Korte samenvatting: LLM-analysetools met kostenoptimalisatiefuncties helpen organisaties het tokengebruik te monitoren, uitgavenpatronen te volgen en de kosten voor AI-infrastructuur te verlagen door middel van intelligente caching, modelselectie en geautomatiseerde resourceallocatie. Toonaangevende platforms combineren realtime kostenbewaking met prestatie-observatie om kostbare workflows te identificeren en te optimaliseren zonder in te leveren op responskwaliteit. Effectief kostenbeheer vereist sessiegebaseerde tracking, snelle optimalisatie en strategische modelselectie op basis van taakcomplexiteit.
Organisaties die grote taalmodellen implementeren, staan voor een fundamentele uitdaging: de kosten kunnen ongemerkt de pan uit rijzen. Prijsstelling op basis van tokens betekent dat elke API-aanroep kosten met zich meebrengt, en zonder de juiste analyses kan die supportchatbot of documentanalysator budgetten in een alarmerend tempo opbranden.
De explosieve groei van de toepassing van LLM (Large-Library Modeling) heeft geleid tot een dringende vraag naar gespecialiseerde analyseplatformen. Deze tools houden niet alleen de uitgaven bij, maar identificeren ook actief mogelijkheden voor optimalisatie, automatiseren strategieën voor kostenbesparing en bieden het inzicht dat nodig is om weloverwogen beslissingen te nemen over modelselectie en infrastructuur.
Maar er is iets belangrijks om te weten: niet alle analyseplatformen zijn gelijk. Sommige richten zich puur op het observeren van gegevens, andere geven prioriteit aan kostenbewaking, en de beste combineren beide met bruikbare optimalisatiefuncties. Begrijpen welke mogelijkheden het belangrijkst zijn voor jouw specifieke toepassing, maakt het verschil tussen effectief kostenbeheer en zinloos geld uitgeven aan een probleem.
Inzicht in de kostenstructuur en prijsmodellen van een LLM-opleiding
Tokengebaseerde prijsstelling domineert het LLM-landschap. Volgens de officiële prijsstelling van Anthropic kost Claude Opus 4.6 $5 per miljoen inputtokens en $25 per miljoen outputtokens. Deze prijsasymmetrie is belangrijk: outputtokens kosten vijf keer zoveel als inputtokens.
De algemene regel is: langere prompts en langere gegenereerde antwoorden betekenen een hoger aantal tokens en hogere kosten.
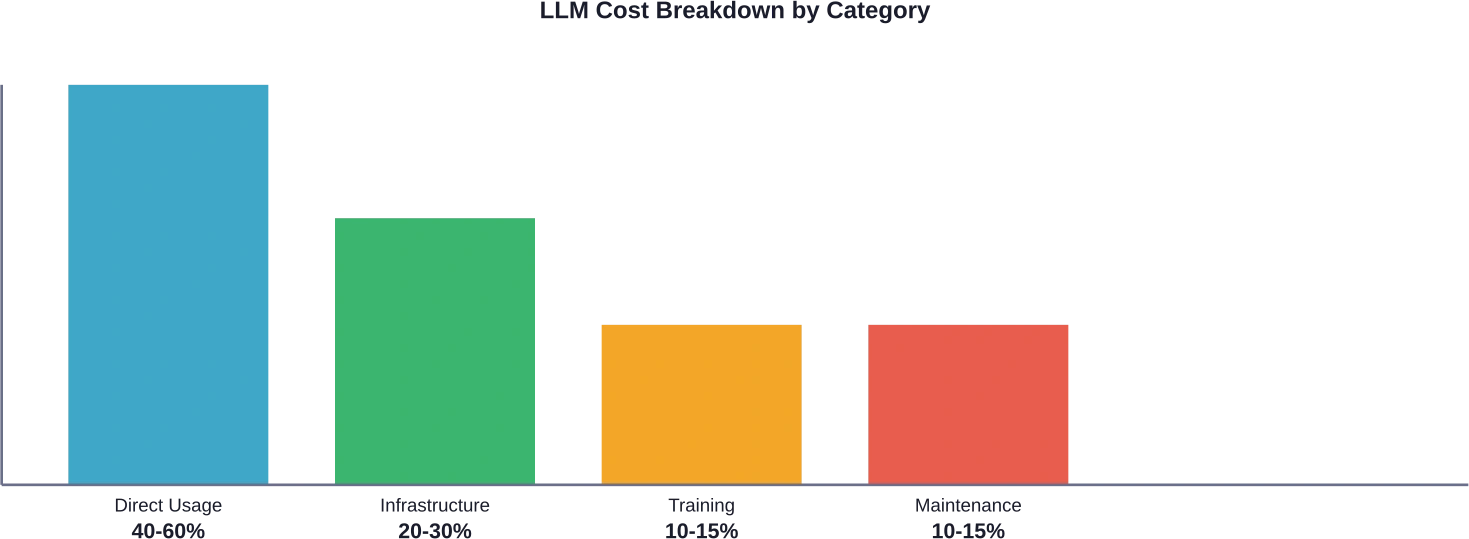
Eerlijk gezegd: de meeste organisaties onderschatten hun werkelijke LLM-kosten. Volgens brancheanalyses kunnen directe gebruikskosten 40-601 TP3T van de totale LLM-uitgaven uitmaken, waarbij infrastructuur en integratie 20-301 TP3T in beslag nemen en training en optimalisatie de rest.
De verborgen kostenvermenigvuldigers
Volgens de AWS-documentatie kan het cachen van prompts de latentie van inferentiereacties met maximaal 851 TP3T en de kosten van invoertokens met maximaal 901 TP3T verlagen voor ondersteunde modellen op Amazon Bedrock. Maar zonder analyses om cachebare patronen te identificeren, lopen organisaties deze besparingen volledig mis.
Volgens AWS-casestudies varieert de verwerkingstijd van verzoeken van 6,76 seconden tot 32,24 seconden, waarbij de variatie voornamelijk te wijten is aan verschillende vereisten voor uitvoertokens. Snelle reacties van minder dan 10 seconden worden doorgaans toegepast op eenvoudige query's, terwijl complexe analytische taken meer dan 30 seconden in beslag nemen.
De grootte van het contextvenster verhoogt ook de kosten. Claude Opus 4.6 biedt in bèta een contextvenster van 1 miljoen tokens aan – krachtig, maar duur als organisaties routinematig onnodig grote contexten versturen.
Kernfuncties van LLM-analyseplatforms
Effectieve LLM-analyseplatforms bieden drie fundamentele mogelijkheden: uitgebreide kostenbewaking, inzicht in prestaties en bruikbare optimalisatie-inzichten. Elk onderdeel vervult een specifieke functie bij het beheren van AI-workloads.
Kostenregistratie op basis van sessies
Sessies groeperen gerelateerde verzoeken om de werkelijke kosten van gebruikersinteracties weer te geven. In plaats van individuele API-aanroepen te zien, zien teams complete workflows. Volgens voorbeelden van kostenregistratie kosten ondersteuningschats gemiddeld ongeveer $0,12 met 5 API-aanroepen, documentanalyseworkflows kosten ongeveer $0,45 met 12 API-aanroepen, terwijl snelle zoekopdrachten ongeveer $0,02 kosten met één aanroep.
Deze granulariteit is belangrijk. Organisaties kunnen vaststellen welke interactietypen de kosten verhogen en dienovereenkomstig optimaliseren. Het alternatief – elke API-aanroep als een op zichzelf staand geval beschouwen – verhult de werkelijke kosten per eenheid van AI-functies.
Realtime gebruiksmonitoring
Patronen in tokenverbruik onthullen mogelijkheden voor optimalisatie. Analyseplatforms volgen de verhouding tussen inkomende en uitgaande tokens, identificeren dure prompts en signaleren afwijkende gebruikspieken voordat deze budgetten beïnvloeden.
Maar wacht even. Realtime monitoring is alleen nuttig als het tot actie leidt. De beste platforms integreren geautomatiseerde waarschuwingen en budgetdrempels die voorkomen dat de kosten de pan uit rijzen.
Vergelijking van modelprestaties
Verschillende modellen blinken uit in verschillende taken. Analytische tools maken A/B-testen mogelijk tussen verschillende modellen om de optimale balans tussen kosten en kwaliteit voor elk specifiek gebruiksscenario te vinden.
Volgens onderzoek van het MIT-IBM Watson AI Lab vertegenwoordigt een gemiddelde relatieve fout van 4% de best haalbare nauwkeurigheid als gevolg van willekeurige zaadruis, maar een fout tot 20% blijft bruikbaar voor besluitvorming. Organisaties moeten acceptabele prestatiedrempels definiëren voordat ze de kosten optimaliseren.
Kostenoptimalisatiestrategieën mogelijk gemaakt door analysetools
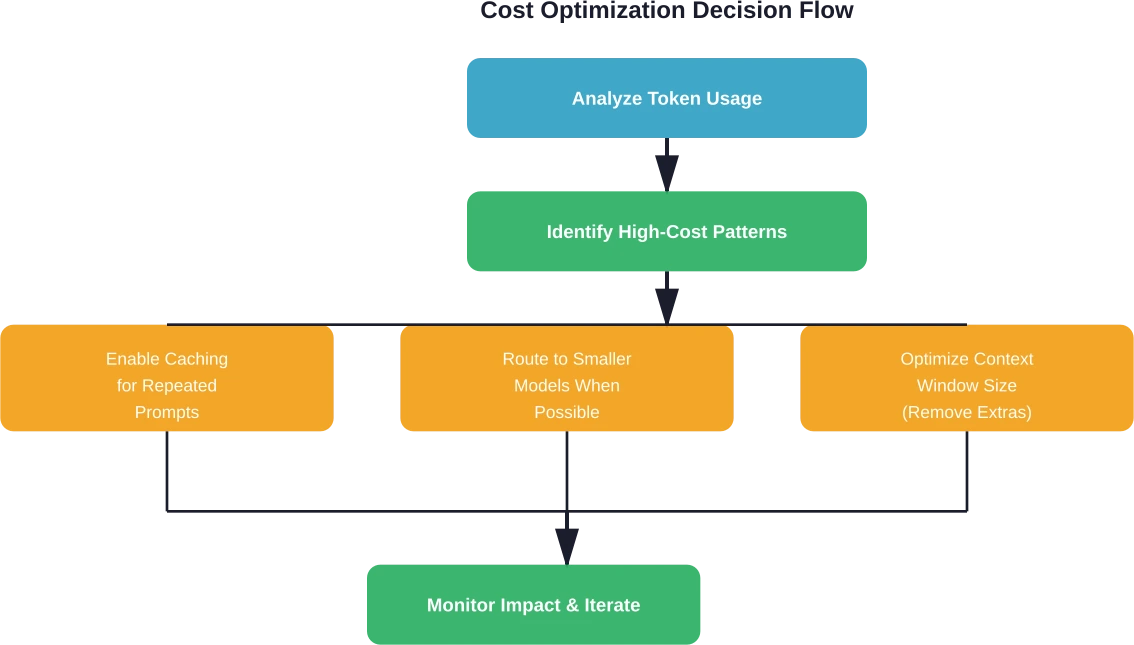
Analyseplatformen rapporteren niet alleen kosten, ze maken ook specifieke optimalisatiestrategieën mogelijk die de uitgaven direct verlagen zonder dat dit ten koste gaat van de functionaliteit.
Intelligente promptcaching
Promptcaching slaat veelgebruikte promptsegmenten op en hergebruikt deze bij verschillende verzoeken. Caching levert aanzienlijke verbeteringen in latentie op; AWS documenteert responstijdverminderingen tot wel 85% voor gecachede query's. Maar zonder analyses om cachebare patronen te identificeren, lopen organisaties deze besparingen volledig mis.
Twee caching-methoden domineren: caching op systeemniveau slaat veelgebruikte prompt-prefixes op, terwijl request-response caching complete query-antwoordparen opslaat voor hergebruik. Analysetools identificeren welke prompts het meest baat hebben bij caching op basis van herhalingsfrequentie en tokenlengte.
Strategische modelselectie
Een kosten-batenanalyse van de implementatie van LLM op locatie door Carnegie Mellon toont aan dat de benchmarkscores binnen 20% van toonaangevende commerciële modellen de praktijk binnen bedrijven weerspiegelen, waarbij bescheiden prestatieverschillen acceptabel blijven voor kostenbesparing.
Analyseplatforms bieden mogelijkheden om aanvragen door te sturen naar minder dure modellen wanneer de kwaliteitseisen dit toelaten. Voor eenvoudige classificatietaken zijn geen geavanceerde modellen nodig; kleinere, goedkopere alternatieven voldoen prima.
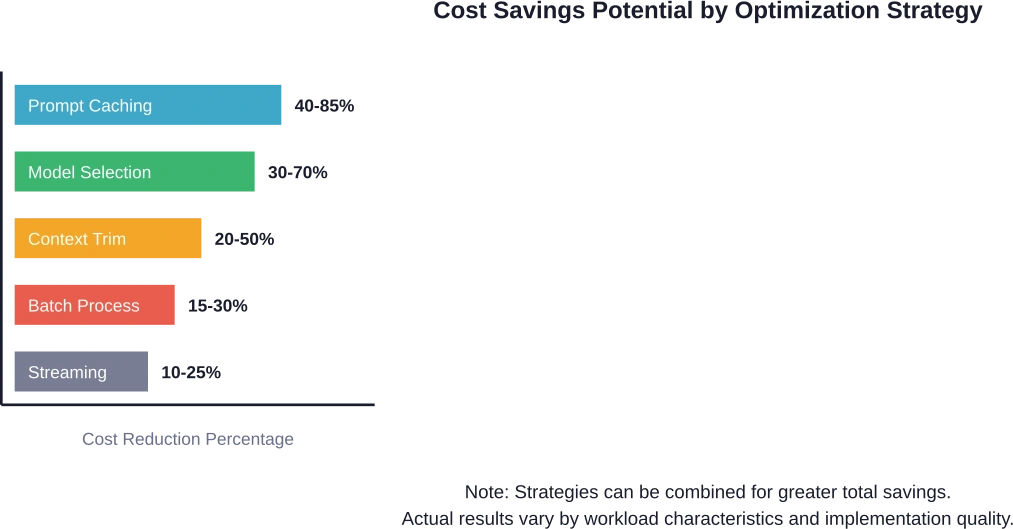
| Strategie | Kostenreductie | Implementatiecomplexiteit | Kwaliteitsimpact
|
|---|---|---|---|
| Snelle cache | 40-85% | Laag | Geen |
| Modelselectie | 30-70% | Medium | Taakafhankelijk |
| Contextoptimalisatie | 20-50% | Medium | Geen tot minimaal |
| Batchverwerking | 15-30% | Hoog | Voegt latentie toe |
| Responsstreaming | 10-25% | Laag | Geen |
Contextvensteroptimalisatie
Veel applicaties versturen bij elk verzoek onnodig grote contexten. Analysegegevens onthullen de gemiddelde contextgrootte en identificeren mogelijkheden om irrelevante informatie te verwijderen.
Kortere contexten betekenen minder invoertokens en een snellere verwerking. Casestudies uit de industrie tonen aan dat systematische contextoptimalisatie aanzienlijke kostenbesparingen oplevert.
Geautomatiseerde kwaliteitsdrempels
Onderzoek van OpenAI naar zelfontwikkelende agenten beveelt aan om optimalisatiecycli voort te zetten totdat de kwaliteitsdrempels >80% positieve feedback bereiken of nieuwe iteraties minimale verbetering laten zien. Analyseplatforms volgen deze statistieken en geven een signaal wanneer verdere optimalisatie geen meerwaarde meer oplevert.

Verlaag de kosten van je LLM-opleiding met de juiste ingenieurspartner.
Veel bedrijven gebruiken LLM-analysetools om het gebruik, het tokenverbruik en de modelprestaties te monitoren, maar de grootste kostenbesparingen komen meestal voort uit de manier waarop de modellen in eerste instantie worden gebouwd en geïntegreerd. Dit is waar AI Superieur Ze zijn er vaak bij betrokken. Hun team werkt aan de technische laag achter LLM-systemen: het ontwerpen van aangepaste modellen, het voorbereiden van trainingsdata, het verfijnen van architecturen en het integreren van LLM's in bestaande workflows, zodat bedrijven de prestaties en operationele kosten effectiever kunnen beheersen.
Als u de LLM-uitgaven in 2026 wilt verlagen, is het wellicht de moeite waard om te bekijken hoe uw modellen worden getraind, geïmplementeerd en gemonitord. Een technische audit of architectuurbeoordeling kan vaak onnodige inferentiekosten, inefficiënte pipelines of slecht geoptimaliseerde modellen aan het licht brengen.
Praat met AI Superieur Als u uw huidige LLM-opzet wilt evalueren en praktische manieren wilt vinden om de operationele kosten op lange termijn te verlagen.
Vergelijking van toonaangevende LLM-analyseplatforms
Het landschap van analyseplatformen omvat gespecialiseerde observability-tools, oplossingen die specifiek voor cloudproviders zijn ontwikkeld en open-source alternatieven. Elke categorie biedt specifieke voordelen.
Native oplossingen van de cloudprovider
AWS, Google Cloud en Azure bieden geïntegreerde analyses binnen hun bredere AI-platformen. Het gebruik en de kosten van Amazon Bedrock worden gemonitord via AWS Billing and Cost Management-rapporten en AWS Cost Explorer API's, waardoor programmatische toegang tot organisatiebrede uitgavengegevens mogelijk is.
Google Conversational Insights biedt twee prijsniveaus: Standaard en Enterprise. De kosten variëren afhankelijk van het type interactie. Chatgesprekken worden per bericht gefactureerd, terwijl spraakgesprekken per minuut worden gefactureerd. Het Enterprise-niveau voegt Quality AI-functionaliteiten toe met ondersteuning voor maximaal 50 aangepaste evaluaties per gesprek.
Native oplossingen integreren naadloos met bestaande cloudinfrastructuur, maar missen mogelijk geavanceerde optimalisatiefuncties die wel aanwezig zijn in gespecialiseerde platforms.
Gespecialiseerde observatieplatformen
Speciaal ontwikkelde LLM-observatieplatforms richten zich uitsluitend op het monitoren en optimaliseren van AI-workloads. Deze tools bieden doorgaans diepere analyses, geavanceerdere optimalisatiefuncties en leverancieronafhankelijke ondersteuning voor meerdere LLM-aanbieders.
Belangrijke functionaliteiten zijn onder andere het traceren van verzoeken in gedistribueerde systemen, latentieanalyse, foutpercentagebewaking en kostenallocatie per functie of team. De beste platforms leveren bruikbare inzichten in plaats van alleen ruwe statistieken.
Open source alternatieven
Open-source analysetools zijn aantrekkelijk voor organisaties met specifieke behoeften of budgetbeperkingen. Deze oplossingen bieden transparantie en aanpassingsmogelijkheden, maar vereisen wel een grotere technische investering voor implementatie en onderhoud.
Communitygedreven ontwikkeling betekent dat functies evolueren op basis van daadwerkelijke gebruikersbehoeften, hoewel de ondersteuning en documentatie voor bedrijven mogelijk achterlopen op commerciële alternatieven.
| Platformtype | Het beste voor | Belangrijkste voordeel | Belangrijkste beperking
|
|---|---|---|---|
| Cloud-native | Implementaties in één cloudomgeving | Diepe integratie | Vendor lock-in |
| Gespecialiseerde gereedschappen | Multimodelomgevingen | Geavanceerde optimalisatie | Extra kosten |
| Open source | Aangepaste vereisten | Transparantie en controle | Onderhoudslast |
Implementatie-best practices voor kostenanalyse
Het effectief inzetten van analysetools vereist zorgvuldige planning en realistische verwachtingen ten aanzien van de tijdlijnen voor optimalisatie.
Het vaststellen van basisstatistieken
Organisaties kunnen niet optimaliseren wat ze niet meten. Begin daarom met het bijhouden van het totale tokenverbruik, de gemiddelde kosten per gebruikersinteractie en de verdeling van de uitgaven over verschillende functies of gebruiksscenario's.
Een basismeting moet minimaal twee weken duren om representatieve gebruikspatronen vast te leggen. Seizoensschommelingen of pieken in het gebruik beïnvloeden de gemiddelden, dus langere meetperioden leveren betrouwbaardere gegevens op.
Realistische optimalisatiedoelen stellen
Onderzoek van het MIT-IBM Watson AI Lab benadrukt het belang van het bepalen van het benodigde rekenbudget en de gewenste modelnauwkeurigheid vóór de optimalisatie begint. Teams moeten vaststellen of een gemiddelde relatieve fout van 4% of een fout van 20% aan hun behoeften voldoet.
Agressieve kostenbesparingsdoelstellingen gaan soms ten koste van de functionaliteit. Het doel is niet minimale uitgaven, maar optimale uitgaven voor de vereiste kwaliteitsniveaus.
Gefaseerde uitrol implementeren
Optimaliseer niet alles tegelijk. Test cachingstrategieën eerst op endpoints met een hoog volume, meet de impact en breid vervolgens uit naar andere gebieden.
Geleidelijke uitrol zorgt ervoor dat variabelen geïsoleerd blijven en maakt het gemakkelijker om kostenbesparingen toe te schrijven aan specifieke veranderingen. Het minimaliseert ook het risico: als optimalisatie een negatieve impact heeft op de gebruikerservaring, blijft de impact beperkt.
Continue monitoring en iteratie
Kostenoptimalisatie is geen eenmalig project. Gebruikspatronen veranderen, nieuwe modellen met andere prijzen worden gelanceerd en toepassingsvereisten wijzigen.
Plan driemaandelijkse evaluaties van analysedata om opkomende patronen te identificeren. Automatisering vermindert handmatige werkzaamheden: platforms die automatisch optimalisatiemogelijkheden signaleren, besparen aanzienlijk veel tijd.
Geavanceerde optimalisatietechnieken
Naast basiskostenbewaking bieden geavanceerde technieken extra besparingen voor complexe implementaties.
Multi-agent model routing
Onderzoek naar optimalisatie vanuit natuurlijke taal met behulp van LLM-gestuurde agenten toont aan dat het combineren van diverse modellen leidt tot prestatieverbeteringen. Een framework behaalde een nauwkeurigheid van 88,11 TP3T op de NLP4LP-dataset en 82,31 TP3T op Optibench, waarmee de foutpercentages met respectievelijk 581 TP3T en 521 TP3T werden verlaagd ten opzichte van eerdere resultaten door samenwerking tussen meerdere agenten.
Analyseplatformen kunnen intelligente routering implementeren die verzoeken doorstuurt naar het meest kostenefficiënte model dat elke taak aankan. Eenvoudige query's worden doorgestuurd naar snelle, goedkope modellen. Complexere redeneertaken worden doorgestuurd naar krachtigere – en duurdere – alternatieven.
Aandachtsoptimalisatie voor gegroepeerde zoekopdrachten
Voor organisaties die zelf gehoste modellen gebruiken, heeft de configuratie van het aandachtmechanisme een aanzienlijke impact op de kosten. Onderzoek naar kostenoptimale aandacht voor gegroepeerde query's bij het modelleren van lange contexten laat zien dat het gebruik van minder aandachtskoppen bij het opschalen van de modelgrootte in scenario's met lange contexten zowel het geheugengebruik als het aantal FLOPs met meer dan 50% vermindert in vergelijking met de GQA-configuratie van Llama-3, zonder dat de modelprestaties achteruitgaan.
Dit is van belang voor maatwerkimplementaties, waarbij de infrastructuurkosten een aanzienlijk deel uitmaken van de totale uitgaven.
Geautomatiseerde omscholingslussen
OpenAI-onderzoek naar zelfontwikkelende agenten introduceert herhaalbare hertrainingslussen die uitzonderlijke gevallen vastleggen en fouten corrigeren zonder constante menselijke tussenkomst. Systemen die output van lage kwaliteit identificeren en automatisch hertrainen op basis van feedback, verminderen zowel het foutpercentage als de verspilling van tokens door het opnieuw genereren van mislukte reacties.
Analyseplatforms die de kwaliteit van de output bijhouden, maken deze geautomatiseerde verbeteringscycli mogelijk, wat na verloop van tijd steeds grotere kostenbesparingen oplevert.
Het rendement van investeringen in data-analyse evalueren
Analyseplatformen brengen extra kosten met zich mee: abonnementen, integratiekosten en doorlopend onderhoud. Organisaties hebben kaders nodig om te evalueren of investeringen een positief rendement opleveren.
Het berekenen van het break-evenpunt
Onderzoek naar kosten-batenanalyses van on-premise LLM-implementaties onderzoekt wanneer organisaties quitte spelen ten opzichte van commerciële diensten. Dezelfde methodologie is van toepassing op analysetools: bereken de maandelijkse LLM-uitgaven, schat het haalbare kostenbesparingspercentage op basis van optimalisatiefuncties en vergelijk dit met de abonnementskosten van het platform.
Als de maandelijkse kosten voor LLM bijvoorbeeld $50.000 bedragen en analyses een reductie van 30% mogelijk maken door middel van caching en modelselectie, dan levert dat een maandelijkse besparing op van $15.000. Een analyseplatform dat $2.000 per maand kost, is dan direct rendabel en levert een netto maandelijks voordeel op van $13.000.
Het kwantificeren van operationele efficiëntiewinsten
Kostenbesparing is slechts een deel van de waardevergelijking. Analyseplatforms verminderen de tijd die engineers handmatig besteden aan het onderzoeken van prestatieproblemen, het debuggen van kostbare query's en het genereren van gebruiksrapporten.
Uit brancherapporten blijkt dat teams een aanzienlijke productiviteitsverhoging realiseren wanneer de juiste analyses knelpunten bij het debuggen wegnemen. Tijdsbesparing vertaalt zich direct in lagere arbeidskosten of een hogere ontwikkelsnelheid.
Factoring van de waarde van risicobeperking
Budgetwaarschuwingen en detectie van afwijkingen voorkomen kostenrampen. Organisaties zonder adequate monitoring ontdekken uit de hand gelopen kosten pas dagen of weken nadat ze zich voordoen – wanneer de facturen binnenkomen.
De waarde van het vermijden van één enkele onverwachte rekening van $100.000 rechtvaardigt een aanzienlijke investering in analyses. De voordelen van risicobeperking zijn moeilijker te kwantificeren, maar hebben een wezenlijke invloed op de totale eigendomskosten.
Analyses op locatie versus in de cloud
Organisaties die zelfgehoste LLM's inzetten, hebben andere analysebehoeften dan organisaties die uitsluitend commerciële API's gebruiken.
Voordelen van cloudanalyse
Cloudgebaseerde analyseplatformen vereisen minimale installatie, schalen automatisch en ontvangen continu functie-updates zonder handmatige tussenkomst. Ze zijn zeer geschikt voor organisaties die gebruikmaken van commerciële LLM-diensten, waarbij tracking op API-niveau voldoende inzicht biedt.
Integratie houdt doorgaans in dat er SDK-aanroepen worden toegevoegd of dat verzoeken via gatewaydiensten worden gerouteerd – voor de meeste ontwikkelteams is dit vrij eenvoudig.
Overwegingen bij implementatie op locatie
Zelfgehoste analyses zijn geschikt voor organisaties met strenge eisen op het gebied van gegevensbeheer of voor organisaties die intern eigen modellen gebruiken. Volgens onderzoek van Stanford naar intelligentie per watt kunnen lokale LLM's (Large Learning Machines) 88,71 TP3T (Twin Pounds per Three Tobs) aan chat- en redeneertaken in één beurt nauwkeurig verwerken, waardoor zelfhosting voor veel toepassingen haalbaar is.
Maar on-premise implementaties brengen een grotere complexiteit met zich mee. Organisaties hebben infrastructuur nodig voor het analyseplatform zelf, moeten updates handmatig uitvoeren en hebben specialistische expertise nodig om de systemen te onderhouden.
Hybride benaderingen
Veel organisaties hanteren hybride strategieën: cloudanalyse voor commercieel gebruik van LLM (Learning Learning Models) in combinatie met on-premise monitoring voor zelfgehoste modellen. Dit biedt een goede balans tussen gebruiksgemak en controle, terwijl tegelijkertijd een volledig overzicht van de gehele AI-stack behouden blijft.
Toekomstige trends in kostenanalyse voor LLM-programma's
Het analyselandschap blijft zich snel ontwikkelen, omdat organisaties steeds geavanceerdere mogelijkheden eisen.
Voorspellende kostenmodellering
De volgende generatie platformen zal toekomstige kosten voorspellen op basis van gebruikstrends, applicatiewijzigingen en prijsveranderingen van modellen. Proactieve waarschuwingen informeren teams voordat de kosten stijgen, in plaats van problemen achteraf te melden.
Machine learningmodellen die getraind zijn op historische gebruikspatronen kunnen de maandelijkse uitgaven steeds nauwkeuriger voorspellen, waardoor een betere budgetplanning mogelijk wordt.
Geautomatiseerde optimalisatieagenten
Onderzoek naar geautomatiseerde optimalisatie van op LLM gebaseerde agenten (ARTEMIS) toont systemen aan die continu experimenteren met configuratiewijzigingen, de impact meten en automatisch verbeteringen doorvoeren zonder menselijke tussenkomst.
Deze zelfoptimaliserende systemen zouden een revolutie teweeg kunnen brengen in kostenbeheer door handmatige optimalisatie volledig overbodig te maken. Vroege implementaties laten veelbelovende resultaten zien, maar bevinden zich nog in een experimentele fase.
Geïntegreerde analyse van meerdere aanbieders
Organisaties maken steeds vaker gebruik van meerdere LLM-aanbieders: OpenAI voor sommige taken, Anthropic voor andere, en open-sourcemodellen voor specifieke toepassingen. Het blijft echter een uitdaging om uniforme analyses over alle aanbieders heen te realiseren.
Toekomstige platforms bieden naadloze tracking van meerdere aanbieders, waardoor een eerlijke vergelijking van kosten mogelijk is en intelligente routering tussen leveranciers wordt geboden op basis van realtime prijs- en prestatiegegevens.
Veelvoorkomende implementatie-uitdagingen
Organisaties stuiten op voorspelbare obstakels bij de implementatie van analyseplatformen. Door op deze uitdagingen te anticiperen, wordt een succesvolle implementatie versneld.
Onvolledige gebruiksvermelding
Om bij te houden welk team, welke functie of welke gebruiker specifieke kosten heeft gegenereerd, is instrumentatie in alle applicaties nodig. Veel organisaties registreren in eerste instantie het totale gebruik, maar missen gedetailleerde toewijzing van kosten.
Oplossing: implementeer vanaf het begin consistente tagstandaarden. Voeg metadata toe aan elk LLM-verzoek met vermelding van de bronapplicatie, het gebruikerstype en de functiecategorie.
Alertheidsvermoeidheid
Overgevoelige kostenwaarschuwingen leren teams om meldingen te negeren. Als elke kleine piek in het gebruik alarmen activeert, worden belangrijke waarschuwingen samen met de ruis genegeerd.
Oplossing: stel waarschuwingsdrempels in op basis van statistische significantie in plaats van absolute veranderingen. Een kostenstijging van 10% kan nader onderzoek rechtvaardigen als deze gedurende meerdere dagen aanhoudt, maar niet als deze slechts gedurende één uur optreedt.
Optimalisatieanalyse-verlamming
Sommige teams besteden meer tijd aan het analyseren van optimalisatiemogelijkheden dan aan het implementeren ervan. Een gedetailleerd onderzoek van elke potentiële verbetering werkt daardoor contraproductief.
Oplossing: pas de 80/20-regel toe. Concentreer je eerst op de optimalisaties met de grootste impact, zoals caching voor repetitieve workloads en modelselectie voor endpoints met een hoog volume. Kleinere optimalisaties kunnen wachten.
Veelgestelde vragen
Hoeveel kunnen organisaties realistisch gezien de kosten van LLM verlagen met behulp van analysetools?
Kostenbesparingen variëren aanzienlijk, afhankelijk van de initiële efficiëntie en de kenmerken van de werkbelasting. Organisaties met repetitieve query's en zonder bestaande caching kunnen 50-701 TP3T besparen door alleen al prompt caching toe te passen. Organisaties die al basisoptimalisaties implementeren, zien doorgaans nog eens 20-401 TP3T extra besparingen door strategische modelselectie en contextoptimalisatie. De sleutel is het identificeren van de plekken waar uw specifieke implementatie resources verspilt – analyseplatforms zijn uitermate geschikt om deze mogelijkheden aan het licht te brengen.
Werken analyseplatformen met alle aanbieders van LLM-programma's?
De meeste gespecialiseerde analyseplatformen ondersteunen grote commerciële aanbieders zoals OpenAI, Anthropic, Google en AWS Bedrock via standaard API-integraties. Cloud-native oplossingen werken doorgaans alleen binnen hun respectievelijke ecosystemen – AWS-tools voor Bedrock, Google-tools voor Vertex AI. Voor zelfgehoste modellen of kleinere aanbieders hangt de compatibiliteit af van de vraag of het platform mogelijkheden voor aangepaste integratie biedt of specifieke instrumentatie vereist.
Wat is de gebruikelijke implementatietijdlijn voor LLM-analyse?
De basisintegratie van analyses duurt 1-2 weken voor cloudgebaseerde platforms die gebruikmaken van standaard SDK's. Dit omvat de installatie, de implementatie van basistags en de initiële configuratie van het dashboard. Een uitgebreide implementatie met sessietracking, aangepaste attributie en automatisering van optimalisaties duurt 4-8 weken, afhankelijk van de complexiteit van de applicatie. Organisaties met gedistribueerde systemen of aangepaste LLM-implementaties moeten rekening houden met 2-3 maanden voor een volledige uitrol, inclusief testen en verfijning.
Zouden kleine teams moeten investeren in speciale analyseplatformen?
Teams die maandelijks minder dan 1.000 tot 5.000 dollar uitgeven aan LLM-gebruik, kunnen de kosten vaak adequaat beheren met standaardtools van de cloudprovider en handmatige monitoring. De complexiteit en kosten van dedicated platforms wegen op deze schaal mogelijk niet op tegen de voordelen. Zodra de maandelijkse LLM-kosten de 1.000 tot 1.000 tot 1.000 dollar overschrijden, leveren gespecialiseerde analyses doorgaans een positief rendement op investering (ROI) op door geautomatiseerde optimalisatie en gedetailleerd inzicht. Bereken uw potentiële besparingen: als de realistische kostenbesparingen de abonnementskosten van het platform met een factor 3 of meer overtreffen, is de investering de moeite waard.
Hoe gaan analysetools om met snelheidsbeperking en quotabeheer?
Geavanceerde platforms bevatten aangepaste functies voor snelheidsbeperking die voorkomen dat applicaties de geconfigureerde gebruikslimieten overschrijden. Deze systemen onderscheppen verzoeken voordat ze de LLM-providers bereiken en weigeren of plaatsen overtollig verkeer in een wachtrij op basis van gedefinieerde beleidsregels. Snelheidsbeperking voorkomt zowel kostenoverschrijdingen als het uitputten van API-quota van providers. Sommige platforms implementeren intelligente wachtrijen die prioriteit geven aan waardevolle verzoeken tijdens perioden met beperkte capaciteit.
Kunnen analyseplatformen de latentie verlagen én de kosten verlagen?
Ja, veel kostenoptimalisaties verbeteren tegelijkertijd de responstijden. Caching levert de meest dramatische verbeteringen in latentie op, waardoor de responstijd voor gecachede query's volgens onderzoek van AWS met wel 851 TP3T wordt verkort. Kleinere, snellere modellen die voor de juiste taken worden geselecteerd, reageren vaak sneller dan overgekwalificeerde grensmodellen, terwijl ze ook nog eens minder kosten. Contextoptimalisatie verlaagt zowel de kosten voor tokenverwerking als de tijd die nodig is om onnodig grote invoer te verwerken. De beste analyseplatforms brengen kansen aan het licht waar kosten- en prestatieverbeteringen samenvallen.
Welke meetgegevens zijn het belangrijkst voor kostenbeheer bij een LLM-opleiding?
Vier meetwaarden vormen de basis voor effectief kostenbeheer: de totale maandelijkse uitgaven geven inzicht in de algehele impact op het budget; de kosten per gebruikersinteractie onthullen de kosteneffectiviteit van verschillende functionaliteiten; de verhouding tussen input- en outputtokens identificeert dure responspatronen; en de cache-hitrate meet hoe effectief caching overbodige verwerking vermindert. Samen stellen deze meetwaarden teams in staat om zowel de totale kosten als specifieke optimalisatiemogelijkheden te begrijpen. Geavanceerde teams voegen daar de nauwkeurigheid van de modelselectie aan toe – door bij te houden hoe vaak goedkopere modellen aan de kwaliteitsdrempels voldoen.
Conclusie
LLM-analysetools met robuuste kostenoptimalisatiefuncties zijn geëvolueerd van handige monitoringoplossingen tot essentiële infrastructuur voor elke organisatie die AI op grote schaal inzet. De combinatie van realtime kostenbewaking, prestatie-observatie en geautomatiseerde optimalisatiemogelijkheden levert direct rendement op voor teams die aanzienlijke bedragen uitgeven aan API's voor taalmodellen.
Het korte antwoord? Organisaties kunnen de kosten van LLM met 20-70% verlagen door systematische optimalisatie met behulp van de juiste analyses – zonder in te leveren op responskwaliteit of functionaliteit. Maar succes vereist meer dan alleen het installeren van een dashboard. Effectief kostenbeheer vereist duidelijke basisstatistieken, realistische optimalisatiedoelen, geleidelijke implementatie en continue monitoring.
Onderzoek van MIT, Carnegie Mellon en toonaangevende AI-bedrijven toont consequent aan dat de combinatie van strategische modelselectie, intelligente caching, contextoptimalisatie en geautomatiseerde routering cumulatieve voordelen oplevert. Teams die kostenoptimalisatie als een doorlopende discipline beschouwen in plaats van een eenmalig project, realiseren duurzame kostenbesparingen en behouden tegelijkertijd de flexibiliteit om nieuwe modellen en mogelijkheden te implementeren zodra deze beschikbaar komen.
Het aanbod aan analyseplatformen biedt oplossingen voor elk implementatiescenario: van cloud-native tools die geïntegreerd zijn met grote providers tot gespecialiseerde observatieplatformen die omgevingen met meerdere leveranciers ondersteunen, en open-source alternatieven voor specifieke behoeften. De keuze voor het juiste platform hangt af van de implementatiearchitectuur, budgetbeperkingen en de mate van optimalisatie.
Begin met het vaststellen van de huidige basiskosten en gebruikspatronen. Identificeer de optimalisatiemogelijkheden met de grootste impact, specifiek voor uw werklast. Kies analysetools die bruikbare inzichten opleveren in plaats van teams te overladen met ruwe cijfers. Voer optimalisaties geleidelijk door, meet de resultaten en herhaal het proces op basis van data in plaats van aannames.
Organisaties die uitblinken in kostenbeheer van taalmodellen hebben een gemeenschappelijke eigenschap: ze implementeren uitgebreide instrumenten, analyseren continu en optimaliseren systematisch. Naarmate taalmodellen geavanceerder en wijdverspreider worden, onderscheidt deze discipline duurzame AI-implementaties van dure experimenten die nooit de productieschaal bereiken.
Klaar om uw LLM-kosten te optimaliseren? Begin met meten – u kunt immers niets verbeteren als u het niet bijhoudt. Kies een analyseplatform dat aansluit op uw infrastructuur, implementeer basisregistratie en laat de data onthullen waar uw specifieke implementatie resources verspilt. De inzichten zullen u verrassen en de besparingen zullen de inspanning rechtvaardigen.