Resumen rápido: Las estrategias de optimización de costos de LLM ayudan a las organizaciones a reducir los gastos operativos manteniendo el rendimiento de la IA. Los enfoques clave incluyen la optimización de la solicitud, el enrutamiento de modelos, el almacenamiento en caché, la cuantificación y el ajuste de la infraestructura. Las investigaciones demuestran que estas técnicas pueden reducir los costos entre 10 y 501 TP3T mediante métodos como la compresión de solicitudes, la selección estratégica de modelos y la gestión eficiente de tokens.
Los costes operativos de ejecutar modelos de lenguaje complejos en producción pueden dispararse rápidamente. Lo que comienza como una prometedora prueba de concepto se convierte en una carga financiera cuando se escala a millones de llamadas a la API mensuales.
Las organizaciones que implementan modelos de lógica difusa (LLM) se enfrentan a una dura realidad: los costos de procesamiento aumentan linealmente con el uso. Para un modelo con aproximadamente 175 mil millones de parámetros, el espacio de memoria requerido sería de aproximadamente 350 GB (para FP16) o 700 GB (para FP32). Esto es solo el almacenamiento; los costos reales de inferencia se acumulan con cada token procesado.
Pero he aquí la clave: la optimización de costes no implica sacrificar el rendimiento. Los enfoques estratégicos pueden reducir drásticamente los gastos manteniendo, o incluso mejorando, la calidad de la producción.
Comprensión de los modelos de precios de los programas de maestría en derecho (LLM)
La mayoría de los servicios LLM basados en la nube cobran por token. Los usuarios pagan por separado por los tokens de entrada (la solicitud) y los tokens de salida (la respuesta generada). Este mecanismo de pago por token crea una dinámica interesante.
Una investigación del Laboratorio de IA MIT-IBM Watson (en “A Hitchhiker's Guide to Scaling Law Estimation”, 2024/2025) muestra que un error relativo promedio (ARE) de aproximadamente 4% representa la mejor precisión de predicción alcanzable al estimar leyes de escala (es decir, pronosticar la pérdida de modelos grandes a partir de modelos más pequeños de la misma familia), debido principalmente al ruido aleatorio de la semilla, que por sí solo puede causar diferencias de hasta ~4% en la pérdida final incluso para configuraciones de entrenamiento idénticas. Un ARE de hasta 20% sigue siendo útil para muchas tareas prácticas de toma de decisiones en la selección de modelos y la asignación de presupuestos. Estas consideraciones son importantes al evaluar las compensaciones entre costo y rendimiento en diferentes familias o tamaños de modelos.
Los tokens de entrada almacenados en caché suelen costar alrededor del 10 % de los tokens de entrada normales. Esta asimetría de precios crea oportunidades para obtener ahorros significativos mediante estrategias de almacenamiento en caché.
La estructura de precios también implica que, para la mayoría de los proveedores, la generación de resultados cuesta más que el procesamiento de insumos. Esta realidad fundamental impulsa diversas estrategias de optimización que trasladan el consumo de tokens de los resultados costosos a los insumos más económicos.
Técnicas de optimización rápida
La ingeniería de avisos representa la solución más sencilla para la reducción de costos. Los avisos mal estructurados desperdician tokens y generan resultados innecesarios.
Comprimir sin perder contexto
Las instrucciones demasiado extensas consumen muchos tokens de entrada. Una solicitud de descripción de producto podría decir originalmente: “Genera una descripción atractiva para un teléfono inteligente. Debe mencionar las características y especificaciones clave, como el tamaño de la pantalla, la resolución de la cámara, la duración de la batería y la capacidad de almacenamiento. Intenta que sea atractiva y persuasiva”.”
La versión optimizada: “Genera una descripción de producto atractiva para un teléfono inteligente con pantalla de 6,5 pulgadas, cámara de 48 MP, batería de 5000 mAh y 256 GB de almacenamiento”.”
Misma intención, menos tokens, orientación más específica. Este enfoque reduce los costos de entrada y, a menudo, mejora la calidad de la salida gracias a la precisión.
Estructurar los resultados estratégicamente
Las respuestas estructuradas minimizan el desperdicio de tokens. En lugar de solicitar respuestas de formato libre que requieren análisis, se solicitan JSON o formatos específicos. Esta técnica se utiliza en sistemas de producción donde los marcos de trabajo de agentes electrónicos emplean respuestas estructuradas para minimizar la longitud de las respuestas de los candidatos.
Según la documentación de OpenAI sobre el ajuste fino del aprendizaje por refuerzo, las especificaciones claras de las tareas con respuestas verificables permiten un comportamiento más eficiente del modelo. Las rúbricas explícitas y los evaluadores basados en código miden el éxito funcional a la vez que reducen la verbosidad innecesaria.
| Tipo de solicitud | Uso del token | Impacto en los costos | Mejor para
|
|---|---|---|---|
| Verboso, desestructurado | Alto | Base | Fase de exploración |
| Comprimido, estructurado | Medio | Reducción de 20-30% | Implementaciones en producción |
| Almacenado en caché con estructura | Bajo | Reducción de 40-50% | Tareas repetitivas |
Selección y enrutamiento de modelos estratégicos
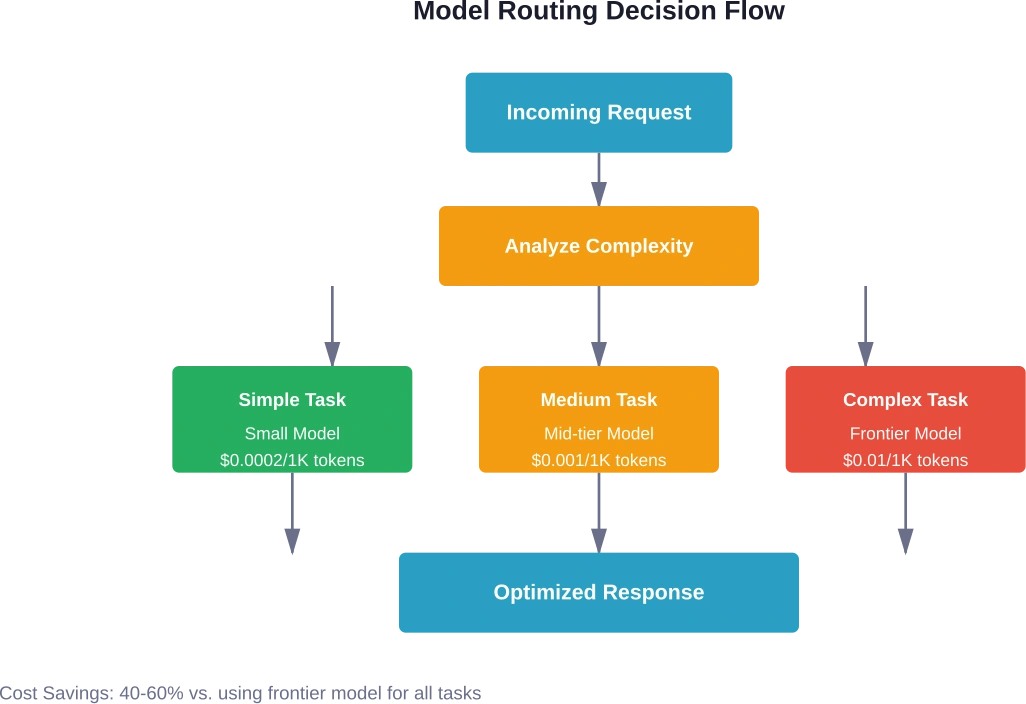
No todas las tareas requieren el modelo más potente disponible. El enrutamiento de modelos —que dirige las diferentes solicitudes a modelos del tamaño adecuado— genera ahorros sustanciales.
Adaptar la capacidad del modelo a la complejidad de la tarea.
Las tareas de clasificación sencillas no requieren modelos de última generación. El análisis de sentimientos, la generación de resúmenes básicos o el etiquetado de categorías funcionan bien con alternativas más pequeñas y económicas. Reserve los modelos costosos para el razonamiento complejo, la generación de información matizada o las tareas que requieren conocimiento especializado.
Las investigaciones sobre la eficiencia de los modelos demuestran que las arquitecturas rediseñadas pueden alcanzar un rendimiento comparable a diferentes escalas. La arquitectura del modelo desempeña un papel fundamental que va más allá del simple número de parámetros.
Los sistemas de producción informan de una combinación de implementaciones de modelos OpenAI, Anthropic y locales, según los requisitos de las tareas, a lo largo de más de 2 millones de llamadas mensuales a la API. Este enfoque heterogéneo optimiza la relación coste-rendimiento en diferentes casos de uso.
Implementar lógica de enrutamiento inteligente
Los sistemas de enrutamiento automatizados analizan las solicitudes entrantes y seleccionan los modelos adecuados. Las plataformas de IA optimizan automáticamente tanto la selección de LLM como la infraestructura subyacente, eliminando la necesidad de tomar decisiones manuales.
La lógica de enrutamiento considera factores como la complejidad de la consulta, la precisión requerida, la tolerancia a la latencia y los precios actuales. El enrutamiento dinámico se adapta a las condiciones cambiantes sin intervención manual.
Estrategias de almacenamiento en caché para cargas de trabajo repetitivas
El almacenamiento en caché ofrece reducciones de costos inmediatas y drásticas para aplicaciones con patrones repetitivos. Los sistemas de producción reportan tasas de acierto de caché del 40 por ciento, y algunas implementaciones ahorran aproximadamente $3,000 mensuales en costos de API.
Implementar almacenamiento en caché semántico
El almacenamiento en caché básico guarda coincidencias exactas con las solicitudes. El almacenamiento en caché semántico va más allá: reconoce consultas similares incluso con diferente redacción. Las preguntas "¿Cómo restablezco mi contraseña?" y "¿Cuál es el proceso para recuperar la contraseña?" generan la misma respuesta almacenada en caché.
Este enfoque beneficia especialmente a los sistemas de atención al cliente, búsqueda de documentación y preguntas frecuentes, donde los usuarios formulan preguntas idénticas de manera diferente.
Mensajes y contexto del sistema de caché
Las indicaciones del sistema que definen el comportamiento del modelo rara vez cambian. Almacenarlas en caché reduce el procesamiento redundante. El contexto que aparece en múltiples solicitudes, como información de la empresa, catálogos de productos o guías de estilo, debe almacenarse en caché de forma intensiva.
Los enfoques de ingeniería de contexto demuestran que los subagentes pueden explorar extensamente, utilizando decenas de miles de tokens, pero devolver resúmenes condensados de 1000 a 2000 tokens. El almacenamiento en caché de estos resultados intermedios evita exploraciones redundantes y exhaustivas de la misma información.
Parada temprana y control de salida
Los modelos suelen generar más contenido del necesario. Las técnicas de parada temprana detectan cuándo se ha generado suficiente información y detienen la generación.
La investigación sobre ES-CoT (Early Stopping Chain-of-Thought) demuestra métodos para detectar la convergencia de respuestas y detener la generación de forma temprana. Cuando respuestas consecutivas idénticas indican convergencia, la generación finaliza, lo que reduce los costos de los tokens de inferencia manteniendo una precisión comparable.
La técnica funciona solicitando al modelo que genere su respuesta actual en cada paso del razonamiento. La longitud de la racha de respuestas idénticas consecutivas sirve como medida de convergencia. Los aumentos bruscos en la longitud de la racha que superan los umbrales mínimos provocan la terminación del proceso.
Establecer límites máximos de tokens
Limita explícitamente la longitud de la salida mediante parámetros de la API. Esto evita la generación excesiva de datos que desperdician tokens en procesos innecesarios. Cada tarea requiere límites distintos; ajústalos según el caso de uso.
La clasificación requiere 10 tokens. El resumen podría requerir 200. La generación de textos extensos podría justificar más de 1000. Sin embargo, las configuraciones predeterminadas que permiten una salida ilimitada propician el desperdicio.
Cuantización y compresión de modelos
La cuantización reduce la precisión de los pesos del modelo, disminuyendo así los requisitos de memoria y los costos computacionales. Los modelos LLM suelen utilizar precisión FP16 para reducir los requisitos de memoria en comparación con FP32. Una cuantización adicional a INT8 o INT4 proporciona ahorros adicionales.
Cuantificación posterior al entrenamiento
La reducción de la densidad después del entrenamiento disminuye el costo del modelo al eliminar pesos de redes densas. La investigación sobre la inducción de la densidad demuestra la eficacia de los enfoques de reducción de la densidad después del entrenamiento en modelos probados con una sola GPU NVIDIA RTX A6000 (48 GB).
Las matrices densas nativas carecen de una alta dispersión, lo que dificulta la eliminación directa de pesos. Los enfoques avanzados inducen patrones de dispersión que preservan las capacidades del modelo a la vez que reducen los requisitos computacionales.
Destilación para tareas especializadas
La destilación del conocimiento crea modelos más pequeños que imitan a otros más grandes para tareas específicas. El modelo del estudiante aprende de los resultados del profesor, capturando el comportamiento relevante para la tarea con menos parámetros.
Los marcos de Autodistill permiten diseñar modelos especializados con costes de inferencia sustancialmente menores mediante enfoques de destilación del conocimiento.
| Técnica | Complejidad | Reducción de costos | Impacto en la calidad
|
|---|---|---|---|
| Optimización inmediata | Bajo | 20-30% | A menudo mejora |
| Enrutamiento del modelo | Medio | 40-60% | Mínimo |
| Almacenamiento en caché | Bajo | 30-50% | Ninguno |
| Parada temprana | Medio | 30-40% | Mínimo |
| Cuantización | Alto | 50-70% | Degradación del 5-10% |
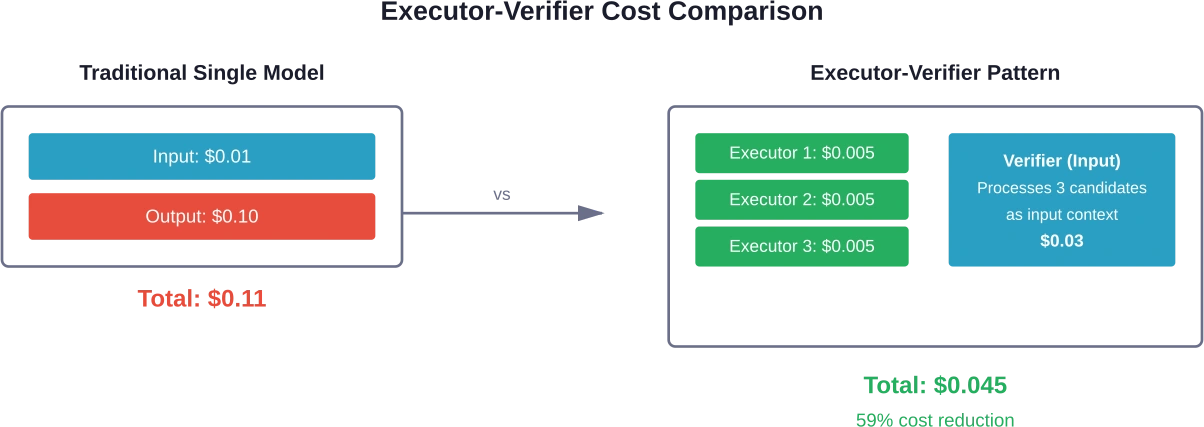
Arquitecturas ejecutor-verificador
El paradigma ejecutor-verificador traslada el consumo de tokens de las costosas salidas a las más económicas entradas. Múltiples modelos pequeños, implementados localmente, generan respuestas candidatas. Un potente modelo basado en la nube verifica cuál de las candidatas es la correcta.
Los marcos de trabajo de agentes electrónicos demuestran que este enfoque reduce el uso de tokens entre un 10 y un 50 por ciento en comparación con los métodos de referencia. La asimetría de precios entre los tokens de entrada y salida hace que la verificación sea más barata que la generación.
Los ejecutores pequeños se ejecutan localmente o en infraestructura de bajo costo. Generan múltiples candidatos diversos en paralelo. El verificador procesa todos los candidatos como contexto de entrada (con tarifas de token de entrada más bajas) y selecciona o sintetiza la mejor respuesta.
Esta arquitectura resulta especialmente adecuada para tareas con criterios de corrección claros: problemas matemáticos, generación de código, cuestiones fácticas o extracción de datos estructurados.
Optimización de la infraestructura y el despliegue
Más allá de las optimizaciones a nivel de modelo, las decisiones sobre la infraestructura influyen significativamente en los costes.
Optimizar la selección de hardware
La selección de la GPU es crucial. NVIDIA TensorRT-LLM proporciona API de Python para definir modelos LLM con optimizaciones de vanguardia que permiten una inferencia eficiente en GPUs de NVIDIA. Las pruebas demuestran mejoras de rendimiento significativas en el hardware adecuado.
Los experimentos realizados con GPU NVIDIA RTX A6000 individuales con 48 GB de memoria demuestran una inferencia viable para modelos que requieren una gestión cuidadosa de los recursos. El dimensionamiento adecuado del hardware evita el sobredimensionamiento a la vez que mantiene una latencia aceptable.
Procesamiento por lotes cuando sea posible
Los requisitos en tiempo real a veces generan limitaciones artificiales. El procesamiento por lotes de múltiples solicitudes mejora el rendimiento y reduce los costos por solicitud. Tareas como la moderación, clasificación o análisis de contenido suelen tolerar pequeños retrasos que permiten el procesamiento por lotes.
Considere el autoalojamiento para escalar.
Con un volumen suficiente, el autoalojamiento resulta económico. Los precios de las API en la nube incluyen márgenes sustanciales. Las organizaciones que procesan millones de solicitudes al mes deberían evaluar la infraestructura dedicada.
El punto de equilibrio depende de las capacidades técnicas, los costos de mantenimiento y los patrones de uso. Los posibles ahorros a gran escala podrían justificar un análisis exhaustivo.
Sistemas de refinamiento iterativo
Los sistemas de destilación y refinamiento paralelo (PDR) generan diversos borradores en paralelo, los condensan en espacios de trabajo delimitados y los refinan en función de dicho espacio. Este enfoque suele ofrecer un mejor rendimiento que las largas cadenas de pensamiento, manteniendo una menor latencia y un tamaño de contexto reducido.
El refinamiento secuencial mejora iterativamente una única respuesta candidata sin espacio de trabajo persistente. Las pruebas en tareas matemáticas demuestran que los procesos iterativos superan los resultados de una sola pasada con presupuestos secuenciales equivalentes. El PDR superficial ofrece las mayores mejoras: aproximadamente un 10 % de mejora en conjuntos de problemas complejos.
Estos métodos consideran los modelos como operadores de mejora con estrategias continuas. Generan cuatro respuestas más cortas y combinan sus fortalezas en una única respuesta superior. Esto suele superar a la generación de una única respuesta larga, utilizando menos tokens en total.
Monitoreo y optimización continuos
La optimización de costes no es algo que se haga una sola vez. El monitoreo continuo permite identificar nuevas oportunidades y detectar regresiones.
Seguimiento de métricas clave
Supervise los tokens por solicitud, el costo por transacción, las tasas de aciertos de caché y la distribución de la selección de modelos. Establezca valores de referencia y reciba alertas ante anomalías. Los patrones de uso cambian, por lo que las estrategias de optimización deben adaptarse.
Implementar bucles de retroalimentación
Los marcos de agentes autoevolutivos implementan bucles de reentrenamiento que detectan problemas y mejoran el rendimiento. La optimización debe continuar hasta alcanzar umbrales de calidad —normalmente, con más de 80¹TP3T de resultados que reciben retroalimentación positiva— o hasta que se observen rendimientos decrecientes, donde las nuevas iteraciones muestren una mejora mínima.
El diseño de sistemas basado en la evaluación utiliza las evaluaciones como proceso central para crear sistemas autónomos de nivel de producción. La evaluación estructurada con métricas claras permite una mejora sistemática sin conjeturas.
Evaluación del modelo regular
Constantemente se lanzan nuevos modelos con una mejor relación precio-rendimiento. Las evaluaciones trimestrales garantizan que las implementaciones aprovechen las últimas opciones. El modelo de vanguardia de ayer se convierte en la alternativa de gama media del mañana.
Pruebe las nuevas versiones comparándolas con los parámetros de referencia existentes. Cambiar de modelo requiere cambios mínimos en el código, pero puede generar ahorros sustanciales o mejoras en las capacidades.
Errores comunes que se deben evitar
Varios errores socavan los esfuerzos de optimización:
- Optimización excesiva únicamente en función del coste: La calidad es fundamental. Una reducción de costos del 50 % no sirve de nada si la calidad del producto disminuye lo suficiente como para requerir intervención humana. Siempre mida la precisión junto con los indicadores de costos.
- Ignorando las implicaciones de la latencia: Algunas técnicas de optimización priorizan el costo sobre la latencia. El procesamiento por lotes y el enrutamiento de modelos aumentan el tiempo de procesamiento. Asegúrese de que el rendimiento siga siendo aceptable para los casos de uso.
- Estrategias de optimización estática: Lo que funciona hoy puede que no funcione mañana. Los precios de los modelos cambian, surgen nuevas funcionalidades y los patrones de uso evolucionan. Las estrategias estáticas pierden eficacia gradualmente.
- Optimización prematura: Comience con técnicas básicas como la optimización de solicitudes y el almacenamiento en caché. Los enfoques complejos, como la destilación de modelos personalizados, requieren una inversión considerable. Asegúrese de que el volumen justifique el esfuerzo.
Ejemplos reales de ahorro de costes
Las implementaciones en producción demuestran ahorros significativos gracias a estas estrategias.
Los sistemas que procesan más de 2 millones de llamadas a la API al mes en múltiples aplicaciones reportan tasas de acierto de caché del 40 %, lo que supone un ahorro de aproximadamente $3000 mensuales. Esto representa una implementación sencilla con un retorno de la inversión inmediato.
Los marcos de trabajo de agentes electrónicos, al reducir el uso de tokens entre un 10 % y un 50 %, mantienen o mejoran la precisión en tareas que requieren un alto nivel de conocimiento. Las pruebas realizadas en tareas que requieren un alto nivel de conocimiento y razonamiento demuestran la eficacia del enfoque ejecutor-verificador.
Los métodos de parada temprana reducen los tokens de inferencia en aproximadamente un 41 por ciento en promedio en cinco conjuntos de datos de razonamiento y tres modelos LLM, manteniendo una precisión comparable.
Estos datos representan resultados obtenidos de sistemas de producción que manejan cargas de trabajo reales.

Deja de malgastar dinero en másteres en derecho con IA superior
Muchos equipos adoptan modelos de lenguaje complejos y solo después se dan cuenta de la rapidez con la que pueden dispararse los costos de infraestructura. El uso de tokens aumenta, los modelos tardan más de lo previsto y los sistemas que funcionaban bien en las pruebas empiezan a resultar costosos en producción.
IA superior Ayuda a las empresas a diseñar y optimizar sistemas LLM para que mantengan su eficiencia a gran escala. Sus equipos trabajan en el desarrollo de modelos personalizados, su ajuste fino y la optimización del flujo de trabajo de IA, reduciendo a menudo el uso innecesario de recursos informáticos y mejorando la forma en que los modelos se implementan dentro de los procesos comerciales reales.
Si los costes de su LLM siguen aumentando, póngase en contacto con nosotros. IA superior para auditar tu configuración y corregir las ineficiencias antes de que llegue tu próxima factura de la nube.
Preguntas frecuentes
¿Cuál es la forma más rápida de reducir los costes de un máster en Derecho (LLM)?
La optimización y el almacenamiento en caché de las solicitudes de información ofrecen resultados inmediatos con una mínima complejidad de implementación. Comience por comprimir las solicitudes de información extensas, solicitar resultados estructurados e implementar un almacenamiento en caché básico para las consultas repetidas. Estos cambios pueden reducir los costos entre un 20 % y un 40 % en cuestión de días.
¿Cuánto se puede ahorrar en el enrutamiento por modelos?
El enrutamiento de modelos suele generar ahorros del 40 al 60 por ciento en comparación con el uso de modelos de vanguardia para todas las tareas. El ahorro exacto depende de la distribución de las tareas: los entornos con muchas tareas sencillas de clasificación o extracción obtienen mayores ahorros que aquellos que requieren principalmente razonamiento complejo.
¿La cuantización perjudica significativamente la calidad del modelo?
Las técnicas de cuantización modernas mantienen la calidad de forma excepcional. La cuantización INT8 suele provocar una degradación de la precisión de entre el 1 % y el 3 %, a la vez que reduce los requisitos de memoria en aproximadamente un 50 %. La cuantización INT4 muestra una degradación de entre el 5 % y el 10 %, pero permite ejecutar modelos mucho más grandes en hardware limitado.
¿Cuándo deberían las organizaciones considerar el autoalojamiento?
El autoalojamiento resulta económico con un volumen mensual de entre 10 y 50 millones de tokens, dependiendo de las capacidades técnicas y los precios de la API en la nube. Las organizaciones con experiencia en ingeniería de aprendizaje automático y patrones de uso consistentes alcanzan el punto de equilibrio antes. Calcule el costo total de propiedad, incluyendo la infraestructura, el mantenimiento y los costos de oportunidad.
¿Con qué frecuencia deben revisarse las estrategias de optimización de costes?
Las revisiones trimestrales detectan cambios importantes en precios, funcionalidades del modelo y patrones de uso. El monitoreo mensual de métricas clave identifica anomalías que requieren atención inmediata. Los cambios importantes en la funcionalidad de la aplicación justifican una reevaluación inmediata de la optimización.
¿Pueden las empresas más pequeñas permitirse técnicas de optimización avanzadas?
Por supuesto. Técnicas básicas como la optimización de solicitudes, el almacenamiento en caché y la selección de modelos requieren una inversión técnica mínima. Enfoques avanzados como la destilación personalizada o el autoalojamiento resultan útiles para volúmenes mayores, pero el ahorro inicial proviene de cambios sencillos que cualquier organización puede implementar.
¿Cuál es la relación entre la optimización de costes y la latencia?
Algunas técnicas mejoran ambos aspectos: la detención temprana reduce el costo y la latencia simultáneamente. Otras generan desventajas: el enrutamiento basado en modelos añade una ligera sobrecarga de enrutamiento, y el procesamiento por lotes retrasa las solicitudes individuales. Diseñe estrategias de optimización considerando los requisitos de latencia para casos de uso específicos.
Avanzando en la optimización de costos
La optimización de costes de LLM es un proceso continuo, no un destino final. Empiece con técnicas de alto impacto y baja complejidad. Mida los resultados con rigor. Realice iteraciones basadas en datos.
Las organizaciones que logran implementar con éxito soluciones LLM en entornos de producción consideran la optimización de costos como una competencia fundamental. Realizan un seguimiento continuo, experimentan sistemáticamente y adaptan sus estrategias a medida que cambian las condiciones.
La investigación continúa impulsando técnicas de optimización. Mantenerse al día con los avances garantiza que las implementaciones se beneficien de las últimas innovaciones. Constantemente surgen nuevos métodos de compresión, enrutamiento e inferencia eficiente.
Pero los principios fundamentales permanecen inalterables: comprender los modelos de precios, asignar los recursos a las necesidades, eliminar el desperdicio y medirlo todo. Estos principios permiten crear estructuras de costos sostenibles que se adaptan al crecimiento del negocio.
Empiece a implementar una o dos estrategias esta semana. Mida el impacto. A partir de ahí, siga avanzando. El efecto acumulativo de múltiples optimizaciones se multiplica: una mejora del 20 % aquí, del 30 % allá, y de repente los costos generales se reducen un 60 % mientras que la calidad mejora.
Eso no es teórico. Eso es lo que logran los sistemas de producción cuando las organizaciones abordan la optimización de costos de manera sistemática.