Resumen rápido: Entrenar un modelo LLM desde cero cuesta entre 78 y 192 millones de TP4T para modelos de vanguardia como GPT-4 y Gemini Ultra 1.0, debido a la gran cantidad de clústeres de GPU, electricidad, adquisición de datos y talento de ingeniería. Los modelos más pequeños se pueden entrenar por entre 50 000 y 500 000 TP4T utilizando infraestructura en la nube o por menos de 100 000 TP4T con técnicas de optimización eficientes, pero las organizaciones se enfrentan a costes continuos de inferencia, almacenamiento y mantenimiento que a menudo superan los gastos de entrenamiento.
Los grandes modelos de lenguaje han transformado nuestra interacción con la tecnología. Pero lo que la mayoría de la gente desconoce es que el coste de crear estos modelos es astronómico.
Según el Informe del Índice de IA de Stanford de 2025, los costos de entrenamiento de los modelos de vanguardia se han disparado. El entrenamiento de GPT-4 osciló entre $78 millones y $100 millones. El costo de entrenamiento de Gemini Ultra se estima en aproximadamente $191 millones, según el Informe del Índice de IA de Stanford de 2024. Estas cifras representan un aumento de 287 000 veces con respecto al costo de entrenar un modelo Transformer en 2017, que rondaba los $670 millones.
¿Qué motiva estos enormes gastos? Y, lo que es más importante, ¿cuánto cuesta realmente entrenar un modelo propio desde cero?
Desglosando los costos reales de la formación en LLM
Entrenar un modelo de lenguaje complejo desde cero no solo es costoso, sino que supone un compromiso financiero multidimensional que abarca hardware, energía, datos y capital humano.
Infraestructura informática: El mayor gasto
Los costos de procesamiento lo superan todo. Las GPU de alto rendimiento como la NVIDIA H100 pueden costar entre 1 y 30 000 dólares por unidad. Pero eso es solo el principio.
Para contextualizar, el entrenamiento de modelos de vanguardia requiere miles de GPU funcionando continuamente durante semanas o meses. Un estudio de arXiv que analiza la economía de las GPU encontró que una GPU A800 80G tiene un costo horario base de aproximadamente $0.79 por hora, con rangos típicos que oscilan entre $0.51 y $0.99 por hora dependiendo de la configuración y el precio de la plataforma en la nube.
Según se informa, OpenAI gastó más de 1.040.000 millones de dólares en el entrenamiento de GPT-4, destinando una parte significativa a los costes de computación en la nube. La magnitud de la cifra es difícil de comprender.
| Modelo | Costo estimado de capacitación | Fuente |
|---|---|---|
| GPT-4 | $78M-$100M+ | Wall Street Journal, Índice de IA de Stanford 2025 |
| Gemini Ultra 1.0 | $191M | Informe del Índice de IA de Stanford 2024 |
| GPT-4o | ~$100M | Estimaciones de la industria |
| Transformer (2017) | $670 | Informe del Índice de IA de Stanford 2025 |
Consumo de energía y costes medioambientales
El funcionamiento continuo de miles de GPU consume enormes cantidades de electricidad. Un estudio publicado por Springer en 2025 sobre la eficiencia energética en modelos de lenguaje de gran tamaño destaca que la dinámica del consumo energético se correlaciona directamente con el tamaño del modelo y la configuración del procesamiento por lotes.
El impacto ambiental va más allá de la fase de entrenamiento. A medida que aumentan las exigencias computacionales, también aumentan las preocupaciones sobre la sostenibilidad y la huella de carbono.
Adquisición y preparación de datos
Un aspecto que no recibe suficiente atención es que el trabajo humano detrás de los datos de entrenamiento está significativamente infravalorado. Un documento publicado en Hugging Face en abril de 2025 argumenta que los costos de producción de datos deberían ser iguales o superiores a los costos computacionales del entrenamiento.
Los conjuntos de datos de calidad no surgen de la nada. Requieren:
- Tarifas de recopilación de datos y licencias
- Limpieza y anotación manual
- Cumplimiento de derechos de autor y revisión legal
- Actualizaciones y mantenimiento continuos
El artículo argumenta de forma convincente que los datos de formación representan la parte más costosa —y peor remunerada— del desarrollo de los programas de aprendizaje de derecho (LLM).
Talento de ingeniería y gastos generales operativos
Para obtener un máster en Derecho (LLM) se requiere experiencia especializada. Los ingenieros de aprendizaje automático, los científicos de datos, los especialistas en infraestructura y los investigadores no son baratos. Los salarios para estos puestos suelen oscilar entre 150.000 y más de 500.000 dólares anuales en los principales centros tecnológicos.
Además de los salarios, existen gastos operativos generales: gestión de proyectos, seguimiento de experimentos, control de versiones de modelos, seguridad e infraestructura de cumplimiento normativo.
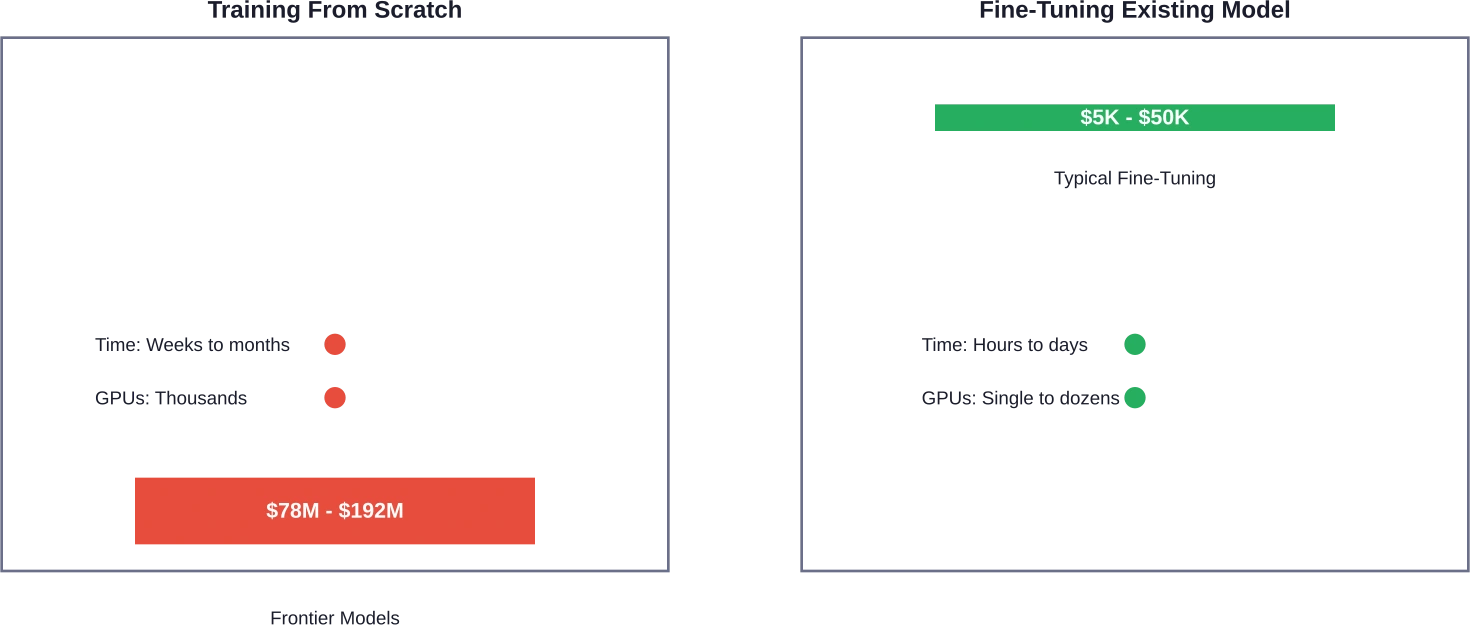
Entrenamiento desde cero vs. ajuste fino: una comparación de costos
No todo el mundo necesita crear GPT-5. Decidir entre entrenar desde cero y perfeccionar un modelo existente puede ahorrar a las organizaciones entre 60 y 901 TP3T de su presupuesto de IA.
Cuándo tiene sentido entrenar desde cero
Un entrenamiento completo desde cero suele tener sentido cuando:
- Su dominio requiere patrones de lenguaje fundamentalmente diferentes a los modelos generales.
- Las normativas de protección de datos prohíben el uso de modelos comerciales.
- Necesitas tener control total sobre la arquitectura y el comportamiento del modelo.
- Su organización cuenta con el presupuesto y la experiencia necesarios para respaldar el desarrollo de modelos a largo plazo.
La alternativa de ajuste fino
El ajuste fino consiste en tomar un modelo preentrenado y adaptarlo a tareas o dominios específicos. La diferencia de costo es sustancial. Mientras que entrenar GPT-4 desde cero costó casi 100 millones de TP4T, ajustarlo para aplicaciones especializadas podría costar entre 5000 y 50 000 TP4T.
Una investigación de la Universidad Nacional de Colombia demostró estrategias de ajuste fino eficientes mediante LoRA (Adaptación de Rango Bajo). Sus experimentos mostraron que un modelo base cuantificado a 8 bits podía ajustarse en aproximadamente 7 horas en una sola GPU NVIDIA T4 con 16 GB de VRAM, hardware que cuesta aproximadamente $2-4 por hora en las principales plataformas en la nube.
Formación económica: ¿Es posible realizarla por menos de 100.000 TP4T?
La respuesta es sí, pero con importantes limitaciones en cuanto al tamaño y las capacidades del modelo.
Un artículo de arXiv titulado “FLM-101B: Un programa LLM abierto y cómo capacitarlo con un presupuesto de $100K” demostró que la capacitación en LLM a menor escala es factible con una gestión cuidadosa de los recursos. Las estrategias clave incluyen:
- Utilizar arquitecturas de modelos más pequeñas (entre 1 y 20 mil millones de parámetros en lugar de más de 175 mil millones).
- Aprovechar los marcos de código abierto y las bases de código preexistentes.
- Optimización de las ejecuciones de entrenamiento con una selección eficiente de hiperparámetros.
- Utilizando técnicas de entrenamiento y cuantificación de precisión mixta
Un estudio del Instituto Fraunhofer comparó tres optimizadores —AdamW, Lion y una tercera variante— para el preentrenamiento de modelos lineales de lógica difusa (LLM) con un presupuesto limitado. Sus experimentos utilizaron dos nodos de clúster equipados con múltiples GPU, demostrando que la elección del optimizador influye significativamente tanto en el tiempo de entrenamiento como en el rendimiento final del modelo.
La alternativa de peso abierto
El lanzamiento de gpt-oss-120b y gpt-oss-20b por parte de OpenAI en agosto de 2025 cambió las reglas del juego. Estos modelos de peso abierto, publicados bajo la licencia Apache 2.0, ofrecen un sólido rendimiento en el mundo real a un coste sustancialmente menor que el del entrenamiento desde cero.
Ahora las organizaciones pueden descargar estos modelos y ajustarlos para casos de uso específicos, evitando por completo los enormes costes iniciales de formación.
Nube frente a instalación local: ¿Cuál resulta más económico a largo plazo?
Investigadores de Carnegie Mellon publicaron un análisis de costo-beneficio que examina cuándo la implementación local de un programa LLM alcanza el punto de equilibrio con los servicios comerciales en la nube. Sus hallazgos cuestionan las ideas convencionales.
Costos de infraestructura en la nube
Las plataformas en la nube ofrecen flexibilidad, pero cobran tarifas premium por el tiempo de GPU. Los principales proveedores suelen cobrar:
- $2-8 por hora para instancias de GPU de alto rendimiento
- Costes de transferencia de datos (a menudo pasados por alto, pero sustanciales a gran escala)
- Costes de almacenamiento para puntos de control del modelo y datos de entrenamiento
- tarifas de llamadas a la API si se utilizan servicios gestionados
¿La ventaja? Cero inversión inicial y la posibilidad de escalar según la demanda.
Inversión en infraestructura local
La compra directa de hardware requiere un capital considerable, pero elimina los costos recurrentes de la nube. Un clúster de GPU NVIDIA H100 podría costar entre 1.500.000 y 1.200.000 dólares por adelantado, pero esa inversión se amortiza en un plazo de 3 a 5 años.
El análisis de Carnegie Mellon reveló que las organizaciones con cargas de trabajo de IA sostenidas y predecibles suelen alcanzar el punto de equilibrio en un plazo de 12 a 18 meses cuando optan por la implementación local en lugar de los servicios en la nube.
Pero hay un inconveniente: la infraestructura local requiere personal especializado para el mantenimiento, los sistemas de refrigeración, la infraestructura eléctrica y la seguridad; costes que muchos análisis presupuestarios pasan por alto.
¿Qué factores influyen en el aumento de los costes de la formación en Derecho (LLM)?
Varios factores determinan si su presupuesto de capacitación se acerca más a $50,000 o a $50 millones.
Tamaño y arquitectura del modelo
La relación entre los parámetros y el costo no es lineal, sino exponencial. Duplicar el tamaño del modelo duplica con creces los costos de entrenamiento debido a:
- El aumento de los requisitos de memoria obliga al paralelismo multi-GPU.
- Tiempos de entrenamiento más prolongados a medida que la convergencia se ralentiza con la escala.
- Se requieren mayores datos para entrenar adecuadamente arquitecturas más grandes.
Duración y convergencia de la formación
Las sesiones de entrenamiento que no convergen suponen un enorme desperdicio de recursos. Un ajuste eficiente de los hiperparámetros puede influir drásticamente en la velocidad de aprendizaje de un modelo. Una sesión de entrenamiento bien ajustada podría alcanzar la precisión deseada en la mitad de tiempo que una mal configurada.
Aquí es donde la experiencia da sus frutos. Los ingenieros que comprenden los programas de tasa de aprendizaje, la optimización del tamaño de lote y las técnicas de regularización ahorran a las organizaciones millones en recursos computacionales desperdiciados.
Calidad y cantidad de datos
Entrenar con datos de baja calidad produce modelos de baja calidad, pero adquirir datos de alta calidad cuesta mucho dinero. Algunas organizaciones gastan más en la gestión de datos que en infraestructura informática.
El consenso emergente, plasmado en el documento de posición de Hugging Face sobre la economía de los datos de formación, es que los datos deberían ser el componente más costoso del desarrollo de un máster en derecho (LLM). Actualmente, están infravalorados.
Costes ocultos más allá de la formación
Aquí es donde fallan muchas proyecciones presupuestarias: los costos de capacitación son solo el comienzo.
Infraestructura de inferencia
El equipo de WiNGPT presentó un marco de "economía de la inferencia" que considera la inferencia de modelos lineales de lógica difusa (LLM) como una actividad de producción computacional. Su análisis reveló que los costos de inferencia suelen superar los costos de entrenamiento durante la vida útil del modelo.
Cada consulta enviada a su modelo consume recursos computacionales. A gran escala, la infraestructura de inferencia puede costar cientos de miles de dólares al mes.
Actualizaciones y reentrenamiento del modelo
El lenguaje evoluciona. La información objetiva cambia. Los requisitos empresariales cambian. Los modelos desarrollados en 2024 quedan obsoletos en 2026.
La formación continua o los programas de aprendizaje permanente representan costes recurrentes que muchas organizaciones subestiman durante la planificación inicial.
Almacenamiento y gestión de datos
Los puntos de control del modelo, los conjuntos de datos de entrenamiento, los registros de experimentos y los sistemas de control de versiones consumen almacenamiento. En el caso de los modelos de vanguardia, hablamos de petabytes de datos. Los costos de almacenamiento se acumulan silenciosamente, pero de forma considerable.
Supervisión y mantenimiento
Los sistemas de aprendizaje automático en producción requieren una monitorización constante para:
- Degradación del rendimiento
- Detección y mitigación de sesgos
- Vulnerabilidades de seguridad
- Fiabilidad y disponibilidad de la API
Estos costes operativos se mantienen mientras el modelo permanezca en producción.
| Categoría de costo | Una sola vez | Periódico | Rango típico |
|---|---|---|---|
| Formación inicial | ✓ | $50K – $192M | |
| Infraestructura de inferencia | ✓ | $10K – $500K/mes | |
| Reentrenamiento del modelo | ✓ | 20-50% de costo inicial/año | |
| Almacenamiento | ✓ | $5K – $50K/mes | |
| Equipo de ingeniería | ✓ | $500K – $5M/año | |
| Adquisición de datos | ✓ | ✓ | $100K – $10M+ |
Estrategias para reducir los costes de la formación en Derecho (LLM)
Las organizaciones inteligentes emplean múltiples tácticas para mantener los gastos bajo control sin sacrificar el rendimiento del modelo.
Aprendizaje por transferencia y formación progresiva
En lugar de entrenar desde cero, comience con un modelo de peso abierto existente y adáptelo progresivamente. Este enfoque, documentado en una investigación de la Universidad Nacional de Colombia, reduce el tiempo de entrenamiento entre 80 y 90 TP3T.
Técnicas de optimización eficientes
La investigación del Instituto Fraunhofer, que comparó AdamW, Lion y otros optimizadores, demostró que la selección del optimizador influye significativamente tanto en la velocidad de entrenamiento como en el consumo de recursos. Elegir el optimizador adecuado para cada caso específico puede reducir los costos de entrenamiento entre 20 y 301 TP3T.
Cuantización y compresión
El entrenamiento con precisión mixta (que combina operaciones de punto flotante de 16 y 32 bits) reduce el consumo de memoria y acelera el cálculo. La cuantización posterior al entrenamiento a representaciones de 8 o incluso 4 bits reduce el tamaño del modelo para su implementación sin una pérdida de rendimiento catastrófica.
Los experimentos realizados en la Universidad Nacional de Colombia demostraron un entrenamiento exitoso de LoRA en modelos cuantificados a 8 bits, mientras que los modelos pre-cuantizados de 4 bits mostraron un rendimiento aceptable en hardware de consumo.
Asignación inteligente de recursos
El uso y la gestión eficientes de los recursos informáticos evitan el pago por tiempo de inactividad. Las estrategias incluyen:
- Puja de instancias spot en plataformas en la nube para ejecuciones de entrenamiento no críticas
- Paralelismo en pipeline para maximizar la utilización de la GPU.
- Acumulación de gradiente para simular lotes de mayor tamaño en hardware limitado.
- Capacidades de reinicio de puntos de control para recuperarse de interrupciones.
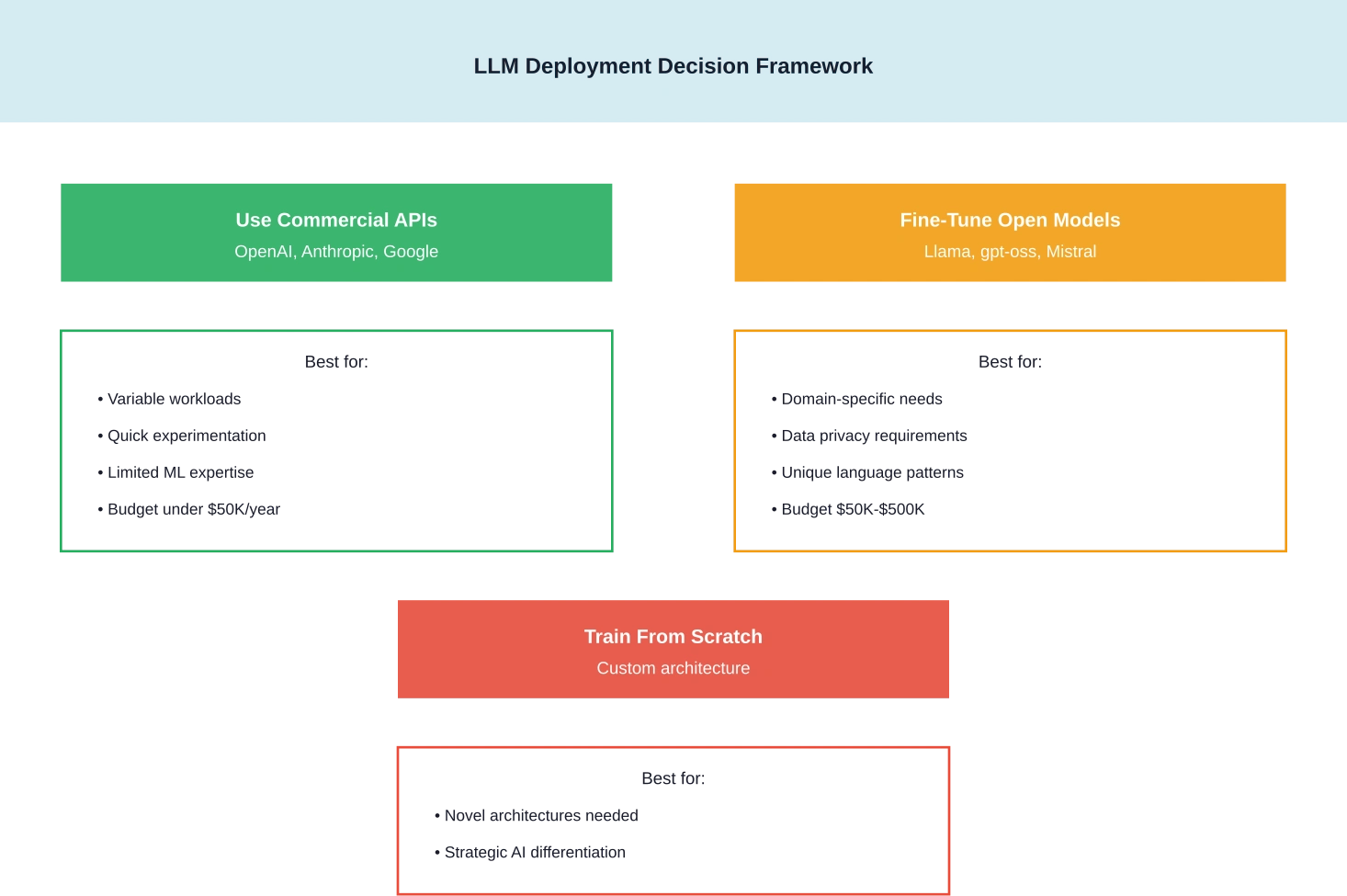
¿Deberías cursar tu propio máster en Derecho (LLM) en 2026?
El marco de decisión ha cambiado drásticamente con la proliferación de modelos de ponderación abierta capaces.
Para la mayoría de las organizaciones, la respuesta es no, al menos no desde cero. Los modelos gpt-oss de OpenAI, la serie Llama 3 de Meta y otras alternativas de peso abierto ofrecen un rendimiento que costaría decenas de millones replicar.
Pero, ¿el ajuste fino? Esa es otra historia. Las organizaciones con requisitos de dominio únicos, necesidades específicas de cumplimiento normativo o datos propietarios suelen beneficiarse del ajuste fino de los modelos existentes en lugar de depender únicamente de las API comerciales de uso general.
Cuándo tiene sentido la formación presencial
El análisis de costo-beneficio de Carnegie Mellon identificó escenarios específicos en los que la implementación y la capacitación del programa LLM en las instalaciones de la empresa resultan económicamente viables:
- Cargas de trabajo sostenidas que superan las 10.000 horas de GPU al año.
- Requisitos estrictos de residencia de datos que prohíben el uso de la nube.
- Iniciativas estratégicas de IA a largo plazo que abarcan más de 3 años.
- Disponibilidad de experiencia interna en infraestructura de aprendizaje automático
Cuando los servicios en la nube ganan
Para proyectos experimentales, cargas de trabajo variables u organizaciones sin experiencia en infraestructura de aprendizaje automático, las soluciones basadas en la nube y los servicios API ofrecen una mejor relación costo-beneficio. La flexibilidad para reducir la escala —o incluso desconectarse por completo— elimina el riesgo de una inversión de capital improductiva.

Reduzca los costos de la formación LLM antes de comenzar.
Entrenar un modelo LLM desde cero es costoso no solo por el coste computacional, sino también por la preparación de los datos, las elecciones de arquitectura del modelo y la estrategia de entrenamiento. IA superior Trabaja en esta capa de ingeniería, ayudando a las empresas a diseñar modelos de lógica descriptiva personalizados, preparar conjuntos de datos de entrenamiento y optimizar los procesos de entrenamiento para que los modelos se construyan de manera eficiente desde el principio.
Si está estimando el costo real de la formación de un LLM en 2026, es útil revisar la configuración técnica antes de comprometer grandes presupuestos de computación. Contacto IA superior evaluar la arquitectura de su programa de formación e identificar dónde se pueden reducir los costes incluso antes de que comience el proceso de formación.
El futuro de la economía en la formación de másteres en derecho (LLM)
Varias tendencias están transformando el panorama de los costes.
El lanzamiento de GPT-5.3-Codex por parte de OpenAI en febrero de 2026 (anunciado el 5 de febrero de 2026) demostró una eficiencia 25% superior a la de su predecesor. A medida que mejoran las arquitecturas de los modelos, disminuye la capacidad de cómputo necesaria para un rendimiento equivalente.
Los avances en hardware también continúan. Las sucesivas generaciones de GPU de NVIDIA ofrecen mejoras significativas en el rendimiento por vatio, lo que reduce tanto los gastos de capital como los operativos.
Pero, quizás lo más significativo, es que la democratización del acceso mediante modelos de ponderación abierta está transformando radicalmente quién puede participar en el desarrollo de los másteres en derecho (LLM). Lo que requería $100 millones en 2023 podría lograrse con $100 000 en 2026 mediante el uso inteligente del aprendizaje por transferencia y técnicas de formación eficientes.
Preguntas frecuentes
¿Cuánto cuesta entrenar GPT-4 desde cero?
Según el Informe del Índice de IA de Stanford de 2024 y un artículo de The Wall Street Journal, el entrenamiento de GPT-4 costó entre 1.047.800 y 1.041.000 millones de dólares. Esto incluye la infraestructura informática, los costos de energía, la adquisición de datos y los recursos de ingeniería durante el período de entrenamiento. El costo de entrenamiento de Gemini Ultra se estima en aproximadamente 1.041.000 millones de dólares, según el Informe del Índice de IA de Stanford de 2024.
¿Es posible formar a un LLM por menos de $100,000?
Sí, pero con limitaciones significativas en cuanto al tamaño y las capacidades del modelo. La investigación documentada en el artículo FLM-101B demostró que es posible entrenar modelos más pequeños (de 1 a 20 mil millones de parámetros) con un presupuesto de $100,000 mediante arquitecturas eficientes, procedimientos de entrenamiento optimizados y una gestión cuidadosa de los recursos. El ajuste fino de los modelos de peso abierto existentes resulta mucho más rentable para la mayoría de los casos de uso.
¿Qué es más económico: la formación LLM en la nube o en las instalaciones de la empresa?
Depende de los patrones de uso. Un estudio de Carnegie Mellon reveló que, por lo general, la implementación local alcanza el punto de equilibrio con los costos de la nube en un plazo de 12 a 18 meses para organizaciones con cargas de trabajo sostenidas y predecibles que superan las 10 000 horas de GPU anuales. Los servicios en la nube resultan más rentables para cargas de trabajo variables, proyectos experimentales u organizaciones que carecen de experiencia en infraestructura.
¿Cuánto cuesta la inferencia LLM en comparación con el entrenamiento?
Las investigaciones del equipo de WiNGPT sugieren que los costos de inferencia suelen superar los costos de entrenamiento durante la vida útil de un modelo. Si bien el entrenamiento es un gasto único (con reentrenamiento periódico), la inferencia se ejecuta de forma continua mientras el modelo esté en servicio. Las aplicaciones con mucho tráfico pueden generar cientos de miles de dólares en costos de inferencia mensuales.
¿Es más barato el ajuste fino que el entrenamiento desde cero?
Mucho más económico. El ajuste fino puede costar entre 60 y 90 TP3T menos que el entrenamiento desde cero. Mientras que entrenar modelos de vanguardia como GPT-4 cuesta entre 78 y 100 millones de TP4T, ajustar esos mismos modelos para aplicaciones específicas suele costar entre 5000 y 50 000 TP4T. Una investigación de la Universidad Nacional de Colombia demostró un ajuste fino efectivo en tan solo 7 horas en una sola GPU NVIDIA T4.
¿Qué GPU es la mejor para la formación de LLM con presupuesto limitado?
Para capacitaciones con presupuesto limitado, las GPU NVIDIA T4 (16 GB de VRAM) ofrecen un punto de partida razonable a $2-4 por hora en plataformas en la nube. Para proyectos más exigentes, las GPU A100 o H100 brindan un mejor rendimiento por dólar, aunque con tarifas por hora más altas. La A800 80G tiene costos base de alrededor de $0.79 por hora, según una investigación de arXiv sobre la economía de las GPU.
¿Cómo cambian los modelos de ponderación abierta como gpt-oss la economía?
El lanzamiento en marzo de 2026 de gpt-oss-120b y gpt-oss-20b por parte de OpenAI bajo la licencia Apache 2.0 transforma radicalmente el panorama de costes. Ahora, las organizaciones pueden descargar modelos de última generación y ajustarlos a sus necesidades específicas, evitando así el elevado coste que supone entrenarlos desde cero. Esto democratiza el acceso a modelos de vanguardia para organizaciones con presupuestos limitados.
Tomar la decisión sobre la capacitación
Formar a un máster en Derecho desde cero representa una inversión financiera enorme que solo tiene sentido para organizaciones con requisitos únicos, presupuestos sustanciales e iniciativas estratégicas de IA a largo plazo.
Para la gran mayoría de los casos de uso, el ajuste fino de modelos de ponderación abierta ofrece entre 80 y 901 TP3T de valor a un costo de entre 5 y 101 TP3T. La proliferación de modelos abiertos de alta calidad de OpenAI, Meta, Mistral y otros ha hecho que el desarrollo personalizado de LLM sea accesible para organizaciones que no se lo habrían planteado hace tres años.
La verdadera cuestión no es si puedes permitirte entrenar desde cero, sino si puedes permitirte no aprovechar los miles de millones de dólares ya invertidos en modelos básicos de entrenamiento con peso libre.
¿Listo para explorar la implementación de LLM en su organización? Comience evaluando los modelos de ponderación abierta existentes según sus requisitos específicos. Calcule los costos de inferencia esperados utilizando herramientas como las disponibles para el cálculo de costos de entrenamiento de LLM. Y, lo más importante, comience con experimentos de ajuste fino a pequeña escala antes de comprometerse con mayores inversiones en infraestructura.