Korte samenvatting: Strategieën voor kostenoptimalisatie van LLM helpen organisaties de operationele kosten te verlagen en tegelijkertijd de AI-prestaties te behouden. Belangrijke benaderingen zijn onder andere promptoptimalisatie, modelroutering, caching, kwantisering en infrastructuuroptimalisatie. Onderzoek toont aan dat deze technieken de kosten met 10-501 TP3T kunnen verlagen door middel van methoden zoals promptcompressie, strategische modelselectie en efficiënt tokenbeheer.
De operationele kosten van het draaien van grote taalmodellen in een productieomgeving kunnen snel oplopen. Wat begint als een veelbelovend proof-of-concept, wordt een financiële last wanneer het wordt opgeschaald naar miljoenen API-aanroepen per maand.
Organisaties die LLM's inzetten, worden geconfronteerd met een harde realiteit: verwerkingskosten die lineair toenemen met het gebruik. Voor een model met ongeveer 175 miljard parameters zou de benodigde geheugenruimte ongeveer 350 GB (voor FP16) of 700 GB (voor FP32) bedragen. Dat is alleen de opslag; de werkelijke inferentiekosten lopen op met elk verwerkt token.
Maar het punt is: kostenoptimalisatie betekent niet dat de prestaties eronder lijden. Strategische benaderingen kunnen de kosten drastisch verlagen, terwijl de kwaliteit van de output behouden blijft of zelfs verbetert.
Inzicht in LLM-prijsmodellen
De meeste cloudgebaseerde LLM-diensten rekenen per token. Gebruikers betalen apart voor invoertokens (de prompt) en uitvoertokens (het gegenereerde antwoord). Dit betaalmechanisme per token zorgt voor interessante dynamiek.
Onderzoek van het MIT-IBM Watson AI Lab (in “A Hitchhiker's Guide to Scaling Law Estimation”, 2024/2025) toont aan dat een gemiddelde relatieve fout (ARE) van ongeveer 4% de best haalbare voorspellingsnauwkeurigheid vertegenwoordigt bij het schatten van schaalwetten (d.w.z. het voorspellen van het verlies van grote modellen op basis van kleinere modellen uit dezelfde familie). Dit is grotendeels te wijten aan willekeurige zaadruis, die op zichzelf al tot wel 4% verschillen in het uiteindelijke verlies kan veroorzaken, zelfs bij identieke trainingsconfiguraties. Een ARE tot 20% blijft nuttig voor veel praktische besluitvormingstaken bij modelselectie en budgettoewijzing. Deze overwegingen zijn belangrijk bij het evalueren van de kosten-prestatieverhouding tussen modelfamilies of -groottes.
Gecachede invoertokens kosten doorgaans ongeveer 10 procent van de prijs van normale invoertokens. Deze prijsverschillen creëren mogelijkheden voor aanzienlijke besparingen door strategische caching-strategieën.
De prijsstructuur betekent ook dat de kosten voor het genereren van output voor de meeste aanbieders hoger liggen dan de kosten voor het verwerken van input. Deze fundamentele waarheid vormt de basis voor diverse optimalisatiestrategieën die het tokenverbruik verschuiven van dure outputs naar goedkopere inputs.
Snelle optimalisatietechnieken
Prompt engineering is de meest voor de hand liggende manier om kosten te besparen. Slecht gestructureerde prompts verspillen tokens en genereren onnodige output.
Comprimeren zonder context te verliezen
Uitgebreide prompts verbruiken veel invoertokens. Een verzoek om een productbeschrijving zou bijvoorbeeld kunnen luiden: "Genereer een aantrekkelijke productbeschrijving voor een smartphone. Deze moet de belangrijkste kenmerken en specificaties vermelden, zoals de schermgrootte, cameraresolutie, batterijduur en opslagcapaciteit. Probeer de beschrijving boeiend en overtuigend te maken."“
De geoptimaliseerde versie: "Genereer een aantrekkelijke productbeschrijving voor een smartphone met een 6,5-inch scherm, een 48MP-camera, een 5000mAh-batterij en 256GB-opslag."“
Dezelfde intentie, minder tokens, specifiekere instructies. Deze aanpak verlaagt de inputkosten en verbetert vaak de outputkwaliteit door meer precisie.
Structureer de output strategisch
Gestructureerde output minimaliseert tokenverspilling. In plaats van te vragen om vrije antwoorden die geparseerd moeten worden, kunt u JSON of specifieke formaten opvragen. Deze techniek wordt toegepast in productiesystemen waar E-Agent frameworks gestructureerde output gebruiken om de lengte van kandidaat-antwoorden te minimaliseren.
Volgens de documentatie van OpenAI over het finetunen van reinforcement learning, zorgen duidelijke taakspecificaties met verifieerbare antwoorden voor efficiënter modelgedrag. Expliciete beoordelingscriteria en codegebaseerde beoordelaars meten het functionele succes en verminderen tegelijkertijd onnodige omslachtigheid.
| Prompttype | Tokengebruik | kostenimpact | Het beste voor
|
|---|---|---|---|
| Uitgebreid, ongestructureerd | Hoog | Basislijn | Verkenningsfase |
| Gecomprimeerd, gestructureerd | Medium | 20-30%-reductie | Productie-implementaties |
| Opgeslagen met structuur | Laag | 40-50%-reductie | Repetitieve taken |
Strategische modelselectie en routering
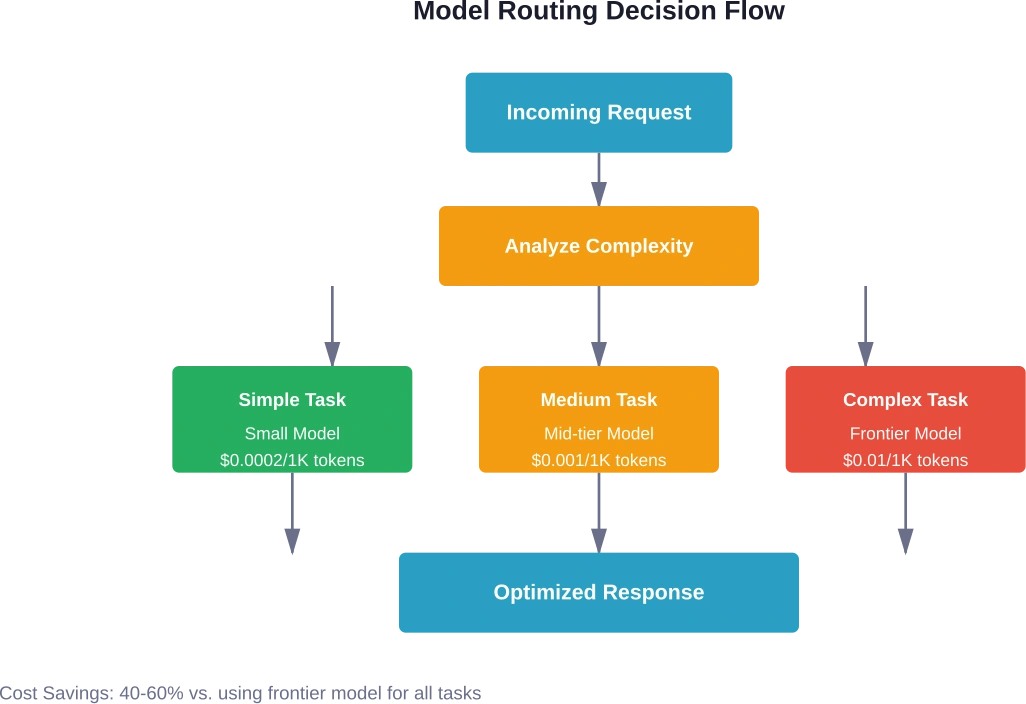
Niet elke taak vereist het krachtigste beschikbare model. Modelroutering – het doorsturen van verschillende verzoeken naar modellen met de juiste capaciteit – levert aanzienlijke kostenbesparingen op.
Stem de mogelijkheden van het model af op de complexiteit van de taak.
Voor eenvoudige classificatietaken zijn geen geavanceerde modellen nodig. Sentimentanalyse, basissamenvatting of categorietagging werken prima met kleinere, goedkopere alternatieven. Reserveer dure modellen voor complexe redeneringen, genuanceerde generatie of gespecialiseerde kennistaken.
Onderzoek naar de efficiëntie van modellen toont aan dat herontworpen architecturen vergelijkbare prestaties kunnen leveren op verschillende schaalniveaus. De architectuur van het model speelt een cruciale rol, die verder gaat dan alleen het aantal parameters.
Productiesystemen melden dat ze OpenAI-, Anthropic- en lokale modelimplementaties combineren op basis van taakvereisten, met meer dan 2 miljoen API-aanroepen per maand. Deze heterogene aanpak optimaliseert de kosten-prestatieverhouding voor verschillende gebruiksscenario's.
Implementeer intelligente routeringslogica.
Geautomatiseerde routeringssystemen analyseren binnenkomende verzoeken en selecteren de juiste modellen. AI Enabler-platforms bieden geautomatiseerde optimalisatie van zowel de LLM-selectie als de onderliggende infrastructuur, waardoor handmatige besluitvorming overbodig wordt.
De routeringslogica houdt rekening met factoren zoals de complexiteit van de query, de vereiste nauwkeurigheid, de tolerantie voor latentie en de actuele prijzen. Dynamische routering past zich aan veranderende omstandigheden aan zonder handmatige tussenkomst.
Cachestrategieën voor repetitieve workloads
Caching levert onmiddellijke en aanzienlijke kostenbesparingen op voor applicaties met repetitieve patronen. Productiesystemen rapporteren een cache-hitpercentage van 40 procent, waarbij sommige implementaties maandelijks ongeveer 1.400.300 aan API-kosten besparen.
Implementeer semantische caching.
Basiscaching slaat exacte overeenkomsten met prompts op. Semantische caching gaat een stap verder: het herkent vergelijkbare vragen, zelfs met een andere formulering. "Hoe reset ik mijn wachtwoord?" en "Wat is de procedure voor wachtwoordherstel?" leveren hetzelfde antwoord op uit de cache.
Deze aanpak is met name gunstig voor klantenservice, documentatiezoeksystemen en FAQ-systemen, waar gebruikers identieke vragen op verschillende manieren formuleren.
Cachesysteemprompts en context
Systeemprompts die het gedrag van een model definiëren, veranderen zelden. Door deze in de cache op te slaan, wordt overbodige verwerking verminderd. Context die in meerdere verzoeken voorkomt, zoals bedrijfsinformatie, productcatalogi of stijlgidsen, moet actief in de cache worden opgeslagen.
Contextuele engineeringbenaderingen laten zien dat subagenten uitgebreid kunnen verkennen, waarbij ze tienduizenden tokens gebruiken, maar gecondenseerde samenvattingen van 1.000-2.000 tokens teruggeven. Het cachen van deze tussenresultaten voorkomt dat dezelfde informatie herhaaldelijk opnieuw wordt opgevraagd.
Vroegtijdige stopzetting en vermogensregeling
Modellen genereren vaak meer inhoud dan nodig. Technieken voor vroegtijdige stopzetting detecteren wanneer er voldoende informatie is gegenereerd en stoppen de generatie.
Onderzoek naar ES-CoT (Early Stopping Chain-of-Thought) toont methoden aan om convergentie van antwoorden te detecteren en de generatie vroegtijdig te stoppen. Wanneer opeenvolgende identieke stapantwoorden convergentie aangeven, wordt de generatie beëindigd, waardoor de kosten voor inferentietokens worden verlaagd met behoud van een vergelijkbare nauwkeurigheid.
De techniek werkt door het model bij elke redeneerstap te vragen zijn huidige antwoord te geven. De lengte van een reeks identieke antwoorden dient als maatstaf voor convergentie. Sterke toenames in de lengte van een reeks die de minimale drempelwaarden overschrijden, leiden tot beëindiging.
Stel maximale tokenlimieten in
Beperk de lengte van de uitvoer expliciet via API-parameters. Dit voorkomt dat er te veel tokens worden gegenereerd voor onnodige verwerking. Verschillende taken vereisen verschillende limieten; pas deze aan op basis van de specifieke toepassing.
Classificatie vereist 10 tokens. Samenvatting heeft er mogelijk 200 nodig. Het genereren van uitgebreide teksten kan er meer dan 1000 rechtvaardigen. Maar standaardinstellingen die onbeperkte uitvoer toestaan, leiden tot verspilling.
Kwantisatie en modelcompressie
Kwantisatie verlaagt de precisie van modelgewichten, waardoor de geheugenvereisten en rekenkosten afnemen. LLM's gebruiken doorgaans FP16-precisie om de geheugenvereisten te verlagen ten opzichte van FP32. Verdere kwantisatie naar INT8 of INT4 levert nog meer besparingen op.
Kwantisering na de training
Sparsheid na de training verlaagt de modelkosten door gewichten uit dichte netwerken te verwijderen. Onderzoek naar het induceren van sparsiteit demonstreert benaderingen voor sparsiteit na de training op modellen die zijn getest met een enkele NVIDIA RTX A6000 GPU (48 GB).
Van nature voorkomende dichte matrices missen een hoge mate van spaarzaamheid, waardoor het direct verwijderen van gewichten storend is. Geavanceerde methoden induceren spaarzaamheidspatronen die de mogelijkheden van het model behouden en tegelijkertijd de rekenkundige vereisten verlagen.
Destillatie voor specialistische taken
Door kennisdestillatie worden kleinere modellen gecreëerd die grotere modellen nabootsen voor specifieke taken. Het leerlingmodel leert van de output van de leraar en legt taakrelevant gedrag vast in minder parameters.
Autodistill-frameworks maken het mogelijk om gespecialiseerde modellen te ontwerpen met aanzienlijk lagere inferentiekosten door middel van kennisdestillatiebenaderingen.
| Techniek | Complexiteit | Kostenreductie | Kwaliteitsimpact
|
|---|---|---|---|
| Snelle optimalisatie | Laag | 20-30% | Vaak verbetert |
| Modelroutering | Medium | 40-60% | Minimaal |
| Caching | Laag | 30-50% | Geen |
| Vroegtijdig stoppen | Medium | 30-40% | Minimaal |
| Kwantisatie | Hoog | 50-70% | 5-10%-degradatie |
Executor-Verifier-architecturen
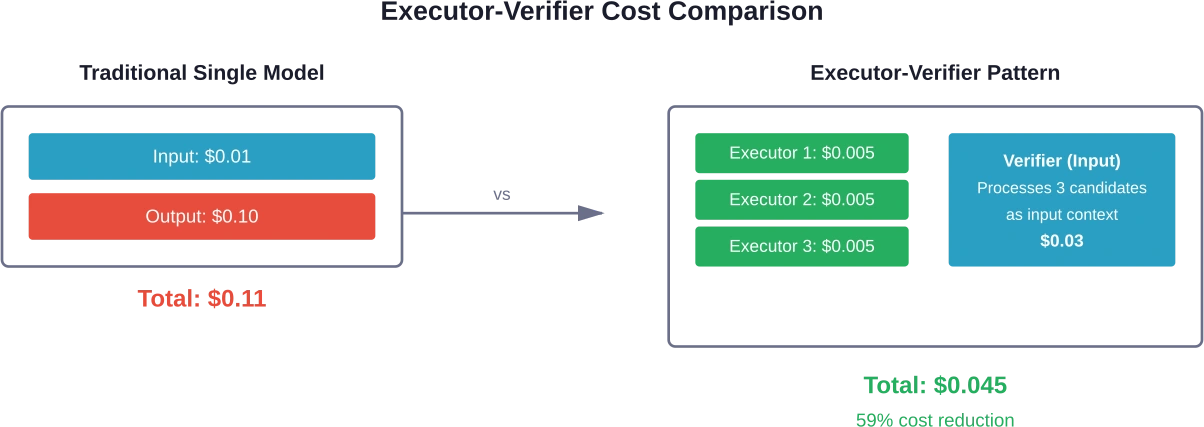
Het executor-verifier-paradigma verschuift het verbruik van tokens van dure outputs naar goedkopere inputs. Meerdere kleine, lokaal geïmplementeerde modellen genereren kandidaat-antwoorden. Een krachtig, cloudgebaseerd model verifieert welke kandidaat correct is.
E-Agent frameworks tonen aan dat deze aanpak het tokengebruik met 10-50 procent vermindert in vergelijking met standaardmethoden. De prijsasymmetrie tussen input- en outputtokens maakt verificatie goedkoper dan generatie.
Kleine uitvoerders draaien lokaal of op goedkope infrastructuur. Ze genereren parallel meerdere diverse kandidaten. De verificator verwerkt alle kandidaten als inputcontext – tegen lagere tarieven voor inputtokens – en selecteert of synthetiseert het beste antwoord.
Deze architectuur is met name geschikt voor taken met duidelijke correctheidscriteria: wiskundige problemen, codegeneratie, feitelijke vragen of het extraheren van gestructureerde gegevens.
Infrastructuur- en implementatieoptimalisatie
Naast optimalisaties op modelniveau hebben infrastructuurkeuzes een aanzienlijke invloed op de kosten.
Optimaliseer de hardwareselectie
De keuze van de GPU is belangrijk. NVIDIA TensorRT-LLM biedt Python API's om LLM's te definiëren met geavanceerde optimalisaties voor efficiënte inferentie op NVIDIA GPU's. Tests tonen een aanzienlijke prestatieverbetering op de juiste hardware.
Experimenten met enkele NVIDIA RTX A6000 GPU's met 48 GB geheugen tonen aan dat inferentie mogelijk is voor modellen die zorgvuldig resourcebeheer vereisen. Door de hardware op de juiste manier te dimensioneren, wordt overprovisionering voorkomen en blijft de latentie acceptabel.
Batchverwerking indien mogelijk
Realtimevereisten creëren soms kunstmatige beperkingen. Het gelijktijdig verwerken van meerdere verzoeken in batches verbetert de doorvoer en verlaagt de kosten per verzoek. Taken zoals contentmoderatie, classificatie of analyse tolereren vaak kleine vertragingen, waardoor batchverwerking mogelijk is.
Overweeg zelfhosting voor schaalvergroting.
Bij voldoende volume wordt zelfhosting economisch haalbaar. De prijsstelling van cloud-API's omvat aanzienlijke marges. Organisaties die maandelijks miljoenen verzoeken verwerken, zouden een eigen infrastructuur moeten overwegen.
Het break-evenpunt hangt af van de technische mogelijkheden, de onderhoudskosten en het gebruikspatroon. Potentiële besparingen op grote schaal kunnen een grondige analyse rechtvaardigen.
Iteratieve verfijningssystemen
Parallel-Distill-Refine (PDR)-systemen genereren parallel diverse concepten, distilleren deze tot afgebakende werkruimtes en verfijnen ze op basis van die werkruimte. Deze aanpak levert vaak betere prestaties op dan een lange denkketen, terwijl de latentie en de contextgrootte lager blijven.
Sequentiële verfijning verbetert iteratief een enkele kandidaat-oplossing zonder permanente werkruimte. Tests op wiskundige taken tonen aan dat iteratieve pipelines de basisprestaties van single-pass-methoden overtreffen bij vergelijkbare sequentiële budgetten. Shallow PDR levert de grootste winst op: een verbetering van ongeveer 10 procent op uitdagende probleemsets.
Deze methoden beschouwen modellen als verbeteringsoperatoren met continue strategieën. Genereer vier kortere antwoorden en combineer hun sterke punten in één superieur antwoord. Dit presteert vaak beter dan het genereren van één lang antwoord, terwijl er minder tokens nodig zijn.
Continue monitoring en optimalisatie
Kostenoptimalisatie is geen eenmalige actie. Continue monitoring identificeert nieuwe mogelijkheden en spoort terugvallen op.
Volg belangrijke statistieken
Monitor het aantal tokens per verzoek, de kosten per transactie, de cache-hitrate en de verdeling van de modelselectie. Stel basiswaarden vast en waarschuw bij afwijkingen. Gebruikspatronen veranderen – optimalisatiestrategieën moeten zich daaraan aanpassen.
Implementeer feedbackloops
Zelfontwikkelende agentframeworks implementeren hertrainingscycli die problemen signaleren en de prestaties verbeteren. Optimalisatie moet doorgaan totdat kwaliteitsdrempels zijn bereikt – doorgaans gericht op >80% aan outputs die positieve feedback ontvangen – of totdat er sprake is van afnemende meeropbrengst, waarbij nieuwe iteraties minimale verbetering laten zien.
Evaluatiegestuurd systeemontwerp gebruikt evaluaties als kernproces voor het creëren van productieklare autonome systemen. Gestructureerde evaluatie met duidelijke meetwaarden maakt systematische verbetering mogelijk zonder giswerk.
Regelmatige modelbeoordeling
Er komen constant nieuwe modellen op de markt met een verbeterde prijs-prestatieverhouding. Kwartaalevaluaties zorgen ervoor dat bij de implementatie gebruik wordt gemaakt van de nieuwste opties. Het grensverleggende model van gisteren wordt morgen een middenklasse alternatief.
Test nieuwe releases aan de hand van bestaande benchmarks. Het overschakelen naar een ander model vereist minimale codeaanpassingen, maar kan aanzienlijke besparingen of verbeteringen in functionaliteit opleveren.
Veelvoorkomende valkuilen die je moet vermijden
Verschillende fouten ondermijnen optimalisatiepogingen:
- Overoptimalisatie puur met het oog op kostenbesparing: Kwaliteit is belangrijk. Een kostenbesparing van 50 procent betekent niets als de kwaliteit van de output zodanig afneemt dat menselijke tussenkomst noodzakelijk is. Meet de nauwkeurigheid altijd in samenhang met de kosten.
- De gevolgen van latentie negeren: Sommige optimalisatietechnieken ruilen latentie in voor kostenbesparing. Batchverwerking en modelroutering verhogen de verwerkingstijd. Zorg ervoor dat de prestaties acceptabel blijven voor de beoogde toepassingen.
- Statische optimalisatiestrategieën: Wat vandaag werkt, werkt morgen misschien niet meer. Prijsmodellen veranderen, nieuwe mogelijkheden ontstaan en gebruikspatronen evolueren. Statische strategieën verliezen geleidelijk aan hun effectiviteit.
- Voortijdige optimalisatie: Begin met basistechnieken zoals promptoptimalisatie en caching. Complexere benaderingen zoals het distilleren van aangepaste modellen vereisen een aanzienlijke investering. Zorg ervoor dat het volume de inspanning rechtvaardigt.
Praktische voorbeelden van kostenbesparingen
Implementaties in productieomgevingen tonen aan dat deze strategieën aanzienlijke besparingen opleveren.
Systemen die maandelijks meer dan 2 miljoen API-aanroepen verwerken voor meerdere applicaties, rapporteren een cache-hitpercentage van 40 procent, wat een besparing oplevert van ongeveer 1 TP4T3.000 per maand. Dit is een eenvoudige implementatie met een onmiddellijk rendement op investering (ROI).
E-Agent frameworks die het tokengebruik met 10-50 procent verminderen, behouden of verbeteren de nauwkeurigheid bij kennisintensieve taken. Tests op kennisintensieve en redeneertaken tonen de effectiviteit van de executor-verifier-aanpak aan.
Methoden voor vroegtijdige beëindiging verminderen het aantal inferentietokens met gemiddeld ongeveer 41 procent over vijf datasets voor redeneren en drie LLM's, terwijl de nauwkeurigheid vergelijkbaar blijft.
Deze cijfers representeren gerapporteerde resultaten van productiesystemen die daadwerkelijke werkbelastingen verwerken.

Stop met geld verspillen aan LLM's met AI Superior
Veel teams nemen grote taalmodellen in gebruik en realiseren zich pas later hoe snel de infrastructuurkosten kunnen oplopen. Het gebruik van tokens neemt toe, modellen draaien langer dan verwacht en systemen die tijdens het testen prima werkten, worden in productie ineens duur.
AI Superieur Helpt bedrijven bij het ontwerpen en optimaliseren van LLM-systemen, zodat deze efficiënt blijven op grote schaal. Hun teams werken aan de ontwikkeling van aangepaste modellen, het verfijnen ervan en de optimalisatie van AI-workflows, waardoor vaak onnodig computergebruik wordt verminderd en de implementatie van modellen binnen daadwerkelijke bedrijfsprocessen wordt verbeterd.
Als de kosten van je LLM-opleiding blijven stijgen, neem dan contact op AI Superieur Om je configuratie te controleren en de inefficiënties te verhelpen voordat je volgende cloudfactuur binnenkomt.
Veelgestelde vragen
Wat is de snelste manier om de kosten van een LLM-opleiding te verlagen?
Door promptoptimalisatie en caching worden direct resultaten behaald met minimale implementatiecomplexiteit. Begin met het comprimeren van uitgebreide prompts, het opvragen van gestructureerde output en het implementeren van basiscaching voor herhaalde query's. Deze wijzigingen kunnen de kosten binnen enkele dagen met 20-40 procent verlagen.
Hoeveel kan modelgebaseerde routeplanning besparen?
Het routeren van modellen levert doorgaans een besparing op van 40-60 procent ten opzichte van het gebruik van grensmodellen voor alle taken. De exacte besparing hangt af van de taakverdeling: omgevingen met veel eenvoudige classificatie- of extractietaken laten een hogere besparing zien dan omgevingen die voornamelijk complexe redeneringen vereisen.
Heeft kwantisering een significant negatief effect op de modelkwaliteit?
Moderne kwantiseringstechnieken behouden de kwaliteit opmerkelijk goed. INT8-kwantisering leidt doorgaans tot een nauwkeurigheidsverlies van 1-3 procent, terwijl de geheugenvereisten met ongeveer 50 procent worden verminderd. INT4-kwantisering vertoont een verlies van 5-10 procent, maar maakt het mogelijk om veel grotere modellen op beperkte hardware uit te voeren.
Wanneer zouden organisaties moeten overwegen om hun eigen servers te hosten?
Zelfhosting wordt economisch haalbaar bij een maandelijks verbruik van 10 tot 50 miljoen tokens, afhankelijk van de technische mogelijkheden en de prijsstelling van de cloud-API. Organisaties met expertise in machine learning en consistente gebruikspatronen bereiken het break-evenpunt sneller. Bereken de totale eigendomskosten, inclusief infrastructuur, onderhoud en opportuniteitskosten.
Hoe vaak moeten kostenoptimalisatiestrategieën worden herzien?
Driemaandelijkse evaluaties signaleren belangrijke verschuivingen in prijsstelling, modelfunctionaliteit en gebruikspatronen. Maandelijkse monitoring van belangrijke statistieken identificeert afwijkingen die onmiddellijke aandacht vereisen. Belangrijke wijzigingen in de applicatiefunctionaliteit rechtvaardigen een onmiddellijke herbeoordeling met het oog op optimalisatie.
Kunnen kleinere bedrijven zich geavanceerde optimalisatietechnieken veroorloven?
Absoluut. Basistechnieken zoals promptoptimalisatie, caching en modelselectie vereisen minimale technische investeringen. Geavanceerde benaderingen zoals aangepaste distillatie of zelfhosting zijn zinvol bij grotere volumes, maar de initiële besparingen komen voort uit eenvoudige aanpassingen die elke organisatie kan implementeren.
Wat is het verband tussen kostenoptimalisatie en latentie?
Sommige technieken verbeteren beide aspecten: vroegtijdig stoppen verlaagt de kosten en de latentie tegelijkertijd. Andere technieken brengen compromissen met zich mee: modelroutering voegt een lichte overhead toe aan de routering, batchverwerking vertraagt individuele verzoeken. Ontwerp optimalisatiestrategieën rekening houdend met de latentievereisten voor specifieke gebruiksscenario's.
Vooruitgang boeken met kostenoptimalisatie
Kostenoptimalisatie voor levenscyclusmanagement (LLM) is een continu proces, geen eindbestemming. Begin met effectieve, eenvoudige technieken. Meet de resultaten nauwkeurig. Herhaal het proces op basis van de verzamelde gegevens.
Organisaties die succesvol LLM-implementaties in productieomgevingen hebben, beschouwen kostenoptimalisatie als een kerncompetentie. Ze monitoren continu, experimenteren systematisch en passen hun strategieën aan naarmate de omstandigheden veranderen.
Onderzoek blijft zich ontwikkelen op het gebied van optimalisatietechnieken. Door op de hoogte te blijven van de ontwikkelingen, kunnen implementaties profiteren van de nieuwste innovaties. Er verschijnen regelmatig nieuwe methoden voor compressie, routering en efficiënte inferentie.
Maar de basisprincipes blijven hetzelfde: inzicht in prijsmodellen, afstemming van middelen op behoeften, eliminatie van verspilling en meting van alles. Deze principes leiden tot duurzame kostenstructuren die meegroeien met de bedrijfsgroei.
Begin deze week met het implementeren van één of twee strategieën. Meet de impact. Bouw daarop verder. Het cumulatieve effect van meerdere optimalisaties versterkt elkaar: een verbetering van 20 procent hier, 30 procent daar, en plotseling dalen de totale kosten met 60 procent terwijl de kwaliteit verbetert.
Dat is geen theorie. Dat is wat productiesystemen bereiken wanneer organisaties kostenoptimalisatie systematisch aanpakken.