Resumen rápido: Para monitorizar los costes de las aplicaciones LLM, es necesario realizar un seguimiento en tiempo real del uso de tokens, la selección de modelos y los patrones de solicitud para evitar sobrecostes. Herramientas líderes como Datadog LLM Observability, Langfuse y las soluciones nativas en la nube de AWS Bedrock y OpenAI ofrecen atribución de costes, análisis de uso y recomendaciones de optimización. Una monitorización eficaz combina plataformas de observabilidad con prácticas estratégicas como la optimización inmediata, la selección de modelos y el almacenamiento en caché.
A medida que las aplicaciones de IA generativa pasan del prototipo a la producción, los costos de los tokens pueden dispararse. Una sola cadena de mensajes no optimizada puede multiplicar los gastos por diez, y sin visibilidad en tiempo real de los patrones de uso, los equipos a menudo descubren los sobrecostos solo cuando llega la factura.
El monitoreo tradicional de costos en la nube no es suficiente para las aplicaciones LLM. Los modelos de precios basados en tokens requieren una observabilidad especializada que rastree no solo el tiempo de cómputo, sino también los tokens de entrada, los tokens de salida, la selección del modelo y la frecuencia de las solicitudes en diferentes proveedores.
Esto plantea un desafío fundamental: ¿cómo pueden los equipos mantener la visibilidad de los costes de LLM sin sacrificar la velocidad de desarrollo ni el rendimiento de la aplicación?
Por qué es importante el control de costes en el programa LLM
El modelo de precios basado en tokens cambia radicalmente la forma en que escalan los costos de las aplicaciones. A diferencia de la infraestructura tradicional, donde los costos se correlacionan con el tiempo de actividad del servidor, los gastos de LLM dependen del volumen y la complejidad de cada solicitud.
Según la documentación de AWS publicada en octubre de 2025 (Crea un sistema proactivo de gestión de costes mediante IA para Amazon Bedrock), las organizaciones se enfrentan a dificultades para gestionar los costes asociados a los precios basados en tokens, que pueden generar facturas inesperadas si el uso no se supervisa cuidadosamente. Los métodos tradicionales, como las alertas presupuestarias y la detección de anomalías en los costes, suelen reaccionar demasiado tarde.
Esto es lo que diferencia la gestión de costes de LLM:
- El consumo de tokens varía enormemente en función de la longitud de la solicitud y la complejidad de la respuesta.
- Los distintos modelos tienen precios muy diferentes (Amazon Nova Micro cuesta $0,000035 por cada 1.000 tokens de entrada y $0,00014 por cada 1.000 tokens de salida, frente a modelos más grandes con precios más elevados).
- Los flujos de trabajo de agentes de varios pasos incrementan los costos a través de múltiples llamadas LLM.
- Los patrones de uso de la producción rara vez coinciden con las estimaciones de desarrollo.
En serio: la mayoría de los equipos solo descubren que tienen un problema de costos después de haber acumulado miles de dólares en gastos. El monitoreo proactivo evita por completo esa situación.
Comprender la economía de los tokens
El precio de los tokens no es uniforme en todos los modelos ni entre todos los proveedores. La rentabilidad depende en gran medida del modelo base que impulse la aplicación y de cómo se estructuren las solicitudes.
La documentación de OpenAI muestra que los tokens de audio en los mensajes de usuario cuentan como 1 token por cada 100 ms de audio, mientras que los mensajes del asistente utilizan 1 token por cada 50 ms. Estas variaciones son importantes al desarrollar aplicaciones multimodales.
Los modelos de Amazon Nova demuestran claramente el espectro de precios. Tal como se documenta en los materiales de AWS de junio de 2025:
| Modelo | Tokens de entrada (por cada 1.000) | Tokens de salida (por cada 1.000) |
|---|---|---|
| Amazon Nova Micro | $0.000035 | $0.00014 |
| Variantes más grandes de Nova | Tasas más altas | Escalado proporcional |
El modelo más grande no siempre es necesario para todas las tareas. Adaptar la capacidad del modelo a la complejidad del caso de uso influye directamente en los costes.
Anthropic ofrece una API de uso y costes que permite el acceso programático a los datos de gastos de la organización. Esto permite a los equipos crear paneles personalizados y controles de costes automatizados.

Implementar sistemas de monitoreo LLM
Las aplicaciones LLM requieren monitorización para realizar un seguimiento del uso, el rendimiento y la estabilidad operativa.
IA superior Desarrolla herramientas de monitorización y gestión para sistemas de IA en producción, ayudando a las organizaciones a operar aplicaciones basadas en LLM de forma más eficiente.
Su labor de desarrollo puede incluir:
- sistemas de seguimiento de uso
- Análisis rápido y de respuesta
- monitoreo de infraestructura
- Herramientas de optimización de sistemas de IA
IA superior Ayuda a los equipos a trasladar las aplicaciones LLM desde el prototipo a entornos de producción estables.
Componentes básicos del monitoreo de costos de LLM
Los sistemas de monitoreo eficaces rastrean múltiples dimensiones simultáneamente. El uso de tokens por sí solo no cuenta toda la historia.
Seguimiento del uso de tokens
Cada solicitud genera tokens de entrada y salida. Los sistemas de monitorización deben capturar ambas dimensiones y atribuirlas a usuarios, funciones o flujos de trabajo específicos.
El número de tokens de entrada depende de las decisiones de ingeniería de las indicaciones. Las indicaciones del sistema demasiado detalladas o la inyección excesiva de contexto aumentan los costes por solicitud. Los tokens de salida varían según parámetros del modelo como la temperatura y la configuración de max_tokens.
La documentación de Apigee de Google describe las políticas de tokens LLM como cruciales para el control de costos, aprovechando las métricas de uso de tokens para establecer límites y proporcionar monitoreo en tiempo real. La plataforma permite configurar límites de tokens, como restringir las solicitudes a 1000 tokens por minuto.
Atribución de selección de modelos
Las aplicaciones que utilizan varios modelos requieren una asignación de costos por tipo de modelo. Una decisión de enrutamiento que envía consultas sencillas a un modelo costoso supone un desperdicio de presupuesto.
Las estrategias de cascada de modelos pueden optimizar los costos al intentar primero los modelos más económicos y aumentar la escala solo cuando sea necesario. El monitoreo debe registrar qué modelo procesó cada solicitud y la diferencia de costo asociada.
Análisis de patrones de solicitud
Los patrones temporales revelan oportunidades de optimización. El procesamiento por lotes durante las horas de menor actividad, la limitación de solicitudes durante los picos de tráfico y la identificación de llamadas redundantes requieren datos históricos sobre patrones.
Las pruebas de AWS documentadas en octubre de 2025 mostraron tiempos de ejecución de flujos de trabajo que oscilaban entre 6,76 y 32,24 segundos, según los requisitos de tokens de salida. Comprender estos patrones facilita la planificación de la capacidad.
Las mejores herramientas para el control de costes de los programas de Maestría en Derecho (LLM)
Varias plataformas se han consolidado como líderes en la observabilidad y la gestión de costes de LLM. Cada una ofrece diferentes ventajas en función de la arquitectura de implementación y el ecosistema del proveedor.
Observabilidad de Datadog LLM
La plataforma de Datadog se integra con los principales proveedores de LLM, incluidos OpenAI, Anthropic y Amazon Bedrock, tal como se documenta en los materiales de colaboración de AWS. La documentación de AWS de julio de 2025 (Supervisar agentes creados en Amazon Bedrock con la observabilidad LLM de Datadog) describe cómo Datadog supervisa los agentes creados en Bedrock con capacidades de observabilidad completas.
La plataforma realiza un seguimiento del uso de tokens, la latencia y los costos en todas las llamadas LLM en un panel centralizado. Los registros capturan flujos de trabajo de agentes de varios pasos, mostrando cómo se acumulan los costos a través de cadenas complejas.
Entre sus principales funcionalidades se incluyen la atribución de costes en tiempo real, la monitorización del rendimiento y la detección de anomalías. Los equipos pueden configurar alertas presupuestarias y visualizar las tendencias de gasto a lo largo del tiempo.
Los precios varían en función del volumen de uso, y existen planes empresariales personalizados disponibles para implementaciones a gran escala.
Langfuse
Langfuse ofrece observabilidad LLM de código abierto con la opción de autoalojamiento. La plataforma proporciona vistas basadas en sesiones que vinculan las solicitudes LLM relacionadas, lo que facilita la comprensión de los recorridos del usuario.
La sólida capacidad de observación para cadenas de varios pasos y flujos de trabajo de agentes distingue a Langfuse. El rastreo jerárquico muestra las relaciones padre-hijo entre las llamadas LLM, mientras que el seguimiento de costos atribuye el gasto a rastreos o sesiones específicas.
Los debates en la comunidad destacan que, si bien la opción de alojamiento propio ofrece control total, la versión en la nube comienza en $29/mes con precios basados en el uso más allá del nivel básico, con una opción de alojamiento propio gratuita disponible.
Herramientas nativas de Amazon Bedrock
AWS integró la gestión de costes directamente en Bedrock. La documentación de octubre de 2025 describe un sistema proactivo de gestión de costes basado en IA que va más allá de las alertas presupuestarias tradicionales.
El flujo de trabajo mantiene patrones de ejecución consistentes al procesar solicitudes de duración variable (de 6,76 a 32,24 segundos, según los requisitos del token de salida). Esta integración nativa significa que no se requiere una plataforma de observabilidad independiente para las cargas de trabajo de Bedrock.
Las estrategias de optimización de costos documentadas en junio de 2025 hacen hincapié en la selección del modelo como un factor clave. Elegir la variante adecuada del modelo Nova puede reducir drásticamente los costos sin sacrificar la calidad de la aplicación.
Herramientas de gestión de costes de OpenAI
OpenAI ofrece seguimiento de uso nativo a través del panel de control de la API y acceso programático mediante puntos finales de uso. La documentación de la API en tiempo real explica cómo se acumulan los costos en las diferentes modalidades: texto, audio e imágenes.
El cálculo de los tokens de audio varía según el tipo de mensaje (1 token cada 100 ms para mensajes de usuario, 1 token cada 50 ms para mensajes del asistente). Comprender estos matices evita cargos inesperados en aplicaciones con control por voz.
La plataforma ofrece límites presupuestarios y umbrales de notificación configurables a nivel de organización y de proyecto.
API de uso y coste antrópicos
El enfoque de Anthropic proporciona acceso programático a los datos de uso de la organización a través de una API dedicada. Esto permite integraciones personalizadas de monitoreo de costos sin depender de plataformas de terceros.
La documentación de Claude Code de Anthropic muestra que el comando /cost proporciona estadísticas detalladas sobre el uso de tokens, incluyendo el costo total (ejemplo: $0.55), la duración de la API y los cambios en el código. Estos datos detallados ayudan a los desarrolladores a comprender con precisión qué factores influyen en el gasto de sus aplicaciones.
La limitación de velocidad y los controles de gasto por equipo permiten a los administradores limitar el uso a nivel organizativo.
Soluciones de monitorización nativas de la nube
Los principales proveedores de servicios en la nube han integrado la monitorización de costes de LLM en sus plataformas de observabilidad más amplias.
Monitor de Azure
La monitorización de Azure se extiende a las implementaciones de Azure OpenAI Service. La plataforma realiza un seguimiento del consumo de tokens, las tasas de solicitud y los costes en todos los modelos implementados.
La integración con Azure Cost Management proporciona una visibilidad unificada tanto de los gastos de infraestructura como de los de LLM, lo que facilita la comprensión de los costes totales de las aplicaciones.
Google Cloud y Apigee
El enfoque de Google utiliza políticas de tokens de Apigee LLM para el control de costos. Estas políticas imponen límites basados en métricas de uso de tokens y proporcionan monitoreo en tiempo real del consumo de tokens instantáneos.
La documentación describe cómo implementar límites de velocidad, como 1000 tokens por minuto, utilizando políticas PromptTokenLimit. Esto evita costos excesivos derivados de picos de tráfico inesperados.
Infraestructura de Hugging Face
Los precios de Hugging Face, publicados en enero de 2026, abarcan desde el nivel gratuito hasta las soluciones empresariales. Los puntos finales de inferencia se facturan en función del tiempo de procesamiento multiplicado por el precio del hardware.
Una solicitud que tarda 10 segundos en una GPU con un coste de $0,00012 por segundo genera un cargo de $0,0012, tal como se documenta en las guías de precios de Hugging Face. Comprender este modelo de tiempo de cómputo difiere de la tarificación basada en tokens y requiere enfoques de monitorización distintos.
La plataforma ofrece paneles de control que muestran el consumo de recursos computacionales, pero las discusiones de la comunidad de abril de 2025 revelan confusión sobre cómo convertir el tiempo de ejecución en costos exactos. Una mejor documentación de la fórmula de conversión sería útil.
| Plataforma | Modelo de precios | Funciones de monitoreo | Mejor para |
|---|---|---|---|
| Perro de datos | Basado en el uso | Observabilidad unificada, seguimientos, alertas | Entornos multiproveedor |
| Langfuse | Alojamiento propio gratuito, nube $29+ | Seguimiento de sesiones, trazas jerárquicas | Preferencia por el código abierto |
| AWS Bedrock | Incluido con el servicio | Integración nativa, patrones de solicitud | Implementaciones nativas de AWS |
| OpenAI nativo | Incluido | Panel de uso, acceso a la API | Aplicaciones exclusivas de OpenAI |
| API antrópica | Incluido | Datos de costos programáticos | Aplicaciones basadas en Claude |
Estrategias de optimización de costos
El monitoreo identifica problemas. La optimización los soluciona. Varias estrategias reducen de forma consistente los costos de LLM sin comprometer la funcionalidad.
Ingeniería rápida
Las indicaciones concisas reducen la cantidad de tokens de entrada. Las investigaciones demuestran que el código deficiente conlleva un consumo de tokens significativamente mayor durante la inferencia en comparación con el código limpio, con un consumo medio de tokens de 28,13 para el código limpio frente a 33,30 para el código deficiente.
Eliminar el contexto innecesario, usar instrucciones claras y estructurar las indicaciones de manera eficiente reducen los costos por solicitud. Probar diferentes formulaciones de indicaciones y medir el uso de tokens permite identificar los enfoques más eficientes.
Selección de modelos
Los modelos específicos para cada tarea suelen ser más rentables que los modelos de propósito general. La documentación de AWS destaca que el modelo más grande no siempre es necesario para todas las aplicaciones.
Un enfoque en cascada prueba primero los modelos más económicos y solo recurre a ellos cuando la precisión cae por debajo de ciertos umbrales. Esto equilibra dinámicamente el costo y la calidad.
Las investigaciones sobre el análisis de costo-beneficio definen la paridad de rendimiento como las puntuaciones de referencia dentro del 20% de los principales modelos comerciales, lo que refleja las normas empresariales donde las pequeñas diferencias de precisión se compensan con los beneficios en cuanto a costo, seguridad e integración.
Estrategias de almacenamiento en caché
El almacenamiento en caché de respuestas para consultas repetidas elimina por completo las llamadas LLM redundantes. El almacenamiento en caché semántico va más allá al reconocer consultas similares (no solo idénticas) y devolver respuestas almacenadas en caché.
La documentación de OpenAI sobre optimización de costes destaca el almacenamiento en caché como estrategia principal. La API de procesamiento por lotes y el procesamiento flexible proporcionan mecanismos adicionales de reducción de costes para cargas de trabajo que no requieren una respuesta inmediata.
Estrangulamiento estratégico
La limitación de velocidad evita picos de costos durante aumentos inesperados del tráfico. Las políticas de tokens de Apigee imponen límites que protegen contra el gasto descontrolado.
Las arquitecturas basadas en colas absorben los picos de tráfico sin aumentar inmediatamente el uso de LLM. Esto implica cierta latencia a cambio de costes predecibles.
Mejores prácticas de implementación
La implementación de un sistema de control de costes requiere tanto integración técnica como procesos organizativos.
Enfoque de instrumentación
Instrument LLM realiza llamadas a nivel del SDK en lugar de intentar extraer información de los paneles de control de los proveedores. La integración directa captura metadatos de las solicitudes, como identificadores de usuario, indicadores de funciones y contextos de sesión, lo que permite una atribución de costos detallada.
La mayoría de las plataformas de observabilidad ofrecen SDK o integraciones con OpenTelemetry que capturan trazas automáticamente. La instrumentación manual ofrece mayor control, pero requiere un mayor esfuerzo de ingeniería.
Configuración de alertas
Configure alertas escalonadas basadas en umbrales de gasto absolutos y aumentos porcentuales. Una alerta de presupuesto diario $100 detecta aumentos graduales, mientras que una alerta de aumento horario 200% detecta picos repentinos.
La detección de anomalías de costos de AWS funciona para la infraestructura, pero a menudo reacciona demasiado tarde para los costos basados en tokens. La monitorización en tiempo real mediante plataformas de observabilidad LLM especializadas detecta los problemas con mayor rapidez.
Educación en equipo
Los desarrolladores necesitan tener visibilidad sobre las implicaciones económicas de sus decisiones. Mostrar el número de tokens y los costes estimados durante el desarrollo ayuda a generar conciencia sobre los costes.
La documentación de Claude Code muestra que el comando /cost proporciona estadísticas a nivel de sesión, incluyendo el costo total, la duración y los cambios en el código. Integrar bucles de retroalimentación similares en las herramientas internas permite tomar mejores decisiones.
Auditorías periódicas
Las revisiones mensuales de costos permiten identificar oportunidades de optimización y validar que los controles funcionen según lo previsto. El seguimiento del costo por usuario, el costo por función y el costo por transacción revela dónde se concentra el gasto.
Comparar los costes reales con las estimaciones iniciales permite detectar deficiencias en la planificación y mejorar las previsiones futuras.
Medición del retorno de la inversión y del éxito
El control de costes en sí mismo requiere tiempo y recursos. Los equipos necesitan métricas claras para justificar la inversión.
Los indicadores clave de rendimiento incluyen:
- Coste por función de la aplicación o sesión de usuario
- Reducción porcentual en el consumo de tokens después de la optimización
- Tiempo medio para detectar anomalías en los costes
- Variación entre el gasto presupuestado y el gasto real
La investigación sobre agentes eficientes logró un rendimiento del 96,71 TP3T de OWL al tiempo que redujo los costos operativos de 1 TP4T0,398 a 1 TP4T0,228, lo que resultó en una mejora del 28,41 TP3T en el costo de paso (de arXiv: Efficient Agents).
El objetivo no es minimizar los costos a cualquier precio, sino maximizar el valor por cada dólar invertido. A veces, un mayor costo se traduce en un valor proporcionalmente mayor.
Errores comunes que se deben evitar
Diversos errores socavan sistemáticamente los esfuerzos de control de costes.
El monitoreo aislado, sin acciones de optimización, desperdicia esfuerzos. Los datos sin decisiones no reducen el gasto. Cree ciclos de retroalimentación que conviertan la información en cambios inmediatos, selección de modelos o mejoras de arquitectura.
Optimizar en exceso demasiado pronto en el desarrollo ralentiza la velocidad de iteración. Espere a que los patrones de uso se estabilicen antes de realizar una optimización agresiva. La optimización prematura basada en el uso del prototipo rara vez refleja la realidad de la producción.
Ignorar los costos de oportunidad también es importante. El tiempo que un desarrollador dedica a optimizar un gasto de $50/mes podría costar más que simplemente pagar la factura. Concéntrese en optimizar los esfuerzos donde se concentra el gasto.
Ignorar las compensaciones en cuanto a latencia genera nuevos problemas. El almacenamiento en caché agresivo o la selección de modelos más pequeños pueden reducir los costos, pero aumentan los tiempos de respuesta lo suficiente como para perjudicar la experiencia del usuario. Es necesario monitorear ambas dimensiones simultáneamente.
Tendencias futuras en la gestión de costes de los másteres en Derecho
El panorama del control de costes sigue evolucionando rápidamente a medida que la tecnología madura.
Las restricciones de costo probabilísticas representan un enfoque emergente. Una investigación en ArXiv sobre cascadas de modelos optimizadas describe C3PO, un sistema que optimiza la selección de modelos de lógica difusa (LLM) con restricciones de costo probabilísticas para tareas de razonamiento. Esto va más allá de simples umbrales, logrando una sofisticada optimización del equilibrio entre costo y calidad.
El enrutamiento entre múltiples proveedores basado en precios en tiempo real será cada vez más común. A medida que convergen las capacidades de los modelos, se intensifica la competencia de precios. Los sistemas que enrutan dinámicamente las solicitudes al proveedor más económico que ofrezca una calidad suficiente brindarán ventajas competitivas.
El hardware especializado para inferencia continúa mejorando la relación precio-rendimiento. Los documentos de precios de Hugging Face indican que las instancias de Intel Sapphire Rapids x1 comienzan en $0.033/hora (a la fecha de la fuente). Los aceleradores de IA personalizados de los proveedores de la nube siguen reduciendo los costos.
Pero un momento. Los precios base más bajos no eliminan la necesidad de supervisión. Simplemente cambian el enfoque de la optimización, pasando del gasto total a métricas de eficiencia como el costo por tarea completada con éxito.
Preguntas frecuentes
¿Cómo calculo el coste de una solicitud a la API de LLM?
Multiplique los tokens de entrada por el precio del token de entrada del modelo y luego sume los tokens de salida multiplicados por el precio del token de salida. Por ejemplo, con Amazon Nova Micro a $0.000035 por cada 1000 tokens de entrada y $0.00014 por cada 1000 tokens de salida, una solicitud con 500 tokens de entrada y 1500 tokens de salida cuesta aproximadamente $0.0000175 + $0.00021 = $0.0002275.
¿Cuál es la diferencia entre la monitorización LLM y la APM tradicional?
La monitorización tradicional del rendimiento de las aplicaciones se centra en métricas de infraestructura como la CPU, la memoria y la latencia de las solicitudes. La monitorización LLM añade el consumo de tokens, la selección de modelos, los patrones de avisos y la atribución de costes específicos para las cargas de trabajo de IA generativa. Muchas plataformas integran ahora ambas funcionalidades.
¿Puedo controlar los costes en varios proveedores de LLM?
Sí. Plataformas como Datadog LLM Observability admiten múltiples proveedores, incluidos OpenAI, Anthropic y Amazon Bedrock, en un panel de control unificado. Esto permite comparar costos y desarrollar estrategias de enrutamiento entre múltiples proveedores.
¿Cuánto se puede ahorrar realmente optimizando los costes?
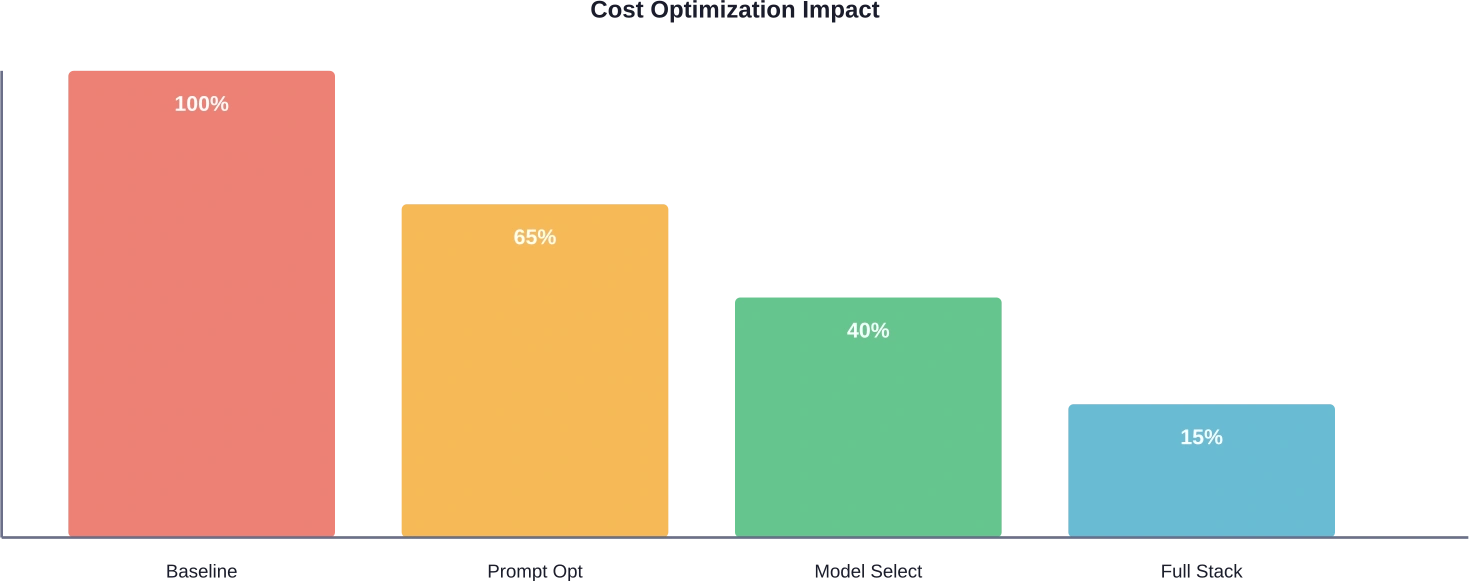
Los resultados de la optimización varían según la aplicación. Las pruebas de AWS mostraron un ahorro potencial de costos de hasta 90% para el flujo de trabajo de Step Functions Express en comparación con el flujo de trabajo estándar en la misma carga de trabajo. La ingeniería de entrega rápida generalmente reduce los costos entre 20 y 40%, la selección de modelos entre 30 y 50% adicionales, y el almacenamiento en caché elimina por completo las llamadas redundantes. El ahorro exacto depende de la eficiencia base y del esfuerzo de optimización.
¿Debería alojar los modelos en mi propio servidor para reducir costes?
El autoalojamiento resulta conveniente a una escala suficiente. Un estudio de ArXiv sobre análisis de costo-beneficio muestra que el punto de equilibrio depende del volumen de uso, las capacidades técnicas y la posibilidad de alcanzar un rendimiento similar al de los modelos comerciales. Para muchas organizaciones, los servicios gestionados siguen siendo más rentables si se tiene en cuenta el tiempo de ingeniería.
¿Con qué frecuencia debo revisar los costos del programa LLM?
Durante la implementación inicial, revise diariamente los paneles de control en tiempo real para detectar problemas de configuración a tiempo. Realice análisis detallados de costos semanalmente durante el desarrollo activo y mensualmente una vez que el uso se estabilice. Configure alertas automáticas para anomalías en lugar de depender únicamente de las revisiones programadas.
¿Qué métricas son las más importantes para la gestión de costes de un máster en Derecho (LLM)?
Realice un seguimiento del costo por sesión de usuario, el costo por tarea completada con éxito, la eficiencia de los tokens (valor de salida por token) y la variación de costos con respecto al presupuesto. Estas métricas vinculan el gasto directamente con los resultados del negocio, en lugar de tratar los costos como gastos de infraestructura abstractos.
Avanzando con el monitoreo de costos de LLM
Gestionar los costes de las solicitudes de máster en derecho (LLM) requiere visibilidad continua, optimización estratégica y disciplina organizativa. El modelo de precios basado en tokens difiere fundamentalmente de los costes de infraestructura tradicionales, lo que exige enfoques de monitorización especializados.
Comience con las herramientas de monitorización nativas de proveedores como OpenAI, Anthropic o AWS Bedrock. Estas funcionalidades integradas proporcionan visibilidad básica sin costes adicionales de plataforma. A medida que las aplicaciones crecen, considere plataformas de observabilidad especializadas como Datadog o Langfuse para funciones avanzadas como compatibilidad con múltiples proveedores y alertas sofisticadas.
El verdadero valor reside en vincular la monitorización con la acción. Controle los costes, identifique oportunidades de optimización mediante ingeniería y selección de modelos eficaces, y mida el impacto de los cambios. Cree mecanismos de retroalimentación que ayuden a los desarrolladores a comprender las implicaciones de los costes durante el desarrollo, en lugar de descubrir problemas en producción.
La optimización de costes no consiste en minimizar el gasto a cualquier precio, sino en maximizar el valor obtenido por cada dólar invertido, manteniendo al mismo tiempo los estándares de calidad y rendimiento. Una base de monitorización adecuada permite alcanzar ese equilibrio.
¿Listo para tomar el control del gasto de LLM? Comience hoy mismo implementando el seguimiento básico de tokens en sus aplicaciones. Las pequeñas mejoras se multiplican rápidamente cuando se aplican de forma consistente en todas las llamadas de LLM.