Quick Summary: AI data pipelines combine machine learning with data engineering to automate schema mapping, processing, and quality checks—turning raw, unstructured information into AI-ready datasets with minimal manual intervention. Unlike traditional ETL, they iterate continuously through ingestion, transformation, feature engineering, training, and monitoring stages. Modern declarative frameworks demonstrate 50% development efficiency gains, 500× scalability improvements, and up to 80% compute cost reductions.
Every ambitious AI project hits the same wall: mountains of messy data sitting in disconnected systems, nowhere near the clean, structured format models demand.
Traditional ETL tools choke on unstructured logs, images, and free-text fields. They require armies of engineers to map schemas manually every time a source changes. And when GPU clusters sit idle at 10–15% utilization waiting for the next batch, compute budgets evaporate.
That’s the problem AI data pipelines solve. They don’t just move data—they learn from it, adapt to schema drift automatically, and keep training infrastructure saturated.
What Makes AI Data Pipelines Different
Traditional data pipelines follow a linear path: extract raw data, transform it through fixed rules, load it into a warehouse. The workflow is predictable. Run it once, and it’s done.
AI data pipelines operate in continuous loops. Ingest → prepare → engineer features → train models → predict → monitor → retrain. Each stage feeds insights back upstream.
Here’s the thing though—they also handle what traditional ETL can’t: unstructured data at scale. Documents, images, audio, free-text customer feedback—formats that represent the majority of enterprise information but remain untouched by conventional tools.
| Dimension | Traditional Data Pipeline | AI Data Pipeline |
|---|---|---|
| Primary purpose | Reporting and business intelligence | Model training, inference, and prediction |
| Output | Dashboards, reports, aggregated metrics | Trained models, predictions, feature stores |
| Workflow | Linear: Extract → Transform → Load | Iterative: Ingest → Prep → Train → Predict → Monitor → Retrain |
| Schema handling | Manual mapping, breaks on schema drift | ML-driven auto-mapping, adapts to changes |
| Data types | Primarily structured (databases, CSV) | Structured + unstructured (text, images, logs) |
| Governance | Access control at warehouse level | End-to-end lineage, model versioning, audit trails |
Real talk: the automation layer is what separates the two. Machine learning models embedded in the pipeline itself detect schema changes, suggest transformations, and flag anomalies before they poison downstream models.
The Five Core Stages of Modern AI Data Pipelines
Ingestion: Connecting Everything
Data originates everywhere—APIs, databases, event streams, S3 buckets, on-prem warehouses. Ingestion pulls it all into a unified environment.
Modern connectors handle batch and streaming simultaneously. A declarative framework might specify sources once, then automatically parallelize ingestion across hundreds of partitions.
Apache Spark is widely adopted for distributed ingestion in enterprise data pipelines. But proprietary platforms increasingly abstract Spark’s complexity behind SQL-like declarative syntax.
Transformation: Cleaning and Structuring
Raw data arrives with duplicates, null values, inconsistent formatting, and missing timestamps. Transformation logic deduplicates records, imputes missing values, normalizes timestamps, and converts data types.
Traditional ETL requires engineers to write and maintain transformation scripts manually. AI-powered platforms use anomaly detection models to auto-flag suspect records and suggest remediation rules.
Research from academic data management studies shows AI-driven validation reduces duplicate records by 75% and improves data accuracy by 18%.
Feature Engineering: Building Model Inputs
Models don’t consume raw columns—they need engineered features. Categorical encoding, scaling, windowing, lagging, aggregation across time periods—all preprocessing that turns raw attributes into predictive signals.
Automated feature engineering tools test thousands of candidate transformations, rank them by predictive power, and version the final feature set alongside model checkpoints.
This stage is iterative. Models fail, engineers add new features, pipelines retrain. Tight feedback loops compress weeks of experimentation into days.
Training and Validation
Prepared data splits into training and validation sets—typically 80/20. The training subset teaches the model patterns; the validation subset tests whether those patterns generalize.
Hyperparameter tuning happens here: learning rates, batch sizes, regularization coefficients. Automated search tools like MLFlow or proprietary AutoML platforms test hundreds of configurations in parallel.
Benchmarks from production-scale implementations show end-to-end training times of approximately 60 hours for full models. Fine-tuning pre-trained foundation models cuts that to 8 hours 47 minutes, with average runtime of 1 minute 45 seconds per run.
Deployment and Monitoring
Trained models move into inference environments—REST APIs, batch scoring jobs, embedded edge devices. Monitoring tracks prediction latency, throughput, error rates, and data drift.
When input distributions shift—seasonal changes, new product launches, schema updates—performance degrades. Automated alerts trigger retraining workflows before users notice accuracy drops.
Governance layers enforce access control, audit trails, and compliance policies from ingestion through model output. Centralized governance prevents teams from reinventing security logic in every pipeline.
How AI Transforms Data Pipeline Performance
Eliminating GPU Starvation
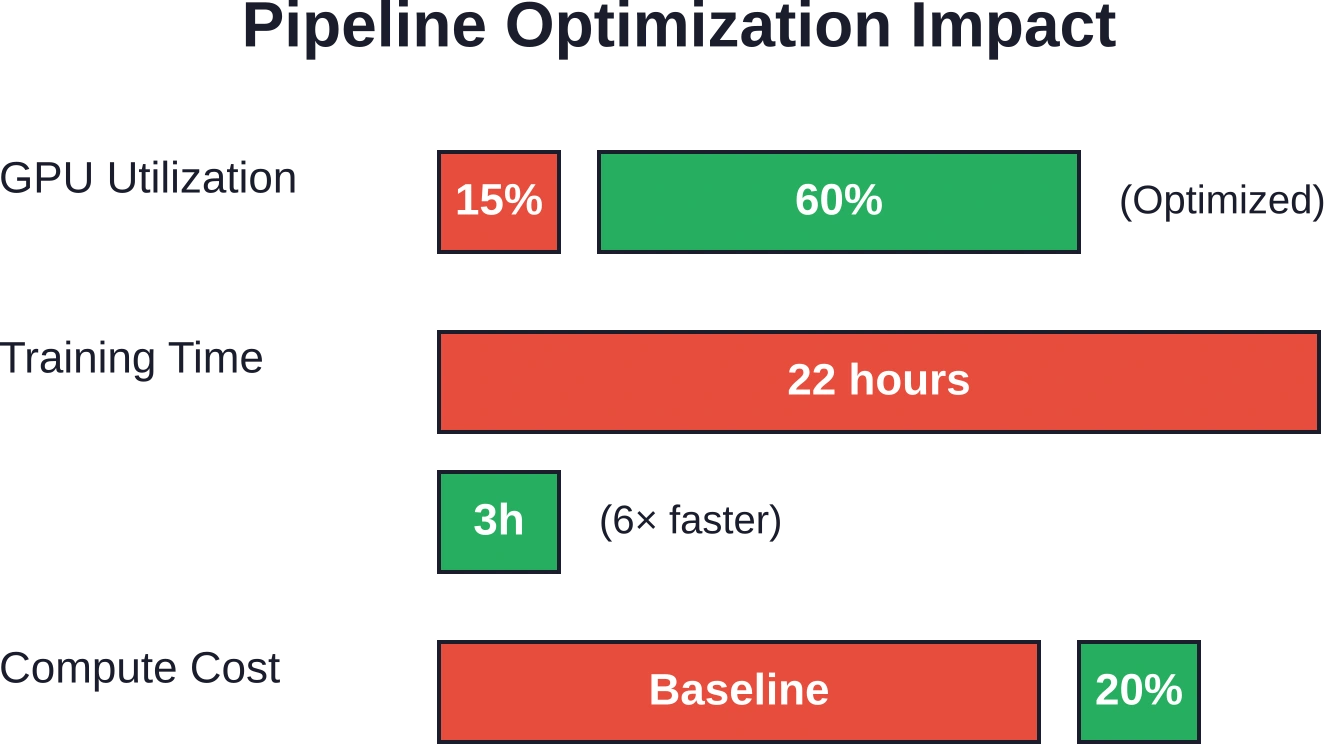
High-performance GPUs idle when data loading can’t keep pace with compute throughput. In baseline industrial deep learning pipelines, researchers observed GPUs sitting at 10–15% utilization while waiting for batches.
Optimized data pipelines using distributed loaders like Petastorm achieved 60% GPU utilization and delivered an overall 6× speedup. End-to-end training time dropped from 22 hours to 3 hours. Compute cost reductions hit 80% by eliminating wasted cycles.
The bottleneck wasn’t the model—it was I/O. Fix the pipeline, and hardware investment pays off.
Declarative Frameworks for Scale
Imperative pipeline code—Python scripts chaining Spark jobs—becomes unmaintainable at scale. Debugging requires reading thousands of lines. Collaboration stalls when logic is scattered across repositories.
Declarative frameworks let engineers specify *what* transformations to apply, not *how* to execute them. The platform optimizes execution plans automatically.
Enterprise case studies using declarative pipelines report 50% better development efficiency, collaboration efforts compressed from weeks to days, 500× scalability improvements, and 10× throughput gains compared to imperative implementations.
Academic evaluations confirmed 5.7× throughput gains over non-framework code and 99% CPU utilization during distributed processing.
Auto-Healing and Schema Evolution
Production systems face constant change. Upstream APIs add fields, rename columns, or alter data types without warning. Traditional pipelines break and wait for manual fixes.
AI-guided schema evolution detects mismatches automatically, infers correct mappings using historical patterns, and applies transformations on the fly. Explainable AI agents surface recommendations—”Column `user_id` renamed to `userId`; auto-mapping applied”—so engineers audit changes without digging through logs.
Real-time data quality enhancement layers validate records during ingestion, flag outliers, and route suspect data to quarantine tables for review. Models continue training on clean subsets while engineers investigate anomalies asynchronously.

Prepare AI Data Pipelines for Real Model Development
AI projects depend on more than a model. The data has to be collected, structured, prepared, and connected to the way the system will actually be used. AI Superior works with AI and data strategy, AI software development, machine learning, business intelligence, and AI integration. For AI data pipelines, this can include preparing data for ML models, building data-driven applications, supporting analytics workflows, and making sure AI systems can work with existing business data sources.
AI Superior’s work can cover:
- Planning data requirements for AI projects
- Preparing business data for machine learning models
- Building AI software connected to existing data sources
- Supporting analytics and BI workflows
- Integrating AI systems into current business processes
👉Get in touch with AI Superior to discuss how your data can be prepared for AI models, analytics tools, or custom AI software.
Common Challenges and How to Overcome Them
Challenge: Data Quality Degradation
Model performance drops without code changes. Downstream dashboards show declining accuracy. Root cause: upstream data sources introduced nulls, duplicates, or formatting inconsistencies weeks ago.
Solution: Continuous quality checks at ingestion. Statistical profiling models baseline distributions—mean, variance, cardinality—and alert when new batches deviate beyond thresholds. Automated data accuracy improvements of 18% and duplicate reductions of 75% are achievable with AI-driven validation.
Challenge: Fragmented Infrastructure
Legacy systems store data in silos—on-prem databases, cloud warehouses, data lakes, SaaS applications. Moving data between environments requires custom scripts, VPNs, and manual coordination.
Solution: Unified ingestion platforms with pre-built connectors for 100+ sources. Declarative configuration consolidates authentication, rate limiting, and incremental sync logic. Teams define sources once; the platform handles the plumbing.
Challenge: Scaling Without Maintainability Collapse
Imperative pipeline code grows into thousands of lines. Each new feature adds conditional branches. Debugging takes days. New team members can’t onboard.
Solution: Adopt declarative frameworks. Specify transformations as configuration files or SQL-like queries. The execution engine optimizes parallelism, retries, and resource allocation automatically. Enterprise teams report 40% codebase reductions and weeks-to-days troubleshooting compression.
Architecture Best Practices for Production Systems
Separate Storage and Compute
Tightly coupled architectures force scaling storage and compute together. Over-provisioning wastes budget; under-provisioning throttles jobs.
Cloud-native designs decouple the two. Store data in object storage (S3, GCS, Azure Blob). Spin up ephemeral compute clusters (Spark, Dask, Ray) only when jobs run. Shut them down afterward.
Version Everything
Code, data, models, and configurations all change over time. Without versioning, reproducing a result from three months ago becomes archaeology.
Modern MLOps platforms integrate Git for code, DVC for datasets, and model registries for trained artifacts. Every training run links to exact input data snapshots and hyperparameter configs. Rollbacks are one command.
Implement End-to-End Lineage
Regulators and auditors ask: “How did the model arrive at this prediction?” Engineers ask: “Which upstream table caused this bug?”
Lineage tracking logs every transformation—source table → intermediate feature → model input → prediction. Metadata stores capture timestamps, schema versions, and user actions. Query interfaces let teams trace backward from any output to its origins.
Build Observability From Day One
Pipelines fail silently. Jobs complete successfully but produce garbage. Alerts fire too late.
Instrument every stage: ingestion row counts, transformation error rates, feature distribution shifts, model prediction latency. Dashboards surface anomalies in real time. On-call teams catch issues before users report them.
Use Cases Across Industries
Real-Time Fraud Detection (Financial Services)
Transactions stream in milliseconds. Models score each transaction for fraud risk, blocking suspicious activity before settlement.
Pipelines ingest event streams (Kafka, Kinesis), join with customer profile features, and invoke low-latency inference endpoints. Monitoring tracks false positive rates and adapts thresholds dynamically.
Predictive Maintenance (Manufacturing)
Sensors on factory equipment emit telemetry—temperature, vibration, pressure. Models predict failures days before they occur, scheduling maintenance during planned downtime.
Pipelines aggregate time-series data into rolling windows (hourly, daily), engineer lag features, and retrain models weekly as new failure patterns emerge.
Personalized Recommendations (E-commerce)
User clickstreams and purchase histories feed collaborative filtering models. Recommendations update in near-real-time as preferences shift.
Batch pipelines rebuild item embeddings nightly. Streaming pipelines update user profiles on every interaction. Hybrid architectures balance freshness and compute cost.
Clinical Decision Support (Healthcare)
Electronic health records contain structured lab results, unstructured physician notes, medical images, and prescription histories. Models synthesize signals across modalities to flag at-risk patients.
Pipelines handle multi-modal ingestion, apply NLP to extract entities from notes, normalize lab units, and enforce HIPAA-compliant access control throughout.
Key Platform Features to Evaluate
When assessing pipeline platforms, prioritize these capabilities:
- Pre-built connectors: Databases, SaaS apps, cloud storage, streaming sources
- Schema inference: Automatic detection and mapping of data types
- Transformation libraries: SQL, Python, visual DAG builders
- Orchestration: Scheduling, dependencies, retries, backfills
- Monitoring and alerts: Data quality metrics, pipeline health dashboards
- Governance: Access control, audit logs, lineage tracking
- Scalability: Distributed execution engines (Spark, Dask, Ray)
- Integration: Model registries, feature stores, experiment tracking
Proprietary platforms abstract complexity but introduce vendor lock-in. Open-source tools (Airflow, Prefect, Dagster) offer flexibility but require more operational overhead.

Adoption Strategy: Start Small, Scale Fast
Don’t attempt an enterprise-wide pipeline overhaul on day one. Pilot with a single high-impact use case—fraud detection, churn prediction, demand forecasting—where stakeholders already feel pain.
Build the end-to-end flow: ingestion from one critical source, minimal transformations, one model, one deployment target. Prove value quickly. Then expand.
Document lessons learned. Standardize patterns that work. Socialize wins across teams. As adoption grows, centralize shared components—authentication modules, monitoring dashboards, governance policies—into reusable templates.
Invest in training. Pipeline engineers need both data engineering skills (SQL, distributed systems) and ML fundamentals (bias, overfitting, evaluation metrics). Cross-functional pairing accelerates knowledge transfer.
The Road Ahead: AI Pipelines in 2026 and Beyond
Declarative frameworks are becoming table stakes. Teams that still write imperative Spark scripts will struggle to compete on velocity.
Automated feature engineering tools will commoditize what today requires deep domain expertise. Models will propose candidate features; engineers will curate and approve.
Governance and explainability will shift from afterthoughts to first-class requirements. Regulatory pressure—EU AI Act, state-level privacy laws—forces organizations to prove models are fair, transparent, and auditable. Pipelines that bake governance in from ingestion onward will adapt faster than those retrofitting compliance.
Edge deployment will accelerate. As models shrink (quantization, distillation) and edge hardware improves, inference moves closer to data sources. Pipelines will need to orchestrate training in the cloud and deployment to thousands of distributed endpoints.
But the core principle remains: AI is only as good as the data feeding it. Pipelines that automate ingestion, transformation, and quality checks free teams to focus on what machines can’t do—asking better questions.
Frequently Asked Questions
What is an AI data pipeline?
An AI data pipeline is an automated workflow that ingests raw data from multiple sources, transforms it into clean structured formats, engineers features for machine learning models, trains and validates those models, deploys them for inference, and continuously monitors performance. Unlike traditional ETL, AI pipelines iterate through feedback loops—retraining models as data drifts and adapting schemas automatically using embedded machine learning.
How do AI data pipelines differ from traditional ETL?
Traditional ETL follows a linear extract-transform-load sequence for reporting and business intelligence. AI data pipelines operate in continuous loops, handling both structured and unstructured data (text, images, logs), using ML to auto-map schemas, and feeding monitoring insights back upstream to trigger retraining. They prioritize model training and inference outputs over static dashboards.
What performance improvements can AI pipelines deliver?
Production benchmarks show AI-optimized pipelines achieve 60% GPU utilization (up from 10–15% baseline), deliver 6× overall speedups, reduce training time from 22 hours to 3 hours, and cut compute costs by 80%. Declarative frameworks demonstrate 50% development efficiency gains, 500× scalability improvements, and 10× throughput increases compared to imperative implementations.
Which tools are commonly used for AI data pipelines?
Popular open-source tools include Apache Spark (distributed processing), Apache Airflow and Prefect (orchestration), MLFlow (experiment tracking), and DVC (data versioning). Proprietary platforms like Databricks, Snowflake, and specialized AI ETL services offer managed environments with built-in connectors, governance, and monitoring. Tool choice depends on team expertise, scale, and tolerance for operational overhead.
What are the biggest challenges in building AI data pipelines?
Common obstacles include data quality degradation (upstream changes introducing nulls or duplicates), fragmented infrastructure (data siloed across incompatible systems), schema drift (API changes breaking pipelines), and maintainability collapse as imperative code grows. Solutions involve continuous quality checks, unified ingestion platforms, ML-driven schema evolution, and adopting declarative frameworks that separate logic from execution.
How important is governance in AI data pipelines?
Governance is critical for regulatory compliance, audit trails, and trust. End-to-end lineage tracking logs every transformation from source to prediction, enabling teams to trace bugs and regulators to verify fairness. Access control, role-based permissions, and automated audit logs prevent unauthorized data exposure. Organizations that build governance into pipelines from day one adapt faster to evolving privacy laws and AI regulations.
Can AI pipelines handle unstructured data?
Yes—handling unstructured data (documents, images, audio, free-text) is one of their core advantages over traditional ETL. AI pipelines use NLP models to extract entities from text, computer vision models to classify images, and embeddings to convert unstructured inputs into numerical features models can consume. This capability unlocks the majority of enterprise data that conventional tools ignore.
Conclusion: Build Pipelines That Learn
AI models grab headlines. But pipelines determine whether those models ever make it to production.
The organizations winning in 2026 aren’t necessarily those with the largest data science teams. They’re the ones that automated the plumbing—ingestion, transformation, monitoring—so engineers spend time solving business problems instead of debugging ETL scripts.
Start with one high-impact use case. Prove the value of automated schema mapping, real-time quality checks, and continuous retraining. Then scale the patterns across teams.
The competitive advantage isn’t the model architecture—it’s the pipeline infrastructure that keeps models fed, fresh, and reliable. Build that, and AI stops being a science project and starts being a business driver.