Korte samenvatting: Open-source LLM's elimineren licentiekosten, maar verschuiven de kosten naar infrastructuur, talent en onderhoud. Minimale interne implementaties kosten jaarlijks 1 TP4 TB 125.000 tot 1 TP4 TB 190.000, terwijl implementaties op bedrijfsniveau meer dan 1 TP4 TB 12 miljoen kunnen kosten. De kosteneffectiviteit hangt af van het gebruiksvolume, de technische expertise en de aanpassingsbehoeften; propriëtaire API's blijken vaak goedkoper voor lichte tot middelzware workloads.
De belofte klinkt aantrekkelijk: download een open-source, grootschalig taalmodel, implementeer het op je eigen infrastructuur en vermijd de terugkerende API-kosten van propriëtaire diensten. Geen facturering per token meer. Geen vendor lock-in.
Maar er is een probleem: dat 'gratis' model heeft een prijskaartje waar de meeste organisaties niet bij stilstaan.
Open-source LLM's verschuiven de kosten van voor de hand liggende posten zoals licentiekosten naar minder zichtbare, maar even substantiële kosten: gespecialiseerd technisch talent, GPU-infrastructuur, doorlopend onderhoud en operationele overhead. Deze verborgen kosten kunnen de kosten van commerciële API-diensten ruimschoots overtreffen, met name op kleinere schaal.
De keuze tussen open-source en propriëtaire LLM's gaat niet over gratis versus betaald. Het gaat erom welke kostenstructuur het beste aansluit bij uw gebruikspatronen, technische mogelijkheden en zakelijke behoeften.
Waarom open-source LLM's eigenlijk niet gratis zijn
De term 'open source' schept een gevaarlijke misvatting. Ja, je kunt modelgewichten downloaden zonder licentiekosten. Maar het implementeren van die gewichten in productieomgevingen vereist aanzienlijke middelen.
Proprietäre LLM-diensten zoals OpenAI's GPT-5.2, Google Gemini of Anthropic's Claude rekenen per token. Begin 2026 kostte OpenAI's GPT-5.2 Pro $21,00 per miljoen inputtokens ($168 output), terwijl budgetvarianten zoals GPT-5.2 Mini beginnen bij $0,25 per miljoen inputtokens. Volgens geverifieerde prijsgegevens weerspiegelen deze tarieven een reeks niveaus die een balans bieden tussen prestaties en kosten. DeepSeek's V3.2-Exp "denkende" modellen worden aangeboden voor $0,28 per miljoen inputtokens (cache-miss) en $0,42 per miljoen outputtokens, aanzienlijk goedkoper dan westerse concurrenten.
Open-source modellen draaien deze vergelijking om. In plaats van gebruiksafhankelijke kosten betaal je voor:
- Hardware aanschaffen of GPU's huren in de cloud
- Salarissen voor ingenieurs voor implementatie en integratie
- Infrastructuurbeheer en -monitoring
- Beveiligingsversterking en nalevingswerkzaamheden
- Modeloptimalisatie en -fijnstelling
- Doorlopend onderhoud en ondersteuning
Deze kosten blijven relatief vast, ongeacht het gebruiksvolume, waardoor een fundamenteel ander economisch model ontstaat dan bij API's met betaling per gebruik.
De werkelijke kosten van infrastructuur
Het uitvoeren van LLM's vereist aanzienlijke rekenkracht. Modellen met miljarden parameters vereisen GPU's met veel VRAM, snelle interconnecties en robuuste koelsystemen.
Vereisten voor hardware-investeringen
Voor een minimale productie-implementatie is doorgaans minstens één krachtige GPU nodig. De A100 GPU's van NVIDIA, die veel gebruikt worden voor LLM-inferentie, kosten tussen de 10.000 en 15.000 euro per stuk. Grotere modellen of hogere doorvoereisen verhogen dat bedrag snel.
Maar de aanschaf van hardware is slechts het begin. Fysieke infrastructuur vereist rackruimte, stroomvoorziening, koelsystemen en netwerkverbindingen. Organisaties zonder bestaande datacentercapaciteit worden geconfronteerd met extra kapitaaluitgaven voor deze ondersteunende systemen.
De economie van cloud-GPU's
Cloud GPU-instances bieden een alternatief voor het bezit van hardware, maar de kosten blijven aanzienlijk. Volgens een analyse van Hugging Face naar de economische aspecten van GPU-clouds, domineren de investeringskosten de prijsstructuren in de cloud. Zo kost een NVIDIA Tesla V100 doorgaans zo'n 10.000 USD om aan te schaffen, terwijl de gemiddelde huurprijs per uur tussen de 12 en 13 miljard USD ligt. Dit betekent dat de uurtarieven voor cloudopslag snel oplopen bij continu gebruik.
En dit is wat de initiële kostenramingen in de war schopt: inferentieworkloads vereisen continue beschikbaarheid. In tegenstelling tot trainingstaken die eenmalig worden uitgevoerd, draaien productieomgevingen continu. Die 24/7-werking zet de uurkosten voor de cloud om in hoge maandelijkse rekeningen.
De investering in menselijk kapitaal
Infrastructuur is slechts één kostenpost. De specialistische kennis die nodig is voor het implementeren en onderhouden van open-source LLM's overstijgt vaak de hardwarekosten.
Vereiste technische functies
Productie-LLM-implementaties vereisen meerdere gespecialiseerde rollen. MLOps-engineers houden zich bezig met implementatiepipelines, inferentieoptimalisatie en het schalen van de infrastructuur. Software-integratie-engineers bouwen de verbindingen tussen modellen en bestaande systemen – werk dat volgens beschikbare gegevens doorgaans zo'n 601 TP3T aan engineeringinspanning in AI-projecten vergt.
DevOps-specialisten beheren Kubernetes-clusters, containerorkestratie en infrastructuurbewaking. Beveiligingsengineers implementeren toegangscontroles, auditregistratie en compliance-frameworks. Data-engineers bouwen pipelines voor het verfijnen en evalueren van modellen.
In de huidige competitieve markt voor AI-talent gaan voor elke functie aanzienlijke salarissen gepaard. Senior ML-engineers verdienen vaak tussen de 1.150.000 en 250.000 dollar per jaar, waarbij de totale beloningspakketten voor toptalent nog hoger kunnen uitvallen.
Doorlopende ondersteuningsvereisten
Maar dit is wat organisaties vaak overvalt: implementatie is geen eenmalig project. Productie-LLM-systemen vereisen continue aandacht.
Modellen moeten periodiek worden bijgewerkt naarmate de mogelijkheden verbeteren. Inferentiestacks zoals vLLM of NVIDIA Triton vereisen onderhoud en optimalisatie. Integratiepunten vallen weg wanneer upstream-systemen veranderen. De prestaties verslechteren zonder continue afstemming.
Dit creëert een permanente personeelsbehoefte. Organisaties kunnen geen open-source LLM implementeren en er vervolgens niets meer aan doen; ze verbinden zich tot een voortdurende investering in engineering.
Kostenscenario's uit de praktijk
Abstracte kostencategorieën zijn minder belangrijk dan concrete scenario's. Wat kost het nu echt om open-source LLM's op verschillende schaalniveaus te gebruiken?
Minimale interne implementatie
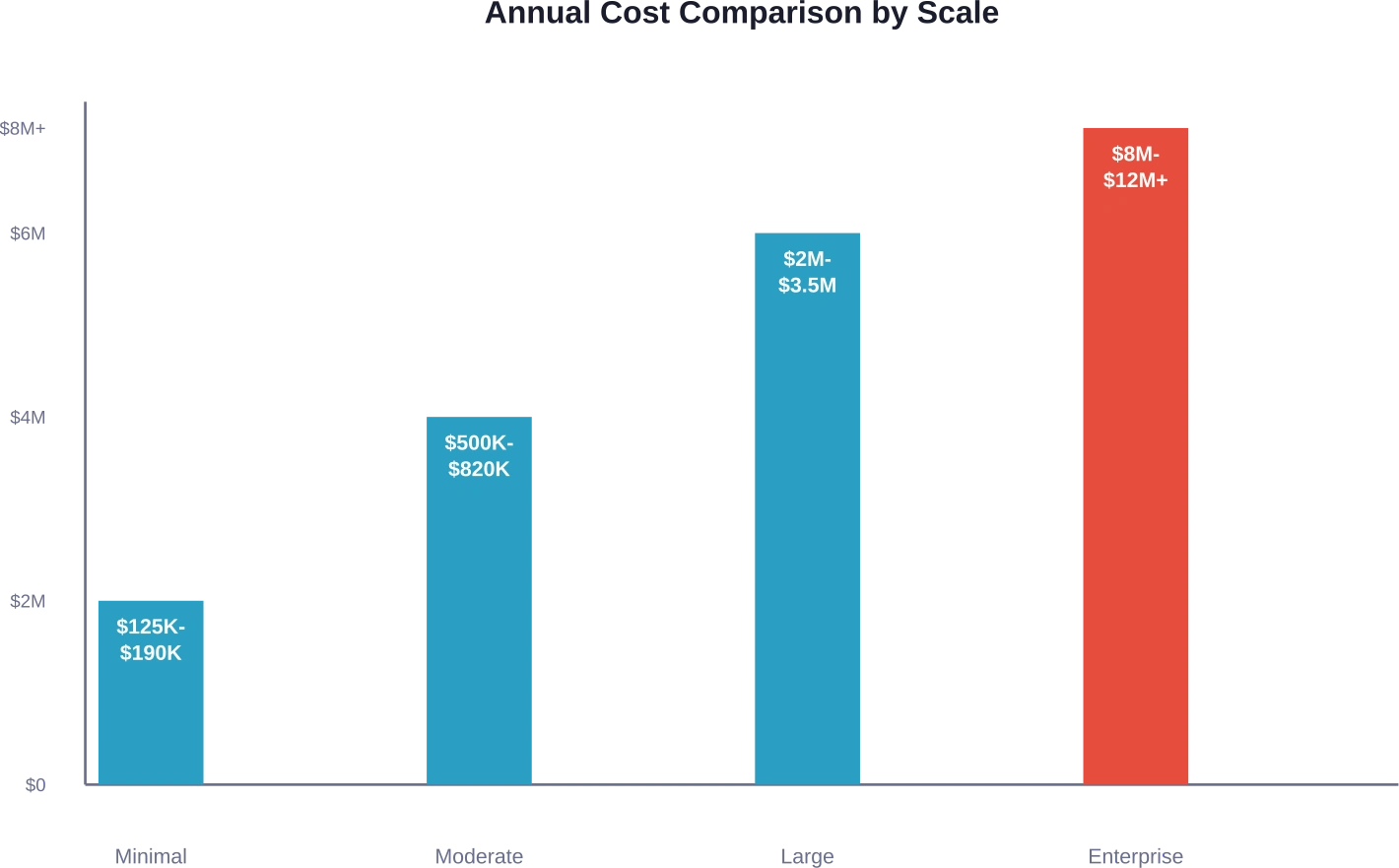
Een eenvoudige interne chatbot of documentanalysetool voor een klein team is het meest basale implementatiescenario. Volgens kostenramingen uit brancheanalyses kosten zelfs minimale interne implementaties jaarlijks tussen de 125.000 en 190.000 dollar.
Dit scenario gaat uit van de volgende aannames:
- Cloud GPU-instanties in plaats van hardwareaankoop.
- Inferentie-opstelling met één GPU
- Deeltijdse technische ondersteuning (geen vast personeel)
- Minimale aanpassingsmogelijkheden, afgezien van de meest basale fijnafstelling.
- Laag queryvolume (honderden tot enkele duizenden per dag)
De kosten zijn grofweg als volgt op te delen: cloudinfrastructuur (40%), engineeringtijd (45%) en monitoring-/beveiligingstools (15%).
Gemiddelde klantgerichte functies
Klantgerichte applicaties verhogen de risico's aanzienlijk. Hogere beschikbaarheidseisen, een groter queryvolume en de behoefte aan productondersteuning drijven de kosten voor middelgrote implementaties op tot 1.500.000 tot 1.820.000 dollar per jaar.
Dit scenario omvat doorgaans:
- Multi-GPU-configuratie voor redundantie en doorvoer.
- Toegewijd engineeringteam (2-3 voltijdse functies)
- Aangepaste fijnafstemming voor domeinspecificiteit
- Uitgebreide monitoring en waarschuwingen
- Beveiligingsversterking en nalevingswerkzaamheden
De infrastructuurkosten stijgen, maar de engineeringkosten blijven het hoogst. Het bouwen van betrouwbare, productieklare systemen vereist een voortdurende engineeringinspanning die veel verder reikt dan de initiële implementatie.
Kernproducten op bedrijfsniveau
Wanneer LLM-functionaliteiten centraal komen te staan in het productaanbod, lopen de kosten dramatisch op. Implementaties op bedrijfsniveau die duizenden gelijktijdige gebruikers bedienen, kunnen jaarlijks meer dan 1 TP4 TB 8 miljoen tot 1 TP4 TB 12 miljoen kosten.
Deze implementaties vereisen:
- GPU-clusters met meerdere regio's voor betere prestaties en redundantie.
- Toegewijde engineeringteams (8-15+ engineers)
- Uitgebreide modeloptimalisatie en aangepaste architecturen
- Beveiligings- en compliancekaders voor bedrijven
- 24/7 operationele ondersteuning
Op deze schaal worden de personeelskosten voor de engineeringafdeling de belangrijkste kostenpost, die de infrastructuurkosten ruimschoots overtreft.
| Implementatieschaal | Jaarlijkse kostenrange | Belangrijkste kostenfactoren | Typische gebruiksscenario's
|
|---|---|---|---|
| Minimale interne | $125K–$190K | Cloud-GPU's, deeltijdtechniek | Interne chatbots, documentanalyse |
| Gemiddelde klantgerichtheid | $500K–$820K | Toegewijd engineeringteam, multi-GPU | Automatisering van klantondersteuning, contentgeneratie |
| Grootschalige productie | $2M–$3.5M | Grote engineeringteams, geoptimaliseerde infrastructuur | Kernproductkenmerken, API's voor grote volumes |
| Kernproduct voor bedrijven | $8M–$12M+ | Uitgebreide teams, clusters verspreid over meerdere regio's | Bedrijfskritische AI-producten en platformaanbiedingen |
Prijsstelling van de eigen LLM API in 2026
Om de kosten van open-source software te vergelijken, is het belangrijk om de alternatieven van propriëtaire software te begrijpen. De prijsstelling van API's is aanzienlijk veranderd, waarbij grote aanbieders hun tarieven hebben aangepast en nieuwe prijsniveaus hebben geïntroduceerd.
Huidige prijsstelling
Begin 2026 liepen de prijzen van eigen LLM-systemen sterk uiteen. Volgens geverifieerde prijsgegevens die tot februari 2026 zijn bijgewerkt:
- OpenAI's GPT-5.2 Pro kost $21,00 per miljoen inputtokens en $168,00 per miljoen outputtokens, wat hun premium vlaggenschip-niveau vertegenwoordigt. Standaard GPT-5.2 kost respectievelijk $1,75 en $14,00, terwijl GPT-5.2 Mini budgetvriendelijke tarieven biedt van $0,25 en $2,00.
- De prijsstelling van Google Gemini varieert per model. Hun nieuwste aanbiedingen bieden een goede balans tussen prestaties en kosten voor verschillende gebruiksscenario's.
- De Claude-modellen van Anthropic behouden hun concurrentiepositie in het midden- tot premiumsegment, met de nadruk op de gewenste lengte en veiligheidsvoorzieningen.
- xAI heeft Grok 4 gelanceerd voor $3/$15 per miljoen tokens, Grok 4 Fast voor $0.20/$0.50 en Grok 4.1 Fast voor $0.20/$0.50 per miljoen tokens.
- De V3.2-Exp "denkende" modellen van DeepSeek kosten $0,28 per miljoen inputtokens (cache-miss) en $0,42 per miljoen outputtokens, aanzienlijk goedkoper dan westerse concurrenten.
Kostenberekeningen op basis van gebruik
De API-kosten schalen lineair met het gebruik. Een applicatie die maandelijks 100 miljoen tokens verwerkt met GPT-5.2 Pro (à $21,00 per miljoen inputtokens) zou jaarlijks ongeveer $25K aan inputtokens kosten. Dezelfde workload op DeepSeek V3.2-Exp kost jaarlijks ongeveer $336 – een verschil van 74 keer.
Deze lineaire schaalvergroting zorgt voor duidelijke break-evenpunten. Toepassingen met een hoog volume rechtvaardigen uiteindelijk investeringen in open-source infrastructuur. Bij lichte tot middelzware workloads is het gebruik van API's vrijwel altijd voordeliger.
Het omslagpunt hangt af van de specifieke prijsniveaus en infrastructuurkosten, maar ligt voor de meeste organisaties doorgaans ergens tussen de 50 en 200 miljoen tokens per maand.
Verborgen operationele kosten
Naast de voor de hand liggende infrastructuur- en salariskosten, brengen open-source LLM-implementaties minder zichtbare operationele kosten met zich mee die zich in de loop der tijd opstapelen.
Monitoring en observeerbaarheid
Productie-LLM-systemen vereisen uitgebreide monitoring. Het bijhouden van latentie, doorvoerstatistieken, foutpercentages en resourcegebruik moet allemaal in realtime inzichtelijk zijn.
Commerciële observability-platformen berekenen kosten op basis van datavolume en bewaartermijnen. Deze kosten stijgen met de complexiteit van het systeem en het dataverkeer.
Maatwerkoplossingen voor monitoring verschuiven de kosten naar de ontwikkeltijd – het bouwen van dashboards, waarschuwingssystemen en diagnostische tools vergt aanzienlijke ontwikkelingsmiddelen.
Modelupdates en versiebeheer
Open-source LLM-ecosystemen ontwikkelen zich snel. Er verschijnen regelmatig nieuwe modelversies met verbeterde mogelijkheden, hogere efficiëntie of bugfixes.
Elke update vereist testen, validatie en een implementatieplanning. Regressietesten zorgen ervoor dat nieuwe versies de bestaande functionaliteit niet verstoren. Prestatiebenchmarking valideert verbeteringen. Terugdraaiprocedures bereiden voor op mogelijke storingen.
Organisaties kunnen updates niet zomaar negeren; achterstand oplopen met cruciale beveiligingspatches of prestatieverbeteringen leidt tot technische schulden en concurrentienadelen.
Beveiliging en naleving
LLM-implementaties die gevoelige gegevens verwerken, moeten aan strenge beveiligingsvereisten voldoen. Toegangscontrole, auditregistratie, gegevensversleuteling en netwerkisolatie vereisen allemaal implementatie en onderhoud.
Compliancekaders zoals SOC 2, HIPAA of GDPR leggen aanvullende eisen op. Regelmatige beveiligingsaudits, penetratietests en kwetsbaarheidsbeheer brengen terugkerende kosten met zich mee.
Aanbieders van propriëtaire API's verzorgen doorgaans de nalevingscertificeringen en de beveiligingsinfrastructuur, waardoor deze lasten voor de klant worden weggenomen. Open-source implementaties nemen deze verantwoordelijkheid volledig op zich.
Wanneer open source financieel aantrekkelijk is
Ondanks de aanzienlijke kosten bieden open-source LLM's in specifieke scenario's overtuigende economische voordelen.
Werkbelastingen bij grootschalige productie
Het omslagpunt waarop open-source goedkoper wordt dan API's hangt af van het gebruiksvolume. Het maandelijks verwerken van honderden miljoenen of miljarden tokens leidt tot enorme API-kosten die investeringen in infrastructuur rechtvaardigen.
Een applicatie die maandelijks 500 miljoen tokens verwerkt via eigen API's van gemiddelde kwaliteit, zou jaarlijks tussen de $200K en $400K kunnen opleveren. Dezelfde workload op een zelfgehoste infrastructuur zou in totaal tussen de $300K en $500K kunnen kosten, maar met een relatief vlakke schaalvergroting daarna.
Bij een omvang van miljarden tokens verschuift de economie duidelijk naar zelfhosting.
Specialistische domeinvereisten
Sommige toepassingen vereisen uitgebreide fijnafstemming op basis van domeinspecifieke gegevens. Medische diagnoses, analyse van juridische documenten of gespecialiseerde technische vakgebieden profiteren van modellen die getraind zijn op domeinspecifieke corpora.
Aanbieders van propriëtaire API's bieden diensten voor fijnafstelling, maar de kosten lopen snel op bij uitgebreide aanpassingen. Open-source modellen maken onbeperkte fijnafstelling mogelijk zonder kosten per trainingsmodule.
Organisaties met zeldzame talen, gespecialiseerde woordenschat of unieke opmaakvereisten vinden open-source modellen wellicht geschikter, hoewel de specifieke kosten-batenverhouding per gebruikssituatie verschilt.
Gegevensprivacy en -soevereiniteit
Wettelijke voorschriften verbieden soms het verzenden van gevoelige gegevens naar externe API's. Medische dossiers, financiële informatie of vertrouwelijke gegevens vereisen mogelijk verwerking op locatie.
Open-source LLM's maken volledige controle over gegevens mogelijk. Informatie verlaat nooit de organisatiestructuur, wat de naleving van regelgeving vereenvoudigt en risico's vermindert.
De waarde van deze controle hangt af van de gevoeligheid van de gegevens en de regelgeving, maar voor sommige organisaties is het ononderhandelbaar, ongeacht de kosten.
Strategische onafhankelijkheid op lange termijn
Afhankelijkheid van externe API-aanbieders brengt strategische risico's met zich mee. Aanbieders kunnen de prijzen verhogen, modellen stopzetten of de servicevoorwaarden wijzigen. Serviceonderbrekingen hebben directe gevolgen voor applicaties die ervan afhankelijk zijn.
Open-source implementaties elimineren de afhankelijkheid van leveranciers. Organisaties bepalen zelf hun beschikbaarheid, prijsstelling en roadmap.
Een onderzoekspaper op arXiv over kosten-batenanalyse van on-premise LLM-implementatie definieert prestatiepariteit als benchmarkscores binnen 20% van de beste commerciële modellen, wat de normen binnen bedrijven weerspiegelt waarbij kleine nauwkeurigheidsverschillen worden gecompenseerd door kosten-, beveiligings- en integratievoordelen.
Prestatieoverwegingen
Bij kostenvergelijkingen wordt een cruciaal aspect over het hoofd gezien: de prestatieverschillen tussen open-source en propriëtaire modellen.
Capaciteitstekorten
De beste propriëtaire modellen presteren over het algemeen beter dan vergelijkbare open-source alternatieven bij uitdagende redeneertaken, complexe instructies en gespecialiseerde domeinen.
Het verschil varieert aanzienlijk per taaktype. Bij eenvoudige classificatie, gestructureerde data-extractie of sjabloongebaseerde generatie zijn de verschillen minimaal. Complexe redeneringen, genuanceerd taalbegrip of creatieve taken geven de voorkeur aan geavanceerde, gepatenteerde modellen.
Organisaties moeten evalueren of verschillen in mogelijkheden relevant zijn voor hun specifieke toepassingen. Veel applicaties presteren goed met een gemiddeld prestatieniveau tegen lagere kosten.
Optimalisatiemogelijkheden
Open-source implementaties maken uitgebreide optimalisatie mogelijk die niet beschikbaar is bij API-services. Kwantisatie reduceert de modelgrootte en het geheugenverbruik, terwijl de nauwkeurigheid acceptabel blijft. Kennisdestillatie draagt mogelijkheden over naar kleinere, snellere modellen.
Onderzoek gepubliceerd op Hugging Face naar de efficiëntie van redeneerprocessen toonde aan dat kortere redeneerketens vergelijkbare of betere prestaties kunnen leveren met lagere rekenkosten. Specifiek lieten eenvoudige short-1@k-benaderingen tot wel 40% minder denktokens zien in vergelijking met standaardbenaderingen, terwijl de kwaliteit van de output behouden bleef.
Aangepaste inferentiestacks zoals vLLM of NVIDIA Triton bieden prestatieoptimalisatie die niet beschikbaar is via gestandaardiseerde API's. Batchstrategieën, cachingmechanismen en hardwarespecifieke optimalisaties kunnen de doorvoer en latentie aanzienlijk verbeteren.
Latentie en doorvoer
Zelfgehoste infrastructuur maakt geografische distributie dichter bij de gebruikers mogelijk, waardoor de netwerklatentie wordt verminderd. Dedicated hardware elimineert wachttijden die ontstaan door gedeelde API-infrastructuur.
Het bouwen van krachtige inferentiesystemen vereist echter aanzienlijke expertise. Slecht geoptimaliseerde implementaties leiden vaak tot een hogere latentie dan goed ontworpen API-services.
De kostenbeslissing nemen
Bij de keuze tussen open-source en propriëtaire LLM's moet je meerdere aspecten evalueren, die verder gaan dan een simpele kostenvergelijking.
Bereken de totale eigendomskosten.
Nauwkeurige kostenramingen moeten alle kostenposten omvatten:
- Infrastructuur: GPU-hardware of cloudverhuur, netwerken, opslag
- Personeel: Salarissen in de ingenieurssector, wervingskosten, opleiding
- Operaties: Monitoringtools, beveiligingssoftware, compliance-audits
- Opportuniteitskosten: De tijd die ingenieurs aan productontwikkeling besteden, wordt hierdoor afgeleid.
- Risicopremie: Kosten door uitval, prestatieproblemen, beveiligingsincidenten
Organisaties onderschatten steevast de personeels- en operationele kosten, terwijl ze de besparingen op infrastructuurkosten overschatten.
Evalueer de technische mogelijkheden
Succesvolle open-source implementaties vereisen aanzienlijke technische expertise. Teams moeten vaardigheden bezitten op het gebied van gedistribueerde systemen, GPU-programmering, ML-optimalisatie en productiebeheer.
Organisaties die deze expertise missen, hebben twee opties: capaciteit opbouwen door het aannemen en opleiden van personeel (duur en tijdrovend) of externe consultants inhuren (duur en creëert afhankelijkheid).
API-services nemen de meeste technische vereisten weg, waardoor teams zich kunnen concentreren op de applicatielogica in plaats van op de infrastructuur.
Overweeg hybride benaderingen.
De keuze is niet zwart-wit. Veel organisaties combineren met succes verschillende benaderingen.
LLM-routeringsstrategieën selecteren dynamisch modellen op basis van de kenmerken van het verzoek. Eenvoudige query's worden doorgestuurd naar snelle, goedkope modellen, terwijl complexe taken gebruikmaken van krachtige alternatieven. Volgens onderzoek van Hugging Face naar het routeren van batchgewijze instructies, zorgt deze optimalisatie voor een evenwicht tussen prestaties en kosten bij gemengde workloads.
Ontwikkelings- en testomgevingen kunnen API's gebruiken, terwijl de productieomgeving op een eigen infrastructuur draait. Dit verlaagt de infrastructuurkosten tijdens periodes met een laag volume en maakt API-vrije productie mogelijk.
Taakspecifieke specialisatie maakt gebruik van open-source modellen voor gestandaardiseerde taken met een hoog volume, terwijl eigen API's worden ingezet voor complexe, variabele verzoeken.
| Overweging | Voorstander van open source | Geeft de voorkeur aan eigen API's
|
|---|---|---|
| Gebruiksvolume | Zeer hoog (meer dan 500 miljoen tokens per maand) | Laag tot gemiddeld (<100 miljoen tokens/maand) |
| Technische expertise | Sterke ML- en infrastructuurteams | Beperkte expertise op het gebied van machine learning, kleine teams. |
| Aanpassingsbehoeften | Uitgebreide fijnafstelling vereist | Standaardmodellen volstaan |
| Gegevensprivacy | Strikte wettelijke vereisten | Standaard commerciële voorwaarden zijn aanvaardbaar. |
| Tijd tot marktintroductie | Strategische investering op lange termijn | Snelle inzet cruciaal |
| Kostenvoorspelbaarheid | Geef de voorkeur aan vaste infrastructuurkosten. | Variabele kosten aanvaardbaar |
Kostenoptimalisatiestrategieën
Organisaties die zich inzetten voor open-source LLM's kunnen verschillende strategieën toepassen om de kosten te beheersen.
Infrastructuur op de juiste schaal
Bij veel implementaties wordt hardware overgedimensioneerd op basis van piekbelasting in plaats van normaal gebruik. Infrastructuur met automatische schaalbaarheid past de capaciteit dynamisch aan op basis van de vraag, waardoor de kosten van ongebruikte resources worden verlaagd.
Spot-instances en preemptible VM's bieden aanzienlijke cloudkortingen – soms wel 60-801 ton korting op de standaardprijs – in ruil voor mogelijke onderbrekingen. Batchworkloads en ontwikkelomgevingen kunnen goed tegen onderbrekingen.
Modelselectie en -optimalisatie
Kleinere modellen leveren na finetuning verrassend goede prestaties op gespecialiseerde taken. Onderzoek naar het optimaliseren van kleine taalmodellen voor e-commerce-taken toonde aan dat een goed gefinetuned Llama 3.2-model met 1 miljard parameters een nauwkeurigheid van 99% behaalde, wat overeenkomt met de prestaties van GPT-5.1 op het gebied van gespecialiseerde intentieherkenning.
Kwantisatie verlaagt de nauwkeurigheid van modellen van 16-bits naar 8-bits of zelfs 4-bits representaties, waardoor de geheugenvereisten en inferentiekosten met 50-75% worden verlaagd met minimale impact op de kwaliteit.
Modeldestillatie traint kleinere leerlingmodellen om grotere leraarmodellen na te bootsen, waardoor een betere afweging tussen efficiëntie en prestatie wordt bereikt dan bij training vanaf nul.
Efficiënte inferentietechnieken
Door verzoeken te bundelen, worden meerdere invoergegevens tegelijk verwerkt, wat de GPU-benutting aanzienlijk verbetert. Continue batchverwerkingstechnieken maken dynamische batchassemblage mogelijk voor realtime-toepassingen.
KV-cache-optimalisatie vermindert overbodige berekeningen tijdens autoregressieve generatie, met name voor lange contexten of gesprekken die uit meerdere beurten bestaan.
Door middel van request routing worden eenvoudige query's naar kleine, snelle modellen gestuurd en complexe query's naar grotere modellen, waardoor de kosten-prestatieverhouding over de verschillende werkbelastingen wordt geoptimaliseerd.

Bekijk de kosten van uw open-source LLM-opleiding met Technical Insight.
Open-source LLM's lijken misschien goedkoop omdat het basismodel gratis is, maar de werkelijke kosten zitten vaak in de training, finetuning, dataverwerking en implementatie. Beslissingen over modelgrootte, architectuur en integratie hebben een enorme impact op het computergebruik en de lopende operationele kosten. AI Superieur richt zich op het technische werk achter open-source LLM's: het creëren van modellen, het optimaliseren van trainingsworkflows en het opzetten van efficiënte implementatiepipelines, zodat u inzicht krijgt in en controle hebt over uw budget. (aisuperior.com/services/llm-model-creation-services)
Als u in 2026 verborgen kosten wilt bijhouden en een duidelijker beeld wilt krijgen van waar de kosten vandaan komen, begin dan met de technische configuratie. Neem contact op met AI Superieur Om uw huidige open-source LLM-implementatie te evalueren en praktische manieren te vinden om de totale eigendomskosten te verlagen.
Toekomstige kostentrends
De kostenontwikkeling van LLM-opleidingen blijft zich snel ontwikkelen, waarbij verschillende trends het economische landschap hertekenen.
Druk op de API-prijzen
De concurrentie tussen propriëtaire aanbieders neemt toe. De agressieve prijsstelling van DeepSeek van $0,28 per miljoen inputtokens dwong concurrenten om hun eigen tarieven te herzien.
Verbeterde inferentie-efficiëntie verlaagt de kosten voor aanbieders, waardoor lagere prijzen mogelijk zijn met behoud van marges. Voortdurende hardwareverbeteringen en algoritmeoptimalisaties zouden deze trend moeten ondersteunen.
Meer capabele open-source modellen
Het prestatieverschil tussen open-source en propriëtaire modellen wordt steeds kleiner. Modellen die vandaag als open-source worden uitgebracht, evenaren de prestaties van propriëtaire alternatieven van 12 tot 18 maanden geleden.
Deze ontwikkeling vermindert de prestatievermindering die gepaard gaat met het kiezen voor open-source opties, waardoor deze voor meer toepassingen geschikt worden.
Gespecialiseerde kleine modellen
Taakspecifieke, kleine modellen die voor specifieke domeinen zijn getraind, concurreren steeds vaker met grote, algemene modellen op specifieke toepassingen.
Deze gespecialiseerde modellen draaien op goedkopere hardware met lagere operationele kosten, waardoor de economische haalbaarheid van open-source voor specifieke toepassingen verbetert.
Veelvoorkomende fouten bij kostenramingen
Organisaties maken steevast voorspelbare fouten bij het evalueren van de kosten van LLM.
Personeelskosten negeren
De meest voorkomende fout: bestaande technische resources als "gratis" beschouwen omdat de salarissen al begroot zijn.
De implementatie en het onderhoud van LLM vergen aanzienlijke engineeringtijd. Die tijd gaat gepaard met opportuniteitskosten: engineers die aan de infrastructuur werken, kunnen niet tegelijkertijd productfuncties ontwikkelen.
Een correcte kostenberekening omvat alle personeelskosten, niet alleen de extra aanwervingen.
Het onderschatten van de operationele overheadkosten
De initiële implementatie vertegenwoordigt mogelijk 20-301 TP3T aan totale inspanning gedurende een levenscyclus van meerdere jaren. Doorlopend onderhoud, updates, monitoring en optimalisatie nemen het grootste deel van die tijd in beslag.
Organisaties begroten de implementatie, maar onderschatten de operationele behoeften op de lange termijn, wat na de lancering tot een tekort aan middelen leidt.
Piekwaarde vergelijken met gemiddelde waarde
API-kosten die berekend zijn op basis van piekgebruik lijken hoger dan de vaste infrastructuurkosten. De meeste workloads bereiken echter niet continu een piekbelasting; de werkelijke kosten worden bepaald door het gemiddelde gebruik.
De infrastructuur moet rekening houden met piekcapaciteit, waardoor er tijdens normaal gebruik ongebruikte resources beschikbaar blijven. API's brengen alleen kosten in rekening voor daadwerkelijk gebruik en schalen daardoor vanzelfsprekend mee met de vraag.
Compliance en beveiliging over het hoofd zien.
Beveiligingsmaatregelen, compliance-audits en wettelijke vereisten brengen aanzienlijke extra kosten met zich mee voor zelfgehoste implementaties.
Organisaties zonder ervaring met ML-systemen in productieomgevingen onderschatten deze kosten steevast met 50 tot 100 biljoen dollar.
Veelgestelde vragen
Zijn open-source LLM's echt gratis?
Nee. Hoewel modelgewichten zonder licentiekosten beschikbaar zijn, vereist de implementatie een aanzienlijke infrastructuur, gespecialiseerd technisch talent en doorlopend onderhoud. De totale eigendomskosten voor minimale implementaties beginnen rond de 1.125.000 dollar per jaar, terwijl implementaties op bedrijfsniveau de 1.12 miljoen dollar overschrijden.
Wanneer wordt open-source goedkoper dan propriëtaire API's?
Het break-evenpunt ligt doorgaans tussen de 50 en 200 miljoen tokens per maand, afhankelijk van de specifieke API-prijzen en infrastructuurkosten. Bij zeer grote volumes (meer dan 500 miljoen tokens per maand) is zelfhosting vrijwel altijd de beste optie, terwijl bij kleinere volumes meestal API's met betaling per gebruik voordeliger zijn.
Wat zijn de grootste verborgen kosten van open-source LLM's?
Salarissen voor ingenieurs vormen de grootste, vaak over het hoofd geziene kostenpost en nemen doorgaans 45 tot 55 biljoen dollar van de totale kosten in beslag. Organisaties onderschatten steevast de specialistische expertise die nodig is voor implementatie, optimalisatie en doorlopend onderhoud. Beveiligingsversterking en naleving van regelgeving vormen een andere, eveneens vaak onderschatte, kostenpost.
Hoeveel goedkoper zijn open-source LLM's vergeleken met propriëtaire varianten?
Het hangt volledig af van het gebruiksvolume. Bij lage volumes zijn eigen API's aanzienlijk goedkoper – mogelijk 5 tot 10 keer goedkoper als de volledige totale eigendomskosten (TCO) worden meegerekend. Bij zeer hoge volumes kan een zelfgehoste infrastructuur de kosten per token met 50 tot 80 ton verlagen. Het voordeel verschuift afhankelijk van de schaal, de aanpassingsbehoeften en de beschikbare expertise.
Welke technische expertise is nodig om open-source LLM's te beheren?
Voor de implementatie in een productieomgeving zijn ML-engineers nodig voor modeloptimalisatie, MLOps-specialisten voor de implementatie-infrastructuur, DevOps-engineers voor systeembeheer en software-engineers voor integratiewerkzaamheden. Beveiligingsexpertise is cruciaal voor productiesystemen die gevoelige gegevens verwerken. Bij minimale implementaties kunnen deze rollen worden samengevoegd tot 1-2 personen, terwijl op bedrijfsniveau dedicated teams nodig zijn.
Kunnen kleine bedrijven zich de implementatie van open-source LLM veroorloven?
De meeste kleine bedrijven vinden eigen API's voordeliger, tenzij ze specifieke eisen hebben zoals strikte gegevensbescherming, uitgebreide aanpassingsmogelijkheden of uitzonderlijk hoge gebruiksvolumes. Het jaarlijkse minimumbedrag van $125K+ voor zelfhosting overstijgt doorgaans de API-kosten voor kleine bedrijven totdat het gebruik een aanzienlijke schaal bereikt.
Wat is de beste aanpak voor kostenbewuste organisaties?
Begin met eigen API's om de geschiktheid van het product voor de markt te valideren en gebruikspatronen te begrijpen. Dit minimaliseert de initiële investering en de technische complexiteit. Overweeg open-source implementatie pas wanneer de schaal is bereikt en de API-kosten onbetaalbaar worden (doorgaans 1 TP4T200K+ per jaar), en zorg ervoor dat de technische expertise aanwezig is om een zelfgehoste infrastructuur effectief te ondersteunen.
Conclusie: De juiste economische keuze maken
Open-source LLM's zijn niet gratis; ze hebben een fundamenteel andere kostenstructuur die specifieke organisatorische contexten bevoordeelt.
De kosten van het 'gratis' model vertalen zich in aanzienlijke investeringen in infrastructuur, personeel en operationele kosten. Voor scenario's met laag tot gemiddeld gebruik bieden eigen API's een betere prijs-kwaliteitverhouding met een aanzienlijk lagere complexiteit. Organisaties betalen alleen voor het daadwerkelijke gebruik en besteden de implementatie, schaalbaarheid en het onderhoud uit aan leveranciers.
Open-source implementaties zijn economisch aantrekkelijk bij grote volumes, waar de API-kosten per token onbetaalbaar worden, wanneer uitgebreide aanpassingen diepgaande toegang tot modellen vereisen, of wanneer gegevensprivacy on-premise verwerking noodzakelijk maakt. Deze scenario's rechtvaardigen de aanzienlijke vaste kosten en technische complexiteit.
De beslissing vereist een eerlijke beoordeling van de werkelijke kosten – inclusief de vaak over het hoofd geziene personeelskosten – ten opzichte van realistische gebruiksverwachtingen. Organisaties met sterke ML-engineeringcapaciteiten en duidelijke plannen voor grootschalig gebruik profiteren van open-sourcebenaderingen. Organisaties met beperkte expertise, matig gebruik of strakke deadlines vinden API's doorgaans praktischer.
Het allerbelangrijkste is dat je begrijpt dat de vraag niet is "open source of proprietair", maar "welk kostenmodel past het beste bij ons gebruik, onze mogelijkheden en onze behoeften?". Beantwoord die vraag eerlijk, en de economisch optimale keuze wordt vanzelf duidelijk.
Bent u klaar om de LLM-opties voor uw specifieke gebruikssituatie te evalueren? Bereken het verwachte tokenvolume, beoordeel de technische mogelijkheden en modelleer beide kostenstructuren met realistische aannames. De cijfers zullen u beter helpen bij uw beslissing dan welke algemene aanbeveling dan ook.