Korte samenvatting: Het monitoren van de kosten van LLM-apps vereist realtime tracking van tokengebruik, modelselectie en aanvraagpatronen om budgetoverschrijdingen te voorkomen. Toonaangevende tools zoals Datadog LLM Observability, Langfuse en cloud-native oplossingen van AWS Bedrock en OpenAI bieden kostenattributie, gebruiksanalyses en optimalisatieaanbevelingen. Effectieve monitoring combineert observatieplatforms met strategische werkwijzen zoals snelle optimalisatie, modelselectie en caching.
Naarmate generatieve AI-toepassingen van prototype naar productie evolueren, kunnen de tokenkosten enorm oplopen. Een enkele, niet-geoptimaliseerde promptketen kan de kosten vertienvoudigen, en zonder realtime inzicht in gebruikspatronen ontdekken teams budgetoverschrijdingen vaak pas wanneer de factuur binnenkomt.
Traditionele cloudkostenmonitoring is niet geschikt voor LLM-toepassingen. Op tokens gebaseerde prijsmodellen vereisen gespecialiseerde observability die niet alleen de rekentijd bijhoudt, maar ook inkomende en uitgaande tokens, modelselectie en aanvraagfrequentie bij verschillende providers.
Dit leidt tot een fundamentele uitdaging: hoe behouden teams inzicht in de kosten van LLM zonder de ontwikkelsnelheid of de applicatieprestaties te belemmeren?
Waarom kostenbewaking voor een LLM-opleiding belangrijk is
Het op tokens gebaseerde prijsmodel verandert fundamenteel de manier waarop applicatiekosten schalen. In tegenstelling tot traditionele infrastructuur, waar kosten samenhangen met de uptime van de server, zijn de kosten van LLM afhankelijk van het volume en de complexiteit van elk afzonderlijk verzoek.
Volgens AWS-documentatie die in oktober 2025 is gepubliceerd (Build a proactive AI cost management system for Amazon Bedrock), ondervinden organisaties problemen met het beheren van kosten die samenhangen met op tokens gebaseerde prijsstelling. Dit kan leiden tot onverwachte facturen als het gebruik niet nauwlettend wordt bijgehouden. Traditionele methoden zoals budgetwaarschuwingen en detectie van kostenafwijkingen reageren vaak te laat.
Dit is wat kostenbeheer bij een LLM-opleiding anders maakt:
- Het tokenverbruik varieert sterk, afhankelijk van de lengte van de prompt en de complexiteit van het antwoord.
- De verschillende modellen hebben aanzienlijk verschillende prijzen (de Amazon Nova Micro kost $0.000035 per 1.000 inputtokens en $0.00014 per 1.000 outputtokens, terwijl grotere modellen hogere tarieven hanteren).
- Workflowprocessen met meerdere agentstappen verhogen de kosten door middel van meerdere LLM-aanroepen.
- Het productiegebruik komt zelden overeen met de ontwikkelingsramingen.
Eerlijk gezegd: de meeste teams ontdekken pas dat ze een kostenprobleem hebben nadat de kosten oplopen tot duizenden euro's. Proactieve monitoring voorkomt dat scenario volledig.
Inzicht in token-economie
De prijsstelling van tokens is niet uniform voor alle modellen of aanbieders. De economische aspecten zijn sterk afhankelijk van het onderliggende model van de applicatie en de manier waarop verzoeken worden gestructureerd.
Uit de documentatie van OpenAI blijkt dat audiotokens in gebruikersberichten tellen als 1 token per 100 ms audio, terwijl berichten van de assistent tellen als 1 token per 50 ms. Deze verschillen zijn van belang bij het ontwikkelen van multimodale applicaties.
De Amazon Nova-modellen laten het prijsspectrum duidelijk zien. Zoals gedocumenteerd in AWS-materiaal uit juni 2025:
| Model | Invoertokens (per 1.000) | Uitvoertokens (per 1.000) |
|---|---|---|
| Amazon Nova Micro | $0.000035 | $0.00014 |
| Grotere Nova-varianten | Hogere tarieven | Proportioneel geschaald |
Het grootste model is niet altijd nodig voor elke taak. Het afstemmen van de mogelijkheden van het model op de complexiteit van de toepassing heeft een directe invloed op de kosten.
Anthropic biedt een Usage and Cost API waarmee programmatisch toegang verkregen kan worden tot uitgavengegevens van organisaties. Dit stelt teams in staat om aangepaste dashboards en geautomatiseerde kostenbeheersing te bouwen.

Implementeer LLM-monitoringsystemen
LLM-applicaties vereisen monitoring om het gebruik, de prestaties en de operationele stabiliteit te volgen.
AI Superieur Ontwikkelt monitoring- en beheertools voor AI-systemen in productieomgevingen, waarmee organisaties LLM-gebaseerde applicaties efficiënter kunnen beheren.
Hun ontwikkelingswerkzaamheden kunnen onder meer het volgende omvatten:
- systemen voor het bijhouden van gebruik
- prompt- en responsanalyses
- infrastructuurbewaking
- AI-systeemoptimalisatietools
AI Superieur Helpt teams bij het overzetten van LLM-applicaties van prototype naar stabiele productieomgevingen.
Kerncomponenten van LLM-kostenbewaking
Effectieve monitoringsystemen volgen meerdere dimensies tegelijk. Het gebruik van tokens alleen vertelt niet het hele verhaal.
Het bijhouden van tokengebruik
Elke aanvraag genereert zowel invoer- als uitvoertokens. Monitoringsystemen moeten beide dimensies vastleggen en toewijzen aan specifieke gebruikers, functies of workflows.
Het aantal invoertokens is afhankelijk van de keuzes die in de prompt-engineering worden gemaakt. Uitgebreide systeemprompts of overmatige contextinjectie verhogen de kosten per verzoek. Het aantal uitvoertokens varieert op basis van modelparameters zoals de temperatuur en de max_tokens-instellingen.
De Apigee-documentatie van Google beschrijft LLM-tokenbeleid als cruciaal voor kostenbeheersing, waarbij gebruik wordt gemaakt van statistieken over tokengebruik om limieten af te dwingen en realtime monitoring mogelijk te maken. Het platform maakt het mogelijk om prompt-tokenlimieten in te stellen, zoals het beperken van verzoeken tot 1.000 tokens per minuut.
Attributie van modelselectie
Applicaties die meerdere modellen gebruiken, vereisen kostentoewijzing per modeltype. Een routeringsbeslissing die eenvoudige query's naar een duur model stuurt, leidt tot budgetverspilling.
Modelcascaderingsstrategieën kunnen de kosten optimaliseren door eerst de goedkopere modellen te proberen en pas over te schakelen naar complexere modellen wanneer dat nodig is. Monitoring moet bijhouden welk model elk verzoek heeft afgehandeld en wat het bijbehorende kostenverschil was.
Analyse van aanvraagpatronen
Tijdsgebonden patronen onthullen mogelijkheden voor optimalisatie. Batchverwerking tijdens daluren, het beperken van aanvragen tijdens verkeerspieken en het identificeren van overbodige oproepen vereisen allemaal historische patroongegevens.
AWS-tests die in oktober 2025 zijn uitgevoerd, toonden aan dat de uitvoeringstijden van workflows varieerden van 6,76 tot 32,24 seconden, afhankelijk van de vereisten voor uitvoertokens. Inzicht in deze patronen helpt bij de capaciteitsplanning.
Belangrijkste tools voor kostenbewaking van een LLM-opleiding
Er zijn verschillende platforms naar voren gekomen als leiders op het gebied van LLM-observatie en kostenbeheer. Elk platform heeft zijn eigen sterke punten, afhankelijk van de implementatiearchitectuur en het ecosysteem van aanbieders.
Datadog LLM Observability
Het platform van Datadog integreert met belangrijke LLM-aanbieders, waaronder OpenAI, Anthropic en Amazon Bedrock, zoals beschreven in de AWS-partnerschapsdocumenten. AWS-documentatie van juli 2025 (Monitor agents built on Amazon Bedrock with Datadog LLM Observability) beschrijft hoe Datadog agents die op Bedrock zijn gebouwd, monitort met volledige observability-functionaliteit.
Het platform houdt het tokengebruik, de latentie en de kosten van alle LLM-gesprekken bij in een centraal dashboard. Traces leggen de workflows van agenten in meerdere stappen vast en laten zien hoe de kosten zich opstapelen in complexe ketens.
Belangrijke functionaliteiten zijn onder meer realtime kostenallocatie, prestatiebewaking en detectie van afwijkingen. Teams kunnen budgetwaarschuwingen instellen en uitgaventrends in de loop van de tijd visualiseren.
De prijzen variëren afhankelijk van het gebruiksvolume, met op maat gemaakte bedrijfsabonnementen beschikbaar voor grootschalige implementaties.
Langfuse
Langfuse biedt open-source LLM-observatie met de mogelijkheid tot zelfhosting. Het platform biedt sessiegebaseerde weergaven die gerelateerde LLM-verzoeken aan elkaar koppelen, waardoor het gemakkelijker wordt om gebruikerstrajecten te begrijpen.
De sterke observeerbaarheid van meerstapsketens en agentworkflows onderscheidt Langfuse. Hiërarchische tracering toont ouder-kindrelaties tussen LLM-aanroepen, terwijl kostenregistratie uitgaven koppelt aan specifieke traces of sessies.
Uit discussies binnen de community blijkt dat de zelfgehoste optie weliswaar volledige controle biedt, maar dat de cloudversie begint bij $29 per maand, met gebruiksafhankelijke prijsstelling na het basisabonnement. Er is ook een gratis zelfgehoste optie beschikbaar.
Amazon Bedrock Native Tools
AWS heeft kostenbeheer direct in Bedrock geïntegreerd. De documentatie van oktober 2025 beschrijft een proactief AI-kostenbeheersysteem dat verder gaat dan traditionele budgetwaarschuwingen.
De workflow handhaaft consistente uitvoeringspatronen bij het verwerken van verzoeken met een variërende duur (6,76 tot 32,24 seconden, afhankelijk van de vereisten voor het uitvoertoken). Dankzij deze native integratie is er geen apart observatieplatform nodig voor Bedrock-workloads.
De in juni 2025 beschreven kostenoptimalisatiestrategieën benadrukken modelselectie als een belangrijk instrument. Door de juiste Nova-modelvariant te kiezen, kunnen de kosten aanzienlijk worden verlaagd zonder dat dit ten koste gaat van de applicatiekwaliteit.
OpenAI-tools voor kostenbeheer
OpenAI biedt native gebruiksregistratie via het API-dashboard en programmatische toegang via gebruiks-endpoints. De documentatie van de Realtime API legt uit hoe kosten worden berekend voor verschillende modaliteiten: tekst, audio en afbeeldingen.
De berekening van audiotokens verschilt per berichttype (1 token per 100 ms voor gebruikersberichten, 1 token per 50 ms voor berichten van de spraakassistent). Inzicht in deze nuances voorkomt onverwachte kosten bij spraakgestuurde toepassingen.
Het platform biedt budgetlimieten en meldingsdrempels die op organisatie- en projectniveau kunnen worden geconfigureerd.
API voor antropisch gebruik en kosten
De aanpak van Anthropic biedt programmatische toegang tot gebruiksgegevens van organisaties via een speciale API. Dit maakt integraties voor kostenbewaking op maat mogelijk, zonder afhankelijk te zijn van platforms van derden.
De documentatie van Claude Code van Anthropic laat zien dat het commando /cost gedetailleerde statistieken over tokengebruik levert, waaronder de totale kosten (bijvoorbeeld $0.55), de duur van de API-aanvragen en wijzigingen in de code. Deze gedetailleerde gegevens helpen ontwikkelaars precies te begrijpen waardoor de uitgaven in hun applicaties worden gedreven.
Door middel van snelheidsbeperkingen en budgetbeheer voor teams kunnen beheerders het gebruik op organisatieniveau beperken.
Cloud-native monitoringoplossingen
Grote cloudproviders hebben LLM-kostenbewaking geïntegreerd in hun bredere observatieplatformen.
Azure Monitor
De monitoringfuncties van Azure omvatten ook Azure OpenAI Service-implementaties. Het platform houdt het tokenverbruik, de aanvraagfrequentie en de kosten bij voor alle geïmplementeerde modellen.
Integratie met Azure Cost Management biedt een uniform overzicht van zowel infrastructuur- als LLM-kosten, waardoor de totale applicatiekosten beter inzichtelijk worden.
Google Cloud en Apigee
Google gebruikt Apigee LLM-tokenbeleid voor kostenbeheersing. Dit beleid legt limieten op basis van gebruiksstatistieken van tokens en biedt realtime monitoring van het tokenverbruik.
De documentatie beschrijft hoe snelheidslimieten zoals 1.000 tokens per minuut kunnen worden geïmplementeerd met behulp van PromptTokenLimit-beleid. Dit voorkomt dat de kosten door onverwachte verkeerspieken de pan uit rijzen.
Infrastructuur voor het omarmen van gezichten
De prijslijst van Hugging Face, gepubliceerd in januari 2026, toont een spectrum van gratis tiers tot enterprise-oplossingen. Inference Endpoints berekent de kosten op basis van rekentijd vermenigvuldigd met de hardwareprijs.
Een verzoek dat 10 seconden duurt op een GPU met kosten van $0.00012 per seconde, resulteert in een factuur van $0.0012, zoals beschreven in de prijsgidsen van Hugging Face. Het begrijpen van dit rekentijdmodel verschilt van tokengebaseerde prijsstelling en vereist andere monitoringmethoden.
Het platform biedt dashboards met gebruiksgegevens die het rekenverbruik weergeven, maar discussies binnen de community sinds april 2025 laten verwarring zien over de omrekening van de gebruiksduur naar de exacte kosten. Betere documentatie van de conversieformule zou helpen.
| Platform | Prijsmodel | Monitoringfuncties | Het beste voor |
|---|---|---|---|
| Datadog | Gebruiksgebaseerd | Geïntegreerde observatie, tracering en waarschuwingen | Omgevingen met meerdere providers |
| Langfuse | Gratis zelfhosting, $29+ cloud | Sessie-tracking, hiërarchische traceringen | Voorkeur voor open source |
| AWS Bedrock | Inbegrepen bij de service | Native integratie, aanvraagpatronen | AWS-native implementaties |
| OpenAI Native | Inbegrepen | Gebruiksdashboard, API-toegang | Apps die exclusief voor OpenAI zijn ontwikkeld |
| Antropische API | Inbegrepen | Programmatische kostengegevens | Op Claude gebaseerde applicaties |
Kostenoptimalisatiestrategieën
Monitoring brengt problemen aan het licht. Optimalisatie lost ze op. Verschillende strategieën verlagen consequent de LLM-kosten zonder de functionaliteit in gevaar te brengen.
Snelle techniek
Beknopte prompts verminderen het aantal invoertokens. Onderzoek toont aan dat code met veel codefragmenten (smelly code) leidt tot een aanzienlijk hoger tokenverbruik tijdens inferentie in vergelijking met schone code, met een mediaan tokenverbruik van 28,13 voor schone code tegenover 33,30 voor code met codefragmenten.
Het weglaten van onnodige context, het gebruik van duidelijke instructies en het efficiënt structureren van prompts verlagen de kosten per verzoek. Door verschillende promptformuleringen te testen en het tokengebruik te meten, kunnen de meest efficiënte benaderingen worden geïdentificeerd.
Modelselectie
Taakspecifieke modellen presteren vaak beter dan algemene modellen wat betreft kosteneffectiviteit. De AWS-documentatie benadrukt dat het grootste model niet altijd nodig is voor elke toepassing.
Bij een trapsgewijze aanpak worden eerst de goedkopere modellen uitgeprobeerd en wordt pas overgeschakeld naar duurdere modellen wanneer de nauwkeurigheid onder bepaalde drempelwaarden daalt. Dit zorgt voor een dynamische balans tussen kosten en kwaliteit.
Onderzoek naar kosten-batenanalyse definieert prestatiepariteit als benchmarkscores binnen 20% van de beste commerciële modellen, die de normen binnen bedrijven weerspiegelen waarbij kleine nauwkeurigheidsverschillen worden gecompenseerd door kosten-, beveiligings- en integratievoordelen.
Cachingstrategieën
Het cachen van antwoorden voor herhaalde query's elimineert volledig overbodige LLM-aanroepen. Semantische caching gaat nog een stap verder door vergelijkbare (niet alleen identieke) query's te herkennen en antwoorden uit de cache terug te geven.
De documentatie van OpenAI over kostenoptimalisatie benadrukt caching als een primaire strategie. De Batch API en flex processing bieden aanvullende mechanismen voor kostenreductie bij workloads die niet tijdsgevoelig zijn.
Strategische verstikking
Rate limiting voorkomt prijsstijgingen tijdens onverwachte verkeerspieken. Het tokenbeleid van Apigee legt limieten op die beschermen tegen ongebreidelde uitgaven.
Op wachtrijen gebaseerde architecturen vangen verkeerspieken op zonder het LLM-gebruik direct op te schalen. Dit gaat ten koste van een zekere latentie, maar resulteert in voorspelbare kosten.
Implementatie-best practices
Het implementeren van kostenbewaking vereist zowel technische integratie als organisatorische processen.
Instrumentatiebenadering
Instrumenteer LLM-aanroepen op SDK-niveau in plaats van te proberen providerdashboards te scrapen. Directe integratie legt verzoekmetadata vast, zoals gebruikers-ID's, feature flags en sessiecontexten, waardoor gedetailleerde kostentoewijzing mogelijk is.
De meeste observatieplatformen bieden SDK's of OpenTelemetry-integraties die automatisch traceringen vastleggen. Handmatige instrumentatie biedt meer controle, maar vereist meer technische inspanning.
Waarschuwingsconfiguratie
Stel gelaagde waarschuwingen in op basis van absolute bestedingsdrempels en procentuele stijgingen. Een dagelijkse budgetwaarschuwing van $100 detecteert geleidelijke stijgingen, terwijl een waarschuwing van 200% voor uurlijkse stijgingen plotselinge pieken detecteert.
AWS-kostenanomaliedetectie werkt voor infrastructuur, maar reageert vaak te laat bij op tokens gebaseerde kosten. Realtime monitoring via gespecialiseerde LLM-observatieplatformen spoort problemen sneller op.
Teamonderwijs
Ontwikkelaars moeten inzicht hebben in de kosten die hun keuzes met zich meebrengen. Door het aantal tokens en de geschatte kosten tijdens de ontwikkeling te tonen, wordt het kostenbewustzijn vergroot.
De documentatie van Claude Code laat zien dat het commando /cost statistieken op sessieniveau levert, waaronder de totale kosten, de duur en de codewijzigingen. Het inbouwen van vergelijkbare feedbackloops in interne tools leidt tot betere beslissingen.
Regelmatige audits
Maandelijkse kostenanalyses brengen optimalisatiemogelijkheden aan het licht en bevestigen dat de controles naar behoren werken. Door de kosten per gebruiker, per functionaliteit en per transactie bij te houden, wordt duidelijk waar de uitgaven zich concentreren.
Door de werkelijke kosten te vergelijken met de initiële schattingen worden planningslacunes aan het licht gebracht en worden toekomstige prognoses verbeterd.
Het meten van ROI en succes
Kostenbewaking kost op zich al tijd en middelen. Teams hebben duidelijke meetbare resultaten nodig om de investering te rechtvaardigen.
De belangrijkste prestatie-indicatoren zijn onder meer:
- Kosten per applicatiefunctie of gebruikerssessie
- Percentage reductie in tokenverbruik na optimalisatie
- Gemiddelde tijd om kostenafwijkingen te detecteren
- Verschil tussen begrote en werkelijke uitgaven
Onderzoek naar efficiënte agenten heeft een prestatie van 96,7% van OWL bereikt, terwijl de operationele kosten zijn verlaagd van $0,398 naar $0,228, wat resulteerde in een verbetering van 28,4% in de kosten per doorgang (bron: arXiv: Efficient Agents).
Het doel is niet om de kosten ten koste van alles te minimaliseren, maar om de waarde per bestede dollar te maximaliseren. Soms leveren hogere kosten proportioneel meer waarde op.
Veelvoorkomende valkuilen die je moet vermijden
Een aantal fouten ondermijnt steevast de inspanningen om de kosten te bewaken.
Monitoring in isolatie, zonder optimalisatieacties, is verspilling van tijd en energie. Data zonder beslissingen leiden niet tot lagere kosten. Bouw feedbackloops die inzichten omzetten in snelle veranderingen, modelselecties of architectuurverbeteringen.
Te vroeg optimaliseren tijdens de ontwikkeling vertraagt de iteratiesnelheid. Wacht tot de gebruikspatronen stabiel zijn voordat je agressief gaat optimaliseren. Voortijdige optimalisatie op basis van prototypegebruik weerspiegelt zelden de productierealiteit.
Ook het negeren van opportuniteitskosten is belangrijk. De tijd die ontwikkelaars besteden aan het optimaliseren van een uitgave van $50 per maand kan meer kosten dan alleen het betalen van de rekening. Concentreer uw optimalisatie-inspanningen op de gebieden waar de uitgaven het hoogst zijn.
Het negeren van de afwegingen tussen latentie en prestaties creëert nieuwe problemen. Agressieve caching of modelselectie kan de kosten verlagen, maar de responstijden zodanig verlengen dat de gebruikerservaring eronder lijdt. Monitor beide aspecten tegelijkertijd.
Toekomstige trends in kostenbeheer voor LLM-opleidingen
Het landschap van kostenbewaking blijft zich snel ontwikkelen naarmate de technologie volwassener wordt.
Probabilistische kostenbeperkingen vertegenwoordigen een opkomende aanpak. Onderzoek op ArXiv naar geoptimaliseerde modelcascades beschrijft C3PO, een systeem dat de selectie van LLM's optimaliseert met probabilistische kostenbeperkingen voor redeneertaken. Dit gaat verder dan eenvoudige drempelwaarden en omvat geavanceerde optimalisatie van de afweging tussen kosten en kwaliteit.
Multiprovider-routering op basis van realtime prijsstelling zal steeds gebruikelijker worden. Naarmate de mogelijkheden van modellen op elkaar aansluiten, neemt de prijsconcurrentie toe. Systemen die aanvragen dynamisch doorsturen naar de goedkoopste provider met voldoende kwaliteit, zullen een concurrentievoordeel opleveren.
Gespecialiseerde hardware voor inferentie blijft de prijs-prestatieverhouding verbeteren. Prijsgegevens van Hugging Face tonen aan dat Intel Sapphire Rapids x1-instanties beginnen bij $0,033/uur (op de datum van het bronmateriaal). Aangepaste AI-acceleratoren van cloudproviders blijven de kosten drukken.
Maar wacht even. Lagere basisprijzen nemen de behoefte aan monitoring niet weg. Ze verschuiven de focus van optimalisatie van de totale uitgaven naar efficiëntiemetingen zoals de kosten per succesvol afgeronde taak.
Veelgestelde vragen
Hoe bereken ik de kosten van een LLM API-verzoek?
Vermenigvuldig de inputtokens met de inputtokenprijs van het model en tel daar vervolgens de outputtokens vermenigvuldigd met de outputtokenprijs bij op. Bijvoorbeeld, met Amazon Nova Micro tegen $0.000035 per 1.000 inputtokens en $0.00014 per 1.000 outputtokens, kost een verzoek met 500 inputtokens en 1.500 outputtokens ongeveer $0.0000175 + $0.00021 = $0.0002275.
Wat is het verschil tussen LLM-monitoring en traditionele APM?
Traditionele applicatieprestatiemonitoring richt zich op infrastructuurstatistieken zoals CPU, geheugen en aanvraaglatentie. LLM-monitoring voegt daar tokenverbruik, modelselectie, promptpatronen en kostenattributie aan toe, specifiek voor generatieve AI-workloads. Veel platforms integreren tegenwoordig beide functionaliteiten.
Kan ik de kosten bij meerdere LLM-aanbieders in de gaten houden?
Ja. Platforms zoals Datadog LLM Observability ondersteunen meerdere aanbieders, waaronder OpenAI, Anthropic en Amazon Bedrock, in één overzichtelijk dashboard. Dit maakt kostenvergelijkingen en routeringsstrategieën voor meerdere aanbieders mogelijk.
Hoeveel kan kostenoptimalisatie realistisch gezien besparen?
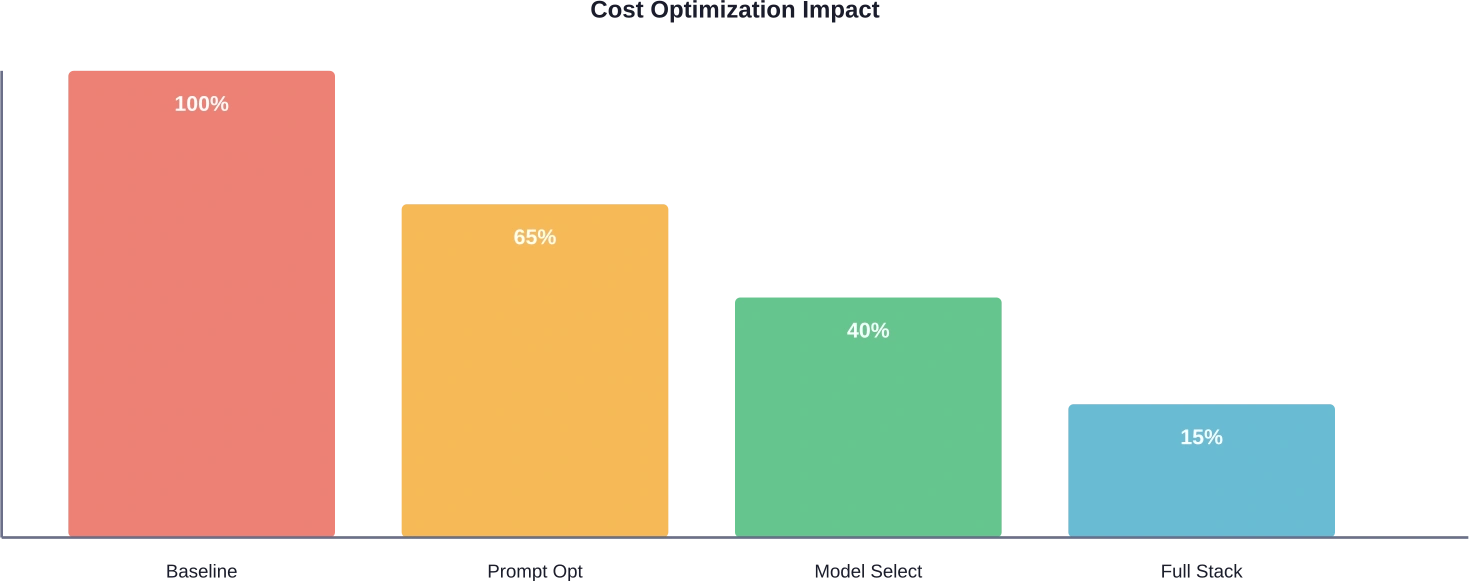
De resultaten van optimalisatie variëren per toepassing. AWS-tests toonden potentiële kostenbesparingen tot 901 TP3T voor Step Functions Express-workflows in vergelijking met Standard-workflows bij dezelfde workload. Prompt engineering verlaagt de kosten doorgaans met 20-401 TP3T, modelselectie met nog eens 30-501 TP3T, en caching elimineert volledig redundante aanroepen. De exacte besparingen zijn afhankelijk van de basisefficiëntie en de optimalisatie-inspanning.
Moet ik de modellen zelf hosten om de kosten te drukken?
Zelfhosting is zinvol bij voldoende schaal. Onderzoek van ArXiv naar kosten-batenanalyses toont aan dat het omslagpunt afhangt van het gebruiksvolume, de technische mogelijkheden en of prestatiegelijkheid met commerciële modellen haalbaar is. Voor veel organisaties blijven beheerde services kosteneffectiever wanneer de benodigde ontwikkeltijd wordt meegerekend.
Hoe vaak moet ik de kosten van een LLM-opleiding herzien?
Controleer tijdens de eerste implementatie dagelijks de realtime dashboards om configuratieproblemen vroegtijdig op te sporen. Voer wekelijks gedetailleerde kostenanalyses uit tijdens de actieve ontwikkelingsfase en maandelijks zodra het gebruik stabiel is. Stel geautomatiseerde waarschuwingen in voor afwijkingen in plaats van uitsluitend te vertrouwen op geplande controles.
Welke meetgegevens zijn het belangrijkst voor kostenbeheer bij een LLM-opleiding?
Houd de kosten per gebruikerssessie, de kosten per succesvol voltooide taak, de tokenefficiëntie (outputwaarde per token) en de kostenafwijking ten opzichte van het budget bij. Deze meetgegevens koppelen uitgaven direct aan bedrijfsresultaten in plaats van kosten te beschouwen als abstracte infrastructuuruitgaven.
Verder met de kostenbewaking van LLM
Het beheersen van de kosten van LLM-aanvragen vereist continue transparantie, strategische optimalisatie en organisatorische discipline. Het op tokens gebaseerde prijsmodel verschilt fundamenteel van traditionele infrastructuurkosten en vereist daarom gespecialiseerde monitoringmethoden.
Begin met native monitoringtools van providers zoals OpenAI, Anthropic of AWS Bedrock. Deze ingebouwde mogelijkheden bieden basisinzicht zonder extra platformkosten. Naarmate applicaties schalen, kunt u overwegen om gebruik te maken van dedicated observability-platforms zoals Datadog of Langfuse voor geavanceerde functies zoals ondersteuning voor meerdere providers en geavanceerde waarschuwingen.
De echte waarde schuilt in het koppelen van monitoring aan actie. Houd kosten bij, identificeer optimalisatiemogelijkheden door middel van snelle engineering en modelselectie, en meet de impact van wijzigingen. Bouw feedbackloops die ontwikkelaars helpen de kostenimplicaties tijdens de ontwikkeling te begrijpen, in plaats van problemen pas in productie te ontdekken.
Kostenoptimalisatie gaat niet over het minimaliseren van uitgaven tegen elke prijs. Het gaat erom de waarde per bestede dollar te maximaliseren, met behoud van kwaliteits- en prestatienormen. De juiste monitoringinfrastructuur maakt die balans haalbaar.
Klaar om de controle over uw LLM-uitgaven te nemen? Begin vandaag nog met het implementeren van eenvoudige token-tracking in uw applicaties. Kleine verbeteringen stapelen zich snel op wanneer ze consequent worden toegepast op alle LLM-aanroepen.