Puntos clave: Los costos de ajuste fino de LLM suelen oscilar entre $300 y más de $12 000, dependiendo del tamaño del modelo, la técnica y la infraestructura. Los modelos pequeños (2-3 mil millones de parámetros) con LoRA cuestan entre $300 y $700, mientras que los modelos más grandes (7 mil millones) cuestan entre $1000 y $3000 con LoRA, o hasta $12 000 para un ajuste fino completo. Los costos ocultos incluyen la preparación de datos, el almacenamiento, la sobrecarga computacional y el mantenimiento continuo, que pueden duplicar las estimaciones iniciales.
La factura resulta diferente al ajustar modelos de lenguaje complejos. Lo que comienza como un prometedor proyecto de IA se convierte rápidamente en un tema de debate presupuestario que inquieta a los directores financieros.
Los costos de optimización no se limitan a las horas de GPU. El gasto real incluye la preparación de datos, el almacenamiento, los experimentos fallidos y los costos generales de infraestructura que suelen tomar por sorpresa a los equipos. Los debates en la comunidad revelan que tareas sencillas de optimización cuestan entre $3000 y $10 000, y eso sin tener en cuenta los gastos ocultos.
Aquí te explicamos qué factores influyen realmente en esos costes y cómo mantenerlos bajo control.
Desglosando los costos reales de ajuste fino
El tamaño del modelo importa más de lo que la mayoría de los equipos esperan. La cantidad de parámetros impacta directamente en los requisitos de computación y, en última instancia, en la factura.
Según los datos disponibles, estos son los precios reales de los diferentes tamaños de modelos:
| Tamaño del modelo | Método de ajuste fino | Rango de costos típico | Tiempo de entrenamiento |
|---|---|---|---|
| Phi-2 (2.7 mil millones de parámetros) | LoRA | $300 – $700 | Varias horas |
| Mistral 7B | LoRA | $1.000 – $3.000 | 6-12 horas |
| Mistral 7B | Ajuste fino completo | Hasta $12.000 | 24-48 horas |
| Llama 2 7B | LoRA | $1.200 – $3.500 | 8-16 horas |
La técnica es tan importante como el tamaño del modelo. La adaptación de bajo rango (LoRA) reduce drásticamente los costos al actualizar solo un pequeño subconjunto de parámetros en lugar de todo el modelo. Los métodos LoRA lograron un aumento promedio de precisión de 36% con respecto a los modelos de referencia, según las pruebas realizadas con conjuntos de datos financieros, manteniendo los costos bajo control.
Pero esas cifras solo cuentan una parte de la historia.

Obtenga un desglose claro de los costos de ajuste fino de LLM de AI Superior.
Los costes de ajuste fino de los modelos lineales generalizados (LLM) varían en función del tamaño del conjunto de datos, la elección del modelo, la infraestructura y los requisitos de evaluación. IA superior Ayuda a las organizaciones a evaluar si es necesario realizar ajustes o si las soluciones de ingeniería rápida o basadas en la recuperación son más rentables.
Su enfoque incluye:
- Estrategia de evaluación y preparación de datos
- Configuración del proceso de selección y entrenamiento de modelos
- Evaluación del desempeño y análisis comparativo
- Configuración de implementación y monitoreo
Si está considerando perfeccionar su LLM, consulte IA superior para un análisis de costo-beneficio alineado con el retorno de la inversión esperado.
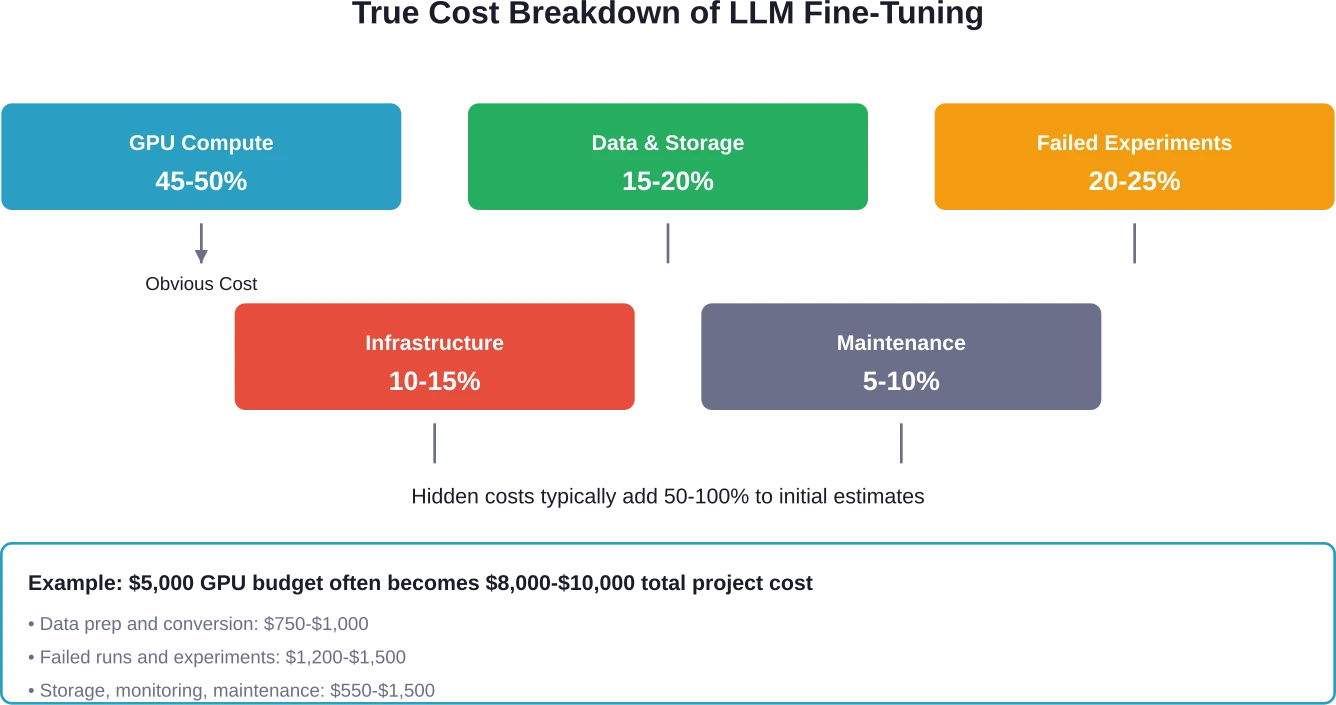
Los gastos ocultos de los que nadie te advierte
El precio indicado en la etiqueta para el tiempo de GPU representa quizás la mitad del costo real. El resto aparece en aspectos que los equipos no contemplan en su presupuesto inicial.
Preparación y almacenamiento de datos
Los datos sin procesar no sirven para el ajuste fino. Convertir los conjuntos de datos al formato correcto (normalmente JSONL en la mayoría de las plataformas) requiere tiempo de ingeniería. Los miembros de la comunidad que trabajan con 400 000 muestras de entrenamiento y 2000 de prueba informan de una sobrecarga de preprocesamiento considerable.
Los costos de almacenamiento se acumulan rápidamente. Los conjuntos de datos de entrenamiento, los conjuntos de validación, los puntos de control del modelo y las múltiples versiones experimentales requieren almacenamiento. AWS y los proveedores de la nube cobran por separado por esto, y el costo se acumula con el paso de los meses.
Experimentos fallidos e iteración
La primera fase de ajuste fino rara vez produce resultados listos para producción. Los equipos iteran sobre los hiperparámetros, la calidad de los datos y los métodos de entrenamiento. Cada iteración tiene un coste.
Las investigaciones sobre la eficiencia de los datos demuestran que el ajuste fino que tiene en cuenta la complejidad logró la misma precisión utilizando solo 11% de datos originales y superó a otros métodos en un promedio de 4,7%. Sin embargo, descubrir el enfoque óptimo requiere experimentación, y los intentos fallidos cuestan tanto como los exitosos.
Gastos generales de infraestructura
El autoalojamiento añade costes adicionales más allá de la computación. Los clústeres multi-GPU, las redes, la monitorización y el mantenimiento requieren recursos. Los nodos GPU básicos cuestan a partir de $2,500 al mes, y la infrautilización supone un derroche de dinero en hardware inactivo.
Ajuste fino de OpenAI: Precios basados en API
OpenAI ofrece el ajuste fino como un servicio gestionado, cobrando por token en lugar de por infraestructura. El modelo de facturación difiere significativamente de los enfoques autogestionados.
Los costos de entrenamiento se calculan multiplicando el número de tokens por el número de épocas. Para GPT-3.5-turbo, los conjuntos de datos de entrenamiento típicos, con entre 90 000 y 100 000 tokens, cuestan varios cientos de dólares para un ajuste fino completo. Los conjuntos de validación implican cargos adicionales por tokens.
Pero aquí es donde la cosa se complica. La API estima de antemano el consumo máximo de tokens, incluyendo los tokens de imagen y la sobrecarga de las llamadas a funciones. Las imágenes pueden consumir hasta 1105 tokens para resoluciones estándar o 36 835 tokens para entradas de alta resolución por época; costes que sorprenden a los desarrolladores que no leen la letra pequeña.
El ajuste fino por refuerzo (RFT) para modelos de razonamiento utiliza un enfoque de facturación completamente diferente. En lugar de precios basados en tokens, RFT cobra en función del tiempo dedicado a realizar el trabajo principal de aprendizaje automático. La facturación depende de la configuración de compute_multiplier, la frecuencia de validación y la selección del modelo de evaluación.
Costos de AWS y la plataforma en la nube
Amazon Bedrock y SageMaker ofrecen optimización gestionada con precios de pago por uso. Los costes varían según el proveedor del modelo, la modalidad y el tipo de instancia.
El precio de SageMaker depende de la instancia seleccionada. La instancia ml.g5.12xlarge, comúnmente utilizada para el ajuste fino de modelos 7B, consume aproximadamente $7-$8 por hora. Un proceso de ajuste fino típico, que dura entre 8 y 12 horas, cuesta entre $60 y $100 solo en capacidad de procesamiento.
Los precios de Amazon Bedrock varían significativamente según el modelo. Los modelos Titan, las variantes de Claude y los modelos Llama tienen tarifas diferentes. El ajuste fino de modelos de incrustación suele ser más económico que el ajuste fino de modelos generativos.
El almacenamiento en AWS genera costos adicionales. El almacenamiento S3 para conjuntos de datos, artefactos de modelos y puntos de control, además de los volúmenes EBS para instancias, acumulan cargos. Para un proyecto con 1000 usuarios que realizan 10 solicitudes diarias con 2000 tokens de entrada y 1000 tokens de salida, los costos de almacenamiento y transferencia de datos pueden superar los costos de computación con el tiempo.
La decisión entre alojamiento propio y alojamiento en la nube
El autoalojamiento puede parecer caro al principio, pero puede resultar más económico a gran escala. La nube parece barata inicialmente, pero los costes se acumulan con el tiempo.
| Factor | Autogestionado | Nube/API |
|---|---|---|
| Inversión inicial | Alto ($5.000-$15.000) | Ninguno |
| Costo operativo mensual | Solo electricidad (~$100-$300) | $500-$5,000+ |
| Escalabilidad | Limitado por el hardware | Esencialmente ilimitado |
| Carga de mantenimiento | Alto (equipo interno) | Ninguno |
| Privacidad de datos | Control total | Depende del proveedor |
| Punto de equilibrio | 3-6 meses | N / A |
Una RTX 4090 cuesta 1600 TPM como compra única, frente a las GPU en la nube que cuestan 2500 TPM al mes. El hardware se amortiza en cuestión de semanas para equipos con cargas de trabajo constantes.
Pero la nube tiene sentido para la experimentación y las cargas de trabajo variables. Poner en marcha una tarea de ajuste fino cuando sea necesario es mejor que mantener hardware inactivo.
Estrategias de reducción de costos que realmente funcionan.
Reducir los costes de ajuste fino no significa sacrificar los resultados. Varias técnicas probadas reducen significativamente los gastos.
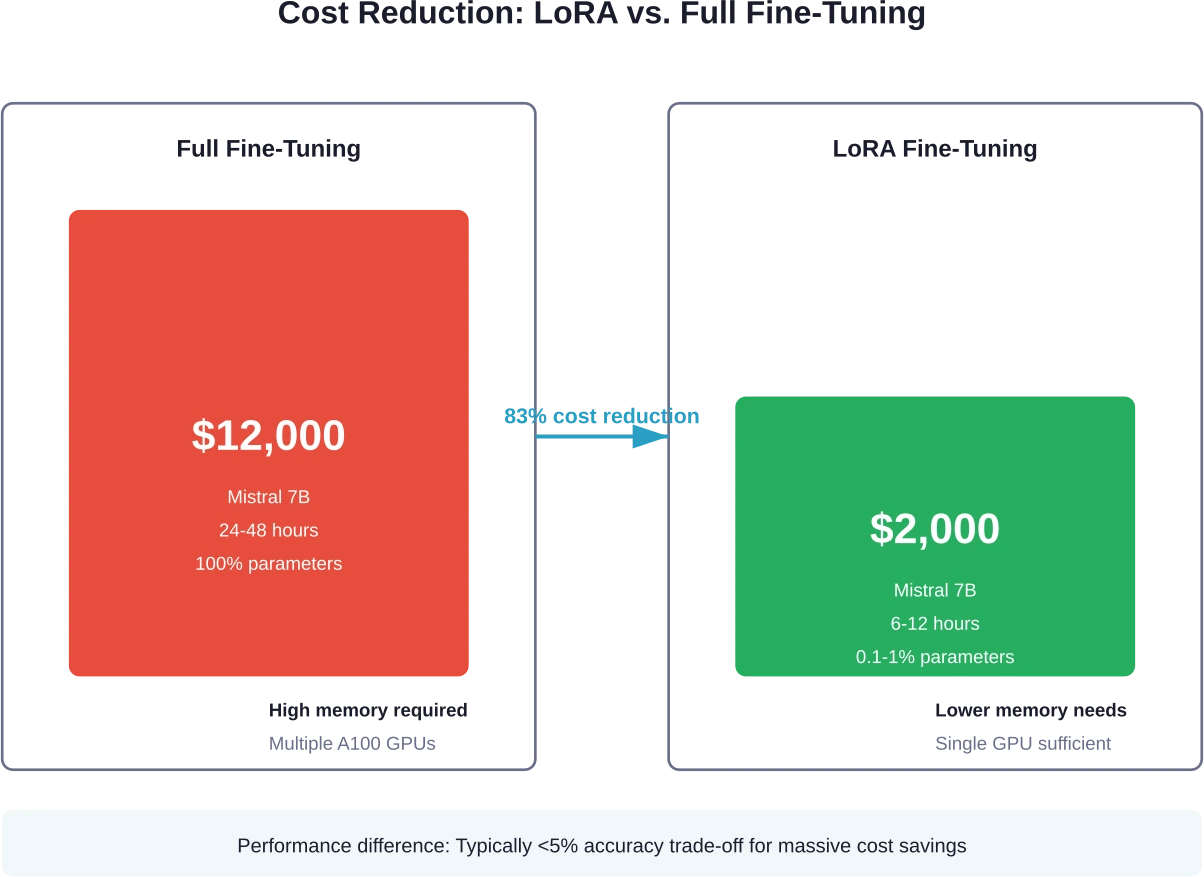
Utilice LoRA en lugar de un ajuste fino completo.
LoRA logra resultados comparables actualizando solo entre 0,1 y 11 TP3T parámetros del modelo. La reducción en los parámetros entrenables se traduce directamente en menores requisitos computacionales y tiempos de entrenamiento más rápidos.
Los métodos LoRA cuestan aproximadamente entre 4 y 10 veces menos que el ajuste fino completo para el mismo modelo. Mistral 7B con LoRA ejecuta entre $1000 y $3000, frente a $12000 para el ajuste fino completo; el mismo modelo, pero con un coste radicalmente diferente.
Aproveche la computación fuera de las horas pico.
Algunos proveedores ofrecen instancias bajo demanda o precios fuera de las horas pico. Los debates en la comunidad sugieren interés en opciones de ajuste fino más económicas, y algunos mencionan posibles reducciones de costos de 70% mediante diversos enfoques de optimización.
Prioriza la calidad de los datos sobre la cantidad.
Más datos de entrenamiento no siempre significan mejores resultados. Las investigaciones sobre el ajuste fino que tiene en cuenta la complejidad demuestran que la selección de datos específica logra la misma precisión con 11% de los datos originales.
La selección de ejemplos de alta calidad reduce la cantidad de tokens y el tiempo de entrenamiento. En lugar de introducir 1 millón de tokens en el modelo, 100 000 tokens cuidadosamente seleccionados suelen ofrecer un rendimiento igual de bueno, con un coste 10%.
Opciones inteligentes de hiperparámetros
Las tasas de aprendizaje agresivas y un menor número de épocas reducen el tiempo de entrenamiento sin perjudicar necesariamente el rendimiento. Encontrar el equilibrio óptimo requiere cierta experimentación, pero el ahorro se acumula rápidamente.
La frecuencia de validación también es importante. Reducir la frecuencia de validación (por ejemplo, cada 100 pasos en lugar de cada 10) disminuye proporcionalmente los costos computacionales de validación. Para el ajuste fino del refuerzo, elegir modelos de calificación eficientes y evitar ejecuciones de validación excesivas reduce directamente los costos.
Cuando el ajuste fino tiene sentido desde el punto de vista financiero
No todos los casos de uso justifican los costes de ajuste fino. La rentabilidad debe ser viable.
El ajuste fino tiene sentido cuando:
- La precisión específica del dominio importa más que el costo. Las aplicaciones médicas, legales o financieras en las que los errores tienen consecuencias reales justifican la inversión.
- El volumen de llamadas a la API encarece el servicio. Las aplicaciones de alto rendimiento que procesan millones de tokens al mes a menudo encuentran que la optimización es más económica que las llamadas repetidas a la API.
- La privacidad de los datos requiere control local. Los datos confidenciales que no pueden salir de los límites de la infraestructura requieren modelos autogestionados y optimizados.
- Se requieren formatos o salidas especializados. Cuando las indicaciones por sí solas no pueden lograr la estructura de salida o la coherencia de comportamiento deseadas.
El ajuste fino no tiene sentido cuando:
- Una intervención de ingeniería rápida logra resultados similares. Las ventanas de contexto ahora admiten entre 200 000 y 1 millón de tokens. Muchas tareas funcionan correctamente con las indicaciones completas del sistema.
- Los modelos cambian más rápido que los ciclos de implementación. Cada 4-6 meses se lanzan modelos mejores. Perfeccionar el Mistral 4B queda obsoleto cuando se lanzan Qwen o Llama 3 semanas después.
- El volumen no justifica el coste inicial. Las aplicaciones con poco tráfico que pagan 100 TPM al mes en tarifas de API no pueden justificar 5000 TPM en costos de ajuste fino.
El cálculo se reduce a un análisis del punto de equilibrio. Si el ajuste fino cuesta $8000 y ahorra $500 al mes en tarifas de API, el período de recuperación de la inversión es de 16 meses. Esto es razonable para aplicaciones estables a largo plazo. Es pésimo para proyectos experimentales o casos de uso que evolucionan rápidamente.
La economía del ajuste fino del refuerzo
El ajuste fino mediante aprendizaje por refuerzo introduce una dinámica de costes diferente. A diferencia del ajuste fino supervisado, que se factura mediante tokens, el ajuste fino por refuerzo cobra por el tiempo de cómputo empleado en el trabajo de entrenamiento principal.
La API RFT de OpenAI cobra en función de la duración del entrenamiento, no del tamaño del conjunto de datos. Los factores que influyen en el coste son:
- Calcular los parámetros del multiplicador que controlan la velocidad de entrenamiento.
- Frecuencia de validación y selección del modelo de evaluador
- Duración del episodio y complejidad de la tarea
Optimizar los costes de RFT implica elegir el modelo de evaluador más pequeño que cumpla con los requisitos de calidad, evitar ejecuciones de validación excesivas y mantener la eficiencia del código de evaluación personalizado.
Las investigaciones sobre la optimización de datos en el aprendizaje por refuerzo demuestran que la selección de datos en línea y la reproducción de datos reducen el tiempo de entrenamiento entre 23% y 62%, manteniendo el rendimiento. Esto se traduce directamente en un ahorro de costes proporcional a la reducción del tiempo.
Seguimiento y gestión de los costes recurrentes
El ajuste fino no es un gasto único. Los modelos se desvían, los datos cambian y es necesario volver a entrenarlos.
El seguimiento de los costes por cliente o proyecto permite una asignación de costes transparente. Para los equipos que prestan servicio a varios clientes a través de una única cuenta, la obtención de los detalles del trabajo mediante la API y el cálculo de los costes a partir de los tokens entrenados y el tipo de modelo proporciona un seguimiento aproximado.
Establecer límites estrictos evita gastos excesivos. OpenAI y los proveedores de servicios en la nube admiten topes de gasto que detienen los trabajos de entrenamiento cuando se alcanzan ciertos umbrales. Esto protege contra trabajos mal configurados que consumen miles de horas de GPU.
Es fundamental monitorizar el panel de control. Observar el progreso de la formación permite pausar o cancelar tareas con bajo rendimiento antes de desperdiciar más recursos. La mayoría de las plataformas muestran métricas en tiempo real y costes acumulados.
Preguntas frecuentes
¿Cuánto cuesta ajustar un modelo de 7 mil millones de parámetros?
El ajuste fino de un modelo 7B como Mistral o Llama suele costar entre 1.000 y 3.000 TP4T utilizando técnicas LoRA, o hasta 12.000 TP4T para un ajuste fino completo. El coste exacto depende del tamaño del conjunto de datos, la duración del entrenamiento y la infraestructura elegida (nube o autoalojamiento).
¿Es LoRA tan eficaz como un ajuste fino completo?
LoRA logra un rendimiento comparable al del ajuste fino completo para la mayoría de las aplicaciones, con una diferencia de precisión típicamente inferior a 5%. LoRA actualiza solo entre 0,1 y 1% de parámetros, ofreciendo resultados similares a un costo entre 4 y 10 veces menor y con tiempos de entrenamiento más rápidos.
¿Cuáles son los costes ocultos del ajuste fino de LLM?
Los costos ocultos incluyen la preparación y conversión de datos (10-15% del presupuesto), experimentos fallidos e iteraciones (20-25%), almacenamiento de conjuntos de datos y puntos de control (5-10%), gastos generales de infraestructura para configuraciones autoalojadas (10-15%) y mantenimiento y reentrenamiento continuos (5-10%). Estos costos pueden duplicar las estimaciones iniciales de costos de GPU.
¿Cuándo debo usar la optimización de la API en lugar del autoalojamiento?
La optimización de la API resulta útil para cargas de trabajo variables, experimentación y equipos sin infraestructura de aprendizaje automático. El autoalojamiento se vuelve rentable para cargas de trabajo consistentes y de alto volumen, donde una inversión única en hardware ($5000-$15000) se amortiza en 3 a 6 meses en comparación con los costos continuos de la nube.
¿Cómo puedo reducir los costos de ajuste fino con 70%?
Utilice LoRA en lugar de un ajuste fino completo, aproveche las instancias spot o los precios de computación fuera de las horas pico, optimice la calidad de los datos para reducir el tamaño del conjunto de datos entre 80 y 90%, reduzca la frecuencia de validación y elija hiperparámetros eficientes que acorten el tiempo de entrenamiento. La combinación de estas estrategias puede reducir los costos en 70% o más.
¿Tiene sentido realizar ajustes finos con ventanas de contexto amplias?
En muchos casos, las ventanas de contexto amplias (de 200 000 a 1 millón de tokens) reducen la necesidad de ajustes finos. Si la solicitud exhaustiva produce resultados aceptables, suele ser más económica que los ajustes finos. Sin embargo, estos últimos siguen siendo útiles para lograr un comportamiento consistente, formatos de salida específicos o cuando las llamadas repetidas a la API superan los costos de los ajustes finos.
¿Con qué frecuencia es necesario volver a entrenar los modelos ya ajustados?
La frecuencia de reentrenamiento depende de la deriva de los datos y del ciclo de vida del modelo. Los modelos de producción suelen necesitar actualizaciones cada 3-6 meses a medida que cambian los datos subyacentes o se lanzan mejores modelos base. Las aplicaciones críticas pueden requerir reentrenamiento mensual, mientras que los dominios estables pueden extenderse a ciclos anuales.
Tomar la decisión de inversión
Los ajustes finos cuestan dinero de verdad. La decisión de seguir adelante no debe tomarse a la ligera.
Comience por validar si es necesario realizar ajustes. Pruebe primero con indicaciones detalladas utilizando el modelo base. Muchos equipos descubren que el método 90% de su caso de uso funciona sin necesidad de ajustes.
Calcula el coste total de propiedad, no solo las horas de GPU. Incluye la preparación de datos, el presupuesto para experimentación, el almacenamiento y el mantenimiento. Añade 50-100% a las estimaciones iniciales para cubrir los costes ocultos.
Compárese con los costos de la API para el volumen previsto. Si el gasto actual es de $200/mes y los costos de ajuste fino son de $8000, el punto de equilibrio se alcanza en 40 meses. Este cálculo no funciona para la mayoría de los proyectos.
Consideremos la longevidad del modelo. Perfeccionar un modelo que quedará obsoleto en 4 meses supone un desperdicio de recursos. La rápida evolución de las familias de modelos hace que la optimización sea menos atractiva de lo que parece.
Pero cuando la experiencia en el sector, la privacidad de los datos o la rentabilidad lo justifican, el ajuste fino aporta un valor que los modelos genéricos no pueden igualar. La clave está en analizar las cifras con honestidad antes de comprometer el presupuesto.
Los equipos que logran optimizar LLM lo consideran una decisión de inversión, no una elección técnica. Miden los costos, establecen objetivos de rendimiento claros y conocen su punto de equilibrio antes de que se ponga en marcha la primera GPU.
¿Listo para optimizar los costos de desarrollo de IA? Empiece por medir con precisión sus gastos actuales en API y proyectar el crecimiento del volumen. Esta base determinará si la optimización tiene sentido desde el punto de vista financiero para su situación particular.