Korte samenvatting: NLP (Natural Language Processing) gebruikt op regels gebaseerde en statistische methoden voor specifieke taaltaken tegen lagere kosten, terwijl LLM's (Large Language Models) neurale netwerken zijn die getraind zijn op enorme datasets en uitblinken in generatieve taken, maar aanzienlijk meer kosten. Door beide benaderingen te combineren – NLP voor classificatie en routering, en LLM's voor complexe redeneringen – kunnen de inferentiekosten met 40-90% worden verlaagd, terwijl de kwaliteit behouden blijft.
Iedereen is dol op grote modellen, totdat de rekening komt. Wat tijdens de testfase slechts een paar cent per aanvraag lijkt, loopt in de productie op tot duizenden per maand.
De realiteit? De meeste AI-workloads hebben geen GPT-redenering op elk afzonderlijk queryniveau nodig. Maar zonder een goede kostenarchitectuur komt elke aanvraag sowieso terecht bij het duurste model.
Het punt is echter dat NLP en LLM's geen concurrerende technologieën zijn. Het zijn complementaire tools die, strategisch gecombineerd, zowel prestaties als kostenefficiëntie opleveren. Begrijpen wanneer je welke aanpak moet gebruiken, gaat niet alleen over geld besparen. Het gaat erom duurzame AI-systemen te bouwen die schaalbaar zijn.
Inzicht in het kostenverschil tussen NLP en LLM
Traditionele natuurlijke taalverwerking en grote taalmodellen werken op basis van fundamenteel verschillende economische principes. Dit onderscheid is belangrijk omdat het direct van invloed is op de productiebudgetten.
NLP-systemen brengen doorgaans initiële ontwikkelingskosten met zich mee, zoals het opstellen van regelsets, het trainen van kleinere, gespecialiseerde modellen en het creëren van classificatiepipelines. Eenmaal geïmplementeerd, blijven de inferentiekosten minimaal. Het verwerken van tekst via reguliere expressies, named entity recognition of kleine classificatiemodellen vereist nauwelijks rekenkracht.
LLM's draaien dit model volledig om. De ontwikkelingskosten zijn lager omdat de basismodellen al getraind zijn. Maar de inferentiekosten worden de grootste kostenpost. Elk verwerkt token – zowel input als output – brengt kosten met zich mee.
De realiteit van de tokeneconomie
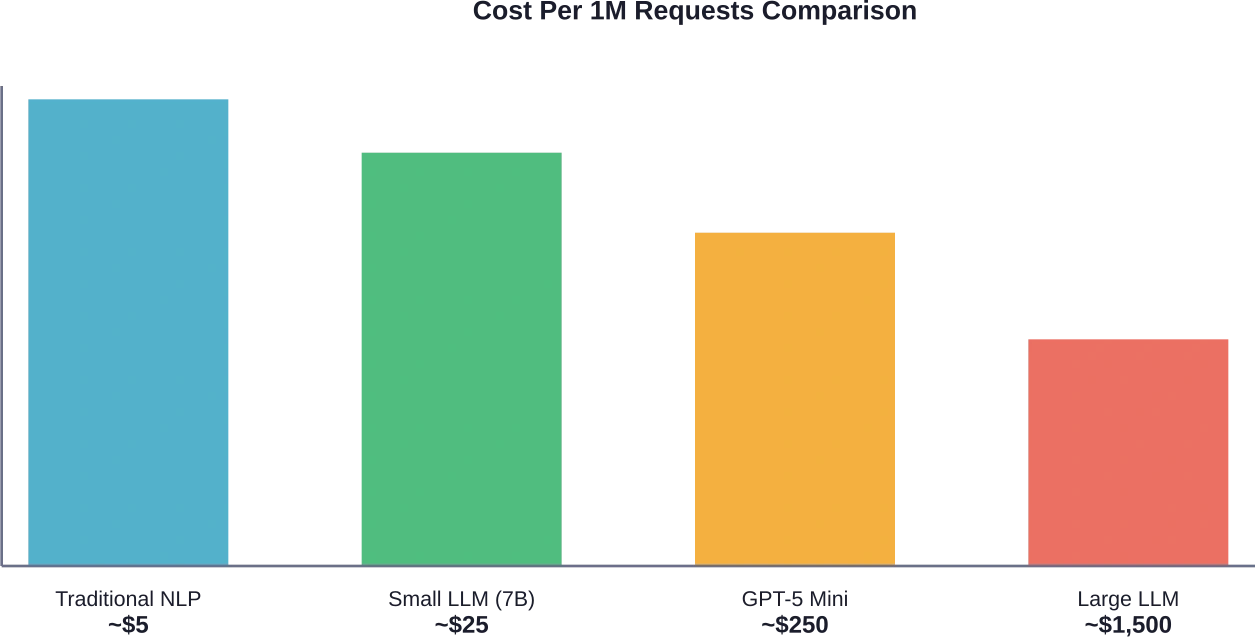
Bij prijsstelling op basis van tokens schalen de kosten lineair met het gebruik. Volgens gegevens van Hugging Face Inference Providers lopen de huidige marktprijzen voor concurrerende modellen aanzienlijk uiteen:
| Model | Aanbieder | Invoer (per 1 miljoen tokens) | Uitvoer (per 1 miljoen tokens) | Contextvenster |
|---|---|---|---|---|
| GPT-5 Mini | Open AI | $0.25 | $2.00 | ~400k |
| Qwen3.5-35B-A3B | Novita | $0.25 | $2.00 | 262,144 |
| Qwen3.5-27B | Novita | $0.30 | $2.40 | 262,144 |
| Qwen3.5-397B-A17B | Samen | $0.60 | $3.60 | 262,144 |
Uitvoertokens kosten steevast 8 tot 10 keer meer dan invoertokens. Deze asymmetrie bestraft uitgebreide antwoorden. Een chatbot die antwoorden van 500 woorden genereert, verbruikt het budget exponentieel sneller dan een chatbot die is geoptimaliseerd voor beknopte antwoorden.
Eerlijk gezegd: die $0,25 per miljoen inputtokens klinkt goedkoop totdat de productieomvang toeneemt. Verwerk maandelijks 100 miljoen tokens – makkelijk haalbaar voor een middelgrote applicatie – en dat is $25.000 alleen al voor de input. Tel daar de output bij op en de werkelijke kosten lopen flink op.
Infrastructuurkosten die verder gaan dan API-aanroepen
De prijsstelling van cloud-GPU's voegt daar nog een extra dimensie aan toe. Volgens een analyse van Hugging Face over de economie van cloudcomputing, domineren de infrastructuurkosten bij zelfhostingmodellen.
De kapitaalinvestering voor GPU-capaciteit vormt de grootste belemmering. Fysieke infrastructuur is minder belangrijk dan de initiële hardwarekosten. Voor organisaties die hun eigen inferentie uitvoeren, verschuift dit het kostenmodel van betaling per token naar planning met vaste capaciteit.
Maar wacht even. Cloud-instanties worden nog steeds per uur gefactureerd. Op basis van de modelgrootte en de hardware-implementatiepatronen die in branchebronnen zijn gedocumenteerd, ontstaan er praktische beperkingen rondom:
| Modelmaat | VRAM (FP16) | VRAM (4-bit) | Cloud-instantietype | Typische gebruiksscenario's |
|---|---|---|---|---|
| 1-3B | 4-6 GB | ~2 GB | AWS g4dn.xlarge | Basis chat, classificatie, automatisch aanvullen |
| 7-8B | 14-16 GB | ~6-8 GB | AWS g5.xlarge | Algemene gevolgtrekking |
Traditionele NLP-componenten draaien probleemloos op CPU-systemen. Er is geen speciale hardware nodig. Het kostenverschil wordt pas echt groot bij grotere schaal.
Waar traditionele NLP kostenvoordelen biedt
Bepaalde taken op het gebied van taalverwerking profiteren niet van de mogelijkheden van LLM. Voor deze taken leveren traditionele NLP-methoden gelijkwaardige of betere resultaten tegen een fractie van de kosten.
Classificatie- en routeringstaken
Intentieclassificatie, sentimentanalyse, onderwerpcategorisatie: dit zijn opgeloste problemen. Kleine, gespecialiseerde modellen, getraind voor specifieke classificatietaken, behalen een nauwkeurigheid van 95%+ en verwerken duizenden verzoeken per seconde op minimale hardware.
Een op BERT gebaseerde classifier, verfijnd voor het routeren van klantenservice, kan 110 miljoen parameters gebruiken. Vergelijk dat eens met de miljarden parameters van GPT-5 Mini. Het classificatiemodel voert inferentie uit in enkele milliseconden op de CPU. Een LLM-aanroep duurt honderden milliseconden en kost per aanvraag vele malen meer.
Discussies binnen de community brengen praktische voorbeelden aan het licht. Volgens een casestudy van Lumitech bleek uit een analyse van hun LLM-gebruik dat 80% aan query's eenvoudig waren. Elke aanvraag belastte onnodig hun duurste model.
Door eerst een NLP-classificatielaag te implementeren, konden ze eenvoudige taken toewijzen aan lichtgewicht modellen en LLM's reserveren voor complexe redeneringen. Het resultaat: een kostenbesparing van 10x – van $200 naar $20 per maand – zonder kwaliteitsverlies.
Patroonherkenning en entiteitsextractie
Reguliere expressies en op regels gebaseerde extractiesystemen kosten vrijwel niets om te gebruiken. Wanneer de vereisten goed gedefinieerd zijn, werken de regels perfect.
E-mailvalidatie, telefoonnummeropmaak, datumparsing, adresnormalisatie: hiervoor zijn geen neurale netwerken nodig. Op regels gebaseerde systemen voeren taken in microseconden uit, zonder API-aanroepen of modelinferentie.
Named entity recognition (NOR) werkt volgens vergelijkbare economische principes. De statistische modellen van SpaCy extraheren entiteiten met hoge nauwkeurigheid in meerdere talen. Eenmaal in het geheugen geladen, is de verwerking vrijwel direct. Geen kosten per aanvraag. Geen tokentelling.
Domeinspecifieke taaltaken
Gespecialiseerde NLP-modellen die getraind zijn voor specifieke domeinen presteren vaak beter dan algemene LLM's en zijn bovendien goedkoper.
De verwerking van medische teksten profiteert van BioBERT of vergelijkbare domeinspecifieke modellen. Analyse van juridische documenten werkt beter met juridische NLP-pipelines. Financiële sentimentanalyse bereikt een hogere nauwkeurigheid met FinBERT dan met generieke LLM's.
Deze modellen bevatten tussen de 100 en 400 miljoen parameters. Zelf hosten wordt economisch haalbaar. De trainingskosten zijn eenmalig. De inferentiekosten worden bij schaalvergroting vrijwel nul.
Wanneer de kosten van een LLM-opleiding zinvol zijn
LLM's rechtvaardigen hun prijskaartje voor specifieke toepassingen. De sleutel is het afstemmen van de mogelijkheden op de vereisten.
Generatieve en creatieve taken
Contentgeneratie, creatief schrijven, codesynthese, samenvatten – dat is het domein van LLM. Traditionele NLP kan geen samenhangende, lange teksten genereren. Op regels gebaseerde systemen kunnen geen marketingteksten schrijven die menselijk klinken.
Bij generatieve workloads worden LLM-kosten onvermijdelijk. De vraag verschuift van óf LLM's moeten worden gebruikt naar welke modelcategorie de beste prijs-kwaliteitverhouding biedt.
OpenAI meldt dat GPT-5 Mini een score van 91,1% behaalt in de AIME-wiskundewedstrijd en 87,8% in een interne "intelligentie"-meting. De prestaties zijn vergelijkbaar met die van veel grotere modellen. Met $0,25 per miljoen inputtokens biedt het baanbrekende mogelijkheden tegen een betaalbare prijs.
Complexe redeneringen en meerstapsvraagstukken
Redeneren in gedachteketens, het beantwoorden van vragen met meerdere stappen, het oplossen van wiskundige problemen: kleinere modellen hebben hier moeite mee. Grotere LLM's met miljarden parameters vertonen opkomende redeneervermogens die de hogere kosten rechtvaardigen.
Maar hier wordt het interessant. Niet elke complexe taak vereist het grootste model. Onderzoek naar het optimaliseren van het gebruik van LLM's laat methoden zien die de kosten met 40-90% verlagen en tegelijkertijd de kwaliteit met 4-7% verbeteren.
De methodologie omvat een uitgebreide evaluatie van verschillende modelniveaus. De resultaten tonen consequent aan dat de selectie van een taakspecifiek model de kwaliteit waarborgt en tegelijkertijd de kosten beheerst.
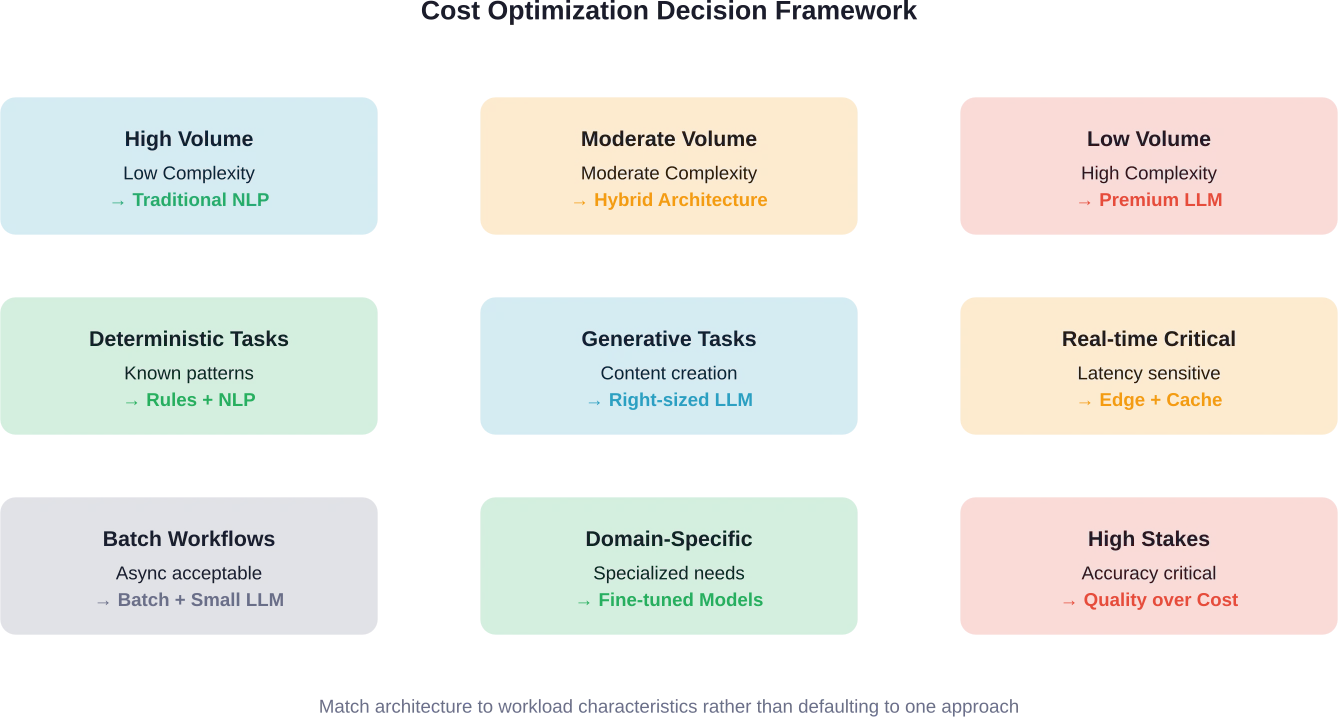
Werkstromen met een laag volume en hoge waarde
Wanneer het aantal aanvragen laag is en de beslissingswaarde hoog, worden de LLM-kosten verwaarloosbaar in vergelijking met de impact op de bedrijfsvoering.
Een juridisch onderzoeksinstrument dat dagelijks 100 zoekopdrachten verwerkt, profiteert van de mogelijkheden van LLM. Zelfs met een premium prijs kunnen de maandelijkse kosten oplopen tot $50-200. De waarde van een nauwkeurige juridische analyse overstijgt die kosten ruimschoots.
Vergelijk dit eens met een chatbot die 100.000 interacties per dag afhandelt. Hetzelfde model, ander volume, compleet ander kostenprofiel. Scenario's met een hoog volume vereisen optimalisatie. Werkprocessen met een laag volume kunnen zich premiummodellen veroorloven.
De hybride architectuurbenadering
De meest kosteneffectieve productiesystemen combineren NLP en LLM's strategisch. Het is geen keuze tussen het een of het ander.
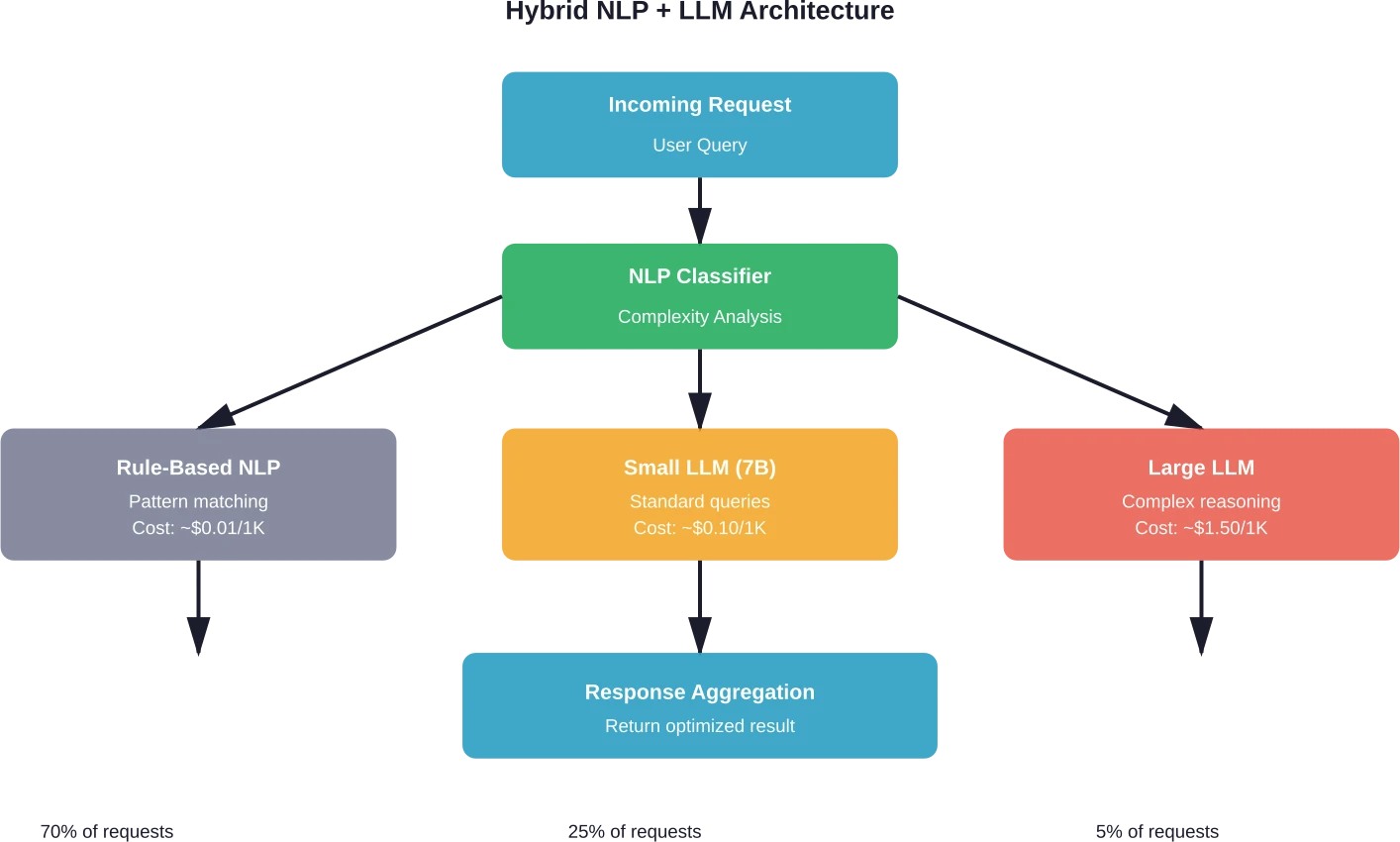
Intelligente aanvraagroutering
Classificatielagen bepalen de complexiteit voordat verzoeken naar de juiste modellen worden doorgestuurd. Eenvoudige taken worden uitgevoerd door snelle, goedkope modellen. Complexe redeneringen worden doorgestuurd naar krachtige LLM's.
De implementatie vereist verschillende componenten. Ten eerste analyseert een lichtgewicht classificator de binnenkomende verzoeken. Dit kan een verfijnd BERT-model zijn of zelfs eenvoudigere heuristieken gebaseerd op de lengte van de zoekopdracht, trefwoorden en structuur.
De classificator categoriseert verzoeken in niveaus: eenvoudige feitelijke vragen, rechtstreekse taken, gemiddelde complexiteit en complexe redeneringen. Elk niveau komt overeen met een ander verwerkingspad.
Teams die intelligente routering implementeren, melden kostenbesparingen van 30-50% zonder meetbare kwaliteitsvermindering wanneer routeringsstrategieën modellen effectief afstemmen op taakvereisten. De sleutel is systematische evaluatie die de routeringslogica valideert en kwaliteitsnormen handhaaft over alle modelniveaus.
Caching en responsoptimalisatie
Semantische caching voorkomt overbodige LLM-aanroepen. Wanneer gebruikers vergelijkbare vragen stellen, worden de in de cache opgeslagen antwoorden direct weergegeven zonder dat dit ten koste gaat van de inferentiekosten.
Traditionele caching vergelijkt exacte zoekopdrachten. Semantische caching gebruikt embeddings om vergelijkbare vragen met een andere formulering te identificeren. Een vectorgelijkeniszoekopdracht bepaalt of de in de cache opgeslagen antwoorden aan nieuwe zoekopdrachten voldoen.
Het inbedden van modellen is goedkoop in gebruik. Zelfs met de extra inbeddingsstap verlaagt het serveren van gecachede antwoorden de kosten aanzienlijk in vergelijking met volledige LLM-inferentie.
Responsoptimalisatie richt zich op het verminderen van het aantal uitvoertokens. Door prompts zo te ontwerpen dat beknopte antwoorden worden aangemoedigd, worden de kosten direct verlaagd. Omdat uitvoertokens 8-10 keer zoveel kosten als invoertokens, leiden uitgebreide antwoorden tot onevenredig hoge kosten.
Progressieve verbetering
Begin met het kleinst mogelijke model. Ga pas over op grotere modellen als dat nodig is.
Een multi-agentsysteem zou taken eerst kunnen uitvoeren met een model met 7 miljard parameters. Als de betrouwbaarheidsscores onder een drempelwaarde komen, probeert het systeem het automatisch opnieuw met een beter model. De meeste verzoeken slagen bij de eerste poging. Alleen in moeilijke gevallen zijn de kosten hoger.
Deze aanpak vereist betrouwbaarheidskalibratie. Modellen moeten hun eigen onzekerheid nauwkeurig inschatten. Goed gekalibreerde modellen weten wanneer ze waarschijnlijk zullen falen en kunnen automatisch een escalatieverzoek indienen.
Praktische kostenoptimalisatiestrategieën
Productiesystemen maken gelijktijdig gebruik van meerdere tactieken. Geen enkele optimalisatie lost het kostenprobleem op zichzelf op. De combinatie levert resultaten op.
Snelle engineering voor efficiëntie
De lengte van de prompt heeft direct invloed op de kosten. Elk token in de prompt wordt verwerkt en in rekening gebracht.
Overmatige context, langdradige instructies, overbodige voorbeelden – deze factoren verhogen het aantal invoertokens onnodig. Gestroomlijnde prompts die de vereisten beknopt weergeven, verlagen de kosten zonder in te boeten aan kwaliteit.
Een beperkt aantal voorbeelden laat het gewenste gedrag zien, maar verbruikt tokens. Door verschillende aantallen voorbeelden te testen, worden de optimale afwegingen gevonden. Soms bereiken drie voorbeelden dezelfde nauwkeurigheid als tien, terwijl er 70% minder tokens worden gebruikt.
Modeloptimalisatie
Groter is niet altijd beter. Bij de keuze van een model dat geschikt is voor de taak, wordt een balans gevonden tussen mogelijkheden en kosten.
Benchmarksuites zoals MMLU, HumanEval en domeinspecifieke evaluaties laten zien welke modellen adequaat presteren voor specifieke taken. Een model met een score van 85% kost mogelijk slechts een tiende van een model met een score van 90%. Het verschil van 5 punten in nauwkeurigheid rechtvaardigt mogelijk geen tienvoudige kostenverhoging voor bepaalde toepassingen.
Uitgebreide benchmarktests en analyses tonen aan dat kleinere modellen voor specifieke taken vaak de mogelijkheden van veel grotere modellen benaderen. DeepSeek V3.2-Exp evenaart en overtreft zijn voorganger V3.1 in openbare benchmarks en biedt tegelijkertijd een betere kostenefficiëntie dankzij architectonische verbeteringen.
Batchverwerking en asynchrone workflows
Realtime inferentie is duurder dan batchverwerking. Wanneer onmiddellijke resultaten niet vereist zijn, verlaagt het bundelen van verzoeken de kosten.
Het samenvatten van documenten, het modereren van content en het extraheren van gegevens: deze taken tolereren vaak enige vertraging. Verwerking in batches zorgt voor een efficiënter gebruik van resources en maakt het mogelijk om volumekortingen met leveranciers af te spreken.
Asynchrone workflows ontkoppelen het indienen van verzoeken van de levering van resultaten. Gebruikers dienen taken in, gaan door met ander werk en ontvangen de resultaten zodra de verwerking is voltooid. Deze flexibiliteit maakt kostenoptimalisatie mogelijk die door realtime beperkingen niet mogelijk is.
Vergelijking van de huidige marktprijzen
De prijzen van aanbieders variëren aanzienlijk. Het loont de moeite om prijzen te vergelijken.
Op basis van gegevens van begin 2026 blijkt dat concurrerende prijzen zich concentreren rond een aantal categorieën. Instapmodellen zoals de GPT-5 Mini en Qwen3.5-35B-A3B beginnen bij $0.25 per miljoen inputtokens en $2.00 per miljoen outputtokens.
De middenklasse modellen hebben ingangsprijzen van $0.30 tot $0.60. De premium, grote modellen hebben ingangsprijzen die hoger liggen dan $0.60.
De grootte van het contextvenster beïnvloedt de waardeberekeningen. Modellen met contextvensters van 256K tot 400K maken andere architectuurpatronen mogelijk dan modellen die beperkt zijn tot vensters van 32K tot 128K. Een grotere context vermindert de noodzaak voor meerdere verzoeken bij het verwerken van lange documenten.
| Capaciteitsniveau | Typische inputprijs | Typische outputprijs | Het beste voor |
|---|---|---|---|
| Ingang (7-8B) | $0.10-0.25 / 1M | $0.80-2.00 / 1M | Classificatie, eenvoudige chat, basissamenvatting |
| Midden (30-40B) | $0.25-0.60 / 1M | $2.00-3.60 / 1M | Algemene taken, gemiddeld redeneervermogen |
| Premie (100 miljard+) | $0.60-2.00 / 1M | $3.60-10.00 / 1M | Complexe redeneringen, gespecialiseerde domeinen |
Latentie en doorvoer variëren onafhankelijk van de prijs. Goedkopere modellen zijn niet per se trager. De infrastructuur en optimalisatie van de provider hebben net zoveel invloed op de prestaties als de grootte van het model.
Verborgen kosten om rekening mee te houden
API-prijzen zijn niet de enige kostenfactor. Ontwikkeltijd, complexiteit van het debuggen en onderhoudskosten dragen allemaal bij aan de totale eigendomskosten.
Traditionele NLP vereist meer ontwikkelingswerk vooraf. Het bouwen van classificatiepipelines, het afstemmen van modellen en het onderhouden van regelsets – deze taken vergen de tijd van ervaren engineers.
LLM's verminderen de frictie tijdens de ontwikkeling. Snelle engineering vervangt modeltraining. Iteratiecycli worden korter. Voor teams met beperkte ML-expertise compenseren de gebruiksvriendelijkheid van LLM's de hogere inferentiekosten.
Maar op grote schaal domineren de inferentiekosten. Een systeem dat dagelijks miljoenen verzoeken verwerkt, zal in een jaar meer uitgeven aan LLM-tokens dan aan de initiële ontwikkeling van NLP. De situatie verandert naarmate het volume toeneemt.
Energie- en milieukostenoverwegingen
Financiële kosten lopen parallel met energieverbruik. Onderzoek van arxiv.org naar de energiekosten van LLM-inferentie benchmarkt de relatie tussen rekenkracht en stroomverbruik.
Het berekenen van de energie die nodig is voor het inleiden van grote modellen vereist aanzienlijke hoeveelheden energie. Hoewel de exacte cijfers afhangen van de hardware en optimalisatie, is de trend duidelijk: grotere modellen verbruiken meer energie per token.
Traditionele NLP-modellen verwerken verzoeken met minimale energieoverhead. CPU-gebaseerde inferentie verbruikt veel minder stroom dan GPU-versnelde LLM-inferentie.
Organisaties met duurzaamheidsdoelstellingen staan voor twee uitdagingen: financiële optimalisatie en het verminderen van de CO2-uitstoot. Gelukkig sluiten deze doelen op elkaar aan. Strategieën die de kosten van levensonderhoud verlagen, leiden doorgaans tegelijkertijd tot een lager energieverbruik.
Efficiënte routering die eenvoudige query's doorstuurt naar lichtgewicht modellen verlaagt zowel de kosten als de uitstoot. Het afstemmen van modellen op de taakvereisten levert milieuvoordelen op naast kostenbesparingen.
Een kostenbewuste architectuur bouwen
Duurzame AI-systemen bewaken en optimaliseren de kosten continu. Eenmalige optimalisatie is niet voldoende. Gebruikspatronen veranderen. Modelprijzen wijzigen. Eisen evolueren.
Kostenbewaking en -toewijzing
Het bijhouden van uitgaven per functie, gebruikersniveau of workflow onthult mogelijkheden voor optimalisatie. Geaggregeerde statistieken verbergen welke componenten de uitgaven veroorzaken.
Gedetailleerde logboekregistratie legt metadata van verzoeken vast: gebruikt model, aantal tokens, latentie, kosten en zakelijke context. Deze gegevens maken analyses mogelijk waarmee kostbare patronen kunnen worden geïdentificeerd.
Sommige functionaliteiten kunnen onevenredig hoge kosten met zich meebrengen in verhouding tot de zakelijke waarde. Uit een gebruiksanalyse zou bijvoorbeeld kunnen blijken dat 5% aan gebruikers 60% van het LLM-budget verbruiken door inefficiënte interactiepatronen. Gerichte optimalisatie of herontwerp van functionaliteiten pakt deze uitschieters aan.
Test- en evaluatiekaders
Kostenoptimalisatie vereist meting. Kwaliteitsindicatoren bevestigen dat goedkopere alternatieven acceptabele prestaties leveren.
Evaluatiekaders vergelijken de resultaten van modellen op verschillende niveaus. Menselijke evaluatie of geautomatiseerde kwaliteitsbeoordeling bepaalt of kleinere modellen voldoende nauwkeurigheid behalen voor specifieke taken.
A/B-testen in een productieomgeving meten de gebruikerstevredenheid bij verschillende modelselecties. Als gebruikers bij bepaalde zoekopdrachten geen onderscheid kunnen maken tussen de reacties van een 7B-model en een 70B-model, voegt het duurdere model geen waarde toe.
Continue optimalisatielussen
Statische architecturen worden minder optimaal naarmate modellen verbeteren en prijzen veranderen. Regelmatige evaluatie identificeert betere alternatieven.
Er komen regelmatig nieuwe modellen op de markt. Een model dat volgende maand verschijnt, biedt mogelijk een betere prijs-kwaliteitverhouding dan de huidige modellen. Door continu te vergelijken met nieuwe releases, zorgen we ervoor dat systemen optimaal profiteren van de beschikbare waarde.
Prijsaanpassingen vinden zonder aankondiging plaats. Door tariefwijzigingen van meerdere aanbieders te monitoren, kan er opportunistisch worden overgestapt wanneer concurrenten een beter aanbod hebben.
Toekomstige kostentrends
De prijsontwikkeling is belangrijk voor de planning op lange termijn. Verschillende factoren beïnvloeden de toekomstige kosten.
De efficiëntie van modellen blijft verbeteren. Architectonische innovaties leveren betere prestaties per parameter op. Onderzoek van arxiv.org naar de efficiëntie van grote taalmodellen documenteert algoritmische vooruitgang die de rekenkundige vereisten verlaagt.
Herontworpen modellen bereiken vergelijkbare mogelijkheden met minder parameters door architecturale optimalisatie. Naarmate deze technieken zich verder ontwikkelen, dalen de kosten per eenheid van functionaliteit.
Concurrentie tussen aanbieders zorgt voor neerwaartse prijsdruk. Naarmate er meer spelers op de markt komen, versnelt de prijscompressie. De introductie van de GPT-5 Mini, Gemini 2.5 Flash en Claude 3.5 Haiku creëerde een nieuwe categorie van krachtige modellen tegen aanzienlijk lagere prijzen dan eerdere generaties.
De hardware blijft zich verbeteren. Nieuwe GPU-architecturen leveren een hogere inferentiedoorvoer. Naarmate de hardware efficiënter wordt, kunnen leveranciers lagere prijzen aanbieden en tegelijkertijd hun marges behouden.
Maar tegelijkertijd neemt de vraag toe. Naarmate meer applicaties LLM's integreren, stijgen de totale uitgaven, zelfs als de kosten per token dalen. Organisaties die niet actief optimaliseren, zien hun uitgaven stijgen ondanks dalende eenheidsprijzen.
Implementatieplan
De overstap van een dure, volledig op LLM gebaseerde architectuur naar kostengeoptimaliseerde hybride systemen vereist planning.
Fase 1: Meting en analyse
Voorzie bestaande systemen van instrumenten om gedetailleerde gebruiksstatistieken vast te leggen. Zonder data is optimalisatie giswerk.
Registreer elk LLM-verzoek met metadata: tijdstempel, gebruiker, functie, prompt-tokens, voltooiingstokens, gebruikt model, latentie en kosten. Aggregeer deze gegevens voor analyse.
Identificeer patronen. Welke functies genereren de meeste verzoeken? Welke gebruikers verbruiken de meeste tokens? Welke promptpatronen komen vaak voor?
Bereken de kosten per functie, per gebruikerssegment en per bedrijfsresultaat. Dit laat zien waar optimalisatie-inspanningen het meeste rendement opleveren.
Fase 2: Snelle successen
Gemakkelijk te realiseren besparingen leveren direct resultaat op en creëren tegelijkertijd momentum voor grotere initiatieven.
Implementeer promptoptimalisatie. Verwijder onnodige context, schrap omslachtige instructies en bundel voorbeelden. Dit vereist minimale ontwikkelingsinspanning, maar vermindert direct het tokenverbruik.
Voeg semantische caching toe. Voor de meeste programmeertalen bestaan bibliotheken die de implementatie eenvoudig maken. Caching kan 20 tot 401 TP3T aan verzoeken elimineren met minimale codeaanpassingen.
Kies duidelijke voorbeelden van optimale optimalisatie. Taken die momenteel gebruikmaken van premium modellen, maar vergelijkbare resultaten opleveren met modellen uit het middensegment, bieden duidelijke mogelijkheden voor optimalisatie.
Fase 3: Strategische architectuur
Grotere projecten vergen meer planning, maar leveren aanzienlijke en langdurige besparingen op.
Bouw de classificatie- en routeringslaag op. Dit vormt de infrastructuur waarop andere optimalisaties voortbouwen. Begin eenvoudig: classificeer verzoeken in eerste instantie in twee of drie niveaus.
Zet taakspecifieke NLP-modellen in voor deterministische workloads met een hoog volume. Deze modellen vervangen LLM-aanroepen volledig voor specifieke gebruikssituaties.
Implementeer progressieve verbetering voor complexe query's. Probeer eerst goedkopere modellen en schaal alleen op wanneer nodig.
Fase 4: Continue verbetering
Optimalisatie is geen project met een einddatum, maar een continu proces.
Plan driemaandelijkse evaluaties van de modelprestaties en -prijzen. Er komen voortdurend nieuwe opties bij. Regelmatige evaluatie zorgt ervoor dat systemen meegroeien met de veranderende omstandigheden.
Monitor kostenstatistieken naast bedrijfsstatistieken. Beschouw kostenefficiëntie als een belangrijke prestatie-indicator, naast kwaliteit, latentie en gebruikerstevredenheid.
Experimenteer met nieuwe benaderingen. Reserveer budget voor het testen van alternatieve architecturen, nieuwe modellen en verschillende aanbieders. De beste optimalisatie voor het volgende kwartaal bestaat mogelijk nog niet.

Verlaag uw AI-kosten voordat ze uit de hand lopen.
De keuze tussen NLP-systemen en grote taalmodellen kan een enorme impact hebben op de AI-uitgaven op de lange termijn. AI Superieur Ze werken samen met bedrijven die AI-systemen nodig hebben die zijn ontworpen voor efficiëntie in de praktijk. Hun team bouwt en verfijnt LLM's (Learning Learning Models), ontwikkelt taakspecifieke modellen en optimaliseert AI-gestuurde workflows, zodat bedrijven het computergebruik kunnen verminderen met behoud van prestaties.
Als u de kosten van AI wilt verlagen in plaats van ze alleen maar op te schalen, neem dan contact op met AI Superieur en ontvang praktische begeleiding bij het bouwen van efficiëntere AI-systemen.
Veelvoorkomende valkuilen die je moet vermijden
Kostenoptimalisatie kan averechts uitpakken als het onzorgvuldig wordt gedaan. Verschillende fouten doen zich dan steeds opnieuw voor.
Voortijdige optimalisatie
Projecten in een vroeg stadium profiteren van snelle iteratie dankzij LLM's. Het is zonde van de middelen om wekenlang aangepaste NLP-pipelines te bouwen voordat de product-marktfit is gevalideerd.
Begin met de eenvoudigste aanpak die werkt. Optimaliseer pas wanneer de schaalvergroting daarom vraagt, niet eerder. Voortijdige optimalisatie leidt de aandacht af van de kernactiviteiten van het product.
Optimaliseren zonder meten
Aannames over de oorzaken van kostenstijgingen blijken vaak onjuist. Gedetailleerde metingen brengen verrassende patronen aan het licht.
Teams optimaliseren soms de verkeerde onderdelen. Een functie die duur lijkt, kan wel 3% aan totale kosten vertegenwoordigen. Ondertussen slokt een over het hoofd geziene workflow stilletjes 40% aan budget op.
Meet eerst de resultaten. Optimaliseer de gebieden met de grootste impact. Negeer minder belangrijke factoren totdat de belangrijkste problemen zijn aangepakt.
Kwaliteit opofferen voor kostenbesparing
Agressieve kostenbesparingen die ten koste gaan van de kwaliteit van de output, blijken contraproductief. Slechte AI-ervaringen schaden het vertrouwen van gebruikers en ondermijnen de productwaarde.
Handhaaf kwaliteitsnormen. Gebruik evaluatiekaders om te controleren of goedkopere alternatieven aan de eisen voldoen. Als dat niet het geval is, is de duurdere optie de juiste keuze.
Ontwikkelingssnelheid negeren
Complexe architecturen voor kostenoptimalisatie kunnen de ontwikkeling vertragen. Het opofferen van flexibiliteit voor marginale kostenbesparingen is zelden zinvol voor producten in een vroeg ontwikkelingsstadium.
Weeg de optimalisatie-inspanning af tegen de bedrijfswaarde. Een systeem dat 1.000 dagelijkse aanvragen verwerkt, heeft niet dezelfde strenge optimalisatie nodig als een systeem dat er 1.000.000 verwerkt.
Veelgestelde vragen
Hoeveel kan een hybride NLP + LLM-architectuur realistisch gezien besparen?
Onderzoek en rapporten uit de gemeenschap tonen kostenbesparingen aan variërend van 401 TP3T tot 901 TP3T, afhankelijk van de kenmerken van de werklast. Systemen met een groot volume aan eenvoudige query's realiseren de grootste besparingen. Applicaties die voornamelijk bestaan uit complexe generatieve taken laten kleinere, maar nog steeds significante besparingen zien. De belangrijkste factor is het percentage verzoeken dat kan worden afgehandeld door goedkopere NLP-benaderingen versus verzoeken die de volledige LLM-functionaliteit vereisen.
Presteren kleinere LLM's eigenlijk wel goed genoeg voor gebruik in een productieomgeving?
Moderne, kleine LLM's zoals de GPT-5 Mini behalen verrassend hoge prestaties in benchmarks. OpenAI rapporteert 91,11 TP3T op AIME-wiskundeproblemen en 87,81 TP3T op interne intelligentiemetingen. Voor veel productietaken evenaren of overtreffen deze modellen de kwaliteit van de vorige generatie grote modellen, terwijl ze 5 tot 10 keer minder kosten. Taakspecifieke evaluatie is essentieel, aangezien de prestaties per gebruiksscenario verschillen.
Wat is het omslagpunt voor het bouwen van aangepaste NLP-modellen versus het gebruik van LLM's?
Over het algemeen rechtvaardigen deterministische taken met een hoog volume de ontwikkeling van aangepaste NLP-modellen. Als een taak dagelijks duizenden verzoeken ontvangt en kan worden afgehandeld door classificatie of extractie, verdienen aangepaste modellen zichzelf binnen enkele weken terug. Bij taken met een laag volume of een hoge variabiliteit zijn LLM's (Large-Led Models) de voorkeur, ondanks de hogere kosten per verzoek, omdat de ontwikkelingsinspanning niet over voldoende verzoeken kan worden afgeschreven.
Hoe bepaal ik welke aanvragen dure modellen vereisen en welke goedkope?
Begin met een lichtgewicht classificator die de kenmerken van verzoeken analyseert: lengte, structuur, trefwoorden en domein. Op basis van deze signalen worden verzoeken naar de juiste modelniveaus doorgestuurd. De initiële classificatienauwkeurigheid hoeft niet perfect te zijn; bouw feedbackloops in die verkeerd doorgestuurde verzoeken identificeren en de classificatie in de loop van de tijd verfijnen. Veel teams melden dat eenvoudige heuristieken verrassend goed werken als uitgangspunt.
Welke monitoringstatistieken moet ik bijhouden voor kostenoptimalisatie van LLM?
Houd het aantal tokens voor invoer en uitvoer apart bij, aangezien de prijsstelling aanzienlijk verschilt. Monitor de kosten per aanvraag, per gebruiker, per functionaliteit en per bedrijfsresultaat. Volg de verdeling van modelselectie om routeringspatronen te begrijpen. Meet de cache-hitratio's als u semantische caching gebruikt. Monitor kwaliteitsstatistieken naast de kosten om ervoor te zorgen dat optimalisatie de prestaties niet verslechtert. Stel waarschuwingen in wanneer de kosten de verwachte patronen overschrijden.
Is het voordeliger om API-services te gebruiken of zelf te hosten om kosten te besparen?
Het antwoord hangt af van de schaal en de technische mogelijkheden. API-services bieden gemak en elimineren de overheadkosten voor infrastructuurbeheer. Bij gemiddelde volumes is prijsstelling per token vaak voordeliger dan het onderhouden van GPU-infrastructuur. Zelfhosting wordt kosteneffectief bij zeer hoge volumes, waar de kosten per aanvraag de afgeschreven infrastructuurkosten overstijgen. Uit een analyse van cloudcomputing door Hugging Face blijkt dat de kapitaalinvestering de belangrijkste belemmering vormt voor zelfhosting, in plaats van de operationele complexiteit.
Hoe vaak veranderen de prijzen van LLM en moet ik daar rekening mee houden bij mijn bouwplannen?
De prijzen van providers wijzigen periodiek, soms zonder voorafgaande kennisgeving. Grote releases introduceren vaak nieuwe prijsniveaus. Door abstractielagen te bouwen die de modelselectie scheiden van de bedrijfslogica, kunnen providers of modellen worden gewisseld zonder ingrijpende refactoring. Ondersteuning voor meerdere providers maakt opportunistische routering mogelijk naar de provider die op een bepaald moment de beste prijs biedt voor specifieke aanvraagtypen.
Conclusie
De keuze tussen NLP en LLM's is niet zwart-wit. De meest kosteneffectieve AI-systemen voor productieomgevingen combineren beide benaderingen strategisch.
Traditionele NLP blinkt uit in deterministische taken met een hoog volume. Op regels gebaseerde systemen en gespecialiseerde modellen verwerken eenvoudige verzoeken tegen minimale kosten. LLM's bieden mogelijkheden die traditionele methoden niet kunnen evenaren, maar tegen aanzienlijk hogere kosten.
Slimme architectuur stuurt verzoeken door naar de juiste verwerkingslagen. Classificatielagen identificeren eenvoudige taken die geen dure modellen vereisen. Complexe redeneringen worden doorgestuurd naar krachtige LLM's. Deze hybride aanpak verlaagt de kosten met 40-90% met behoud van kwaliteit.
Kostenoptimalisatie vereist voortdurende inspanning. Metingen onthullen patronen. Evaluatie valideert alternatieven. Regelmatige evaluaties zorgen ervoor dat systemen meegroeien met verbeterde modellen en prijswijzigingen.
Begin met meten. Instrumenteer uw huidige systeem om inzicht te krijgen in uitgavenpatronen. Identificeer snelle winsten door middel van snelle optimalisatie en caching. Bouw een strategische architectuur voor efficiëntie op de lange termijn. Beschouw kostenbeheer als een doorlopende praktijk in plaats van een eenmalig project.
Organisaties die deze balans weten te vinden, zullen duurzame AI-systemen bouwen die economisch schaalbaar zijn. Degenen die voor alles kiezen voor dure modellen, zullen te maken krijgen met budgetbeperkingen die innovatie belemmeren.
Aan u de volgende stap: breng uw huidige kosten in kaart, identificeer optimalisatiemogelijkheden en voer systematische verbeteringen door. De tools en technieken bestaan. De vraag is of u ze ook daadwerkelijk zult gebruiken.