Mira, lo entiendo. Has visto que OpenClaw es tendencia en todas partes y te intriga la idea de un asistente de IA disponible las 24 horas, los 7 días de la semana, que realmente pueda hacer cosas en tu computadora. Pero luego ves a la gente hablando de gastar cientos de dólares en créditos de API, y de repente esa emoción se convierte en ansiedad por los costos.
La cuestión es que OpenClaw tiene licencia MIT y es completamente de código abierto. Según el repositorio oficial de openclaw/openclaw en GitHub, con más de 100 000 estrellas, este asistente de IA puede ejecutarse en “cualquier sistema operativo. Cualquier plataforma”. Y sí, eso incluye ejecutarlo sin gastar un céntimo.
La verdadera pregunta no es si se puede ejecutar OpenClaw gratis. Es cómo configurarlo para evitar esas facturas de API exorbitantes de las que todos se quejan en las discusiones de la comunidad.
Entendiendo el problema del costo
Antes de abordar las soluciones, analicemos por qué la gente invierte dinero. OpenClaw es básicamente un agente de IA que se conecta a plataformas de mensajería como Slack, WhatsApp o Telegram y ejecuta tareas en tu nombre. Pero aquí está el truco: necesita un modelo de lenguaje para alimentar su cerebro.
La mayoría de los tutoriales te recomiendan Claude, GPT-4 u otras API comerciales. Y no son baratas. Un usuario, en una discusión de GitHub de febrero de 2026, preguntó sobre el "Mejor LLM asequible del momento", destacando que este es un problema importante para la comunidad de OpenClaw.
Pero tienes tres caminos legítimos para una operación con costo cero:
- Ejecución de modelos completamente locales en su propio hardware
- Uso de recursos gratuitos de GPU en la nube
- Aprovechar estratégicamente los niveles de API gratuitos
Analicemos cada enfoque.
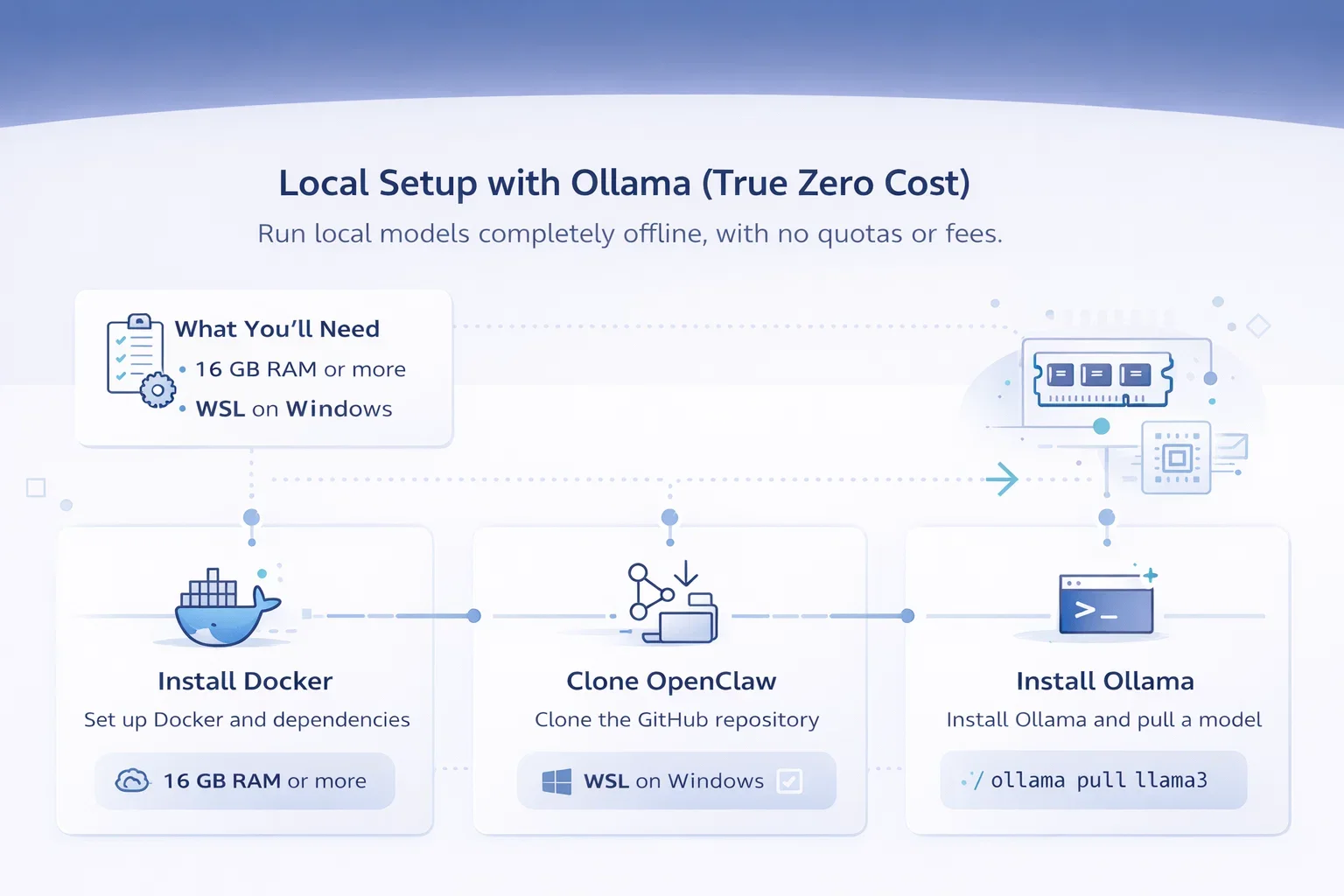
Método 1: Configuración local con Ollama (costo cero real)
Este es mi favorito porque, una vez configurado, eres completamente independiente. Sin cuotas, sin límites de velocidad, sin facturas sorpresa. Según la guía de digitalknk "Cómo ejecutar OpenClaw sin gastar dinero, cuotas ni perder la cordura", que recibió 92 estrellas en GitHub, los modelos locales son la solución más sostenible a largo plazo.
Lo que necesitarás
Hablando en serio: No necesitas una plataforma de juegos con varias GPU. Una computadora decente con 16 GB de RAM puede manejar modelos más pequeños sin problemas. Un usuario de Reddit mencionó que ejecutó OpenClaw correctamente en una Intel NUC con 16 GB, aunque tuvo algunos problemas de configuración iniciales.
Los usuarios de Windows necesitarán WSL (Subsistema de Windows para Linux). Los usuarios de Mac y Linux pueden omitir este paso.
Instalación paso a paso
Instalar Docker y dependencias
OpenClaw se ejecuta en contenedores Docker para garantizar la coherencia entre plataformas. Si usas Windows, instala Docker Desktop y habilita la integración con WSL2. La aplicación basada en Flutter de Mithun_Gowda_B te permite ejecutar OpenClaw AI Gateway directamente en tu teléfono, sin root y con una configuración de un solo toque.
Clonar OpenClaw
Dirígete al repositorio oficial de openclaw/openclaw en GitHub y clónalo en tu equipo local. El proceso de instalación es sencillo, pero como señaló un usuario de Reddit: “No es tan fácil, jaja. Al instalar en un VPS, el problema es localhost y tienes que vincular la IP”.”
Tenga esto en cuenta si está planeando acceso remoto.
Instalar Ollama
Ollama es tu gestor de modelos local. Descárgalo de ollama.ai e instálalo según tu sistema operativo. Luego, extrae un modelo compatible con tu hardware:
- Para 8 GB de RAM: prueba llama3.2 o mistral
- Para 16 GB de RAM: Llama3 8B funciona muy bien
- Para 32 GB+ de RAM: puedes ejecutar llama3 70B o mixtral
El comando se ve así: ollama tira llama3
Configurar la conexión OpenClaw
Ahora necesitas apuntar OpenClaw a tu instancia local de Ollama en lugar de a una API en la nube. Edita tu archivo de configuración de OpenClaw para usar el punto final local (normalmente http://localhost:11434 para Ollama).
Aquí es donde la mayoría de los principiantes tropiezan. Como se mencionó en una discusión de GitHub, la correcta vinculación al host local es importante si se ejecuta en un VPS o se desea acceso remoto.
Expectativas de desempeño
Mira, los modelos locales no igualan el razonamiento de GPT-4 ni las habilidades de programación de Claude. Pero son sorprendentemente eficaces para las tareas cotidianas. Y esto es lo importante: puedes ejecutarlos 24/7 sin preocuparte por el número de tokens ni los límites de velocidad.
Un miembro de la comunidad compartió: “He estado usando una configuración que me cuesta literalmente $0 al mes, permanece activa las 24 horas, los 7 días de la semana y tiene tokens prácticamente ilimitados”.”
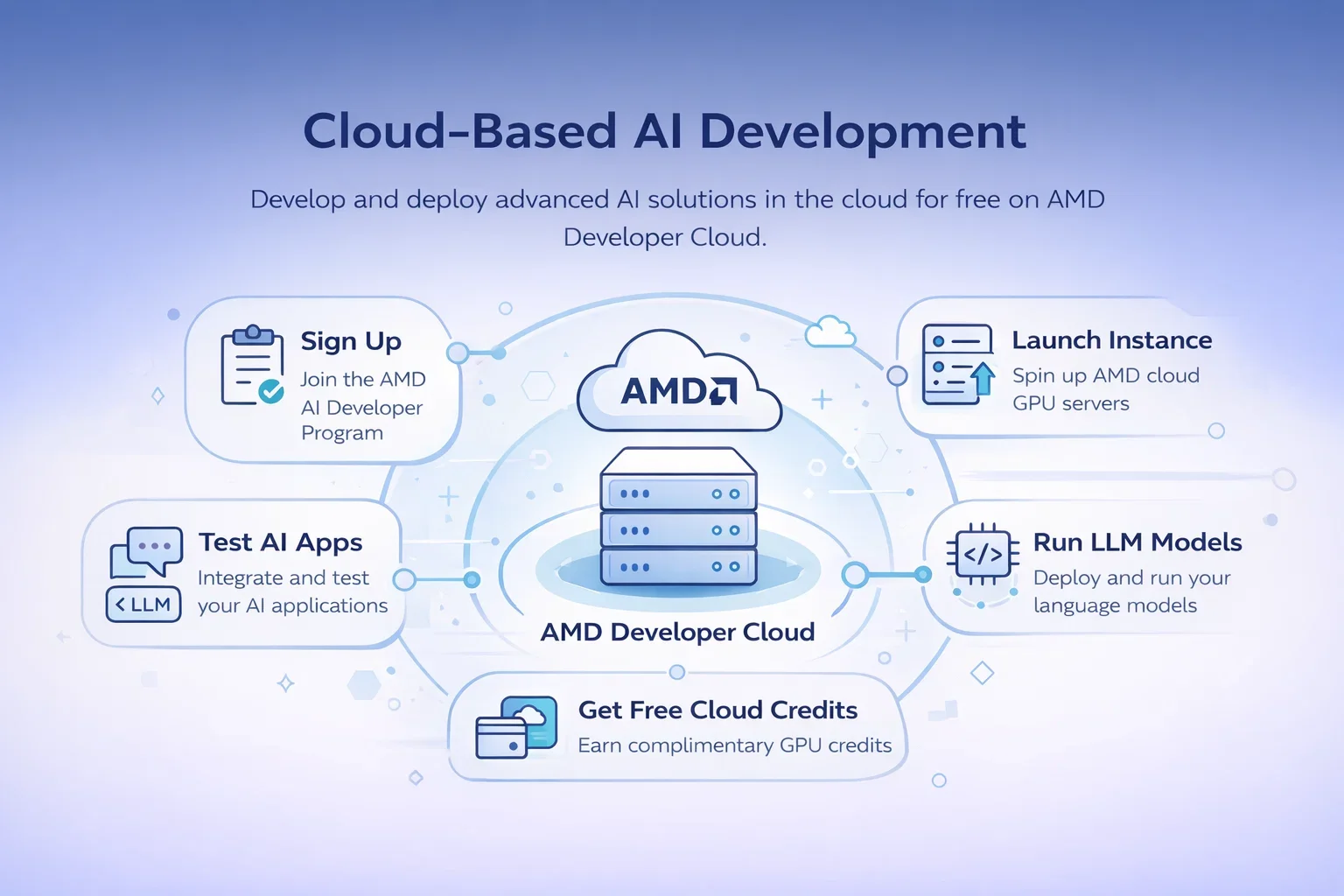
Método 2: AMD Developer Cloud (la mejor opción gratuita en la nube)
Aquí es donde la cosa se pone interesante. Según varias guías de GitHub sobre "OpenClaw con vLLM funcionando gratis en AMD Developer Cloud", puedes acceder a hardware empresarial sin coste a través del Programa para Desarrolladores de IA de AMD.
Hablamos de GPU AMD Instinct MI300X con 192 GB de memoria. Suficiente para ejecutar modelos que normalmente requerirían miles de dólares en GPU de consumo.
Cómo obtener acceso a AMD Developer Cloud
Inscríbete en el Programa para Desarrolladores de IA de AMD. Ofrecen créditos gratuitos en la nube específicamente para desarrolladores que prueban cargas de trabajo de IA. Una guía de febrero de 2026 muestra cómo implementar OpenClaw en esta infraestructura sin costo alguno.“
Pero espera, hay una trampa. Estos son créditos promocionales, no una versión gratuita permanente. Sin embargo, si solo estás probando OpenClaw o usándolo para proyectos personales, los créditos deberían durar bastante tiempo.
Ejecución de vLLM en AMD Cloud
vLLM es un servidor de inferencia optimizado que permite ejecutar modelos de lenguaje grandes de forma eficiente. El proceso de configuración implica:
- Ponga en marcha una instancia de nube de AMD
- Instale vLLM y el modelo elegido
- Configurar OpenClaw para que apunte a su punto final vLLM
- Conecta tus plataformas de mensajería
Según el repositorio secure-openclaw de ComposioHQ (1.5k estrellas), puedes integrar OpenClaw con WhatsApp, Telegram, Signal o iMessage para una experiencia completa de asistente personal.
Método 3: Estrategia de GitHub Codespaces
GitHub ofrece horas de computación gratuitas a través de Codespaces: 60 horas al mes en su versión gratuita. Una guía de configuración creativa mencionaba "implementar OpenClaw en menos de 5 minutos en la versión gratuita de AWS", pero GitHub Codespaces ofrece una alternativa más sencilla.
Ahora bien, 60 horas no son un tiempo de actividad 24/7. Pero si usas tu asistente de IA principalmente durante el trabajo, este tiempo se extiende sorprendentemente. Apágalo mientras duermes o los fines de semana y tendrás una solución gratuita y eficaz.
El enfoque híbrido
Esto es lo que hacen algunos usuarios experimentados: ejecutan tareas livianas localmente con Ollama, pero para tareas complejas de codificación o razonamiento, hacen que OpenClaw llame a una API de nivel gratuito.
OpenRouter, mencionado en conversaciones de Reddit, ofrece créditos gratuitos que se reinician mensualmente. Un usuario comentó: “OpenRouter cuesta más de 10 € por 1000 solicitudes al día en las plantillas gratuitas”. Esos 10 € son créditos, no cargos; úsalos con inteligencia y no tendrás ningún coste.
Consideraciones de seguridad que no puedes ignorar
En serio: OpenClaw tiene acceso total al ordenador. Es potente, pero también potencialmente peligroso si se configura incorrectamente.
Un hilo de Reddit muy activo se centró específicamente en la “Guía de refuerzo de la seguridad” y advirtió: “Dado que veo que muchas personas nuevas están instalando Clawdbot, recomiendo encarecidamente vacunarlo contra ataques de inyección rápida”.”
Existen scripts de detección (como knostic/openclaw-detect con 56 estrellas) específicamente para la "implementación de MDM para identificar instalaciones de OpenClaw en dispositivos administrados". Esto indica que las organizaciones están preocupadas por las implicaciones de seguridad.
Pasos de seguridad esenciales
| Medida de seguridad | Por qué es importante | Cómo implementar |
| Gestión de claves | OpenClaw necesita claves API y credenciales | Utilice 1Password o similar con bóveda dedicada |
| Enlace de red | Evita el acceso externo a su instancia | Vincular solo al host local a menos que se configure una VPN |
| Reglas del firewall | Limita el acceso a OpenClaw | Utilice ufw o Tailscale para acceso remoto seguro |
| Protección contra inyección rápida | Previene comandos maliciosos de fuentes externas | Configurar la validación de entrada y las restricciones de comandos |
Como compartió un usuario preocupado por la seguridad: “Utilizo 1Password para administrar mis claves, la única clave que tiene OpenClaw es la que permite acceder a 1Password a través de una bóveda dedicada y una cuenta de servicio”.”
Eso es arquitectura inteligente.
Problemas de configuración comunes y soluciones
Según las discusiones de la comunidad y la compilación de recursos awesome-openclaw (221 estrellas en GitHub), estos son los problemas que dificultan el trabajo a los principiantes:
“Se instaló pero no ejecuta nada”
Un usuario frustrado de Reddit comentó: “He intentado instalar Clawdbot cinco veces en mi Intel NUC de 16 GB con Ubuntu y no ha funcionado ni una sola vez. Puedo hablar con él, pero no puede compilar nada”.”
Esto suele indicar problemas de permisos o que el modelo no está conectado correctamente. Revise su archivo de configuración y asegúrese de que OpenClaw pueda acceder a su punto final LLM.
Confusión sobre la ubicación de los archivos WSL
Los usuarios de Windows a menudo no encuentran sus archivos de OpenClaw. Como comentó un usuario útil: “Los archivos de devices/pending.json se encontraron en \\wsl$\Ubuntu\home\user\.openclaw\devices; en mi caso, están en el subsistema de Linux”.”
La confusión de “gratis”
Muchas guías gratuitas aún requieren servicios de pago. Un usuario escéptico comentó: "Entonces... ¿Un bot que cuesta $0...? ¿Siempre y cuando tengas suscripciones a Google AI Pro y GitHub Copilot? ¿Cómo es eso de $0?"“
Buen punto. Un coste cero significa que no hay suscripciones, solo modelos locales o créditos de nube realmente gratuitos.
Comparación de plataformas: qué funciona realmente
| Plataforma | Nivel gratuito real | Tiempo de actividad mensual | Actuación | Mejor para |
| Ollama local | Sí (solo costo del hardware) | 24/7 | Bueno para las tareas diarias | Usuarios preocupados por la privacidad |
| Nube para desarrolladores de AMD | Créditos (tiempo limitado) | 24/7 hasta agotar créditos | Excelente para modelos grandes. | Pruebas y desarrollo |
| Espacios de código de GitHub | 60 horas/mes | Tiempo parcial | Depende de la elección del modelo. | Uso de horas de trabajo |
| Nivel gratuito de OpenRouter | Reinicio de créditos mensuales | Hasta agotar los créditos | Varía según el modelo | Enfoques híbridos |
Casos de uso reales que no cuestan un ojo de la cara
Según las discusiones en el repositorio openclaw-blog, la gente está usando configuraciones gratuitas de OpenClaw para:
- Automatización de la revisión de código: haga que revise sus confirmaciones antes de enviarlas
- Resumen de mensajes: resúmenes de canales de Slack o hilos de correo electrónico
- Recordatorios programados: La bifurcación secure-openclaw menciona específicamente esta función
- Asistencia en la investigación: recopilar información y crear resúmenes
- Automatización de tareas: organización de archivos, procesamiento de datos, generación de informes
La clave está en elegir tareas que se ajusten a las capacidades de tu modelo. No esperes que un modelo 7B local escriba código de calidad de producción, pero sin duda puede ayudar con la generación de código repetitivo o la documentación.
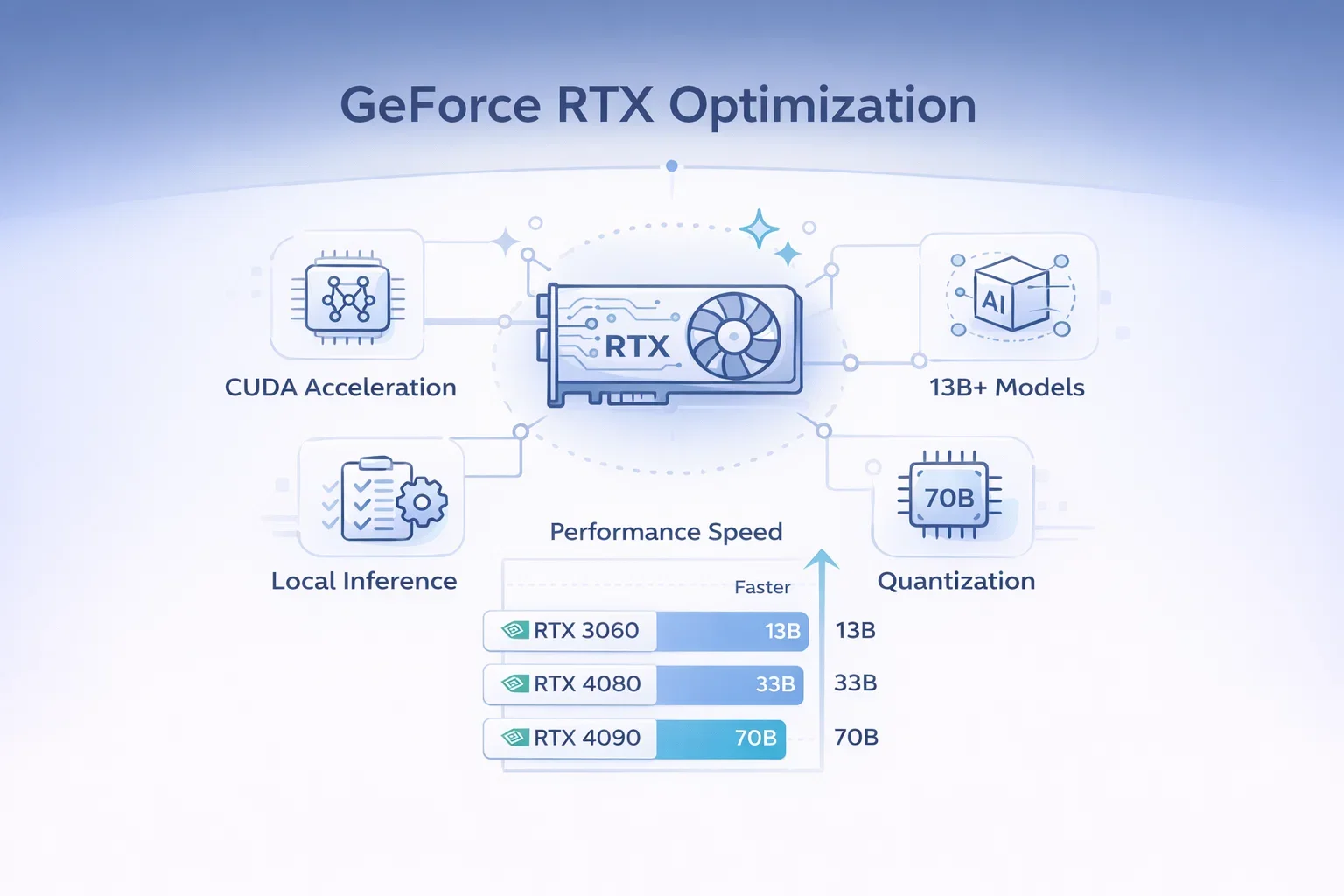
Optimización de GeForce RTX
Una guía popular explica cómo ejecutar OpenClaw gratis en GeForce RTX con optimización de inferencia local. Si tienes una GPU NVIDIA, puedes aprovechar la aceleración CUDA para una inferencia local mucho más rápida.
Se recomienda RTX 3060 o superior para un rendimiento óptimo con modelos 13B. RTX 4090 admite modelos 70B con cuantificación.
[IMAGEN: Cuadro comparativo de rendimiento que muestra las velocidades de inferencia en diferentes GPU]
Proyectos alternativos que vale la pena considerar
El ecosistema OpenClaw ha generado varias alternativas. Según el documento "moltbot-vs-openclaw-complete-comparison", Moltbot es esencialmente una bifurcación con un nombre diferente y una marca diferente. ClawdBot era el nombre original antes de cambiar a OpenClaw.
secure-openclaw de ComposioHQ (258 bifurcaciones, 1.5k estrellas) se centra específicamente en la integración de la plataforma de mensajería con “memoria persistente, recordatorios programados e integraciones con más de 500 aplicaciones”.”
Para configuraciones de presupuesto ultra bajo, un hilo de Reddit titulado “Cómo ejecutar OpenClaw/ClawdBot/MoltBot con un presupuesto limitado (o gratis)” recopila varios enfoques de bajo costo que han funcionado para los miembros de la comunidad.
Reflexiones finales: ¿Realmente vale la pena el coste cero?
Esta es mi opinión honesta después de revisar docenas de guías de configuración y debates de la comunidad: Sí, puedes ejecutar OpenClaw de forma totalmente gratuita en 2026. Pero existe un equilibrio entre el costo y la conveniencia.
Los modelos locales con Ollama te ofrecen total independencia y cero costos mensuales, pero sacrificas algo de rendimiento en comparación con los modelos fronterizos. Los créditos de AMD Developer Cloud ofrecen un excelente rendimiento mientras duran, pero no son una solución permanente. Los niveles de API gratuitos funcionan hasta que se superan las cuotas.
¿El punto ideal? Empieza con Ollama local para las tareas rutinarias y luego usa estratégicamente los recursos gratuitos en la nube para cargas de trabajo exigentes. Como señaló un usuario experimentado en una guía detallada de Reddit: “La clave está en aprovechar los niveles gratuitos y luego gestionarlos”.”
Y mira, incluso si finalmente decides pagar por el acceso a la API, comprender estos métodos gratuitos te permitirá usar esos recursos de pago de forma más eficiente. Sabrás exactamente cuándo necesitas la potencia de la nube y cuándo la local es suficiente.
El repositorio openclaw/openclaw continúa su desarrollo activo con su comunidad de más de 200 000 estrellas. Se publican regularmente más guías de optimización, mejoras de seguridad y herramientas de instalación. Para cuando lea esto, la configuración podría ser aún más sencilla.
¿Listo para crear tu propio asistente de IA 24/7 sin cuotas mensuales? Empieza con la configuración local de Ollama, experimenta con lo que funciona para tu hardware y únete a los recursos de la comunidad awesome-openclaw para aprender de otros que hacen lo mismo.
Tu agente de IA personal te está esperando y no te costará ni un centavo.
Preguntas frecuentes
¿OpenClaw es realmente completamente gratuito?
Sí, el software tiene licencia MIT y es gratuito. Sin embargo, para ejecutarlo se requiere hardware propio (configuración local) o recursos en la nube. Puedes usar opciones totalmente gratuitas como Ollama localmente, créditos AMD Developer Cloud o el plan gratuito de GitHub Codespaces para evitar costos mensuales.
¿Puedo ejecutar OpenClaw en una Raspberry Pi?
Técnicamente sí, como se comenta en las guías de la comunidad sobre "OpenClaw en Raspberry Pi: Creación de un sistema de automatización de IA local con LM Studio". Sin embargo, el rendimiento será limitado. Una Raspberry Pi 4 con 8 GB de RAM puede ejecutar modelos muy pequeños, pero se esperan tiempos de respuesta lentos. Es más un proyecto de aficionado que una solución práctica.
¿Cuál es el requisito mínimo de hardware para la configuración local?
Para una funcionalidad básica, 8 GB de RAM y una CPU moderna. Para un uso cómodo, 16 GB de RAM como mínimo. Si tienes una GPU con más de 8 GB de VRAM, obtendrás un rendimiento significativamente mejor. Muchos usuarios ejecutan OpenClaw con éxito en Intel NUC o Mac Mini.
¿Cómo puedo evitar riesgos de seguridad?
Según las discusiones de seguridad en la comunidad de OpenClaw, los pasos clave incluyen: usar bóvedas de credenciales dedicadas (como 1Password), vincular a localhost a menos que se use una VPN, implementar reglas de firewall y reforzar la seguridad contra ataques de inyección inmediata. Nunca permita que OpenClaw acceda directamente a credenciales confidenciales.
¿Por qué algunas guías mencionan servicios pagos si OpenClaw es gratuito?
OpenClaw es gratuito, pero necesita un modelo de lenguaje para funcionar. Muchos tutoriales utilizan API comerciales como Claude o GPT-4 por su facilidad de configuración. Sin embargo, puedes usar modelos locales o recursos en la nube gratuitos; solo requiere una configuración más compleja.
¿Cuál es la diferencia entre ClawdBot, Moltbot y OpenClaw?
Son esencialmente el mismo proyecto con nombres diferentes. ClawdBot era el nombre original, que luego se convirtió en Moltbot y ahora se llama OpenClaw. La funcionalidad principal sigue siendo la misma: es un agente de IA con acceso total a la computadora que se ejecuta en tu propia infraestructura.
¿Puedo utilizar OpenClaw con fines comerciales de forma gratuita?
La licencia MIT permite el uso comercial del software OpenClaw. Sin embargo, verifique la licencia del modelo de lenguaje que esté utilizando. La mayoría de los modelos de código abierto permiten el uso comercial, pero algunos (como Llama) tienen restricciones basadas en el número de usuarios. Verifique siempre la licencia del modelo específico.