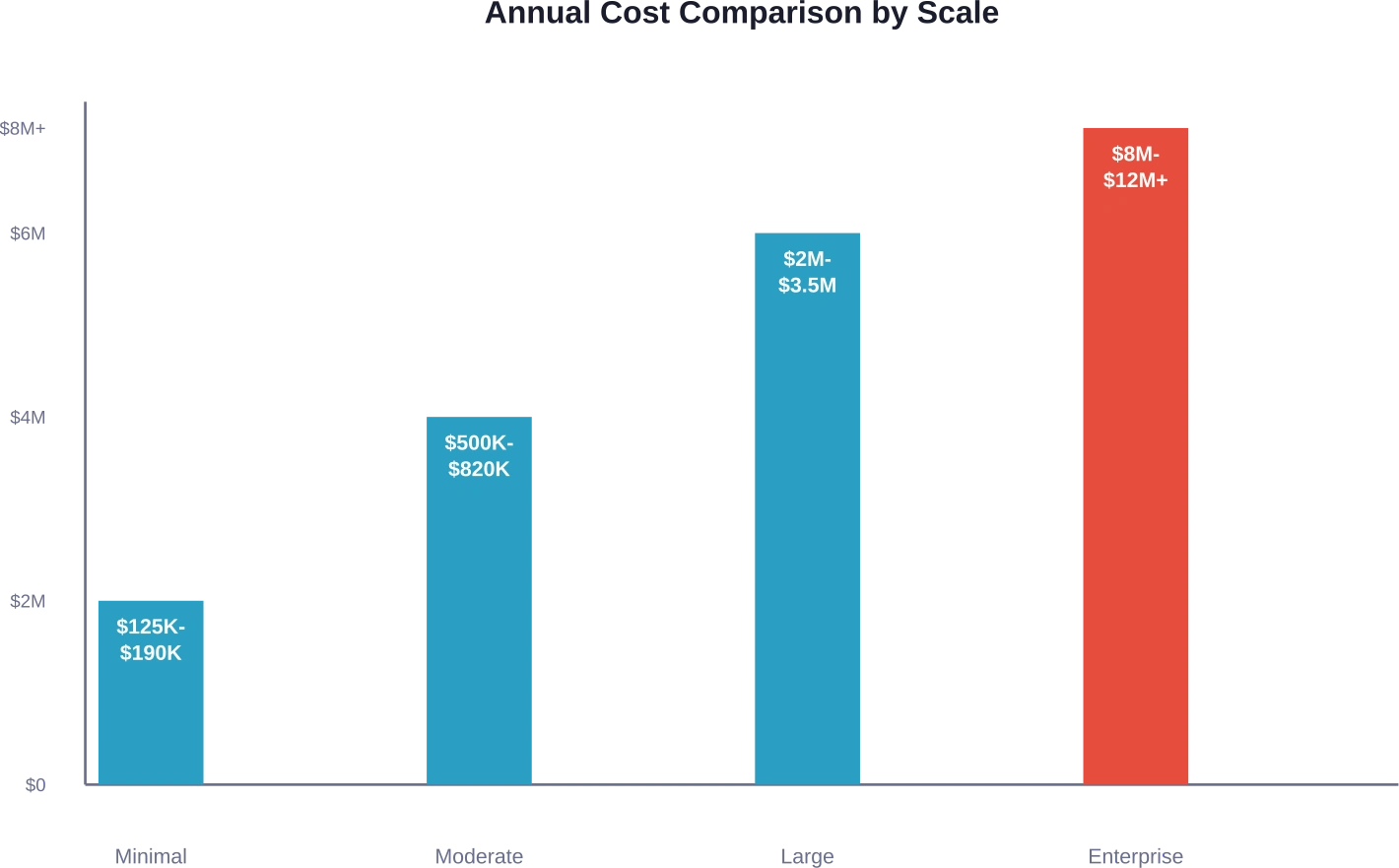
Resumen rápido: Las soluciones de gestión de aprendizaje de código abierto eliminan las tarifas de licencia, pero trasladan los costos a la infraestructura, el talento y el mantenimiento. Las implementaciones internas mínimas cuestan entre 125.000 y 190.000 dólares anuales, mientras que las implementaciones a escala empresarial pueden superar los 12 millones de dólares. La rentabilidad depende del volumen de uso, la experiencia técnica y las necesidades de personalización; las API propietarias suelen ser más económicas para cargas de trabajo bajas o moderadas.
La promesa suena atractiva: descarga un modelo de lenguaje de código abierto de gran tamaño, despliégalo en tu infraestructura y evita los costes recurrentes de las API de los servicios propietarios. Se acabó la facturación por token. Sin dependencia de un proveedor.
Pero aquí está el detalle: ese modelo "gratuito" tiene un precio que pilla desprevenida a la mayoría de las organizaciones.
Los sistemas de gestión de aprendizaje de código abierto trasladan los gastos de partidas obvias, como las tarifas de licencia, a costes menos visibles pero igualmente sustanciales: talento de ingeniería especializado, infraestructura de GPU, mantenimiento continuo y gastos operativos. Estos gastos ocultos pueden superar con creces el coste de los servicios API comerciales, sobre todo a pequeña escala.
La decisión entre programas de máster en derecho (LLM) de código abierto y propietarios no se trata de elegir entre gratuitos o de pago, sino de encontrar la estructura de costes que mejor se adapte a tus patrones de uso, capacidades técnicas y necesidades empresariales.
Por qué los másteres en Derecho de código abierto no son realmente gratuitos
El término “código abierto” genera una peligrosa idea errónea. Si bien es cierto que se pueden descargar los pesos de los modelos sin pagar licencias, su implementación en entornos de producción requiere recursos considerables.
Los servicios LLM propietarios como GPT-5.2 de OpenAI, Google Gemini o Claude de Anthropic cobran por token. A principios de 2026, GPT-5.2 Pro de OpenAI costaba $21,00 por millón de tokens de entrada ($168 de salida), mientras que los niveles económicos como GPT-5.2 Mini comenzaban en $0,25 por millón de tokens de entrada. Según datos de precios verificados, estas tarifas reflejan una gama de niveles que equilibran rendimiento y coste. Los modelos de "pensamiento" V3.2-Exp de DeepSeek se listan a $0,28 por millón de tokens de entrada (cache-fall) y $0,42 por millón de tokens de salida, sustancialmente más baratos que los competidores occidentales.
Los modelos de código abierto invierten esta ecuación. En lugar de tarifas basadas en el uso, usted paga por:
- Adquisición de hardware o alquiler de GPU en la nube
- Salarios de ingeniería para despliegue e integración
- Gestión y monitorización de la infraestructura
- Trabajos de refuerzo de la seguridad y cumplimiento normativo
- Optimización y ajuste fino del modelo
- Mantenimiento y soporte continuo
Estos costes permanecen relativamente fijos independientemente del volumen de uso, lo que crea un modelo económico fundamentalmente diferente al de las API de pago por uso.
La realidad del coste de la infraestructura
La ejecución de modelos LLM exige una gran capacidad de procesamiento. Los modelos con miles de millones de parámetros requieren GPU con una cantidad considerable de VRAM, interconexiones rápidas y sistemas de refrigeración robustos.
Requisitos de inversión en hardware
Un despliegue de producción mínimo suele requerir al menos una GPU de gama alta. Las GPU A100 de NVIDIA, comúnmente utilizadas para la inferencia LLM, cuestan entre 10 000 y 15 000 TPM por unidad. Los modelos más grandes o los requisitos de mayor rendimiento multiplican rápidamente esa cifra.
Sin embargo, la adquisición de hardware es solo el punto de partida. La infraestructura física requiere espacio en racks, distribución de energía, sistemas de refrigeración y conectividad de red. Las organizaciones que no cuentan con capacidad de centro de datos propiamente dicha deben afrontar gastos de capital adicionales para estos sistemas de soporte.
Economía de las GPU en la nube
Las instancias de GPU en la nube ofrecen una alternativa a la propiedad de hardware, pero su precio sigue siendo elevado. Según un análisis de Hugging Face sobre la economía de las GPU en la nube, los costos de capital dominan las estructuras de precios. Por ejemplo, una NVIDIA Tesla V100 suele costar alrededor de 10 000 USD, mientras que su costo promedio de alquiler por hora oscila entre 1 2 y 1 300 USD, lo que significa que las tarifas horarias en la nube aumentan rápidamente cuando se ejecutan de forma continua.
Y aquí radica el problema de las proyecciones de costos iniciales: las cargas de trabajo de inferencia requieren disponibilidad constante. A diferencia de los procesos de entrenamiento, que se ejecutan una sola vez, las implementaciones en producción funcionan de forma continua. Esta operación ininterrumpida convierte los costos por hora de la nube en elevadas facturas mensuales.
La inversión en capital humano
La infraestructura representa solo una dimensión del costo. El talento especializado necesario para implementar y mantener los sistemas de gestión de aprendizaje de código abierto suele superar los gastos de hardware.
Puestos de ingeniería requeridos
Las implementaciones de LLM en producción requieren múltiples roles especializados. Los ingenieros de MLOps se encargan de las canalizaciones de implementación, la optimización de la inferencia y la infraestructura de escalado. Los ingenieros de integración de software crean los conectores entre los modelos y los sistemas existentes, un trabajo que, según los datos disponibles, suele consumir aproximadamente 60% de esfuerzo de ingeniería en proyectos de IA.
Los especialistas en DevOps administran clústeres de Kubernetes, orquestación de contenedores y monitoreo de infraestructura. Los ingenieros de seguridad implementan controles de acceso, registro de auditoría y marcos de cumplimiento. Los ingenieros de datos crean flujos de trabajo para el ajuste y la evaluación de modelos.
En el competitivo mercado actual de talento en IA, cada puesto conlleva salarios sustanciales. Los ingenieros sénior de aprendizaje automático suelen ganar entre 150.000 y 250.000 dólares anuales, y la remuneración total puede ser aún mayor para los profesionales de primer nivel.
Requisitos de soporte continuo
Pero lo que suele pillar desprevenidas a las organizaciones es lo siguiente: la implementación no es un proyecto que se realiza una sola vez. Los sistemas LLM en producción requieren atención continua.
Los modelos necesitan actualizaciones periódicas a medida que mejoran sus capacidades. Las plataformas de inferencia como vLLM o NVIDIA Triton requieren mantenimiento y optimización. Los puntos de integración se rompen cuando cambian los sistemas subyacentes. El rendimiento se degrada sin una optimización continua.
Esto genera una necesidad constante de personal. Las organizaciones no pueden implementar un programa de gestión de proyectos de código abierto y desentenderse; se comprometen a una inversión continua en ingeniería.
Escenarios de costos reales
Las categorías de costos abstractas importan menos que los escenarios concretos. ¿Cuánto cuesta realmente ejecutar modelos de aprendizaje de derecho (LLM) de código abierto a diferentes escalas?
Despliegue interno mínimo
Un chatbot interno básico o una herramienta de análisis de documentos para un equipo pequeño representa el escenario de implementación más sencillo. Según los análisis de costos del sector, incluso las implementaciones internas mínimas cuestan entre 125.000 y 190.000 dólares anuales.
Este escenario supone lo siguiente:
- Instancias de GPU en la nube en lugar de la compra de hardware.
- Configuración de inferencia de una sola GPU
- Soporte de ingeniería a tiempo parcial (no es personal fijo).
- Personalización mínima más allá de los ajustes básicos.
- Bajo volumen de consultas (entre cientos y unos pocos miles diarios)
Los costos se desglosan aproximadamente en infraestructura en la nube (40%), tiempo de ingeniería (45%) y herramientas de monitoreo/seguridad (15%).
Características moderadas orientadas al cliente
Las aplicaciones orientadas al cliente aumentan significativamente los riesgos. Los mayores requisitos de disponibilidad, el aumento del volumen de consultas y las demandas de soporte de producción elevan los costos a entre 1.500.000 y 1.820.000 dólares anuales para implementaciones de escala moderada.
Este escenario suele implicar:
- Configuración multi-GPU para redundancia y rendimiento.
- Equipo de ingeniería especializado (2-3 puestos a tiempo completo)
- Ajuste personalizado para la especificidad del dominio.
- Monitoreo y alerta integral
- Trabajos de refuerzo de la seguridad y cumplimiento normativo
Los costos de infraestructura aumentan, pero los gastos de ingeniería predominan. La construcción de sistemas confiables y aptos para la producción requiere un esfuerzo de ingeniería constante que va mucho más allá de la implementación inicial.
Productos básicos a escala empresarial
Cuando las capacidades de LLM se convierten en un elemento central de la oferta de productos, los costos se disparan drásticamente. Las implementaciones a escala empresarial que dan servicio a miles de usuarios simultáneos pueden superar los $8M–$12M anuales.
Estos despliegues requieren:
- Clústeres de GPU multirregión para rendimiento y redundancia.
- Equipos de ingeniería especializados (de 8 a 15 o más ingenieros)
- Optimización exhaustiva de modelos y arquitecturas personalizadas.
- Marcos de seguridad y cumplimiento empresarial
- Soporte operativo 24/7
A esta escala, el número de empleados de ingeniería se convierte en el principal factor de coste, superando con creces los gastos de infraestructura.
| Escala de despliegue | Rango de costos anuales | Principales factores que influyen en los costos | Casos de uso típicos
|
|---|---|---|---|
| Mínimo interno | $125K–$190K | GPU en la nube, ingeniería a tiempo parcial | Chatbots internos, análisis de documentos |
| Interacción moderada con el cliente | $500K–$820K | Equipo de ingeniería especializado, multi-GPU | Automatización de la atención al cliente, generación de contenido |
| Gran producción | $2M–$3.5M | Grandes equipos de ingeniería, infraestructura optimizada | Funcionalidades principales del producto, API de alto volumen |
| Producto principal empresarial | $8M–$12M+ | Equipos extensos, clústeres multirregionales | Productos y plataformas de IA de misión crítica |
Precios de la API propietaria de LLM en 2026
Comparar los costos del software de código abierto requiere comprender las alternativas propietarias. Los precios de las API han evolucionado significativamente, y los principales proveedores han ajustado las tarifas e introducido nuevos niveles.
Panorama actual de precios
A principios de 2026, los precios de los programas LLM de propiedad exclusiva abarcan un amplio rango. Según datos de precios verificados y actualizados hasta febrero de 2026:
- OpenAI GPT-5.2 Pro cuesta $21,00 por millón de tokens de entrada y $168,00 por millón de tokens de salida, lo que representa su nivel insignia premium. El GPT-5.2 estándar tiene un costo de $1,75 y $14,00 respectivamente, mientras que el GPT-5.2 Mini ofrece tarifas económicas de $0,25 y $2,00.
- El precio de los dispositivos Gemini de Google varía según el modelo. Sus últimas ofertas equilibran el rendimiento y el coste en diferentes casos de uso.
- Los modelos Claude de Anthropic mantienen una posición competitiva en la gama media-alta, haciendo hincapié en la longitud del espacio y las características de seguridad.
- xAI ha lanzado Grok 4 a $3/$15 por millón de tokens, Grok 4 Fast a $0.20/$0.50 y Grok 4.1 Fast a $0.20/$0.50 por millón de tokens.
- Los modelos de "pensamiento" V3.2-Exp de DeepSeek tienen un coste de $0,28 por millón de tokens de entrada (cache-fall) y $0,42 por millón de tokens de salida, considerablemente más baratos que los de sus competidores occidentales.
Cálculos de costos basados en el uso
Los costos de la API aumentan linealmente con el uso. Una aplicación que procesa 100 millones de tokens al mes con GPT-5.2 Pro (a 1 TP4T21,00 por millón de tokens de entrada) incurriría en aproximadamente 1 TP4T25K anuales en tokens de entrada. La misma carga de trabajo en DeepSeek V3.2-Exp genera aproximadamente 1 TP4T336 anuales, una diferencia de 74 veces.
Esta escalabilidad lineal crea puntos de equilibrio claros. Las aplicaciones de alto volumen acaban justificando las inversiones en infraestructura de código abierto. Las cargas de trabajo bajas o moderadas casi siempre favorecen las API.
El punto de inflexión depende de los niveles de precios específicos y de los costes de infraestructura, pero generalmente se sitúa entre 50 y 200 millones de tokens mensuales para la mayoría de las organizaciones.
Costes operativos ocultos
Más allá de los gastos obvios de infraestructura y salarios, las implementaciones de LLM de código abierto acumulan costos operativos menos visibles que se incrementan con el tiempo.
Monitoreo y observabilidad
Los sistemas LLM de producción requieren una monitorización exhaustiva. El seguimiento de la latencia, las métricas de rendimiento, las tasas de error y la utilización de recursos necesitan visibilidad en tiempo real.
Las plataformas de observabilidad comerciales cobran en función del volumen de datos y los periodos de retención. Estos costes aumentan con la complejidad del sistema y el tráfico.
Las soluciones de monitorización personalizadas trasladan los costes al tiempo de ingeniería: la creación de paneles de control, sistemas de alerta y herramientas de diagnóstico consume importantes recursos de desarrollo.
Actualizaciones y versiones del modelo
Los ecosistemas LLM de código abierto evolucionan rápidamente. Regularmente se lanzan nuevas versiones de los modelos, que ofrecen capacidades mejoradas, mayor eficiencia o correcciones de errores.
Cada actualización requiere pruebas, validación y planificación de la implementación. Las pruebas de regresión garantizan que las nuevas versiones no afecten la funcionalidad existente. Las pruebas de rendimiento validan las mejoras. Los procedimientos de reversión preparan el terreno para posibles fallos.
Las organizaciones no pueden simplemente ignorar las actualizaciones: quedarse atrás en los parches de seguridad críticos o las mejoras de rendimiento genera deuda técnica y desventajas competitivas.
Seguridad y Cumplimiento
Las implementaciones de LLM que manejan datos confidenciales se enfrentan a estrictos requisitos de seguridad. Los controles de acceso, el registro de auditoría, el cifrado de datos y el aislamiento de la red requieren implementación y mantenimiento.
Los marcos de cumplimiento como SOC 2, HIPAA o GDPR imponen requisitos adicionales. Las auditorías de seguridad periódicas, las pruebas de penetración y la gestión de vulnerabilidades generan costes recurrentes.
Los proveedores de API propietarias suelen encargarse de las certificaciones de cumplimiento y la infraestructura de seguridad, liberando a los clientes de estas responsabilidades. Las implementaciones de código abierto asumen la responsabilidad total.
Cuando el código abierto tiene sentido desde el punto de vista financiero
A pesar de sus elevados costes, los másteres jurídicos de código abierto ofrecen ventajas económicas convincentes en determinados escenarios.
Cargas de trabajo de producción de alto volumen
El punto de inflexión en el que el software de código abierto resulta más económico que las API depende del volumen de uso. Procesar cientos de millones o miles de millones de tokens al mes genera enormes costes de API que justifican la inversión en infraestructura.
Una aplicación que procesa 500 millones de tokens al mes en API propietarias de nivel medio podría pagar entre $200K y $400K al año. Esa misma carga de trabajo en una infraestructura autogestionada podría costar entre $300K y $500K en total, pero con una escalabilidad relativamente plana a partir de ese punto.
A escalas de miles de millones de tokens, la economía se inclina decisivamente hacia el autoalojamiento.
Requisitos de dominio especializado
Algunas aplicaciones requieren un ajuste exhaustivo de datos de dominio propietario. El diagnóstico médico, el análisis de documentos legales o los campos técnicos especializados se benefician de modelos entrenados con corpus específicos del dominio.
Los proveedores de API propietarias ofrecen servicios de ajuste fino, pero los costos aumentan rápidamente para una personalización extensa. Los modelos de código abierto permiten un ajuste fino ilimitado sin cargos por token de entrenamiento.
Las organizaciones con idiomas poco comunes, vocabularios especializados o requisitos de formato únicos pueden encontrar que los modelos de código abierto son más adaptables, aunque la relación coste-beneficio específica varía según el caso de uso.
Privacidad y soberanía de los datos
En ocasiones, las normativas prohíben el envío de datos confidenciales a API externas. Los historiales médicos, la información financiera o los datos clasificados pueden requerir procesamiento local.
Los sistemas de gestión de la vida legal de código abierto permiten un control total de los datos. La información nunca sale de la infraestructura de la organización, lo que simplifica el cumplimiento normativo y reduce los riesgos.
El valor de este control depende de la sensibilidad de los datos y del contexto normativo, pero para algunas organizaciones es innegociable independientemente del coste.
Independencia estratégica a largo plazo
La dependencia de proveedores de API externos genera riesgos estratégicos. Estos proveedores pueden aumentar los precios, discontinuar modelos o modificar las condiciones del servicio. Las interrupciones del servicio afectan directamente a las aplicaciones que dependen de él.
Las implementaciones de código abierto eliminan la dependencia de proveedores. Las organizaciones controlan su propia disponibilidad, precios y hoja de ruta.
Un artículo de investigación de arXiv sobre el análisis de costo-beneficio de la implementación local de LLM define la paridad de rendimiento como puntuaciones de referencia dentro del 20% de los principales modelos comerciales, lo que refleja las normas empresariales donde las pequeñas brechas de precisión se compensan con los beneficios de costo, seguridad e integración.
Consideraciones de rendimiento
Las comparaciones de costes pasan por alto una dimensión fundamental: las diferencias de rendimiento entre los modelos de código abierto y los modelos propietarios.
Brechas de capacidad
Por lo general, los modelos propietarios de primer nivel superan a las alternativas de código abierto comparables en tareas de razonamiento desafiantes, instrucciones complejas y dominios especializados.
La diferencia varía significativamente según el tipo de tarea. La clasificación simple, la extracción de datos estructurados o la generación basada en plantillas muestran diferencias mínimas. El razonamiento complejo, la comprensión del lenguaje con matices o las tareas creativas favorecen los modelos propietarios de última generación.
Las organizaciones deben evaluar si las diferencias de capacidad son relevantes para sus casos de uso específicos. Muchas aplicaciones funcionan bien con un rendimiento de nivel medio a un menor coste.
Oportunidades de optimización
Las implementaciones de código abierto permiten una optimización exhaustiva que no está disponible con los servicios API. La cuantificación reduce el tamaño del modelo y los requisitos de memoria, manteniendo una precisión aceptable. La destilación del conocimiento transfiere capacidades a modelos más pequeños y rápidos.
Una investigación publicada en Hugging Face que examina la eficiencia del razonamiento encontró que las cadenas de razonamiento más cortas pueden lograr un rendimiento similar o mejor con un costo computacional reducido. Específicamente, los enfoques básicos short-1@k demostraron hasta 40% tokens de pensamiento menos en comparación con los enfoques estándar, manteniendo la calidad de la salida.
Las pilas de inferencia personalizadas, como vLLM o NVIDIA Triton, ofrecen una optimización del rendimiento que no está disponible a través de las API estandarizadas. Las estrategias de procesamiento por lotes, los mecanismos de almacenamiento en caché y las optimizaciones específicas del hardware pueden mejorar drásticamente el rendimiento y la latencia.
Latencia y rendimiento
La infraestructura autogestionada permite una distribución geográfica más cercana a los usuarios, lo que reduce la latencia de la red. El hardware dedicado elimina los retrasos en las colas que se producen en la infraestructura API compartida.
Sin embargo, la creación de sistemas de inferencia de alto rendimiento requiere una gran experiencia. Las implementaciones mal optimizadas suelen presentar una latencia mayor que los servicios API bien diseñados.
Tomar la decisión sobre el costo
Elegir entre sistemas LLM de código abierto y propietarios requiere evaluar múltiples dimensiones que van más allá de una simple comparación de costes.
Calcular el costo total de propiedad
Las proyecciones de costos precisas deben incluir todas las categorías de gastos:
- Infraestructura: Hardware de GPU o alquiler de servicios en la nube, redes, almacenamiento
- Personal: Salarios de ingeniería, costos de contratación, capacitación
- Operaciones: Herramientas de monitoreo, software de seguridad, auditorías de cumplimiento.
- Costo de oportunidad: Tiempo de ingeniería desviado del desarrollo de productos
- Prima de riesgo: Costes por tiempo de inactividad, problemas de rendimiento, incidentes de seguridad
Las organizaciones subestiman sistemáticamente los costes de personal y operativos, al tiempo que sobreestiman los ahorros en infraestructuras.
Evaluar las capacidades técnicas
Las implementaciones exitosas de código abierto requieren una sólida experiencia técnica. Los equipos necesitan conocimientos en sistemas distribuidos, programación de GPU, optimización de aprendizaje automático y operaciones de producción.
Las organizaciones que carecen de esta experiencia se enfrentan a dos opciones: desarrollar capacidades mediante la contratación y la formación (costoso y lento) o contratar consultores externos (costoso y que genera dependencia).
Los servicios API eliminan la mayoría de los requisitos técnicos, lo que permite a los equipos centrarse en la lógica de la aplicación en lugar de en la infraestructura.
Considere enfoques híbridos
La decisión no es binaria. Muchas organizaciones combinan diferentes enfoques con éxito.
Las estrategias de enrutamiento LLM seleccionan dinámicamente los modelos según las características de la solicitud. Las consultas sencillas se enrutan a modelos rápidos y económicos, mientras que las tareas complejas utilizan alternativas más potentes. Según un estudio de Hugging Face sobre el enrutamiento de instrucciones por lotes, esta optimización equilibra el rendimiento y el coste en cargas de trabajo mixtas.
Los entornos de desarrollo y preproducción pueden usar API, mientras que la producción se ejecuta en una infraestructura autogestionada. Esto reduce los costos de infraestructura durante las fases de bajo volumen y permite una producción sin API.
La especialización en tareas específicas implementa modelos de código abierto para tareas estandarizadas de gran volumen, al tiempo que utiliza API propietarias para solicitudes complejas y variables.
| Consideración | Favorece el código abierto | Favorece las API propietarias
|
|---|---|---|
| Volumen de uso | Muy alto (más de 500 millones de tokens al mes) | Bajo a moderado (<100 millones de tokens/mes) |
| Experiencia técnica | Equipos sólidos de aprendizaje automático e infraestructura. | Experiencia limitada en aprendizaje automático, equipos pequeños |
| Necesidades de personalización | Se requiere un ajuste fino exhaustivo. | Los modelos estándar son suficientes |
| Privacidad de datos | Requisitos reglamentarios estrictos | Se aceptan condiciones comerciales estándar. |
| Tiempo de comercialización | Inversión estratégica a largo plazo | El despliegue rápido es fundamental. |
| Previsibilidad de costos | Preferir costos de infraestructura fijos | Costos variables aceptables |
Estrategias de optimización de costos
Las organizaciones comprometidas con los másteres jurídicos de código abierto pueden emplear diversas estrategias para controlar los costes.
Infraestructura del tamaño adecuado
En muchas implementaciones, el hardware se sobredimensiona en función de la carga máxima en lugar del uso típico. La infraestructura de autoescalado ajusta dinámicamente la capacidad según la demanda, reduciendo los costos de los recursos inactivos.
Las instancias spot y las máquinas virtuales interrumpibles ofrecen importantes descuentos en la nube (a veces entre el 60 % y el 80 % sobre el precio estándar) a cambio de posibles interrupciones. Las cargas de trabajo por lotes y los entornos de desarrollo toleran bien las interrupciones.
Selección y optimización de modelos
Los modelos más pequeños ofrecen un rendimiento sorprendente en tareas especializadas tras su ajuste fino. Una investigación sobre la optimización de modelos de lenguaje pequeños para tareas de comercio electrónico reveló que un modelo Llama 3.2 de mil millones de parámetros, debidamente ajustado, alcanzó una precisión de 99%, igualando el rendimiento de GPT-5.1 en el reconocimiento de intenciones especializadas.
La cuantización reduce la precisión del modelo de 16 bits a representaciones de 8 bits o incluso de 4 bits, lo que reduce los requisitos de memoria y los costos de inferencia en un 50-75% con un impacto mínimo en la calidad.
La destilación de modelos entrena modelos estudiantes más pequeños para imitar modelos maestros más grandes, logrando así mejores equilibrios entre eficiencia y rendimiento que el entrenamiento desde cero.
Técnicas de inferencia eficientes
El procesamiento por lotes gestiona múltiples entradas simultáneamente, lo que mejora drásticamente la utilización de la GPU. Las técnicas de procesamiento continuo por lotes permiten el ensamblaje dinámico de lotes para aplicaciones en tiempo real.
La optimización de la caché KV reduce los cálculos redundantes durante la generación autorregresiva, especialmente en contextos largos o conversaciones de varios turnos.
El enrutamiento de solicitudes envía las consultas simples a modelos pequeños y rápidos, y las consultas complejas a modelos más grandes, optimizando la relación costo-rendimiento en la distribución de la carga de trabajo.

Revise los costos de su LLM de código abierto con Technical Insight.
Los modelos lógicos lineales de código abierto pueden parecer económicos porque el modelo base es gratuito, pero los gastos reales suelen surgir en el entrenamiento, el ajuste fino, la preparación de datos y la implementación. Las decisiones sobre el tamaño, la arquitectura y la integración del modelo tienen un gran impacto en el uso de recursos computacionales y los costos operativos continuos. IA superior Se centra en el trabajo de ingeniería que hay detrás de los modelos de aprendizaje de lenguaje natural (LLM) de código abierto: creación de modelos, optimización de flujos de trabajo de capacitación y configuración de canales de implementación eficientes para que pueda comprender y controlar a dónde va su presupuesto. (aisuperior.com/services/llm-model-creation-services)
Si está haciendo un seguimiento de los gastos ocultos en 2026 y quiere tener una idea más clara de dónde provienen los costos, comience con la configuración técnica. Hable con IA superior Auditar su implementación actual de LLM de código abierto y encontrar formas prácticas de reducir el costo total de propiedad.
Tendencias de costos futuras
La dinámica de costes de los másteres en Derecho (LLM) sigue evolucionando rápidamente, con varias tendencias que están transformando el panorama económico.
Presión a la baja sobre los precios de las API
La competencia entre los proveedores de software propietario se intensifica. Los precios agresivos de DeepSeek, de $0.28 por millón de tokens de entrada, obligaron a los competidores a evaluar sus propias tarifas.
Una mayor eficiencia en la inferencia reduce los costos para los proveedores, lo que permite ofrecer precios más bajos sin comprometer los márgenes de ganancia. Las continuas mejoras en el hardware y las optimizaciones algorítmicas deberían mantener esta tendencia.
Modelos de código abierto más capaces
La diferencia de rendimiento entre los modelos de código abierto y los propietarios se reduce continuamente. Los modelos publicados hoy como código abierto igualan el rendimiento de las alternativas propietarias de hace 12 a 18 meses.
Esta trayectoria reduce la penalización en el rendimiento que supone elegir opciones de código abierto, lo que las hace viables para más aplicaciones.
Modelos pequeños especializados
Los modelos pequeños, entrenados para tareas específicas en dominios particulares, compiten cada vez más con los modelos grandes de propósito general en aplicaciones especializadas.
Estos modelos especializados funcionan con hardware más económico y con menores costes operativos, lo que mejora la rentabilidad del código abierto para casos de uso específicos.
Errores comunes en la estimación de costos
Las organizaciones cometen sistemáticamente errores predecibles al evaluar los costes de los programas de gestión de leyes laborales (LLM).
Ignorar los costos de personal
El error más frecuente: tratar los recursos de ingeniería existentes como “gratuitos” porque los salarios ya están presupuestados.
El despliegue y el mantenimiento de LLM consumen una cantidad considerable de tiempo de ingeniería. Ese tiempo conlleva un coste de oportunidad: los ingenieros que trabajan en la infraestructura no pueden desarrollar simultáneamente funcionalidades del producto.
Una contabilidad de costos adecuada incluye los costos totales de personal, no solo las contrataciones adicionales.
Subestimación de los gastos generales operativos
El despliegue inicial representa quizás entre 20 y 301 TP3T de esfuerzo total a lo largo de un ciclo de vida de varios años. El mantenimiento continuo, las actualizaciones, la monitorización y la optimización consumen la mayor parte.
Las organizaciones presupuestan la implementación, pero subestiman las necesidades operativas sostenidas, lo que genera escasez de recursos después del lanzamiento.
Comparación del pico con el promedio
Los costos de la API calculados utilizando el uso máximo parecen inflados en comparación con los costos fijos de infraestructura. Sin embargo, la mayoría de las cargas de trabajo no mantienen un uso máximo de forma continua; el uso promedio determina los gastos reales.
La infraestructura debe prever la capacidad máxima, lo que genera recursos inactivos durante el funcionamiento normal. Las API solo cobran por el uso real, escalando automáticamente según la demanda.
Supervisión del cumplimiento y la seguridad
El refuerzo de la seguridad, las auditorías de cumplimiento y los requisitos normativos añaden costes sustanciales a las implementaciones autogestionadas.
Las organizaciones sin experiencia con sistemas de ML de producción subestiman habitualmente estos gastos en un 50-100%.
Preguntas frecuentes
¿Los másteres en Derecho de código abierto son realmente gratuitos?
No. Si bien los pesos del modelo están disponibles sin costo de licencia, su implementación requiere una infraestructura considerable, personal de ingeniería especializado y mantenimiento continuo. El costo total de propiedad para implementaciones mínimas comienza en alrededor de 125 mil millones de 10.
¿Cuándo deja de ser más barato el software de código abierto que las API propietarias?
El punto de equilibrio suele situarse entre 50 y 200 millones de tokens mensuales, dependiendo de los precios específicos de la API y los costes de infraestructura. Las aplicaciones de muy alto volumen (más de 500 millones de tokens mensuales) casi siempre se benefician del autoalojamiento, mientras que las de menor volumen suelen optar por API de pago por uso.
¿Cuáles son los mayores costes ocultos de los másteres en derecho de código abierto?
Los salarios de ingeniería representan el mayor gasto, a menudo subestimado, consumiendo típicamente entre 45 y 551 TP3T del total de costos. Las organizaciones subestiman sistemáticamente la experiencia especializada necesaria para la implementación, la optimización y el mantenimiento continuo. El fortalecimiento de la seguridad y el cumplimiento normativo añaden otra dimensión de costo que con frecuencia se subestima.
¿Cuánto más baratos son los másteres jurídicos de código abierto que las opciones propietarias?
Depende totalmente del volumen de uso. Con volúmenes bajos, las API propietarias cuestan mucho menos, potencialmente entre 5 y 10 veces menos si se tiene en cuenta el costo total de propiedad. Con volúmenes muy altos, la infraestructura autogestionada puede reducir los costos por token entre 50 y 801 TP3T. La ventaja varía según la escala, las necesidades de personalización y la experiencia disponible.
¿Qué conocimientos técnicos se necesitan para gestionar programas de máster en derecho de código abierto?
Los despliegues en producción requieren ingenieros de aprendizaje automático para la optimización de modelos, especialistas en MLOps para la infraestructura de despliegue, ingenieros de DevOps para la gestión de sistemas e ingenieros de software para la integración. La experiencia en seguridad es fundamental para los sistemas de producción que manejan datos confidenciales. Los despliegues mínimos pueden consolidar estas funciones en 1 o 2 personas, mientras que la escala empresarial requiere equipos dedicados.
¿Pueden las pequeñas empresas permitirse la implementación de software LLM de código abierto?
La mayoría de las pequeñas empresas consideran que las API propietarias son más económicas, a menos que tengan requisitos específicos como una estricta privacidad de datos, necesidades de personalización extensas o volúmenes de uso excepcionalmente altos. El mínimo anual de $125K+ para el autoalojamiento suele superar los costos de las API para las pequeñas empresas hasta que el uso alcanza una escala considerable.
¿Cuál es el mejor enfoque para las organizaciones que buscan reducir costos?
Comience con API propietarias para validar la adecuación del producto al mercado y comprender los patrones de uso. Esto minimiza la inversión inicial y la complejidad técnica. Considere la implementación de código abierto solo después de alcanzar una escala donde los costos de las API se vuelvan prohibitivos (normalmente $200K+ anuales), y asegúrese de contar con la experiencia técnica necesaria para dar soporte a una infraestructura autogestionada de manera eficaz.
Conclusión: Tomar la decisión económica correcta
Los másteres en Derecho de código abierto no son gratuitos; tienen una estructura de costes fundamentalmente diferente que favorece a contextos organizativos específicos.
Los modelos de pago “gratuitos” implican inversiones sustanciales en infraestructura, personal y operaciones. Para escenarios de uso bajo a moderado, las API propietarias ofrecen una mejor relación costo-beneficio con una complejidad mucho menor. Las organizaciones pagan solo por el uso real, delegando la implementación, el escalado y el mantenimiento a los proveedores.
Las implementaciones de código abierto resultan económicamente viables en grandes volúmenes, donde los costos de la API por token se vuelven prohibitivos, cuando la personalización exhaustiva requiere un acceso profundo al modelo o cuando la privacidad de los datos exige el procesamiento local. Estos escenarios justifican los elevados costos fijos y la complejidad técnica.
La decisión exige una evaluación honesta de los costos reales —incluidos los gastos de personal, a menudo pasados por alto— en comparación con proyecciones de uso realistas. Las organizaciones con sólidas capacidades de ingeniería de aprendizaje automático y vías claras para un uso a gran escala se benefician de los enfoques de código abierto. Aquellas con experiencia limitada, un uso moderado o plazos ajustados suelen encontrar las API más prácticas.
Lo más importante es comprender que la pregunta no es "¿código abierto o propietario?", sino "¿qué modelo de costos se ajusta mejor a nuestro uso, capacidades y requisitos?". Responda con honestidad y la opción económicamente óptima quedará clara.
¿Listo para evaluar las opciones de LLM para su caso de uso específico? Calcule el volumen de tokens esperado, evalúe las capacidades técnicas y modele ambas estructuras de costos con supuestos realistas. Los datos numéricos guiarán la decisión mejor que cualquier recomendación general.