Resumen rápido: Las pruebas de rendimiento de LLM miden el desempeño de la inferencia en términos de rendimiento, latencia y eficiencia de costos. Herramientas de evaluación comparativa como MLPerf, vLLM y GuideLLM ayudan a las organizaciones a evaluar las opciones de implementación. Los modelos pequeños autohospedados (de 7 a 14 mil millones de parámetros) cuestan entre 95 y 991 TP3T menos que las API comerciales, manteniendo un rendimiento comparable para muchos casos de uso.
Los elevados costes de implementación de modelos de lenguaje pueden determinar el éxito o el fracaso de un proyecto de IA. Según informes de AWS y otras fuentes del sector, la inferencia consume más de 901 TP3T del consumo total de energía de los modelos de lenguaje en entornos de producción. Se trata de un gasto operativo enorme que exige una medición precisa.
La evaluación comparativa del rendimiento de los servicios de LLM ya no se centra únicamente en la velocidad. La rentabilidad se ha convertido en la principal preocupación para las organizaciones que escalan aplicaciones de IA. La cuestión no es si un modelo puede gestionar las solicitudes, sino si puede hacerlo de forma rentable.
El problema es el siguiente: la mayoría de los equipos carecen de un enfoque sistemático para medir simultáneamente el rendimiento y el coste. Optimizan una sola métrica y ven cómo los gastos se disparan sin control.
Comprender los estándares de servicio de LLM
Los indicadores de rendimiento miden cómo se comportan los modelos de lógica difusa (LLM) en condiciones específicas. A diferencia de las clasificaciones de calidad de modelos, que valoran la capacidad de razonamiento, los indicadores de rendimiento se centran en métricas operativas: rendimiento, latencia, utilización de recursos y, en última instancia, coste por inferencia.
El conjunto de pruebas de rendimiento MLPerf Inference de MLCommons representa el estándar de la industria para medir el rendimiento de las cargas de trabajo de aprendizaje automático e inteligencia artificial. La versión 5.1 de MLPerf Inference introdujo Llama3.1-8B como modelo de referencia, que ofrece una longitud de contexto de 128 000 tokens que refleja los requisitos empresariales del mundo real.
Pero un momento, ¿qué es lo que realmente importa al realizar una evaluación comparativa?
Indicadores clave de rendimiento
El rendimiento mide las solicitudes procesadas por segundo. Un mayor rendimiento significa que se puede atender a más usuarios con el mismo hardware. GuideLLM calcula percentiles completos, incluidos los percentiles 0,1, 1, 5, 10, 25, 75, 90, 95 y 99, para el rendimiento y otras métricas.
La latencia mide el tiempo de respuesta. MLPerf define restricciones de latencia específicas para diferentes escenarios. Los escenarios de flujo único miden la latencia del percentil 90, mientras que los escenarios de servidor buscan tiempos de respuesta inferiores a un segundo para aplicaciones interactivas.
El tiempo hasta el primer token (TTFT) es crucial para la experiencia del usuario. En serio: los usuarios se dan cuenta cuando las respuestas tardan más de 200-300 ms en aparecer. Esta métrica influye directamente en la percepción de la capacidad de respuesta de la aplicación.
El rendimiento de generación de tokens difiere del rendimiento de solicitudes. Mide la cantidad de tokens producidos por segundo, lo que se correlaciona directamente con la velocidad de salida visible para el usuario. Investigaciones recientes sobre la inferencia de modelos de lenguaje de razonamiento muestran fluctuaciones significativas de memoria durante la generación de tokens que afectan esta métrica.
Escenarios de referencia estándar
MLPerf define cuatro escenarios principales. Cada uno simula diferentes patrones de aplicación con características de carga específicas.
| Guión | Generación de consultas | Restricción de latencia | Métrica de rendimiento |
|---|---|---|---|
| Flujo único | Consultas secuenciales | percentil 90 | latencia 90%-ile |
| Flujo múltiple | Lotes de intervalo fijo | percentil 99 | Máximo de transmisiones |
| Servidor | Distribución de Poisson | percentil 99 | Consultas por segundo |
| Desconectado | Todas las consultas a la vez | Ninguno | Rendimiento total |
Los escenarios de servidor simulan cargas de API de producción con solicitudes distribuidas según una distribución de Poisson. Este patrón refleja un comportamiento de usuario realista, donde las solicitudes llegan de forma aleatoria en lugar de a intervalos fijos.
Medición de los costos de inferencia de LLM
El análisis de costos requiere comprender tanto los gastos directos como los indirectos. La depreciación del hardware, el consumo de energía, las tarifas de alojamiento y los gastos operativos contribuyen al costo total de propiedad.
Según el marco de economía de la inferencia del equipo WiNGPT, la inferencia LLM debe considerarse como producción inteligente basada en computación. La GPU A800 80G, por ejemplo, tiene un costo horario base de aproximadamente $0.79 por hora, que suele oscilar entre $0.51 y $0.99 por hora bajo supuestos operativos comunes.
Componentes del costo total de propiedad
Los costos de hardware comienzan con la adquisición. Las configuraciones de servidor con 8 GPU pueden costar $320 000 o más, dependiendo del modelo de GPU. La depreciación generalmente sigue un ciclo de cuatro años para implementaciones empresariales.
Los costos de aprovisionamiento de infraestructura incluyen tarifas de alojamiento, consumo de energía, refrigeración y espacio en rack. Estos gastos operativos se acumulan con el tiempo. En las implementaciones en la nube, el precio de las instancias varía significativamente según el tipo de GPU y la región.
Las licencias y el mantenimiento del software generan costes recurrentes. Los marcos de servicio de código abierto como vLLM eliminan las tarifas de licencia, pero las soluciones comerciales cobran por despliegue o por token procesado.
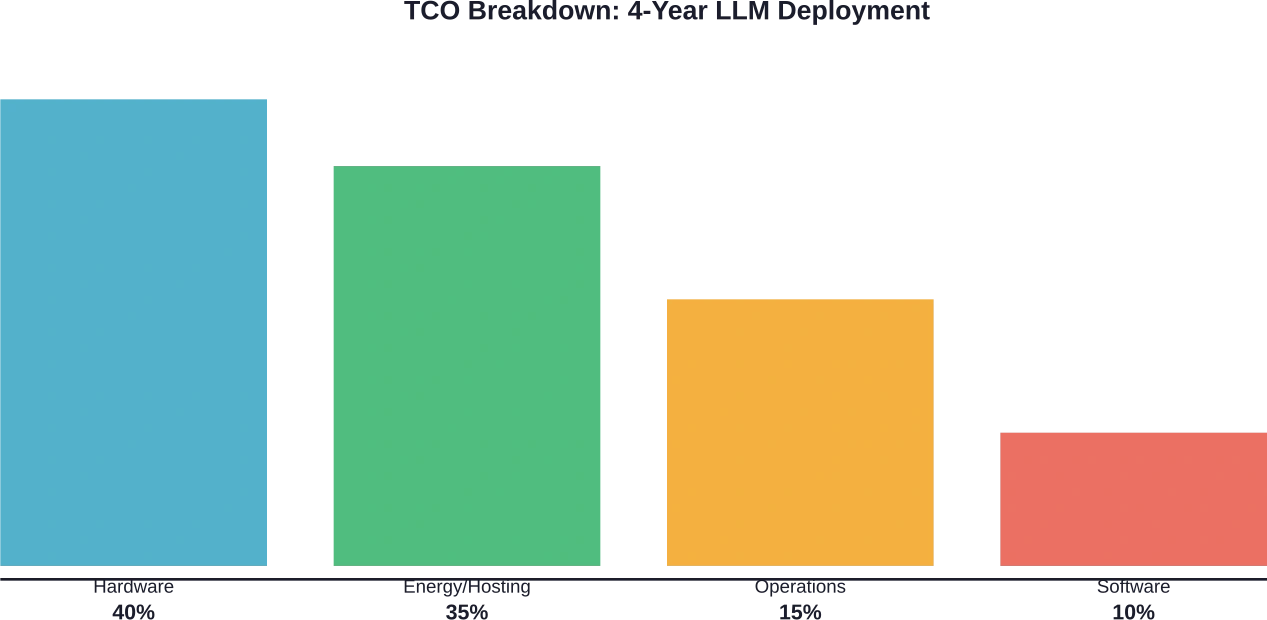
Comparación de costos entre alojamiento propio y API
Los ratios de costes revelan diferencias drásticas entre los distintos enfoques de implementación. Un estudio publicado por Fin AI demuestra que los modelos más pequeños ofrecen ahorros sustanciales en comparación con las API comerciales.
| Modelo | Parámetros | Coste frente a GPT-4.1 | Costo vs GPT-4.1 Mini | Costo vs Soneto 3.7 |
|---|---|---|---|---|
| Gemma 3 4B | 4B | 0.04 | 0.20 | 0.01 |
| Llama DeepSeek 8B | 8B | 0.05 | 0.27 | 0.01 |
| Qwen 3 14B | 14B | 0.05 | 0.27 | 0.01 |
| Gemma 3 27B | 27B | 0.34 | 1.71 | 0.08 |
| Llama DeepSeek 70B | 70B | 1.70 | 8.49 | 1.10 |
| Qwen 3 235B | 235B | 2.17 | 10.83 | 1.40 |
Los modelos más pequeños, con menos de 14 mil millones de parámetros, cuestan significativamente menos que los modelos de la clase GPT-4. Los estudios muestran que los costos son entre 0,04 y 0,05 veces menores que los de GPT-4.1. Esto supone un cambio radical para las aplicaciones de alto volumen, donde los requisitos de calidad permiten el uso de modelos más pequeños.
El equipo de ingeniería de Salesforce documentó un ahorro anual de más de 14.000 millones de dólares al reemplazar las dependencias LLM en producción con un servicio simulado para flujos de trabajo de desarrollo y evaluación comparativa. Esto eliminó el consumo de tokens para pruebas fuera de producción, manteniendo al mismo tiempo la capacidad de validación a 16.000 solicitudes por minuto, con una capacidad máxima que supera las 24.000 solicitudes por minuto.
Herramientas y marcos de evaluación comparativa
Existen diversos marcos de trabajo que permiten establecer puntos de referencia sistemáticos para la gestión del rendimiento de las aplicaciones web. Cada uno ofrece diferentes capacidades para medir el rendimiento y la eficiencia en costes.
Suite de evaluación comparativa vLLM
El proyecto vLLM proporciona herramientas de evaluación comparativa integradas para medir el rendimiento y la latencia. El marco admite varios conjuntos de datos, incluidos ShareGPT, BurstGPT y datos aleatorios sintéticos generados a partir de tokenizadores de modelos.
Los parámetros clave de evaluación comparativa de vLLM incluyen límites máximos de concurrencia, tasas de solicitudes y selección de conjuntos de datos. Al establecer la concurrencia máxima en 10, el servidor procesa hasta 10 solicitudes simultáneamente, poniendo en cola las solicitudes adicionales hasta que haya capacidad disponible.
Las pruebas de rendimiento de la versión vLLM-ascend v0.7.3 demostraron su eficacia con los modelos Qwen2.5-7B-Instruct y Qwen2.5-VL-7B-Instruct a tasas de QPS de 1, 4, 16 e infinito (ilimitado). Para las pruebas se utilizaron 200 indicaciones muestreadas aleatoriamente de los conjuntos de datos ShareGPT y vision-arena con semillas aleatorias fijas para garantizar la reproducibilidad.
Guía LLM para la evaluación comparativa de la producción
GuideLLM, del proyecto vLLM, se especializa en la evaluación de inferencias en entornos reales. Simula diferentes patrones de tráfico mediante perfiles de carga configurables.
Las pruebas de carga basadas en tasas admiten tasas de solicitud constantes. Al ejecutarlas a 10 solicitudes por segundo durante 20 segundos con datos sintéticos de 128 tokens de solicitud y 256 tokens de salida, se obtienen mediciones de rendimiento de referencia. La herramienta calcula distribuciones de percentiles completas, incluyendo los percentiles 0,1, 1, 5, 10, 25, 50, 75, 90, 95, 99 y 99,9 para cada métrica.
Los patrones de carga son importantes porque las diferentes aplicaciones generan distintos tipos de tráfico. Las pruebas de ráfaga revelan el comportamiento del sistema ante picos de carga repentinos, mientras que las pruebas sostenidas miden el rendimiento en estado estable.
Pruebas de rendimiento de inferencia de MLPerf
MLPerf Inference representa el estándar de referencia en la industria. El conjunto de pruebas de rendimiento abarca escenarios de centros de datos y dispositivos móviles con cargas de trabajo estandarizadas en los ámbitos de la visión artificial, el habla y el procesamiento del lenguaje.
En entornos de centros de datos, MLPerf mide las consultas por segundo bajo restricciones de latencia específicas. Las pruebas de rendimiento en entornos de servidor utilizan patrones de consulta con distribución de Poisson y objetivos de latencia del percentil 99. En entornos sin conexión, se maximiza el rendimiento sin restricciones de latencia.
La versión 5.1 de MLPerf Inference introdujo Llama3.1-8B con soporte para contextos de 128 000 tokens. Este benchmark refleja los requisitos empresariales modernos para tareas de comprensión y generación de contextos extensos.
Compromisos entre costo y rendimiento de las GPU
La selección del hardware influye drásticamente tanto en el rendimiento como en la rentabilidad. Las investigaciones sobre la rentabilidad en la prestación de servicios LLM a través de GPU heterogéneas revelan que los diferentes tipos de GPU se adaptan mejor a las distintas características de la carga de trabajo.
| Tipo de GPU | FLOPS FP16 máximos | Ancho de banda de memoria | Límite de memoria | Precio por hora |
|---|---|---|---|---|
| A6000 | 91 TFLOPS | 768 GB/s | 48 GB | $0.83 |
| A40 | 150 TFLOPS | 696 GB/s | 48 GB | $0.55 |
| L40 | 181 TFLOPS | 864 GB/s | 48 GB | $1.15 |
El ancho de banda de la memoria suele ser más importante que la capacidad de cómputo para la inferencia LLM. La generación de tokens está limitada por la memoria, ya que carga repetidamente los pesos del modelo desde la memoria de la GPU. El A6000 tiene un ancho de banda de memoria de 768 GB/s, inferior al del L40 (864 GB/s) y significativamente inferior al del H100 o el A100 (2-3 TB/s).
Las implementaciones heterogéneas de GPU optimizan la relación costo-eficiencia al adaptar las capacidades de la GPU a las características de las solicitudes. Las solicitudes que requieren mucha computación se dirigen a GPU con alto FLOPS, mientras que las que requieren mucha memoria prefieren opciones de alto ancho de banda. Este enfoque mejora la utilización de los recursos en diversos patrones de solicitud.
Tamaño del modelo y requisitos de hardware
El número de parámetros determina directamente los requisitos mínimos de memoria. La precisión FP16 requiere aproximadamente 2 bytes por parámetro, mientras que la cuantización de 4 bits reduce esta cifra a aproximadamente 0,5 bytes por parámetro.

Las opciones de GPU en la nube varían significativamente en capacidad y costo. Las instancias AWS g4dn.xlarge admiten cargas de trabajo básicas con GPU de gama de consumo. AWS g5.xlarge ofrece un mejor rendimiento para modelos de 7 a 8 mil millones de recursos. Los modelos más grandes requieren configuraciones de múltiples GPU o instancias especializadas con alta capacidad de memoria.
Optimización de la relación coste-eficacia
La optimización de costes requiere equilibrar múltiples factores simultáneamente. Las compensaciones entre rendimiento, calidad y gastos exigen una medición e iteración sistemáticas.
Impacto de la cuantificación
La cuantización de 4 bits reduce los requisitos de memoria y aumenta el rendimiento con una mínima degradación de la calidad. La mayoría de las aplicaciones toleran la cuantización sin una pérdida de rendimiento perceptible. La cuantización de 4 bits reduce los requisitos de memoria en aproximadamente 75% en comparación con la precisión FP16, manteniendo al mismo tiempo mejoras en el rendimiento.
La cuantización de 8 bits ofrece una solución intermedia, ya que proporciona una mejor preservación de la calidad con un ahorro moderado de memoria. Para aplicaciones donde la calidad es crucial, la cuantización de 8 bits representa una opción más segura que la agresiva cuantización de 4 bits.
Ajuste del tamaño del lote
Los lotes de mayor tamaño mejoran la utilización de la GPU y el rendimiento. Procesar 32 solicitudes simultáneamente logra una mayor eficiencia del hardware que procesarlas secuencialmente. Sin embargo, los lotes más grandes aumentan la latencia de las solicitudes individuales.
El procesamiento por lotes dinámico optimiza este equilibrio agrupando las solicitudes que llegan dentro de un intervalo de tiempo. Cuando las solicitudes llegan de forma esporádica, los lotes efectivos más pequeños mantienen una baja latencia. Durante los picos de carga, el procesamiento por lotes automático maximiza el rendimiento.
Estrategias de enrutamiento de solicitudes
El enrutamiento inteligente de solicitudes a diferentes tipos de GPU mejora la rentabilidad. Las solicitudes cortas con lotes pequeños se enrutan a GPU optimizadas para computación. Las solicitudes de contexto largo requieren un acceso sustancial a la memoria del hardware optimizado para ancho de banda.
El balanceo de carga entre réplicas evita puntos críticos y mejora la utilización general. El enrutamiento round-robin funciona para cargas de trabajo homogéneas, pero el enrutamiento sensible a las solicitudes ofrece mejores resultados para patrones de solicitud diversos.
Creación de una calculadora de TCO
Para estimar con precisión los costos, es necesario llevar un registro sistemático de todos los componentes de los gastos. Las organizaciones necesitan tener visibilidad de los costos reales por solicitud para tomar decisiones de implementación informadas.
Los costos de hardware se dividen en adquisición y depreciación. Un servidor de 8 GPU con un precio de $320,000 y un período de depreciación de 4 años cuesta $80,000 anualmente o aproximadamente $9.13 por hora, suponiendo un funcionamiento ininterrumpido (24/7).
Los gastos operativos incluyen tarifas de alojamiento, consumo de energía y mantenimiento. Las implementaciones en la nube simplifican este cálculo, ya que los costos por hora de instancia incluyen la mayoría de los gastos operativos. Las implementaciones autogestionadas requieren un seguimiento independiente de los costos de las instalaciones, el consumo de energía a tarifas típicas de 0,10 a 0,15 por kWh y los gastos generales administrativos.
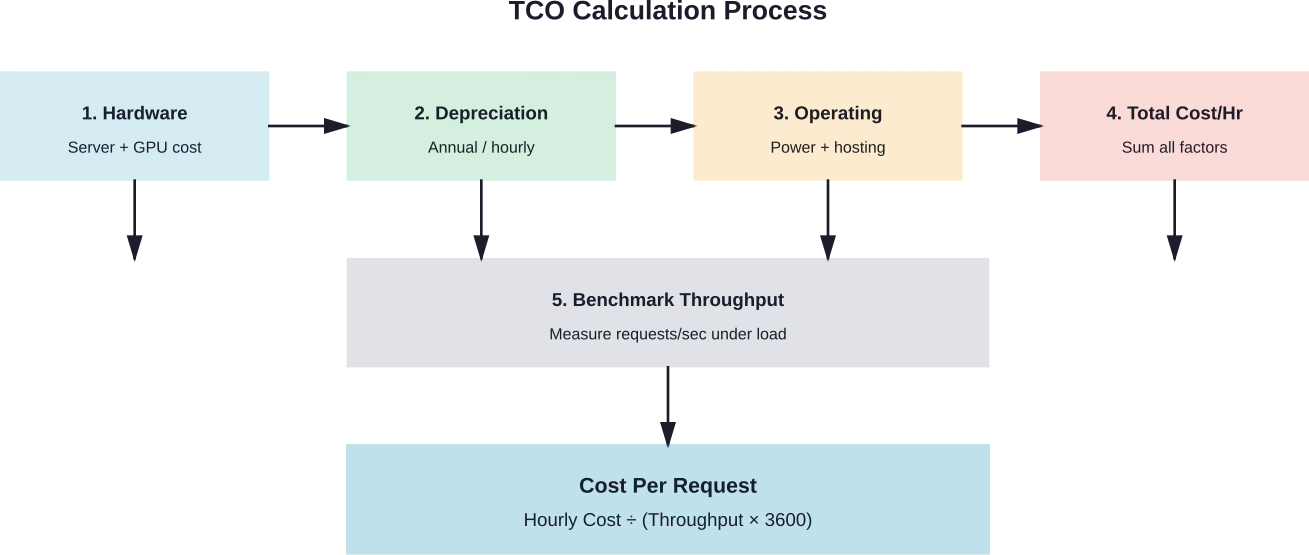
La fórmula para calcular el costo por solicitud combina los costos por hora con el rendimiento medido:
Coste por solicitud = Coste por hora ÷ (Solicitudes por segundo × 3600)
Para una implementación que cuesta $10 por hora y que atiende 50 solicitudes por segundo, el costo por solicitud es igual a $0,0000556 o aproximadamente $0,056 por cada 1.000 solicitudes.

Reduzca los costos de los servicios de LLM con una ingeniería de modelos más inteligente.
Los análisis comparativos suelen centrarse en los tokens, las GPU y los precios de la infraestructura. Sin embargo, las diferencias reales en los costos generalmente provienen de cómo se diseña e implementa el modelo. IA superior Trabaja en la capa de ingeniería: crea modelos lógicos de aprendizaje (LLM) personalizados, optimiza los procesos de entrenamiento y estructura las implementaciones para que los modelos se ejecuten de manera eficiente en producción.
Si sus pruebas de rendimiento muestran altos costos de servicio, el problema puede ser la arquitectura o la configuración de inferencia. Hable con IA superior para revisar su sistema LLM e identificar formas prácticas de reducir los costos de servicio.
Flujo de trabajo práctico de evaluación comparativa
La evaluación comparativa sistemática sigue un proceso repetible. Comenzar con cargas de trabajo representativas garantiza que las mediciones reflejen las condiciones de producción.
Selección de conjuntos de datos
ShareGPT ofrece patrones de conversación realistas con indicaciones de distinta duración y requisitos de respuesta. El conjunto de datos contiene interacciones reales de usuarios, lo que lo hace valioso para realizar pruebas en entornos de producción. El muestreo aleatorio de 200 a 500 indicaciones con una semilla aleatoria fija garantiza resultados reproducibles.
Los conjuntos de datos sintéticos permiten realizar pruebas controladas de escenarios específicos. La generación aleatoria de tokens crea indicaciones con distribuciones de longitud predeterminadas. Este enfoque permite probar casos límite, como la longitud máxima del contexto o patrones de tokens inusuales.
Configuración del patrón de carga
Las pruebas de tasa constante miden el rendimiento en estado estacionario. Ejecutar a 10 QPS durante 60 segundos establece las características de rendimiento y latencia de referencia. Aumentar gradualmente la tasa permite identificar la carga máxima sostenible antes de que se degrade la latencia.
Las pruebas de ráfaga revelan el comportamiento ante picos de tráfico repentinos. El aumento gradual de 1 QPS a 100 QPS en 10 segundos y la medición del tiempo de recuperación demuestran la resiliencia del sistema. Los sistemas de producción suelen experimentar patrones de ráfaga durante las horas pico de uso.
Análisis de resultados
Las distribuciones percentiles revelan comportamientos atípicos que los promedios ocultan. Si bien una latencia del percentil 50 podría ser aceptable, los valores del percentil 99 muestran la peor experiencia de usuario posible. GuideLLM calcula automáticamente los percentiles desde 0,1% hasta 99,9% para un análisis exhaustivo.
La degradación del rendimiento bajo carga sostenida indica contención de recursos. Un rendimiento estable durante toda la duración de la prueba demuestra una escalabilidad adecuada. La disminución del rendimiento sugiere fugas de memoria, limitación térmica u otros problemas sistémicos.
Consideraciones sobre energía y potencia
El consumo de energía impacta directamente en los costos operativos y la sostenibilidad ambiental. Un estudio de TokenPowerBench destaca que el consumo de energía para inferencias supera los costos de entrenamiento en un factor de 10 o más para sistemas de producción que procesan miles de millones de consultas diarias.
Los datos de referencia de ML.ENERGY muestran que la energía se ha convertido en un recurso crítico que limita su uso. En muchas regiones, acceder a una infraestructura de energía suficiente para las flotas de GPU cuesta más y lleva más tiempo que la adquisición de hardware.
La medición del consumo energético durante las pruebas de rendimiento permite visualizar los costes. El consumo típico de una GPU oscila entre 250 W para tarjetas optimizadas para la eficiencia y 700 W para aceleradores de alto rendimiento. A razón de 1 TP4T0,12 por kWh, una GPU de 400 W cuesta aproximadamente 1 TP4T0,048 por hora solo en electricidad.
Al multiplicar los costos de energía por la cantidad de GPU y sumar los gastos generales de la instalación, se obtiene el gasto total de energía. Para un servidor de 8 GPU que consume 3200 W más los gastos generales, los costos de energía se aproximan a $0,40-0,50 por hora, dependiendo de las tarifas eléctricas locales y la eficiencia de la refrigeración.
Preguntas frecuentes
¿Cuál es el tamaño de modelo más rentable para su implementación en producción?
Los modelos con entre 7.000 y 14.000 millones de parámetros ofrecen una excelente relación coste-eficacia para aplicaciones empresariales. Un estudio de FinAI demuestra que estos modelos cuestan aproximadamente un 0,05% más que los modelos de la clase GPT-4, manteniendo una calidad aceptable para tareas como atención al cliente, clasificación de contenido y extracción de datos estructurados. Los modelos más pequeños, de entre 1.000 y 3.000 millones de parámetros, son adecuados para tareas de clasificación sencillas, mientras que los modelos de más de 70.000 millones deberían reservarse para aplicaciones que requieran la máxima capacidad de razonamiento.
¿Cómo afecta el tamaño del lote a los costes de servicio de LLM?
Los lotes de mayor tamaño mejoran la utilización de la GPU y reducen el coste por solicitud al procesar varias consultas simultáneamente. Duplicar el tamaño del lote de 8 a 16 suele aumentar el rendimiento entre 40 y 60 TP3T sin un aumento proporcional en el coste del hardware. Sin embargo, el tamaño del lote incrementa la latencia para las solicitudes individuales. Las estrategias de procesamiento por lotes dinámico equilibran estas ventajas y desventajas ajustando el tamaño del lote en función de la carga actual, maximizando el rendimiento durante los picos de demanda y manteniendo una baja latencia durante los periodos de menor actividad.
¿Deberían las organizaciones alojar sus propios programas de maestría en derecho (LLM) o utilizar API comerciales?
El autoalojamiento de modelos más pequeños puede resultar rentable para implementaciones de alto volumen, con puntos de equilibrio que varían según el tamaño del modelo y la configuración del hardware. Por debajo de este umbral, los precios de las API comerciales siguen siendo competitivos si se tienen en cuenta los gastos operativos. Las implementaciones autoalojadas pueden generar ahorros sustanciales en comparación con las API comerciales, dependiendo del tamaño del modelo y la configuración de la implementación. Las organizaciones también deben considerar los requisitos de experiencia técnica, ya que el autoalojamiento exige capacidades de gestión de infraestructura, monitorización y optimización del rendimiento que las API comerciales gestionan automáticamente.
¿Qué herramientas de evaluación comparativa funcionan mejor para medir el rendimiento de los servicios de LLM?
GuideLLM destaca por su capacidad para realizar pruebas de rendimiento en entornos de producción reales, con patrones de carga configurables y métricas completas. El conjunto de herramientas de evaluación comparativa de vLLM ofrece una excelente integración para equipos que ya utilizan vLLM para la gestión de servidores. MLPerf Inference proporciona pruebas de rendimiento estandarizadas y fiables para comparar diferentes configuraciones de hardware y software. Varias herramientas de evaluación comparativa cumplen distintas funciones: MLPerf para comparaciones estandarizadas, GuideLLM para patrones de producción reales y herramientas de vLLM para pruebas integradas en el framework.
¿Cuánta VRAM se requiere para los diferentes tamaños de modelo?
La precisión FP16 requiere aproximadamente 2 bytes por parámetro: los modelos de 7 bits necesitan entre 14 y 16 GB, los de 13 bits entre 26 y 28 GB, y los de 70 bits 140 GB. La cuantización de 4 bits reduce los requisitos en 75%: los modelos de 7 bits se ejecutan en 6-8 GB, los de 13 bits en 10-12 GB y los de 70 bits en 35-40 GB. Añada entre 20 y 30% de sobrecarga para la caché KV y la memoria de activación. Un modelo de 7 bits con cuantización de 4 bits se ejecuta sin problemas en GPU de consumo con 8 GB de VRAM, mientras que los modelos de 70 bits requieren GPU profesionales con más de 40 GB o configuraciones multi-GPU.
¿Qué causa la variabilidad de la latencia en la inferencia de modelos lineales generalizados (LLM)?
Las limitaciones de ancho de banda de la memoria crean el principal cuello de botella de latencia. La generación de tokens carga repetidamente los pesos del modelo desde la memoria de la GPU, lo que hace que la inferencia dependa de la memoria en lugar de la capacidad de cómputo. La cola de solicitudes durante cargas elevadas añade un tiempo de espera variable. El tamaño de la caché KV aumenta con la longitud del contexto, incrementando la presión sobre la memoria y ralentizando los tokens subsiguientes. Las investigaciones sobre la inferencia de modelos de lenguaje de razonamiento muestran fluctuaciones significativas de memoria que afectan al rendimiento constante. La monitorización de la latencia del percentil 99 revela estas variaciones mejor que las métricas promedio.
¿Cómo mejoran la rentabilidad las implementaciones heterogéneas de GPU?
Los distintos tipos de GPU destacan en diferentes características de carga de trabajo. Las GPU de alto ancho de banda, como la A6000 (768 GB/s), optimizan la generación de tokens con limitaciones de memoria, mientras que las GPU de alto rendimiento computacional, como la A40 (150 TFLOPS), destacan en operaciones de alto rendimiento computacional. Un estudio publicado en ICML 2025 demuestra que el enrutamiento de solicitudes basado en los requisitos de memoria y computación mejora la utilización en flotas heterogéneas. Las implementaciones heterogéneas de GPU pueden optimizar sustancialmente la rentabilidad en comparación con los enfoques homogéneos, al asignar las características de las solicitudes a los tipos de GPU adecuados, en lugar de sobredimensionar un solo tipo de GPU.
Conclusión
Los puntos de referencia de LLM proporcionan una visibilidad esencial sobre las compensaciones entre rendimiento y coste que determinan la viabilidad de la implementación. Las organizaciones que miden sistemáticamente el rendimiento, la latencia y el coste total de propiedad toman decisiones informadas sobre el autoalojamiento frente a las API comerciales, la selección del tamaño del modelo y el aprovisionamiento de hardware.
Los datos muestran patrones claros. Los modelos más pequeños, con parámetros entre 7B y 14B, ofrecen un ahorro de costes de entre 95 y 99% en comparación con los modelos comerciales de vanguardia, manteniendo una calidad aceptable para muchas aplicaciones empresariales. La rentabilidad del autoalojamiento depende del volumen diario de tokens, los costes de hardware y los gastos operativos específicos de cada organización. La cuantización de 4 bits reduce los requisitos de memoria en 75% con un impacto mínimo en la calidad.
Pero lo más importante es lo siguiente: la evaluación comparativa no es una actividad puntual. Las características de rendimiento cambian con las actualizaciones del modelo, las mejoras en la infraestructura de servicio y la evolución de los patrones de carga de trabajo. Las organizaciones que establecen flujos de trabajo de evaluación comparativa continua mantienen la rentabilidad a medida que sus implementaciones de IA se expanden.
Comience con cargas de trabajo representativas del tráfico de producción. Mida exhaustivamente el rendimiento, los percentiles de latencia y la utilización de recursos. Calcule el costo total de propiedad (TCO) real, incluyendo la depreciación del hardware, el consumo de energía y los gastos operativos. Pruebe múltiples configuraciones de implementación para identificar el equilibrio óptimo entre costo y rendimiento para casos de uso específicos.
Las herramientas existen: MLPerf, vLLM, GuideLLM y otras ofrecen sólidas capacidades de evaluación comparativa. Las metodologías han sido probadas mediante su adopción en la industria y la investigación académica. Lo que queda es la aplicación sistemática de estos marcos a los requisitos y limitaciones específicos de cada organización. Realice evaluaciones comparativas con diligencia, optimice continuamente y observe cómo los costos de los servicios de LLM se vuelven sostenibles a gran escala.