Resumen rápido: Entrenar un modelo de lenguaje grande cuesta entre 1.4T50.000 y más de 1.4T500 millones, dependiendo del tamaño del modelo, la infraestructura y la duración del entrenamiento. Los modelos más pequeños con 20.000 millones de parámetros pueden costar entre 1.4T50.000 y 1.4T100.000, mientras que sistemas masivos como GPT-4 o Gemini pueden superar los 1.4T100 millones. Los mayores gastos son el tiempo de cómputo de la GPU, la preparación de datos y la infraestructura en la nube.
La economía del entrenamiento de grandes modelos lingüísticos se ha convertido en un factor determinante en el desarrollo de la IA. Las organizaciones se enfrentan ahora a decisiones cruciales sobre si crear sus propios modelos o suscribirse a servicios comerciales.
¿Y las cifras? Son asombrosas.
Según una investigación de Epoch AI, tanto GPT-4 como Gemini de Google han costado cientos de millones de dólares en entrenamiento. No se trata solo de mejoras graduales respecto a modelos anteriores; la barrera financiera ha aumentado drásticamente en los últimos años.
Sin embargo, hay que tener en cuenta que no todas las organizaciones necesitan un modelo innovador. Comprender la estructura de costos ayuda a determinar el enfoque adecuado para cada caso de uso específico.
¿Qué factores influyen en los costes de entrenamiento de los modelos de lenguaje a gran escala?
Los costes de formación se dividen en varias categorías principales, cada una de las cuales contribuye significativamente al coste total.
Infraestructura informática
El hardware de GPU domina la hoja de gastos. Los modelos con alrededor de 100 mil millones de parámetros requieren hardware de GPU avanzado, como las GPU A100 de NVIDIA. Para un modelo de 20 mil millones de parámetros, la infraestructura suele necesitar entre 8 y 16 GPU A100 de 80 GB.
El coste computacional por sí solo oscila entre $50.000 y $100.000 para un modelo más pequeño. Ese cálculo de referencia —aproximadamente $22.000 (16 A100 × $2,75/hora × 500 horas)— representa únicamente la ejecución de entrenamiento exitosa.
Pero espera.
Las ejecuciones fallidas y la experimentación pueden duplicar o triplicar fácilmente esa cifra. Entrenar modelos de lenguaje grandes no es un proceso que se complete de una sola vez. El ajuste de hiperparámetros, los experimentos de arquitectura y la resolución de problemas consumen tiempo de computación adicional.
Tiempo y duración
La duración del entrenamiento aumenta en función del tamaño y la complejidad del modelo. Un modelo con 20 mil millones de parámetros podría entrenarse en 500-1000 horas. Los modelos más grandes, con más de 120 mil millones de parámetros, pueden requerir varios miles de horas de GPU.
Los costos de la infraestructura en la nube se acumulan por hora. Esto significa que cada optimización que reduce el tiempo de entrenamiento disminuye directamente los gastos. La selección eficiente de hiperparámetros, un mejor diseño del flujo de datos y la reducción del tiempo de inactividad de la GPU son factores que influyen económicamente.
Preparación y gestión de datos
Los datos de entrenamiento de alta calidad no aparecen por arte de magia. Las organizaciones invierten mucho en la recopilación, limpieza, etiquetado y organización de datos. El agotamiento gradual de los datos públicos de alta calidad ha agudizado este desafío.
Los costos de almacenamiento y transferencia de datos también se acumulan. Mover conjuntos de datos masivos entre sistemas de almacenamiento y clústeres de computación genera costos de ancho de banda y almacenamiento que muchos presupuestos iniciales subestiman.

Comprenda el costo real de obtener un LLM.
El entrenamiento de un modelo de lenguaje complejo implica mucho más que recursos computacionales. La ingeniería de datos, la experimentación con modelos, la evaluación y la infraestructura de implementación también afectan los costos totales.
IA superior Ayuda a las organizaciones a evaluar si está justificado entrenar un modelo desde cero o si son más prácticos enfoques alternativos como la adaptación del modelo o la integración de API.
Sus servicios incluyen:
- diseño del proceso de capacitación
- estrategia y validación del conjunto de datos
- planificación de infraestructuras
- Análisis de costo-beneficio de modelos personalizados
Si está considerando el desarrollo de un máster en derecho (LLM) personalizado, un análisis de viabilidad puede ayudarle a evitar costes de formación innecesarios.
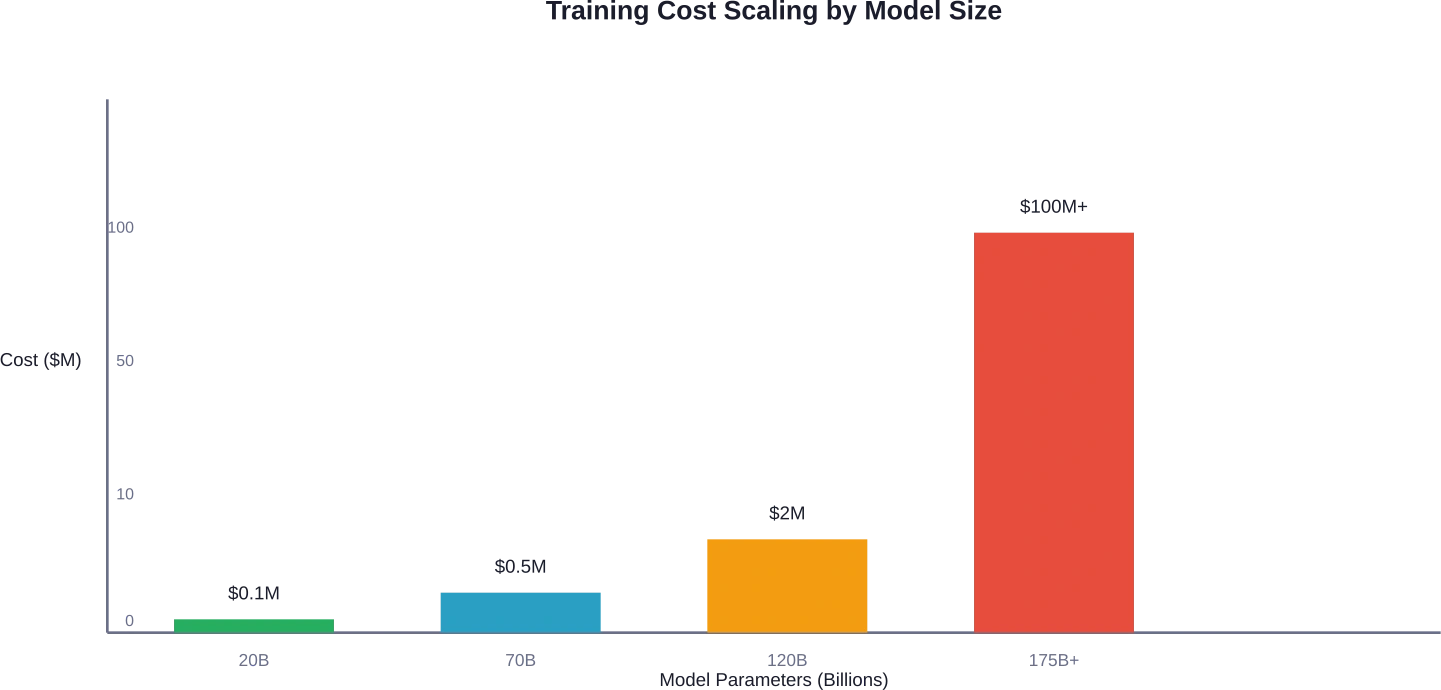
Comparación de costos en el mundo real: parámetros de 20 mil millones a 120 mil millones
Analicemos los rangos de costos reales para diferentes escalas de modelos.
| Tamaño del modelo | Requisitos de la GPU | Costo de cálculo base | Costo total estimado |
|---|---|---|---|
| Parámetros 20B | 8-16 A100 80 GB | $22,000-$50,000 | $50,000-$100,000 |
| Parámetros 70B | 32-64 A100 80 GB | $100,000-$250,000 | $200,000-$500,000 |
| Parámetros de 120B+ | 64-128+ A100 80GB | $300,000-$800,000 | $500,000-$2,000,000 |
| Modelos Frontier (175B+) | Más de 1000 GPU | $50M-$200M+ | $100M-$500M+ |
La diferencia entre los modelos pequeños y grandes no es lineal, sino exponencial. Un modelo con 120 mil millones de parámetros cuesta aproximadamente entre 5 y 20 veces más que uno con 20 mil millones, no solo por la cantidad de parámetros, sino también por la complejidad del entrenamiento, los tiempos de convergencia más largos y los costos de infraestructura.
El modelo Frontier Premium
Sistemas como GPT-4 y Gemini operan en un nivel de costos completamente diferente. Según datos de Epoch AI, el desarrollo de estos modelos ha costado cientos de millones de dólares.
¿Por qué cifras tan astronómicas?
Los modelos de vanguardia requieren enormes clústeres de GPU que funcionan durante meses. Incorporan experimentación exhaustiva, múltiples sesiones de entrenamiento, pruebas de seguridad y trabajos de alineación. Tan solo la infraestructura —la gestión simultánea de miles de GPU— exige sistemas de orquestación sofisticados.
Desglose de los gastos de infraestructura
Los costos de infraestructura van más allá del simple alquiler de GPU. Las organizaciones deben tener en cuenta el conjunto completo de componentes.
Opciones de hardware de GPU
Las GPU A100 de NVIDIA siguen siendo el estándar para la formación en LLM, aunque las variantes más recientes, H100 y H200, ofrecen un mejor rendimiento a precios más elevados. La elección depende de la disponibilidad, el presupuesto y el plazo de entrega.
Los proveedores de servicios en la nube aplican tarifas diferentes. AWS, Google Cloud y Microsoft Azure tienen estructuras de precios distintas para las instancias con GPU. Los proveedores especializados en cargas de trabajo de IA a veces ofrecen mejores tarifas para un uso prolongado.
Almacenamiento y redes
Los puntos de control del modelo, los datos de entrenamiento y los registros consumen una cantidad considerable de almacenamiento. Un modelo con 120 mil millones de parámetros genera archivos de puntos de control que superan los 500 GB cada uno. Las organizaciones suelen guardar varios puntos de control durante el entrenamiento para su posterior recuperación y análisis.
El ancho de banda de la red también es importante. La transferencia de datos entre el almacenamiento y el procesamiento, especialmente para el entrenamiento distribuido en múltiples nodos, puede añadir miles de dólares a la factura mensual.
Alojamiento e implementación
Los costos de entrenamiento son solo el comienzo. El alojamiento de estos modelos para inferencia genera gastos continuos. Para modelos con alrededor de 100 mil millones de parámetros, los costos de alojamiento oscilan entre 14.000 y 500.000 TP4T al año, dependiendo del tamaño del modelo y los patrones de uso.
Los costes de desarrollo, ampliamente citados, de modelos simplificados como DeepSeek-V3 pueden excluir los gastos de entrenamiento de modelos maestros más potentes de los que se derivaron, lo que ilustra cómo los enfoques contables pueden ocultar las inversiones totales en desarrollo.
Estrategias de optimización para reducir los costos de capacitación
Existen varias técnicas que pueden reducir drásticamente los gastos de capacitación sin sacrificar la calidad del modelo.
Cuantificación y precisión mixta
Los marcos de cuantificación FP4 para modelos lineales de pérdida (LLM) han demostrado su potencial para lograr una precisión comparable a la de BF16 y FP8 con una degradación mínima en modelos a gran escala. Esta tecnología reduce los requisitos de memoria y acelera los cálculos, disminuyendo directamente el tiempo de GPU necesario.
El entrenamiento con precisión mixta se ha convertido en una práctica habitual. Utilizar una precisión menor para ciertas operaciones y mantener una precisión mayor donde es necesario equilibra eficazmente la velocidad y la exactitud.
Métodos de entrenamiento de bajo rango
La aplicación de parametrizaciones de bajo rango a los modelos lineales lineales basados en transformadores reduce los costos computacionales y, en algunos casos, puede incluso mejorar el rendimiento. Estos métodos comprimen el espacio de parámetros manteniendo la expresividad del modelo.
Estrategias de datos eficientes
Las investigaciones sobre las leyes de escalado óptimo de Chinchilla indican que un desarrollador de LLM que entrena un modelo 13B esperando una demanda de inferencia de 2 billones de tokens podría potencialmente reducir el cálculo total en aproximadamente 1,7 × 10²² FLOPs (17%) entrenando modelos más pequeños durante más tiempo.
¿La clave? Entrenar durante un tiempo ligeramente mayor con más datos puede reducir los costos de inferencia posteriores si el modelo va a atender muchas solicitudes. El costo total de propiedad importa más que solo el costo de entrenamiento.

Instancias Spot y máquinas virtuales preemptivas
Los proveedores de servicios en la nube ofrecen instancias spot con descuento que pueden interrumpirse. Para flujos de trabajo de capacitación tolerantes a fallos con puntos de control regulares, las instancias spot reducen los costos entre 40 y 70 TP3T en comparación con los precios bajo demanda.
¿La contrapartida? La formación podría alargarse debido a las interrupciones. Pero con una gestión adecuada de los puntos de control, el ahorro suele justificar la complejidad.
La decisión de construir o comprar
Las organizaciones se enfrentan a una elección fundamental: capacitar a su propio modelo o utilizar servicios comerciales.
Cuando los servicios comerciales tienen sentido
Para la mayoría de los casos de uso, suscribirse a servicios comerciales de modelado lógico de aprendizaje (LLM) resulta más económico. Las API de OpenAI, Anthropic y Google permiten acceder a modelos de vanguardia sin necesidad de inversión inicial.
Según estudios de análisis de costo-beneficio, las organizaciones necesitan un uso sostenido significativo para alcanzar el punto de equilibrio con los servicios comerciales. Los estudios sugieren que los umbrales de paridad de rendimiento en torno a 20% de los principales modelos comerciales marcan puntos de equilibrio viables para la inversión en infraestructura.
Cuando el entrenamiento tiene sentido
La formación personalizada resulta atractiva cuando:
- Los requisitos específicos del dominio exigen datos de formación especializados.
- Las normativas de privacidad de datos impiden el envío de información a API de terceros.
- El volumen de inferencias previsto supera los millones de solicitudes mensuales.
- El ajuste fino de los modelos comerciales resulta insuficiente para el caso de uso.
Las organizaciones que prevén un uso intensivo y sostenido durante varios años pueden lograr un menor coste total de propiedad con modelos autogestionados. El punto de equilibrio depende del tamaño del modelo, el volumen de solicitudes y los niveles de rendimiento requeridos.
Consideraciones de cálculo en tiempo de prueba
Investigaciones recientes sobre la asignación de recursos computacionales durante las pruebas revelan otra dimensión de los costos. Los gastos de inferencia pueden superar los costos de entrenamiento para modelos ampliamente utilizados.
Las estrategias de asignación adaptativa que distribuyen la capacidad de procesamiento dinámicamente según la dificultad de la consulta mejoran sustancialmente la eficiencia. Los indicadores de dificultad sin entrenamiento ayudan a distribuir presupuestos de procesamiento fijos entre las consultas de prueba, maximizando las instancias resueltas y respetando las restricciones presupuestarias.
Las investigaciones sobre agentes eficientes demuestran que el diseño óptimo del marco de trabajo es de suma importancia. Un estudio encontró un marco de trabajo que mantenía un rendimiento del 96,71 TP3T de un agente líder de código abierto, al tiempo que reducía los costos operativos de 0,398 a 0,228, lo que representa una mejora de 28,41 TP3T en el costo de paso.
Principios contables para los costos de desarrollo de la IA
Los responsables políticos utilizan cada vez más el coste de desarrollo y la capacidad de procesamiento como indicadores de las capacidades y los riesgos de la IA. Las leyes recientes introducen requisitos regulatorios supeditados a umbrales de coste específicos.
Pero aquí radica el problema: las ambigüedades técnicas en la contabilidad de costos crean lagunas. Una contabilidad restrictiva puede ocultar los costos totales de desarrollo de un modelo. Los costos de desarrollo, ampliamente citados para modelos simplificados como DeepSeek-V3, podrían excluir los gastos de entrenamiento de modelos maestros más potentes de los que se derivaron.
Las organizaciones deben adoptar una contabilidad integral que incluya:
- Todas las sesiones de entrenamiento, incluidos los experimentos fallidos.
- Costos de adquisición, limpieza y preparación de datos
- Gastos generales de infraestructura y redes
- Tiempo de ingeniería para el desarrollo de la arquitectura
- Trabajos de pruebas de seguridad y alineación
- Costos de los modelos de enseñanza para enfoques de destilación
| Categoría de costo | Típico % del total | ¿A menudo se pasa por alto? |
|---|---|---|
| Computación con GPU (ejecución exitosa) | 30-40% | No |
| Experimentos fallidos | 15-25% | Sí |
| Preparación de datos | 10-15% | Sí |
| Almacenamiento y redes | 5-10% | Sí |
| Mano de obra de ingeniería | 20-30% | A veces |
| Seguridad y alineación | 5-10% | Sí |
Tendencias de costos futuras
Diversos factores influirán en los costes de formación en los próximos años.
El hardware de las GPU sigue avanzando. La arquitectura Blackwell de NVIDIA, que incluye las variantes B100, B200 y GB200, promete un mejor rendimiento por dólar. Sin embargo, la demanda mantiene los precios elevados.
Los costes de los datos están aumentando. A medida que los datos públicos de alta calidad se vuelven más escasos, las organizaciones invierten más en conjuntos de datos propios, generación de datos sintéticos y acuerdos de licencia de datos.
Dicho esto, las mejoras algorítmicas y el aumento de la eficiencia en el entrenamiento compensan parcialmente los costes de hardware. La comunidad investigadora desarrolla continuamente mejores métodos de optimización, leyes de escalado y diseños de arquitectura.
Preguntas frecuentes
¿Cuánto cuesta entrenar un modelo con 70 mil millones de parámetros?
El entrenamiento de un modelo con 70 mil millones de parámetros suele costar entre $200.000 y $500.000. Esto incluye los costes base de computación de $100.000 a $250.000 para 32-64 GPU A100, más gastos adicionales por ejecuciones fallidas, experimentación, preparación de datos y gastos generales de infraestructura.
¿Pueden las organizaciones más pequeñas permitirse entrenar modelos de lenguaje de gran tamaño?
Las organizaciones más pequeñas pueden entrenar modelos de tamaño moderado (de 1 a 20 mil millones de parámetros) para $10 000 a $100 000 utilizando recursos de GPU en la nube y técnicas de optimización. Sin embargo, para la mayoría de las aplicaciones, usar servicios de API comerciales o ajustar modelos de código abierto existentes resulta más rentable que entrenarlos desde cero.
¿Cuál es la parte más costosa de la formación para obtener un LLM?
El tiempo de cómputo de la GPU representa entre 30 y 401 TP3T del costo total de la mayoría de los proyectos. Sin embargo, al considerar los experimentos fallidos y el ajuste de hiperparámetros, los gastos relacionados con el cómputo suelen superar los 501 TP3T del presupuesto total. La mano de obra de ingeniería generalmente representa otros 20 a 301 TP3T.
¿Cuánto tiempo se tarda en entrenar un modelo de lenguaje grande?
La duración del entrenamiento varía drásticamente según el tamaño del modelo. Un modelo con 20 mil millones de parámetros podría entrenarse en 500-1000 horas de GPU (aproximadamente 3-6 semanas en un clúster de 16 GPU). Los modelos más grandes, con más de 120 mil millones de parámetros, pueden requerir varios miles de horas de GPU, extendiendo el entrenamiento a 2-4 meses. Los modelos de vanguardia con más de 175 mil millones de parámetros suelen entrenarse durante varios meses en clústeres masivos.
¿Es más económico entrenar una sola vez o usar llamadas a la API a largo plazo?
Esto depende totalmente del volumen de uso. Para aplicaciones que realizan menos de 10 millones de llamadas a la API al mes, los servicios comerciales suelen ser más económicos. Las organizaciones con un uso sostenido de alto volumen, especialmente aquellas que necesitan modelos especializados o tienen requisitos de privacidad de datos, pueden encontrar que la autoformación es más rentable a largo plazo.
¿Cuál es la diferencia entre el coste de entrenamiento y el coste de inferencia?
El costo de entrenamiento es el gasto único para desarrollar el modelo, que oscila entre miles y cientos de millones de dólares. El costo de inferencia es el gasto continuo para ejecutar el modelo y realizar predicciones, y se cobra por solicitud o token. En el caso de modelos ampliamente implementados, los costos totales de inferencia durante la vida útil del modelo suelen superar los costos de entrenamiento.
¿Cómo puedo reducir los costes de la formación en Derecho (LLM)?
Las estrategias clave para la reducción de costos incluyen el uso de cuantización (entrenamiento FP4/FP8), el aprovechamiento de instancias spot para obtener ahorros de 40 a 70%, la implementación de puntos de control eficientes para minimizar el desperdicio de computación, la optimización de las canalizaciones de datos para reducir el tiempo de inactividad de la GPU y la consideración de la destilación de modelos a partir de modelos maestros más grandes cuando sea apropiado.
Tomar la decisión de inversión
Entrenar modelos de lenguaje complejos sigue siendo costoso, pero los costos varían. Las organizaciones no se enfrentan a una disyuntiva entre modelos de vanguardia y no hacer nada.
Una evaluación realista comienza con los requisitos del caso de uso. ¿Qué nivel de rendimiento resuelve realmente el problema empresarial? ¿La aplicación requiere capacidades de vanguardia o bastaría con un modelo especializado más pequeño?
Para muchas aplicaciones, los modelos con un rango de parámetros de entre 7 y 20 mil millones ofrecen excelentes resultados a un coste razonable. Estos sistemas pueden entrenarse para entre $50 000 y $200 000, lo que los hace accesibles a organizaciones medianas con necesidades específicas en su sector.
La carrera por desarrollar modelos innovadores —que buscan alcanzar más de 175 mil millones de parámetros— tiene sentido principalmente para las empresas que desarrollan plataformas de IA de propósito general. Para el resto, la solución ideal suele estar en modelos más pequeños y especializados, optimizados para tareas específicas.
Analice el costo total de propiedad. La capacitación es solo el comienzo. Considere también el alojamiento, los costos de inferencia, el mantenimiento continuo y el equipo de ingeniería necesario para dar soporte al sistema.
La economía del desarrollo de los sistemas de gestión del aprendizaje automático (LLM) sigue evolucionando. El hardware mejora, los algoritmos se vuelven más eficientes y surgen nuevas técnicas de formación con regularidad. Lo que hoy cuesta $500 000 podría costar $200 000 en dos años, o podría ofrecer un rendimiento tres veces superior por el mismo precio.
Las organizaciones que se adentren en este sector deben empezar poco a poco, medir con precisión y escalar en función del valor demostrado. La tecnología ha madurado lo suficiente como para que la experimentación ya no requiera una inversión inicial masiva. Prototipe con modelos más pequeños, valide el enfoque y, a continuación, decida si le conviene más escalar o seguir utilizando API comerciales.
La revolución de la IA sigue acelerándose, pero la implementación inteligente supera a la mera escalabilidad. Comprender estas estructuras de costos ayuda a las organizaciones a tomar decisiones informadas en lugar de perseguir indicadores que quizás no sean relevantes para sus aplicaciones específicas.