Resumen rápido: El ajuste fino de un modelo LLM suele costar entre $5 y $10 000, dependiendo del tamaño del modelo, la técnica y la infraestructura. Los modelos más pequeños (de 2 a 8 mil millones de parámetros) con métodos eficientes en parámetros, como LoRA, se pueden ajustar por menos de $10 en GPU en la nube, mientras que el ajuste fino completo de modelos más grandes en infraestructura premium puede superar los $10 000. Comprender los factores que influyen en el costo (recursos computacionales, volumen de datos de entrenamiento, arquitectura del modelo y elección de la técnica) ayuda a los equipos a presupuestar de manera efectiva.
El coste de ajustar modelos de lenguaje complejos suele sorprender a la mayoría de los equipos. Entrenar desde cero puede costar millones (según se informa, el Gemini Ultra de Google alcanzó los 191 millones de TP4T, mientras que el GPT-4 llegó a los 78 millones de TP4T), pero ajustar modelos existentes es una historia completamente diferente.
Sin embargo, hay un detalle importante: los costos de optimización varían enormemente. Un equipo de investigación de Stanford optimizó Qwen3-8B-Base por menos de 1 TP4T5 utilizando adaptadores LoRA en el servicio gestionado de Together AI. Mientras tanto, las tareas completas de optimización en infraestructura empresarial suelen costar entre 1 TP4T3000 y 1 TP4T10 000.
Entender a dónde va tu dinero es más importante que el precio de venta.
¿Qué factores influyen en los costes de ajuste fino?
Cuatro factores principales determinan el coste real del ajuste fino.
Infraestructura informática
La elección de la GPU genera la mayor variación de costes. Los proveedores de servicios en la nube cobran por hora, y las tarifas difieren drásticamente según la clase de hardware.
Una NVIDIA A10G, considerada de gama media según los estándares actuales, cuesta aproximadamente entre $1,50 y $2,50 por hora en las principales plataformas en la nube. El proceso de optimización que costó menos de $10 mencionado anteriormente se ejecutó durante cuatro horas en una sola A10G.
Pero aumentar la escalabilidad se vuelve costoso rápidamente. Las GPU de gama alta como las A100 o H100 consumen entre $4 y $8 por hora en AWS o Google Cloud. Las configuraciones multi-GPU para modelos más grandes multiplican estos costos linealmente.
El autoalojamiento presenta un cálculo diferente. Una RTX 4090 cuesta aproximadamente 1600 THB por adelantado, pero elimina los cargos recurrentes por hora. Según las discusiones en LinkedIn, una GPU se amortiza en semanas en comparación con las suscripciones mensuales a nodos de GPU en la nube (que cuestan 2500 THB), siempre que la utilización se mantenga alta de forma constante.
Tamaño y arquitectura del modelo
El número de parámetros influye directamente en los requisitos de memoria y en la duración del entrenamiento.
| Tamaño del modelo | VRAM (Ajuste fino completo) | VRAM (LoRa de 4 bits) | Rango de costos típico |
|---|---|---|---|
| Parámetros 2-3B | 6-8 GB | 2-3 GB | $300-$700 |
| Parámetros 7-8B | 14-16 GB | 6-8 GB | $1,000-$3,000 (LoRA) Hasta $12,000 (completo) |
| Parámetros 12-13B | 24-28 GB | 10-12 GB | $5,000-$15,000 |
El modelo Phi-2 (2.700 millones de parámetros) con LoRA suele costar entre $300 y $700. Los modelos Mistral 7B se sitúan entre $1.000 y $3.000 utilizando LoRA, pero un ajuste fino completo puede elevar los costes hasta $12.000.
Los requisitos de memoria explican el porqué. El ajuste fino completo almacena gradientes para cada parámetro. Un modelo de 7 bits necesita aproximadamente 28 GB de VRAM solo para cargar pesos con una precisión de 16 bits, sin contar los gradientes, los estados del optimizador y la memoria de activación durante el entrenamiento.
Selección de técnicas de entrenamiento
El método elegido para el ajuste fino modifica drásticamente tanto el coste como los requisitos de recursos.
- Ajuste fino completo Actualiza todos los parámetros del modelo. Este enfoque ofrece máximo control y personalización, pero requiere una cantidad considerable de VRAM. El uso de memoria aumenta linealmente con el tamaño del modelo, lo que hace que el ajuste fino completo de modelos con más de 13 mil millones de parámetros sea poco práctico sin configuraciones multi-GPU.
- Ajuste fino con parámetros eficientes (PEFT) Las técnicas actualizan solo un pequeño subconjunto de pesos. LoRA (Adaptación de Bajo Rango) inserta módulos adaptadores entrenables entre las capas del transformador, manteniendo congelado el modelo base. Según una investigación de arXiv sobre métodos eficientes en el uso de recursos, LoRA reduce sustancialmente la memoria de entrenamiento, manteniendo una precisión comparable a la del ajuste fino completo.
¿Impacto en el mundo real? Investigadores de Stanford lograron una precisión de 0,78 al optimizar Qwen3-8B con LoRA (rango=32) frente a una precisión de 0,41 en el modelo base, con un coste computacional inferior a $5. Esta mejora en el rendimiento con un coste mínimo demuestra por qué las técnicas PEFT dominan las aplicaciones prácticas.
- Cuantización Reduce aún más los costos. El entrenamiento con cuantización de 4 bits mediante bitsandbytes redujo el consumo de memoria de FLUX.1-dev LoRA de aproximadamente 60 GB a unos 37 GB, según la documentación de Hugging Face. La degradación de la calidad fue mínima.

Tamaño del conjunto de datos y duración del entrenamiento
Más datos de entrenamiento no siempre significan mejores resultados, pero sin duda implican mayores costes.
El número de tokens determina el tiempo de procesamiento. La API de ajuste fino de OpenAI, que factura en función de los tokens de entrenamiento en lugar del tiempo real, deja clara esta relación. En los debates de la comunidad se menciona que el seguimiento de los costes requiere monitorizar los tokens entrenados, ya que la facturación se ha alejado de las métricas principales de tiempo de entrenamiento.
La calidad de los datos es más importante que la cantidad. Los equipos suelen obtener mejores resultados con 500 ejemplos cuidadosamente seleccionados que con 5000 muestras ruidosas. La mala calidad de los datos prolonga el tiempo de entrenamiento, ya que el modelo tiene dificultades para encontrar patrones consistentes, lo que aumenta los costos sin mejorar los resultados.

Implementar soluciones LLM personalizadas con IA superior
Para perfeccionar un modelo de lenguaje extenso, se requiere el conjunto de datos, la infraestructura de entrenamiento y el proceso de evaluación adecuados. En muchos casos, también se pueden considerar la adaptación personalizada del modelo o los sistemas basados en la recuperación de información.
IA superior Desarrolla soluciones LLM personalizadas para empresas que requieren capacidades de IA específicas de su sector.
Su experiencia incluye:
- Preparación y anotación de conjuntos de datos
- ajuste fino y evaluación del modelo
- Arquitecturas RAG e híbridas
- Implementación en producción de sistemas LLM
Si necesita una solución LLM personalizada adaptada a sus datos y flujos de trabajo, IA superior puede respaldar el proceso de desarrollo.
Costos ocultos que se acumulan
La factura de tu proveedor de servicios en la nube no cuenta toda la historia.
Mano de obra para la preparación de datos
La limpieza, el formato y la validación de los datos de entrenamiento consumen una cantidad considerable de tiempo de ingeniería. Las inconsistencias en los conjuntos de datos limitan directamente el rendimiento del modelo; una investigación sobre el ajuste fino para la reparación automatizada de programas (arXiv:2507.19909) señala que las tasas de concordancia de las anotaciones humanas limitan la precisión alcanzable.
Si los anotadores solo coinciden en el 701% de los casos, el modelo no puede superar de forma fiable una precisión del 701%, independientemente de la inversión en entrenamiento.
Costos de experimentación
El ajuste fino rara vez tiene éxito en el primer intento. El ajuste de hiperparámetros (tasa de aprendizaje, tamaño del lote, número de épocas) requiere múltiples ejecuciones de entrenamiento.
Presupuesto para un mínimo de 3 a 5 iteraciones. Cada prueba experimental cuesta lo mismo que la capacitación en producción.
Validación y evaluación
En los métodos de ajuste fino por refuerzo, la validación durante el entrenamiento genera costes adicionales. La guía de OpenAI sobre la facturación de RFT menciona explícitamente la frecuencia de validación como un factor determinante del coste: una validación más frecuente implica facturas más altas.
La selección del modelo de evaluador también es importante. Utilizar un modelo más grande para evaluar los puntos de control del entrenamiento cuesta más por ciclo de validación que utilizar evaluadores más pequeños y rápidos.
Almacenamiento e implementación
Los puntos de control del modelo consumen almacenamiento. Un modelo de 7 mil millones de parámetros con una precisión de 16 bits requiere aproximadamente 14 GB de espacio en disco por punto de control. Guardar puntos de control en cada época a lo largo de varios experimentos supone un coste adicional.
La infraestructura de despliegue representa un coste continuo. El autoalojamiento requiere el mantenimiento de nodos GPU las 24 horas del día, los 7 días de la semana. El despliegue basado en API traslada los costes a un modelo de precios de inferencia por token.
Análisis de costos entre la nube y el alojamiento propio
La decisión de construir o comprar depende de los patrones de utilización y de la escala.
Precios de proveedores de servicios en la nube
Las principales plataformas en la nube ofrecen servicios de optimización gestionados y computación GPU sin procesar. Los servicios gestionados simplifican la complejidad de la infraestructura, pero aumentan el precio. Según la documentación de recursos informáticos para la investigación de Stanford, el servicio de entrenamiento gestionado de Together AI proporcionó el ejemplo de optimización inferior a $5, significativamente más económico que una infraestructura equivalente autogestionada.
El alquiler de GPU sin procesar ofrece mayor control. Las instancias AWS g5.xlarge (NVIDIA A10G) tienen un precio inicial de aproximadamente $1.50/hora. Las instancias multi-GPU para modelos más grandes escalan proporcionalmente: una instancia g5.12xlarge con 4 GPU A10G cuesta aproximadamente $6/hora.
Economía del autoalojamiento
Las GPU para consumidores hacen viable el ajuste fino local para modelos más pequeños. Una RTX 4060 Ti de 16 GB maneja modelos de 7B con LoRA y cuantización. El costo inicial alcanza los 1200-1600 T/$, pero elimina los cargos recurrentes.
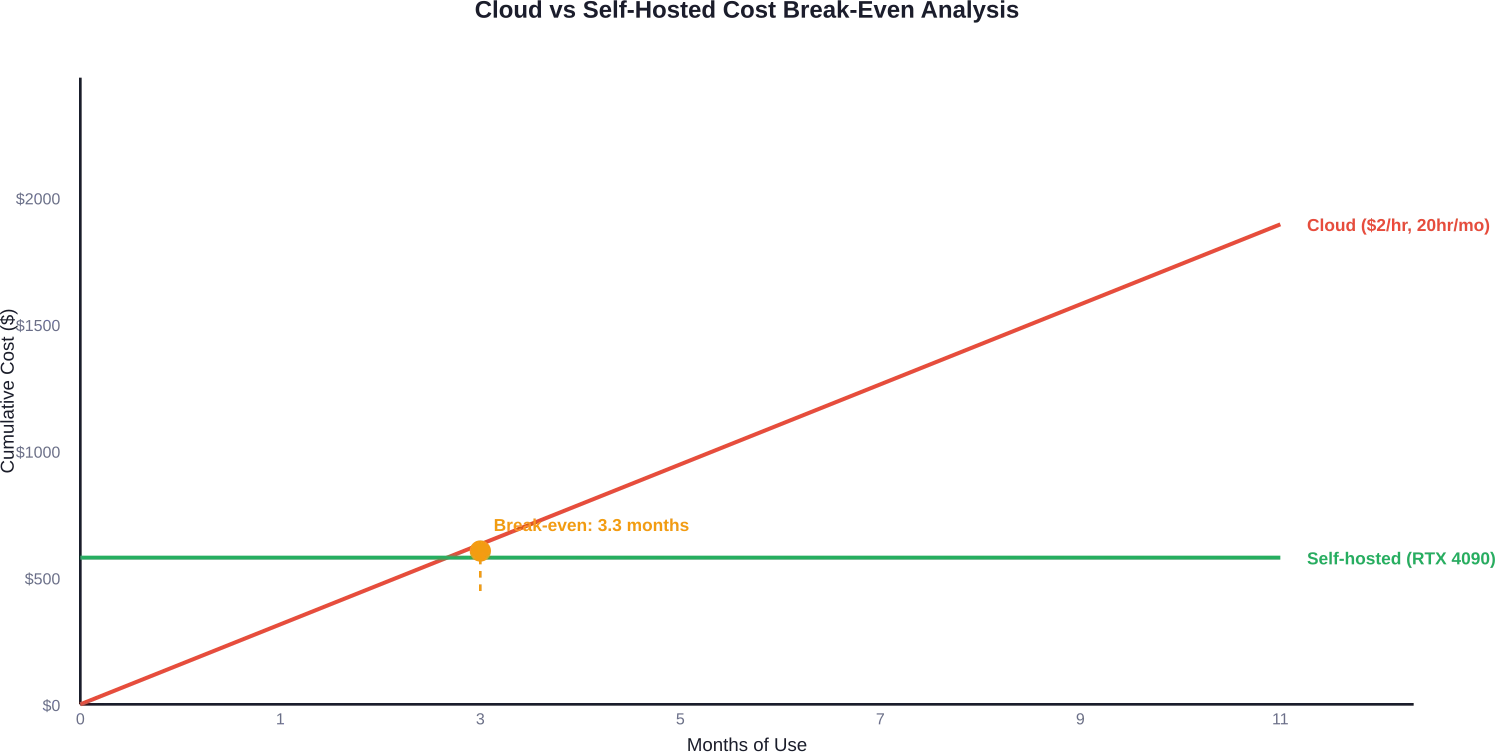
Los cálculos favorecen el autoalojamiento cuando la utilización supera las 15-20 horas mensuales. Con tarifas de nube de $2/hora, 20 horas mensuales cuestan $480, lo que significa que una GPU de $1600 se amortiza en menos de cuatro meses de uso constante.
Pero la nube ofrece flexibilidad para cargas de trabajo esporádicas. Ejecutar una tarea de ajuste fino al mes durante cuatro horas ($8-$10 en la nube) no justifica la compra de una GPU.
Cuando el ajuste fino tiene sentido desde el punto de vista financiero
No todos los casos de uso justifican la inversión en ajustes finos.
Calcula tu línea de base
Compare los costos de optimización con las alternativas de API. Si una tarea requiere 10 millones de tokens de inferencia al mes, los costos de la API, a razón de 1 TP4T0,001 por cada 1000 tokens, ascienden a 1 TP4T10 000 anuales. Una inversión única de 1 TP4T2000 en optimización, que permite una inferencia más económica con modelos más pequeños, ofrece un retorno de la inversión en cuestión de meses.
Pero si una ingeniería rápida logra resultados aceptables con un modelo base, el ajuste fino supone un desperdicio de recursos.
Las ventanas de contexto cambian el cálculo.
Los modelos modernos admiten ventanas de contexto de entre 200 000 y 1 millón de tokens. Incorporar el conocimiento del dominio en las indicaciones elimina la necesidad de ajustes finos para muchas aplicaciones. Cuando se lanzan nuevos modelos base cada 4-6 meses, mantener versiones optimizadas se convierte en un gasto recurrente.
Los debates en la comunidad ponen de manifiesto este cambio: los equipos prefieren cada vez más las ventanas de contexto amplias con indicaciones bien diseñadas en lugar del ajuste fino personalizado, ya que el cambio a modelos base mejorados no requiere ningún reentrenamiento.
El ajuste fino da sus frutos
En determinados escenarios, sigue siendo preferible realizar ajustes finos:
- Formato de salida consistente que la solicitud no puede garantizar de manera confiable.
- Conocimientos especializados del dominio no presentes en los datos de entrenamiento del modelo base.
- Aplicaciones críticas en cuanto a latencia, donde los modelos más pequeños y ajustados superan a los modelos base más grandes.
- Inferencia de alto volumen donde los costos de la API por token superan la inversión única en capacitación.
- Requisitos de privacidad que impiden el uso de API externas
Reducción de costes de ajuste fino sin sacrificar la calidad.
Existen varias estrategias para reducir gastos sin comprometer el rendimiento.
Empieza poco a poco
Comience con el modelo más pequeño que pueda funcionar. Ajuste un modelo de 3 mil millones de parámetros antes de intentar variantes de 7 o 13 mil millones. El rendimiento podría ser suficiente y los costos se mantendrán por debajo de $500.
Según una investigación de arXiv sobre el ajuste fino de modelos lineales de lógica difusa (LLM) ligeros para la clasificación del sentimiento financiero (arXiv:2512.00946), se evalúan modelos de 7 a 8 mil millones de parámetros, incluidos DeepSeek-LLM 7B, Llama3 8B Instruct y Qwen3 8B, frente a FinBERT en conjuntos de datos financieros. Los modelos más pequeños ofrecen resultados de nivel de producción para tareas bien definidas.
Usar LoRA por defecto
Inicie cualquier proyecto de ajuste fino con LoRA, a menos que existan razones de peso que justifiquen un ajuste fino completo. La retención de calidad del 80-95% frente a la reducción de costes del 70-95% convierte a LoRA en la opción predeterminada obvia.
La optimización de parámetros de clasificación permite una mayor mejora. Las clasificaciones LoRA más bajas (8-16) reducen los costos en comparación con las clasificaciones más altas (32-64), con un impacto mínimo en la precisión para muchas tareas.
Optimizar la duración del entrenamiento
Un mayor número de épocas no garantiza mejores resultados. Supervise la pérdida de validación y detenga el entrenamiento cuando la mejora se estanque. La detención temprana evita el desperdicio de recursos computacionales en ganancias marginales.
La investigación del laboratorio de IA Watson del MIT-IBM sobre las leyes de escalado indica que un 4 por ciento de ARE es aproximadamente la mejor precisión alcanzable que se podría esperar debido al ruido aleatorio de la semilla, lo que requiere una cuidadosa asignación del presupuesto de computación, pero ir más allá de ese punto produce rendimientos decrecientes a un costo exponencialmente mayor.
Seleccionar datos de entrenamiento de forma rigurosa
Quinientos ejemplos de alta calidad superan a 5000 ejemplos mediocres. Invierta tiempo en la calidad de los datos desde el principio para reducir las iteraciones de entrenamiento necesarias.
Elimine duplicados, corrija inconsistencias de formato y valide las etiquetas. Los datos limpios se ejecutan más rápido y se obtienen mejores resultados, lo que reduce tanto el tiempo como los costos.
Considere los servicios gestionados.
En ocasiones, el coste de la plataforma es menor que el tiempo de ingeniería. Los servicios gestionados se encargan del aprovisionamiento de infraestructura, la monitorización y la gestión de puntos de control. Para equipos sin experiencia en infraestructura de aprendizaje automático, plataformas gestionadas como Together AI o Hugging Face AutoTrain ofrecen resultados más rápidos a un menor coste total.
Preguntas frecuentes
¿Cuánto cuesta optimizar GPT-3.5 o GPT-4?
OpenAI cobra en función de los tokens de entrenamiento. El ajuste fino de GPT-3.5-turbo cuesta aproximadamente 1 TP4T0.008 por cada 1000 tokens de entrenamiento. Entrenar un conjunto de datos con 100 000 tokens de entrenamiento cuesta aproximadamente 1 TP4T0.80. El precio del ajuste fino de GPT-4 es significativamente más alto; consulte la página oficial de precios de OpenAI para conocer las tarifas actuales, ya que cambian periódicamente.
¿Puedo ajustar con precisión los modelos LLM en un ordenador portátil?
Los modelos más pequeños (de 2 a 3 mil millones de parámetros) funcionan en portátiles de gama alta con 16 GB o más de memoria unificada o VRAM dedicada, utilizando cuantización de 4 bits y LoRA. El entrenamiento es muy lento: de horas a días, dependiendo del tamaño del conjunto de datos. Las GPU en la nube siguen siendo más prácticas en la mayoría de los casos, pero el ajuste fino en portátiles es técnicamente factible para la experimentación.
¿Resulta más económico a largo plazo realizar ajustes finos que utilizar llamadas a la API?
Depende del volumen de inferencias. Calcula los costos mensuales de la API con el uso actual y compáralos con la inversión inicial en optimización, más los costos de inferencia con tu modelo optimizado. Para aplicaciones de alto volumen (millones de tokens mensuales), la optimización suele generar un retorno de la inversión en cuestión de meses. Para usos experimentales o de bajo volumen, las API son más económicas.
¿Con qué frecuencia debo recalibrar mi modelo?
Realice un reajuste fino cuando los modelos base mejoren significativamente o cuando el rendimiento se degrade con nuevos patrones de datos. Muchos equipos omiten por completo el reajuste fino con los modelos modernos de contexto amplio, y en su lugar actualizan las indicaciones al cambiar a modelos base más recientes. Evalúe si las ventajas del reajuste fino persisten a medida que se amplían las ventanas de contexto y mejoran las capacidades del modelo base.
¿Cuál es la diferencia entre el coste de ajuste fino y el coste de inferencia?
El ajuste fino es un gasto único de entrenamiento para personalizar el modelo. El costo de inferencia se refiere a los gastos recurrentes cada vez que el modelo genera predicciones. Los modelos autoalojados transfieren los costos de inferencia a una infraestructura fija, mientras que los modelos basados en API cobran por token procesado. Considere ambos al calcular el costo total de propiedad.
¿Necesito varias GPU para ajustar con precisión los LLM?
No es adecuado para modelos con menos de 13 mil millones de parámetros al usar LoRA y cuantización. Una sola GPU de consumo (RTX 3060 de 12 GB o superior) maneja modelos de 7 a 8 mil millones con técnicas PEFT. El ajuste fino completo de modelos más grandes o el entrenamiento con más de 13 mil millones de parámetros generalmente requiere configuraciones multi-GPU, a menos que se acepte una cuantización extrema.
¿Cómo puedo calcular los costes de ajuste fino antes de empezar?
Identifica el tamaño del modelo, elige la técnica de entrenamiento (completa o LoRA), estima la duración del entrenamiento según el tamaño del conjunto de datos y calcula las horas de GPU necesarias. Multiplica las horas de GPU por las tarifas del proveedor de la nube. Añade un margen de 30-40% para experimentación. Comienza con pequeñas pruebas piloto para validar las estimaciones antes de comprometerte con presupuestos de entrenamiento completos.
Tomar la decisión de ajuste fino
Los costes de ajuste fino varían en dos órdenes de magnitud según las decisiones tomadas de antemano.
Los equipos exitosos comienzan por preguntarse si es necesario realizar ajustes finos. Ventanas de contexto más amplias y mejores modelos base resuelven problemas que requerían ajustes finos hace apenas unos meses. Cuando se demuestra que es necesario realizar ajustes finos, técnicas eficientes en parámetros como LoRA hacen que los modelos personalizados sean accesibles con presupuestos inferiores a $100 para la mayoría de los casos de uso.
Los costosos fallos comparten patrones comunes: omitir la validación de la calidad de los datos, elegir modelos sobredimensionados y realizar un ajuste fino completo cuando bastaría con LoRA.
En serio: destina presupuesto para experimentación. La primera prueba de entrenamiento rara vez produce resultados listos para producción. Planifica de 3 a 5 iteraciones, controla los costos activamente y optimiza de forma intensiva.
¿Listo para comenzar a optimizar tu modelo dentro de tu presupuesto? Empieza con el modelo viable más pequeño, usa LoRA por defecto y valida la calidad de los datos antes de invertir en computación. Tu primer ajuste exitoso te enseñará más que cualquier guía.