Resumen rápido: El código asíncrono puede reducir drásticamente los costos de LLM cuando se implementa correctamente, pero errores comunes como el envío de solicitudes por adelantado pueden anular los ahorros. Los patrones asíncronos estratégicos combinados con técnicas como el almacenamiento en caché de avisos, el procesamiento por lotes y la concurrencia controlada pueden reducir los costos entre 60 y 901 TP3T manteniendo el rendimiento. El precio del modelo o3 de OpenAI se redujo de 801 TP3T a 1 TP4T2-8 por millón de tokens a partir de junio de 2025, lo que hace que la implementación asíncrona adecuada sea aún más rentable.
Los costes de LLM pueden dispararse más rápido de lo que la mayoría de los equipos esperan. Lo que empieza como unos pocos scripts de validación o flujos de trabajo basados en agentes se convierte rápidamente en miles de llamadas a la API que consumen los presupuestos a un ritmo alarmante.
Sin embargo, aquí está el problema: la programación asíncrona promete hacer todo más rápido y eficiente. Pero cuando se implementa incorrectamente, en realidad puede... aumentar sus costes dando la ilusión de optimización.
¿El culpable? Patrones sutiles en el código asíncrono que ejecutan todas las solicitudes por adelantado, incluso cuando los procesos posteriores se detienen prematuramente o solo necesitan resultados parciales. Según las discusiones de la comunidad en los foros de desarrolladores de OpenAI, los desarrolladores que migran de implementaciones síncronas a asíncronas suelen encontrarse con picos de costos inesperados a pesar de los tiempos de ejecución más rápidos.
La trampa del coste oculto en el código LLM asíncrono
El código asíncrono parece la opción más lógica para las aplicaciones LLM. Se envían múltiples solicitudes simultáneamente, se procesan los resultados a medida que llegan y se continúa. Ejecución más rápida, usuarios más satisfechos.
Pero existe una trampa latente en los patrones asíncronos más comunes.
Cuando las funciones asíncronas crean todas sus llamadas a la API por adelantado —envolviéndolas en tareas o promesas antes de que se ejecute cualquier lógica de procesamiento— cada solicitud llega a los servidores del proveedor de LLM. Incluso si la lógica de validación se detiene tras el primer fallo. Incluso si el usuario cancela a mitad de camino. Incluso si solo se necesitaban tres resultados, pero se pusieron en cola cincuenta.
Las solicitudes ya se han enviado. Los tokens ya se están procesando. La factura ya está aumentando.
Cómo funciona el despido por solicitud anticipada
Consideremos un script de validación que compruebe las respuestas de LLM según criterios de calidad. Una implementación asíncrona sencilla podría ser la siguiente:
| async def validar_respuestas(prompts): tareas = [call_llm_api(prompt) for prompt in prompts] para tarea en tareas: resultado = esperar tarea Si no cumple_los_criterios(resultado): devolver Falso devolver verdadero |
¿Ves el problema? Esa comprensión de lista en la línea 2 crea todas las tareas de llamada a la API inmediatamente. Antes incluso de que comience el bucle. Antes de que se realice cualquier validación.
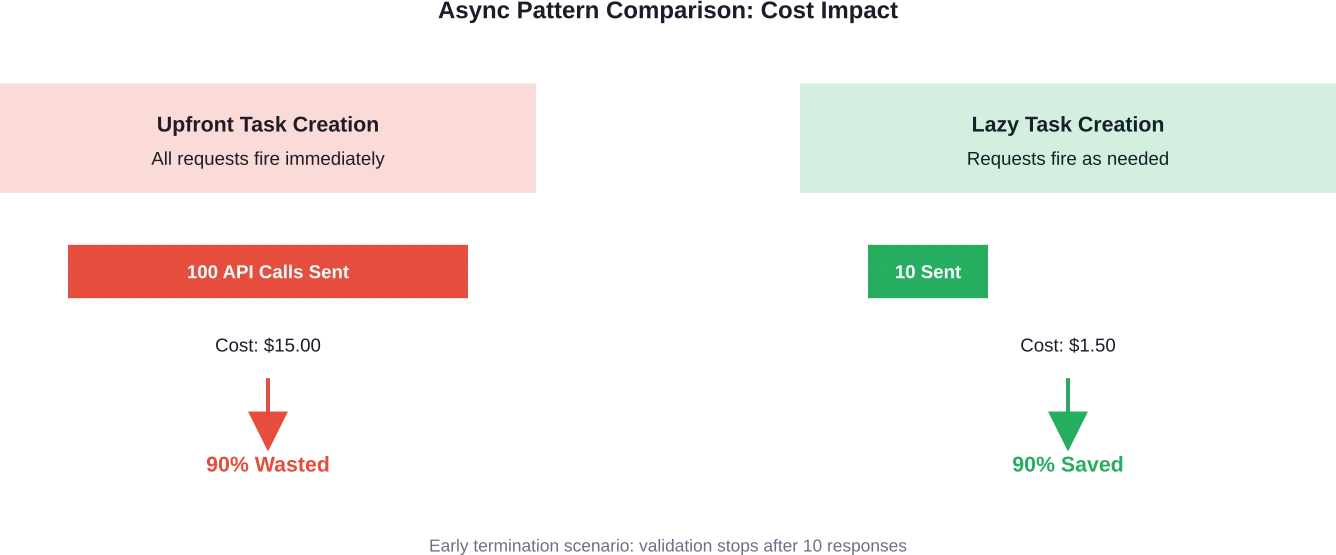
Si el primer resultado no supera la validación, la función devuelve Falso, pero ya hay otras cuarenta y nueve llamadas a la API en curso, consumiendo tokens y generando costes.
Impacto en los costos del mundo real
Un equipo de desarrollo descubrió este problema cuando su script de validación LLM se ejecutaba rápidamente, pero generaba facturas inesperadamente altas. A pesar de haber implementado un código asíncrono aparentemente eficiente, estaban procesando diez veces más tokens de los necesarios.
¿La solución? Cinco líneas de código que reestructuraron la forma en que se creaban y esperaban las tareas. En lugar de crear todas las tareas por adelantado, trasladaron la creación de tareas dentro del bucle, lo que permite la terminación anticipada para evitar llamadas innecesarias a la API.
Resultado: Reducción de costes del 90% prácticamente sin pérdida de velocidad ni funcionalidad.
Concurrencia controlada: La solución de semáforos
Corregir el envío de solicitudes por adelantado es el primer paso. Pero existe otro patrón asíncrono que afecta tanto a los costos como al rendimiento: la concurrencia no controlada.
Cuando las aplicaciones envían cientos o miles de solicitudes LLM simultáneas, crean varios problemas:
- Limitación de velocidad que provoca reintentos y retrasos.
- Latencia inconsistente debido a que la infraestructura del proveedor tiene problemas con los picos de carga.
- Solicitudes fallidas que necesitan reprocesarse, duplicando los costos.
- Presión de memoria derivada de la gestión de demasiadas conexiones simultáneas.
La solución implica el uso de semáforos asyncio, un mecanismo de control de concurrencia que limita la cantidad de solicitudes que se ejecutan simultáneamente.
Implementación de la limitación de velocidad basada en semáforos
Según los debates en la comunidad de OpenAI, los desarrolladores que implementan el control de concurrencia mediante un semáforo asyncio con un límite de 5 llamadas simultáneas observan un rendimiento más consistente. Si bien esto no reduce directamente el uso de tokens, evita la cascada de fallos y reintentos que incrementan los costes.
| import asyncio async def controlled_llm_call(semaphore, prompt): asíncrono con semáforo: return await call_llm_api(prompt) async def process_batch(prompts): semáforo = asyncio.Semáforo(5) tareas = [controlled_llm_call(semaphore, p) for p in prompts] return await asyncio.gather(*tasks) |
Este patrón garantiza que solo se ejecuten cinco solicitudes simultáneamente, lo que reduce los picos de consumo de recursos y estabiliza la latencia.
Pero un momento, aún persiste el problema de la activación inicial. La lista de tareas se crea antes de que se realice cualquier procesamiento. Para optimizar los costos, combine la concurrencia controlada con la creación diferida de tareas.
Almacenamiento en caché de mensajes: El secreto para la reducción de costos del 60%
Ahora hablemos de otro tipo de optimización, una que funciona independientemente de la implementación asíncrona que se utilice.
El almacenamiento en caché de solicitudes aprovecha el hecho de que muchas aplicaciones LLM envían el mismo contexto repetidamente. Artículos de investigación, documentación, instrucciones del sistema, conjuntos de datos de ejemplo: contenido que permanece constante en múltiples consultas.
Cuando se habilita el almacenamiento en caché, el proveedor LLM procesa y almacena este contenido repetido. Las solicitudes posteriores que reutilizan el contenido almacenado en caché solo pagan por los nuevos tokens, no por la solicitud completa.
Cómo funciona el almacenamiento en caché de mensajes
La mayoría de los principales proveedores de LLM ahora ofrecen almacenamiento en caché rápido con mecanismos similares:
- Marca ciertas partes de tu mensaje como almacenables en caché.
- Los procesos de primera solicitud almacenan en caché ese contenido.
- Las solicitudes posteriores dentro de un intervalo de tiempo reutilizan la caché.
- Usted paga tarifas reducidas por los tokens almacenados en caché.
La caché (almacenamiento en caché de avisos) suele mantenerse válida durante 5 a 10 minutos de inactividad. Si el contenido se reutiliza dentro de ese lapso, se obtienen ahorros considerables.
En serio: si tienes un documento de investigación de 30.000 tokens y quieres hacer diez preguntas diferentes sobre él, el almacenamiento en caché cambia la economía por completo.
Sin almacenamiento en caché, el LLM procesa los 30 000 tokens para cada pregunta, lo que suma un total de 300 000 tokens. Con el almacenamiento en caché, se paga el precio completo por la primera solicitud y luego tarifas reducidas por la parte almacenada en caché en las nueve solicitudes siguientes.
| Guión | Total de tokens procesados | Reducción de costos
|
|---|---|---|
| Sin almacenamiento en caché (10 consultas) | 300.000 tokens | Base |
| Con almacenamiento en caché (10 consultas) | ~120.000 tokens | Ahorros 60% |
| Con almacenamiento en caché (50 consultas) | ~180.000 tokens | Ahorros de 88% |
Combinando el almacenamiento en caché con patrones asíncronos
Aquí es donde la cosa se pone interesante. Cuando se combina una implementación asíncrona adecuada con el almacenamiento en caché de solicitudes, el ahorro de costes se multiplica.
El código asíncrono agrupa de forma natural las solicitudes similares en el tiempo, justo lo que necesita el almacenamiento en caché para ser efectivo. Todas las solicitudes que llegan dentro del período de validez de la caché se benefician del mismo contenido almacenado.
Pero si tu implementación asíncrona genera solicitudes innecesarias, esas llamadas adicionales consumen tu presupuesto de contenido en caché sin aportar valor. El ahorro de almacenamiento en caché de 60% se ve anulado por la multiplicación de solicitudes innecesarias por diez.
Si se aciertan ambas cosas, la economía se transforma por completo.
API por lotes: Ahorre tiempo y obtenga enormes ahorros de costes.
La API Batch de OpenAI representa otra estrategia de reducción de costos compatible con el procesamiento asíncrono. Como se comenta en la comunidad de desarrolladores de OpenAI, estos están migrando aproximadamente 4200 llamadas síncronas a la API Batch para aprovechar la ventana de procesamiento de 24 horas y el ahorro de costos.
La disyuntiva es sencilla: aceptar tiempos de procesamiento más largos a cambio de costes significativamente reducidos.
Cuándo tiene sentido el procesamiento por lotes
Las API por lotes funcionan mejor para:
- Procesamiento y análisis de conjuntos de datos
- pipelines de generación de contenido
- Flujos de trabajo de evaluación y prueba
- Cualquier carga de trabajo en la que los resultados inmediatos no sean críticos.
El patrón asíncrono aquí es diferente. En lugar de gestionar solicitudes concurrentes, la aplicación envía un trabajo por lotes y verifica su finalización. El proveedor de LLM optimiza el procesamiento en segundo plano, a menudo redirigiendo las solicitudes a infraestructura menos utilizada o procesándolas durante las horas de menor actividad.
| Patrón asíncrono de la API de lotes # async def submit_batch_job(requests): lote = esperar cliente.lotes.crear( archivo_entrada=archivo_lote_cargado(solicitudes), endpoint=”/v1/chat/completes” ) devolver lote.id async def poll_batch_status(batch_id): mientras que verdadero: lote = esperar cliente.lotes.retrieve(batch_id) Si batch.status == “completed”: return await retrieve_batch_results(batch_id) esperar asyncio.sleep(60) |
El ahorro de costes se debe a la capacidad del proveedor para optimizar la utilización de los recursos. Cuando no se requieren respuestas inmediatas, pueden gestionar las solicitudes de forma más eficiente.

Reduzca los costos de LLM con la arquitectura adecuada.
Los costos de LLM a menudo se deben a patrones de uso ineficientes, solicitudes extensas y canalizaciones de inferencia mal estructuradas. Trabajar con un equipo de ingeniería de IA experimentado como IA superior Puede ayudar a identificar el origen real de los costos. La empresa desarrolla sistemas de IA personalizados y aplicaciones basadas en LLM, incluyendo herramientas de PNL, chatbots y plataformas de análisis de datos. Sus ingenieros diseñan flujos de trabajo de modelos, optimizan la infraestructura y estructuran las implementaciones para que los sistemas escalen sin costos computacionales innecesarios.
¿Busca reducir el coste de impartir su máster en Derecho (LLM)?
Habla con una IA superior a:
- Diseño de pipelines LLM y arquitectura de backend
- desarrollar sistemas de PLN y aplicaciones basadas en IA
- Implementar e integrar modelos en el software existente.
👉 Solicita una consulta de IA con IA superior para hablar sobre tu proyecto de máster en Derecho (LLM).
Panorama actual de precios de los másteres en derecho (LLM) en 2026
Para comprender la optimización de costos, es necesario conocer los precios actuales. En junio de 2025, OpenAI anunció importantes reducciones de precio para su modelo o3: una disminución de 80% con respecto a los precios anteriores.
La nueva estructura de precios de o3:
- Tokens de entrada: $2 por cada millón de tokens
- Tokens de salida: $8 por cada millón de tokens
Según estudios sobre arquitecturas de mezcla de expertos, GPT-4.5 cobraba $150 por la generación de un millón de tokens, lo que resultaba prohibitivo para muchas aplicaciones. La drástica reducción de precio en los modelos más recientes modifica el cálculo de la relación costo-beneficio para las técnicas de optimización.
Dicho esto, incluso con costes por token más bajos, los patrones asíncronos ineficientes pueden generar gastos significativos a gran escala. Un millón de llamadas innecesarias a la API a $2 por millón de tokens de entrada sigue siendo $2.000 desperdiciados.
Patrones asíncronos avanzados para el control de costes de LLM
Más allá de lo básico, varios patrones asíncronos avanzados ofrecen oportunidades adicionales para optimizar los costes.
Precarga de caché KV asíncrona
Las investigaciones sobre la aceleración del rendimiento de la inferencia de LLM mediante la precarga asíncrona de caché KV muestran mejoras significativas en el rendimiento. En las GPU NVIDIA H20, este método logra una aceleración de la inferencia de extremo a extremo de hasta 1,97 veces en los LLM de código abierto más utilizados.
Si bien esta técnica se centra principalmente en la reducción de la latencia en lugar de en el ahorro directo de costes, una inferencia más rápida implica un mayor rendimiento por GPU, lo que reduce los costes de infraestructura por solicitud.
Formación asíncrona en RLHF
Para las organizaciones que entrenan modelos personalizados, el aprendizaje por refuerzo asíncrono (RLHF, por sus siglas en inglés) a partir de la retroalimentación humana ofrece ventajas en la eficiencia computacional. Las investigaciones demuestran que los enfoques asíncronos de RLHF pueden entrenar modelos aproximadamente 40% más rápido que los métodos síncronos tradicionales.
El ahorro de costes se debe a la reducción del tiempo de entrenamiento y a una utilización más eficiente de la GPU. Los marcos de entrenamiento asíncrono, como AsyncFlow, muestran mejoras en el rendimiento de entre 1,76 y 1,82 veces con respecto a las implementaciones de referencia a gran escala.
Respuestas de transmisión con terminación anticipada
Las respuestas de la API en tiempo real permiten otro patrón de optimización de costes: la terminación anticipada en función de la calidad de la respuesta.
En lugar de esperar la respuesta completa, las aplicaciones pueden evaluar los tokens transmitidos en tiempo real y cancelar la solicitud si el resultado no cumple con los umbrales de calidad. Esto evita el desperdicio de tokens en respuestas que finalmente se descartarán.
| async def stream_with_quality_check(prompt): flujo = esperar cliente.chat.completions.create( modelo="gpt-4", mensajes=[{“rol”: “usuario”, “contenido”: mensaje}], transmisión=Verdadero ) acumulado = “” asíncrono para fragmento en flujo: acumulado += chunk.choices[0].delta.content o “” si debería_terminar_temprano(acumulado): esperar flujo.aclose() devolver Ninguno retorno acumulado |
La clave reside en definir controles de calidad adecuados que se ejecuten con la suficiente rapidez para aportar valor: comprobar si hay contenido prohibido, respuestas fuera de tema o infracciones de formato.
Medición y seguimiento de la eficiencia de costos asíncronos
La optimización sin medición es una mera conjetura. Un control de costes eficaz requiere el seguimiento de las métricas adecuadas.
Indicadores clave para el seguimiento
| Métrico | Lo que revela | Objetivo
|
|---|---|---|
| Tokens por solicitud | Eficiencia y tiempos de respuesta rápidos | Minimizar sin pérdida de calidad |
| Tasa de aciertos de caché | Con qué frecuencia se reutiliza el contenido almacenado en caché. | Por encima de 70% para cargas de trabajo repetitivas |
| Tasa de solicitudes fallidas | Costos de reintento por errores y limitación de velocidad | Por debajo de 2% |
| Tasa de terminación anticipada | Con qué frecuencia las solicitudes se detienen antes de completarse. | Seguimiento en relación con el ahorro de costes |
| Número de solicitudes simultáneas | Carga en la infraestructura del proveedor | Límites de coincidencia de semáforo |
| Coste por resultado satisfactorio | Coste real, incluidos los fallos y los reintentos. | Objetivo de optimización principal |
Implementación del seguimiento de costos
La mayoría de los proveedores de LLM ofrecen paneles de control de uso, pero estos suelen mostrar datos agregados. Para una optimización más precisa, implemente el seguimiento a nivel de solicitud en su aplicación.
Según los debates de la comunidad sobre el uso de la API, la visualización de los cargos agrupados por partida revela patrones importantes. Algunos desarrolladores descubrieron variaciones inexplicables en el uso de tokens que solo se hicieron visibles mediante un seguimiento detallado.
Envuelve tus llamadas a la API con instrumentación que registre:
- Fecha y hora de la solicitud y latencia
- Recuentos de tokens de entrada y salida
- Estado de acierto/fallo de la caché
- Tipos de errores e intentos de reintento
- Coste real basado en los precios actuales.
Estos datos permiten identificar anomalías en los costes antes de que se conviertan en problemas presupuestarios.
Implementación en el mundo real: Un enfoque paso a paso
Bien, ¿cómo se implementan realmente estas optimizaciones de costes en una aplicación real?
Comience con una auditoría de los patrones asíncronos actuales. Busque estas señales de alerta:
- Comprensiones de listas que crean todas las tareas antes de cualquier instrucción await.
- Llamadas asyncio.gather() sin límites de concurrencia
- No se solicita configuración de caché a pesar del contenido repetitivo.
- Trabajos por lotes síncronos que podrían migrar a API de procesamiento por lotes.
- Falta de manejo de errores que provoca reintentos costosos.
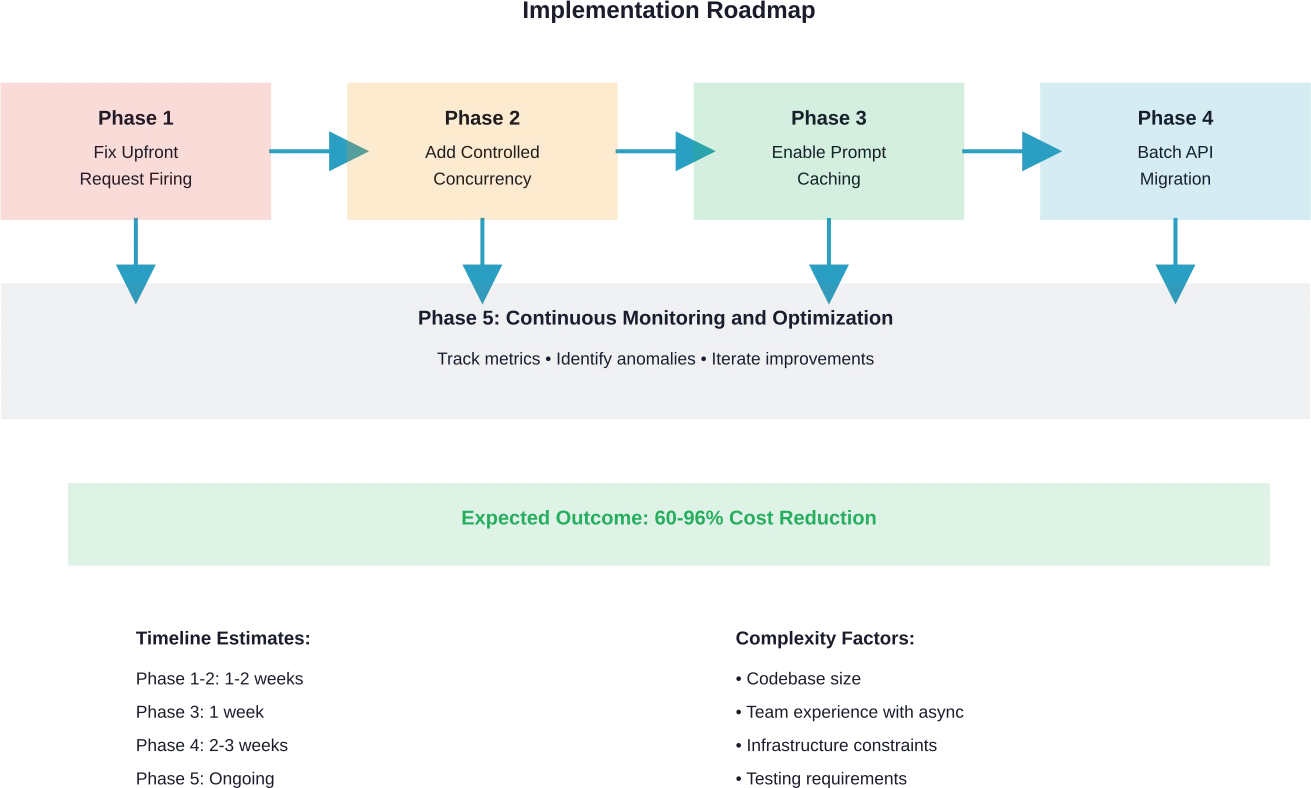
Fase 1: Corregir el disparo de la solicitud inicial
Identificar las funciones que crean todas las tareas antes de que comience el procesamiento. Refactorizar para la creación diferida de tareas:
| # Antes: Todas las tareas creadas por adelantado async def process_items(items): tareas = [procesar_elemento(elemento) para elemento en elementos] para tarea en tareas: resultado = esperar tarea Si no se valida(resultado): devolver Falso # Después: Tareas creadas según sea necesario async def process_items(items): para cada elemento en elementos: resultado = esperar a procesar_elemento(elemento) Si no se valida(resultado): devolver Falso |
Este simple cambio puede eliminar entre 50 y 90% solicitudes innecesarias en flujos de trabajo con lógica de terminación anticipada.
Fase 2: Agregar concurrencia controlada
Implementar semáforos para evitar problemas de límite de velocidad:
| Clase LLMClient: def __init__(self, max_concurrent=5): self.semaphore = asyncio.Semaphore(max_concurrent) self.cliente = OpenAI() async def call(self, prompt): asíncrono con self.semaphore: return await self.client.chat.completes.create( modelo="gpt-4", mensajes=[{“rol”: “usuario”, “contenido”: mensaje}] ) |
Fase 3: Habilitar el almacenamiento en caché de mensajes
Estructura las indicaciones para maximizar la reutilización de la caché. Coloca el contenido estático al principio y márcalo como almacenable en caché según la API de tu proveedor.
Fase 4: Trasladar las cargas de trabajo adecuadas al procesamiento por lotes.
Evalúe qué flujos de trabajo pueden tolerar respuestas demoradas. Los procesos de procesamiento de conjuntos de datos, generación de contenido y evaluación son los principales candidatos.
Fase 5: Implementar el monitoreo
Agregue el seguimiento de costos para medir el impacto de las optimizaciones e identificar nuevas oportunidades.
Errores comunes y cómo evitarlos
Incluso con las mejores intenciones, la optimización de costos asíncrona puede fallar. Estas son las trampas más comunes.
Sobreoptimización a expensas de la latencia
Reducir la concurrencia de forma demasiado drástica evita problemas de limitación de velocidad, pero aumenta drásticamente el tiempo total de ejecución. Un límite de semáforo de 1 podría eliminar la limitación de velocidad, pero también serializa todas las solicitudes.
Encuentra el punto óptimo mediante pruebas. Comienza con límites conservadores y auméntalos gradualmente mientras monitoreas las tasas de error.
Confusión sobre la invalidación de la caché
El almacenamiento en caché de mensajes funciona de maravilla hasta que el contenido almacenado en caché se vuelve obsoleto. Las aplicaciones que actualizan documentos de referencia o instrucciones del sistema necesitan estrategias de invalidación de caché.
La mayoría de los proveedores gestionan esto automáticamente mediante la caducidad programada, pero tenga en cuenta el plazo. Si se producen cambios importantes en el contenido, esperar 10 minutos a que caduque la caché podría resultar inaceptable.
Ignorar los costos de las solicitudes fallidas
Muchas implementaciones asíncronas se centran en las solicitudes exitosas e ignoran el costo de los fallos. Los errores de límite de velocidad, los tiempos de espera agotados y los fallos de validación suelen provocar reintentos que multiplican los costos.
Realiza un seguimiento independiente de las solicitudes fallidas e implementa un retroceso exponencial con límites máximos de reintentos.
Migración prematura de la API de procesamiento por lotes
Trasladar las cargas de trabajo al procesamiento por lotes sin comprender sus requisitos de latencia provoca problemas en la experiencia del usuario. No todas las cargas de trabajo "no críticas" pueden tolerar retrasos de 24 horas.
Comience con cargas de trabajo verdaderamente asíncronas, como el procesamiento de conjuntos de datos durante la noche, antes de tocar cualquier cosa que esté orientada al usuario.
Preguntas frecuentes
¿Cuánto puede reducir de forma realista la optimización asíncrona los costes de LLM?
La reducción de costos depende en gran medida de los patrones de implementación actuales. Las aplicaciones con lógica de envío de solicitudes anticipado y terminación temprana pueden experimentar reducciones de entre 60 y 901 TP3T. Las aplicaciones que ya utilizan patrones asíncronos eficientes podrían obtener ahorros de entre 20 y 401 TP3T solo con el almacenamiento en caché y el procesamiento por lotes. La clave está en identificar dónde se producen las solicitudes innecesarias en el flujo de trabajo actual.
¿El almacenamiento en caché de mensajes instantáneos funciona con todos los proveedores de LLM?
La mayoría de los principales proveedores ofrecen ahora almacenamiento en caché instantáneo o funciones similares, pero los detalles de implementación varían. Consulte la documentación del proveedor para conocer los requisitos específicos sobre el tamaño mínimo de la caché, la duración de la misma y las estructuras de precios. Algunos proveedores almacenan la caché automáticamente, mientras que otros requieren una configuración explícita.
¿Qué límite de concurrencia debo usar con los semáforos?
Comience con 5 a 10 solicitudes simultáneas y supervise los errores de límite de velocidad. Si observa una limitación constante, reduzca el límite. Si la tasa de errores es baja y la latencia es aceptable, auméntelo gradualmente. El límite óptimo depende de los límites de velocidad de su proveedor, el tamaño de las solicitudes y los requisitos de latencia de la aplicación. Según las discusiones de la comunidad, los límites entre 5 y 10 funcionan bien para la mayoría de las aplicaciones.
¿Puedo combinar las respuestas en tiempo real con el almacenamiento en caché de las solicitudes?
Sí, la transmisión en tiempo real y el almacenamiento en caché son complementarios. El contenido de las solicitudes almacenado en caché reduce la cantidad de tokens que deben procesarse, mientras que la transmisión en tiempo real proporciona acceso anticipado a los resultados y permite una finalización temprana. Esta combinación ofrece ventajas tanto en términos de costo como de latencia.
¿Cómo puedo medir si las optimizaciones realmente están generando ahorros?
Implemente un sistema de seguimiento de costos a nivel de solicitud que registre el número de tokens y calcule los costos según los precios vigentes. Compare los costos antes y después de los cambios de optimización durante períodos de carga de trabajo equivalentes. Según las recomendaciones de la comunidad, visualizar el uso agrupado por partida en los paneles de control del proveedor revela patrones de costos detallados que las vistas agregadas no muestran.
¿Debo optimizar primero el coste o la latencia?
Esto depende de los requisitos de la aplicación. Las funciones orientadas al usuario suelen priorizar la latencia manteniendo costos aceptables. El procesamiento en segundo plano puede tolerar una mayor latencia para ahorrar costos. Comience por eliminar el desperdicio: solicitudes innecesarias que no aportan valor independientemente de la velocidad. Luego, equilibre la relación costo-latencia según los casos de uso específicos.
¿Qué ocurre con las solicitudes en curso cuando mi aplicación falla?
Las solicitudes asíncronas enviadas a los proveedores de LLM continúan procesándose incluso si su aplicación finaliza. El proveedor sigue cobrando por las solicitudes completadas. Implemente controladores de cierre adecuados que cancelen las solicitudes pendientes y cierren correctamente los bucles de eventos asíncronos para evitar solicitudes huérfanas que generen cargos sin entregar resultados.
Reflexiones finales: Cómo aprovechar la programación asíncrona para su presupuesto
La programación asíncrona no es intrínsecamente buena ni mala para los costes de LLM; es una herramienta que requiere una implementación cuidadosa.
Los patrones que hacen que el código se ejecute más rápido también pueden hacer que las facturas se disparen si se realizan solicitudes innecesarias. Pero cuando se implementa correctamente, la programación asíncrona permite estrategias de optimización de costos que el código síncrono simplemente no puede igualar.
Comience con una auditoría honesta de los patrones asíncronos actuales. Busque la creación de tareas al inicio, la concurrencia descontrolada y las oportunidades de almacenamiento en caché desaprovechadas. Solucione primero los problemas más importantes, que suelen ser el envío de solicitudes al inicio en flujos de trabajo con terminación anticipada.
A continuación, se pueden añadir optimizaciones adicionales: almacenamiento en caché instantáneo para contenido repetitivo, procesamiento por lotes para cargas de trabajo no urgentes y transmisión con controles de calidad para funciones en tiempo real.
Y, sobre todo, mídelo todo. Registra los tokens, los costes, la latencia y las tasas de error a nivel de solicitud. Los datos revelarán oportunidades de optimización que no son evidentes solo con la inspección del código.
El panorama de costes de LLM sigue evolucionando. La reducción de precio 80% de OpenAI para los modelos o3 en junio de 2025 cambió significativamente la economía. Pero incluso con costes por token más bajos, la eficiencia es fundamental a gran escala.
¿Listo para reducir los costos de tu LLM? Empieza hoy mismo revisando tus patrones de implementación asíncrona. Las soluciones de cinco líneas que eliminan las solicitudes innecesarias suelen ser las que mayor impacto generan con menor esfuerzo.