Descripción general: Entrenar un modelo de lenguaje complejo como GPT-4 cuesta entre 1.047.800 y 192 millones de dólares, de los cuales entre 60.000 y 701.000 millones corresponden a infraestructura informática. Los costos se derivan de clústeres de GPU, consumo eléctrico, preparación de datos y personal de ingeniería. Optimizar los modelos existentes puede reducir los gastos entre 60.000 y 901.000 millones en comparación con el entrenamiento desde cero.
Los grandes modelos de lenguaje han transformado la inteligencia artificial, pasando de ser una curiosidad de investigación a una poderosa herramienta comercial. Pero lo que muchos desconocen es que el coste de crear estos sistemas rivaliza con el de lanzar satélites al espacio.
Según el Informe del Índice de IA de Stanford de 2025, el entrenamiento de GPT-4 tuvo un costo estimado de entre $78 y 100 millones. Gemini Ultra 1.0 elevó esa cifra a $192 millones. Esto representa un aumento de 287 000 veces con respecto a los $670 que costaba entrenar un modelo Transformer en 2017.
La economía que respalda estas cifras no es mera curiosidad académica. Las organizaciones que evalúan si desarrollar modelos personalizados o licenciar los existentes necesitan datos concretos. Los equipos de investigación que buscan financiación necesitan proyecciones presupuestarias realistas. Y los observadores de la industria que siguen de cerca el desarrollo de la IA necesitan contexto para comprender la dinámica del mercado.
Este análisis examina a dónde va cada dólar al entrenar modelos de lenguaje de vanguardia, por qué los costos aumentan tan drásticamente y qué estrategias realmente reducen los gastos sin sacrificar el rendimiento.
Anatomía de los costos de la formación en LLM
Los costos de capacitación no provienen de una sola partida. Varias categorías de gastos se suman para formar totales de ocho y nueve cifras.
La infraestructura informática acapara la mayor parte del presupuesto. Los proveedores de servicios en la nube cobran por el acceso a la GPU por hora, y los entrenamientos se extienden durante semanas o meses. Según se informa, OpenAI gastó más de 100 millones de dólares en el entrenamiento de GPT-4, destinando una parte significativa a los costes de computación en la nube.
Los costos de hardware aumentan con la complejidad del modelo. Los modelos más grandes requieren aceleradores más potentes y en mayor cantidad. La diferencia entre entrenar un modelo de 20 mil millones de parámetros y uno de 120 mil millones no es lineal. Los requisitos computacionales aumentan exponencialmente a medida que aumenta el número de parámetros.
Pero esperen. Los costos del hardware solo cuentan una parte de la historia.
Los multiplicadores ocultos
El consumo de electricidad genera gastos recurrentes que muchos presupuestos iniciales subestiman. En febrero de 2026, Anthropic anunció su compromiso de cubrir los aumentos en el precio de la electricidad en sus centros de datos, lo que demuestra la seriedad con la que los principales laboratorios de IA se toman este asunto. Señalaron que entrenar un solo modelo de IA de vanguardia pronto requerirá gigavatios de energía, reconociendo así la carga que estos sistemas suponen para la infraestructura.
La preparación y el almacenamiento de datos añaden otra capa de complejidad. Los conjuntos de datos de entrenamiento para modelos como GPT-4 contienen cientos de miles de millones de tokens procedentes de libros, sitios web, artículos académicos y corpus especializados. La adquisición, limpieza, filtrado y almacenamiento de estos datos requiere equipos e infraestructura específicos.
El talento en ingeniería tiene una remuneración muy alta. Los investigadores de aprendizaje automático y los ingenieros de infraestructura capaces de coordinar entrenamientos en miles de GPU son escasos. Sus salarios, bonificaciones y paquetes de acciones representan una parte sustancial del costo total del proyecto.
Las iteraciones experimentales multiplican los costos iniciales. Encontrar los hiperparámetros óptimos (tasas de aprendizaje, tamaños de lote, variaciones arquitectónicas) requiere múltiples ejecuciones de entrenamiento. Cada experimento fallido consume horas de GPU sin producir el modelo final.

Infraestructura de GPU: El gasto dominante
Las unidades de procesamiento gráfico (GPU) constituyen la base del entrenamiento de la IA moderna. Estos chips especializados destacan en las operaciones matriciales paralelas que requieren las redes neuronales.
NVIDIA domina el mercado. Sus aceleradores H100 y A100 impulsan la mayoría de las operaciones de entrenamiento a gran escala. Los proveedores de servicios en la nube cobran aproximadamente $2-4 por hora de GPU H100. Entrenar un modelo de vanguardia puede requerir entre 10 000 y 25 000 GPU funcionando durante varias semanas.
Las cifras se vuelven brutales rápidamente. A razón de $3 por hora de GPU, operar 15 000 GPU durante 30 días seguidos cuesta $32,4 millones, solo por el tiempo de procesamiento. Esto sin contar el almacenamiento, la red ni ningún otro componente de infraestructura.
La compra directa de hardware modifica la estructura de costos. Si bien la inversión inicial es mayor, evitar los costos recurrentes de la nube puede reducir el gasto total a largo plazo. Las organizaciones que planean múltiples ciclos de capacitación o procesos de ajuste continuos suelen encontrar que la compra es más económica que el alquiler.
El problema del tiempo de inactividad
Sin embargo, hay un detalle importante: las GPU no son productivas en todo momento mientras están encendidas. Los cuellos de botella en la carga de datos, el guardado de puntos de control y las pausas de depuración crean períodos de inactividad en los que el costoso hardware permanece sin usar, pero aun así genera costos.
Una investigación de arXiv que examinó marcos de entrenamiento LLM eficientes reveló que, a pesar de consumir toda su potencia, las GPU durante el preentrenamiento estándar suelen operar a tasas de utilización subóptimas de entre 30% y 50%. Esta ineficiencia se debe a la forma en que las arquitecturas Transformer interactúan con las capacidades del hardware.
Existen soluciones. Los marcos de entrenamiento optimizados pueden mejorar la utilización de la GPU al agilizar los flujos de datos, superponer el cálculo con la comunicación y minimizar la sobrecarga de sincronización. Estas mejoras no solo aceleran el entrenamiento, sino que reducen directamente el total de horas de GPU necesarias.
| Tipo de hardware | Costo por hora en la nube | Precio de compra | Punto de equilibrio |
|---|---|---|---|
| NVIDIA H100 | $2.50-$4.00 | $30,000-$40,000 | 10.000-16.000 horas |
| NVIDIA A100 | $1.50-$2.50 | $10,000-$15,000 | 6.000-10.000 horas |
| NVIDIA H200 | $3.50-$5.00 | $40,000-$50,000 | 11.000-14.000 horas |
Costes energéticos: una preocupación creciente
Las facturas de electricidad para las sesiones de entrenamiento rivalizan con los gastos del propio hardware. Los modelos Frontier consumen gigavatios-hora de energía, suficiente para abastecer a miles de hogares durante meses.
La eficiencia energética se ha convertido en un foco de investigación primordial. Un trabajo publicado en arXiv que examina la optimización energética en aplicaciones basadas en LLM prioriza el consumo de energía como una métrica clave de eficiencia, junto con las medidas de rendimiento tradicionales. Los experimentos realizados con hardware NVIDIA RTX 8000 demostraron que los enfoques optimizados logran una precisión comparable a la de los métodos de referencia, al tiempo que reducen el consumo de energía entre 23 y 50%.
Seamos realistas: los costos de la energía no se limitan a la factura inmediata. La infraestructura necesaria para suministrar gigavatios de potencia requiere subestaciones, sistemas de refrigeración y generadores de respaldo. Los operadores de centros de datos incluyen estas inversiones de capital en sus modelos de precios.
A medida que aumentan las necesidades de capacitación, la infraestructura eléctrica se convierte en un obstáculo competitivo. Las organizaciones con acceso a electricidad confiable y de bajo costo obtienen ventajas significativas en la economía de la capacitación.
Entrenamiento desde cero vs. ajuste fino
No todos los proyectos requieren la creación de un modelo desde cero. El ajuste fino de modelos preentrenados ofrece una alternativa rentable para muchas aplicaciones.
La situación económica cambia drásticamente. Ajustar un modelo como Llama 2 o GPT-3.5 con datos específicos del dominio puede costar entre 1.400 y 5.000 millones de yuanes, dependiendo del tamaño del conjunto de datos y los requisitos de computación. Esto supone entre 1.000 y 10.000 veces menos coste que entrenar un modelo comparable desde cero.
Una investigación documentada en arXiv que examina estrategias eficientes para la mejora de modelos lineales de bajo nivel (LLM) reveló que el ajuste fino con técnicas como LoRA (Adaptación de Bajo Rango) puede ejecutarse en hardware modesto. Un experimento aplicó el entrenamiento LoRA a un modelo precuantizado de 4 bits utilizando una única GPU NVIDIA T4 con 16 GB de VRAM, completando el proceso en 7 horas.
Sin embargo, el ajuste fino conlleva limitaciones. Los modelos preentrenados presentan sesgos inherentes y lagunas de conocimiento derivadas de sus datos de entrenamiento originales. El ajuste fino adapta el comportamiento del modelo a tareas específicas, pero no altera fundamentalmente su conocimiento ni sus capacidades principales.
¿Cuándo tiene sentido empezar a entrenar desde cero?
Las organizaciones buscan una formación integral por diversas razones. Los conjuntos de datos propietarios que no se pueden compartir con proveedores de modelos externos requieren formación interna. Los dominios especializados donde los modelos existentes tienen un rendimiento deficiente se benefician de arquitecturas personalizadas entrenadas desde cero con corpus relevantes.
La diferenciación competitiva impulsa algunas decisiones. Las empresas que desarrollan productos basados en IA buscan modelos que sus competidores no puedan replicar simplemente ajustando alternativas disponibles públicamente.
Es fundamental controlar el comportamiento del modelo. El entrenamiento desde cero proporciona una visibilidad completa de las fuentes de datos, los procedimientos de entrenamiento y las características del modelo, algo crucial para las industrias reguladas o las aplicaciones críticas para la seguridad.


Calcula el coste de tu formación en LLM.
El entrenamiento de grandes modelos de lenguaje (LLM, por sus siglas en inglés) implica la curación de datos, la infraestructura, la asignación de recursos computacionales, la experimentación y la evaluación. IA superior Analizamos su conjunto de datos, objetivos y metas de rendimiento antes de estimar los recursos y el tiempo necesarios. El desglose de costos incluye el preprocesamiento, los ciclos de entrenamiento, el ajuste fino y la validación. Esto le permite planificar el gasto en computación y el esfuerzo de ingeniería con anticipación.
¿Listo para calcular tu inversión en formación LLM?
Habla con una IA superior a:
- evalúa tu conjunto de datos y tus objetivos
- definir la estrategia de capacitación y calcular las necesidades
- Reciba una estimación de costos estructurada para la formación en LLM.
👉 Solicitar un Presupuesto de formación LLM de IA Superior.
Ejemplos de costos reales
Los modelos específicos proporcionan puntos de referencia concretos para comprender la economía de la formación.
Según The Wall Street Journal y el Informe del Índice de IA de Stanford de 2025, el entrenamiento de GPT-4 tuvo un costo estimado de entre 1.047.800 y 1.000 millones de dólares. Esta cifra incluye la infraestructura informática, la electricidad, la adquisición de datos y los recursos de ingeniería durante todo el período de entrenamiento.
Gemini Ultra 1.0 elevó los costos a aproximadamente 192 millones de dólares, según el Informe del Índice de IA de Stanford de 2025. Este aumento en los gastos refleja una mayor escala, una duración de entrenamiento más prolongada o una experimentación más extensa durante el desarrollo.
El entrenamiento de GPT-40 duró aproximadamente 100 millones de horas. Estos modelos de vanguardia de los principales laboratorios comparten estructuras de costos similares: presupuestos de ocho o nueve cifras, dominados por el procesamiento de GPU y el consumo de energía.
Las organizaciones más pequeñas se enfrentan a una situación económica diferente. Entrenar un modelo de 7 mil millones de parámetros podría costar entre 1.500.000 y 1.200.000, dependiendo del acceso al hardware y su eficiencia. Un modelo de 20 mil millones de parámetros podría costar entre 1.500.000 y 1.200.000. Estas cifras siguen siendo considerables, pero están al alcance de startups bien financiadas o equipos de investigación empresarial.
La trayectoria de la inflación de precios
Los costes de formación se han disparado exponencialmente. El informe Stanford AI Index Report 2025 documentó un aumento de 287.000 veces desde 2017 hasta la actualidad, pasando de $670 para los primeros modelos Transformer a cifras de nueve dígitos para los sistemas de vanguardia actuales.
Esta tendencia no muestra signos de revertirse. Los modelos siguen aumentando en número de parámetros, volumen de datos de entrenamiento y complejidad arquitectónica. Cada generación exige mayor capacidad de procesamiento que la anterior.
Dicho esto, las mejoras en la eficiencia compensan parcialmente el aumento de escala. Mejores algoritmos, hardware optimizado y técnicas de entrenamiento mejoradas permiten obtener mayor capacidad por cada dólar invertido. De hecho, el costo por unidad de capacidad del modelo ha disminuido, incluso a pesar del aumento de los costos absolutos de entrenamiento.
Estrategias para reducir los costos de capacitación
Es posible adoptar múltiples enfoques para reducir sustancialmente los gastos sin sacrificar proporcionalmente la calidad del modelo.
Los marcos de entrenamiento eficientes minimizan el desperdicio de ciclos de GPU. Técnicas como la acumulación de gradientes, el entrenamiento de precisión mixta y las canalizaciones de carga de datos optimizadas mejoran la utilización del hardware. Según el análisis de sistemas de entrenamiento de alto rendimiento, abordar la utilización ineficiente de los recursos computacionales durante el entrenamiento de transformadores puede reducir drásticamente tanto el tiempo de entrenamiento como el consumo de energía.
Las técnicas de compresión de modelos reducen los requisitos computacionales. La cuantización representa los pesos con menos bits, disminuyendo el ancho de banda de la memoria y las necesidades de almacenamiento. La poda elimina las conexiones menos importantes, reduciendo el tamaño del modelo. La destilación del conocimiento transfiere capacidades de modelos grandes a modelos más pequeños de forma más eficiente que el entrenamiento desde cero.
La asignación inteligente de recursos evita pagar por hardware inactivo. La pausa automática de los clústeres de GPU durante las fases de preparación de datos, el dimensionamiento dinámico de la infraestructura para cada etapa de entrenamiento y la programación de las ejecuciones durante las horas de menor demanda de electricidad contribuyen a reducir los costos totales.
La optimización de hiperparámetros reduce los experimentos fallidos. Las estrategias de búsqueda sistemáticas encuentran configuraciones de entrenamiento efectivas más rápido que el ajuste manual. Menos ejecuciones de entrenamiento desperdiciadas significan menos horas de GPU consumidas en callejones sin salida.
La decisión entre la nube y las instalaciones locales
La infraestructura en la nube ofrece flexibilidad y bajos costos iniciales. Se pueden activar miles de GPU para una prueba de entrenamiento y liberarlas una vez finalizada. Este enfoque es ideal para organizaciones que realizan experimentos ocasionales o que no tienen claras sus necesidades de computación a largo plazo.
El hardware instalado en las instalaciones del cliente requiere una inversión inicial considerable, pero elimina los gastos de alquiler recurrentes. El análisis del punto de equilibrio suele mostrar que la propiedad resulta rentable tras 10 000 a 16 000 horas de uso de chips H100 o de 6 000 a 10 000 horas para chips A100.
Las organizaciones que planifican múltiples ciclos de entrenamiento a gran escala, operaciones continuas de ajuste fino o procesos de desarrollo de modelos a largo plazo suelen encontrar que la compra de hardware resulta más económica a pesar de los mayores costes iniciales.
| Estrategia de reducción de costos | Ahorros potenciales | Complejidad de la implementación |
|---|---|---|
| Marcos de capacitación eficientes | 20-40% | Medio |
| Cuantización del modelo | 30-50% | Bajo |
| Planificación inteligente de recursos | 15-30% | Medio |
| Ajuste fino frente a entrenamiento desde cero | 60-90% | Bajo (si el modelo base se ajusta a las necesidades) |
| Hardware local (a largo plazo) | 40-60% | Alto |
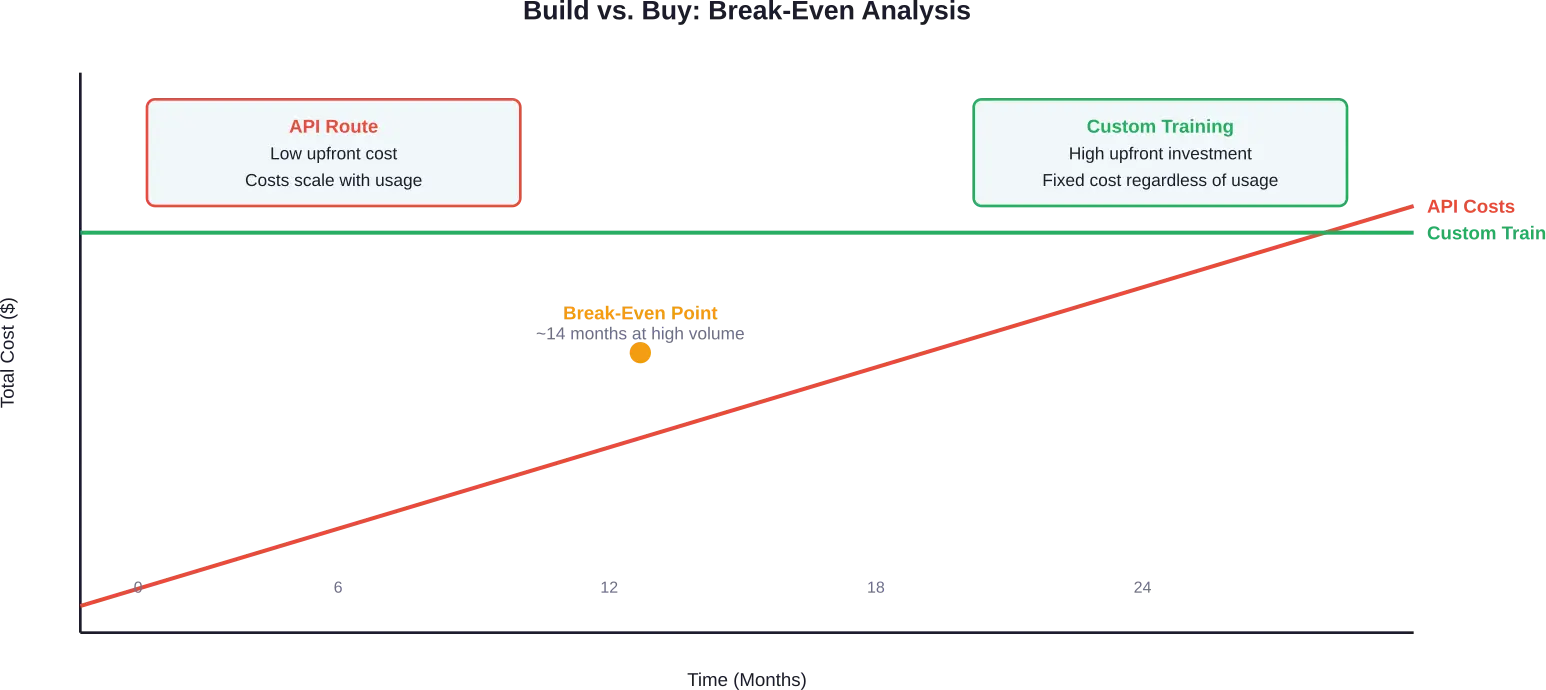
La decisión de construir o comprar
Muchas organizaciones se enfrentan a una pregunta fundamental: ¿desarrollar un modelo a medida o adquirir licencias de modelos ya existentes?
El acceso a la API para modelos como GPT-4 comienza en $0,60 por millón de tokens de entrada para algunos proveedores, y el precio de salida varía según el modelo. Gemini Flash-Lite ofrece tarifas aún más bajas, de $0,075 por millón de tokens de entrada y $0,30 por millón de tokens de salida, según datos de precios de 2025.
La tarificación basada en el uso parece económica al principio. Sin embargo, los costes aumentan linealmente con el tráfico. Las aplicaciones que procesan 1,2 millones de mensajes diarios a razón de 150 tokens cada uno pueden generar facturas mensuales de API de entre 15 000 y 60 000 tokens, dependiendo de los niveles de precios y las proporciones de entrada/salida.
Con grandes volúmenes de uso, la infraestructura propia resulta más económica. Un análisis del punto de equilibrio de un caso documentado mostró que los costos de la API alcanzaban los $60 000 mensuales y tendían a superar los $500 000 anuales, una cifra que justifica una importante inversión inicial en capacitación.
La decisión depende de los patrones de uso, la personalización requerida y el posicionamiento competitivo. Las aplicaciones con un uso predecible y de alto volumen, requisitos de dominio especializados o necesidad de transparencia del modelo tienden a optar por el entrenamiento personalizado. Los proyectos con uso variable, capacidades generales o plazos de desarrollo ajustados se inclinan por el acceso a la API.
Tendencias de costos futuras
Los costes de formación seguirán evolucionando a medida que cambien la tecnología y la dinámica del mercado.
Las mejoras en la eficiencia del hardware reducen progresivamente el coste por cálculo. Las generaciones de arquitectura de NVIDIA muestran un aumento constante del rendimiento por vatio. La entrada de competidores en el mercado de aceleradores impulsará una mayor optimización y competencia de precios.
Los avances algorítmicos permiten obtener mayor capacidad con menor capacidad de procesamiento. Técnicas como las arquitecturas de mezcla de expertos, los mecanismos de atención dispersa y los algoritmos de optimización mejorados reducen el presupuesto computacional necesario para alcanzar objetivos de rendimiento específicos.
Es probable que los costos de la energía aumenten a medida que la infraestructura de IA ejerza mayor presión sobre las redes eléctricas. Conforme las exigencias de capacitación se incrementen y la infraestructura eléctrica se vuelva cada vez más crítica, las organizaciones con acceso a energía renovable de bajo costo obtendrán ventajas competitivas.
Las presiones regulatorias pueden afectar la economía de la formación. Los gobiernos preocupados por el consumo de energía, la privacidad de los datos o la seguridad de la IA podrían implementar requisitos que aumenten los costos de cumplimiento o restrinjan ciertas prácticas.
Las tendencias de democratización podrían reducir las barreras de entrada. Los modelos de código abierto, las plataformas informáticas compartidas y la mejora de la eficiencia en la formación podrían poner el desarrollo de modelos a gran escala al alcance de organizaciones medianas, en lugar de estar reservado exclusivamente a los gigantes tecnológicos.
Preguntas frecuentes
¿Cuánto cuesta entrenar a GPT-4?
Según The Wall Street Journal y el Informe del Índice de IA de Stanford de 2025, el entrenamiento de GPT-4 tuvo un costo estimado de entre 1.047.000 y 100 millones de dólares. Esta cifra incluye la infraestructura de GPU, el consumo de electricidad, la preparación de datos y los recursos de ingeniería durante el período de entrenamiento de varios meses.
¿Por qué la formación de LLM es tan cara?
Los costos de entrenamiento se derivan principalmente de la infraestructura de computación GPU, que representa entre 60 y 701 TP3T de gastos. Un modelo de vanguardia podría requerir entre 10 000 y 25 000 GPU de alto rendimiento funcionando continuamente durante semanas o meses. Los costos adicionales incluyen el consumo de electricidad (gigavatios-hora de energía), el personal de ingeniería, la adquisición y preparación de datos, y las iteraciones experimentales para optimizar los hiperparámetros.
¿Puede la optimización reducir los costes de formación de los másteres en Derecho (LLM)?
El ajuste fino de modelos existentes suele costar entre 60 y 90 millones de TP3T menos que el entrenamiento desde cero. Adaptar un modelo preentrenado como Llama 2 o GPT-3.5 para tareas específicas podría costar entre 5000 y 50 000 TP4T, en comparación con los 78 a 192 millones de TP4T que cuesta entrenar modelos de vanguardia. Técnicas como LoRA permiten el ajuste fino en GPU individuales, completándose en horas en lugar de semanas.
¿Cuál es la diferencia en los costos de capacitación entre la nube y la capacitación en las instalaciones del cliente?
La infraestructura en la nube cobra entre $2 y 4 por hora de GPU H100, sin inversión inicial, pero con tarifas de alquiler recurrentes. La compra de hardware H100 cuesta entre $30 000 y $40 000 por unidad por adelantado, pero elimina las tarifas de alquiler. El punto de equilibrio se alcanza entre las 10 000 y las 16 000 horas de uso. Las organizaciones que planean múltiples sesiones de capacitación suelen encontrar que la propiedad es más económica a pesar de los mayores requisitos de capital inicial.
¿Cuánta electricidad consume la formación de un máster en Derecho (LLM)?
Los modelos de vanguardia consumen gigavatios-hora de electricidad, suficiente para abastecer miles de hogares durante meses. Entrenar un solo modelo de IA de vanguardia pronto requerirá gigavatios de capacidad energética. Los costos de electricidad representan entre 15 y 201 millones de dólares del total de gastos de entrenamiento para modelos grandes, debido tanto a las facturas directas de servicios públicos como a la infraestructura de apoyo.
¿Cuál es la forma más económica de entrenar un modelo de lenguaje personalizado?
El ajuste fino de un modelo de código abierto existente mediante técnicas eficientes como LoRA ofrece el punto de partida más económico. Un estudio documentó un experimento de entrenamiento de LoRA que se completó en 7 horas en una sola GPU NVIDIA T4 con 16 GB de VRAM, hardware disponible en plataformas como Google Colab. Para aplicaciones donde el ajuste fino proporciona capacidades suficientes, este enfoque reduce los costos entre 1000 y 10 000 veces en comparación con el entrenamiento desde cero.
¿Siguen aumentando los costes de formación?
Los costos absolutos de entrenamiento para los modelos de vanguardia siguen aumentando a medida que crece el número de parámetros y el tamaño de los conjuntos de datos. El Informe del Índice de IA de Stanford 2025 documentó un incremento de 287 000 veces desde 2017 hasta la actualidad. Sin embargo, el costo por unidad de capacidad del modelo está disminuyendo debido a las mejoras de hardware y los avances algorítmicos. Las ganancias en eficiencia compensan parcialmente el aumento de escala, aunque los presupuestos totales para los modelos de última generación siguen en aumento.
Comprender la inversión
Los costes de formación en Derecho (LLM) reflejan la intensidad computacional necesaria para crear sistemas que procesen y generen lenguaje humano a gran escala. Esos precios de ocho y nueve cifras no son arbitrarios: representan miles de procesadores especializados que funcionan continuamente, consumiendo megavatios de energía, coordinados por equipos de ingenieros especializados que trabajan con conjuntos de datos masivos.
La economía seguirá evolucionando. El hardware será más eficiente. Los algoritmos mejorarán. La competencia impulsará la innovación. Pero la disyuntiva fundamental persiste: la capacidad requiere capacidad de procesamiento, y el procesamiento cuesta dinero.
Las organizaciones que evalúan la posibilidad de desarrollar modelos personalizados necesitan proyecciones de costos realistas, no estimaciones optimistas. Los equipos que buscan financiación deben tener en cuenta todas las categorías de gastos, no solo los gastos obvios de alquiler de GPU. Además, los observadores del sector que siguen de cerca el desarrollo de la IA deben comprender que los costos de capacitación sirven como un indicador útil de la escala y la capacidad del modelo.
El camino a seguir depende de los requisitos específicos. Las aplicaciones de alto volumen con necesidades especializadas suelen justificar la formación a medida, a pesar de la considerable inversión inicial. Para proyectos de menor volumen o de propósito general, el acceso a la API resulta más económico. Y muchos casos de uso se sitúan en un punto intermedio, donde la optimización proporciona el equilibrio adecuado entre personalización y rentabilidad.
¿Listo para avanzar con el desarrollo del modelo? Comience calculando sus patrones de uso específicos, identificando qué funcionalidades requieren capacitación personalizada y cuáles requieren ajuste fino, y realizando un análisis de punto de equilibrio para la escala de implementación prevista. Los datos le ayudarán a determinar qué camino es el más adecuado para su situación particular.