Overzicht: Het trainen van een groot taalmodel zoals GPT-4 kost tussen de 1,4 biljoen en 1,92 miljard dollar, waarbij de computerinfrastructuur 60 tot 701 biljoen dollar aan kosten vertegenwoordigt. Deze kosten vloeien voort uit GPU-clusters, elektriciteitsverbruik, dataverwerking en de benodigde technische expertise. Het finetunen van bestaande modellen kan de kosten met 60 tot 901 biljoen dollar verlagen in vergelijking met het trainen van een model vanaf nul.
Grote taalmodellen hebben kunstmatige intelligentie getransformeerd van een onderzoeksonderwerp tot een commerciële grootmacht. Maar wat de meeste mensen zich niet realiseren, is dat de kosten voor het ontwikkelen van deze systemen vergelijkbaar zijn met de kosten voor het lanceren van satellieten in de ruimte.
Volgens het Stanford AI Index Report 2025 kostte de training van GPT-4 naar schatting $78-100 miljoen. Gemini Ultra 1.0 verhoogde dat bedrag naar $192 miljoen. Dat is een stijging van 287.000 keer ten opzichte van de $670 die het kostte om een Transformer-model te trainen in 2017.
De economische aspecten achter deze cijfers zijn niet zomaar academische curiositeiten. Organisaties die overwegen om zelf modellen te ontwikkelen of bestaande modellen in licentie te nemen, hebben concrete gegevens nodig. Onderzoeksteams die financiering zoeken, hebben realistische budgetprognoses nodig. En branchewatchers die de ontwikkeling van AI volgen, hebben context nodig om de marktdynamiek te begrijpen.
Deze analyse onderzoekt waar elke dollar naartoe gaat bij het trainen van geavanceerde taalmodellen, waarom de kosten zo dramatisch stijgen en welke strategieën de kosten daadwerkelijk verlagen zonder dat dit ten koste gaat van de prestaties.
De anatomie van de kosten van een LLM-opleiding
De kosten voor training bestaan niet uit één enkele post. Meerdere kostenposten tellen op tot bedragen van acht of negen cijfers.
De computerinfrastructuur domineert het budget. Cloudproviders rekenen per uur voor GPU-toegang en trainingssessies strekken zich uit over weken of maanden. OpenAI zou naar verluidt meer dan 1,4 biljoen dollar hebben uitgegeven aan GPT-4-training, waarvan een aanzienlijk deel is besteed aan cloudcomputingkosten.
De hardwarekosten schalen mee met de complexiteit van het model. Grotere modellen vereisen krachtigere accelerators – en meer ervan. Het verschil tussen het trainen van een model met 20 miljard parameters en een model met 120 miljard parameters is niet lineair. De rekenkracht die nodig is, neemt exponentieel toe naarmate het aantal parameters stijgt.
Maar wacht even. De kosten van de hardware vertellen slechts een deel van het verhaal.
De verborgen vermenigvuldigers
Elektriciteitsverbruik brengt doorlopende kosten met zich mee die in veel initiële budgetten worden onderschat. Anthropic kondigde in februari 2026 aan dat ze de stijging van de elektriciteitsprijzen voor hun datacenters zullen dekken, wat aantoont hoe serieus grote AI-laboratoria dit probleem nemen. Ze merkten op dat het trainen van één enkel geavanceerd AI-model binnenkort gigawatts aan stroom zal vereisen, een erkenning van de infrastructuurbelasting die deze systemen met zich meebrengen.
Het voorbereiden en opslaan van data voegt daar nog een extra laag aan toe. Trainingsdatasets voor modellen zoals GPT-4 bevatten honderden miljarden tokens afkomstig uit boeken, websites, wetenschappelijke publicaties en gespecialiseerde corpora. Het verwerven, opschonen, filteren en opslaan van deze data vereist speciale teams en infrastructuur.
Technisch talent verdient een hoge vergoeding. Onderzoekers op het gebied van machine learning en infrastructuurtechnici die trainingssessies over duizenden GPU's kunnen coördineren, zijn schaars. Hun salarissen, bonussen en aandelenpakketten vormen een aanzienlijk deel van de totale projectkosten.
Experimentele iteraties verhogen de basiskosten aanzienlijk. Het vinden van optimale hyperparameters – leersnelheden, batchgroottes, architectuurvariaties – vereist meerdere trainingssessies. Elk mislukt experiment verbruikt GPU-uren zonder het uiteindelijke model op te leveren.

GPU-infrastructuur: de grootste kostenpost
Grafische processoren vormen de ruggengraat van moderne AI-training. Deze gespecialiseerde chips blinken uit in de parallelle matrixbewerkingen die neurale netwerken vereisen.
NVIDIA domineert de markt. Hun H100- en A100-acceleratoren vormen de basis van de meeste grootschalige trainingsoperaties. Cloudproviders rekenen ongeveer 1 TP4T2-4 per H100 GPU-uur. Het trainen van een grensverleggend model kan 10.000 tot 25.000 GPU's vereisen die meerdere weken draaien.
De berekening wordt al snel pijnlijk. Met $3 per GPU-uur kost het 30 dagen lang draaien van 15.000 GPU's $32,4 miljoen – alleen al voor de rekentijd. En dan hebben we het nog niet eens over opslag, netwerken of andere infrastructuurcomponenten.
De aanschaf van hardware verandert de kostenstructuur. Hoewel de initiële investeringskosten hoger liggen, kan het vermijden van terugkerende cloudkosten de totale uitgaven op de lange termijn verlagen. Organisaties die meerdere trainingssessies plannen of hun processen continu optimaliseren, vinden het vaak voordeliger om hardware te bezitten dan te huren.
Het probleem van de inactiviteit
Het probleem is echter dat GPU's niet elk moment dat ze aanstaan productief zijn. Knelpunten bij het laden van gegevens, het opslaan van checkpoints en pauzes tijdens het debuggen creëren periodes waarin dure hardware ongebruikt blijft, maar wel kosten met zich meebrengt.
Onderzoek van arXiv naar efficiënte LLM-trainingsframeworks toonde aan dat GPU's, ondanks het volledige stroomverbruik, tijdens standaard pre-training vaak een suboptimale benutting hebben van 30%-50%. Deze inefficiëntie komt voort uit de manier waarop transformer-architecturen interageren met de mogelijkheden van de hardware.
Er bestaan oplossingen. Geoptimaliseerde trainingsframeworks kunnen het GPU-gebruik verbeteren door datapijplijnen te stroomlijnen, berekeningen en communicatie te overlappen en de synchronisatiekosten te minimaliseren. Deze verbeteringen versnellen niet alleen de training, maar verminderen ook direct het totale aantal benodigde GPU-uren.
| Hardwaretype | Uurlijkse kosten voor cloudcomputing | Aankoopprijs | Break-evenpunt |
|---|---|---|---|
| NVIDIA H100 | $2.50-$4.00 | $30,000-$40,000 | 10.000-16.000 uur |
| NVIDIA A100 | $1.50-$2.50 | $10,000-$15,000 | 6.000-10.000 uur |
| NVIDIA H200 | $3.50-$5.00 | $40,000-$50,000 | 11.000-14.000 uur |
Energiekosten: een groeiende bron van bezorgdheid
De elektriciteitsrekening voor trainingsvluchten is bijna net zo hoog als de aanschafkosten van de hardware zelf. Frontier-modellen verbruiken gigawattuur aan stroom – genoeg om duizenden huizen maandenlang van energie te voorzien.
Energie-efficiëntie is een belangrijk onderzoeksgebied geworden. Gepubliceerd werk op arXiv over energieoptimalisatie in LLM-gebaseerde applicaties geeft prioriteit aan energieverbruik als een belangrijke efficiëntiemaatstaf, naast traditionele prestatiemetingen. Experimenten met NVIDIA RTX 8000-hardware toonden aan dat geoptimaliseerde benaderingen een vergelijkbare nauwkeurigheid bereiken als de basismodellen, terwijl het energieverbruik met 23 tot 501 TP3T wordt verminderd.
Eerlijk gezegd: energiekosten gaan niet alleen over de directe energierekening. De infrastructuur voor het leveren van gigawatts aan stroom vereist onderstations, koelsystemen en noodaggregaten. Datacenteroperators nemen deze kapitaalinvesteringen mee in hun prijsmodellen.
Naarmate de vraag naar trainingen toeneemt, wordt de energie-infrastructuur een concurrentieel knelpunt. Organisaties met toegang tot goedkope, betrouwbare elektriciteit behalen aanzienlijke voordelen op het gebied van trainingskosten.
Trainen vanaf nul versus finetunen
Niet elk project vereist het volledig vanaf nul opbouwen van een model. Het finetunen van voorgegetrainde modellen biedt een kosteneffectief alternatief voor veel toepassingen.
De economische gevolgen veranderen drastisch. Het finetunen van een model zoals Llama 2 of GPT-3.5 op domeinspecifieke data kan 1.400.000 tot 1.400.000 euro kosten, afhankelijk van de grootte van de dataset en de benodigde rekenkracht. Dat is 1.000 tot 10.000 keer goedkoper dan het trainen van een vergelijkbaar model vanaf nul.
Onderzoek dat op arXiv is gepubliceerd en waarin efficiënte LLM-verbeteringsstrategieën werden onderzocht, toonde aan dat finetuning met technieken zoals LoRA (Low-Rank Adaptation) kan worden uitgevoerd op bescheiden hardware. In één experiment werd LoRA-training toegepast op een vooraf gekwantiseerd model van 4 bits met behulp van een enkele NVIDIA T4 GPU met 16 GB VRAM, waarbij het proces in 7 uur werd voltooid.
Maar finetuning kent wel beperkingen. Voorgegetrainde modellen bevatten ingebouwde vooroordelen en kennishiaten uit hun oorspronkelijke trainingsdata. Finetuning past het gedrag van het model aan voor specifieke taken, maar verandert de kernkennis of -mogelijkheden van het model niet fundamenteel.
Wanneer is het zinvol om helemaal vanaf nul te beginnen met trainen?
Organisaties kiezen om verschillende redenen voor volledige training. Eigen datasets die niet met externe modelaanbieders kunnen worden gedeeld, maken interne training noodzakelijk. Gespecialiseerde domeinen waar bestaande modellen slecht presteren, profiteren van op maat gemaakte architecturen die vanaf nul worden getraind op relevante corpora.
Concurrentievoordelen spelen een rol bij sommige beslissingen. Bedrijven die AI-gedreven producten ontwikkelen, willen modellen die concurrenten niet zomaar kunnen kopiëren door publiekelijk beschikbare alternatieven te verfijnen.
Controle over het gedrag van het model is essentieel. Trainen vanaf nul biedt volledig inzicht in databronnen, trainingsprocedures en modelkenmerken – cruciaal voor gereguleerde sectoren of veiligheidskritische toepassingen.


Bereken de kosten van uw LLM-opleiding
Het trainen van grote taalmodellen (LLM's) omvat het samenstellen van gegevens, de infrastructuur, het budgetteren van rekenkracht, experimenteren en evalueren. AI Superieur Uw dataset, doelstellingen en prestatiedoelen worden geanalyseerd voordat de benodigde resources en tijd worden ingeschat. De kosten worden opgesplitst in voorbewerking, trainingscycli, finetuning en validatie. Hierdoor kunt u de rekenkracht en de benodigde engineeringinspanningen vooraf plannen.
Klaar om uw investering in een LLM-opleiding te berekenen?
Praat met AI die superieur is aan:
- Evalueer uw dataset en doelen.
- Definieer de trainingsstrategie en bereken de behoeften.
- ontvang een gestructureerde kostenraming voor de LLM-opleiding
👉 Vraag een LLM-opleidingsofferte van AI Superior.
Praktische kostenvoorbeelden
Specifieke modellen bieden concrete referentiepunten voor het begrijpen van de economische aspecten van opleidingen.
De trainingskosten van GPT-4 worden geschat op $78-100 miljoen, volgens The Wall Street Journal en het Stanford AI Index Report 2025. Dit bedrag omvat de computerinfrastructuur, elektriciteit, dataverzameling en technische middelen gedurende de gehele trainingsperiode.
Gemini Ultra 1.0 heeft de kosten opgedreven tot ongeveer 1.400.192 miljoen dollar volgens het Stanford AI Index Report 2025. De hogere kosten weerspiegelen de grotere schaal, de langere trainingsduur en de uitgebreidere experimenten tijdens de ontwikkeling.
GPT-40-trainingen kostten ongeveer 100 miljoen keer TP4T. Deze grensverleggende modellen van grote laboratoria hebben vergelijkbare kostenstructuren: budgetten van acht of negen cijfers, voornamelijk bepaald door GPU-rekenkracht en energieverbruik.
Kleinere organisaties hebben te maken met andere economische kosten. Het trainen van een model met 7 miljard parameters kan 1 TP4 50.000 tot 1 TP4 200.000 kosten, afhankelijk van de beschikbare hardware en de efficiëntie. Een model met 20 miljard parameters kan 1 TP4 500.000 tot 1 TP4 2 miljoen kosten. Deze bedragen zijn aanzienlijk, maar liggen binnen het bereik van goed gefinancierde startups of onderzoeksteams binnen grote bedrijven.
Het prijsinflatietraject
De trainingskosten zijn exponentieel gestegen. Het Stanford AI Index Report 2025 documenteerde een toename van 287.000x van 2017 tot nu – van $670 voor vroege Transformer-modellen tot bedragen van negen cijfers voor de huidige grensverleggende systemen.
Deze trend vertoont geen tekenen van omkering. Modellen blijven groeien in het aantal parameters, de hoeveelheid trainingsdata en de architectonische complexiteit. Elke generatie vereist meer rekenkracht dan de vorige.
Desondanks compenseren efficiëntieverbeteringen de schaalvergrotingen gedeeltelijk. Betere algoritmen, geoptimaliseerde hardware en verbeterde trainingstechnieken zorgen voor meer functionaliteit per bestede dollar. De kosten per eenheid modelfunctionaliteit zijn zelfs gedaald, terwijl de absolute trainingskosten zijn gestegen.
Strategieën om de opleidingskosten te verlagen
Meerdere benaderingen kunnen de kosten aanzienlijk verlagen zonder dat de modelkwaliteit evenredig afneemt.
Efficiënte trainingsframeworks minimaliseren verspilde GPU-cycli. Technieken zoals gradiëntaccumulatie, training met gemengde precisie en geoptimaliseerde data-laadpipelines verbeteren het hardwaregebruik. Volgens analyses van high-throughput trainingssystemen kan het aanpakken van inefficiënt gebruik van rekenresources tijdens de training van transformermodellen de trainingstijd en het energieverbruik drastisch verminderen.
Modelcompressietechnieken verminderen de rekenkracht die nodig is. Kwantisatie representeert gewichten met minder bits, waardoor de geheugenbandbreedte en opslagbehoefte afnemen. Snoeien verwijdert minder belangrijke verbindingen, waardoor de modelgrootte kleiner wordt. Kennisdestillatie draagt mogelijkheden van grote modellen efficiënter over naar kleinere modellen dan training vanaf nul.
Slimme toewijzing van resources voorkomt dat er betaald wordt voor hardware die niet gebruikt wordt. Het automatisch pauzeren van GPU-clusters tijdens de datavoorbereidingsfasen, het dynamisch aanpassen van de infrastructuur aan elke trainingsfase en het plannen van runs tijdens daluren voor elektriciteit dragen allemaal bij aan lagere totale kosten.
Hyperparameteroptimalisatie vermindert mislukte experimenten. Systematische zoekstrategieën vinden sneller effectieve trainingsconfiguraties dan handmatige afstemming. Minder verspilde trainingsruns betekenen minder GPU-uren die verloren gaan aan doodlopende wegen.
De keuze tussen de cloud en een on-premise oplossing.
Cloudinfrastructuur biedt flexibiliteit en lage opstartkosten. Start duizenden GPU's op voor een trainingssessie en deactiveer ze vervolgens weer. Deze aanpak werkt goed voor organisaties die af en toe experimenten uitvoeren of onzeker zijn over hun rekenkrachtbehoeften op de lange termijn.
Hardware op locatie vereist aanzienlijke investeringen, maar elimineert terugkerende huurkosten. Een break-evenanalyse laat doorgaans zien dat het rendabel wordt om de hardware zelf te installeren na 10.000-16.000 uur gebruik van de H100-chip of 6.000-10.000 uur voor de A100-chip.
Organisaties die meerdere grote trainingssessies plannen, continue verfijningsprocessen uitvoeren of langetermijnmodellen ontwikkelen, merken vaak dat de aanschaf van hardware voordeliger is, ondanks de hogere initiële kosten.
| Kostenreductiestrategie | Potentiële besparingen | Implementatiecomplexiteit |
|---|---|---|
| Efficiënte trainingsprogramma's | 20-40% | Medium |
| Modelkwantisatie | 30-50% | Laag |
| Slimme resourceplanning | 15-30% | Medium |
| Fijn afstellen versus helemaal opnieuw beginnen | 60-90% | Laag (als het basismodel aan de behoeften voldoet) |
| Hardware op locatie (lange termijn) | 40-60% | Hoog |
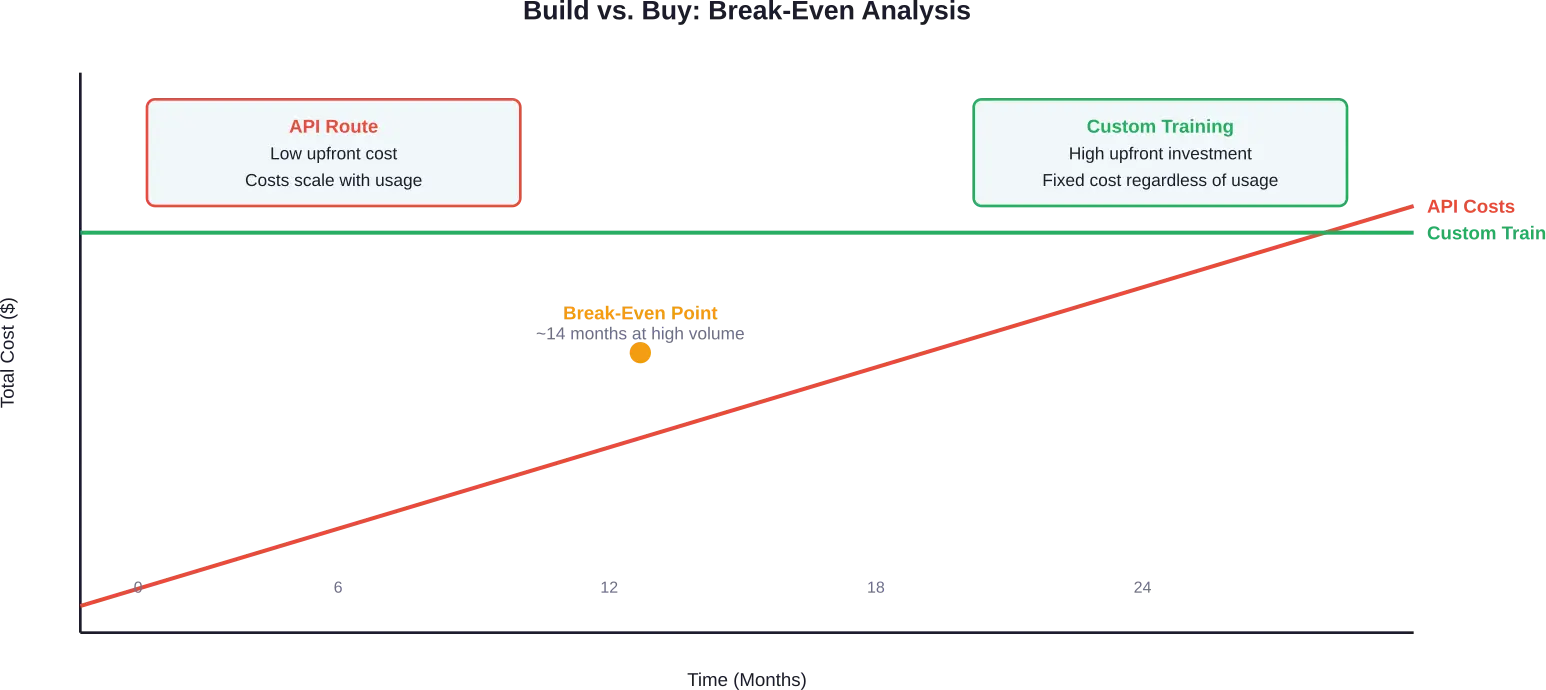
De keuze tussen zelf bouwen en kopen.
Veel organisaties staan voor een fundamentele vraag: een model op maat trainen of bestaande modellen in licentie nemen?
API-toegang tot modellen zoals GPT-4 begint bij $0,60 per miljoen inputtokens voor sommige aanbieders, waarbij de outputprijzen per model variëren. Gemini Flash-Lite biedt zelfs nog lagere tarieven van $0,075 per miljoen inputtokens en $0,30 per miljoen outputtokens volgens prijsgegevens uit 2025.
Prijsstelling op basis van gebruik lijkt in eerste instantie economisch voordelig. Maar de kosten stijgen lineair met het verkeer. Applicaties die dagelijks 1,2 miljoen berichten verwerken met elk 150 tokens kunnen maandelijks API-kosten genereren van $15.000 tot $60.000, afhankelijk van de prijsniveaus en de input/output-verhoudingen.
Bij grote volumes wordt eigen infrastructuur economischer. Een break-evenanalyse voor een gedocumenteerd geval toonde aan dat de API-kosten maandelijks $60.000 bedragen en oplopen tot meer dan $500.000 per jaar – een bedrag dat een aanzienlijke investering in training vooraf rechtvaardigt.
De beslissing hangt af van gebruikspatronen, benodigde aanpassingen en concurrentiepositie. Applicaties met voorspelbaar hoog gebruiksvolume, specifieke domeinvereisten of de behoefte aan transparantie van het model neigen naar training op maat. Projecten met variabel gebruik, algemene functionaliteiten of strakke ontwikkeltijden neigen naar toegang via een API.
Toekomstige kostentrends
De opleidingskosten zullen blijven evolueren naarmate de technologie en de marktdynamiek veranderen.
De verbeteringen in hardware-efficiëntie verlagen gestaag de kosten per berekening. De nieuwe generaties architecturen van NVIDIA laten consistente prestatieverbeteringen per watt zien. Concurrenten die de markt voor accelerators betreden, zullen verdere optimalisatie en prijsconcurrentie stimuleren.
Algoritmische vooruitgang maakt het mogelijk om met minder rekenkracht meer te bereiken. Technieken zoals mixture-of-experts-architecturen, schaarse aandachtmechanismen en verbeterde optimalisatiealgoritmen verlagen het benodigde rekenbudget om specifieke prestatiedoelen te behalen.
De energiekosten zullen waarschijnlijk stijgen naarmate de AI-infrastructuur een grotere druk op de elektriciteitsnetten uitoefent. Naarmate de trainingsbehoeften toenemen en de energie-infrastructuur steeds crucialer wordt, zullen organisaties met toegang tot goedkope, hernieuwbare energie een concurrentievoordeel behalen.
Regelgeving kan de economische aspecten van trainingen beïnvloeden. Overheden die zich zorgen maken over energieverbruik, gegevensbescherming of de veiligheid van AI, kunnen eisen stellen die de nalevingskosten verhogen of bepaalde praktijken beperken.
Democratiseringstrends zouden de drempel voor toetreding kunnen verlagen. Open-source modellen, gedeelde computerplatforms en verbeterde trainingsefficiëntie zouden grootschalige modelontwikkeling binnen het bereik van middelgrote organisaties kunnen brengen, in plaats van uitsluitend voor techreuzen.
Veelgestelde vragen
Wat zijn de trainingskosten voor een GPT-4?
De trainingskosten voor GPT-4 worden geschat op 1,78 tot 100 miljoen dollar, volgens The Wall Street Journal en het Stanford AI Index Report 2025. Dit bedrag omvat de GPU-infrastructuur, het elektriciteitsverbruik, de datavoorbereiding en de technische middelen gedurende de trainingsperiode van meerdere maanden.
Waarom is een LLM-opleiding zo duur?
De trainingskosten vloeien voornamelijk voort uit de GPU-rekeninfrastructuur, die 60-701 TP3T aan uitgaven vertegenwoordigt. Een grensmodel kan 10.000 tot 25.000 krachtige GPU's vereisen die weken of maandenlang continu draaien. Bijkomende kosten omvatten elektriciteitsverbruik (gigawattuur), technisch talent, dataverzameling en -voorbereiding, en experimentele iteraties om hyperparameters te optimaliseren.
Kan optimalisatie de opleidingskosten voor een LLM-programma verlagen?
Het finetunen van bestaande modellen kost doorgaans 60-901 TP3T minder dan het trainen van een model vanaf nul. Het aanpassen van een voorgegetraind model zoals Llama 2 of GPT-3.5 voor specifieke taken kan 1 TP4T5.000-1 TP4T50.000 kosten, vergeleken met 1 TP4T78-192 miljoen voor het trainen van een grensverleggend model. Technieken zoals LoRA maken finetuning op individuele GPU's mogelijk, waardoor het proces in uren in plaats van weken kan worden voltooid.
Wat is het verschil in kosten tussen cloudgebaseerde en on-premise training?
Cloudinfrastructuur rekent $2-4 per uur voor een H100 GPU, zonder investering vooraf, maar met doorlopende huurkosten. De aanschaf van H100-hardware kost $30.000-$40.000 per stuk vooraf, maar elimineert de huurkosten. Het break-evenpunt wordt bereikt na ongeveer 10.000-16.000 gebruiksuren. Organisaties die meerdere trainingssessies plannen, vinden het bezit van de hardware vaak voordeliger, ondanks de hogere initiële investeringskosten.
Hoeveel elektriciteit verbruikt een opleiding tot LLM-kandidaat?
Geavanceerde AI-modellen verbruiken gigawattuur aan elektriciteit – genoeg om duizenden huizen maandenlang van stroom te voorzien. Het trainen van één enkel geavanceerd AI-model zal binnenkort gigawatt aan stroomcapaciteit vereisen. De elektriciteitskosten vertegenwoordigen 15 tot 201 biljoen dollar aan totale trainingskosten voor grote modellen, waarbij zowel de directe energierekeningen als de kosten voor de ondersteunende infrastructuur de kosten opdrijven.
Wat is de goedkoopste manier om een aangepast taalmodel te trainen?
Het finetunen van een bestaand open-source model met behulp van efficiënte technieken zoals LoRA biedt de meest kostenefficiënte instapmogelijkheid. Onderzoek heeft aangetoond dat een LoRA-trainingsexperiment in 7 uur kon worden voltooid op een enkele NVIDIA T4 GPU met 16 GB VRAM – hardware die beschikbaar is op platforms zoals Google Colab. Voor toepassingen waarbij finetuning voldoende mogelijkheden biedt, verlaagt deze aanpak de kosten met een factor 1.000 tot 10.000 in vergelijking met training vanaf nul.
Stijgen de opleidingskosten nog steeds?
De absolute trainingskosten voor geavanceerde modellen blijven stijgen naarmate het aantal parameters en de omvang van de datasets toenemen. Het Stanford AI Index Report 2025 documenteerde een toename van 287.000x van 2017 tot nu. De kosten per eenheid modelcapaciteit dalen echter door verbeteringen in hardware en algoritmes. Efficiëntiewinsten compenseren de schaalvergroting gedeeltelijk, hoewel de totale budgetten voor state-of-the-art modellen blijven stijgen.
Inzicht in de investering
De kosten van een LLM-opleiding weerspiegelen de rekenintensiteit van het creëren van systemen die menselijke taal op grote schaal verwerken en genereren. Die prijskaartjes van acht of negen cijfers zijn niet willekeurig – ze vertegenwoordigen duizenden gespecialiseerde processoren die continu draaien, megawatts aan stroom verbruiken en worden aangestuurd door teams van gespecialiseerde ingenieurs die met enorme datasets werken.
De economie zal zich blijven ontwikkelen. Hardware wordt efficiënter. Algoritmen worden beter. Concurrentie stimuleert innovatie. Maar de fundamentele afweging blijft: capaciteit vereist rekenkracht, en rekenkracht kost geld.
Organisaties die overwegen om aangepaste modellen te bouwen, hebben realistische kostenramingen nodig, geen onrealistische schattingen. Teams die financiering aanvragen, moeten rekening houden met alle kostenposten, niet alleen met de voor de hand liggende kosten voor GPU-huur. En waarnemers in de sector die de ontwikkeling van AI volgen, moeten begrijpen dat trainingskosten een nuttige indicator zijn voor de schaal en mogelijkheden van een model.
De te volgen koers hangt af van de specifieke vereisten. Bij grootschalige toepassingen met specialistische behoeften is maatwerktraining vaak gerechtvaardigd, ondanks een aanzienlijke investering vooraf. Voor kleinschalige of algemene projecten is API-toegang economischer. En veel toepassingen bevinden zich ergens daartussenin, waar fijnafstemming de juiste balans biedt tussen maatwerk en kostenefficiëntie.
Klaar om verder te gaan met modelontwikkeling? Begin met het berekenen van uw specifieke gebruikspatronen, het identificeren van welke functionaliteiten aangepaste training vereisen en welke slechts fijnafstemming nodig hebben, en het uitvoeren van een break-evenanalyse voor uw verwachte implementatieschaal. De gegevens zullen duidelijk maken welke aanpak het meest geschikt is voor uw specifieke situatie.