Resumen rápido: Las mejores plataformas de análisis LLM para el seguimiento de costos y calidad en 2026 incluyen Confident AI para el monitoreo centrado en la evaluación con precios basados en el uso, Langfuse para la observabilidad de código abierto con seguimiento de sesiones y Datadog LLM Observability para el rastreo a escala empresarial. MiniMax M2.5 se destaca como el modelo más rentable con una sólida calidad analítica, mientras que los marcos de AgServe demuestran cómo el servicio con reconocimiento de sesiones puede lograr una calidad equivalente a GPT-4o con un costo de 16,51 TP3T.
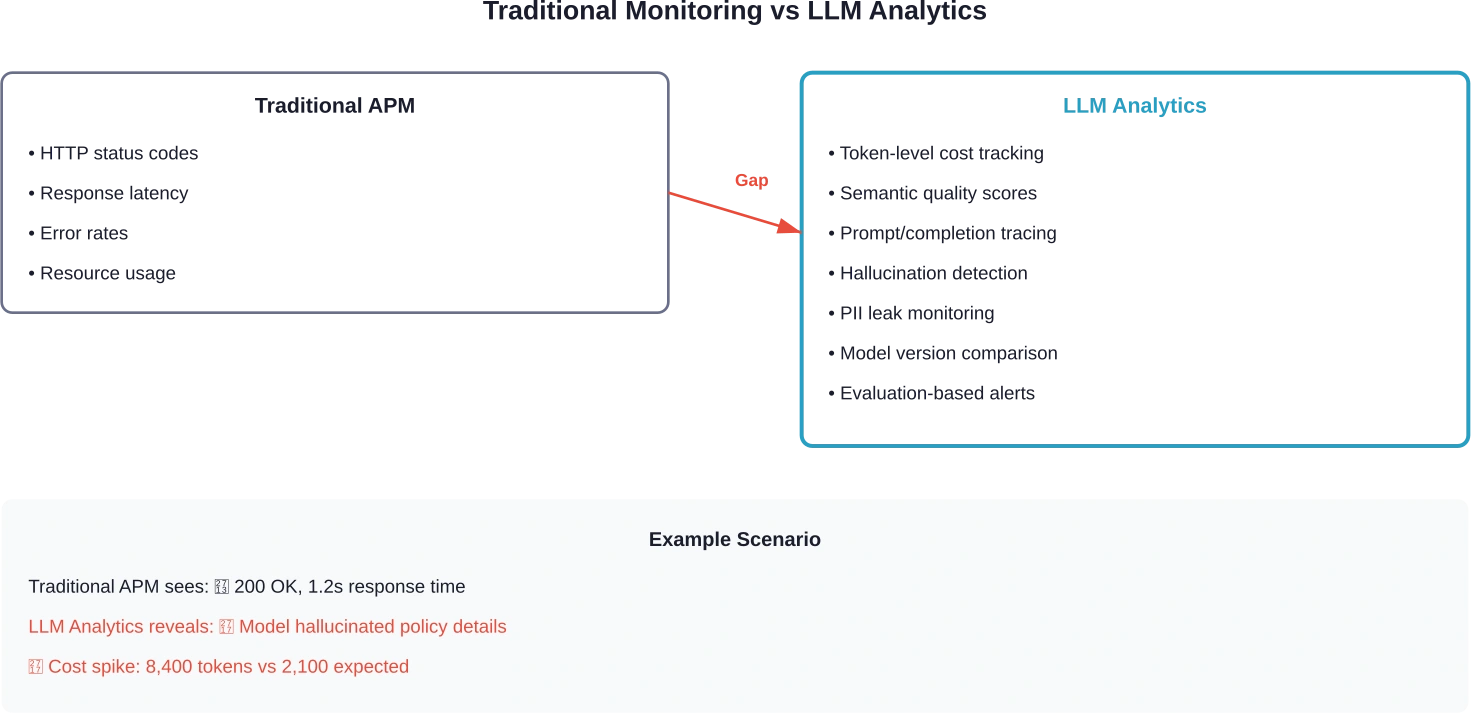
La monitorización tradicional no detecta los fallos de la IA. Un panel de control de APM podría mostrar una respuesta 200 en 1,2 segundos, pero no revelará que el modelo olvidó un detalle de la política, filtró información confidencial o se desvió del tema a mitad de la conversación.
Esa es la brecha que cubren las herramientas de análisis LLM. Rastrean las solicitudes y las finalizaciones, calculan los costos de los tokens por solicitud, detectan desviaciones de calidad entre versiones del modelo y exponen patrones de fallas que las plataformas de observabilidad estándar pasan por alto por completo.
A medida que las aplicaciones basadas en LLM escalan desde el prototipo hasta la producción, los costos de los tokens pueden dispararse rápidamente. Una sola cadena de mensajes no optimizada puede multiplicar los gastos por diez. Sin visibilidad en tiempo real de los patrones de uso, los equipos suelen descubrir los sobrecostos presupuestarios solo cuando el daño ya está hecho.
Esta guía analiza las principales plataformas de análisis LLM para el seguimiento de costes y calidad. Explicaremos las diferencias entre cada herramienta, compararemos los precios de los distintos proveedores y determinaremos qué plataformas se adaptan mejor a cada escenario de implementación.
Por qué es importante el seguimiento de costes y calidad del programa LLM
Los sistemas de IA en producción fallan de forma diferente al software tradicional. Un servidor web devuelve datos o genera un error. Pero un LLM puede devolver JSON con formato perfecto que contiene información completamente inventada.
El control de costes supone otro desafío. El sistema de precios basado en tokens implica que cada modificación de las indicaciones altera la economía. Añadir contexto para mejorar la calidad podría triplicar el coste por solicitud. Cambiar de GPT-4 a un modelo más pequeño podría reducir los costes en 90%, pero degradaría la precisión de la salida por debajo de los umbrales aceptables.
Según investigaciones sobre sistemas de agentes, las plataformas de modelos existentes carecen de conocimiento de la sesión, lo que genera compromisos innecesarios entre costo y calidad. El marco AgServe demuestra que la gestión de caché KV con conocimiento de la sesión y la cascada de modelos basada en la calidad pueden lograr una calidad de respuesta comparable a la de GPT-4o con tan solo 16,51 TP3T del costo.
Esto es lo que permite un análisis adecuado del programa LLM:
- Atribución de costos a nivel de token en todas las indicaciones, usuarios, funciones y versiones del modelo
- detección de deriva de calidad mediante puntuaciones de evaluación automatizadas y ciclos de retroalimentación humana
- Seguimiento de latencia que separa el tiempo de respuesta de la API del tiempo de procesamiento del modelo.
- Análisis de patrones de fallas que pone de manifiesto desencadenantes comunes de alucinaciones o errores de formato.
- Vigilancia de seguridad por fugas de información personal identificable, intentos de inyección rápida y violaciones de la política de contenido
Sin estas capacidades, los equipos trabajan a ciegas. No pueden optimizar las decisiones de ingeniería, no pueden demostrar el retorno de la inversión a las partes interesadas y no pueden detectar la degradación de la calidad antes de que afecte a los usuarios.
¿Qué diferencia a LLM Analytics de la observabilidad estándar?
Las herramientas APM estándar registran las solicitudes, los errores y la latencia. Esto es necesario, pero insuficiente para las aplicaciones LLM.
La diferencia fundamental: los análisis de LLM deben evaluar la calidad semántica de resultados, no solo si la llamada a la API tuvo éxito. Un código de estado 200 no indica si el consejo del modelo fue preciso, relevante o seguro.
Tres capacidades distinguen el análisis específico de LLM de la monitorización tradicional:
Cálculo de costos basado en tokens
Cada llamada a la API consume tokens de entrada (la solicitud) y tokens de salida (la finalización). Los costos varían según el modelo, el tipo de token y, a veces, la hora del día. Para un seguimiento adecuado de los costos, es necesario analizar los metadatos de uso de cada respuesta de la API y asignarlos al centro de costos correcto.
Según la documentación de Anthropic sobre gestión de costes, el comando /cost proporciona estadísticas detalladas sobre el uso de tokens, incluyendo el coste total, la duración de la API, la duración real y los cambios en el código. Este seguimiento detallado permite a los equipos identificar las operaciones costosas antes de que se amplíen.
Métricas de calidad basadas en la evaluación
La calidad no se puede inferir a partir de los códigos de estado HTTP. Las plataformas de análisis solucionan esto mediante evaluaciones automatizadas en cada finalización. Estas evaluaciones comprueban si hay errores, miden la relevancia con respecto a los resultados esperados, verifican el cumplimiento del formato e identifican posibles infracciones de seguridad.
La investigación de Anthropic sobre la evaluación de agentes destaca que las buenas evaluaciones ayudan a los equipos a implementar agentes de IA con mayor confianza. Sin ellas, los equipos se estancan en ciclos reactivos, detectando los problemas solo en producción, donde solucionar un fallo genera otros.
Seguimiento de solicitudes y finalización
Los registros estándar capturan los puntos finales y los códigos de estado. El rastreo LLM captura el ciclo completo de finalización de la solicitud, incluyendo mensajes del sistema, entradas del usuario, llamadas a funciones, parámetros del modelo y la salida final. Este contexto es esencial para depurar problemas de calidad y optimizar las solicitudes.
La guía de OpenAI sobre evaluación con Langfuse demuestra cómo el seguimiento de los pasos internos de los flujos de trabajo de los agentes permite implementar estrategias de evaluación tanto en línea como fuera de línea que los equipos utilizan para llevar a los agentes a producción de forma fiable.
Las mejores plataformas de análisis de datos para másteres en derecho (LLM) en 2026
El mercado de análisis de datos para programas de maestría en derecho (LLM) ha madurado significativamente. Actualmente, las plataformas se dividen en tres categorías: herramientas centradas en la evaluación, marcos de observabilidad de código abierto y suites de monitoreo empresarial.
Así se comparan las principales plataformas:
IA segura
Confident AI centra la monitorización de la calidad de LLM en las evaluaciones y las métricas de calidad estructuradas, en lugar de la observabilidad al estilo APM. Integra en una única plataforma la puntuación automatizada de las evaluaciones, el seguimiento de LLM, la detección de vulnerabilidades y la retroalimentación humana.
Esta herramienta resulta ideal para equipos que priorizan el control de calidad sobre la observabilidad general. Cada traza se evalúa automáticamente según métricas configurables como la relevancia, la tasa de alucinaciones y el cumplimiento del formato.
Características principales:
- Biblioteca de evaluación integrada con más de 20 métricas de calidad.
- Soporte personalizado para evaluadores en controles de calidad específicos del dominio.
- Integración de la retroalimentación humana para los flujos de trabajo RLHF
- Análisis de vulnerabilidades para inyección rápida y fuga de información personal identificable (PII).
- Control de versiones de conjuntos de datos para pruebas de regresión
Precios: Con precios basados en el uso, resulta una opción accesible para equipos con volúmenes de trazas moderados. Se recomienda evaluar la previsión de costes durante el periodo de implementación.
Ideal para: Equipos centrados en el aseguramiento de la calidad y en ciclos de desarrollo basados en la evaluación.
Langfuse
Langfuse ofrece observabilidad LLM de código abierto con seguimiento completo de la finalización de las solicitudes, seguimiento de costos a nivel de token y monitoreo de calidad. La plataforma admite modelos de implementación tanto autoalojados como en la nube.
Según la guía de OpenAI sobre la evaluación de agentes con Langfuse, la plataforma supervisa los pasos internos del agente y permite el uso de métricas de evaluación tanto en línea como fuera de línea por parte de los equipos para llevar a los agentes a producción de forma fiable.
Langfuse destaca por su seguimiento con reconocimiento de sesiones, agrupando trazas relacionadas en sesiones para facilitar el análisis de conversaciones de varios turnos y flujos de trabajo de agentes.
Características principales:
- Trazas ilimitadas en el plan Pro
- Seguimiento de conversaciones basado en sesiones
- Puntuación de evaluación en tiempo real
- Atribución de costos por usuario, función o modelo
- Núcleo de código abierto con opción de nube empresarial.
Precios: Langfuse Cloud ofrece un plan Hobby (50.000 unidades al mes gratis), un plan Core ($29 al mes + uso) y un plan Pro ($199 al mes + uso). Ambos planes de pago incluyen 100.000 unidades, con un consumo adicional a partir de $8 por cada 100.000 unidades.
Ideal para: Equipos que desean la flexibilidad del código abierto con alojamiento en la nube opcional, especialmente para aplicaciones conversacionales de múltiples turnos.
Helicone
Helicone proporciona una observabilidad LLM ligera centrada en la optimización de costes. La plataforma actúa como una capa intermedia entre las aplicaciones y las API de LLM, capturando todas las solicitudes sin necesidad de modificar el código.
La arquitectura de proxy simplifica la implementación. Basta con cambiar el punto final de la API y Helicone empieza a registrar las solicitudes inmediatamente. Esta simplicidad tiene sus inconvenientes: menor flexibilidad para evaluaciones personalizadas y ausencia de métricas de calidad integradas.
Características principales:
- Integración sin código mediante proxy API
- Seguimiento del uso de tokens en todos los modelos.
- Control de costes y alertas presupuestarias
- Capa de análisis de latencia y almacenamiento en caché
- Soporte para más de 10 proveedores de LLM
Precios: El plan gratuito incluye 10 000 solicitudes al mes. El plan Pro comienza en $79/mes con precios basados en el uso.
Ideal para: Equipos que necesitan visibilidad rápida de los costes sin necesidad de realizar evaluaciones exhaustivas.
Observabilidad de Datadog LLM
Datadog ha ampliado su plataforma de monitorización empresarial para abarcar las aplicaciones LLM. Esta integración permite visualizar los rastros de LLM en el mismo panel de control que las métricas de infraestructura, los datos de APM y los registros.
Esta visión unificada ayuda a los equipos a correlacionar el rendimiento de LLM con el comportamiento del sistema subyacente. Las duraciones de finalización lentas podrían estar relacionadas con la latencia de la base de datos. Los picos de costos podrían coincidir con lanzamientos de funciones específicas.
Características principales:
- Monitorización unificada en toda la infraestructura y la capa LLM.
- Seguimiento de costes en tiempo real y detección de anomalías
- Desglose del uso de tokens por punto final y usuario
- Compatibilidad con métricas personalizadas para KPI específicos de dominio.
- Características de seguridad y cumplimiento empresarial
Precios: Integrado con la suscripción existente de Datadog. Consulta el sitio web oficial para conocer los planes actuales adaptados a las necesidades de observabilidad de LLM.
Ideal para: Equipos empresariales que ya utilizan Datadog y desean consolidar la monitorización LLM en su infraestructura de observabilidad existente.
Tejido de pesos y sesgos
Weave amplía las capacidades de seguimiento de experimentos de W&B a las aplicaciones LLM. Realiza un seguimiento de las plantillas de indicaciones, los parámetros del modelo y los resultados en todos los experimentos, lo que facilita la comparación de las variaciones de las indicaciones y las configuraciones del modelo.
La plataforma destaca por su capacidad de evaluación offline. Los equipos pueden capturar trazas de producción, reproducirlas con diferentes modelos o parámetros y medir las diferencias de calidad antes de implementar los cambios.
Características principales:
- Flujo de trabajo centrado en experimentos para una optimización rápida
- Evaluación sin conexión con reproducción de trazas
- Seguimiento de costos por experimento y variante del modelo
- Integración con las herramientas del ciclo de vida de aprendizaje automático de W&B.
- Gestión de conjuntos de datos para pruebas de referencia
Precios: Plan gratuito disponible. Planes para equipos y empresas con precios basados en el uso; consulte el sitio web oficial para conocer las tarifas actuales.
Ideal para: Equipos de aprendizaje automático que realizan experimentos exhaustivos de optimización de la inmediatez y que necesitan capacidades de evaluación fuera de línea.
| Plataforma | Seguimiento de costos | Métricas de calidad | Conciencia de la sesión | Precio inicial
|
|---|---|---|---|---|
| IA segura | Sí | Más de 20 evaluaciones integradas | Básico | Basado en el uso |
| Langfuse | Sí | Evaluadores personalizados | Avanzado | Gratis / $249/mes |
| Helicone | Sí | Limitado | No | Gratis / $79/mes |
| Datadog LLM | Sí | Métricas personalizadas | Básico | Precios para empresas |
| Tejido W&B | Sí | Centrado en la experimentación | Repetición sin conexión | Nivel gratuito disponible |

Construya sistemas LLM con un control claro de costos y calidad.
Las aplicaciones de gestión del aprendizaje automático (LLM) necesitan visibilidad sobre el rendimiento de los modelos en producción. El seguimiento de las indicaciones, las respuestas, el uso de tokens y el comportamiento del sistema ayuda a los equipos a mantener la calidad y comprender cómo se utilizan realmente sus sistemas de IA. IA superior Desarrolla plataformas de IA donde los modelos de lenguaje se integran con sistemas de backend, flujos de datos y herramientas analíticas. Sus ingenieros crean software de IA que admite el registro, la evaluación y la monitorización para que las aplicaciones LLM se puedan gestionar de forma fiable en producción.
¿Despliega una aplicación LLM en producción?
Habla con una IA superior a:
- desarrollar aplicaciones basadas en LLM y herramientas de PLN
- Integrar los flujos de trabajo de monitoreo y análisis.
- Implementar sistemas de IA dentro de las plataformas de software existentes
👉 Contacto IA superior para hablar sobre su proyecto de desarrollo de IA.
Cómo elegir el modelo adecuado para un análisis rentable
La elección de la plataforma es importante, pero la selección del modelo determina el costo real y los resultados en cuanto a calidad. Las recientes comparativas revelan diferencias significativas en la capacidad de los modelos para gestionar cargas de trabajo analíticas.
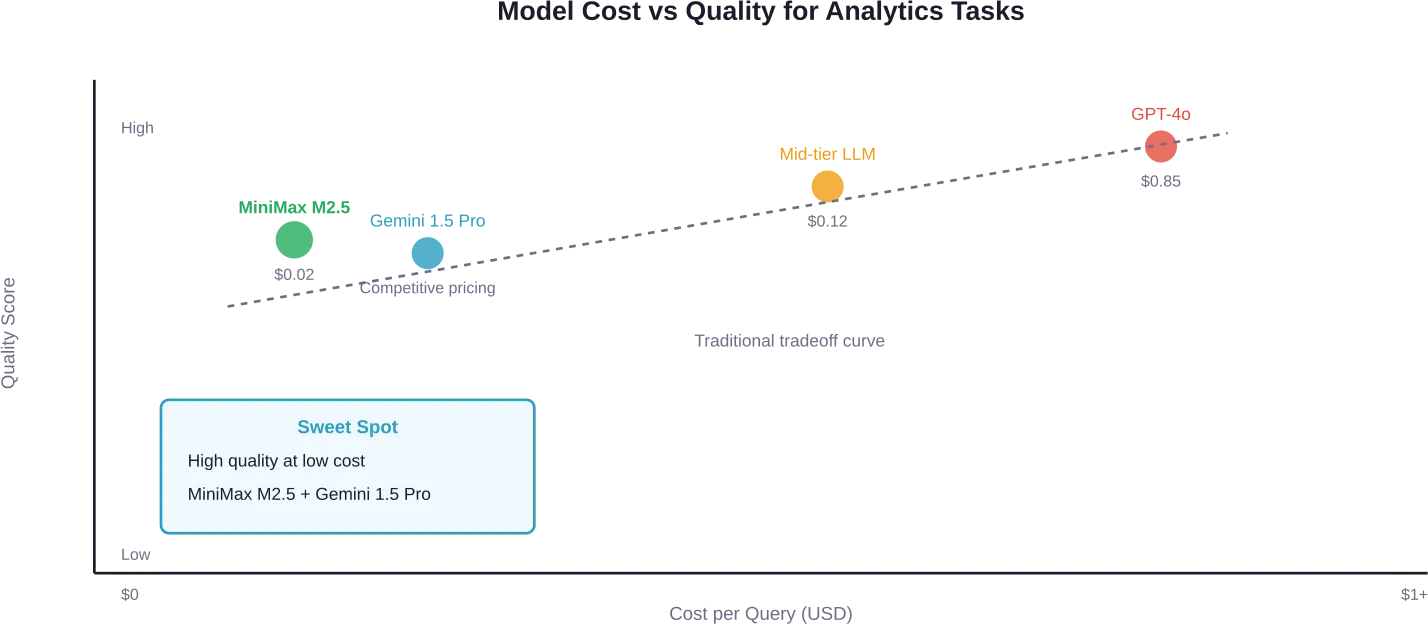
Según las pruebas realizadas con datos reales de Google Analytics, MiniMax M2.5 ofreció una calidad excelente en múltiples ejecuciones de prueba, costó $0.02 por consulta y logró un tiempo medio de finalización de 70 segundos.
La evaluación comparativa analizó los modelos en varias dimensiones:
- Calificación de calidad: ¿El modelo proporcionó información útil más allá de los datos brutos?
- Puntuación de precisión: ¿Con qué precisión utilizó las dimensiones y métricas reales de GA4?
- Coste por consulta: Coste total de la API para completar la tarea analítica
- Estado latente: Tiempo transcurrido desde la presentación puntual hasta la finalización
Para análisis estratégicos que requieren un razonamiento más profundo, Gemini 1.5 Pro demostró un rendimiento sólido. Identificó de inmediato fallos en el seguimiento de atribución en los datos de prueba y se centró en un análisis de conversión práctico. A estos precios, los equipos pueden ejecutar cientos de consultas diarias con un coste mínimo.
Las investigaciones sobre la selección de modelos LLM para tareas complejas de múltiples etapas confirman estos hallazgos. El marco MixLLM demostró que, en comparación con el uso de un único modelo LLM comercial potente, la selección adaptativa de modelos mejora la calidad de los resultados en 1-16%, al tiempo que reduce el coste de inferencia en 18-92%.
Marco de compensación entre costo y calidad
Las investigaciones sobre cómo superar las compensaciones entre costo y calidad en el servicio de agentes revelan que las arquitecturas conscientes de la sesión pueden romper la curva de compensación tradicional. AgServe logra una calidad de respuesta comparable a la de GPT-4o con un costo de 16,5% mediante dos innovaciones:
- Gestión de caché KV con reconocimiento de sesión: El marco utiliza la eliminación basada en el tiempo estimado de llegada y la calibración de incrustación posicional in situ para aumentar drásticamente las tasas de reutilización de la caché. Esto reduce los cálculos redundantes en sesiones de múltiples turnos.
- Modelo en cascada con conciencia de la calidad: En lugar de comprometerse con un único modelo para toda la sesión, AgServe realiza una evaluación de calidad en tiempo real y actualiza los modelos a mitad de la sesión cuando es necesario. Esto permite comenzar con modelos más económicos y aumentar la escala solo cuando la calidad lo requiere.
La investigación demuestra una mejora de 1,8 veces en la calidad en relación con la curva tradicional de compensación entre coste y calidad, lo que prueba de forma efectiva que las elecciones arquitectónicas adecuadas pueden ofrecer mejores resultados a costes más bajos simultáneamente.
Métricas clave para el seguimiento
Para que el análisis de LLM sea efectivo, es necesario realizar un seguimiento de las métricas adecuadas. Muchos equipos se centran exclusivamente en el coste o la latencia, ignorando las señales de calidad que predicen la satisfacción del usuario.
Métricas de costos
- Consumo de tokens por solicitud: Mida los tokens de entrada y salida por separado. Las estrategias de optimización difieren: reducir los tokens de entrada requiere una ingeniería rápida, mientras que controlar los tokens de salida exige mejores parámetros de muestreo o restricciones de formato.
- Coste por interacción de usuario: Calcula el coste total de los tokens en todas las llamadas a la API necesarias para completar una tarea de usuario. Una sola pregunta del usuario puede desencadenar varias llamadas al modelo (recuperación, razonamiento, formato), y el coste total es más importante que el coste de cada llamada individual.
- Coste por función o punto final: La atribución permite analizar el retorno de la inversión (ROI). ¿Qué funcionalidades generan valor que justifique sus costes de gestión de clientes potenciales (LLM)? ¿Cuáles generan un gran gasto de tokens sin un beneficio proporcional para el usuario?
La documentación de Anthropic sobre la gestión de costes hace hincapié en el seguimiento de los patrones de uso con el comando /stats, que proporciona visibilidad a nivel de sesión sobre el uso de tokens, la duración de la API, el tiempo real transcurrido y los cambios en el código.
Métricas de calidad
- Tasa de alucinaciones: Porcentaje de respuestas que contienen información inventada sin el contexto proporcionado. Esto requiere una verificación automatizada de los hechos comparándola con documentos fuente o bases de conocimiento.
- Puntuación de relevancia: ¿Qué tan bien responde la solución a la consulta real del usuario? La similitud semántica entre la pregunta y la respuesta proporciona una métrica aproximada.
- Cumplimiento del formato: Para resultados estructurados (JSON, CSV, SQL), ¿qué porcentaje de autocompletados se analizan correctamente sin errores?
- Infracciones de seguridad: Frecuencia de resultados que contienen información de identificación personal, contenido ofensivo o respuestas a intentos de inyección de mensajes.
Una investigación sobre la evaluación de la calidad de la cadena de pensamiento en la generación de código reveló que los factores externos representan el 53,601% de los errores (principalmente requisitos poco claros y falta de contexto), mientras que los factores internos representan el 40,101% (principalmente inconsistencias entre el razonamiento y las indicaciones). Esto sugiere que monitorear tanto la calidad de la entrada como los patrones de razonamiento del modelo es importante para mantener los estándares de salida.
Métricas de rendimiento
- Tiempo hasta el primer token (TTFT): Latencia antes de que el modelo comience a transmitir la salida. Fundamental para la percepción de la capacidad de respuesta en las interfaces de chat.
- Tokens por segundo: La velocidad de generación disminuye una vez que comienza la transmisión. Las velocidades más lentas frustran a los usuarios que esperan largas esperas para que finalicen.
- Latencia de extremo a extremo: Tiempo total desde la solicitud del usuario hasta la respuesta completa, incluyendo la recuperación, el preprocesamiento, la inferencia del modelo y el postprocesamiento.
| Categoría métrica | Indicadores clave | Por qué es importante
|
|---|---|---|
| Costo | Uso de tokens, coste por interacción, coste por función | Controla el gasto y permite el análisis del retorno de la inversión. |
| Calidad | Tasa de alucinaciones, puntuación de relevancia, cumplimiento del formato | Garantiza la precisión de la salida y la satisfacción del usuario. |
| Actuación | TTFT, tokens/segundo, latencia de extremo a extremo | Mantiene una experiencia de usuario receptiva. |
| Seguridad | Fugas de información personal identificable, intentos de inyección rápida, violaciones de políticas. | Previene incidentes de seguridad y problemas de cumplimiento normativo. |
Estrategias de implementación
Para obtener valor de los análisis de LLM se necesita algo más que instalar una herramienta de monitorización. Los equipos requieren enfoques estructurados para la instrumentación, el diseño de la evaluación y las alertas.
Comience con el trazado
Instrumentar las llamadas a la API de LLM para capturar todos los datos de solicitud y respuesta.
Como mínimo, registre:
- Marca de tiempo e ID de solicitud
- Nombre del modelo y parámetros
- Mensaje completo (mensaje del sistema, entrada del usuario, contexto)
- Texto completo
- Recuento de tokens (entrada, salida, total)
- Desglose de la latencia (tiempo de API, tiempo de procesamiento)
- Cálculo de costos
La mayoría de las plataformas de análisis proporcionan SDK que gestionan esto automáticamente. Pero incluso un simple registro personalizado en un formato estructurado permite realizar análisis posteriores.
Definir parámetros de calidad
Las investigaciones sobre la simplificación de las evaluaciones de agentes de IA destacan que las estrategias de evaluación deben ajustarse a la complejidad del sistema. Los evaluadores basados en código (coincidencia de cadenas, pruebas binarias, análisis estático) funcionan para resultados deterministas. Los evaluadores basados en LLM se encargan de la evaluación semántica cuando la coincidencia exacta falla.
Cree un conjunto de datos de referencia con indicaciones representativas y resultados esperados. Ejecute nuevas versiones del modelo o plantillas de indicaciones con este conjunto de datos antes de su implementación. Realice un seguimiento de las métricas de calidad a lo largo del tiempo para detectar regresiones.
Según las directrices de OpenAI sobre la evaluación de agentes con Langfuse, la evaluación fuera de línea normalmente implica disponer de un conjunto de datos de referencia con pares de solicitud-respuesta, ejecutar el agente en ese conjunto de datos y comparar las salidas utilizando mecanismos de puntuación adicionales.
Configurar alertas de costos
Los sobrecostes presupuestarios se producen rápidamente con los precios basados en tokens.
Configurar alertas para:
- Coste diario superior al de referencia en 25%+
- Las solicitudes individuales consumen 10 veces más tokens de lo normal.
- Usuarios o características específicas que generan costos desproporcionados
- Los cambios inesperados en la versión del modelo aumentan el gasto.
Las alertas deben dar lugar a una investigación, no al pánico. Los picos de costes suelen indicar el éxito del producto (mayor uso) más que problemas. Sin embargo, la visibilidad permite distinguir el crecimiento de la ineficiencia.
Implementar bucles de retroalimentación
Las métricas automatizadas no capturan todo lo que les importa a los usuarios. Añada mecanismos de retroalimentación explícitos:
- Pulgar arriba/abajo en las finalizaciones
- Informes detallados sobre problemas relacionados con resultados deficientes.
- Encuestas de satisfacción a nivel de sesión
Correlaciona los comentarios de los usuarios con las puntuaciones de calidad automatizadas. Si los humanos califican sistemáticamente mal las tareas con puntuaciones altas, es necesario recalibrar las métricas automatizadas.
Técnicas avanzadas de optimización
Una vez que la monitorización básica esté operativa, varias técnicas avanzadas pueden mejorar significativamente la relación coste-calidad.
Modelo en cascada con reconocimiento de sesión
Las investigaciones sobre la asistencia de agentes demuestran que la selección de modelos en función de la sesión ofrece mejoras significativas. En lugar de utilizar un único modelo durante toda la conversación, el sistema comienza con un modelo más económico y lo actualiza a mitad de la sesión cuando la calidad lo requiere.
El marco AgServe logra una calidad equivalente a GPT-4o con un coste de 16,5% mediante la selección y actualización dinámica de modelos durante la vida útil de la sesión, basándose en una evaluación de calidad en tiempo real.
La implementación requiere:
- Puntuación de calidad después de cada respuesta del modelo
- Umbrales que definen los niveles de calidad aceptables
- Lógica para recurrir a modelos más capaces (y costosos) cuando sea necesario.
- Gestión de caché KV para reutilizar el contexto entre cambios de modelo.
Optimización de mensajes instantáneos basada en análisis
Los análisis revelan qué patrones de avisos se correlacionan con problemas de calidad o sobrecostos. Los problemas comunes incluyen:
- Relleno excesivo de contexto: Se añaden documentos completos a las indicaciones cuando bastaría con extractos específicos. Los análisis que muestran un alto número de tokens de entrada con puntuaciones de relevancia bajas indican este problema.
- Instrucciones vagas: Las indicaciones genéricas como "analice estos datos" generan resultados divagantes y poco claros. Los análisis que muestran un bajo cumplimiento del formato o una gran variabilidad en la longitud de los resultados sugieren problemas de claridad en las instrucciones.
- Restricciones faltantes: No especificar la longitud o el formato de la salida genera respuestas innecesariamente largas. El análisis del uso de tokens lo pone de manifiesto rápidamente.
Estrategias de almacenamiento en caché
Muchas aplicaciones LLM procesan repetidamente contextos similares. El análisis que identifica prefijos de indicaciones de alta frecuencia permite desarrollar estrategias de almacenamiento en caché específicas.
El almacenamiento en caché semántico guarda incrustaciones de las preguntas recientes. Cuando una nueva pregunta es semánticamente similar a una almacenada en caché, se devuelve la respuesta almacenada en caché en lugar de llamar a la API. Esto funciona bien para aplicaciones de preguntas frecuentes donde muchos usuarios hacen preguntas similares.
El almacenamiento en caché de prefijos de mensajes reutiliza el procesamiento de mensajes y contextos comunes del sistema. Si 80% mensajes comparten el mismo prefijo de 2000 tokens, almacenar en caché ese cálculo ahorra costes significativos.
Errores comunes y cómo evitarlos
Incluso los equipos que cuentan con infraestructura de monitorización cometen errores previsibles que socavan la eficacia del análisis de datos.
Seguimiento de métricas de vanidad
Las métricas como el total de llamadas a la API o el recuento total de tokens no determinan las decisiones. Su valor aumenta a medida que el producto tiene éxito. Monitorea las métricas que indican problemas: costo por valor entregado, tasas de degradación de la calidad y latencia atípica.
Ignorar la significación estadística
Los resultados de LLM son estocásticos. Un único fallo no indica problemas sistémicos. Sin embargo, los equipos suelen reaccionar de forma exagerada ante fallos puntuales en lugar de analizar las tendencias.
Se requieren tamaños de muestra suficientes antes de concluir que existe una regresión de calidad. La investigación sobre la selección de modelos lineales generalizados (MLG) para tareas de múltiples etapas hace hincapié en el diseño de sistemas que toleren las fluctuaciones de rendimiento causadas por la estocasticidad de los MLD.
Optimización únicamente en función del coste
Reducir costes mediante la normativa 50% no sirve de nada si la calidad disminuye lo suficiente como para perjudicar la experiencia del usuario. El objetivo es lograr una relación óptima entre coste y calidad, no minimizar el coste.
Los análisis deben rastrear ambas dimensiones simultáneamente. La investigación sobre el servicio con reconocimiento de sesión demuestra que una arquitectura adecuada puede mejorar la calidad. mientras Reduciendo costes, trascendiendo la disyuntiva tradicional.
No se está probando en producción.
La evaluación offline con conjuntos de datos de referencia es importante, pero el comportamiento en producción difiere. Los usuarios formulan las consultas de manera distinta a como lo esperan los diseñadores de pruebas. Los casos límite del mundo real no aparecen en los conjuntos de datos seleccionados.
Realiza un seguimiento continuo de la producción y utilízalo para perfeccionar las pruebas de rendimiento fuera de línea. La prueba de rendimiento debe evolucionar para reflejar los patrones de uso reales.
Preguntas frecuentes
¿Cuál es la diferencia entre la monitorización LLM y la observabilidad LLM?
El monitoreo realiza un seguimiento de las métricas predefinidas y genera alertas cuando superan los umbrales establecidos. La observabilidad permite explorar el comportamiento del sistema mediante consultas arbitrarias sobre datos de rastreo detallados. La mayoría de las plataformas modernas combinan ambos enfoques: métricas estructuradas para paneles de control y alertas, y rastreos detallados para depurar problemas específicos.
¿Cuánto suele costar el análisis de datos para LLM?
Los modelos de precios varían considerablemente. Las plataformas basadas en el uso cobran según el volumen de trazas. Las plataformas de suscripción como Langfuse Pro cuestan $249/mes para trazas ilimitadas. Las suites empresariales como Datadog integran la monitorización LLM en los contratos existentes.
¿Pueden las herramientas analíticas reducir los costes de mi máster en Derecho (LLM)?
El análisis de datos no reduce directamente los costos, pero permite tomar decisiones de optimización que sí lo hacen. Las investigaciones sobre el servicio con reconocimiento de sesión demuestran que es posible lograr reducciones de costos superiores a las establecidas por la norma 80% mediante mejoras arquitectónicas.
¿Qué métricas de calidad son las más importantes para las aplicaciones de LLM en producción?
La tasa de alucinaciones y la puntuación de relevancia son cruciales para la precisión de los datos. El cumplimiento del formato es importante para los resultados estructurados. Las métricas de seguridad (filtración de información personal identificable, resistencia a la inyección de mensajes) previenen incidentes de seguridad. Las métricas específicas dependen del caso de uso: las aplicaciones de atención al cliente priorizan dimensiones de calidad diferentes a las de las herramientas de generación de código.
¿Debo usar herramientas de análisis LLM de código abierto o comerciales?
Las herramientas de código abierto como Langfuse ofrecen flexibilidad de implementación y evitan la dependencia de un proveedor específico, pero requieren gestión de la infraestructura. Las plataformas comerciales proporcionan alojamiento gestionado, un desarrollo de funciones más rápido y soporte especializado. Los equipos con una sólida infraestructura suelen preferir el código abierto. Los equipos centrados en el desarrollo de aplicaciones, en lugar de las operaciones, generalmente optan por soluciones gestionadas.
¿Cómo puedo medir el retorno de la inversión (ROI) de las inversiones en análisis de datos de programas de maestría en derecho (LLM)?
Realice un seguimiento de tres dimensiones: ahorro de costes gracias a la optimización (menor consumo de tokens), mejoras en la calidad (mejores valoraciones de los usuarios, menos incidencias de soporte) y velocidad de desarrollo (depuración más rápida, implementaciones más seguras). La mayoría de los equipos obtienen un retorno de la inversión positivo en 2 o 3 meses solo con la optimización de costes, antes de tener en cuenta los beneficios en calidad y velocidad.
¿Cuál es la configuración analítica mínima viable para una nueva solicitud de LLM?
Comience con un seguimiento básico que registre cada solicitud, finalización, recuento de tokens y costo. Añada una métrica de calidad simple relevante para el dominio (cumplimiento de formato para salidas estructuradas, puntuación de relevancia para aplicaciones de chat). Configure alertas de costos para sobrecostos. Esta configuración mínima se implementa en 1 o 2 días y previene los problemas de producción más comunes.
Conclusión
El análisis de datos de LLM ha pasado de ser una característica deseable a una necesidad en la producción. Sin visibilidad sobre los costos de los tokens, las métricas de calidad y las características de rendimiento, los equipos operan a ciegas.
El panorama de plataformas ofrece opciones sólidas para diversas necesidades. Confident AI lidera el monitoreo de calidad centrado en la evaluación. Langfuse proporciona flexibilidad de código abierto con un sólido seguimiento de sesiones. Helicone ofrece visibilidad rápida de costos mediante implementación basada en proxy. Datadog extiende la observabilidad empresarial a las cargas de trabajo de LLM.
Pero las herramientas por sí solas no garantizan el éxito. Un análisis eficaz requiere realizar un seguimiento de las métricas adecuadas, establecer puntos de referencia de calidad, implementar mecanismos de retroalimentación y utilizar la información obtenida para impulsar decisiones de optimización.
Las investigaciones demuestran que las arquitecturas con gestión de sesiones pueden superar las limitaciones tradicionales de relación coste-calidad. AgServe alcanza una calidad equivalente a GPT-40 con un coste de 16,51 TP3T mediante la gestión inteligente de la caché KV y la selección dinámica de modelos. Estas técnicas funcionan porque adaptan la arquitectura del sistema a las características específicas de las cargas de trabajo LLM.
Los equipos que obtienen mejores resultados comparten prácticas comunes. Implementan sistemas de análisis exhaustivos desde el primer día. Definen parámetros de calidad desde el principio y realizan un seguimiento continuo de las regresiones. Optimizan basándose en datos, no en la intuición. Y consideran el análisis de datos como un sistema de retroalimentación que mejora con el tiempo, no como una implementación puntual.
Comience implementando el seguimiento básico de costos y el rastreo. Agregue métricas de calidad relevantes para el caso de uso. Configure alertas que detecten problemas antes de que afecten a los usuarios. Luego, utilice la visibilidad resultante para impulsar mejoras iterativas en las indicaciones, la selección de modelos y la arquitectura del sistema.
La diferencia entre los equipos que tienen éxito con las aplicaciones de LLM en producción y los que fracasan suele radicar en el análisis de datos. La medición impulsa la optimización. La optimización impulsa una economía sostenible. Y una economía sostenible permite crear productos de IA realmente útiles.