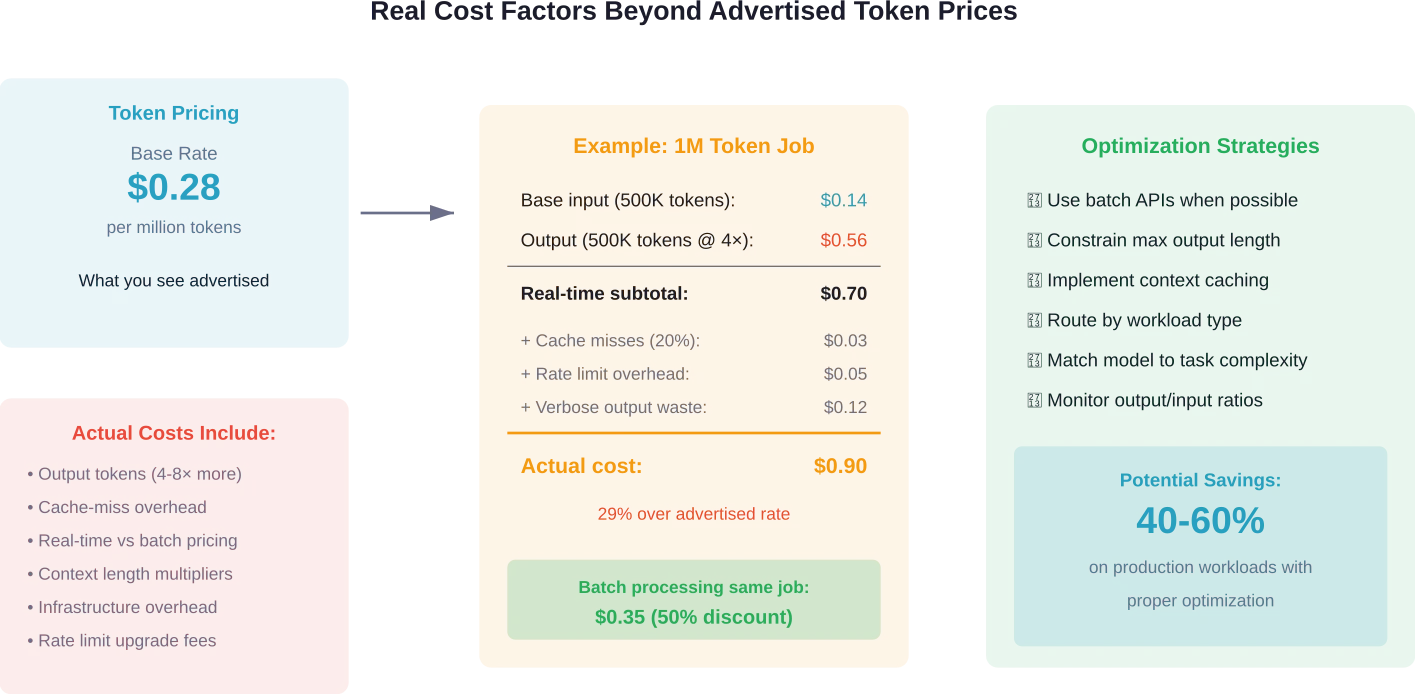
Snelheid-kostenverhouding: de optimale balans vinden
De optimale aanbieder hangt volledig af van de werklast.
Voor toepassingen waarbij latency cruciaal is – zoals chatbots voor klanten, realtime programmeerassistenten en interactieve demo's – rechtvaardigt snelheid een hogere prijs. Een reactievertraging van 2 seconden jaagt gebruikers weg, ongeacht de kostenbesparing.
Voor grootschalige batchverwerking – zoals contentclassificatie, data-extractie en analysepipelines – is de kostprijs per miljoen tokens doorslaggevend. De prijsstelling van DeepSeek ($0.28) bij acceptabele (zo niet toonaangevende) prestaties is economisch gezien een verstandige keuze.
Onderzoek naar LLM-begeleiding suggereert dat hybride benaderingen beide metrieken kunnen optimaliseren. Door kleinere, snellere modellen te gebruiken voor de initiële verwerking en complexe query's door te sturen naar grotere modellen, worden de gemiddelde kosten verlaagd met behoud van kwaliteit. Volgens de studie verbeteren zelfs kleine hints van grotere modellen (10-30% van de volledige respons) de nauwkeurigheid van kleinere modellen aanzienlijk.
Overwegingen met betrekking tot de modelgrootte
De grootte van het model heeft een directe invloed op zowel de snelheid als de kosten.
Volgens de richtlijnen van Hugging Face voor het kiezen van open-source LLM's vereist een model met 7-8 miljard parameters 14-16 GB VRAM bij FP16-precisie, of 6-8 GB met 4-bits kwantisering. Cloudopties omvatten AWS g5.xlarge-instanties.
Kleinere modellen met 1-3 miljard parameters draaien op 4-6 GB VRAM (2 GB gekwantiseerd) en kunnen basistaken – tekstclassificatie, automatisch aanvullen, eenvoudige chat – uitvoeren op bescheiden hardware zoals een RTX 3060 of laptop-GPU's.
Grotere modellen leveren betere redeneringen op, maar vereisen meer rekenkracht. Voor de implementatie van een LLaMA-2-70B-model zijn volgens onderzoek naar efficiëntie minimaal twee NVIDIA A100 GPU's (elk met 80 GB VRAM) nodig voor FP16-inferentie.
De meest kosteneffectieve aanbieders voor snelle inferentie
Op basis van prestatiecijfers en prijsgegevens bieden verschillende aanbieders aantrekkelijke verhoudingen tussen snelheid en kosten:
SiliconFlow
SiliconFlow combineert concurrerende snelheid (2,3 keer sneller dan sommige toonaangevende platforms) met flexibele prijsstelling. Het platform ondersteunt zowel serverloze als gereserveerde capaciteit, waardoor kostenoptimalisatie mogelijk is op basis van gebruikspatronen.
De dienst biedt een alles-in-één AI-cloud met een toonaangevende prijs-prestatieverhouding, gericht op zowel ontwikkelaars als bedrijven.
Aanbieders van gezichtsuitdrukkingen omhelzen
De uniforme router van Hugging Face combineert meerdere providers, waardoor automatisch de snelste of goedkoopste optie voor elk model wordt gekozen. Volgens hun eigen gegevens:
- Novita biedt Qwen3.5-modellen met een ingangsspanning van $0.25-$0.60 en een latentie van minder dan 1,1 seconde.
- Together AI biedt vergelijkbare modellen met een iets hogere latentie, maar vergelijkbare prijzen.
- Meerdere aanbieders concurreren om elk populair model, wat de efficiëntie verhoogt.
De router ondersteunt OpenAI-compatibele API-aanroepen, wat de migratie van andere providers vereenvoudigt. Ontwikkelaars kunnen routeringsvoorkeuren specificeren, zoals "snelst" en "goedkoopst", om te optimaliseren voor verschillende doelstellingen.
Mistral AI
Mistral AI levert sterke prestaties tegen een prijs in het middensegment. Het bedrijf richt zich op efficiënte modelarchitecturen die de inferentiekosten verlagen zonder aan functionaliteit in te boeten.
Mistral-modellen behalen concurrerende kwaliteitsnormen met redelijke kosten per token, waardoor ze aantrekkelijk zijn voor productieomgevingen waar meerdere beperkingen een rol spelen.
Diepzoeken
Voor taken waarbij kosten een doorslaggevende factor zijn, vertegenwoordigt de scherpe prijsstelling van DeepSeek ($0.28 input / $0.40 output) de huidige marktondergrens voor capabele modellen.
De prestaties blijven achter bij die van premium aanbieders, maar zijn voor veel toepassingen nog steeds acceptabel. De kostenbesparingen – tot wel 90% vergeleken met topmodellen – maken gebruiksscenario's mogelijk die anders een hogere prijs niet zouden rechtvaardigen.
Vuurwerk AI
Fireworks AI is gespecialiseerd in geoptimaliseerde inferentie voor open-source modellen. Het platform richt zich op betrouwbaarheid van productieniveau met voorspelbare prijzen en prestaties.
De dienst biedt een infrastructuur die specifiek is afgestemd op LLM-servers, met functies die zijn ontworpen voor ontwikkelaars die applicaties bouwen in plaats van te experimenteren met modellen.
Overwegingen bij prestatiebenchmarking
Gepubliceerde benchmarks weerspiegelen niet altijd de prestaties in de praktijk.
Verschillende factoren zorgen voor een kloof tussen de geadverteerde meetwaarden en de daadwerkelijke productieervaring:
De belasting van de dienst heeft invloed op de latentie. Aanbieders die zwaar belast worden, werken trager. Het tijdstip, de geografische regio en de actuele vraag hebben allemaal invloed op de daadwerkelijke responstijden.
De kenmerken van een verzoek zijn van groot belang. Korte prompts met beknopte resultaten worden sneller verwerkt dan redeneertaken met een lange context. Volgens onderzoek naar de afweging tussen energieverbruik en prestaties bij LLM-inferentie, vertoont inferentie aanzienlijke variabiliteit tussen verschillende zoekopdrachten en uitvoeringsfasen.
In serverloze architecturen kan de latentie bij een koude start van invloed zijn op het eerste verzoek.
Snelheidslimieten beperken de doorvoer. Zelfs snelle API's beperken het aantal verzoeken boven een bepaald niveau, waardoor abonnementen van een hogere categorie of gereserveerde capaciteit nodig zijn voor toepassingen met een hoog volume.
Opties voor de implementatie van infrastructuur
Naast beheerde API's hebben infrastructuurkeuzes een aanzienlijke invloed op de kosten en prestaties.
Serverloze API's
Serverloze oplossingen zoals die van Hugging Face, OpenAI en anderen rekenen per token en vereisen geen infrastructuurbeheer. Dit model werkt goed voor variabele workloads, prototyping en applicaties met een onvoorspelbare vraag.
Het nadeel is dat de kosten per token hoger liggen dan bij een dedicated infrastructuur op grote schaal.
Gereserveerde capaciteit
Gereserveerde GPU-instances of dedicated endpoints bieden gegarandeerde resources tegen lagere tarieven per token. Providers zoals SiliconFlow bieden deze optie aan naast serverless-tarieven.
Gereserveerde capaciteit is economisch zinvol zodra het gebruik consistente drempels bereikt waarbij de kosten voor de inzet lager worden dan de kosten voor een serverloze oplossing.
Zelfgehoste inferentie
Het uitvoeren van inferentie op eigen of gehuurde infrastructuur biedt maximale controle en potentieel de laagste kosten bij zeer grote volumes.
Onderzoek naar de implementatie van LLM's op edge-apparaten wijst op beperkingen: een model met 7-8 miljard parameters vereist aanzienlijke geheugen- en rekenkracht. Karakteriseringsstudies van mobiele SoC's tonen aan dat zelfs met heterogene processoren de geheugenbandbreedte de doorvoer beperkt, waarbij sommige configuraties slechts 40-45 GB/s per eenheid halen voordat meerdere processoren nodig zijn om de beschikbare bandbreedte te benutten.
Zelfhosting vereist expertise in het implementeren, optimaliseren, monitoren en schalen van modellen – overhead die serverloze API's elimineren.
De juiste leverancier kiezen voor uw werkzaamheden
Bij de besluitvorming moeten de kenmerken van de werkdruk voorrang krijgen boven abstracte vergelijkingen.
Stel de volgende vragen:
- Wat is het gebruikspatroon? Bij constante, grote werkbelastingen is gereserveerde capaciteit of zelfhosting een goede optie. Variabele, onvoorspelbare vraag is daarentegen meer geschikt voor serverloze API's.
- Hoe gevoelig is de applicatie voor latency? Gebruikersinteracties in realtime vereisen reactietijden van minder dan een seconde. Achtergrondprocessen tolereren een latentie van enkele seconden om kosten te besparen.
- Welke modelcapaciteit is nu eigenlijk nodig? Veel applicaties overdimensioneren hun modellen qua capaciteit. Kleinere, snellere modellen kunnen eenvoudige taken tegen lagere kosten afhandelen.
- Kan batchverwerking werken? Niet-urgente opdrachten profiteren van batchkortingen voor 50% wanneer aanbieders deze aanbieden.
- Wat is de verhouding tussen output en input? Applicaties die lange reacties genereren, betalen veel voor uitvoertokens. Het beperken van de uitgebreidheid van de informatie verlaagt de kosten aanzienlijk.
- Heeft de werklast baat bij contextcaching? Door herhaaldelijk vergelijkbare contexten te verwerken met caching-ondersteuning worden de kosten per aanvraag verlaagd.
Veelgestelde vragen
Wat is de goedkoopste LLM-inferentie-API in 2026?
DeepSeek biedt de laagste prijs aan met $0,28 per miljoen inputtokens en $0,40 per miljoen outputtokens voor hun V3.2-Exp-modellen vanaf begin 2026. Grok 4 Fast van xAI heeft een vergelijkbare prijs van $0,20 input / $0,50 output. De totale kosten zijn echter afhankelijk van de uitvoerdetails, de cachingefficiëntie en of batchverwerking beschikbaar is. De "goedkoopste" optie varieert op basis van deze workloadspecifieke factoren.
Welke aanbieder heeft de snelste LLM-inferentiesnelheid?
Groq staat consequent bekend als de snelste inferentieprovider, dankzij speciaal ontwikkelde LPU-hardware die is geoptimaliseerd voor LLM-workloads. Benchmarks van derden en discussies binnen de community bevestigen dat Groq toonaangevende prestaties levert op het gebied van tokens per seconde. Volgens Hugging Face-statistieken zijn andere snelle opties onder andere Novita (met Qwen-modellen met een latentie van 0,66-1,09 seconden) en SiliconFlow (2,3 keer sneller dan sommige toonaangevende platforms). De werkelijke snelheid is afhankelijk van de modelgrootte, de contextlengte en de huidige belasting.
Hoeveel kost het om 1 miljard tokens via een LLM API te verwerken?
De kosten voor 1 miljard tokens variëren enorm, afhankelijk van de aanbieder en de verhouding tussen input en output. Bij de tarieven van DeepSeek ($0.28 input / $0.40 output) kost 1 miljard tokens $280 voor alleen input of $400 voor alleen output. Bij de tarieven van OpenAI's GPT-5.2 Pro ($21 input / $168 output) kost hetzelfde volume $21.000 input of $168.000 output. Een typische workload met 60% input en 40% output zou ongeveer $328 kosten bij DeepSeek, tegenover $79.800 bij GPT-5.2 Pro – een verschil van 240 keer.
Leveren API's voor batchverwerking daadwerkelijk een kostenbesparing op?
Ja, indien beschikbaar. OpenAI en Google bieden batch-API's met een korting van ongeveer 501 TP3T ten opzichte van realtimeverwerking. Het nadeel is een langere verwerkingstijd: batchtaken kunnen uren in plaats van seconden duren. Volgens discussies binnen de Hugging Face-community bieden veel serverloze Hugging Face-endpoints geen specifieke batchkorting, hoewel dedicated inference-endpoints dat mogelijk wel doen. Batchverwerking is zinvol voor taken zoals dataverwerking, contentgeneratie en analyse waarbij geen onmiddellijke resultaten vereist zijn.
Moet ik serverless of gereserveerde GPU-capaciteit gebruiken?
Het hangt af van het gebruikspatroon en het volume. Serverloze API's werken goed bij variabele vraag, prototyping en lage tot gemiddelde volumes, waarbij het gemak opweegt tegen de kosten per token. Gereserveerde capaciteit wordt kosteneffectief wanneer consistent gebruik het break-evenpunt bereikt, waarbij de commitmentkosten lager worden dan de equivalente serverloze uitgaven. SiliconFlow biedt beide opties, waardoor optimalisatie mogelijk is op basis van gebruikspatronen. Bereken uw werkelijke, aanhoudende tokenvolume en vergelijk dit met de reserveringsprijzen om de break-evendrempel te bepalen.
Welke invloed heeft de modelgrootte op de inferentiesnelheid en de kosten?
Grotere modellen vereisen meer rekenkracht, wat zowel de latentie als de infrastructuurkosten verhoogt. Volgens de documentatie van Hugging Face heeft een model van 1-3 miljard bytes slechts 2-4 GB VRAM nodig en levert het snelle inferentie op bescheiden hardware, geschikt voor basistaken. Een model van 7-8 miljard bytes vereist 6-16 GB VRAM, afhankelijk van de kwantisering, en kan complexere workloads aan. Een model van 70 miljard bytes vereist meer dan 140 GB VRAM (meerdere high-end GPU's) en verwerkt verzoeken trager. Kleinere modellen optimaliseren snelheid en kosten; grotere modellen verbeteren de mogelijkheden en de kwaliteit van de redenering. Stem de modelgrootte af op de werkelijke taakvereisten in plaats van standaard het grootste beschikbare model te gebruiken.
Kan ik de kosten verlagen door de lengte van de prompts te optimaliseren?
Absoluut. Kortere prompts verbruiken minder invoertokens, wat de kosten direct verlaagt. Belangrijker nog, het beperken van de maximale uitvoerlengte voorkomt dure, uitgebreide antwoorden. Omdat uitvoertokens 4 tot 8 keer duurder zijn dan invoertokens, verbruikt een model dat onnodig lange antwoorden genereert snel budget. Volgens de beste praktijken kunt u de parameter max_tokens het beste aanpassen aan uw specifieke gebruikssituatie: een te lage waarde leidt tot korte antwoorden, terwijl een te hoge waarde onnodige uitgebreidheid toelaat. Monitor de werkelijke uitvoerlengtes en pas de limieten dienovereenkomstig aan. Contextcaching voor herhaalde promptelementen verlaagt de kosten verder, indien ondersteund door de provider.
Conclusie: Balans tussen snelheid en kosten
De snelste LLM-inferentie-API is niet voor elke workload de beste keuze, en de goedkoopste API is niet altijd de meest kosteneffectieve als kwaliteit en snelheid belangrijk zijn.
In 2026 biedt de markt een echte keuze. Premium aanbieders zoals OpenAI leveren geavanceerde mogelijkheden tegen een premium prijs. Agressieve uitdagers zoals DeepSeek bieden lagere prijzen dan gevestigde bedrijven, vaak met een verschil van 901 TP3T of meer. Gespecialiseerde infrastructuuraanbieders zoals Groq en SiliconFlow optimaliseren voor snelheid of kostenefficiëntie.
De optimale provider hangt volledig af van uw specifieke vereisten: gevoeligheid voor latentie, eisen aan de uitvoerkwaliteit, gebruiksvolume, detailniveau van de uitvoer, mogelijkheden voor caching en of batchverwerking geschikt is voor uw gebruikssituatie.
Begin met het in kaart brengen van de kenmerken van uw workload. Meet het werkelijke tokenvolume, de input/output-ratio's en de latentievereisten. Koppel deze vereisten vervolgens aan providers die geoptimaliseerd zijn voor uw specifieke beperkingen.
Ga er niet van uit dat de duurste optie de beste resultaten oplevert, of dat de goedkoopste optie te veel inlevert op kwaliteit. Test meerdere aanbieders met representatieve workloads voordat u overgaat tot een grootschalige implementatie.
De markt voor LLM-inferentie blijft ook in 2026 zeer competitief, met snel verbeterende prijzen en prestaties. Houd nieuwe spelers in de gaten en voer regelmatig benchmarks uit om ervoor te zorgen dat u optimale waarde krijgt naarmate het landschap zich ontwikkelt.
Bent u klaar om uw LLM-inferentiekosten te optimaliseren? Vergelijk uw specifieke werklast met die van verschillende aanbieders aan de hand van de prijsgegevens en prestatiestatistieken in deze handleiding om de beste verhouding tussen snelheid en kosten voor uw toepassing te vinden.