ملخص سريع: تجمع مسارات بيانات الذكاء الاصطناعي بين التعلم الآلي وهندسة البيانات لأتمتة رسم خرائط المخططات ومعالجة البيانات وفحص جودتها، محولةً المعلومات الخام غير المهيكلة إلى مجموعات بيانات جاهزة للذكاء الاصطناعي بأقل قدر من التدخل اليدوي. وعلى عكس عمليات استخراج البيانات وتحويلها وتحميلها التقليدية، فإنها تتكرر باستمرار خلال مراحل الاستيعاب والتحويل وهندسة الميزات والتدريب والمراقبة. وتُظهر الأطر التصريحية الحديثة مكاسب في كفاءة التطوير تصل إلى 50%، وتحسينات في قابلية التوسع تصل إلى 500 ضعف، وتخفيضات في تكلفة الحوسبة تصل إلى 80%.
كل مشروع طموح في مجال الذكاء الاصطناعي يصطدم بنفس العقبة: جبال من البيانات الفوضوية الموجودة في أنظمة منفصلة، بعيدة كل البعد عن التنسيق النظيف والمنظم الذي تتطلبه النماذج.
تُعاني أدوات استخراج البيانات وتحويلها وتحميلها التقليدية من مشاكل في التعامل مع السجلات غير المهيكلة والصور وحقول النصوص الحرة. فهي تتطلب جيوشًا من المهندسين لرسم خرائط المخططات يدويًا في كل مرة يتغير فيها المصدر. وعندما تبقى مجموعات وحدات معالجة الرسومات (GPU) خاملة بمعدل استخدام يتراوح بين 10 و151 تيرابايت/3 تيرابايت في انتظار الدفعة التالية، تتلاشى ميزانيات الحوسبة.
هذه هي المشكلة التي تحلها خطوط نقل بيانات الذكاء الاصطناعي. فهي لا تنقل البيانات فحسب، بل تتعلم منها، وتتكيف مع تغيرات المخططات تلقائيًا، وتحافظ على تشبع البنية التحتية للتدريب.
ما الذي يميز خطوط بيانات الذكاء الاصطناعي؟
تتبع مسارات البيانات التقليدية مسارًا خطيًا: استخراج البيانات الأولية، وتحويلها وفقًا لقواعد ثابتة، ثم تحميلها إلى مستودع البيانات. سير العمل قابل للتنبؤ. يتم تشغيله مرة واحدة، وينتهي الأمر.
تعمل مسارات بيانات الذكاء الاصطناعي في حلقات متواصلة. الاستيعاب ← التحضير ← هندسة الميزات ← تدريب النماذج ← التنبؤ ← المراقبة ← إعادة التدريب. كل مرحلة تُعيد المعلومات إلى المراحل السابقة.
لكن الأمر المهم هو أنها تتعامل أيضاً مع ما لا تستطيع عمليات استخراج البيانات وتحويلها وتحميلها التقليدية التعامل معه: البيانات غير المهيكلة على نطاق واسع. المستندات، والصور، والملفات الصوتية، وتعليقات العملاء النصية الحرة - وهي تنسيقات تمثل غالبية معلومات المؤسسات ولكنها لا تزال بمنأى عن الأدوات التقليدية.
| الأبعاد | خط نقل البيانات التقليدي | خط أنابيب بيانات الذكاء الاصطناعي |
|---|---|---|
| الغرض الأساسي | إعداد التقارير ومعلومات الأعمال | تدريب النموذج والاستدلال والتنبؤ |
| الناتج | لوحات المعلومات، والتقارير، والمقاييس المجمعة | النماذج المدربة، والتنبؤات، ومخازن الميزات |
| سير العمل | خطي: استخراج ← تحويل ← تحميل | عملية تكرارية: استيعاب البيانات ← تحضيرها ← تدريبها ← تنبؤها ← مراقبتها ← إعادة تدريبها |
| معالجة المخططات | التخطيط اليدوي، فترات راحة عند انحراف المخطط | رسم الخرائط التلقائي المدعوم بالتعلم الآلي، يتكيف مع التغييرات |
| أنواع البيانات | ذات بنية أساسية (قواعد البيانات، ملفات CSV) | البيانات المنظمة وغير المنظمة (نصوص، صور، سجلات) |
| الحوكمة | التحكم في الوصول على مستوى المستودع | تتبع كامل للبيانات، وإصدارات النماذج، وسجلات التدقيق |
بصراحة: طبقة الأتمتة هي ما يفصل بينهما. نماذج التعلم الآلي المدمجة في خط المعالجة نفسه تكتشف تغييرات المخطط، وتقترح التحويلات، وتحدد الحالات الشاذة قبل أن تؤثر سلبًا على النماذج اللاحقة.
المراحل الخمس الأساسية لخطوط نقل بيانات الذكاء الاصطناعي الحديثة
الابتلاع: ربط كل شيء
تأتي البيانات من كل مكان - واجهات برمجة التطبيقات، وقواعد البيانات، وتدفقات الأحداث، ومساحات تخزين S3، ومستودعات البيانات المحلية. وتقوم عملية الاستيعاب بجمع كل ذلك في بيئة موحدة.
تتعامل الموصلات الحديثة مع معالجة البيانات المجمعة والمتدفقة في آن واحد. قد يحدد إطار العمل التصريحي المصادر مرة واحدة، ثم يقوم تلقائيًا بتوزيع عملية الاستيعاب بالتوازي عبر مئات الأقسام.
يُستخدم Apache Spark على نطاق واسع لمعالجة البيانات الموزعة في خطوط نقل البيانات المؤسسية. لكن المنصات الاحتكارية تُخفي بشكل متزايد تعقيدات Spark خلف بنية برمجية شبيهة بلغة SQL.
التحول: التنظيف والهيكلة
تصل البيانات الأولية متضمنةً بيانات مكررة، وقيمًا فارغة، وتنسيقًا غير متناسق، وطوابع زمنية مفقودة. تعمل آلية التحويل على إزالة السجلات المكررة، واستكمال القيم المفقودة، وتوحيد الطوابع الزمنية، وتحويل أنواع البيانات.
تتطلب عمليات استخراج البيانات وتحويلها وتحميلها التقليدية من المهندسين كتابة وصيانة نصوص التحويل يدويًا. أما المنصات المدعومة بالذكاء الاصطناعي فتستخدم نماذج كشف الشذوذ لتحديد السجلات المشبوهة تلقائيًا واقتراح قواعد المعالجة.
تُظهر الأبحاث من دراسات إدارة البيانات الأكاديمية أن التحقق المدعوم بالذكاء الاصطناعي يقلل من السجلات المكررة بنسبة 75% ويحسن دقة البيانات بنسبة 18%.
هندسة الميزات: بناء مدخلات النموذج
لا تستخدم النماذج الأعمدة الخام، بل تحتاج إلى ميزات مُهندسة. التشفير الفئوي، والتحجيم، والتقسيم الزمني، والتأخير، والتجميع عبر الفترات الزمنية - كلها عمليات معالجة مسبقة تحول السمات الخام إلى إشارات تنبؤية.
تقوم أدوات هندسة الميزات الآلية باختبار آلاف التحويلات المرشحة، وتصنيفها حسب قدرتها التنبؤية، وإصدار مجموعة الميزات النهائية جنبًا إلى جنب مع نقاط التحقق من النموذج.
هذه المرحلة تكرارية. تفشل النماذج، ويضيف المهندسون ميزات جديدة، وتعاد تدريب خطوط الأنابيب. تعمل حلقات التغذية الراجعة المحكمة على ضغط أسابيع من التجارب إلى أيام.
التدريب والتحقق
يتم تقسيم البيانات المُعدة إلى مجموعات تدريب وتحقق - عادةً بنسبة 80/20. تقوم مجموعة التدريب بتعليم النموذج الأنماط؛ بينما تختبر مجموعة التحقق ما إذا كانت تلك الأنماط قابلة للتعميم.
يتم ضبط المعلمات الفائقة هنا: معدلات التعلم، وأحجام الدُفعات، ومعاملات التنظيم. تقوم أدوات البحث الآلي مثل MLFlow أو منصات AutoML الخاصة باختبار مئات التكوينات بالتوازي.
تُظهر نتائج الاختبارات المعيارية من تطبيقات الإنتاج واسعة النطاق أن أوقات التدريب الشاملة للنماذج الكاملة تبلغ حوالي 60 ساعة. أما ضبط النماذج الأساسية المدربة مسبقًا فيُقلل هذه المدة إلى 8 ساعات و47 دقيقة، بمتوسط وقت تشغيل يبلغ دقيقة و45 ثانية لكل عملية تشغيل.
النشر والمراقبة
تنتقل النماذج المدربة إلى بيئات الاستدلال - واجهات برمجة تطبيقات REST، ووظائف تسجيل البيانات المجمعة، وأجهزة الحافة المدمجة. وتراقب عملية المراقبة زمن استجابة التنبؤ، والإنتاجية، ومعدلات الخطأ، وانحراف البيانات.
عندما تتغير توزيعات المدخلات - نتيجة للتغيرات الموسمية، أو إطلاق منتجات جديدة، أو تحديثات المخططات - يتراجع الأداء. تعمل التنبيهات الآلية على تشغيل عمليات إعادة التدريب قبل أن يلاحظ المستخدمون انخفاض الدقة.
تُطبّق طبقات الحوكمة ضوابط الوصول، وسجلات التدقيق، وسياسات الامتثال بدءًا من مرحلة الإدخال وحتى إخراج النموذج. وتمنع الحوكمة المركزية الفرق من إعادة ابتكار منطق الأمان في كل مسار.
كيف يُحدث الذكاء الاصطناعي تحولاً في أداء خطوط نقل البيانات
القضاء على نقص موارد وحدة معالجة الرسومات
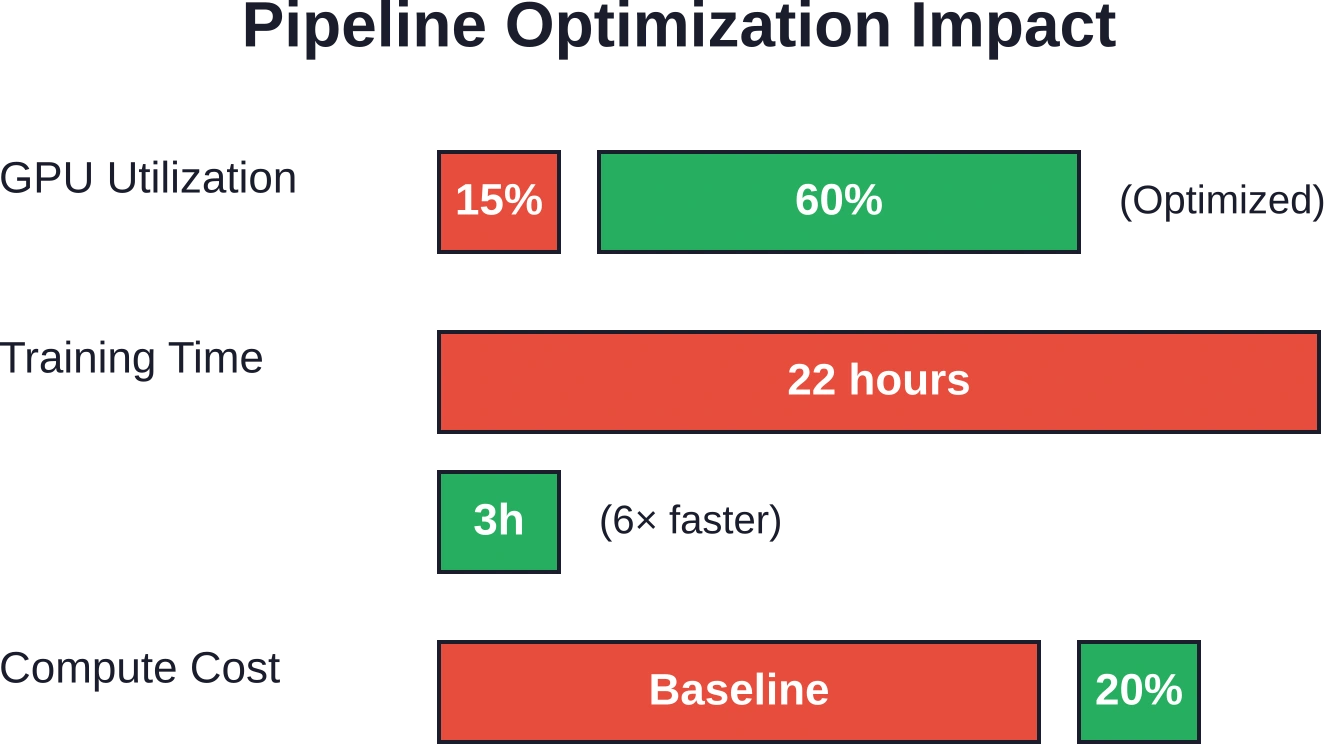
تبقى وحدات معالجة الرسومات عالية الأداء في وضع الخمول عندما لا يستطيع تحميل البيانات مواكبة معدل نقل البيانات. في خطوط أنابيب التعلم العميق الصناعية الأساسية، لاحظ الباحثون أن وحدات معالجة الرسومات تعمل بمعدل استخدام يتراوح بين 10 و151 تيرابايت/3 تيرابايت أثناء انتظارها للدفعات.
حققت مسارات البيانات المُحسّنة باستخدام مُحمّلات موزعة مثل Petastorm استخدامًا لوحدة معالجة الرسومات (GPU) بلغ 60%، مما أدى إلى تسريع إجمالي قدره 6 أضعاف. انخفض وقت التدريب الشامل من 22 ساعة إلى 3 ساعات. وبلغت تخفيضات تكلفة الحوسبة 80% من خلال التخلص من الدورات المهدرة.
لم تكن المشكلة في النموذج نفسه، بل في عمليات الإدخال والإخراج. أصلح خط الأنابيب، وسيؤتي الاستثمار في الأجهزة ثماره.
أطر تصريحية للتوسع
يصبح كود خط الأنابيب الإجرائي - وهو عبارة عن نصوص بايثون تربط مهام سبارك - غير قابل للصيانة عند التوسع. ويتطلب تصحيح الأخطاء قراءة آلاف الأسطر. ويتعثر التعاون عندما تتوزع التعليمات البرمجية عبر مستودعات متعددة.
تتيح الأطر التصريحية للمهندسين تحديد *ما* هي التحويلات التي سيتم تطبيقها، وليس *كيفية* تنفيذها. تعمل المنصة على تحسين خطط التنفيذ تلقائيًا.
تشير دراسات حالة المؤسسات التي تستخدم خطوط الأنابيب التصريحية إلى كفاءة تطوير أفضل بمقدار 50%، وتقليص جهود التعاون من أسابيع إلى أيام، وتحسينات في قابلية التوسع بمقدار 500 ضعف، وزيادة في الإنتاجية بمقدار 10 أضعاف مقارنة بالتنفيذات الإجرائية.
أكدت التقييمات الأكاديمية زيادة الإنتاجية بمقدار 5.7 مرة مقارنة بالبرامج غير المعتمدة على إطار العمل، واستخدام وحدة المعالجة المركزية بمقدار 99% أثناء المعالجة الموزعة.
الشفاء الذاتي وتطور المخطط
تواجه أنظمة الإنتاج تغييرات مستمرة. تضيف واجهات برمجة التطبيقات (APIs) حقولاً، أو تعيد تسمية الأعمدة، أو تُغير أنواع البيانات دون سابق إنذار. وتتعطل خطوط المعالجة التقليدية وتنتظر إصلاحات يدوية.
يكشف تطوير المخططات الموجه بالذكاء الاصطناعي عن حالات عدم التطابق تلقائيًا، ويستنتج عمليات الربط الصحيحة باستخدام الأنماط التاريخية، ويطبق التحويلات فورًا. تقدم وكلاء الذكاء الاصطناعي القابلة للتفسير توصيات مثل "تمت إعادة تسمية العمود `user_id` إلى `userId`؛ تم تطبيق الربط التلقائي"، مما يتيح للمهندسين مراجعة التغييرات دون الحاجة إلى البحث في السجلات.
تعمل طبقات تحسين جودة البيانات في الوقت الفعلي على التحقق من صحة السجلات أثناء استيعابها، وتحديد القيم الشاذة، وتوجيه البيانات المشتبه بها إلى جداول العزل للمراجعة. وتستمر النماذج في التدريب على مجموعات فرعية نظيفة بينما يقوم المهندسون بالتحقيق في الحالات الشاذة بشكل غير متزامن.

إعداد مسارات بيانات الذكاء الاصطناعي لتطوير نماذج حقيقية
تعتمد مشاريع الذكاء الاصطناعي على أكثر من مجرد نموذج. يجب جمع البيانات وهيكلتها وإعدادها وربطها بالطريقة التي سيتم بها استخدام النظام فعلياً. متفوقة الذكاء الاصطناعي يعمل في مجال الذكاء الاصطناعي واستراتيجية البيانات، وتطوير برمجيات الذكاء الاصطناعي، والتعلم الآلي، وذكاء الأعمال، وتكامل الذكاء الاصطناعي. بالنسبة لخطوط بيانات الذكاء الاصطناعي، يشمل ذلك إعداد البيانات لنماذج التعلم الآلي، وبناء تطبيقات تعتمد على البيانات، ودعم سير عمل التحليلات، والتأكد من قدرة أنظمة الذكاء الاصطناعي على العمل مع مصادر بيانات الأعمال الحالية.
يمكن أن تشمل أعمال شركة AI Superior ما يلي:
- متطلبات بيانات التخطيط لمشاريع الذكاء الاصطناعي
- إعداد بيانات الأعمال لنماذج التعلم الآلي
- بناء برمجيات الذكاء الاصطناعي المتصلة بمصادر البيانات الحالية
- دعم عمليات التحليل وسير عمل ذكاء الأعمال
- دمج أنظمة الذكاء الاصطناعي في عمليات الأعمال الحالية
👉تواصل مع شركة AI Superior لمناقشة كيفية إعداد بياناتك لنماذج الذكاء الاصطناعي، أو أدوات التحليل، أو برامج الذكاء الاصطناعي المخصصة.
التحديات الشائعة وكيفية التغلب عليها
التحدي: تدهور جودة البيانات
انخفض أداء النموذج دون إجراء أي تغييرات برمجية. وتُظهر لوحات المعلومات اللاحقة انخفاضًا في الدقة. السبب الجذري: أدخلت مصادر البيانات الأولية قيمًا فارغة أو مكررة أو تناقضات في التنسيق منذ أسابيع.
الحل: إجراء فحوصات جودة مستمرة عند إدخال البيانات. تقوم نماذج التحليل الإحصائي بتحليل التوزيعات الأساسية - المتوسط، والتباين، والعدد - وتنبيه المستخدمين عند انحراف الدفعات الجديدة عن الحدود المحددة. يمكن تحقيق تحسينات آلية في دقة البيانات تصل إلى 18% وتقليل البيانات المكررة بمقدار 75% باستخدام التحقق المدعوم بالذكاء الاصطناعي.
التحدي: البنية التحتية المجزأة
تخزن الأنظمة القديمة البيانات في مستودعات معزولة - قواعد بيانات محلية، ومستودعات بيانات سحابية، وبحيرات بيانات، وتطبيقات SaaS. ويتطلب نقل البيانات بين هذه البيئات برامج نصية مخصصة، وشبكات VPN، وتنسيقًا يدويًا.
الحل: منصات استيعاب موحدة مزودة بموصلات جاهزة لأكثر من 100 مصدر. يعمل التكوين التصريحي على دمج المصادقة، وتحديد معدل البيانات، ومنطق المزامنة التزايدية. تقوم الفرق بتحديد المصادر مرة واحدة؛ وتتولى المنصة جميع الإجراءات اللازمة.
التحدي: التوسع دون انهيار قابلية الصيانة
يتضخم كود خط الأنابيب الإجرائي ليصل إلى آلاف الأسطر. وتضيف كل ميزة جديدة فروعًا شرطية. ويستغرق تصحيح الأخطاء أيامًا. ولا يمكن لأعضاء الفريق الجدد الانضمام بسهولة.
الحل: اعتماد أطر عمل تصريحية. تحديد التحويلات كملفات تهيئة أو استعلامات شبيهة بلغة SQL. يعمل محرك التنفيذ على تحسين التوازي، وإعادة المحاولات، وتخصيص الموارد تلقائيًا. تُفيد فرق المؤسسات بانخفاض حجم قاعدة التعليمات البرمجية بمقدار 40%، وتقليص وقت استكشاف الأخطاء وإصلاحها من أسابيع إلى أيام.
أفضل الممارسات المعمارية لأنظمة الإنتاج
التخزين والحوسبة المنفصلة
تُجبر البنى المترابطة بإحكام على توسيع نطاق التخزين والحوسبة معًا. يؤدي الإفراط في التخصيص إلى إهدار الميزانية، بينما يؤدي نقص التخصيص إلى إبطاء العمليات.
تُفصل التصاميم السحابية الأصلية بين النظامين. تُخزن البيانات في وحدات تخزين الكائنات (S3، GCS، Azure Blob). تُشغل مجموعات الحوسبة المؤقتة (Spark، Dask، Ray) فقط عند تشغيل المهام، ثم تُغلق بعد ذلك.
إصدار كل شيء
تتغير جميع عناصر البرمجة والبيانات والنماذج والإعدادات بمرور الوقت. وبدون نظام إدارة الإصدارات، يصبح استعادة نتيجة من ثلاثة أشهر مضت أشبه بالتنقيب عن الآثار.
تدمج منصات MLOps الحديثة نظام Git لإدارة التعليمات البرمجية، ونظام DVC لإدارة مجموعات البيانات، وسجلات النماذج لحفظ البيانات المُدرَّبة. ويرتبط كل تشغيل تدريبي بنسخ دقيقة من بيانات الإدخال وتكوينات المعلمات الفائقة. ويمكن التراجع عن التغييرات بأمر واحد.
تطبيق نظام تتبع السلالة من البداية إلى النهاية
يتساءل المنظمون والمدققون: "كيف توصل النموذج إلى هذا التوقع؟" ويتساءل المهندسون: "أي جدول بيانات رئيسي تسبب في هذا الخطأ؟"“
يسجل نظام تتبع النسب كل عملية تحويل - من جدول المصدر إلى الميزة الوسيطة، ثم إلى مدخلات النموذج، وصولاً إلى التنبؤ. وتخزن البيانات الوصفية الطوابع الزمنية، وإصدارات المخططات، وإجراءات المستخدم. وتتيح واجهات الاستعلام للفرق تتبع أي مخرجات إلى أصولها.
بناء قابلية المراقبة من اليوم الأول
تتعطل خطوط الأنابيب بصمت. تُنجز المهام بنجاح ولكنها تُنتج بيانات غير صالحة. تصل التنبيهات متأخرة جدًا.
تُزوّد كل مرحلة بأجهزة قياس: عدد صفوف الإدخال، ومعدلات أخطاء التحويل، وتغيرات توزيع الميزات، وزمن استجابة تنبؤ النموذج. تعرض لوحات المعلومات أي شذوذات في الوقت الفعلي. وتكتشف فرق الدعم الفني المشكلات قبل أن يبلغ عنها المستخدمون.
حالات الاستخدام عبر مختلف الصناعات
الكشف عن الاحتيال في الوقت الفعلي (الخدمات المالية)
تتم المعاملات في غضون أجزاء من الثانية. تقوم النماذج بتقييم كل معاملة من حيث مخاطر الاحتيال، وتمنع النشاط المشبوه قبل التسوية.
تستقبل خطوط المعالجة تدفقات الأحداث (Kafka، Kinesis)، وتدمجها مع خصائص ملف تعريف العميل، وتستدعي نقاط نهاية الاستدلال منخفضة زمن الاستجابة. يراقب نظام المراقبة معدلات الإنذارات الكاذبة ويُعدّل العتبات ديناميكيًا.
الصيانة التنبؤية (التصنيع)
تُصدر أجهزة الاستشعار الموجودة على معدات المصنع بيانات القياس عن بُعد - درجة الحرارة، والاهتزاز، والضغط. وتتنبأ النماذج بالأعطال قبل حدوثها بأيام، مما يسمح بجدولة الصيانة خلال فترات التوقف المخطط لها.
تقوم خطوط الأنابيب بتجميع بيانات السلاسل الزمنية في نوافذ متحركة (ساعة، يوم)، وهندسة ميزات التأخير، وإعادة تدريب النماذج أسبوعيًا مع ظهور أنماط فشل جديدة.
التوصيات الشخصية (التجارة الإلكترونية)
تُستخدم سجلات نقرات المستخدمين وسجلات الشراء لتغذية نماذج التصفية التعاونية. ويتم تحديث التوصيات بشكل شبه فوري مع تغير التفضيلات.
تقوم خطوط المعالجة الدفعية بإعادة بناء تضمينات العناصر ليلاً. بينما تقوم خطوط المعالجة المتدفقة بتحديث ملفات تعريف المستخدمين مع كل تفاعل. وتوازن البنى الهجينة بين حداثة البيانات وتكلفة الحوسبة.
دعم القرار السريري (الرعاية الصحية)
تحتوي السجلات الصحية الإلكترونية على نتائج مختبرية منظمة، وملاحظات طبية غير منظمة، وصور طبية، وسجلات وصفات طبية. تقوم النماذج بتجميع الإشارات عبر مختلف الوسائل لتحديد المرضى المعرضين للخطر.
تتولى خطوط المعالجة التعامل مع عمليات الإدخال متعددة الوسائط، وتطبيق معالجة اللغة الطبيعية لاستخراج الكيانات من الملاحظات، وتوحيد وحدات المختبر، وفرض التحكم في الوصول المتوافق مع قانون HIPAA في جميع أنحاء النظام.
أهم ميزات المنصة التي يجب تقييمها
عند تقييم منصات خطوط الأنابيب، أعطِ الأولوية لهذه القدرات:
- موصلات جاهزة: قواعد البيانات، تطبيقات SaaS، التخزين السحابي، مصادر البث المباشر
- استدلال المخطط: الكشف التلقائي عن أنواع البيانات وتعيينها
- مكتبات التحويل: SQL، بايثون، أدوات إنشاء الرسوم البيانية الموجهة غير الدورية المرئية
- التوزيع الموسيقي: الجدولة، والتبعيات، وإعادة المحاولات، وإعادة التعبئة
- المراقبة والتنبيهات: مقاييس جودة البيانات، ولوحات معلومات حالة خط الأنابيب
- الحوكمة: التحكم في الوصول، وسجلات التدقيق، وتتبع النسب
- قابلية التوسع: محركات التنفيذ الموزعة (Spark، Dask، Ray)
- اندماج: سجلات النماذج، ومخازن الميزات، وتتبع التجارب
تُبسط المنصات الاحتكارية التعقيد ولكنها تُؤدي إلى احتكار المورد. أما الأدوات مفتوحة المصدر (مثل Airflow وPrefect وDagster) فتُوفر المرونة ولكنها تتطلب المزيد من النفقات التشغيلية.

استراتيجية التبني: ابدأ صغيراً، وتوسع بسرعة
لا تحاول إجراء إصلاح شامل لخط أنابيب المؤسسة بأكملها في اليوم الأول. ابدأ بتجربة حالة استخدام واحدة ذات تأثير كبير - مثل كشف الاحتيال، أو التنبؤ بانقطاع العملاء، أو التنبؤ بالطلب - حيث يشعر أصحاب المصلحة بالفعل بالمشكلة.
أنشئ تدفقًا متكاملًا من البداية إلى النهاية: استيعاب البيانات من مصدر رئيسي واحد، بأقل قدر من التحويلات، ونموذج واحد، وهدف نشر واحد. أثبت القيمة بسرعة. ثم توسع.
وثّق الدروس المستفادة. وحّد الأنماط الناجحة. وانشر النجاحات بين الفرق. ومع ازدياد التبني، قم بمركزة المكونات المشتركة - وحدات المصادقة، ولوحات مراقبة الأداء، وسياسات الحوكمة - في قوالب قابلة لإعادة الاستخدام.
استثمر في التدريب. يحتاج مهندسو خطوط الأنابيب إلى مهارات هندسة البيانات (SQL، الأنظمة الموزعة) وأساسيات التعلم الآلي (التحيز، التجاوز، مقاييس التقييم). يساهم العمل الثنائي بين مختلف التخصصات في تسريع نقل المعرفة.
الطريق إلى الأمام: مسارات الذكاء الاصطناعي في عام 2026 وما بعده
أصبحت الأطر التصريحية ضرورة أساسية. وستواجه الفرق التي لا تزال تكتب نصوص سبارك الإجرائية صعوبة في المنافسة من حيث سرعة التنفيذ.
ستُسهّل أدوات هندسة الميزات الآلية ما يتطلب اليوم خبرة عميقة في المجال. ستقترح النماذج ميزات مرشحة؛ وسيقوم المهندسون بمراجعتها واعتمادها.
ستتحول الحوكمة وقابلية التفسير من اعتبارات ثانوية إلى متطلبات أساسية. فالضغوط التنظيمية - قانون الذكاء الاصطناعي في الاتحاد الأوروبي، وقوانين الخصوصية على مستوى الولايات - تجبر المؤسسات على إثبات أن النماذج عادلة وشفافة وقابلة للتدقيق. وستتكيف الأنظمة التي تُدمج الحوكمة منذ مرحلة الإدخال فصاعدًا بشكل أسرع من تلك التي تُعدّل الامتثال لاحقًا.
سيتسارع نشر الحوسبة الطرفية. فمع تقلص حجم النماذج (التكميم، والتقطير) وتحسن أجهزة الحوسبة الطرفية، يقترب الاستدلال من مصادر البيانات. وستحتاج خطوط المعالجة إلى تنسيق التدريب في السحابة والنشر إلى آلاف نقاط النهاية الموزعة.
لكن المبدأ الأساسي يبقى قائماً: لا يكون الذكاء الاصطناعي فعالاً إلا بقدر جودة البيانات التي يغذيها. إن أنظمة معالجة البيانات التي تُؤتمت عمليات الاستيعاب والتحويل والتحقق من الجودة تُتيح للفرق التركيز على ما لا تستطيع الآلات فعله، ألا وهو طرح أسئلة أفضل.
الأسئلة الشائعة
ما هي سلسلة بيانات الذكاء الاصطناعي؟
تُعدّ مسارات بيانات الذكاء الاصطناعي سير عمل مؤتمتًا يستقبل البيانات الخام من مصادر متعددة، ويحوّلها إلى تنسيقات منظمة ونظيفة، ويُصمّم خصائص نماذج التعلّم الآلي، ويُدرّب هذه النماذج ويُدقّقها، وينشرها للاستدلال، ويُراقب الأداء باستمرار. وعلى عكس عمليات استخراج البيانات وتحويلها وتحميلها التقليدية، تتكرر مسارات الذكاء الاصطناعي من خلال حلقات التغذية الراجعة، حيث تُعيد تدريب النماذج مع تغير البيانات وتُكيّف المخططات تلقائيًا باستخدام التعلّم الآلي المُدمج.
كيف تختلف مسارات بيانات الذكاء الاصطناعي عن عمليات استخراج البيانات وتحويلها وتحميلها التقليدية؟
تتبع عمليات ETL التقليدية تسلسلًا خطيًا للاستخراج والتحويل والتحميل لأغراض إعداد التقارير وتحليل بيانات الأعمال. أما خطوط أنابيب بيانات الذكاء الاصطناعي، فتعمل في حلقات متواصلة، وتتعامل مع البيانات المهيكلة وغير المهيكلة (نصوص، صور، سجلات)، مستخدمةً التعلم الآلي لرسم خرائط تلقائية للمخططات، وتغذية رؤى المراقبة إلى المصدر لتحفيز إعادة التدريب. وهي تعطي الأولوية لتدريب النموذج ومخرجات الاستدلال على حساب لوحات المعلومات الثابتة.
ما هي التحسينات التي يمكن أن توفرها خطوط أنابيب الذكاء الاصطناعي في الأداء؟
تُظهر معايير الإنتاج أن خطوط المعالجة المُحسّنة بالذكاء الاصطناعي تحقق استخدامًا لوحدة معالجة الرسومات يصل إلى 60% (مقارنةً بالخط الأساسي الذي يتراوح بين 10 و15%)، وتُحقق تسريعًا إجماليًا بمقدار 6 أضعاف، وتُقلل وقت التدريب من 22 ساعة إلى 3 ساعات، وتُخفض تكاليف الحوسبة بمقدار 80%. وتُظهر الأطر التصريحية مكاسب في كفاءة التطوير تصل إلى 50%، وتحسينات في قابلية التوسع بمقدار 500 ضعف، وزيادة في الإنتاجية بمقدار 10 أضعاف مقارنةً بالتنفيذات الإجرائية.
ما هي الأدوات الشائعة الاستخدام في خطوط نقل بيانات الذكاء الاصطناعي؟
تشمل الأدوات مفتوحة المصدر الشائعة Apache Spark (للمعالجة الموزعة)، وApache Airflow وPrefect (للتنسيق)، وMLFlow (لتتبع التجارب)، وDVC (لإدارة إصدارات البيانات). أما المنصات الاحتكارية مثل Databricks وSnowflake وخدمات استخراج البيانات وتحويلها وتحميلها (ETL) المتخصصة في الذكاء الاصطناعي، فتُوفر بيئات مُدارة مزودة بموصلات مدمجة، وأنظمة حوكمة، وأنظمة مراقبة. ويعتمد اختيار الأداة على خبرة الفريق، وحجم العمل، ومدى تحمله للتكاليف التشغيلية الإضافية.
ما هي أكبر التحديات في بناء خطوط نقل بيانات الذكاء الاصطناعي؟
تشمل العقبات الشائعة تدهور جودة البيانات (نتيجةً للتغييرات في المصدر التي تُدخل قيمًا فارغة أو مكررة)، وتجزئة البنية التحتية (حيث تُخزَّن البيانات في أنظمة غير متوافقة)، وانحراف المخطط (نتيجةً لتغييرات واجهة برمجة التطبيقات التي تُعطِّل مسارات البيانات)، وانهيار قابلية الصيانة مع ازدياد حجم التعليمات البرمجية الإجرائية. وتشمل الحلول إجراء فحوصات جودة مستمرة، ومنصات استيعاب موحدة، وتطوير المخططات باستخدام التعلم الآلي، واعتماد أطر عمل تصريحية تفصل المنطق عن التنفيذ.
ما مدى أهمية الحوكمة في مسارات بيانات الذكاء الاصطناعي؟
تُعدّ الحوكمة أساسية للامتثال التنظيمي، وسجلات التدقيق، والثقة. يسجل نظام تتبع مسار البيانات من البداية إلى النهاية كل عملية تحويل من المصدر إلى التنبؤ، مما يُمكّن الفرق من تتبع الأخطاء والجهات التنظيمية من التحقق من العدالة. كما تمنع أنظمة التحكم في الوصول، والصلاحيات القائمة على الأدوار، وسجلات التدقيق الآلية، الكشف غير المصرح به عن البيانات. وتتكيف المؤسسات التي تُدمج الحوكمة في عملياتها منذ البداية بشكل أسرع مع قوانين الخصوصية ولوائح الذكاء الاصطناعي المتطورة.
هل تستطيع سلاسل معالجة الذكاء الاصطناعي التعامل مع البيانات غير المهيكلة؟
نعم، تُعدّ معالجة البيانات غير المهيكلة (المستندات، الصور، الملفات الصوتية، النصوص الحرة) إحدى أهم مزاياها مقارنةً بعمليات استخراج البيانات وتحويلها وتحميلها التقليدية. تستخدم مسارات الذكاء الاصطناعي نماذج معالجة اللغة الطبيعية لاستخراج الكيانات من النصوص، ونماذج رؤية الحاسوب لتصنيف الصور، والتضمينات لتحويل المدخلات غير المهيكلة إلى ميزات رقمية يمكن للنماذج استخدامها. تتيح هذه الإمكانية الوصول إلى غالبية بيانات المؤسسات التي تتجاهلها الأدوات التقليدية.
الخلاصة: بناء مسارات تعلم
تتصدر نماذج الذكاء الاصطناعي عناوين الأخبار، لكنّ البنية التحتية هي التي تحدد ما إذا كانت هذه النماذج ستصل إلى مرحلة الإنتاج أم لا.
لا تقتصر المؤسسات الفائزة في عام 2026 بالضرورة على تلك التي تمتلك أكبر فرق علوم البيانات، بل تشمل تلك التي قامت بأتمتة العمليات الأساسية - من استيعاب البيانات وتحويلها ومراقبتها - مما يتيح للمهندسين قضاء وقتهم في حل مشكلات الأعمال بدلاً من تصحيح أخطاء برامج ETL.
ابدأ بحالة استخدام واحدة ذات تأثير كبير. أثبت قيمة رسم خرائط المخططات الآلي، وفحوصات الجودة في الوقت الفعلي، وإعادة التدريب المستمر. ثم قم بتوسيع نطاق هذه الأنماط لتشمل جميع الفرق.
لا تكمن الميزة التنافسية في بنية النموذج، بل في بنية خط الأنابيب التي تُبقي النماذج مُغذّاة وحديثة وموثوقة. بتأسيس هذه البنية، يتوقف الذكاء الاصطناعي عن كونه مشروعًا علميًا ويبدأ في أن يصبح محركًا للأعمال.