Resumen rápido: Las API de inferencia LLM más rápidas en 2026 provienen de proveedores como Groq, SiliconFlow y Hugging Face, con una latencia inferior a 2 segundos y un rendimiento superior a 100 tokens por segundo. Los precios varían drásticamente: desde $0.28 por millón de tokens de entrada de DeepSeek hasta $21.00 de OpenAI para GPT-5.2 Pro. Para lograr una inferencia rentable, es necesario equilibrar la velocidad, el precio y la capacidad del modelo según la carga de trabajo específica.
La velocidad es crucial al implementar modelos de lenguaje a gran escala. Sin embargo, la API de inferencia más rápida no siempre es la más barata, y la más barata no siempre es lo suficientemente rápida.
A principios de 2026, el mercado de inferencia LLM se ha fragmentado en distintos niveles. Los proveedores premium como OpenAI cobran precios exorbitantes por modelos de vanguardia. Mientras tanto, nuevos competidores agresivos como DeepSeek ofrecen precios 90% o más por debajo de los actores establecidos.
Esta guía desglosa las cifras reales. Precios por millón de tokens, mediciones de latencia reales, pruebas de rendimiento y los costes ocultos que no se anuncian en las páginas de precios.
Comprensión de las métricas de velocidad de inferencia de LLM
Antes de comparar proveedores, conviene entender qué significa realmente "rápido" en el contexto de las API de LLM.
Tres métricas son las más importantes:
- Estado latente Mide el tiempo hasta el primer token: la rapidez con la que el modelo comienza a responder tras recibir la solicitud. Según las métricas del proveedor de inferencias de Hugging Face, los modelos de mayor rendimiento alcanzan una latencia inferior a 1,5 segundos. Groq suele ser citado como extremadamente rápido en pruebas comparativas de terceros y en sus propios informes de rendimiento (tokens/seg).
- Rendimiento Se realiza un seguimiento de los tokens generados por segundo una vez que el modelo comienza a responder. Los datos de Hugging Face muestran que los principales proveedores alcanzan los 127 tokens por segundo o más para modelos como Qwen3.5-35B-A3B.
- Ventana de contexto Determina la cantidad de texto que el modelo puede procesar en una sola solicitud. Los modelos modernos admiten entre 128 KB y 262 KB de tokens, aunque los contextos más largos pueden aumentar tanto la latencia como el coste.
- Sin embargo, la velocidad varía drásticamente según las características de la carga de trabajo. Las consultas cortas con respuestas breves se completan más rápido que las tareas de razonamiento con contexto extenso. El procesamiento por lotes sacrifica la inmediatez de la respuesta a cambio de un mayor rendimiento y menores costos.
Proveedores de inferencia LLM más rápidos por latencia
Cuando la velocidad pura es la prioridad, un puñado de proveedores superan sistemáticamente a la competencia.
Groq: Diseñado específicamente para la velocidad.
Groq utiliza hardware de unidad de procesamiento de lenguaje (LPU) personalizado, diseñado específicamente para la inferencia LLM. Los debates en la comunidad y las propias pruebas de rendimiento de Groq lo posicionan como "extremadamente rápido" en cuanto a velocidad de inferencia, con mediciones de tokens por segundo que lideran consistentemente el mercado.
La compañía publicó nuevos resultados de referencia para Llama 3.3 70B, que demuestran un rendimiento de inferencia líder en la industria. Para aplicaciones donde el tiempo de respuesta inferior a un segundo es crucial (chatbots, asistentes en tiempo real, herramientas interactivas), la arquitectura de Groq ofrece ventajas cuantificables.
Los precios no se publican para todos los modelos, por lo que los desarrolladores deben consultar la documentación oficial de Groq para conocer las tarifas actuales.
SiliconFlow: Velocidad y asequibilidad
SiliconFlow ofreció velocidades de inferencia hasta 2,3 veces más rápidas y una latencia 32% menor en comparación con las principales plataformas de IA en la nube en pruebas de rendimiento recientes, manteniendo una precisión constante. La plataforma ofrece opciones de pago por uso sin servidor y con GPU reservadas.
Esta combinación de velocidad y control de costes convierte a SiliconFlow en una opción atractiva para implementaciones en producción, donde ambos factores son cruciales. La plataforma admite múltiples modelos de código abierto con precios transparentes y opciones de infraestructura flexibles.
Proveedores de inferencia de rostros abrazados
Hugging Face integra múltiples proveedores de inferencia mediante una API unificada, monitorizando el rendimiento en diversas combinaciones de modelos y proveedores. La interfaz permite a los desarrolladores redirigir automáticamente las solicitudes al proveedor más rápido o económico para cada modelo. Gracias a la compatibilidad del enrutador con llamadas OpenAI, la migración resulta sencilla para quienes ya utilizan integraciones.

Desarrolle aplicaciones LLM optimizadas para una inferencia rápida.
Las respuestas rápidas de LLM dependen de la arquitectura, la configuración del modelo y la infraestructura adecuadas. IA superior Desarrollan software de IA y sistemas de PLN que integran grandes modelos lingüísticos en aplicaciones reales como chatbots, herramientas de automatización y plataformas de análisis de datos. Su equipo diseña flujos de trabajo de modelos, servicios de backend y entornos de implementación para que las funcionalidades de LLM se ejecuten de forma fiable en sistemas de producción.
¿Estás desarrollando un producto que utilice las API de LLM?
Habla con una IA superior a:
- Diseñar y crear aplicaciones basadas en LLM
- Desarrollar sistemas de PLN y software de IA.
- Implementar modelos de lenguaje dentro de las plataformas existentes
👉 Solicita una consulta de IA con IA superior para hablar sobre su proyecto.
Precios de inferencia de LLM: Panorama del mercado en 2026
Las estructuras de precios varían enormemente entre los proveedores. Algunos cobran tarifas premium por modelos propietarios. Otros compiten agresivamente ofreciendo precios competitivos para modelos de código abierto.
Así está el mercado a principios de 2026:
Nivel Premium: OpenAI y Anthropic
OpenAI lanzó GPT-5.2 Pro en febrero de 2026 a un costo de $21.00 por millón de tokens de entrada y $168.00 por millón de tokens de salida. El modelo estándar GPT-5.2 cuesta $8.00 de entrada y $32.00 de salida por millón de tokens.
Los modelos Claude de Anthropic se sitúan en un segmento de precios premium similar. Estos proveedores justifican los precios más elevados con sus capacidades de vanguardia, su fiabilidad y sus exhaustivas pruebas de seguridad.
Nivel medio: Google Gemini y otros
Los modelos Gemini de Google ofrecen precios competitivos para modelos de alto rendimiento. El segmento intermedio, más amplio, incluye proveedores como Mistral AI, que equilibra el rendimiento con precios más accesibles que los proveedores premium.
Nivel de presupuesto: DeepSeek Disruption
DeepSeek ha superado agresivamente a sus competidores con sus modelos de "pensamiento" V3.2-Exp, que se ofrecen a tan solo $0.28 por millón de tokens de entrada (cache-fall) y $0.42 por millón de tokens de salida. Esto representa un descuento de más de 90% en comparación con los proveedores premium.
La gama Grok de xAI también está dirigida a desarrolladores que buscan optimizar costes. Grok 4 Fast y Grok 4.1 Fast tienen un precio de $0.20 de entrada / $0.50 de salida por millón de tokens.
| Proveedor | Ejemplo de modelo | Entrada (tokens $/M) | Salida (tokens $/M) | Nivel de rendimiento |
|---|---|---|---|---|
| Abierto AI | GPT-5.2 Pro | $21.00 | $168.00 | De primera calidad |
| Abierto AI | GPT-5.2 | $8.00 | $32.00 | De primera calidad |
| xAI | Comprender 4 | $3.00 | $15.00 | Nivel medio |
| xAI | Comprender 4 rápido | $0.20 | $0.50 | Presupuesto |
| Búsqueda profunda | V3.2-Exp | $0.28 | $0.42 | Presupuesto |
| Novita (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | Presupuesto |
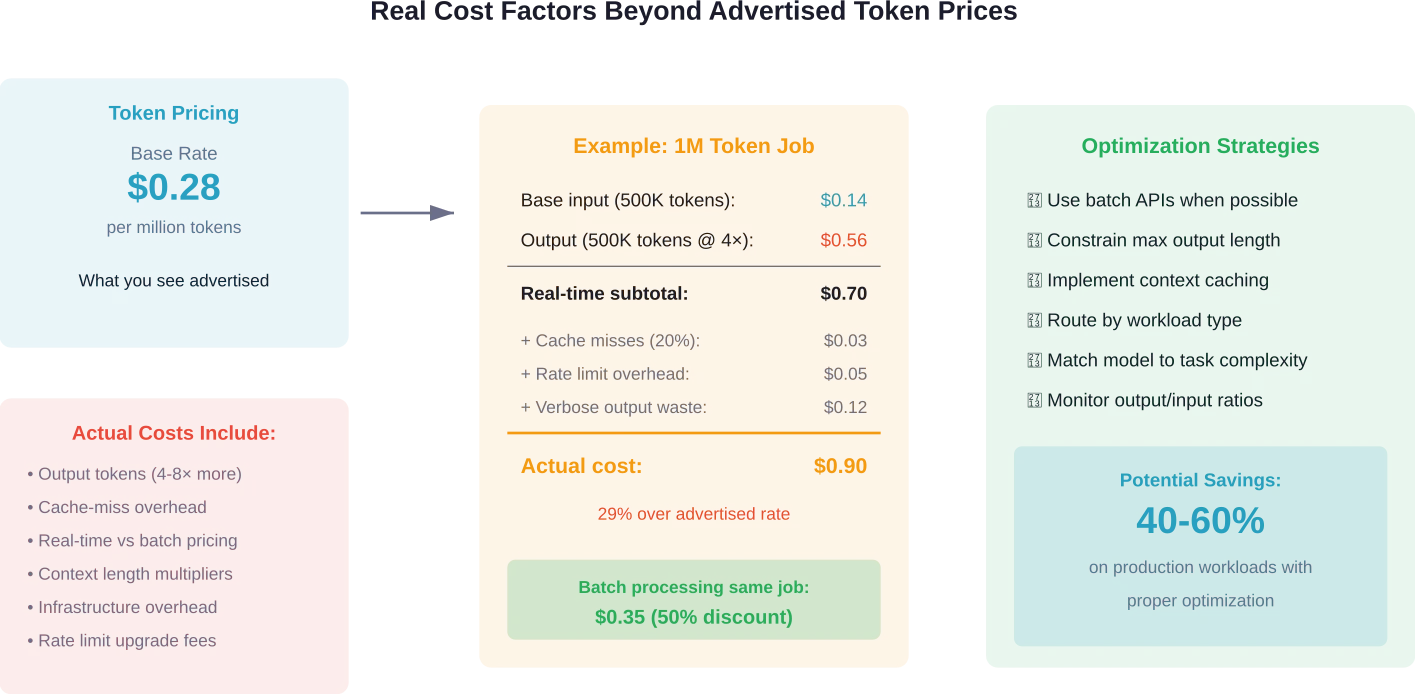
Costes ocultos más allá del precio de los tokens
El precio de venta al público por millón de tokens solo cuenta una parte del costo real.
Varios factores ocultos influyen significativamente en el gasto real:
Almacenamiento en caché y reutilización del contexto
Algunos proveedores ofrecen tarifas con descuento para el contexto almacenado en caché que se reutiliza en distintas solicitudes. La tarifa $0.28 de DeepSeek se aplica a las solicitudes sin caché; el precio para las solicitudes con caché es menor. Si su aplicación procesa repetidamente contextos similares, el almacenamiento en caché puede reducir considerablemente los costos.
Precios por lotes frente a precios en tiempo real
OpenAI y Google ofrecen API de procesamiento por lotes con precios reducidos, a veces hasta 50% por debajo de las tarifas en tiempo real. Según las discusiones de la comunidad de Hugging Face, no existe un equivalente directo de la API Batch de OpenAI con precios especiales con descuento en los puntos finales sin servidor de Hugging Face.
La inferencia por lotes funciona para cargas de trabajo que no requieren una respuesta inmediata: procesamiento de datos, generación de contenido y tareas de análisis. La contrapartida es un retraso en la finalización a cambio de menores costes.
Economía de tokens de producción
Los tokens de salida suelen costar entre 4 y 8 veces más que los tokens de entrada. Un modelo que genera respuestas extensas consume el presupuesto más rápido que uno que responde de forma concisa.
Para optimizar los costos, limitar la longitud máxima de salida evita el uso excesivo de tokens. Establecer límites demasiado bajos puede truncar las respuestas antes de entregarlas por completo, por lo que la configuración requiere un equilibrio entre la exhaustividad y el control de costos.
Costos de infraestructura y escalabilidad
Las API sin servidor cobran por token y no generan gastos generales de infraestructura. Los modelos de capacidad reservada, como las opciones de GPU reservadas de SiliconFlow, requieren compromisos iniciales, pero ofrecen una mejor rentabilidad por token a gran escala.
Las investigaciones sobre la implementación de GPU heterogéneas demuestran que la rentabilidad varía significativamente según las características de la carga de trabajo. Según el análisis del servicio LLM sobre GPU heterogéneas, la asignación de los tipos de solicitud al hardware adecuado mejora la utilización de los recursos y reduce los costos efectivos.
Relación velocidad-coste: encontrar el punto óptimo
El proveedor óptimo depende totalmente de los requisitos de carga de trabajo.
Para aplicaciones donde la latencia es crucial —como chatbots de atención al cliente, asistentes de codificación en tiempo real y demostraciones interactivas— la velocidad justifica un precio elevado. Un retraso de respuesta de 2 segundos ahuyenta a los usuarios, independientemente del ahorro de costes.
Para el procesamiento por lotes de alto volumen (clasificación de contenido, extracción de datos, análisis), el costo por millón de tokens es el factor determinante. El precio de DeepSeek, $0.28, con un rendimiento aceptable (si no líder), tiene sentido desde el punto de vista económico.
Las investigaciones sobre la gestión de modelos de lógica descriptiva sugieren que los enfoques híbridos pueden optimizar ambas métricas. El uso de modelos más pequeños y rápidos para el procesamiento inicial y el enrutamiento de consultas complejas a modelos más grandes reduce los costos promedio sin comprometer la calidad. Según el estudio, incluso pequeñas sugerencias de modelos más grandes (10-30% de respuesta completa) mejoran sustancialmente la precisión de los modelos más pequeños.
Consideraciones sobre el tamaño del modelo
El tamaño del modelo influye directamente tanto en la velocidad como en el coste.
Según las recomendaciones de Hugging Face para elegir modelos LLM de código abierto, un modelo de 7-8 mil millones de parámetros requiere de 14 a 16 GB de VRAM con precisión FP16, o de 6 a 8 GB con cuantización de 4 bits. Las opciones en la nube incluyen instancias AWS g5.xlarge.
Los modelos más pequeños, con entre 1 y 3 mil millones de parámetros, se ejecutan en 4 a 6 GB de VRAM (2 GB cuantificados) y manejan tareas básicas (clasificación de texto, autocompletado, chat simple) en hardware modesto como la RTX 3060 o las GPU de portátiles.
Los modelos más grandes ofrecen un mejor razonamiento, pero requieren más recursos computacionales. Según estudios de eficiencia, la implementación de un modelo LLaMA-2-70B requiere al menos dos GPU NVIDIA A100 (cada una con 80 GB de VRAM) para la inferencia FP16.
Proveedores más rentables para inferencia rápida
Según las métricas de rendimiento y los datos de precios, varios proveedores ofrecen atractivas relaciones velocidad-coste:
SiliconFlow
SiliconFlow combina una velocidad competitiva (2,3 veces más rápida que algunas plataformas líderes) con precios flexibles. La plataforma admite tanto capacidad sin servidor como capacidad reservada, lo que permite optimizar los costos según los patrones de uso.
El servicio proporciona una nube de IA todo en uno con una relación precio-rendimiento líder en el sector, dirigida tanto a desarrolladores como a empresas.
Proveedores de inferencia de rostros abrazados
El enrutador unificado de Hugging Face agrega múltiples proveedores, lo que permite el enrutamiento automático a la opción más rápida o más económica para cada modelo. Según sus métricas:
- Novita ofrece modelos Qwen3.5 con entrada $0.25-$0.60 y latencia inferior a 1,1 segundos.
- Together AI ofrece modelos comparables con una latencia ligeramente mayor, pero precios similares.
- Múltiples proveedores compiten por cada modelo popular, lo que impulsa la eficiencia.
El enrutador admite llamadas a la API compatibles con OpenAI, lo que simplifica la migración desde otros proveedores. Los desarrolladores pueden especificar preferencias de enrutamiento —”:fastest”, “:cheapest”— para optimizar según diferentes objetivos.
Mistral AI
Mistral AI ofrece un rendimiento sólido a un precio de gama media. La empresa se centra en arquitecturas de modelos eficientes que reducen los costes de inferencia sin sacrificar la capacidad.
Los modelos Mistral alcanzan estándares de calidad competitivos a la vez que mantienen costes razonables por token, lo que los hace atractivos para implementaciones en producción que buscan equilibrar múltiples restricciones.
Búsqueda profunda
Para cargas de trabajo donde el costo domina la toma de decisiones, el precio competitivo de DeepSeek ($0.28 de entrada / $0.40 de salida) representa el precio mínimo actual del mercado para modelos capaces.
El rendimiento es inferior al de los proveedores premium, pero sigue siendo aceptable para muchas aplicaciones. El ahorro de costes —hasta 90% en comparación con los modelos de gama alta— permite casos de uso que no justificarían un precio premium.
IA de fuegos artificiales
Fireworks AI se especializa en la inferencia optimizada para modelos de código abierto. La plataforma se centra en la fiabilidad de nivel de producción con precios y rendimiento predecibles.
El servicio proporciona una infraestructura específicamente optimizada para la gestión de LLM, con funciones diseñadas para desarrolladores que crean aplicaciones en lugar de experimentar con modelos.
Consideraciones sobre la evaluación comparativa del desempeño
Los datos de referencia publicados no siempre reflejan el rendimiento en el mundo real.
Diversos factores crean discrepancias entre las métricas anunciadas y la experiencia de producción:
Las condiciones de carga afectan la latencia. Los proveedores con mucha carga experimentan una disminución en la velocidad. La hora del día, la región geográfica y la demanda actual influyen en los tiempos de respuesta reales.
Las características de las solicitudes son de suma importancia. Las indicaciones breves con resultados concisos se completan más rápido que las tareas de razonamiento de contexto extenso. Según investigaciones sobre la relación entre energía y rendimiento en la inferencia de modelos de lenguaje natural (LLM), la inferencia presenta una variabilidad considerable entre las distintas consultas y fases de ejecución.
La latencia de arranque en frío puede afectar a la primera solicitud en arquitecturas sin servidor.
Los límites de velocidad restringen el rendimiento. Incluso las API rápidas limitan las solicitudes que superan ciertos volúmenes, lo que requiere suscripciones de nivel superior o capacidad reservada para aplicaciones de alto volumen.
Opciones de implementación de infraestructura
Más allá de las API gestionadas, las decisiones sobre la infraestructura influyen significativamente en el coste y el rendimiento.
API sin servidor
Las opciones sin servidor, como las de Hugging Face, OpenAI y otras, cobran por token y no requieren gestión de infraestructura. Este modelo funciona bien para cargas de trabajo variables, creación de prototipos y aplicaciones con demanda impredecible.
La desventaja es un mayor coste por token en comparación con una infraestructura dedicada a gran escala.
Capacidad reservada
Las instancias de GPU reservadas o los puntos finales dedicados proporcionan recursos garantizados a tarifas por token más bajas. Proveedores como SiliconFlow ofrecen esta opción junto con los precios de los servicios sin servidor.
La capacidad reservada tiene sentido económico una vez que el uso alcanza umbrales constantes en los que el coste de compromiso cae por debajo del gasto equivalente en servicios sin servidor.
Inferencia autoalojada
Realizar inferencias en infraestructura propia o alquilada proporciona el máximo control y, potencialmente, los costes más bajos para volúmenes muy elevados.
Las investigaciones sobre la implementación de LLM en dispositivos periféricos ponen de manifiesto ciertas limitaciones: un modelo de 7-8 mil millones de parámetros requiere una cantidad considerable de memoria y recursos computacionales. Los estudios de caracterización de SoC móviles demuestran que, incluso con unidades de procesamiento heterogéneas, el ancho de banda de la memoria limita el rendimiento, y algunas configuraciones alcanzan tan solo 40-45 GB/s por unidad antes de requerir múltiples procesadores para saturar el ancho de banda disponible.
El autoalojamiento requiere experiencia en la implementación, optimización, monitorización y escalado de modelos, una carga que las API sin servidor eliminan.
Cómo elegir el proveedor adecuado para su carga de trabajo.
Los criterios de decisión deben priorizar las características de la carga de trabajo sobre las comparaciones abstractas.
Haz estas preguntas:
- ¿Cuál es el patrón de uso? Las cargas de trabajo constantes y de alto volumen favorecen la capacidad reservada o el autoalojamiento. La demanda variable e impredecible se adapta mejor a las API sin servidor.
- ¿Qué tan sensible es la aplicación a la latencia? Las interacciones de usuario en tiempo real requieren tiempos de respuesta inferiores a un segundo. El procesamiento en segundo plano tolera latencias de varios segundos para ahorrar costes.
- ¿Qué capacidad del modelo se necesita realmente? Muchas aplicaciones sobredimensionan la capacidad del modelo. Los modelos más pequeños y rápidos gestionan tareas sencillas a un menor coste.
- ¿Puede funcionar el procesamiento por lotes? Las cargas de trabajo no urgentes se benefician de los descuentos por lotes 50% cuando los proveedores los ofrecen.
- ¿Cuál es la relación entre la producción y la entrada? Las aplicaciones que generan respuestas largas pagan un precio elevado por los tokens de salida. Limitar la verbosidad reduce significativamente los costos.
- ¿La carga de trabajo se beneficia del almacenamiento en caché de contexto? El procesamiento repetido de contextos similares con soporte para almacenamiento en caché reduce los costos por solicitud.
Preguntas frecuentes
¿Cuál es la API de inferencia LLM más barata en 2026?
DeepSeek ofrece el precio más bajo, $0.28 por millón de tokens de entrada y $0.40 por millón de tokens de salida para sus modelos V3.2-Exp a principios de 2026. Grok 4 Fast de xAI, con un precio de $0.20 por entrada y $0.50 por salida, tiene un precio comparable. Sin embargo, el costo total depende de la verbosidad de la salida, la eficiencia del almacenamiento en caché y la disponibilidad del procesamiento por lotes. La opción más económica varía según estos factores específicos de la carga de trabajo.
¿Qué proveedor ofrece la velocidad de inferencia LLM más rápida?
Groq se posiciona consistentemente como el proveedor de inferencia más rápido, gracias a su hardware LPU diseñado específicamente y optimizado para cargas de trabajo LLM. Pruebas de rendimiento de terceros y debates en la comunidad confirman que Groq ofrece un rendimiento líder en la industria en cuanto a tokens por segundo. Según las métricas de Hugging Face, otras opciones rápidas incluyen Novita (que aloja modelos Qwen con una latencia de entre 0,66 y 1,09 segundos) y SiliconFlow (2,3 veces más rápido que algunas plataformas líderes). La velocidad real depende del tamaño del modelo, la longitud del contexto y las condiciones de carga actuales.
¿Cuánto cuesta procesar mil millones de tokens a través de una API LLM?
El costo de mil millones de tokens varía drásticamente según el proveedor y la combinación de entrada/salida. Con las tarifas de DeepSeek ($0.28 entrada / $0.40 salida), mil millones de tokens cuestan $280 solo para entrada o $400 solo para salida. Con las tarifas de GPT-5.2 Pro de OpenAI ($21 entrada / $168 salida), el mismo volumen cuesta $21,000 entrada o $168,000 salida. Una carga de trabajo típica con 60% de entrada y 40% de salida costaría aproximadamente $328 en DeepSeek frente a $79,800 en GPT-5.2 Pro, una diferencia de 240 veces.
¿Las API de procesamiento por lotes realmente ahorran dinero?
Sí, cuando esté disponible. OpenAI y Google ofrecen API para procesamiento por lotes con descuentos de aproximadamente 50% en comparación con el procesamiento en tiempo real. La desventaja es la demora en la finalización: los trabajos por lotes pueden tardar horas en lugar de segundos. Según las discusiones de la comunidad de Hugging Face, muchos endpoints sin servidor de Hugging Face no ofrecen precios con descuento específicos para procesamiento por lotes, aunque los endpoints de inferencia dedicados sí pueden. El procesamiento por lotes es útil para tareas de procesamiento de datos, generación de contenido y análisis donde no se requieren resultados inmediatos.
¿Debo usar capacidad sin servidor o capacidad de GPU reservada?
Depende de los patrones de uso y el volumen. Las API sin servidor funcionan bien para la demanda variable, la creación de prototipos y volúmenes bajos a moderados, donde la comodidad supera el costo por token. La capacidad reservada se vuelve rentable cuando el uso constante alcanza el punto de equilibrio, donde los costos de compromiso caen por debajo del gasto equivalente en una solución sin servidor. SiliconFlow ofrece ambas opciones, lo que permite la optimización en función de los patrones de uso. Calcule su volumen real sostenido de tokens y compárelo con los precios de reserva para determinar el umbral de equilibrio.
¿Cómo afecta el tamaño del modelo a la velocidad y el coste de la inferencia?
Los modelos más grandes requieren más recursos computacionales, lo que aumenta tanto la latencia como los costos de infraestructura. Según la documentación de Hugging Face, un modelo de 1 a 3 mil millones de bits necesita solo de 2 a 4 GB de VRAM y ofrece inferencia rápida en hardware modesto, adecuado para tareas básicas. Un modelo de 7 a 8 mil millones de bits requiere de 6 a 16 GB de VRAM, dependiendo de la cuantización, y maneja cargas de trabajo más complejas. Un modelo de 70 mil millones de bits exige más de 140 GB de VRAM (varias GPU de gama alta) y procesa las solicitudes más lentamente. Los modelos más pequeños optimizan la velocidad y el costo; los modelos más grandes mejoran la capacidad y la calidad del razonamiento. Adapte el tamaño del modelo a los requisitos reales de la tarea en lugar de usar por defecto el modelo más grande disponible.
¿Puedo reducir costes optimizando la longitud de las indicaciones?
Por supuesto. Las indicaciones más cortas consumen menos tokens de entrada, lo que reduce directamente los costos. Más importante aún, limitar la longitud máxima de la respuesta evita respuestas excesivamente largas y costosas. Dado que los tokens de respuesta cuestan entre 4 y 8 veces más que los de entrada, un modelo que genera respuestas innecesariamente largas consume presupuesto rápidamente. Según las mejores prácticas, configure los parámetros `max_tokens` de forma adecuada a su caso de uso: un valor demasiado bajo trunca las respuestas, mientras que uno demasiado alto permite una verbosidad innecesaria. Supervise la longitud real de la respuesta y ajuste los límites según sea necesario. El almacenamiento en caché del contexto para los elementos de las indicaciones repetidas reduce aún más los costos cuando el proveedor lo admite.
Conclusión: Equilibrar velocidad y coste.
La API de inferencia LLM más rápida no es la mejor opción para todas las cargas de trabajo, y la API más barata no siempre es la más rentable cuando la calidad y la velocidad son importantes.
En 2026, el mercado ofrece una verdadera variedad de opciones. Proveedores de alta gama como OpenAI brindan capacidades de vanguardia a precios elevados. Competidores agresivos como DeepSeek ofrecen precios 90% o más inferiores a los de los líderes del mercado. Proveedores de infraestructura especializada como Groq y SiliconFlow optimizan sus procesos para lograr velocidad o rentabilidad.
El proveedor óptimo depende totalmente de sus requisitos específicos: sensibilidad a la latencia, necesidades de calidad de salida, volumen de uso, nivel de detalle de la salida, oportunidades de almacenamiento en caché y si el procesamiento por lotes funciona para su caso de uso.
Empiece por comprender las características de su carga de trabajo. Mida el volumen real de tokens, las relaciones de entrada/salida y los requisitos de latencia. Luego, asigne esos requisitos a los proveedores que se ajusten a sus limitaciones específicas.
No des por sentado que la opción más cara ofrece los mejores resultados, ni que la más barata sacrifica demasiada calidad. Prueba con varios proveedores utilizando cargas de trabajo representativas antes de comprometerte con una implementación a gran escala.
El mercado de inferencia LLM seguirá siendo altamente competitivo en 2026, con precios y rendimiento que mejoran rápidamente. Monitoree a los nuevos participantes y realice comparativas periódicamente para asegurarse de obtener el máximo valor a medida que el panorama evoluciona.
¿Listo para optimizar los costos de inferencia de LLM? Compare su carga de trabajo específica con la de otros proveedores utilizando los datos de precios y las métricas de rendimiento de esta guía para identificar la mejor relación velocidad-costo para su aplicación.