Resumen rápido: El PLN (Procesamiento del Lenguaje Natural) utiliza métodos estadísticos y basados en reglas para tareas lingüísticas específicas a un menor coste, mientras que los LLM (Modelos de Lenguaje a Gran Escala) son redes neuronales entrenadas con conjuntos de datos masivos que destacan en tareas generativas, pero cuyo coste es significativamente mayor. La combinación de ambos enfoques —el PLN para la clasificación y el enrutamiento, y los LLM para el razonamiento complejo— puede reducir los costes de inferencia entre un 40 % y un 90 % manteniendo la calidad.
A todos les encantan los modelos grandes hasta que llega la factura. Lo que parece un coste de céntimos por pedido durante las pruebas se convierte en miles al mes en producción.
¿La realidad? La mayoría de las cargas de trabajo de IA no necesitan razonamiento a nivel de GPT para cada consulta. Pero sin una arquitectura de costos adecuada, cada solicitud termina recurriendo al modelo más costoso.
Sin embargo, la clave está en que el PLN y los modelos de lenguaje natural (MLN) no son tecnologías que compitan entre sí. Son herramientas complementarias que, al combinarse estratégicamente, ofrecen tanto rendimiento como rentabilidad. Saber cuándo usar cada enfoque no se trata solo de ahorrar dinero, sino de construir sistemas de IA sostenibles y escalables.
Comprender la diferencia de costos entre PNL y LLM
El procesamiento tradicional del lenguaje natural y los modelos de lenguaje a gran escala operan con sistemas económicos fundamentalmente diferentes. Esta distinción es importante porque repercute directamente en los presupuestos de producción.
Los sistemas de PLN suelen implicar costes iniciales de desarrollo: creación de conjuntos de reglas, entrenamiento de modelos especializados más pequeños y desarrollo de pipelines de clasificación. Una vez implementados, los costes de inferencia son mínimos. El procesamiento de texto mediante expresiones regulares, el reconocimiento de entidades nombradas o modelos de clasificación pequeños requiere una capacidad de procesamiento insignificante.
Los modelos LLM invierten completamente este modelo. Los costos de desarrollo son menores porque los modelos base vienen preentrenados. Sin embargo, los costos de inferencia se convierten en el gasto principal. Cada token procesado, tanto de entrada como de salida, tiene un costo.
La realidad de la economía de tokens
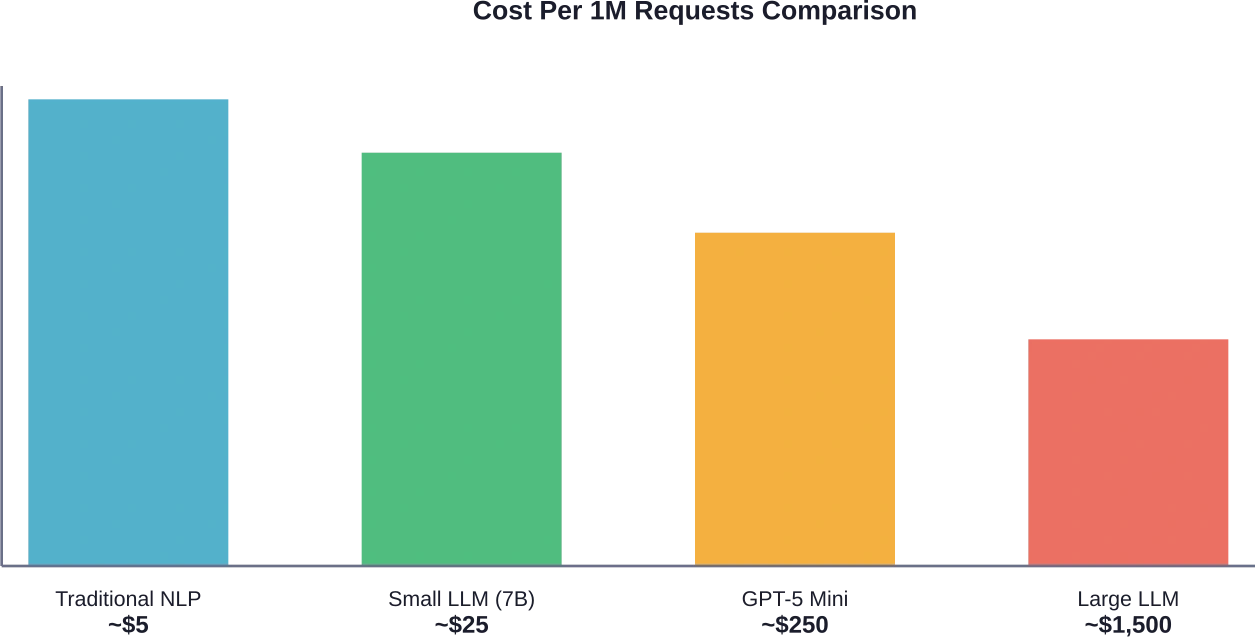
El modelo de precios basado en tokens implica que los costos aumentan linealmente con el uso. Según datos de Hugging Face Inference Providers, las tarifas de mercado actuales para modelos competitivos varían significativamente:
| Modelo | Proveedor | Entrada (por cada millón de tokens) | Salida (por cada millón de tokens) | Ventana de contexto |
|---|---|---|---|---|
| GPT-5 Mini | Abierto AI | $0.25 | $2.00 | ~400 mil |
| Qwen3.5-35B-A3B | Novita | $0.25 | $2.00 | 262,144 |
| Qwen3.5-27B | Novita | $0.30 | $2.40 | 262,144 |
| Qwen3.5-397B-A17B | Juntos | $0.60 | $3.60 | 262,144 |
Los tokens de salida cuestan sistemáticamente entre 8 y 10 veces más que los tokens de entrada. Esta asimetría penaliza las respuestas extensas. Un chatbot que genera respuestas de 500 palabras consume el presupuesto exponencialmente más rápido que uno optimizado para respuestas concisas.
En serio: ese $0,25 por millón de tokens de entrada suena barato hasta que el volumen de producción aumenta. Procesar 100 millones de tokens al mes —algo fácilmente alcanzable para una aplicación de tamaño medio— supone $25 000 solo para las entradas. Si añadimos las salidas, el gasto real se multiplica.
Costos de infraestructura más allá de las llamadas a la API
El precio de las GPU en la nube añade otra capa de complejidad. Según un análisis de Hugging Face sobre la economía de la computación en la nube, los costes de infraestructura predominan en los modelos de autoalojamiento.
La inversión de capital en capacidad de GPU representa la principal barrera. La infraestructura física importa menos que el gasto inicial en hardware. Para las organizaciones que realizan su propia inferencia, esto cambia el modelo de costos de pago por token a planificación de capacidad fija.
Pero un momento. Las instancias en la nube aún se cobran por hora. Según el tamaño del modelo y los patrones de implementación de hardware documentados en fuentes de la industria, surgen limitaciones prácticas en torno a:
| Tamaño del modelo | Memoria RAM virtual (FP16) | VRAM (4 bits) | Tipo de instancia en la nube | Casos de uso típicos |
|---|---|---|---|---|
| 1-3B | 4-6 GB | ~2 GB | AWS g4dn.xlarge | Chat básico, clasificación, autocompletar |
| 7-8B | 14-16 GB | ~6-8 GB | AWS g5.xlarge | Inferencia de propósito general |
Los componentes tradicionales de PLN se ejecutan sin problemas en instancias de CPU. No se requiere hardware especializado. La diferencia de costos se vuelve notable a gran escala.
Dónde la PNL tradicional ofrece ventajas en cuanto a costes
Ciertas tareas de procesamiento del lenguaje no se benefician de las capacidades de LLM. Para estas cargas de trabajo, los métodos tradicionales de PLN ofrecen resultados equivalentes o superiores a una fracción del costo.
Tareas de clasificación y enrutamiento
Clasificación de intenciones, análisis de sentimientos, categorización de temas: estos son problemas resueltos. Pequeños modelos especializados, entrenados para tareas de clasificación específicas, alcanzan una precisión de más del 951% (TP3T+) procesando miles de solicitudes por segundo con un hardware mínimo.
Un clasificador basado en BERT, optimizado para el enrutamiento de atención al cliente, podría utilizar 110 millones de parámetros. Compárese esto con los miles de millones de parámetros de GPT-5 Mini. El modelo de clasificación realiza inferencias en cuestión de milisegundos en la CPU. Una llamada a LLM tarda cientos de milisegundos y cuesta varios órdenes de magnitud más por solicitud.
Los debates comunitarios ponen de relieve ejemplos prácticos. Según un estudio de caso de Lumitech, al analizar el uso de su modelo LLM, descubrieron que 80% de las consultas eran directas. Cada solicitud accedía innecesariamente a su modelo más costoso.
Al implementar primero una capa de clasificación de PLN, asignaron las tareas sencillas a modelos ligeros y reservaron los modelos de lenguaje natural (MLN) para el razonamiento complejo. El resultado: una reducción de costos de 10 veces (de $200 a $20 por mes) sin ninguna degradación de la calidad.
Coincidencia de patrones y extracción de entidades
Los patrones de expresiones regulares y los sistemas de extracción basados en reglas prácticamente no tienen costo operativo. Cuando los requisitos están bien definidos, las reglas funcionan a la perfección.
La validación de correos electrónicos, el formato de números de teléfono, el análisis de fechas y la normalización de direcciones no requieren redes neuronales. Los sistemas basados en reglas se ejecutan en microsegundos sin llamadas a la API ni inferencia de modelos.
El reconocimiento de entidades nombradas sigue principios económicos similares. Los modelos estadísticos de SpaCy extraen entidades con gran precisión en varios idiomas. Una vez cargados en memoria, el procesamiento es prácticamente instantáneo. Sin costes por solicitud. Sin conteo de tokens.
Tareas de lenguaje específicas del dominio
Los modelos de PLN especializados, entrenados para dominios específicos, suelen superar a los modelos de lenguaje natural de propósito general, a la vez que resultan más económicos.
El procesamiento de textos médicos se beneficia de BioBERT o modelos similares adaptados al dominio. El análisis de documentos legales funciona mejor con flujos de trabajo de PLN específicos para el ámbito jurídico. El análisis de sentimiento financiero logra mayor precisión con FinBERT que con modelos de lenguaje natural genéricos.
Estos modelos tienen entre 100 y 400 millones de parámetros. El autoalojamiento resulta económicamente viable. Los costos de entrenamiento son gastos únicos. Los costos de inferencia se aproximan a cero a gran escala.
Cuando los costos del LLM tienen sentido
Los sistemas LLM justifican su precio para casos de uso específicos. La clave está en adecuar la capacidad a los requisitos.
Tareas generativas y creativas
Generación de contenido, escritura creativa, síntesis de código, resumen: estos son terrenos propios del LLM. El PLN tradicional no puede generar contenido extenso y coherente. Los sistemas basados en reglas no pueden escribir textos de marketing que suenen humanos.
Para cargas de trabajo generativas, los costos de LLM se vuelven inevitables. La pregunta ya no es si usar LLM, sino qué nivel de modelo ofrece la mejor relación calidad-precio.
OpenAI informa que GPT-5 Mini logra 91,11 TP3T en el concurso matemático AIME y 87,81 TP3T en una medida interna de "inteligencia". Su rendimiento rivaliza con el de modelos mucho más grandes. Con 1 TP4T0,25 por millón de tokens de entrada, ofrece capacidades de vanguardia a un precio accesible.
Razonamiento complejo y problemas de varios pasos
El razonamiento en cadena, la respuesta a preguntas de múltiples pasos y la resolución de problemas matemáticos presentan dificultades para los modelos más pequeños. Los modelos LLM más grandes, con miles de millones de parámetros, muestran capacidades de razonamiento emergentes que justifican sus mayores costos.
Pero aquí es donde la cosa se pone interesante. No todas las tareas complejas requieren el modelo más grande. Las investigaciones sobre la optimización del uso de LLM muestran métodos que reducen los costos entre 40 y 901 TP3T, al tiempo que mejoran la calidad entre 4 y 71 TP3T.
La metodología implica una evaluación exhaustiva en diferentes niveles de modelos. Los resultados demuestran de forma consistente que la selección del modelo adecuado para cada tarea mantiene la calidad a la vez que controla los gastos.
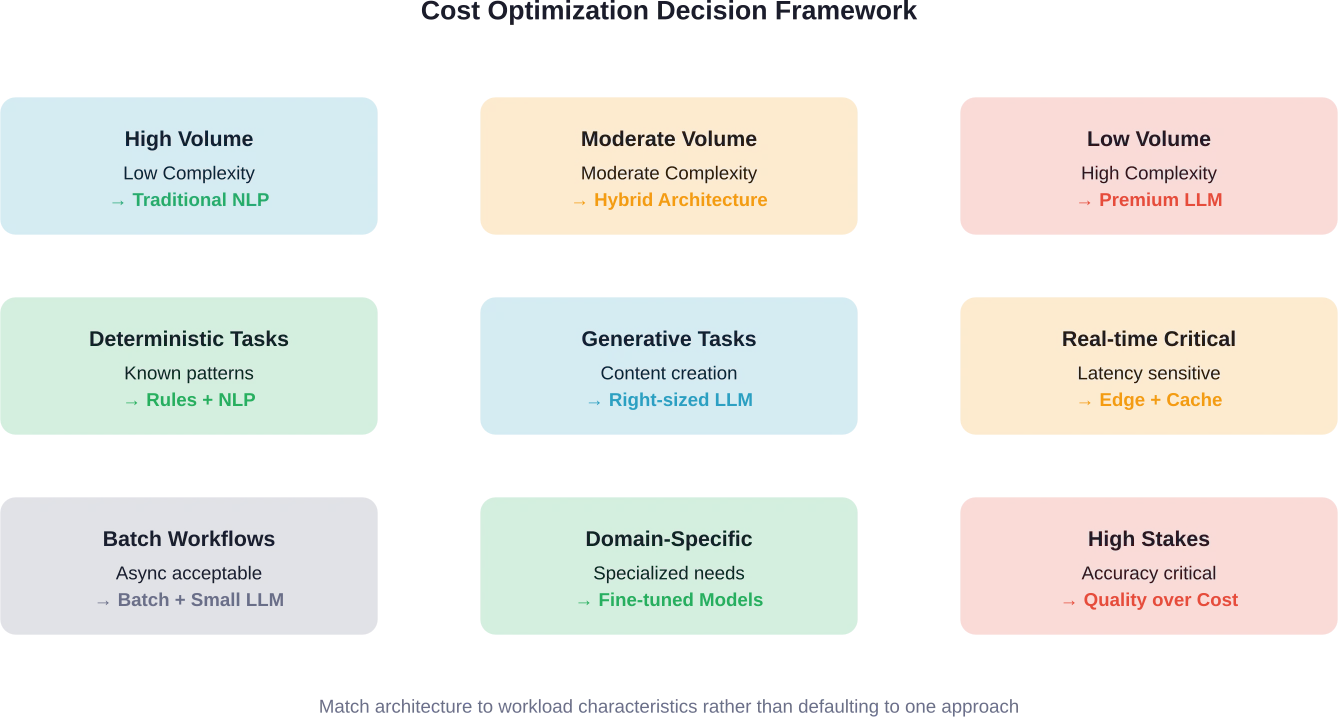
Flujos de trabajo de bajo volumen y alto valor
Cuando el volumen de solicitudes es bajo y el valor de la decisión es alto, los costes de LLM se vuelven insignificantes en comparación con el impacto en el negocio.
Una herramienta de investigación jurídica que procesa 100 consultas diarias se beneficia de las funcionalidades de LLM. Incluso con precios premium, los costos mensuales podrían ascender a entre 150 y 200 dólares. El valor de un análisis jurídico preciso supera con creces ese gasto.
Compárese esto con un chatbot que gestiona 100 000 interacciones diarias. Mismo modelo, diferente volumen, perfil de costes totalmente distinto. Los escenarios de alto volumen requieren optimización. Los flujos de trabajo de bajo volumen pueden permitirse modelos premium.
El enfoque de arquitectura híbrida
Los sistemas de producción más rentables combinan estratégicamente el procesamiento del lenguaje natural (PLN) y los modelos de lenguaje natural (MLN). No se trata de elegir entre uno u otro.
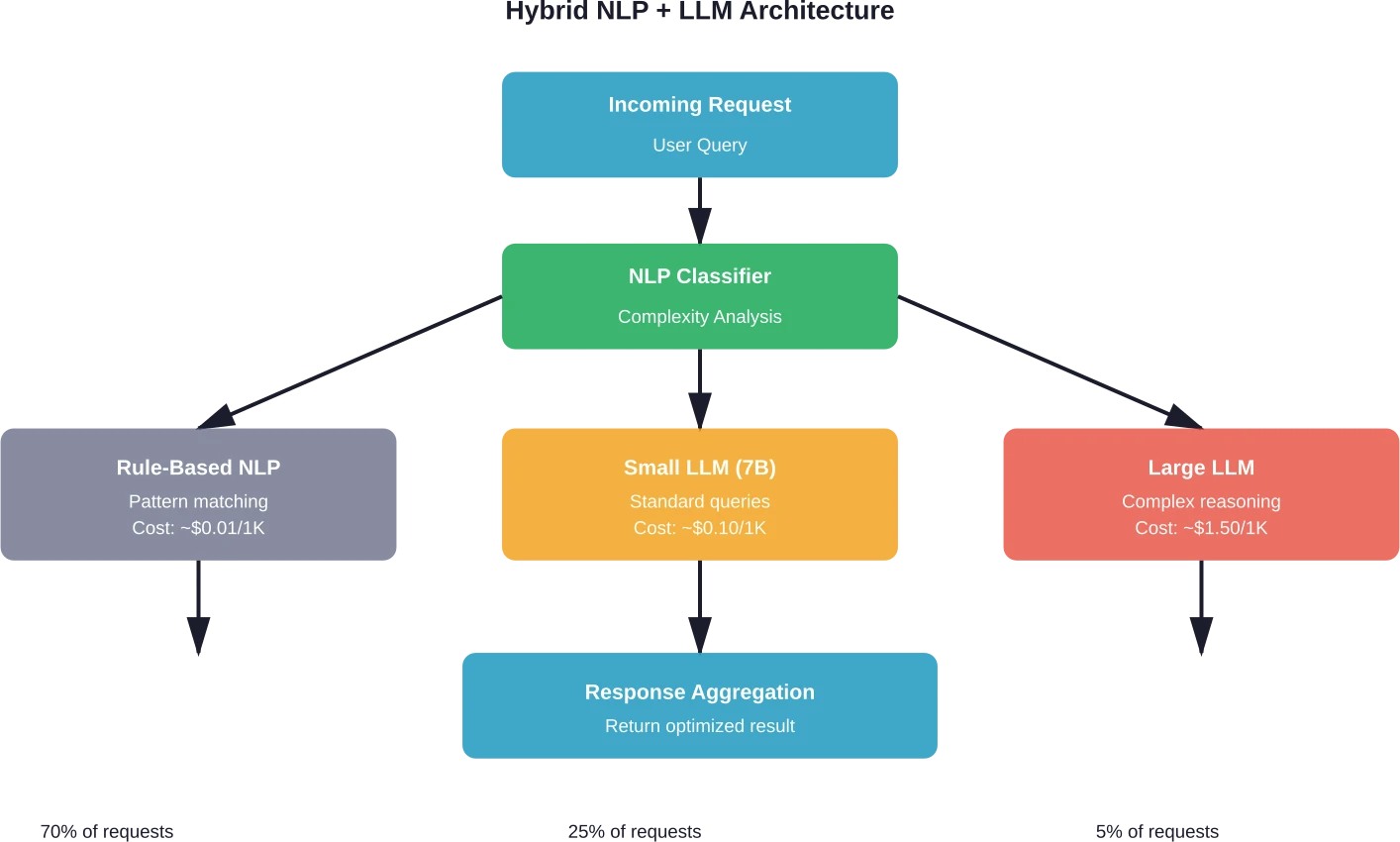
Enrutamiento inteligente de solicitudes
Las capas de clasificación determinan la complejidad antes de dirigir las solicitudes a los modelos apropiados. Las tareas sencillas se procesan en modelos rápidos y económicos. El razonamiento complejo se dirige a modelos LLM más capaces.
La implementación requiere varios componentes. En primer lugar, un clasificador ligero analiza las solicitudes entrantes. Este podría ser un modelo BERT ajustado o incluso heurísticas más simples basadas en la longitud de la consulta, las palabras clave y la estructura.
El clasificador categoriza las solicitudes en niveles: consultas fácticas simples, tareas sencillas, complejidad moderada y razonamiento de alta complejidad. Cada nivel se corresponde con una ruta de procesamiento diferente.
Los equipos que implementan enrutamiento inteligente reportan reducciones de costos de 30 a 50% sin una degradación de calidad apreciable cuando las estrategias de enrutamiento alinean los modelos con los requisitos de las tareas de manera efectiva. La clave reside en una evaluación sistemática que valide la lógica de enrutamiento y mantenga los estándares de calidad en todos los niveles del modelo.
Almacenamiento en caché y optimización de la respuesta
El almacenamiento en caché semántico evita las llamadas LLM redundantes. Cuando los usuarios hacen preguntas similares, las respuestas almacenadas en caché se proporcionan de inmediato sin costes de inferencia.
El almacenamiento en caché tradicional coincide con consultas exactas. El almacenamiento en caché semántico utiliza incrustaciones para identificar preguntas similares con diferente redacción. Una búsqueda de similitud vectorial determina si las respuestas almacenadas en caché satisfacen nuevas consultas.
Los modelos de incrustación son económicos de ejecutar. Incluso con el paso adicional de incrustación, servir respuestas almacenadas en caché reduce drásticamente los costos en comparación con la inferencia LLM completa.
La optimización de la respuesta se centra en reducir los tokens de salida. La ingeniería de mensajes que fomenta respuestas concisas reduce directamente los costos. Dado que los tokens de salida cuestan entre 8 y 10 veces más que los tokens de entrada, las respuestas extensas aumentan desproporcionadamente las facturas.
Mejora progresiva
Empiece con el modelo viable más pequeño. Recurra a modelos más grandes solo cuando sea necesario.
Un sistema multiagente podría intentar primero las tareas con un modelo de 7 mil millones de parámetros. Si los índices de confianza caen por debajo del umbral, el sistema vuelve a intentarlo automáticamente con un modelo más avanzado. La mayoría de las solicitudes se completan con éxito en el primer intento. Solo los casos difíciles generan costes más elevados.
Este enfoque requiere calibración de confianza. Los modelos deben estimar con precisión su propia incertidumbre. Los modelos bien calibrados saben cuándo es probable que fallen y pueden solicitar una escalada automáticamente.
Estrategias de optimización de costes en el mundo real
Los sistemas de producción emplean múltiples tácticas simultáneamente. Ninguna optimización por sí sola resuelve el problema de los costos. La combinación de ambas es la que ofrece resultados.
Ingeniería rápida para la eficiencia
La longitud de la solicitud influye directamente en los costes. Cada token de la solicitud se procesa y se cobra.
El exceso de contexto, las instrucciones prolijas y los ejemplos redundantes aumentan innecesariamente el número de entradas. Las indicaciones simplificadas que transmiten los requisitos de forma concisa reducen los costes sin sacrificar la calidad.
Los ejemplos con pocos disparos demuestran el comportamiento deseado, pero consumen tokens. Probar con diferentes cantidades de ejemplos permite identificar el equilibrio óptimo. A veces, tres ejemplos logran la misma precisión que diez, utilizando 70% tokens menos.
Ajuste correcto del modelo
Lo más grande no siempre es mejor. La selección del modelo adecuado para cada tarea equilibra la capacidad y el coste.
Las pruebas de rendimiento como MMLU, HumanEval y las evaluaciones específicas de dominio revelan qué modelos funcionan adecuadamente para tareas concretas. Un modelo con una puntuación de 85% podría costar una décima parte de lo que cuesta un modelo con una puntuación de 90%. La diferencia de precisión de 5 puntos podría no justificar un coste diez veces mayor para ciertas aplicaciones.
Las exhaustivas pruebas comparativas y los análisis indican que los modelos más pequeños suelen alcanzar capacidades similares a las de modelos mucho más grandes para tareas específicas. DeepSeek V3.2-Exp iguala e incluso supera ligeramente a su predecesor V3.1 en pruebas de rendimiento públicas, a la vez que ofrece una mayor rentabilidad gracias a mejoras arquitectónicas.
Procesamiento por lotes y flujos de trabajo asíncronos
La inferencia en tiempo real cuesta más que el procesamiento por lotes. Cuando no se requiere inmediatez, el procesamiento por lotes reduce los gastos.
La elaboración de resúmenes de documentos, la moderación de contenido y la extracción de datos son tareas que suelen tolerar cierta latencia. El procesamiento por lotes permite una mejor utilización de los recursos y precios negociados por volumen con los proveedores.
Los flujos de trabajo asíncronos desacoplan el envío de solicitudes de la entrega de resultados. Los usuarios envían tareas, continúan con otras actividades y reciben los resultados cuando finaliza el procesamiento. Esta flexibilidad permite optimizar los costos, algo que las limitaciones de tiempo real impiden.
Comparación de los precios actuales del mercado
Los precios de los proveedores varían considerablemente. Comparar precios es importante.
Según datos de principios de 2026, los precios competitivos se agrupan en torno a varios niveles. Los modelos básicos como GPT-5 Mini y Qwen3.5-35B-A3B comienzan en $0.25 por millón de tokens de entrada y $2.00 por millón de tokens de salida.
Los modelos de gama media tienen precios de entrada que van desde $0.30 hasta $0.60. Los modelos premium de gran tamaño superan los $0.60 en cuanto a entradas.
El tamaño de las ventanas de contexto afecta a los cálculos de valores. Los modelos que ofrecen ventanas de contexto de 256 KB a 400 KB permiten patrones arquitectónicos diferentes a los de aquellos limitados a ventanas de 32 KB a 128 KB. Un contexto más amplio reduce la necesidad de realizar múltiples solicitudes al procesar documentos extensos.
| Nivel de capacidad | Precio de entrada típico | Precio de producción típico | Mejor para |
|---|---|---|---|
| Entrada (7-8B) | $0.10-0.25 / 1M | $0.80-2.00 / 1M | Clasificación, chat sencillo, resumen básico |
| Media (30-40B) | $0.25-0.60 / 1M | $2.00-3.60 / 1M | Tareas de propósito general, razonamiento moderado. |
| Premium (100B+) | $0.60-2.00 / 1M | $3.60-10.00 / 1M | Razonamiento complejo, dominios especializados |
La latencia y el rendimiento varían independientemente del precio. Los modelos más económicos no son necesariamente más lentos. La infraestructura y la optimización del proveedor influyen en el rendimiento tanto como el tamaño del modelo.
Costos ocultos a considerar
El precio de la API no es el único factor de coste. El tiempo de desarrollo, la complejidad de la depuración y los gastos generales de mantenimiento también contribuyen al coste total de propiedad.
El PLN tradicional requiere un mayor desarrollo inicial. La creación de sistemas de clasificación, el ajuste de modelos y el mantenimiento de conjuntos de reglas son tareas que exigen tiempo de ingeniería especializada.
Los modelos de aprendizaje automático reducen la fricción en el desarrollo. La ingeniería ágil reemplaza el entrenamiento del modelo. Los ciclos de iteración se acortan. Para equipos con experiencia limitada en aprendizaje automático, la facilidad de uso de los modelos de aprendizaje automático compensa los mayores costos de inferencia.
Pero a gran escala, los costos de inferencia predominan. Un sistema que procesa millones de solicitudes diarias gastará más en tokens LLM en un año que en el desarrollo inicial de PLN. La situación cambia a medida que aumenta el volumen.
Consideraciones sobre costos energéticos y ambientales
Los costos financieros son proporcionales al consumo de energía. Un estudio de arxiv.org sobre los costos energéticos de la inferencia LLM compara la relación entre el cálculo y el consumo de energía.
La inferencia de modelos grandes requiere una cantidad considerable de energía. Si bien las cifras exactas dependen del hardware y la optimización, la tendencia es clara: los modelos más grandes consumen más energía por token.
Los modelos tradicionales de PLN procesan las solicitudes con un consumo mínimo de energía. La inferencia basada en CPU consume mucha menos energía que la inferencia LLM acelerada por GPU.
Las organizaciones comprometidas con la sostenibilidad se enfrentan a una doble presión: la optimización financiera y la reducción de su huella de carbono. Afortunadamente, estos objetivos coinciden. Las estrategias que reducen los costes de gestión de activos suelen reducir simultáneamente el consumo energético.
El enrutamiento eficiente que dirige las consultas sencillas a modelos ligeros reduce tanto los gastos como las emisiones. Ajustar el tamaño de los modelos a los requisitos de las tareas ofrece beneficios medioambientales además de ahorros de costes.
Construyendo una arquitectura que tenga en cuenta los costos.
Los sistemas de IA sostenibles supervisan y optimizan los costes de forma continua. Una optimización puntual no es suficiente. Los patrones de uso cambian. Los precios de los modelos varían. Los requisitos evolucionan.
Seguimiento y atribución de costos
El seguimiento de los gastos por función, nivel de usuario o flujo de trabajo revela oportunidades de optimización. Las métricas agregadas ocultan qué componentes impulsan el gasto.
El registro detallado captura los metadatos de las solicitudes: modelo utilizado, recuento de tokens, latencia, coste y contexto empresarial. Estos datos permiten realizar análisis que identifican patrones costosos.
Algunas funcionalidades podrían generar costos desproporcionados en relación con su valor comercial. Un análisis de uso podría revelar que 5% de usuarios consumen 60% del presupuesto de LLM mediante patrones de interacción ineficientes. La optimización específica o el rediseño de funcionalidades solucionan estos problemas.
Marcos de prueba y evaluación
La optimización de costes requiere medición. Las métricas de calidad validan que las alternativas más económicas mantienen un rendimiento aceptable.
Los marcos de evaluación comparan los resultados de los modelos en diferentes niveles. La evaluación humana o la puntuación de calidad automatizada determinan si los modelos más pequeños alcanzan la precisión suficiente para tareas específicas.
Las pruebas A/B en producción miden la satisfacción del usuario con diferentes modelos. Si los usuarios no pueden distinguir entre las respuestas de un modelo de 7 mil millones y uno de 70 mil millones para ciertas consultas, el modelo más caro no aporta valor.
Bucles de optimización continua
Las arquitecturas estáticas se vuelven subóptimas a medida que los modelos mejoran y los precios cambian. La evaluación periódica permite identificar mejores alternativas.
Se lanzan nuevos modelos con frecuencia. Un modelo que salga el mes que viene podría ofrecer un mejor rendimiento por dólar que las opciones actuales. La evaluación comparativa continua con los nuevos lanzamientos garantiza que los sistemas aprovechen al máximo la mejor relación calidad-precio.
Los ajustes de precios se producen sin previo aviso. Monitorear los cambios de tarifas de múltiples proveedores permite cambiar de proveedor de forma oportuna cuando la competencia ofrece mejores condiciones económicas.
Tendencias de costos futuras
La evolución de los precios es importante para la planificación a largo plazo. Varios factores influyen en los costes futuros.
La eficiencia de los modelos sigue mejorando. Las innovaciones arquitectónicas ofrecen un mejor rendimiento por parámetro. Un estudio de arxiv.org sobre la eficiencia de los modelos de lenguaje a gran escala documenta avances algorítmicos que reducen los requisitos computacionales.
Los modelos rediseñados alcanzan capacidades equivalentes con menos parámetros mediante la optimización arquitectónica. A medida que estas técnicas maduran, los costos por unidad de capacidad disminuyen.
La competencia entre proveedores ejerce presión a la baja sobre los precios. A medida que más participantes ingresan al mercado, la reducción de tarifas se acelera. La introducción de GPT-5 Mini, Gemini 2.5 Flash y Claude 3.5 Haiku creó una nueva gama de modelos capaces a precios significativamente más bajos que las generaciones anteriores.
Las mejoras en el hardware continúan. Las nuevas arquitecturas de GPU ofrecen un mejor rendimiento en la inferencia. A medida que aumenta la eficiencia del hardware, los proveedores pueden ofrecer precios más bajos manteniendo sus márgenes de beneficio.
Pero la demanda crece simultáneamente. A medida que más aplicaciones integran LLM, el gasto total aumenta incluso si los costos por token disminuyen. Las organizaciones que no optimizan activamente ven cómo aumentan sus gastos a pesar de la caída de los precios unitarios.
Hoja de ruta de implementación
La transición de una costosa arquitectura basada exclusivamente en LLM a sistemas híbridos optimizados en costes requiere planificación.
Fase 1: Medición y análisis
Instrumentar los sistemas existentes para capturar métricas de uso detalladas. Sin datos, la optimización es cuestión de adivinar.
Registra cada solicitud LLM con metadatos: marca de tiempo, usuario, función, tokens de solicitud, tokens de finalización, modelo utilizado, latencia y costo. Agrega estos datos para su análisis.
Identifica patrones. ¿Qué funciones generan la mayor cantidad de solicitudes? ¿Qué usuarios consumen la mayor cantidad de tokens? ¿Qué patrones de mensajes aparecen con frecuencia?
Calcula el coste por función, por segmento de usuario y por resultado de negocio. Esto revela dónde las optimizaciones generan mayores beneficios.
Fase 2: Victorias rápidas
Las soluciones más sencillas generan ahorros inmediatos a la vez que impulsan iniciativas de mayor envergadura.
Implementa la optimización de indicaciones. Elimina el contexto innecesario, suprime las instrucciones extensas y consolida los ejemplos. Esto requiere un mínimo esfuerzo de desarrollo, pero reduce inmediatamente el consumo de tokens.
Agregue almacenamiento en caché semántico. Existen bibliotecas para la mayoría de los lenguajes que facilitan la implementación. El almacenamiento en caché puede eliminar entre 20 y 401 TP3T solicitudes con cambios mínimos en el código.
Optimizar el tamaño de los casos más evidentes. Las tareas que actualmente utilizan modelos premium, pero que obtienen resultados equivalentes con modelos de gama media, representan claras oportunidades de optimización.
Fase 3: Arquitectura estratégica
Las iniciativas de mayor envergadura requieren más planificación, pero generan ahorros sustanciales y continuos.
Construye la capa de clasificación y enrutamiento. Esta se convierte en la infraestructura que otras optimizaciones aprovechan. Empieza de forma sencilla: clasifica las solicitudes en dos o tres niveles inicialmente.
Implemente modelos de PLN específicos para cargas de trabajo deterministas de alto volumen. Estos reemplazan por completo las llamadas a LLM para casos de uso específicos.
Implementa la mejora progresiva para consultas complejas. Prueba primero con modelos más económicos y solo recurre a ellos cuando sea necesario.
Fase 4: Mejora continua
La optimización no es un proyecto con fecha de finalización. Es una práctica continua.
Programe revisiones trimestrales del rendimiento y los precios del modelo. Constantemente surgen nuevas opciones. La evaluación periódica garantiza que los sistemas evolucionen a medida que cambia el entorno.
Supervise las métricas de costos junto con las métricas de negocio. Considere la eficiencia de costos como un indicador clave de rendimiento, junto con la calidad, la latencia y la satisfacción del usuario.
Experimenta con nuevos enfoques. Destina un presupuesto para probar arquitecturas alternativas, nuevos modelos y diferentes proveedores. Es posible que aún no exista la mejor optimización para el próximo trimestre.

Reduzca sus costos de IA antes de que se salgan de control.
La elección entre sistemas de procesamiento del lenguaje natural (PLN) y grandes modelos de lenguaje puede afectar drásticamente el gasto en IA a largo plazo. IA superior Colabora con empresas que necesitan sistemas de IA diseñados para la eficiencia en el mundo real. Su equipo crea y perfecciona modelos de lógica de negocio (LLM), desarrolla modelos específicos para cada tarea y optimiza los flujos de trabajo impulsados por IA para que las empresas puedan reducir el uso de recursos informáticos sin comprometer el rendimiento.
Si desea reducir los costos de la IA en lugar de simplemente escalarlos, hable con IA superior y obtener orientación práctica sobre cómo construir sistemas de IA más eficientes.
Errores comunes que se deben evitar
La optimización de costes puede resultar contraproducente si se realiza sin cuidado. Varios errores se repiten con frecuencia.
Optimización prematura
Los proyectos en fase inicial se benefician de la rápida iteración que permiten los modelos LLM. Dedicar semanas a crear pipelines de PLN personalizados antes de validar la adecuación del producto al mercado supone un desperdicio de recursos.
Empiece con el enfoque más sencillo que funcione. Optimice cuando la escala lo requiera, no antes. La optimización prematura desvía la atención del desarrollo principal del producto.
Optimización sin medición
Las suposiciones sobre los factores que influyen en los costos a menudo resultan erróneas. Las mediciones detalladas revelan patrones sorprendentes.
En ocasiones, los equipos optimizan los componentes equivocados. Una función que parece costosa podría representar 31 TP3T del costo total. Mientras tanto, un flujo de trabajo que se pasa por alto consume silenciosamente 401 TP3T del presupuesto.
Primero, mide. Optimiza las áreas de mayor impacto. Ignora los factores menores hasta que se resuelvan los problemas principales.
Sacrificar la calidad por el costo.
Los recortes de costes agresivos que degradan la calidad de la producción resultan contraproducentes. Las malas experiencias con la IA dañan la confianza del usuario y socavan el valor del producto.
Mantenga los estándares de calidad. Utilice marcos de evaluación para validar que las alternativas más económicas cumplan con los requisitos. Cuando no los cumplan, la opción más cara será la correcta.
Ignorar la velocidad de desarrollo
Las arquitecturas complejas de optimización de costes pueden ralentizar el desarrollo. Sacrificar la agilidad a cambio de ahorros marginales rara vez tiene sentido para productos en fase inicial.
Equilibre el esfuerzo de optimización con el valor para el negocio. Un sistema que procesa 1000 solicitudes diarias no necesita el mismo rigor de optimización que uno que procesa 1.000.000.
Preguntas frecuentes
¿Cuánto ahorro real puede suponer la arquitectura híbrida de PLN + LLM?
Los estudios e informes de la comunidad documentan reducciones de costos que oscilan entre 40% y 90%, según las características de la carga de trabajo. Los sistemas con un alto volumen de consultas simples experimentan los mayores ahorros. Las aplicaciones dominadas por tareas generativas complejas registran reducciones menores, pero aún significativas. El factor clave es el porcentaje de solicitudes que pueden ser gestionadas por enfoques de PLN más económicos frente a aquellas que requieren capacidades completas de LLM.
¿Los LLM más pequeños realmente funcionan lo suficientemente bien para su uso en producción?
Los modelos de aprendizaje automático modernos y compactos, como GPT-5 Mini, alcanzan un rendimiento sorprendentemente alto en pruebas comparativas. OpenAI reporta 91,11 TP3T en problemas matemáticos de AIME y 87,81 TP3T en medidas de inteligencia interna. Para muchas tareas de producción, estos modelos igualan o superan la calidad de los modelos grandes de generaciones anteriores, con un coste entre 5 y 10 veces menor. La evaluación específica para cada tarea es fundamental, ya que el rendimiento varía según el caso de uso.
¿Cuál es el punto de equilibrio entre construir modelos de PLN personalizados y usar modelos LLM?
En general, las tareas deterministas de alto volumen justifican el desarrollo de modelos de lenguaje natural (PLN) personalizados. Si una tarea recibe miles de solicitudes diarias y puede gestionarse mediante clasificación o extracción, los modelos personalizados se amortizan en cuestión de semanas. Las tareas de bajo volumen o altamente variables favorecen los modelos de lenguaje natural (MLN) a pesar de los mayores costes por solicitud, ya que el esfuerzo de desarrollo no puede amortizarse entre suficientes solicitudes.
¿Cómo puedo determinar qué solicitudes requieren modelos caros y cuáles modelos baratos?
Comience con un clasificador ligero que analice las características de la solicitud: longitud, estructura, palabras clave y dominio. En función de estas señales, diríjala a los niveles de modelo adecuados. La precisión de la clasificación inicial no tiene por qué ser perfecta; cree bucles de retroalimentación que identifiquen las solicitudes mal dirigidas y perfeccionen la clasificación con el tiempo. Muchos equipos informan que las heurísticas simples funcionan sorprendentemente bien como punto de partida.
¿Qué métricas de monitorización debo seguir para optimizar los costes de LLM?
Realiza un seguimiento independiente del número de tokens para la entrada y la salida, dado que los precios varían significativamente. Supervisa el coste por solicitud, el coste por usuario, el coste por función y el coste por resultado de negocio. Analiza la distribución de la selección de modelos para comprender los patrones de enrutamiento. Mide las tasas de aciertos de caché si utilizas el almacenamiento en caché semántico. Supervisa las métricas de calidad junto con el coste para garantizar que la optimización no degrade el rendimiento. Configura alertas cuando los costes superen los patrones previstos.
¿Es mejor utilizar servicios API o modelos de autoalojamiento para ahorrar costes?
La respuesta depende de la escala y la capacidad técnica. Los servicios API ofrecen comodidad y eliminan los costos de gestión de la infraestructura. Para volúmenes moderados, el precio por token suele ser más económico que el mantenimiento de la infraestructura de GPU. El autoalojamiento se vuelve rentable para volúmenes muy altos, donde los costos por solicitud superan los gastos de infraestructura amortizados. Un análisis de computación en la nube realizado por Hugging Face indica que la inversión de capital representa la principal barrera para el autoalojamiento, más que la complejidad operativa.
¿Con qué frecuencia cambian los precios de LLM y debería tenerlos en cuenta?
Los precios de los proveedores cambian periódicamente, a veces sin previo aviso. Las versiones principales suelen introducir nuevos niveles de precios. La creación de capas de abstracción que separan la selección de modelos de la lógica de negocio permite cambiar de proveedor o modelo sin necesidad de una refactorización extensa. La compatibilidad con múltiples proveedores permite el enrutamiento oportunista hacia quien ofrezca la mejor relación calidad-precio para tipos de solicitudes específicos en un momento dado.
Conclusión
La elección entre PLN y LLM no es binaria. Los sistemas de IA de producción más rentables combinan estratégicamente ambos enfoques.
El PLN tradicional destaca en tareas deterministas de gran volumen. Los sistemas basados en reglas y los modelos especializados procesan solicitudes sencillas a un coste mínimo. Los modelos de lenguaje natural (MLN) ofrecen capacidades que los métodos tradicionales no pueden igualar, pero a un coste significativamente mayor.
La arquitectura inteligente dirige las solicitudes a los niveles de procesamiento adecuados. Las capas de clasificación identifican las tareas sencillas que no requieren modelos costosos. El razonamiento complejo se dirige a modelos de lógica descriptiva (LLM) con capacidad suficiente. Este enfoque híbrido reduce los costos entre un 40 % y un 90 % sin comprometer la calidad.
La optimización de costes requiere un esfuerzo continuo. La medición revela patrones. La evaluación valida las alternativas. Las revisiones periódicas garantizan que los sistemas evolucionen a medida que mejoran los modelos y cambian los precios.
Empiece por la medición. Instrumente su sistema actual para comprender los patrones de gasto. Identifique mejoras rápidas mediante la optimización y el almacenamiento en caché. Desarrolle una arquitectura estratégica para lograr eficiencia a largo plazo. Considere la gestión de costos como una práctica continua, no como un proyecto puntual.
Las organizaciones que logren este equilibrio construirán sistemas de IA sostenibles y escalables económicamente. Aquellas que recurran por defecto a modelos costosos para todo se enfrentarán a limitaciones presupuestarias que restringirán la innovación.
Ahora te toca a ti: evalúa tus costes actuales, identifica oportunidades de optimización e implementa mejoras sistemáticas. Las herramientas y técnicas existen. La cuestión es si las utilizarás.