Resumen rápido: Las herramientas analíticas LLM con funciones de optimización de costos ayudan a las organizaciones a monitorear el uso de tokens, rastrear patrones de gasto y reducir los costos de infraestructura de IA mediante almacenamiento en caché inteligente, selección de modelos y asignación automatizada de recursos. Las plataformas líderes combinan el seguimiento de costos en tiempo real con la observabilidad del rendimiento para identificar flujos de trabajo costosos y optimizarlos sin sacrificar la calidad de la respuesta. Una gestión de costos eficaz requiere seguimiento basado en sesiones, optimización de avisos y selección estratégica de modelos según la complejidad de la tarea.
Las organizaciones que implementan modelos de lenguaje complejos se enfrentan a un desafío fundamental: los costos pueden dispararse sin que nadie se dé cuenta. El sistema de precios basado en tokens implica que cada llamada a la API tiene un costo, y sin un análisis adecuado, el chatbot o el analizador de documentos que lo respalda podrían estar consumiendo los presupuestos a un ritmo alarmante.
El auge de la adopción de modelos de gestión de clientes (LLM) ha generado una demanda urgente de plataformas analíticas especializadas. Estas herramientas no solo controlan el gasto, sino que identifican activamente oportunidades de optimización, automatizan estrategias de reducción de costes y proporcionan la visibilidad necesaria para tomar decisiones informadas sobre la selección de modelos y la infraestructura.
Sin embargo, hay que tener en cuenta que no todas las plataformas de análisis son iguales. Algunas se centran exclusivamente en la observabilidad, otras priorizan el seguimiento de costes, y las mejores combinan ambas con funciones de optimización prácticas. Comprender qué funcionalidades son más importantes para tu caso de uso marca la diferencia entre gestionar los costes de forma eficaz y malgastar dinero en un problema.
Comprensión de las estructuras de costos y los modelos de precios de los programas de Maestría en Derecho (LLM)
El modelo de precios basado en tokens domina el panorama de los sistemas de gestión de clientes (LLM). Según los precios oficiales de Anthropic, Claude Opus 4.6 cuesta $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Esta asimetría de precios es importante, ya que los tokens de salida cuestan cinco veces más que los de entrada.
La regla general es que las indicaciones más largas y las respuestas generadas más extensas implican un mayor número de tokens y, por lo tanto, mayores costes.
En realidad, la mayoría de las organizaciones subestiman sus verdaderos costos de gestión de aprendizaje permanente (LLM). Según análisis del sector, las tarifas de uso directo pueden representar entre 40 y 601 TP3T del total de los gastos de LLM, mientras que la infraestructura y la integración consumen entre 20 y 301 TP3T, y la capacitación y la optimización constituyen el resto.
Los multiplicadores de costos ocultos
La documentación de AWS indica que el almacenamiento en caché de solicitudes instantáneas puede reducir la latencia de respuesta de inferencia hasta en 85% y los costos de tokens de entrada hasta en 90% para los modelos compatibles en Amazon Bedrock. Sin embargo, sin análisis que identifiquen patrones que se puedan almacenar en caché, las organizaciones pierden por completo estos ahorros.
Según los estudios de caso de AWS, el tiempo total de procesamiento de las solicitudes ha oscilado entre 6,76 y 32,24 segundos, y esta variación refleja principalmente los diferentes requisitos de tokens de salida. Las respuestas rápidas, inferiores a 10 segundos, suelen gestionar consultas sencillas, mientras que las tareas analíticas complejas superan los 30 segundos.
El tamaño de las ventanas de contexto también incrementa los costos. Claude Opus 4.6 incluye una ventana de contexto de 1 millón de tokens en versión beta, lo cual es potente, pero costoso si las organizaciones envían habitualmente contextos innecesariamente grandes.
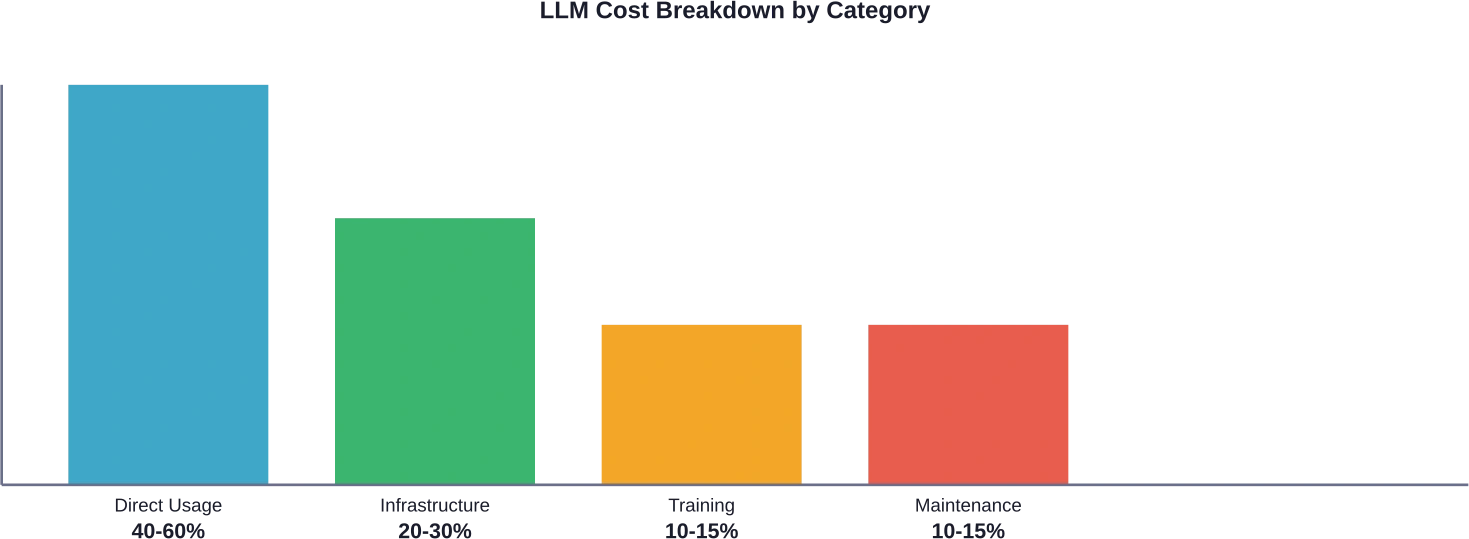
Características principales de las plataformas de análisis LLM
Las plataformas analíticas LLM eficaces ofrecen tres capacidades fundamentales: seguimiento integral de costes, observabilidad del rendimiento e información práctica para la optimización. Cada componente cumple una función específica en la gestión de cargas de trabajo de IA.
Seguimiento de costos basado en sesiones
Las sesiones agrupan las solicitudes relacionadas para mostrar el costo real de las interacciones del usuario. En lugar de ver llamadas individuales a la API, los equipos ven flujos de trabajo completos. Según los ejemplos de seguimiento de costos, los chats de soporte cuestan aproximadamente $0.12 en promedio con 5 llamadas a la API, los flujos de trabajo de análisis de documentos cuestan alrededor de $0.45 con 12 llamadas a la API, mientras que las consultas rápidas cuestan aproximadamente $0.02 con una sola llamada.
Este nivel de detalle es importante. Las organizaciones pueden identificar qué tipos de interacción generan costos y optimizar en consecuencia. La alternativa —tratar cada llamada a la API de forma aislada— oculta la verdadera rentabilidad unitaria de las funcionalidades de IA.
Monitorización del uso en tiempo real
Los patrones de consumo de tokens revelan oportunidades de optimización. Las plataformas de análisis rastrean las proporciones de tokens de entrada y salida, identifican las solicitudes costosas y señalan los picos de uso anómalos antes de que afecten los presupuestos.
Pero un momento. El monitoreo en tiempo real solo es útil si genera acciones. Las mejores plataformas integran alertas automatizadas y límites presupuestarios que evitan el descontrol de los costos.
Comparación del rendimiento de los modelos
Los distintos modelos destacan en diferentes tareas. Las herramientas de análisis permiten realizar pruebas A/B entre los modelos para encontrar el equilibrio óptimo entre coste y calidad para cada caso de uso.
Según una investigación del MIT-IBM Watson AI Lab, un error relativo promedio de 4% representa la mejor precisión alcanzable debido al ruido aleatorio de la semilla, pero un error de hasta 20% sigue siendo útil para la toma de decisiones. Las organizaciones deben definir umbrales de rendimiento aceptables antes de optimizar los costos.
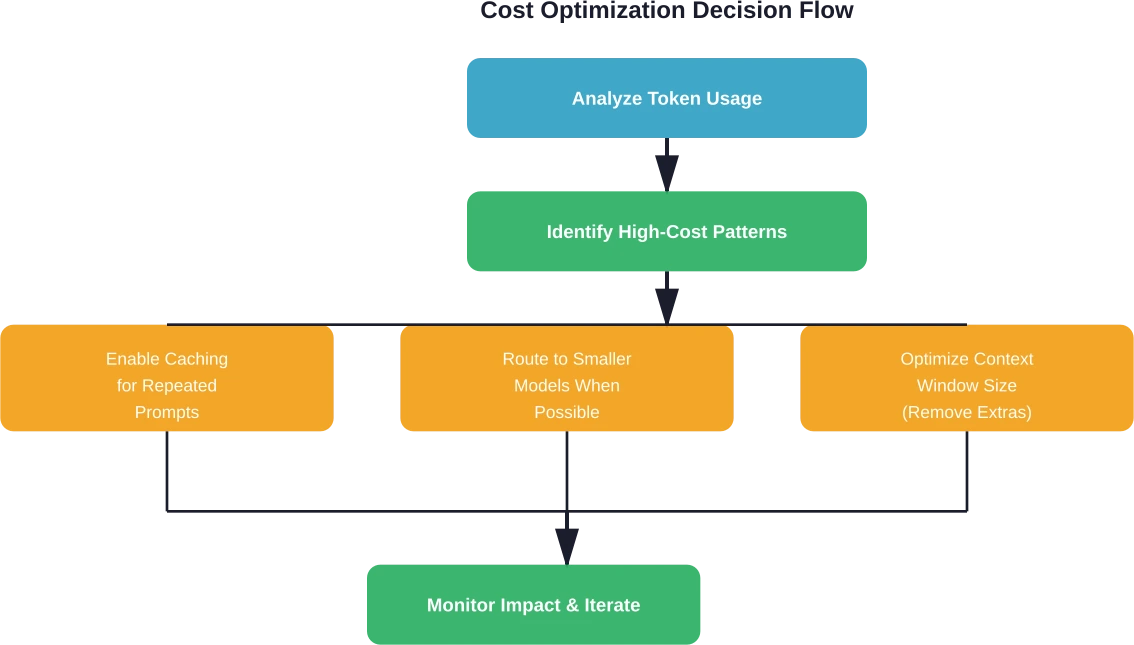
Estrategias de optimización de costes habilitadas por herramientas analíticas
Las plataformas de análisis no solo informan sobre los costes, sino que también permiten implementar estrategias de optimización específicas que reducen directamente el gasto sin sacrificar la funcionalidad.
Almacenamiento en caché inteligente de mensajes
El almacenamiento en caché de solicitudes guarda segmentos de solicitudes de uso frecuente y los reutiliza en distintas solicitudes. Este sistema ofrece mejoras sustanciales en la latencia; AWS ha documentado reducciones en el tiempo de respuesta de hasta 85% para las consultas almacenadas en caché. Sin embargo, sin herramientas de análisis que identifiquen patrones que se puedan almacenar en caché, las organizaciones pierden por completo estos ahorros.
Predominan dos enfoques de almacenamiento en caché: el almacenamiento en caché a nivel de sistema guarda prefijos de indicaciones comunes, mientras que el almacenamiento en caché de solicitud-respuesta guarda pares completos de consulta-respuesta para su reutilización. Las herramientas de análisis identifican qué indicaciones se benefician más del almacenamiento en caché según la frecuencia de repetición y la longitud del token.
Selección de modelos estratégicos
Un análisis de costo-beneficio de la implementación local del programa LLM de Carnegie Mellon establece que las puntuaciones de referencia dentro del período 20% de los principales modelos comerciales reflejan la práctica empresarial, donde las modestas brechas de rendimiento siguen siendo aceptables para la reducción de costos.
Las plataformas de análisis muestran oportunidades para redirigir las solicitudes a modelos menos costosos cuando los requisitos de calidad lo permiten. Las tareas de clasificación sencillas no necesitan modelos de vanguardia; las alternativas más pequeñas y económicas funcionan adecuadamente.
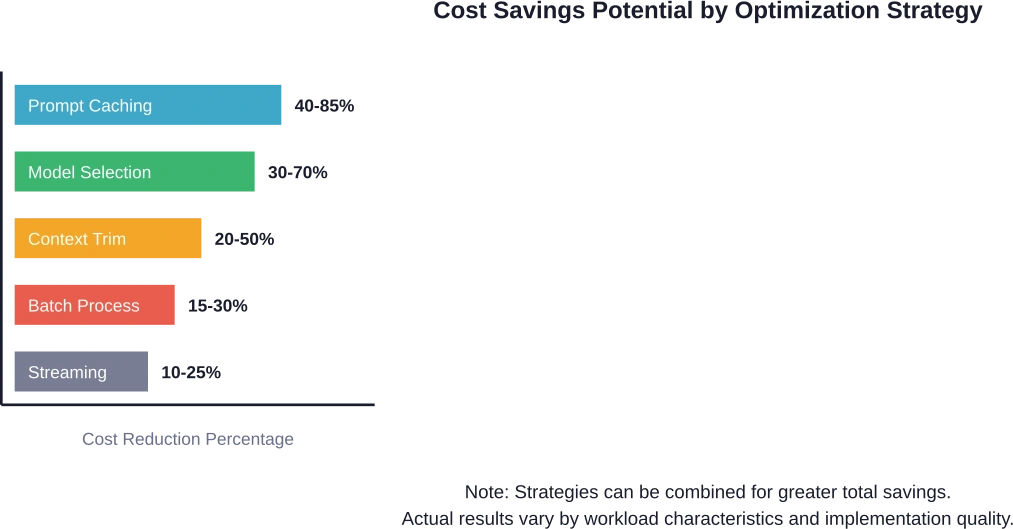
| Estrategia | Reducción de costos | Complejidad de la implementación | Impacto en la calidad
|
|---|---|---|---|
| Almacenamiento en caché de avisos | 40-85% | Bajo | Ninguno |
| Selección de modelos | 30-70% | Medio | Dependiente de la tarea |
| Optimización del contexto | 20-50% | Medio | De ninguna a mínima |
| Procesamiento por lotes | 15-30% | Alto | Añade latencia |
| Transmisión de respuesta | 10-25% | Bajo | Ninguno |
Optimización de la ventana de contexto
Muchas aplicaciones envían contextos innecesariamente grandes con cada solicitud. Los análisis revelan el tamaño promedio de los contextos e identifican oportunidades para eliminar la información irrelevante.
Contextos más cortos implican menos tokens de entrada y un procesamiento más rápido. Estudios de casos de la industria reportan reducciones de costos significativas mediante la optimización sistemática del contexto.
Umbrales de calidad automatizados
La investigación de OpenAI sobre agentes autoevolutivos recomienda continuar los ciclos de optimización hasta que los umbrales de calidad alcancen una retroalimentación positiva superior a 80% o hasta que las nuevas iteraciones muestren una mejora mínima. Las plataformas de análisis monitorizan estas métricas e indican cuándo una mayor optimización produce rendimientos decrecientes.

Reduzca los costos de LLM con el socio de ingeniería adecuado.
Muchas empresas adoptan herramientas analíticas LLM para monitorear el uso, el consumo de tokens y el rendimiento del modelo, pero los mayores ahorros de costos generalmente provienen de cómo se construyen e integran los modelos en primer lugar. Aquí es donde IA superior Suelen participar activamente. Su equipo trabaja en la capa técnica que respalda los sistemas LLM: diseñan modelos personalizados, preparan datos de entrenamiento, ajustan arquitecturas e integran los sistemas LLM en los flujos de trabajo existentes para que las empresas puedan controlar el rendimiento y los costos operativos de manera más eficaz.
Si su objetivo es reducir el gasto en modelos de aprendizaje automático (LLM) en 2026, conviene revisar cómo se entrenan, implementan y supervisan sus modelos. Una auditoría técnica o una revisión de la arquitectura suelen revelar costes de inferencia innecesarios, procesos ineficientes o modelos mal optimizados.
Hablar a IA superior Si desea evaluar su configuración actual de LLM e identificar formas prácticas de reducir los costos operativos a largo plazo.
Comparación de las principales plataformas de análisis de datos para programas de máster en derecho (LLM)
El panorama de las plataformas analíticas incluye herramientas de observabilidad especializadas, soluciones nativas de proveedores de nube y alternativas de código abierto. Cada categoría ofrece ventajas distintas.
Soluciones nativas de proveedores de nube
AWS, Google Cloud y Azure ofrecen análisis integrados dentro de sus plataformas de IA. El uso y los costos de Amazon Bedrock se supervisan mediante los informes de facturación y administración de costos de AWS y las API de AWS Cost Explorer, lo que permite el acceso programático a los datos de gastos de toda la organización.
Google Conversational Insights ofrece dos planes de precios: Estándar y Empresarial, con costos que varían según el tipo de interacción. Las conversaciones de chat se cobran por mensaje, mientras que las de voz se cobran por minuto. El plan Empresarial incluye funciones de IA de calidad con soporte para hasta 50 evaluaciones personalizadas por conversación.
Las soluciones nativas se integran a la perfección con la infraestructura en la nube existente, pero pueden carecer de las funciones de optimización avanzadas que se encuentran en las plataformas especializadas.
Plataformas de observabilidad especializadas
Las plataformas de observabilidad LLM especializadas se centran exclusivamente en la monitorización y optimización de cargas de trabajo de IA. Estas herramientas suelen ofrecer análisis más profundos, funciones de optimización más sofisticadas y soporte independiente del proveedor para múltiples proveedores de LLM.
Entre sus principales funcionalidades se incluyen el seguimiento de solicitudes en sistemas distribuidos, el análisis de latencia, la monitorización de la tasa de errores y la atribución de costes por función o equipo. Las mejores plataformas ofrecen información útil en lugar de simples métricas.
Alternativas de código abierto
Las herramientas de análisis de código abierto resultan atractivas para organizaciones con requisitos específicos o limitaciones presupuestarias. Estas soluciones ofrecen transparencia y personalización, pero requieren una mayor inversión técnica para su implementación y mantenimiento.
El desarrollo impulsado por la comunidad significa que las funcionalidades evolucionan en función de las necesidades reales de los usuarios, aunque el soporte y la documentación empresariales pueden estar por detrás de las alternativas comerciales.
| Tipo de plataforma | Mejor para | Ventaja clave | Limitación primaria
|
|---|---|---|---|
| Nativo de la nube | Implementaciones en una única nube | Integración profunda | Dependencia del proveedor |
| Herramientas especializadas | Entornos multimodelos | Optimización avanzada | Costo adicional |
| Código abierto | Requisitos personalizados | Transparencia y control | Carga de mantenimiento |
Mejores prácticas de implementación para el análisis de costos
Para implementar herramientas analíticas de manera eficaz, se requiere una planificación cuidadosa y expectativas realistas sobre los plazos de optimización.
Establecimiento de métricas de referencia
Las organizaciones no pueden optimizar lo que no miden. Empiece por hacer un seguimiento del consumo total de tokens, el coste medio por interacción de usuario y la distribución de los gastos entre las diferentes funciones o casos de uso.
La medición inicial debe durar al menos dos semanas para capturar patrones de uso representativos. Las variaciones estacionales o los picos de uso afectan a los promedios, por lo que los periodos de medición más largos proporcionan datos más fiables.
Establecer objetivos de optimización realistas
Las investigaciones del Laboratorio de IA Watson del MIT-IBM hacen hincapié en la importancia de definir el presupuesto computacional y la precisión objetivo del modelo antes de comenzar la optimización. Los equipos deben determinar si un error relativo promedio de 4% o de 20% satisface sus necesidades de toma de decisiones.
Los ambiciosos objetivos de reducción de costes a veces comprometen la funcionalidad. El objetivo no es minimizar el gasto, sino optimizarlo para alcanzar los niveles de calidad requeridos.
Implementación de despliegues graduales
No optimices todo a la vez. Prueba primero las estrategias de almacenamiento en caché en los puntos finales con mayor volumen de tráfico, mide el impacto y luego amplíalas a otras áreas.
Las implementaciones graduales permiten aislar variables y facilitan la atribución de reducciones de costos a cambios específicos. Además, minimizan el riesgo: si la optimización afecta negativamente la experiencia del usuario, el impacto es mínimo.
Monitoreo continuo e iteración
La optimización de costes no es un proyecto que se realiza una sola vez. Los patrones de uso evolucionan, se lanzan nuevos modelos con precios diferentes y cambian los requisitos de las aplicaciones.
Programe revisiones trimestrales de los datos analíticos para identificar patrones emergentes. La automatización reduce la carga de trabajo manual: las plataformas que señalan automáticamente las oportunidades de optimización ahorran mucho tiempo.
Técnicas avanzadas de optimización
Más allá del seguimiento básico de costes, las técnicas avanzadas ofrecen ahorros adicionales para implementaciones sofisticadas.
Enrutamiento de modelos multiagente
Las investigaciones sobre optimización a partir del lenguaje natural mediante agentes basados en modelos de lenguaje natural demuestran que la combinación de diversos modelos conduce a mejoras en el rendimiento. Un marco de trabajo logró una precisión de 88,11 TP3T en el conjunto de datos NLP4LP y de 82,31 TP3T en Optibench, reduciendo las tasas de error en 581 TP3T y 521 TP3T respectivamente con respecto a los resultados anteriores mediante la colaboración de múltiples agentes.
Las plataformas de análisis pueden implementar un enrutamiento inteligente que dirige las solicitudes al modelo más rentable capaz de gestionar cada tarea. Las consultas sencillas se dirigen a modelos rápidos y económicos. Las tareas de razonamiento complejas se escalan a alternativas más capaces —y costosas—.
Optimización de la atención para consultas agrupadas
Para las organizaciones que ejecutan modelos autoalojados, la configuración del mecanismo de atención tiene un impacto significativo en los costos. Las investigaciones sobre la atención de consultas agrupadas óptima en términos de costos para el modelado de contexto extenso muestran que, para escenarios de contexto extenso, usar menos unidades de atención al aumentar el tamaño del modelo reduce tanto el uso de memoria como las operaciones de punto flotante (FLOPs) en más de 50% en comparación con la configuración GQA de Llama-3, sin degradación en las capacidades del modelo.
Esto es importante para las implementaciones personalizadas, donde los costos de infraestructura representan un factor significativo en los gastos totales.
Bucles de reentrenamiento automatizados
La investigación de OpenAI sobre agentes autoevolutivos introduce ciclos de reentrenamiento repetibles que detectan casos extremos y corrigen fallos sin intervención humana constante. Los sistemas que identifican resultados de baja calidad y se reentrenan automáticamente en función de la retroalimentación reducen tanto las tasas de error como el desperdicio de tokens derivado de la regeneración de respuestas fallidas.
Las plataformas analíticas que realizan un seguimiento de las métricas de calidad de los resultados permiten estos ciclos de mejora automatizados, lo que genera beneficios de costes acumulativos con el tiempo.
Evaluación del retorno de la inversión en análisis de datos
Las plataformas de análisis representan costos adicionales: suscripciones, esfuerzo de integración y mantenimiento continuo. Las organizaciones necesitan marcos de trabajo para evaluar si las inversiones generan resultados positivos.
Cálculo del punto de equilibrio
Los estudios sobre el análisis de costo-beneficio de la implementación local de LLM examinan cuándo las organizaciones alcanzan el punto de equilibrio en comparación con los servicios comerciales. La misma metodología se aplica a las herramientas de análisis: se calcula el gasto mensual en LLM, se estima el porcentaje de reducción de costos alcanzable en función de las funciones de optimización y se compara con los costos de suscripción de la plataforma.
Por ejemplo, si los costos mensuales de LLM alcanzan los 50 000 y el análisis permite una reducción de 301 TP3T mediante el almacenamiento en caché y la selección de modelos, esto representa un ahorro mensual de 15 000. Una plataforma de análisis que cuesta 2 000 al mes alcanza el punto de equilibrio de inmediato y genera un beneficio mensual neto de 13 000.
Cuantificación de las mejoras en la eficiencia operativa
La reducción de costes representa solo una parte de la ecuación de valor. Las plataformas de análisis reducen el tiempo que los ingenieros dedican a investigar manualmente problemas de rendimiento, depurar consultas costosas y generar informes de uso.
Según informes del sector, los equipos han logrado aumentos significativos de productividad cuando un análisis adecuado elimina los cuellos de botella en la depuración de errores. El ahorro de tiempo se traduce directamente en una reducción de los costos laborales o en una mayor velocidad de desarrollo.
Valor de mitigación de riesgos de factoring
Las alertas presupuestarias y la detección de anomalías previenen desastres de costos. Las organizaciones que no cuentan con un monitoreo adecuado descubren los gastos descontrolados días o semanas después de que se producen, cuando llegan las facturas.
El valor de evitar una factura inesperada de $100,000 justifica una inversión significativa en análisis de datos. Los beneficios de la mitigación de riesgos son más difíciles de cuantificar, pero tienen un impacto sustancial en el costo total de propiedad.
Análisis local frente a análisis en la nube
Las organizaciones que implementan sistemas LLM autogestionados se enfrentan a requisitos analíticos diferentes a los de aquellas que utilizan exclusivamente API comerciales.
Ventajas de la analítica en la nube
Las plataformas de análisis basadas en la nube requieren una configuración mínima, se escalan automáticamente y reciben actualizaciones continuas de funciones sin intervención manual. Son ideales para organizaciones que utilizan servicios LLM comerciales, donde el seguimiento a nivel de API proporciona suficiente visibilidad.
La integración normalmente implica añadir llamadas al SDK o enrutar las solicitudes a través de servicios de puerta de enlace, algo sencillo para la mayoría de los equipos de desarrollo.
Consideraciones para la implementación local
Las soluciones analíticas autogestionadas son ideales para organizaciones con estrictos requisitos de gobernanza de datos o que ejecutan modelos propietarios internamente. Según un estudio de Stanford sobre inteligencia por vatio, los sistemas LLM locales pueden responder con precisión a 88,7% de tareas de chat y razonamiento de un solo turno, lo que hace que la autogestión sea viable para muchos casos de uso.
Sin embargo, las implementaciones locales conllevan una mayor complejidad. Las organizaciones necesitan infraestructura para la propia plataforma de análisis, deben gestionar las actualizaciones manualmente y requieren conocimientos especializados para el mantenimiento de los sistemas.
Enfoques híbridos
Muchas organizaciones adoptan estrategias híbridas: análisis en la nube para el uso comercial de LLM combinado con monitorización local para modelos autogestionados. Esto equilibra la comodidad con el control, a la vez que mantiene una visibilidad integral de todo el conjunto de herramientas de IA.
Tendencias futuras en el análisis de costes de los másteres en derecho (LLM)
El panorama de la analítica sigue evolucionando rápidamente a medida que las organizaciones demandan capacidades más sofisticadas.
Modelado predictivo de costos
Las plataformas de próxima generación predecirán los costos futuros basándose en las tendencias de uso, los cambios en las aplicaciones y las variaciones en los precios de los modelos. Las alertas proactivas avisan a los equipos antes de que los costos se disparen, en lugar de informar los problemas de forma retroactiva.
Los modelos de aprendizaje automático entrenados con patrones de uso históricos pueden pronosticar el gasto mensual con una precisión cada vez mayor, lo que permite una mejor planificación presupuestaria.
Agentes de optimización automatizados
La investigación sobre la optimización automatizada de agentes basados en LLM (ARTEMIS) demuestra la existencia de sistemas que experimentan continuamente con cambios de configuración, miden el impacto e implementan mejoras automáticamente sin intervención humana.
Estos sistemas de autooptimización podrían revolucionar la gestión de costes al eliminar por completo el trabajo de optimización manual. Las primeras implementaciones muestran resultados prometedores, pero aún se encuentran en fase experimental.
Análisis unificado entre proveedores
Las organizaciones utilizan cada vez más múltiples proveedores de modelos de aprendizaje automático (LLM): OpenAI para algunas tareas, Anthropic para otras y modelos de código abierto para casos de uso específicos. La analítica unificada entre todos los proveedores sigue siendo un reto.
Las plataformas futuras ofrecerán un seguimiento integral de múltiples proveedores, lo que permitirá comparaciones de costes directas y un enrutamiento inteligente entre proveedores basado en datos de precios y rendimiento en tiempo real.
Desafíos comunes en la implementación
Las organizaciones se topan con obstáculos previsibles al implementar plataformas de análisis. Anticipar estos desafíos acelera la implementación exitosa.
Atribución de uso incompleta
Para realizar un seguimiento de los costos específicos generados por cada equipo, función o usuario, se requiere instrumentación en todas las aplicaciones. Muchas organizaciones registran inicialmente el uso general, pero carecen de una atribución detallada.
Solución: implementar estándares de etiquetado consistentes desde el principio. Agregar metadatos a cada solicitud LLM que identifiquen la aplicación de origen, el tipo de usuario y la categoría de la función.
Fatiga por alerta
Las alertas de costos excesivamente sensibles capacitan a los equipos para que ignoren las notificaciones. Si cada pequeño aumento en el uso activa las alarmas, las advertencias importantes se descartan junto con el ruido.
Solución: establecer umbrales de alerta basados en la significancia estadística en lugar de cambios absolutos. Un aumento en el costo de 10% podría justificar una investigación si se mantiene durante varios días, pero no si ocurre durante una sola hora.
Parálisis por análisis de optimización
Algunos equipos dedican más tiempo a analizar oportunidades de optimización que a implementarlas. La investigación detallada de cada posible mejora resulta contraproducente.
Solución: aplicar la regla 80/20. Priorizar las optimizaciones de mayor impacto, como el almacenamiento en caché para cargas de trabajo repetitivas y la selección de modelos para puntos finales de alto volumen. Las optimizaciones menores pueden esperar.
Preguntas frecuentes
¿Cuánto pueden reducir de forma realista las organizaciones los costes de los programas de formación jurídica (LLM) con herramientas analíticas?
La reducción de costos varía significativamente según la eficiencia inicial y las características de la carga de trabajo. Las organizaciones con consultas repetitivas y sin almacenamiento en caché pueden lograr reducciones de 50 a 701 TP3T solo con el almacenamiento en caché instantáneo. Aquellas que ya implementan optimizaciones básicas suelen obtener ahorros adicionales de 20 a 401 TP3T mediante la selección estratégica de modelos y la optimización del contexto. La clave está en identificar dónde se desperdician recursos en su implementación específica; las plataformas analíticas son excelentes para detectar estas oportunidades.
¿Las plataformas de análisis son compatibles con todos los proveedores de LLM?
La mayoría de las plataformas de análisis especializadas son compatibles con los principales proveedores comerciales, como OpenAI, Anthropic, Google y AWS Bedrock, mediante integraciones API estándar. Las soluciones nativas de la nube suelen funcionar únicamente dentro de sus respectivos ecosistemas: herramientas de AWS para Bedrock y herramientas de Google para Vertex AI. Para modelos autoalojados o proveedores más pequeños, la compatibilidad depende de si la plataforma ofrece capacidades de integración personalizadas o requiere instrumentación específica.
¿Cuál es el cronograma típico de implementación para el análisis de datos LLM?
La integración básica de análisis tarda de 1 a 2 semanas en plataformas basadas en la nube que utilizan SDK estándar. Esto incluye la configuración, la implementación básica de etiquetado y la configuración inicial del panel de control. El despliegue completo con seguimiento de sesiones, atribución personalizada y automatización de la optimización requiere de 4 a 8 semanas, según la complejidad de la aplicación. Las organizaciones con sistemas distribuidos o implementaciones LLM personalizadas deben prever de 2 a 3 meses para el despliegue completo, incluyendo pruebas y ajustes.
¿Deberían los equipos pequeños invertir en plataformas de análisis especializadas?
Los equipos que gastan menos de 5000 LLM al mes suelen gestionar los costes adecuadamente con las herramientas nativas básicas del proveedor de la nube y la monitorización manual. La complejidad y el coste de las plataformas dedicadas pueden superar las ventajas a esta escala. Cuando los costes mensuales de LLM superan los 10 000-15 000 LLM, las analíticas especializadas suelen ofrecer un retorno de la inversión positivo mediante la optimización automatizada y una visibilidad detallada. Calcule sus ahorros potenciales: si las reducciones de costes realistas superan el coste de la suscripción a la plataforma en un 300% o más, la inversión merece la pena.
¿Cómo gestionan las herramientas de análisis la limitación de velocidad y la administración de cuotas?
Las plataformas avanzadas incluyen funciones de limitación de velocidad personalizadas que impiden que las aplicaciones superen los umbrales de uso configurados. Estos sistemas interceptan las solicitudes antes de que lleguen a los proveedores de LLM, rechazando o poniendo en cola el tráfico excedente según las políticas definidas. La limitación de velocidad evita tanto los sobrecostos como el agotamiento de la cuota de la API del proveedor. Algunas plataformas implementan una gestión de colas inteligente que prioriza las solicitudes de alto valor durante los períodos de capacidad limitada.
¿Pueden las plataformas de análisis reducir la latencia a la vez que los costes?
Sí, muchas optimizaciones de costos mejoran simultáneamente los tiempos de respuesta. El almacenamiento en caché ofrece las mejoras de latencia más significativas, reduciendo el tiempo de respuesta hasta en 85% para las consultas almacenadas en caché, según una investigación de AWS. Los modelos más pequeños y rápidos, seleccionados para las tareas adecuadas, suelen responder con mayor rapidez que los modelos de vanguardia sobrecualificados, a la vez que resultan más económicos. La optimización del contexto reduce tanto los costos de procesamiento de tokens como el tiempo necesario para procesar entradas innecesariamente grandes. Las mejores plataformas de análisis identifican oportunidades donde se alinean las mejoras de costo y rendimiento.
¿Qué métricas son las más importantes para la gestión de costes de un máster en Derecho (LLM)?
Cuatro métricas constituyen la base para una gestión eficaz de costes: el gasto mensual total permite monitorizar el impacto presupuestario general; el coste por interacción de usuario revela la rentabilidad unitaria de las diferentes funcionalidades; la relación token de entrada/salida identifica patrones de respuesta costosos; y la tasa de aciertos de caché mide la eficacia con la que el almacenamiento en caché reduce el procesamiento redundante. En conjunto, estas métricas permiten a los equipos comprender tanto los costes totales como las oportunidades de optimización específicas. Los equipos más avanzados añaden la precisión en la selección de modelos, monitorizando con qué frecuencia los modelos más económicos mantienen los umbrales de calidad.
Conclusión
Las herramientas analíticas de modelos de lenguaje con sólidas funciones de optimización de costos han evolucionado de soluciones de monitoreo deseables a infraestructura esencial para cualquier organización que implemente IA a gran escala. La combinación de seguimiento de costos en tiempo real, observabilidad del rendimiento y capacidades de optimización automatizada ofrece un retorno de la inversión inmediato para los equipos que invierten cantidades significativas en API de modelos de lenguaje.
En resumen, las organizaciones pueden reducir los costos de LLM entre un 20 % y un 70 % mediante una optimización sistemática basada en análisis adecuados, sin sacrificar la calidad de respuesta ni la funcionalidad. Sin embargo, el éxito requiere más que instalar un panel de control. Una gestión de costos eficaz exige métricas de referencia claras, objetivos de optimización realistas, una implementación gradual y un monitoreo continuo.
Las investigaciones del MIT, Carnegie Mellon y las principales empresas de IA demuestran de forma consistente que la combinación de la selección estratégica de modelos, el almacenamiento en caché inteligente, la optimización del contexto y el enrutamiento automatizado ofrece beneficios acumulativos. Los equipos que consideran la optimización de costes como una disciplina continua, en lugar de un proyecto puntual, logran reducciones sostenibles a la vez que mantienen la flexibilidad para adoptar nuevos modelos y capacidades a medida que surgen.
El panorama de las plataformas analíticas ofrece soluciones para cada escenario de implementación: desde herramientas nativas de la nube integradas con los principales proveedores hasta plataformas de observabilidad especializadas que admiten entornos de múltiples proveedores, pasando por alternativas de código abierto para requisitos personalizados. La elección de la plataforma adecuada depende de la arquitectura de implementación, las limitaciones presupuestarias y el nivel de sofisticación de la optimización.
Comience por establecer los costos base actuales y los patrones de uso. Identifique las oportunidades de optimización de mayor impacto específicas para su carga de trabajo. Seleccione herramientas de análisis que proporcionen información útil en lugar de abrumar a los equipos con métricas sin procesar. Implemente las optimizaciones gradualmente, mida los resultados y realice iteraciones basadas en datos, no en suposiciones.
Las organizaciones que triunfan en la gestión de costes de los modelos de lenguaje comparten una característica común: instrumentan de forma integral, analizan continuamente y optimizan sistemáticamente. A medida que los modelos de lenguaje se vuelven más capaces y se generalizan, esta disciplina distingue las implementaciones sostenibles de IA de los experimentos costosos que nunca alcanzan la escala de producción.
¿Listo para optimizar los costos de tu LLM? Empieza por la medición: no puedes mejorar lo que no mides. Elige una plataforma de análisis compatible con tu infraestructura, implementa un seguimiento básico y deja que los datos revelen dónde tu implementación específica desperdicia recursos. Los resultados te sorprenderán y el ahorro justificará el esfuerzo.