Kurzzusammenfassung: KI-Datenpipelines kombinieren maschinelles Lernen mit Data Engineering, um Schema-Mapping, Verarbeitung und Qualitätsprüfungen zu automatisieren und so unstrukturierte Rohdaten mit minimalem manuellem Eingriff in KI-fähige Datensätze umzuwandeln. Im Gegensatz zu herkömmlichen ETL-Prozessen durchlaufen sie kontinuierlich die Phasen Datenerfassung, Transformation, Feature Engineering, Training und Monitoring. Moderne deklarative Frameworks erzielen eine 501-fache Steigerung der Entwicklungseffizienz, eine 500-fache Verbesserung der Skalierbarkeit und eine Reduzierung der Rechenkosten um bis zu 801-fache.
Jedes ambitionierte KI-Projekt stößt an dieselbe Wand: Berge von unstrukturierten Daten, die in unzusammenhängenden Systemen vorliegen und weit entfernt sind von dem sauberen, strukturierten Format, das die Modelle erfordern.
Herkömmliche ETL-Tools stoßen bei unstrukturierten Protokollen, Bildern und Freitextfeldern an ihre Grenzen. Sie erfordern Heerscharen von Ingenieuren, die Schemas bei jeder Änderung einer Datenquelle manuell zuordnen müssen. Und wenn GPU-Cluster mit einer Auslastung von 10–151 TP3T ungenutzt auf den nächsten Batch warten, schwinden die Rechenressourcen.
Genau dieses Problem lösen KI-Datenpipelines. Sie bewegen nicht nur Daten, sondern lernen daraus, passen sich automatisch Schemaänderungen an und sorgen für eine optimale Auslastung der Trainingsinfrastruktur.
Was unterscheidet KI-Datenpipelines?
Herkömmliche Datenpipelines folgen einem linearen Ablauf: Rohdaten werden extrahiert, anhand fester Regeln transformiert und in ein Data Warehouse geladen. Der Workflow ist vorhersehbar. Einmal ausgeführt, ist er abgeschlossen.
KI-Datenpipelines arbeiten in kontinuierlichen Schleifen. Datenaufnahme → Aufbereitung → Merkmalsentwicklung → Modelltraining → Vorhersage → Überwachung → erneutes Training. Jede Phase liefert Erkenntnisse zurück an die vorgelagerten Prozesse.
Aber das Besondere ist: Sie bewältigen auch das, was herkömmliche ETL-Verfahren nicht können: unstrukturierte Daten in großem Umfang. Dokumente, Bilder, Audiodateien, Freitext-Kundenfeedback – Formate, die den Großteil der Unternehmensinformationen ausmachen, aber von herkömmlichen Tools unberücksichtigt bleiben.
| Dimension | Traditionelle Datenpipeline | KI-Datenpipeline |
|---|---|---|
| Hauptzweck | Reporting und Business Intelligence | Modelltraining, Inferenz und Vorhersage |
| Ausgabe | Dashboards, Berichte, aggregierte Kennzahlen | Trainierte Modelle, Vorhersagen, Feature-Stores |
| Workflow | Linear: Extrahieren → Transformieren → Laden | Iterativ: Datenaufnahme → Vorbereitung → Training → Vorhersage → Überwachung → Nachtraining |
| Schemabehandlung | Manuelle Zuordnung, Brüche bei Schemaabweichungen | ML-gesteuerte automatische Kartierung, passt sich Änderungen an |
| Datentypen | Vorwiegend strukturiert (Datenbanken, CSV) | Strukturierte + unstrukturierte Daten (Text, Bilder, Protokolle) |
| Governance | Zugangskontrolle auf Lagerebene | End-to-End-Herkunftsnachverfolgung, Modellversionierung, Prüfprotokolle |
Mal ehrlich: Die Automatisierungsschicht ist das, was die beiden trennt. In die Pipeline selbst eingebettete Modelle des maschinellen Lernens erkennen Schemaänderungen, schlagen Transformationen vor und kennzeichnen Anomalien, bevor diese nachgelagerte Modelle beeinträchtigen.
Die fünf Kernphasen moderner KI-Datenpipelines
Aufnahme: Alles miteinander verbinden
Daten stammen aus den unterschiedlichsten Quellen – APIs, Datenbanken, Ereignisströmen, S3-Buckets, On-Premise-Data-Warehouses. Die Datenerfassung führt sie alle in einer einheitlichen Umgebung zusammen.
Moderne Konnektoren verarbeiten Batch- und Streaming-Daten gleichzeitig. Ein deklaratives Framework könnte die Datenquellen einmalig festlegen und anschließend die Datenerfassung automatisch über Hunderte von Partitionen parallelisieren.
Apache Spark ist für die verteilte Datenerfassung in Unternehmensdatenpipelines weit verbreitet. Proprietäre Plattformen abstrahieren jedoch zunehmend die Komplexität von Spark hinter einer SQL-ähnlichen deklarativen Syntax.
Transformation: Reinigung und Strukturierung
Die Rohdaten enthalten Duplikate, Nullwerte, inkonsistente Formatierungen und fehlende Zeitstempel. Die Transformationslogik entfernt Duplikate, ergänzt fehlende Werte, normalisiert Zeitstempel und konvertiert Datentypen.
Herkömmliche ETL-Prozesse erfordern von Ingenieuren das manuelle Schreiben und Pflegen von Transformationsskripten. KI-gestützte Plattformen nutzen Anomalieerkennungsmodelle, um verdächtige Datensätze automatisch zu kennzeichnen und Korrekturmaßnahmen vorzuschlagen.
Untersuchungen aus dem akademischen Datenmanagement zeigen, dass KI-gestützte Validierung die Anzahl doppelter Datensätze um 751 Tsd.³ reduziert und die Datengenauigkeit um 181 Tsd.³ verbessert.
Feature Engineering: Erstellung von Modelleingaben
Modelle verarbeiten keine Rohdaten – sie benötigen aufbereitete Merkmale. Kategorische Kodierung, Skalierung, Fensterung, Verzögerung, Aggregation über Zeiträume hinweg – all dies sind Vorverarbeitungsschritte, die Rohattribute in prädiktive Signale umwandeln.
Automatisierte Feature-Engineering-Tools testen Tausende von Kandidatentransformationen, ordnen sie nach ihrer Vorhersagekraft und versionieren den endgültigen Feature-Satz zusammen mit Modell-Checkpoints.
Diese Phase ist iterativ. Modelle versagen, Ingenieure fügen neue Funktionen hinzu, Pipelines werden neu trainiert. Enge Feedbackschleifen komprimieren wochenlange Experimente auf Tage.
Schulung und Validierung
Die aufbereiteten Daten werden in Trainings- und Validierungsdatensätze aufgeteilt – typischerweise im Verhältnis 80/20. Der Trainingsdatensatz lehrt das Modell Muster; der Validierungsdatensatz testet, ob diese Muster verallgemeinert werden können.
Hier findet die Hyperparameter-Optimierung statt: Lernraten, Batchgrößen, Regularisierungskoeffizienten. Automatisierte Suchwerkzeuge wie MLFlow oder proprietäre AutoML-Plattformen testen Hunderte von Konfigurationen parallel.
Benchmarks aus produktionsreifen Implementierungen zeigen, dass die Trainingszeit für vollständige Modelle von etwa 60 Stunden abhängt. Durch Feinabstimmung vortrainierter Basismodelle verkürzt sich diese Zeit auf 8 Stunden und 47 Minuten, bei einer durchschnittlichen Laufzeit von 1 Minute und 45 Sekunden pro Durchlauf.
Bereitstellung und Überwachung
Trainierte Modelle werden in Inferenzumgebungen eingesetzt – REST-APIs, Batch-Scoring-Jobs, eingebettete Edge-Geräte. Die Überwachung erfasst Vorhersagelatenz, Durchsatz, Fehlerraten und Datenabweichungen.
Bei Änderungen der Eingabeverteilung – etwa durch saisonale Schwankungen, Produkteinführungen oder Schema-Aktualisierungen – verschlechtert sich die Performance. Automatisierte Warnmeldungen lösen Nachschulungsprozesse aus, bevor Benutzer einen Genauigkeitsverlust bemerken.
Governance-Ebenen gewährleisten Zugriffskontrolle, Audit-Trails und Compliance-Richtlinien von der Datenerfassung bis zur Modellausgabe. Die zentrale Governance verhindert, dass Teams die Sicherheitslogik in jeder Pipeline neu entwickeln müssen.
Wie KI die Leistung von Datenpipelines verändert
Beseitigung von GPU-Auslastung
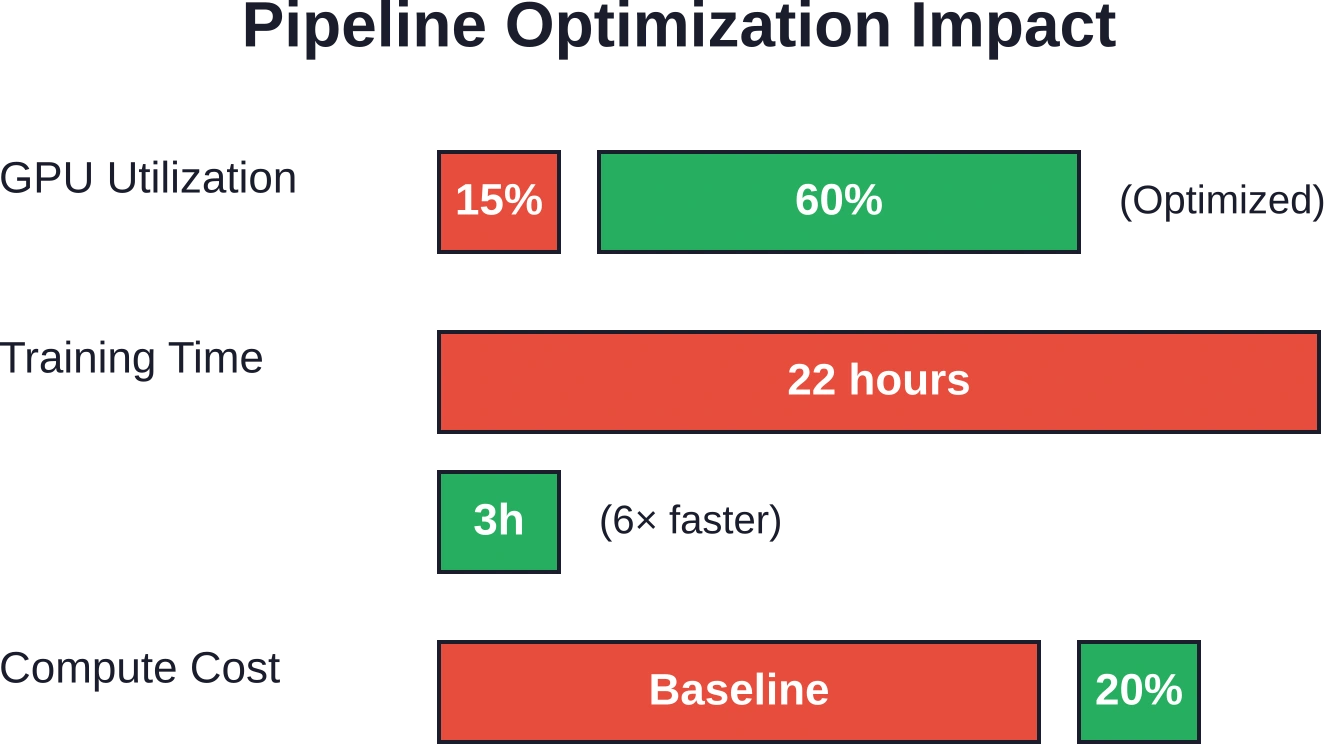
Hochleistungs-GPUs bleiben im Leerlauf, wenn das Laden der Daten nicht mit dem Rechendurchsatz Schritt halten kann. In typischen industriellen Deep-Learning-Pipelines beobachteten Forscher eine GPU-Auslastung von 10–151 TP3T, während diese auf Batches warteten.
Optimierte Datenpipelines mit verteilten Loadern wie Petastorm erreichten eine GPU-Auslastung von 60% und eine 6-fache Beschleunigung. Die Trainingszeit sank von 22 auf 3 Stunden. Durch die Eliminierung ineffizienter Rechenzyklen konnten die Rechenkosten um 80% gesenkt werden.
Der Flaschenhals war nicht das Modell, sondern die Ein-/Ausgabe. Wenn die Datenpipeline optimiert ist, zahlt sich die Hardwareinvestition aus.
Deklarative Frameworks für Skalierbarkeit
Imperativer Pipeline-Code – Python-Skripte, die Spark-Jobs verketten – wird bei großem Umfang unübersichtlich und schwer wartbar. Das Debuggen erfordert das Lesen Tausender Zeilen Code. Die Zusammenarbeit gerät ins Stocken, wenn die Logik über verschiedene Repositories verteilt ist.
Deklarative Frameworks ermöglichen es Entwicklern, *welche* Transformationen angewendet werden sollen, nicht *wie* diese ausgeführt werden. Die Plattform optimiert die Ausführungspläne automatisch.
Fallstudien von Unternehmen, die deklarative Pipelines einsetzen, berichten von einer um 501 % höheren Entwicklungseffizienz, einer Verkürzung des Kollaborationsaufwands von Wochen auf Tage, einer 500-fachen Verbesserung der Skalierbarkeit und einem 10-fachen Durchsatzgewinn im Vergleich zu imperativen Implementierungen.
Akademische Evaluierungen bestätigten einen 5,7-fachen Durchsatzgewinn gegenüber Nicht-Framework-Code und eine CPU-Auslastung von 99% bei verteilter Verarbeitung.
Selbstheilung und Schemaentwicklung
Produktionssysteme sind ständigen Veränderungen ausgesetzt. Upstream-APIs fügen Felder hinzu, benennen Spalten um oder ändern Datentypen ohne Vorwarnung. Traditionelle Pipelines brechen ab und erfordern manuelle Korrekturen.
Die KI-gestützte Schemaentwicklung erkennt automatisch Diskrepanzen, leitet korrekte Zuordnungen anhand historischer Muster ab und wendet Transformationen dynamisch an. Erklärbare KI-Agenten liefern Empfehlungen – ”Spalte `user_id` in `userId` umbenannt; automatische Zuordnung angewendet” – sodass Entwickler Änderungen prüfen können, ohne Protokolle durchsuchen zu müssen.
Echtzeit-Datenqualitätsverbesserungsschichten validieren Datensätze während der Erfassung, kennzeichnen Ausreißer und leiten verdächtige Daten zur Überprüfung in Quarantänetabellen weiter. Modelle werden weiterhin mit sauberen Teilmengen trainiert, während Ingenieure Anomalien asynchron untersuchen.

KI-Datenpipelines für die Entwicklung realer Modelle vorbereiten
KI-Projekte hängen von mehr als einem Modell ab. Die Daten müssen gesammelt, strukturiert, aufbereitet und mit der tatsächlichen Nutzung des Systems verknüpft werden. AI Superior Arbeitet mit KI und Datenstrategie, KI-Softwareentwicklung, maschinellem Lernen, Business Intelligence und KI-Integration. Für KI-Datenpipelines kann dies die Aufbereitung von Daten für ML-Modelle, die Entwicklung datengetriebener Anwendungen, die Unterstützung von Analyse-Workflows und die Sicherstellung der Kompatibilität von KI-Systemen mit bestehenden Geschäftsdatenquellen umfassen.
Die Arbeit von AI Superior kann Folgendes umfassen:
- Planung der Datenanforderungen für KI-Projekte
- Aufbereitung von Geschäftsdaten für maschinelle Lernmodelle
- Entwicklung von KI-Software, die mit bestehenden Datenquellen verbunden ist
- Unterstützung von Analyse- und BI-Workflows
- Integration von KI-Systemen in bestehende Geschäftsprozesse
👉Nehmen Sie Kontakt mit AI Superior auf. um zu besprechen, wie Ihre Daten für KI-Modelle, Analysetools oder kundenspezifische KI-Software vorbereitet werden können.
Häufige Herausforderungen und wie man sie bewältigt
Herausforderung: Verschlechterung der Datenqualität
Die Modellperformance sinkt ohne Codeänderungen. Nachgelagerte Dashboards zeigen eine abnehmende Genauigkeit. Ursache: Vor einigen Wochen wurden in vorgelagerten Datenquellen Nullwerte, Duplikate oder Formatierungsinkonsistenzen eingeführt.
Lösung: Kontinuierliche Qualitätskontrollen bei der Probenannahme. Statistische Profilierungsmodelle ermitteln die Basisverteilungen – Mittelwert, Varianz, Kardinalität – und warnen, sobald neue Chargen die Schwellenwerte überschreiten. Automatisierte Verbesserungen der Datengenauigkeit (18%) und Reduzierung von Duplikaten (75%) sind durch KI-gestützte Validierung möglich.
Herausforderung: Fragmentierte Infrastruktur
Legacy-Systeme speichern Daten in Silos – in lokalen Datenbanken, Cloud-Warehouses, Data Lakes und SaaS-Anwendungen. Der Datentransfer zwischen diesen Umgebungen erfordert benutzerdefinierte Skripte, VPNs und manuelle Koordination.
Lösung: Einheitliche Datenaufnahmeplattformen mit vorkonfigurierten Konnektoren für über 100 Datenquellen. Deklarative Konfiguration konsolidiert Authentifizierung, Ratenbegrenzung und inkrementelle Synchronisierungslogik. Teams definieren die Datenquellen einmalig; die Plattform kümmert sich um die gesamte Infrastruktur.
Herausforderung: Skalierung ohne Zusammenbruch der Wartbarkeit
Imperativer Pipeline-Code wächst auf Tausende von Zeilen an. Jede neue Funktion fügt bedingte Verzweigungen hinzu. Das Debuggen dauert Tage. Neue Teammitglieder können nicht eingearbeitet werden.
Lösung: Deklarative Frameworks einsetzen. Transformationen als Konfigurationsdateien oder SQL-ähnliche Abfragen definieren. Die Ausführungs-Engine optimiert Parallelität, Wiederholungsversuche und Ressourcenzuweisung automatisch. Unternehmensteams berichten von einer Reduzierung der Codebasis um 401 TP3T und einer Herunterfahren des Fehlerbehebungsprozesses von Wochen auf Tage.
Architektur-Best Practices für Produktionssysteme
Getrennter Speicher und Rechenleistung
Eng gekoppelte Architekturen erfordern eine gemeinsame Skalierung von Speicher und Rechenleistung. Überdimensionierung verschwendet Budget; Unterdimensionierung drosselt die Leistung von Anwendungen.
Cloud-native Designs entkoppeln die beiden. Daten werden in Objektspeichern (S3, GCS, Azure Blob) gespeichert. Kurzlebige Rechencluster (Spark, Dask, Ray) werden nur bei Bedarf gestartet und anschließend wieder heruntergefahren.
Version Alles
Code, Daten, Modelle und Konfigurationen ändern sich im Laufe der Zeit. Ohne Versionsverwaltung gleicht die Reproduktion eines drei Monate alten Ergebnisses einer Archäologie.
Moderne MLOps-Plattformen integrieren Git für Code, DVC für Datensätze und Modellregister für trainierte Artefakte. Jeder Trainingslauf verknüpft exakte Momentaufnahmen der Eingabedaten und Hyperparameterkonfigurationen. Rollbacks erfolgen mit einem einzigen Befehl.
Implementieren Sie die durchgängige Herkunftsanalyse
Aufsichtsbehörden und Prüfer fragen: “Wie kam das Modell zu dieser Vorhersage?” Ingenieure fragen: “Welche vorgelagerte Tabelle hat diesen Fehler verursacht?”
Die Nachverfolgung protokolliert jede Transformation – Quelltabelle → Zwischenmerkmal → Modelleingabe → Vorhersage. Metadaten speichern Erfassungszeitpunkte, Schemaversionen und Benutzeraktionen. Abfrageschnittstellen ermöglichen es Teams, von jeder Ausgabe zu ihren Ursprüngen zurückzuverfolgen.
Bauen Sie Observability vom ersten Tag an auf
Pipelines schlagen stillschweigend fehl. Jobs werden zwar erfolgreich abgeschlossen, erzeugen aber fehlerhafte Daten. Warnmeldungen werden zu spät ausgelöst.
Instrumentieren Sie jede Phase: Anzahl der erfassten Datenzeilen, Transformationsfehlerraten, Verschiebungen der Merkmalsverteilung, Latenz der Modellvorhersage. Dashboards decken Anomalien in Echtzeit auf. Bereitschaftsteams erkennen Probleme, bevor Benutzer sie melden.
Anwendungsfälle in verschiedenen Branchen
Betrugserkennung in Echtzeit (Finanzdienstleistungen)
Transaktionen werden in Millisekunden abgewickelt. Modelle bewerten jede Transaktion hinsichtlich des Betrugsrisikos und blockieren verdächtige Aktivitäten vor der Abwicklung.
Pipelines verarbeiten Ereignisströme (Kafka, Kinesis), verknüpfen diese mit Kundenprofilmerkmalen und rufen latenzarme Inferenzendpunkte auf. Die Überwachung erfasst die Falsch-Positiv-Rate und passt Schwellenwerte dynamisch an.
Vorausschauende Instandhaltung (Fertigung)
Sensoren an den Fabrikanlagen senden Telemetriedaten – Temperatur, Vibration, Druck. Modelle sagen Ausfälle Tage im Voraus voraus und ermöglichen so die Planung von Wartungsarbeiten während der vorgesehenen Stillstandszeiten.
Pipelines aggregieren Zeitreihendaten in gleitenden Fenstern (stündlich, täglich), entwickeln Verzögerungsmerkmale und trainieren Modelle wöchentlich neu, wenn neue Ausfallmuster auftreten.
Personalisierte Empfehlungen (E-Commerce)
Nutzerklickmuster und Kaufhistorien speisen kollaborative Filtermodelle. Empfehlungen werden nahezu in Echtzeit aktualisiert, sobald sich Präferenzen ändern.
Batch-Pipelines erstellen die Artikel-Einbettungen jede Nacht neu. Streaming-Pipelines aktualisieren Benutzerprofile bei jeder Interaktion. Hybridarchitekturen gleichen Aktualität und Rechenkosten aus.
Klinische Entscheidungsunterstützung (Gesundheitswesen)
Elektronische Patientenakten enthalten strukturierte Laborbefunde, unstrukturierte Arztberichte, medizinische Bilder und Verschreibungshistorien. Modelle synthetisieren Signale aus verschiedenen Modalitäten, um Risikopatienten zu identifizieren.
Pipelines verarbeiten multimodale Daten, wenden NLP an, um Entitäten aus Notizen zu extrahieren, normalisieren Laboreinheiten und gewährleisten eine durchgängige HIPAA-konforme Zugriffskontrolle.
Wichtige Plattformmerkmale zur Bewertung
Bei der Bewertung von Pipeline-Plattformen sollten Sie folgende Fähigkeiten priorisieren:
- Vorgefertigte Steckverbinder: Datenbanken, SaaS-Anwendungen, Cloud-Speicher, Streaming-Quellen
- Schema-Inferenz: Automatische Erkennung und Zuordnung von Datentypen
- Transformationsbibliotheken: SQL, Python, visuelle DAG-Generatoren
- Orchestrierung: Terminplanung, Abhängigkeiten, Wiederholungsversuche, Nachfüllungen
- Überwachung und Warnmeldungen: Kennzahlen zur Datenqualität, Dashboards zum Zustand der Pipeline
- Regierungsführung: Zugriffskontrolle, Audit-Protokolle, Herkunftsverfolgung
- Skalierbarkeit: Verteilte Ausführungs-Engines (Spark, Dask, Ray)
- Integration: Modellregister, Feature-Stores, Experiment-Tracking
Proprietäre Plattformen abstrahieren zwar die Komplexität, führen aber zu einer Abhängigkeit vom jeweiligen Anbieter. Open-Source-Tools (Airflow, Prefect, Dagster) bieten Flexibilität, erfordern jedoch einen höheren Betriebsaufwand.

Einführungsstrategie: Klein anfangen, schnell skalieren
Versuchen Sie nicht, gleich am ersten Tag eine unternehmensweite Pipeline-Überarbeitung vorzunehmen. Führen Sie stattdessen ein Pilotprojekt mit einem einzelnen, wirkungsvollen Anwendungsfall durch – Betrugserkennung, Abwanderungsprognose, Bedarfsplanung –, bei dem die Beteiligten bereits einen Handlungsbedarf feststellen.
Entwickeln Sie einen durchgängigen Workflow: Datenaufnahme aus einer zentralen Quelle, minimale Transformationen, ein Modell, ein Bereitstellungsziel. Beweisen Sie schnell den Nutzen. Dann können Sie expandieren.
Dokumentieren Sie die gewonnenen Erkenntnisse. Standardisieren Sie bewährte Vorgehensweisen. Teilen Sie Erfolge teamübergreifend. Zentralisieren Sie mit zunehmender Akzeptanz gemeinsam genutzte Komponenten – Authentifizierungsmodule, Monitoring-Dashboards, Governance-Richtlinien – in wiederverwendbaren Vorlagen.
Investieren Sie in Weiterbildung. Pipeline-Ingenieure benötigen sowohl Kenntnisse im Bereich Data Engineering (SQL, verteilte Systeme) als auch Grundlagen des maschinellen Lernens (Bias, Overfitting, Bewertungsmetriken). Bereichsübergreifende Zusammenarbeit beschleunigt den Wissenstransfer.
Der Weg in die Zukunft: KI-Pipelines im Jahr 2026 und darüber hinaus
Deklarative Frameworks werden immer mehr zum Standard. Teams, die immer noch imperative Spark-Skripte schreiben, werden im Hinblick auf die Geschwindigkeit Schwierigkeiten haben, mitzuhalten.
Automatisierte Werkzeuge zur Merkmalsentwicklung werden das, was heute noch tiefgreifendes Fachwissen erfordert, zur Standardisierung machen. Modelle schlagen Merkmale vor; Ingenieure prüfen und genehmigen diese.
Governance und Nachvollziehbarkeit werden von nachträglichen Überlegungen zu zentralen Anforderungen. Regulatorischer Druck – etwa durch die EU-KI-Gesetzgebung und länderspezifische Datenschutzgesetze – zwingt Unternehmen, die Fairness, Transparenz und Überprüfbarkeit ihrer Modelle nachzuweisen. Pipelines, die Governance von Anfang an integrieren, werden sich schneller anpassen als solche, die die Einhaltung von Vorschriften nachträglich anstreben.
Der Einsatz von Edge-Computing wird sich beschleunigen. Mit der Verkleinerung der Modelle (Quantisierung, Destillation) und der Verbesserung der Edge-Hardware rückt die Inferenz näher an die Datenquellen heran. Pipelines müssen das Training in der Cloud und die Bereitstellung auf Tausenden von verteilten Endpunkten orchestrieren.
Das Kernprinzip bleibt jedoch bestehen: KI ist nur so gut wie die Daten, mit denen sie gespeist wird. Pipelines, die die Datenerfassung, -transformation und Qualitätsprüfung automatisieren, ermöglichen es Teams, sich auf das zu konzentrieren, was Maschinen nicht können – nämlich bessere Fragen zu stellen.
Häufig gestellte Fragen
Was ist eine KI-Datenpipeline?
Eine KI-Datenpipeline ist ein automatisierter Workflow, der Rohdaten aus verschiedenen Quellen aufnimmt, sie in saubere, strukturierte Formate transformiert, Merkmale für Modelle des maschinellen Lernens generiert, diese Modelle trainiert und validiert, sie für Inferenzprozesse einsetzt und die Leistung kontinuierlich überwacht. Im Gegensatz zu herkömmlichen ETL-Prozessen durchlaufen KI-Pipelines iterative Feedbackschleifen – sie trainieren Modelle bei Datenänderungen neu und passen Schemata mithilfe von integriertem maschinellem Lernen automatisch an.
Worin unterscheiden sich KI-Datenpipelines von herkömmlichen ETL-Prozessen?
Traditionelle ETL-Prozesse folgen einer linearen Abfolge von Extraktion, Transformation und Laden für Reporting und Business Intelligence. KI-Datenpipelines arbeiten in kontinuierlichen Schleifen und verarbeiten sowohl strukturierte als auch unstrukturierte Daten (Text, Bilder, Protokolle). Sie nutzen maschinelles Lernen zur automatischen Schema-Zuordnung und leiten Erkenntnisse aus dem Monitoring zurück in die vorgelagerten Prozesse, um das Training der Modelle zu optimieren. Dabei priorisieren sie das Modelltraining und die Ergebnisse der Inferenz gegenüber statischen Dashboards.
Welche Leistungsverbesserungen können KI-Pipelines erzielen?
Produktionsbenchmarks zeigen, dass KI-optimierte Pipelines eine GPU-Auslastung von 60% erreichen (gegenüber 10–15% im Basiswert), eine 6-fache Gesamtbeschleunigung erzielen, die Trainingszeit von 22 auf 3 Stunden reduzieren und die Rechenkosten um 80% senken. Deklarative Frameworks weisen im Vergleich zu imperativen Implementierungen eine 50% höhere Entwicklungseffizienz, eine 500-fach verbesserte Skalierbarkeit und einen 10-fach höheren Durchsatz auf.
Welche Tools werden üblicherweise für KI-Datenpipelines verwendet?
Zu den gängigen Open-Source-Tools gehören Apache Spark (verteilte Verarbeitung), Apache Airflow und Prefect (Orchestrierung), MLFlow (Experiment-Tracking) und DVC (Datenversionierung). Proprietäre Plattformen wie Databricks, Snowflake und spezialisierte KI-ETL-Dienste bieten verwaltete Umgebungen mit integrierten Konnektoren, Governance und Monitoring. Die Wahl des Tools hängt von der Expertise des Teams, der Projektgröße und der Bereitschaft zum operativen Mehraufwand ab.
Was sind die größten Herausforderungen beim Aufbau von KI-Datenpipelines?
Häufige Hindernisse sind die Verschlechterung der Datenqualität (durch Änderungen in vorgelagerten Systemen, die Nullwerte oder Duplikate verursachen), fragmentierte Infrastruktur (Daten in inkompatiblen Systemen gespeichert), Schema-Drift (API-Änderungen, die Pipelines unterbrechen) und die zunehmende Wartbarkeit mit wachsendem imperativem Code. Lösungen umfassen kontinuierliche Qualitätsprüfungen, einheitliche Datenaufnahmeplattformen, ML-gestützte Schema-Evolution und die Einführung deklarativer Frameworks, die Logik und Ausführung trennen.
Wie wichtig ist Governance in KI-Datenpipelines?
Governance ist entscheidend für die Einhaltung gesetzlicher Bestimmungen, die Nachverfolgbarkeit von Prüfprotokollen und das Vertrauen in die Daten. Die durchgängige Nachverfolgung der Datenherkunft protokolliert jede Transformation von der Quelle bis zur Vorhersage und ermöglicht es Teams, Fehler aufzuspüren und Aufsichtsbehörden, die Fairness zu überprüfen. Zugriffskontrolle, rollenbasierte Berechtigungen und automatisierte Prüfprotokolle verhindern die unbefugte Offenlegung von Daten. Organisationen, die Governance von Anfang an in ihre Prozesse integrieren, passen sich schneller an sich ändernde Datenschutzgesetze und KI-Vorschriften an.
Können KI-Pipelines unstrukturierte Daten verarbeiten?
Ja – die Verarbeitung unstrukturierter Daten (Dokumente, Bilder, Audio, Freitext) ist einer ihrer Hauptvorteile gegenüber herkömmlichen ETL-Prozessen. KI-Pipelines nutzen NLP-Modelle, um Entitäten aus Texten zu extrahieren, Computer-Vision-Modelle zur Klassifizierung von Bildern und Embeddings, um unstrukturierte Eingaben in numerische Merkmale umzuwandeln, die von den Modellen verarbeitet werden können. Diese Fähigkeit erschließt den Großteil der Unternehmensdaten, die herkömmliche Tools ignorieren.
Fazit: Pipelines entwickeln, die lernen
KI-Modelle sorgen für Schlagzeilen. Doch die Entwicklungspipelines entscheiden darüber, ob diese Modelle jemals in der Produktion zum Einsatz kommen.
Die Unternehmen, die 2026 die Nase vorn haben, sind nicht unbedingt diejenigen mit den größten Data-Science-Teams. Es sind diejenigen, die die grundlegende Infrastruktur – Datenerfassung, Transformation, Überwachung – automatisiert haben, sodass sich die Ingenieure auf die Lösung von Geschäftsproblemen konzentrieren können, anstatt ETL-Skripte zu debuggen.
Beginnen Sie mit einem wirkungsvollen Anwendungsfall. Beweisen Sie den Nutzen von automatisiertem Schema-Mapping, Echtzeit-Qualitätsprüfungen und kontinuierlichem Nachlernen. Skalieren Sie die Muster anschließend teamübergreifend.
Der Wettbewerbsvorteil liegt nicht in der Modellarchitektur, sondern in der Infrastruktur, die dafür sorgt, dass die Modelle stets aktuell und zuverlässig sind. Ist diese Infrastruktur vorhanden, wird KI vom reinen Forschungsprojekt zum entscheidenden Wirtschaftsfaktor.