Korte samenvatting: De implementatiekosten van open-source LLM liggen voor de meeste organisaties tussen de 1.125.000 en 820.000 dollar of meer per jaar, wat de API-prijzen voor typische workloads ruimschoots overstijgt. Hoewel modelgewichten gratis zijn, zorgen infrastructuur, technisch talent, operationele overhead en onderhoud voor aanzienlijke verborgen kosten, waardoor commerciële LLM-diensten kosteneffectiever zijn totdat specifieke break-even drempels worden bereikt.
Het aanbod klinkt onweerstaanbaar: download een open-source, grootschalig taalmodel, implementeer het op je infrastructuur en neem voorgoed afscheid van API-kosten.
Maar er is een probleem: dat 'gratis' model kost je tussen de 1.125.000 en meer dan 1.12 miljoen per jaar, afhankelijk van de schaal.
Open-source LLM's verschuiven de kosten van transparante API-vergoedingen naar verborgen operationele kosten. Volgens onderzoek dat is gepresenteerd in een kosten-batenanalyse, staan organisaties voor een cruciale keuze: zich abonneren op commerciële LLM-diensten van aanbieders zoals OpenAI, Anthropic en Google, of modellen implementeren op hun eigen infrastructuur. De analyse laat zien dat de meeste aannames over kostenbesparingen fundamenteel onjuist zijn.
Deze analyse onderzoekt de werkelijke economische aspecten van de implementatie van open-source LLM in 2026, onderbouwd met gegevens uit productie-implementaties en academische kosten-batenanalyses.
De mythe van het gratis model: waar betaal je eigenlijk voor?
De gewichten van open-sourcemodellen zijn gratis te downloaden. Al het andere kost geld.
Wanneer organisaties een download van $0 vergelijken met API-prijzen die per token worden berekend, lijkt de berekening voor de hand liggend. Maar de vergelijking is misleidend. Gedownloade modelgewichten vertegenwoordigen ruwweg 2-5% aan totale implementatiekosten.
De resterende 95-98% is afkomstig van:
- Hardware-infrastructuur (GPU's, servers, netwerken)
- Technisch talent (ML-engineers, MLOps-specialisten, infrastructuurteams)
- Operationele overhead (monitoring, schaling, betrouwbaarheid)
- Onderhoud en updates (beveiligingspatches, hertraining van modellen, prestatieoptimalisatie)
- Integratiewerkzaamheden (het koppelen van modellen aan bestaande systemen)
Onderzoek naar on-premise implementaties heeft aangetoond dat organisaties specifieke gebruiksdrempels moeten bereiken voordat zelfgehoste modellen qua kosten concurrerend worden met commerciële diensten. Voor de meeste gangbare workloads wordt die drempel nooit bereikt.
Infrastructuurkosten: de realiteit van GPU's
Het uitvoeren van LLM's vereist serieuze computerbronnen. Niet de middelen van een laptop, maar een GPU-infrastructuur op industriële schaal.
Hardwarevereisten per modelgrootte
Een model met 7 miljard parameters kan met hoge inferentiesnelheden draaien op een enkele NVIDIA L4 (24 GB) of zelfs op consumenten-GPU's zoals de RTX 4090/5090, en verbruikt aanzienlijk minder stroom dan een A100. Modellen met 13 miljard parameters vereisen meerdere GPU's. Modellen met 70 miljard parameters of meer vereisen complete GPU-clusters.
En dit zijn geen budgetvideokaarten. Volgens de marktprijzen kost een enkele NVIDIA A100 80GB GPU ongeveer 10.000 tot 15.000 euro. De nieuwere H100 kost ongeveer 25.000 tot 40.000 euro per stuk. De meeste organisaties hebben meerdere exemplaren nodig voor productieworkloads.
| Modelmaat | Minimale GPU-geheugen | Typische hardware | Geschatte kosten
|
|---|---|---|---|
| 7B-parameters | 16-24 GB | 1x A100 40GB | $10,000-$15,000 |
| 13B-parameters | 32-48 GB | 1x A100 80GB of 2x A100 40GB | $20,000-$30,000 |
| 70B-parameters | 140-280 GB | 4x A100 80GB of 2x H100 | $50,000-$80,000 |
| 175B+ parameters | 350 GB+ | 8x A100 80GB of GPU-cluster | $100,000+ |
Afwegingen tussen cloud en on-premise
Organisaties hebben twee mogelijkheden voor hun infrastructuur: het bouwen van eigen datacenters of het huren van GPU-instanties in de cloud.
Infrastructuur op locatie vereist een initiële kapitaalinvestering. Budgetten variëren van 1 TP4T50.000 voor minimale implementaties tot meer dan 1 TP4T500.000 voor clusters op productieschaal. Maar kapitaalkosten zijn slechts het begin. Energie, koeling, fysieke ruimte en onderhoud voegen daar jaarlijks 20 tot 401 TP3T aan toe.
Cloud GPU-instances elimineren de initiële kosten, maar brengen wel doorlopende operationele kosten met zich mee. Cloud GPU-instances van providers zoals AWS kunnen ongeveer $20-$35 per uur kosten voor configuraties met 8 GPU's, wat neerkomt op $14.000-$25.000 per maand voor continu gebruik. Google Cloud en Azure hanteren vergelijkbare prijsstructuren.
Recente innovaties, zoals kwantiseringstechnieken, maken het mogelijk dat sommige modellen op consumentenhardware draaien. Volgens de Hugging Face-documentatie over SmallThinker-modellen kunnen modellen met Q4_0-kwantisering meer dan 20 tokens per seconde verwerken op gewone consumenten-CPU's. De afweging tussen prestaties en nauwkeurigheid maakt deze aanpak echter alleen geschikt voor specifieke toepassingen.
De kosten van menselijk kapitaal: de engineeringteams die je nodig hebt
Infrastructuur is tastbaar. De kosten voor talent zijn waar budgetten echt leeglopen.
Het implementeren en onderhouden van open-source LLM's is geen hobbyproject voor één persoon. Implementaties in productieomgevingen vereisen gespecialiseerde engineeringteams met salarissen die de infrastructuurkosten ver overtreffen.
Kernvereisten voor het team
- Machine learning-ingenieurs: Bouw inferentie-pipelines, optimaliseer modelprestaties en implementeer technieken zoals kwantisatie en batchverwerking. Salarisbereik: $150.000 - $250.000 per jaar. De meeste organisaties hebben er minstens twee nodig voor voldoende dekking en expertise.
- MLOps-ingenieurs: Beheer de implementatie-infrastructuur, beheer Kubernetes-clusters, onderhoud Docker-containers, configureer GPU-quota en implementeer inferentiestacks zoals vLLM of NVIDIA Triton. Salarisbereik: $140.000-$230.000 per jaar. Cruciaal voor schaalvergroting na de proof-of-conceptfase.
- Software-integratie-engineers: Volgens discussies binnen de community gaat er ongeveer 601 TP3T aan engineeringinspanning in AI-projecten zitten in "lijmcode"—het verbinden van modellen met databases, authenticatiesystemen en gebruikersinterfaces. Salarisbereik: $130.000-$200.000 per jaar.
- DevOps-/infrastructuurengineers: Servers onderhouden, netwerken beheren, zorgen voor naleving van beveiligingsvoorschriften en rampenherstel beheren. Salarisbereik: € 120.000 - € 190.000 per jaar.
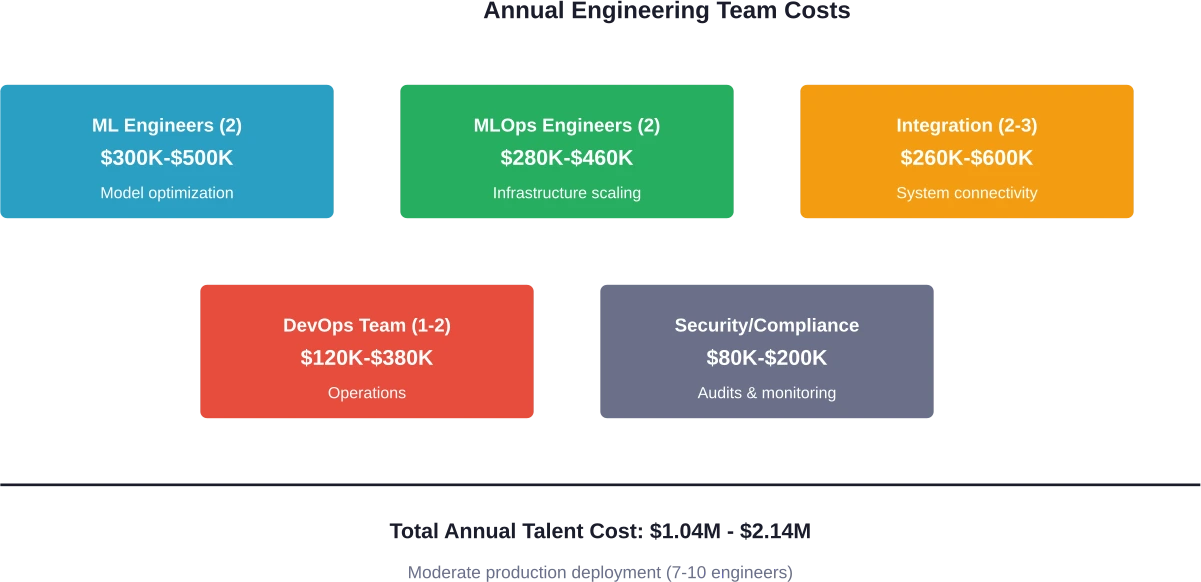
Voor minimale interne implementaties zijn minstens 3-4 engineers nodig. Klantgerichte functionaliteiten vereisen 7-10 engineers. Implementaties op bedrijfsniveau vereisen 15 of meer gespecialiseerde medewerkers.
Volgens de huidige API-prijzen van 2026 kosten GPT-4-klassemodellen (en hun opvolgers zoals GPT-5) ongeveer $0.0025-$0.01 per 1.000 tokens input. Een ML-engineer kost $200.000 per jaar. Die engineer moet 6,6 miljard tokens aan API-aanroepen besparen om alleen al zijn salaris terug te verdienen.
Operationele overheadkosten: de maandelijkse kostenpost
Infrastructuur en salarissen zijn voorspelbare kostenposten. De operationele overheadkosten vormen de grens waar budgetten de realiteit onder ogen zien.
Monitoring en observeerbaarheid
Productie-LLM's vereisen uitgebreide monitoring: latency-tracking, doorvoermetingen, foutpercentages, GPU-gebruik, geheugenverbruik en detectie van kwaliteitsvermindering. Tools zoals Prometheus, Grafana en gespecialiseerde ML-observatieplatforms voegen maandelijks 1 TP4T2.000 tot 1 TP4T10.000 toe.
Gegevensopslag en -overdracht
De gewichten van een model met 70 miljard parameters nemen meer dan 140 GB aan opslagruimte in beslag. Trainingsdata, datasets voor finetuning en inferentielogboeken voegen daar nog terabytes aan toe. Cloudopslag kost 1 TP4T0,02 tot 1 TP4T0,05 per GB per maand. Daar komen nog de kosten voor gegevensoverdracht bij: de kosten voor uitgaand dataverkeer van grote cloudproviders bedragen 1 TP4T0,08 tot 1 TP4T0,12 per GB.
Schaalvergroting en taakverdeling
Productieomgevingen vereisen automatische schaling om variabele belasting aan te kunnen. Onderzoek naar LLM-servers in meerdere fasen (MIST-simulatorstudie) toont aan dat geoptimaliseerde implementaties tot wel 2,8 keer de opbrengst per dollar aan tokens kunnen opleveren door zorgvuldige architectuurkeuzes. Het implementeren van deze optimalisaties vereist echter een geavanceerde infrastructuur.
Loadbalancers, containerorkestratie en redundantiesystemen voegen maandelijks $5.000 tot $25.000 toe voor middelgrote implementaties.
Beveiliging en naleving
Zelfgehoste modellen vereisen beveiligingsaudits, compliance-certificeringen en kwetsbaarheidsbeheer. Voor gereguleerde sectoren lopen deze kosten enorm op. HIPAA-compliance-audits kosten doorgaans tussen de 120.000 en 150.000 euro per jaar voor bestaande infrastructuur, terwijl een SOC 2 Type II-certificering tussen de 30.000 en 60.000 euro kost, inclusief auditkosten.
Implementatiescenario's: een gedetailleerde kostenanalyse
Abstracte cijfers zeggen niets. Hieronder ziet u de kosten van daadwerkelijke implementatiescenario's in 2026.
Scenario 1: Minimale interne tool
Gebruiksscenario: Interne chatbot voor vragen van medewerkers, 100-500 medewerkers, laag gebruiksvolume
Instellen:
- Model met één parameter van 7B (Llama 3 of Mistral)
- 1x A100 40GB GPU (cloudgehost)
- 2 ML-engineers (deeltijd)
- Basisbewaking en infrastructuur
Jaarlijkse kosten:
- GPU-infrastructuur: $15,000-$20,000
- Technisch talent (gedeeltelijk): $80,000-$120,000
- Monitoring en hulpmiddelen: $10,000-$15,000
- Opslag en netwerken: $5,000-$10,000
- Beveiliging en naleving: $15,000-$25,000
Totaal: $125.000-$190.000 per jaar
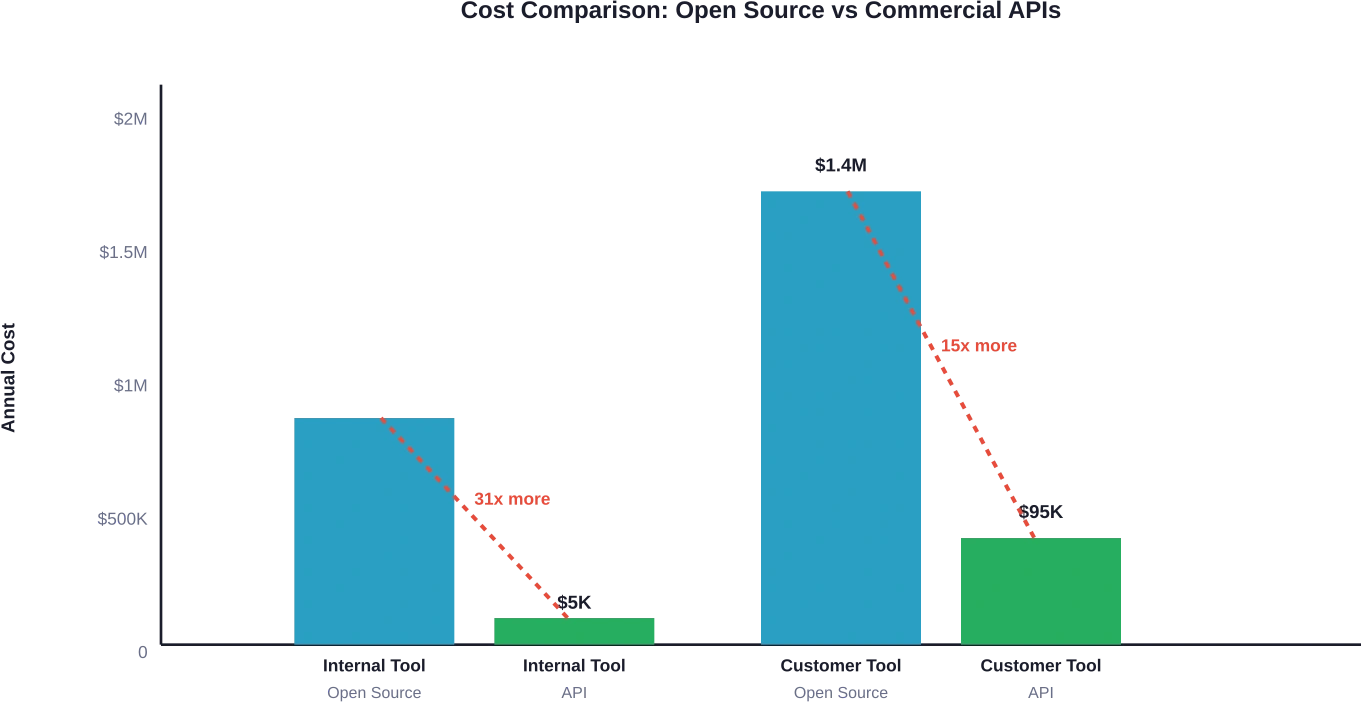
Ter vergelijking: equivalent gebruik via commerciële API's zou jaarlijks aanzienlijk minder kosten – doorgaans $3.000 tot $15.000 voor vergelijkbare tokenvolumes. Het break-evenpunt wordt nooit bereikt.
Scenario 2: Klantgerichte functie
Gebruiksscenario: Chatbot of contentgeneratie voor meer dan 10.000 maandelijks actieve gebruikers, gemiddeld gebruik.
Instellen:
- 13B-70B parametermodel met fijnafstelling
- 4x A100 80GB GPU's met automatische schaling
- 7-10 leden van het engineeringteam
- Monitoring en betrouwbaarheid van productieniveau.
- 24/7 bereikbaarheid voor ondersteuning
Jaarlijkse kosten:
- GPU-infrastructuur: $120,000-$200,000
- Technisch team: $700,000-$1,400,000
- Monitoring en observeerbaarheid: $30,000-$60,000
- Opslag, netwerken, CDN: $25,000-$50,000
- Beveiliging, naleving, audits: $50,000-$80,000
- Bereikbaarheidsdienst en incidentafhandeling: $25,000-$30,000
Totaal: $950.000-$1.820.000 per jaar
Commerciële API-equivalent: geschat op 1 TP4T40.000-1 TP4T150.000 per jaar bij vergelijkbare gebruikspatronen, afhankelijk van het gekozen model. Zelf hosten is financieel alleen rendabel bij een maandelijks gebruik van meer dan 500 miljoen tot 1 miljard tokens.
Scenario 3: Kernproduct voor de onderneming
Gebruiksscenario: LLM als primaire productengine, miljoenen gebruikers, hoge beschikbaarheidseisen
Instellen:
- Meerdere parametermodellen met meer dan 70 miljard parameters en A/B-testen
- GPU-cluster (16-32 eenheden) verspreid over meerdere regio's
- 15-25 ingenieurs
- Infrastructuur van bedrijfsniveau met redundantie
- Toegewijde teams voor beveiliging en naleving van regelgeving
Jaarlijkse kosten:
- GPU-infrastructuur: $1,500,000-$3,000,000
- Technische teams: $2,500,000-$5,000,000
- Monitoring en analyse: $200,000-$400,000
- Opslag en netwerken: $300,000-$600,000
- Beveiliging en naleving: $400,000-$800,000
- Opleiding en onderzoek en ontwikkeling: $500,000-$1,000,000
Totaal: $5.400.000-$10.800.000 per jaar
Deze schaal vertegenwoordigt de drempel waarbij zelfhosting potentieel kosteneffectief wordt ten opzichte van commerciële API's voor gebruikspatronen in de orde van 500 miljoen tot meer dan 1 miljard tokens per maand.
Wanneer open source financieel gezien wél zinvol is
Open-source implementatie is niet per definitie verkeerd. Specifieke scenario's rechtvaardigen de investering.
Break-even drempelanalyse
Onderzoek naar de economische aspecten van on-premise implementaties identificeert kritieke omslagpunten waarop zelfgehoste modellen qua kosten concurrerend worden met commerciële diensten.
De drempelwaarde is afhankelijk van het tokenvolume. Voor typische bedrijfsworkloads:
- Minder dan 100 miljoen tokens per maand: Commerciële API's behalen overtuigend de overwinning.
- 100M-500M tokens per maand: De kosten benaderen gelijkheid, maar API's blijven vaak goedkoper als de engineeringkosten worden meegerekend.
- 500 miljoen tot 1 miljard tokens per maand: Het break-evenpunt waar zelfhosting de kosten kan rechtvaardigen
- Meer dan 1 miljard tokens per maand: Zelf hosten biedt duidelijke kostenvoordelen.
Maar het pure tokenvolume is niet de enige factor.
Niet-financiële drijfveren
- Gegevensprivacy en -soevereiniteit: Gereguleerde sectoren die gevoelige gegevens verwerken (gezondheidszorg, financiën, overheid) worden geconfronteerd met nalevingsvereisten die het gebruik van externe API's verbieden. Zelfhosting wordt dan verplicht, ongeacht de kosten.
- Latentievereisten: Applicaties die responstijden van minder dan 100 ms vereisen, kunnen geen netwerkverkeer naar externe API's tolereren. Volgens een analyse van Hugging Face over edge- versus cloud-inferentie hebben netwerkafstand en -congestie een aanzienlijke invloed op de p95-latentie. Voor latency-kritische applicaties is lokale implementatie ononderhandelbaar.
- Aanpassingsmogelijkheden: Sterk aangepaste modellen met uitgebreide finetuning, domeinspecifieke training en gespecialiseerde architecturen rechtvaardigen investeringen in zelfhosting. Opvallende voorbeelden zijn modellen zoals het DeepSeek R1-model, dat volgens rapporten over verschuivingen in het computerlandschap minder dan 1 TP4T300.000 aan rekenkracht nodig had voor de nabewerking.
- Strategische onafhankelijkheid: Organisaties die AI-gedreven producten ontwikkelen, geven mogelijk prioriteit aan leveranciersonafhankelijkheid en -controle boven kostenoptimalisatie op korte termijn.
| Beslissingsfactor | Geef de voorkeur aan open source wanneer | Geef de voorkeur aan commerciële API's wanneer
|
|---|---|---|
| Tokenvolume | Meer dan 500 miljoen per maand | Minder dan 500 miljoen per maand |
| Latentievereiste | Minder dan 100 ms p95 | 200 ms+ acceptabel |
| Gegevensgevoeligheid | Gereguleerde/geclassificeerde gegevens | Niet-gevoelige werkzaamheden |
| Aanpassingsbehoeften | Uitgebreide fijnafstelling | Standaardfunctionaliteiten |
| Teamexpertise | Bestaande ML/infrastructuurteams | Beperkte technische middelen |
| Beschikbaarheid van kapitaal | Kan $500K+ vooraf investeren | Voorkeur voor operationele kosten |
Verborgen kosten die projecten de nek omdraaien
Naast de voor de hand liggende kosten zijn er diverse verborgen kosten die de implementatie van open-sourceprojecten in de weg staan.
Modelupdates en drift
Modellen verslechteren na verloop van tijd. Gegevensverdelingen veranderen. Gebruikersverwachtingen evolueren. Commerciële API's verwerken updates automatisch. Zelfgehoste implementaties vereisen handmatige tussenkomst.
Het opnieuw trainen of bijwerken van modellen vereist extra GPU-tijd, technische inspanning en testcycli. Budgetteer jaarlijks $50.000-$200.000 voor doorlopend modelonderhoud.
Opportuniteitskosten
De engineeringteams die de LLM-infrastructuur bouwen, ontwikkelen geen productfuncties. De opportuniteitskosten van zeven engineers die zes maanden besteden aan de implementatie-infrastructuur bedragen $350.000-$700.000 aan salariskosten, plus de niet-gerealiseerde waarde van functies die ze niet hebben gebouwd.
Mislukte experimenten
Niet elke implementatie slaagt. Het testen van meerdere modellen, architecturen en optimalisatiestrategieën kost veel resources. Mislukte proof-of-concepts kosten $25.000 tot $100.000 per stuk aan ontwikkeltijd en infrastructuur.
Technische schuld
Gehaaste implementaties creëren technische schuld die in de loop der tijd oploopt. Slecht ontworpen inferentiepipelines, ontoereikende monitoring en kwetsbare integraties vereisen kostbare refactoring. Het oplossen van technische schuld kost 3 tot 5 keer meer dan een correcte initiële implementatie.
Optimalisatiestrategieën die echt werken
Organisaties die ervoor kiezen om hun servers zelf te hosten, kunnen strategieën toepassen om de kosten te verlagen.
Kwantisatie en compressie
Modelquantisatie vermindert de geheugenvereisten en verhoogt de inferentiesnelheid. Onderzoek toont aan dat Q4_0-quantisatie modellen in staat stelt om meer dan 20 tokens per seconde te verwerken op hardware voor consumenten. Deze techniek verlaagt de infrastructuurkosten met 50-751 TP3T met minimale impact op de nauwkeurigheid voor veel taken.
Inferentie-optimalisatiekaders
Gespecialiseerde inferentieservers zoals vLLM, NVIDIA Triton en Text Generation Inference verbeteren de doorvoer aanzienlijk. Deze frameworks kunnen het aantal tokens per seconde met een factor 2 tot 5 verhogen in vergelijking met naïeve implementaties.
De prestatiewinst vertaalt zich direct in kostenbesparingen: minder GPU's voor een gelijkwaardige doorvoer.
Hybride benaderingen
Slimme organisaties kiezen niet voor "alles open source" of "alles API's". Hybride strategieën maken gebruik van commerciële API's voor variabele workloads en piekbelastingen, terwijl een zelfgehoste infrastructuur wordt behouden voor de basisbelasting.
Deze aanpak optimaliseert de kosten: API's verwerken pieken in het verkeer zonder de infrastructuur te overdimensioneren, terwijl zelfgehoste modellen voorspelbare workloads kosteneffectief verwerken.
Kleinere gespecialiseerde modellen
Grotere modellen zijn niet altijd beter. De SmallThinker-familie laat zien dat kleinere, speciaal ontwikkelde modellen op specifieke taken betere prestaties kunnen leveren dan grotere, algemene LLM's. Een goed geoptimaliseerd 7B-model kost 90% minder om uit te voeren dan een 70B-model, terwijl het potentieel betere taakspecifieke prestaties levert.

Het TCO-berekeningskader
Organisaties hebben een systematische aanpak nodig om de totale eigendomskosten te berekenen voordat ze implementatiebeslissingen nemen.
- Stap 1: Schat het tokenvolume in. Bereken het verwachte maandelijkse tokenverbruik op basis van het aantal gebruikers, gebruikspatronen en functievereisten. Neem zowel inkomende als uitgaande tokens mee.
- Stap 2: Bereken de basislijn voor commerciële API's. Vermenigvuldig het tokenvolume met de prijs van de commerciële API. Houd rekening met verschillende modelniveaus als u meerdere modelgroottes gebruikt.
- Stap 3: Bepaal de benodigde infrastructuurgrootte. Stel het aantal GPU's en hun specificaties vast op basis van de modelgrootte, latentievereisten en redundantiebehoeften. Denk hierbij aan netwerken, opslag en rekenkracht.
- Stap 4: Schat de benodigde technische resources in. Tel het aantal FTE's dat nodig is voor ML-engineering, MLOps, integratie, infrastructuur en beveiliging. Neem zowel de initiële implementatie als het doorlopende onderhoud mee.
- Stap 5: Voeg operationele overheadkosten toe. Denk hierbij aan kosten voor monitoring, beveiliging, compliance, gegevensopslag, bandbreedte en incidentafhandeling.
- Stap 6: Houd rekening met verborgen kosten. Neem opportuniteitskosten, mislukte experimenten, technische schuld en onderhoudscycli van het model mee in de berekening.
- Stap 7: Bereken het break-evenpunt. Bepaal het tokenvolume waarbij de totale kosten van zelfhosting gelijk zijn aan de kosten van een commerciële API. De meeste organisaties vinden deze drempel bij 500 miljoen tot 1 miljard tokens per maand.

Verlaag de implementatiekosten van open source LLM voordat ze opschalen.
Open-source LLM's lijken in eerste instantie goedkoop, maar de implementatiekosten lopen vaak snel op zodra infrastructuur, monitoring, schaalbaarheid en integratie erbij komen kijken. AI Superieur Hij/zij werkt aan de technische kant van LLM-systemen: het ontwerpen van modelarchitecturen, het opzetten van infrastructuur en het integreren van modellen in bestaande omgevingen, zodat ze efficiënt in productie draaien.
Als u in 2026 open source LLM's gaat implementeren, is het raadzaam om de architectuur en de implementatiepipeline vroegtijdig te evalueren. Neem contact op. AI Superieur om uw implementatieconfiguratie te evalueren en te bepalen waar de infrastructuur- en inferentiekosten kunnen worden verlaagd.
De realiteit van 2026
De implementatiekosten van open-source LLM-modellen dalen, maar niet zo dramatisch als de mogelijkheden van de modellen verbeteren.
De prijzen van GPU's blijven hardnekkig hoog vanwege de aanhoudende vraag. De salarissen voor AI-specialisten blijven stijgen; ML-engineers met een LLM-diploma zijn zeer gewild en profiteren van een concurrerende salarisgroei.
Ondertussen dalen de prijzen van commerciële API's. Volgens een analyse van Hugging Face over trends in de computerwereld zijn de prijzen van commerciële API's aanzienlijk gedaald ten opzichte van de tarieven van 2024. Claude en Gemini laten vergelijkbare trends zien. De economische voordelen van API's nemen voor de meeste toepassingen steeds meer toe.
Kijk, open source zal specifieke niches domineren: gereguleerde sectoren, toepassingen met lage latency, organisaties die maandelijks miljarden tokens verwerken en bedrijven die onderscheidende, op AI gebaseerde producten ontwikkelen. Voor alle anderen? API's zijn financieel gezien een betere keuze.
Het 'gratis' open-source model kost minimaal 125.000 TP4T en waarschijnlijk meer dan 500.000 TP4T voor iets dat op productieschaal lijkt. Dat is geen kritiek op open source, het is gewoon wiskunde.
Veelgestelde vragen
Wat is het minimale realistische budget voor de implementatie van een open-source LLM?
Voor minimale implementaties van interne tools is jaarlijks $125.000-$190.000 nodig, inclusief basis GPU-infrastructuur, gedeeltelijke engineeringtoewijzing, monitoring en operationele overhead. Alles onder deze drempel duidt op een ondergefinancierd project dat waarschijnlijk zal mislukken.
Hoeveel tokens per maand zijn nodig om zelfhosting rendabel te maken?
Onderzoek wijst uit dat 500 miljoen tot 1 miljard tokens per maand het omslagpunt vormen, waarbij de kosten voor zelfhosting ongeveer gelijk zijn aan die van commerciële API's. Bij minder dan 500 miljoen tokens per maand zijn API's vrijwel altijd goedkoper, mits de engineering- en operationele kosten correct worden meegerekend.
Kunnen kleinere modellen de implementatiekosten aanzienlijk verlagen?
Ja. Een goed geoptimaliseerd model met 7 miljard parameters kost 85-901 TP3T minder aan operationele kosten dan een model met 70 miljard parameters. In combinatie met taakspecifieke finetuning evenaren of overtreffen kleinere modellen vaak de prestaties van grotere modellen voor specifieke toepassingen, waardoor de infrastructuurvereisten drastisch worden verlaagd.
Wat zijn de grootste verborgen kosten bij de implementatie van open-source LLM?
Technisch talent vertegenwoordigt doorgaans een aanzienlijk deel van de totale implementatiekosten – de grootste verborgen kostenpost bij de meeste implementaties binnen organisaties. ML-engineers, MLOps-specialisten en integratieontwikkelaars verdienen jaarsalarissen van 140.000 tot 250.000 euro. Een gemiddelde implementatie vereist 7 tot 10 specialisten, wat alleen al aan jaarlijkse arbeidskosten 1 tot 2 miljoen euro oplevert.
Leveren kwantiseringstechnieken werkelijk een kostenbesparing op zonder dat de kwaliteit eronder lijdt?
Kwantiseringstechnieken zoals Q4_0 kunnen de infrastructuurkosten met 50-751 TP3T verlagen met minimale afname van de nauwkeurigheid voor veel taken. Onderzoek toont aan dat gekwantiseerde modellen meer dan 20 tokens per seconde halen op consumentenhardware. De impact op de nauwkeurigheid varieert echter per taak; grondige tests zijn essentieel vóór implementatie in productie.
Moeten startups gebruikmaken van open-source LLM's of commerciële API's?
De meeste startups zouden moeten beginnen met commerciële API's. De flexibiliteit, voorspelbare kosten en het ontbreken van operationele overheadkosten maken snellere iteratie en productontwikkeling mogelijk. Zelf hosten is alleen zinvol bij het bereiken van een enorme schaal, het verwerken van gereguleerde data of het ontwikkelen van zeer onderscheidende AI-functionaliteiten die essentieel zijn voor een concurrentievoordeel.
Hoeveel kost het om een open-source model te finetunen?
De kosten voor finetuning variëren sterk, afhankelijk van de modelgrootte en de dataset. Minimale finetuning van een model van 7 miljard bytes kost tussen de 15.000 en 15.000 dollar, inclusief GPU-tijd en technische inspanning. Uitgebreide finetuning van modellen van 70 miljard bytes met grote datasets kan oplopen tot meer dan 100.000 tot 300.000 dollar. Opvallende voorbeelden zijn dat indrukwekkende resultaten zijn behaald met een lagere investering; kleinere modellen hebben vergelijkbare prestaties laten zien tegen een fractie van de kosten.
Conclusie: Reken alles goed uit voordat je een beslissing neemt.
De implementatie van open-source LLM is niet gratis. Het is een aanzienlijke investering in engineering en infrastructuur die financieel alleen zinvol is op specifieke schaal en voor bepaalde toepassingen.
Commerciële API's zijn de economisch meest verstandige keuze voor de meeste applicaties die minder dan 500 miljoen tokens per maand verwerken. Ze zijn absoluut goedkoper voor interne tools, applicaties voor medewerkers en klantgerichte functionaliteiten van gemiddelde omvang.
Zelfhosting is de investering waard wanneer er enorme hoeveelheden tokens verwerkt moeten worden (meer dan 1 miljard per maand), er gereguleerde of gevoelige gegevens verwerkt moeten worden die on-premise implementatie vereisen, er aan extreme latency-eisen voldaan moet worden of er zeer specifieke modellen gebouwd moeten worden die essentieel zijn voor productdifferentiatie.
Bereken uw totale eigendomskosten eerlijk. Neem infrastructuur, technisch talent, operationele overhead, verborgen kosten en opportuniteitskosten mee. Vergelijk dat bedrag met de commerciële API-prijzen voor vergelijkbaar gebruik. De cijfers liegen zelden.
En als de cijfers voor jouw specifieke situatie nog steeds pleiten voor zelfhosting? Budgetteer dan twee keer je oorspronkelijke schatting. Implementaties in een productieomgeving kosten altijd meer dan gepland.
Bent u klaar om de implementatiekosten van uw LLM-systeem nauwkeurig te berekenen? Begin met de verwachte tokenvolumes en werk vervolgens terug naar de benodigde infrastructuur en personeel. De break-evenanalyse laat zien of open source of commerciële API's financieel gezien zinvol zijn voor de specifieke behoeften van uw organisatie.