Resumen rápido: El despliegue de modelos de aprendizaje automático de código abierto (LLM) tiene un coste anual de entre 1.040.000 y 1.040.000 dólares o más para la mayoría de las organizaciones, superando con creces los precios de las API para cargas de trabajo típicas. Si bien los pesos del modelo son gratuitos, la infraestructura, el talento de ingeniería, los gastos operativos y el mantenimiento generan importantes costes ocultos que hacen que los servicios LLM comerciales sean más rentables hasta alcanzar determinados umbrales de equilibrio.
La propuesta suena irresistible: descarga un modelo de lenguaje de gran tamaño de código abierto, despliégalo en tu infraestructura y despídete para siempre de las facturas de API.
Pero aquí está el detalle: ese modelo "gratuito" le costará entre 125.000 y más de 12 millones de TP4T al año, dependiendo de su escala.
Los modelos de aprendizaje automático de código abierto trasladan los costos de las tarifas transparentes de la API a gastos operativos ocultos. Según una investigación presentada en un marco de análisis de costo-beneficio, las organizaciones se enfrentan a una decisión crucial: suscribirse a servicios comerciales de modelos de aprendizaje automático de proveedores como OpenAI, Anthropic y Google, o implementar modelos en su propia infraestructura. El análisis revela que la mayoría de las suposiciones sobre el ahorro de costos son fundamentalmente erróneas.
Este análisis examina la economía real de la implementación de programas de maestría en derecho de código abierto en 2026, respaldado por datos de implementaciones en producción y análisis académicos de costo-beneficio.
El mito de las modelos gratuitas: lo que realmente estás pagando.
Los pesos del modelo de código abierto se pueden descargar gratuitamente. Todo lo demás cuesta dinero.
Cuando las organizaciones comparan una descarga de $0 con los precios de la API que cobran por token, la comparación parece obvia. Pero la comparación es engañosa. Los pesos de los modelos descargados representan aproximadamente entre 2 y 5% de los costos totales de implementación.
El 95-98% restante proviene de:
- Infraestructura de hardware (GPU, servidores, redes)
- Talento en ingeniería (ingenieros de aprendizaje automático, especialistas en MLOps, equipos de infraestructura)
- Gastos operativos (monitorización, escalabilidad, fiabilidad)
- Mantenimiento y actualizaciones (parches de seguridad, reentrenamiento del modelo, optimización del rendimiento)
- Trabajo de integración (conexión de modelos con sistemas existentes)
Un estudio que analizó las implementaciones locales reveló que las organizaciones necesitan alcanzar umbrales de uso específicos antes de que los modelos autogestionados sean competitivos en costos con los servicios comerciales. Para la mayoría de las cargas de trabajo típicas, ese umbral nunca se alcanza.
Costes de infraestructura: La realidad de las GPU
Para ejecutar LLM se requieren importantes recursos informáticos. No recursos propios de un portátil. Se necesita una infraestructura de GPU a escala industrial.
Requisitos de hardware según el tamaño del modelo
Un modelo de 7 mil millones de parámetros puede ejecutarse a altas velocidades de inferencia en una sola NVIDIA L4 (24 GB) o incluso en GPU RTX 4090/5090 de gama de consumo, consumiendo mucha menos energía que un A100. Los modelos de 13 mil millones de parámetros necesitan varias GPU. Los modelos de más de 70 mil millones de parámetros requieren clústeres completos de GPU.
Y no se trata de tarjetas gráficas económicas. Según los precios de mercado, una sola GPU NVIDIA A100 de 80 GB cuesta aproximadamente entre 10 000 y 15 000 T. La H100, más reciente, tiene un precio aproximado de entre 25 000 y 40 000 T por unidad. La mayoría de las organizaciones necesitan varias unidades para sus cargas de trabajo de producción.
| Tamaño del modelo | Memoria mínima de GPU | Hardware típico | Costo aproximado
|
|---|---|---|---|
| Parámetros 7B | 16-24 GB | 1x A100 40GB | $10,000-$15,000 |
| Parámetros 13B | 32-48 GB | 1x A100 de 80 GB o 2x A100 de 40 GB | $20,000-$30,000 |
| Parámetros 70B | 140-280 GB | 4x A100 de 80 GB o 2x H100 | $50,000-$80,000 |
| Parámetros 175B+ | 350 GB o más | 8x A100 de 80 GB o clúster de GPU | $100,000+ |
Ventajas e inconvenientes de las soluciones en la nube frente a las implementaciones locales
Las organizaciones se enfrentan a dos opciones de infraestructura: construir centros de datos propios o alquilar instancias de GPU en la nube.
La infraestructura local requiere una inversión inicial de capital. Los presupuestos oscilan entre $50 000 para implementaciones mínimas y más de $500 000 para clústeres a escala de producción. Pero los costos de capital son solo el punto de partida. La energía, la refrigeración, el espacio físico y el mantenimiento suman entre 20 y 40% anualmente.
Las instancias de GPU en la nube eliminan los costos iniciales, pero generan gastos operativos continuos. Las instancias de GPU en la nube de proveedores como AWS pueden costar aproximadamente entre $20 y $35 por hora para configuraciones de 8 GPU, lo que se traduce en entre $14 000 y $25 000 mensuales para operación continua. Google Cloud y Azure ofrecen estructuras de precios similares.
Las innovaciones recientes, como las técnicas de cuantización, permiten que algunos modelos se ejecuten en hardware de consumo. Según la documentación de Hugging Face sobre los modelos SmallThinker, con la cuantización Q4_0, los modelos pueden superar los 20 tokens por segundo en procesadores de consumo comunes. Sin embargo, las compensaciones entre rendimiento y precisión hacen que este enfoque solo sea adecuado para casos de uso específicos.
El gasto en capital humano: equipos de ingeniería que necesitará
La infraestructura es tangible. Los costes de personal son donde realmente se desangran los presupuestos.
Implementar y mantener modelos de aprendizaje de lenguaje natural de código abierto no es un proyecto individual. Las implementaciones en producción requieren equipos de ingeniería especializados con salarios que superan con creces los gastos de infraestructura.
Requisitos del equipo principal
- Ingenieros de aprendizaje automático: Construir pipelines de inferencia, optimizar el rendimiento de los modelos, implementar técnicas como cuantización y procesamiento por lotes. Rango salarial: 150 000-250 000 anuales. La mayoría de las organizaciones necesitan al menos dos para garantizar la cobertura y la profundidad de conocimientos.
- Ingenieros de MLOps: Gestionar la infraestructura de despliegue, administrar clústeres de Kubernetes, mantener contenedores Docker, configurar cuotas de GPU e implementar pilas de inferencia como vLLM o NVIDIA Triton. Rango salarial: 140 000-230 000 anuales. Fundamental para escalar más allá de la prueba de concepto.
- Ingenieros de integración de software: Según las discusiones de la comunidad, aproximadamente 601 TP3T del esfuerzo de ingeniería en proyectos de IA se destinan al "código de conexión", que vincula los modelos con bases de datos, sistemas de autenticación e interfaces de usuario. Rango salarial: $130 000-$200 000 anuales.
- Ingenieros de DevOps/infraestructura: Mantenimiento de servidores, gestión de redes, cumplimiento de las normas de seguridad y gestión de la recuperación ante desastres. Rango salarial: 120.000-190.000 anuales.
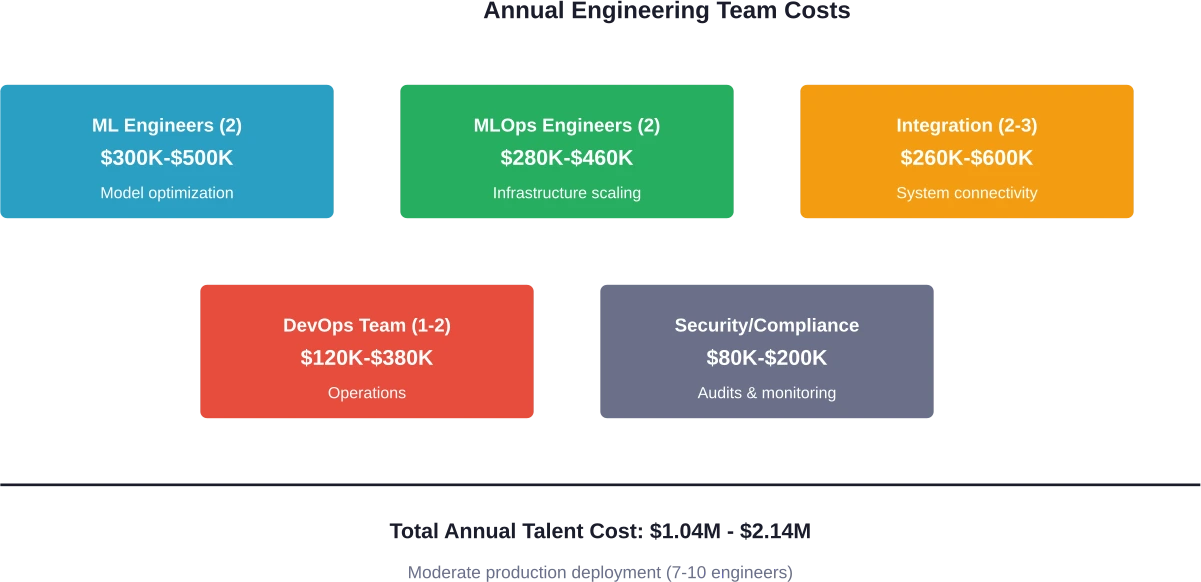
Las implementaciones internas mínimas requieren al menos 3 o 4 ingenieros. Las funciones orientadas al cliente requieren entre 7 y 10. Las implementaciones a escala empresarial necesitan más de 15 personas especializadas.
Según los precios actuales de la API de 2026, los modelos de la clase GPT-4 (y sus sucesores como GPT-5) cuestan aproximadamente entre $0,0025 y $0,01 por cada 1000 tokens de entrada. Un ingeniero de aprendizaje automático cuesta $200 000 al año. Ese ingeniero necesita ahorrarte 6600 millones de tokens en llamadas a la API solo para cubrir su salario.
Gastos operativos generales: El desembolso mensual
La infraestructura y los salarios son partidas presupuestarias predecibles. Los gastos operativos son donde los presupuestos se topan con la realidad.
Monitoreo y observabilidad
Los sistemas de aprendizaje automático en producción requieren una monitorización exhaustiva: seguimiento de la latencia, métricas de rendimiento, tasas de error, utilización de la GPU, consumo de memoria y detección de degradación de la calidad. Herramientas como Prometheus, Grafana y plataformas especializadas de observabilidad de aprendizaje automático añaden entre $2.000 y $10.000 mensuales.
Almacenamiento y transferencia de datos
Los pesos del modelo para un modelo de 70 mil millones de parámetros ocupan más de 140 GB de almacenamiento. Los datos de entrenamiento, los conjuntos de datos de ajuste fino y los registros de inferencia suman terabytes. El almacenamiento en la nube cuesta entre 1 TP4T0,02 y 1 TP4T0,05 por GB al mes. Las tarifas de transferencia de datos añaden otro coste: los cargos de salida de los principales proveedores de nube oscilan entre 1 TP4T0,08 y 1 TP4T0,12 por GB.
Escalado y equilibrio de carga
Los despliegues en producción requieren escalado automático para gestionar la carga variable. Un estudio sobre el servicio LLM en múltiples etapas (estudio del simulador MIST) revela que los despliegues optimizados pueden lograr hasta 2,8 veces más tokens por dólar mediante decisiones arquitectónicas cuidadosas. Sin embargo, implementar estas optimizaciones requiere una infraestructura sofisticada.
Los balanceadores de carga, la orquestación de contenedores y los sistemas de redundancia añaden entre $5.000 y $25.000 mensuales para implementaciones de escala media.
Seguridad y Cumplimiento
Los modelos autogestionados requieren auditorías de seguridad, certificaciones de cumplimiento y gestión de vulnerabilidades. Para las industrias reguladas, estos costos se disparan. Las auditorías de cumplimiento de HIPAA suelen costar entre 20 000 y 50 000 dólares anuales para la infraestructura existente, mientras que la certificación SOC 2 Tipo II cuesta entre 30 000 y 60 000 dólares, incluyendo los honorarios de auditoría.
Escenarios de despliegue: Desglose de costes reales
Las cifras abstractas no tienen sentido. Aquí les mostramos cuánto costarían los escenarios de implementación reales en 2026.
Escenario 1: Herramienta interna mínima
Caso de uso: Chatbot interno para consultas de empleados, entre 100 y 500 empleados, bajo volumen de uso.
Configuración:
- Modelo de un solo parámetro 7B (Llama 3 o Mistral)
- 1 GPU A100 de 40 GB (alojada en la nube)
- 2 ingenieros de aprendizaje automático (a tiempo parcial)
- Monitoreo básico e infraestructura
Costes anuales:
- Infraestructura de GPU: $15,000-$20,000
- Talento en ingeniería (parcial): $80,000-$120,000
- Monitoreo y herramientas: $10,000-$15,000
- Almacenamiento y redes: $5,000-$10,000
- Seguridad y cumplimiento: $15,000-$25,000
Total: $125.000-$190.000 anuales
A modo de comparación: un uso equivalente a través de API comerciales costaría significativamente menos anualmente, normalmente entre 1 TP4T3.000 y 1 TP4T15.000 para volúmenes de tokens similares. El punto de equilibrio nunca se alcanza.
Escenario 2: Característica orientada al cliente
Caso de uso: Chatbot o generación de contenido para más de 10.000 usuarios activos mensuales, uso moderado.
Configuración:
- Modelo de parámetros 13B-70B con ajuste fino
- 4 GPU A100 de 80 GB con escalado automático
- 7-10 miembros del equipo de ingeniería
- Monitorización y fiabilidad de nivel de producción
- Soporte disponible las 24 horas, los 7 días de la semana.
Costes anuales:
- Infraestructura de GPU: $120,000-$200,000
- Equipo de ingeniería: $700,000-$1,400,000
- Monitoreo y observabilidad: $30,000-$60,000
- Almacenamiento, redes, CDN: $25,000-$50,000
- Seguridad, cumplimiento normativo, auditorías: $50,000-$80,000
- Disponibilidad y respuesta ante incidentes: $25,000-$30,000
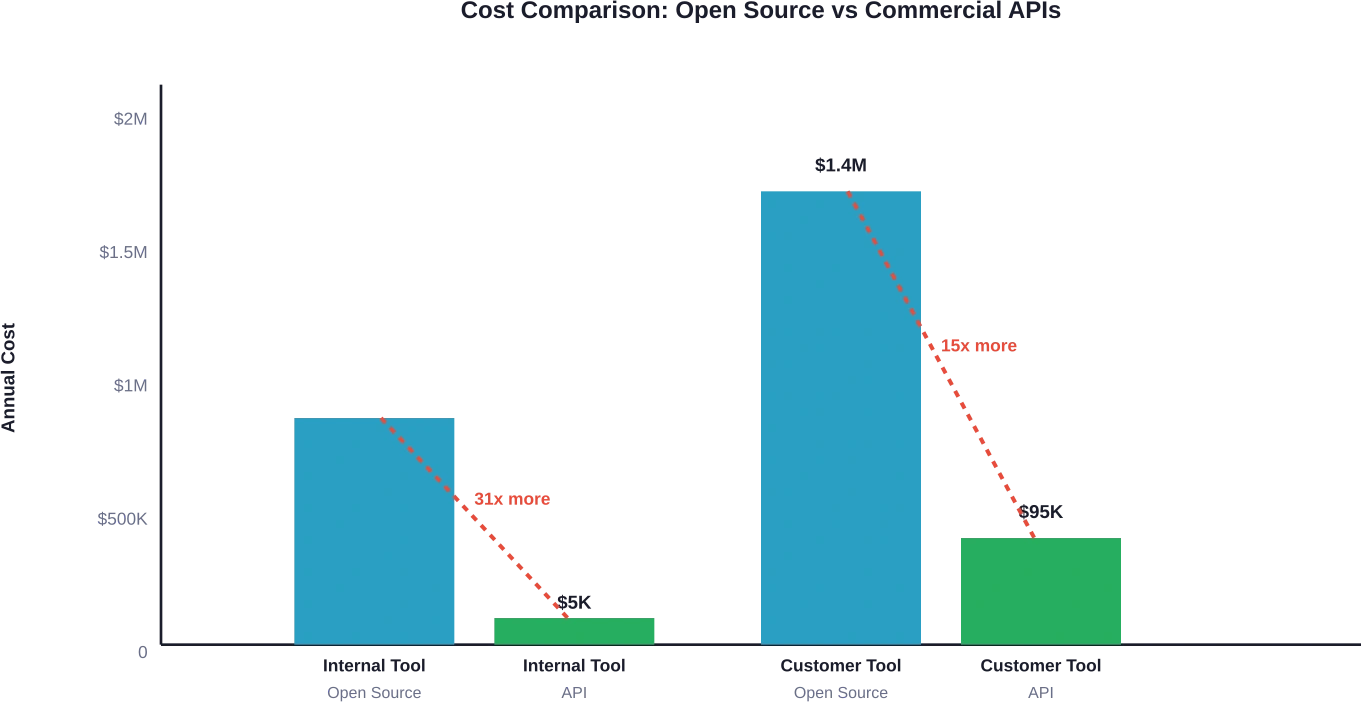
Total: $950.000-$1.820.000 anuales
Equivalente a una API comercial: se estima entre $40 000 y $150 000 anuales para patrones de uso similares, según el modelo elegido. El autoalojamiento solo resulta rentable para volúmenes superiores a 500 millones-1000 millones de tokens mensuales.
Escenario 3: Producto central empresarial
Caso de uso: LLM como motor principal del producto, millones de usuarios, requisitos de alta disponibilidad.
Configuración:
- Múltiples modelos con más de 70 mil millones de parámetros y pruebas A/B.
- Clúster de GPU (16-32 unidades) en múltiples regiones
- 15-25 especialistas en ingeniería
- Infraestructura de nivel empresarial con redundancia.
- Equipos especializados en seguridad y cumplimiento normativo
Costes anuales:
- Infraestructura de GPU: $1,500,000-$3,000,000
- Equipos de ingeniería: $2,500,000-$5,000,000
- Monitoreo y análisis: $200,000-$400,000
- Almacenamiento y redes: $300,000-$600,000
- Seguridad y cumplimiento: $400,000-$800,000
- Formación e I+D: $500,000-$1,000,000
Total: $5.400.000-$10.800.000 anuales
Esta escala representa el umbral en el que el autoalojamiento puede volverse potencialmente competitivo en costos con las API comerciales para patrones de uso en el rango mensual de 500 millones a más de mil millones de tokens.
Cuando el código abierto realmente tiene sentido desde el punto de vista financiero
El despliegue de código abierto no es universalmente incorrecto. Existen escenarios específicos que justifican la inversión.
Análisis del umbral de equilibrio
Las investigaciones que analizan la economía de la implementación local identifican puntos de equilibrio críticos en los que los modelos autogestionados se vuelven competitivos en costes con los servicios comerciales.
El umbral depende del volumen de tokens. Para cargas de trabajo empresariales típicas:
- Menos de 100 millones de tokens mensuales: Las API comerciales obtienen una victoria decisiva.
- Entre 100 y 500 millones de tokens mensuales: Los costes se aproximan a la paridad, pero las API suelen seguir siendo más baratas si se tienen en cuenta los gastos generales de ingeniería.
- Entre 500 millones y 1.000 millones de tokens mensuales: Zona de equilibrio donde el autoalojamiento puede justificar los costos
- Más de 1.000 millones de tokens al mes: El autoalojamiento demuestra claras ventajas en cuanto a costes.
Pero el volumen bruto de tokens no es el único factor.
Factores no financieros
- Privacidad y soberanía de los datos: Los sectores regulados que manejan datos sensibles (sanidad, finanzas, gobierno) se enfrentan a requisitos de cumplimiento que prohíben el uso de API externas. El autoalojamiento se vuelve obligatorio, independientemente del costo.
- Requisitos de latencia: Las aplicaciones que requieren tiempos de respuesta inferiores a 100 ms no toleran viajes de ida y vuelta a las API externas. Según el análisis de Hugging Face sobre la inferencia entre el borde y la nube, la distancia y la congestión de la red impactan significativamente la latencia p95. Para aplicaciones críticas en cuanto a latencia, la implementación local es indispensable.
- Profundidad de personalización: Los modelos altamente personalizados con un ajuste fino exhaustivo, entrenamiento específico para cada dominio y arquitecturas especializadas justifican la inversión en alojamiento propio. Ejemplos notables incluyen modelos como DeepSeek R1, que, según informes sobre cambios en el panorama de la computación, requirió menos de $300,000 para el post-entrenamiento.
- Independencia estratégica: Las organizaciones que desarrollan productos basados en inteligencia artificial pueden priorizar la independencia y el control de los proveedores por encima de la optimización de costes a corto plazo.
| Factor de decisión | Favorece el código abierto cuando | Favorezca las API comerciales cuando
|
|---|---|---|
| Volumen de tokens | Más de 500 millones mensuales | Menos de 500 millones mensuales |
| Requisito de latencia | Menos de 100 ms p95 | 200 ms o más aceptable |
| Sensibilidad de los datos | Datos regulados/clasificados | Cargas de trabajo no sensibles |
| Necesidades de personalización | Ajuste fino exhaustivo | Capacidades estándar |
| Experiencia del equipo | Equipos de ML/infraestructura existentes | Recursos técnicos limitados |
| Disponibilidad de capital | Puede invertir $500K+ por adelantado | Prefiero los gastos operativos |
Costes ocultos que acaban con los proyectos
Más allá de los gastos evidentes, varios costes ocultos dificultan la implementación de proyectos de código abierto.
Actualizaciones del modelo y deriva
Los modelos se degradan con el tiempo. Las distribuciones de datos cambian. Las expectativas de los usuarios evolucionan. Las API comerciales gestionan las actualizaciones automáticamente. Las implementaciones autogestionadas requieren intervención manual.
El reentrenamiento o la actualización de los modelos requiere tiempo adicional de GPU, esfuerzo de ingeniería y ciclos de prueba. Presupuestar entre $50 000 y $200 000 anualmente para el mantenimiento continuo de los modelos.
Costo de oportunidad
Los equipos de ingeniería que construyen la infraestructura de LLM no están desarrollando funcionalidades del producto. El costo de oportunidad de que siete ingenieros dediquen seis meses a la infraestructura de implementación representa entre $350 000 y $700 000 en costos salariales, además del valor no realizado de las funcionalidades que no desarrollaron.
Experimentos fallidos
No todos los despliegues tienen éxito. Probar múltiples modelos, arquitecturas y estrategias de optimización consume muchos recursos. Las pruebas de concepto fallidas cuestan entre $25 000 y $100 000 cada una en tiempo de ingeniería e infraestructura.
Deuda técnica
Las implementaciones apresuradas generan deuda técnica que se acumula con el tiempo. Los flujos de inferencia mal diseñados, la monitorización inadecuada y las integraciones frágiles requieren una costosa refactorización. La solución de la deuda técnica cuesta entre 3 y 5 veces más que una correcta implementación inicial.
Estrategias de optimización que realmente funcionan
Las organizaciones que optan por el autoalojamiento pueden emplear estrategias para reducir costes.
Cuantización y compresión
La cuantización de modelos reduce los requisitos de memoria y aumenta la velocidad de inferencia. Las investigaciones demuestran que la cuantización Q4_0 permite que los modelos superen los 20 tokens por segundo en hardware de consumo. Esta técnica reduce los costos de infraestructura entre 50 y 751 TP3T con un impacto mínimo en la precisión para muchas tareas.
Marcos de optimización de inferencia
Los servidores de inferencia especializados como vLLM, NVIDIA Triton y Text Generation Inference mejoran drásticamente el rendimiento. Estos marcos de trabajo pueden aumentar la cantidad de tokens por segundo entre 2 y 5 veces en comparación con las implementaciones básicas.
Las mejoras en el rendimiento se traducen directamente en ahorros de costes: se necesitan menos GPU para obtener un rendimiento equivalente.
Enfoques híbridos
Las organizaciones inteligentes no optan por soluciones "totalmente de código abierto" ni por "totalmente API". Las estrategias híbridas utilizan API comerciales para cargas de trabajo variables y picos de tráfico, al tiempo que mantienen una infraestructura propia para la carga base.
Este enfoque optimiza los costes: las API gestionan el tráfico en ráfagas sin sobredimensionar la infraestructura, mientras que los modelos autoalojados procesan cargas de trabajo predecibles de forma rentable.
Modelos especializados más pequeños
Los modelos más grandes no siempre son mejores. La familia SmallThinker demuestra que los modelos más pequeños, diseñados para tareas específicas, pueden superar a los modelos LLM de propósito general más grandes en tareas concretas. Un modelo 7B bien optimizado cuesta 90% menos de ejecutar que un modelo 70B, a la vez que ofrece un rendimiento potencialmente superior en tareas específicas.

Marco de cálculo del TCO
Las organizaciones necesitan un enfoque sistemático para calcular el coste total de propiedad antes de tomar decisiones de implementación.
- Paso 1: Estimar el volumen de tokens. Calcular el consumo mensual previsto de tokens en función del número de usuarios, los patrones de uso y los requisitos de las funciones. Incluir tanto los tokens de entrada como los de salida.
- Paso 2: Calcula la base de referencia de la API comercial. Multiplica el volumen de tokens por el precio de la API comercial. Ten en cuenta los diferentes niveles de modelo si utilizas varios tamaños de modelo.
- Paso 3: Dimensionar los requisitos de infraestructura. Determinar la cantidad y las especificaciones de las GPU en función del tamaño del modelo, los requisitos de latencia y las necesidades de redundancia. Incluir redes, almacenamiento y procesamiento.
- Paso 4: Estimar los recursos de ingeniería. Calcular los FTE (equivalentes a tiempo completo) necesarios para ingeniería de aprendizaje automático, operaciones de aprendizaje automático, integración, infraestructura y seguridad. Incluir tanto la implementación inicial como el mantenimiento continuo.
- Paso 5: Añada los gastos operativos. Incluya los costos de monitoreo, seguridad, cumplimiento, almacenamiento de datos, ancho de banda y respuesta a incidentes.
- Paso 6: Ten en cuenta los costes ocultos. Considera el coste de oportunidad, los experimentos fallidos, la deuda técnica y los ciclos de mantenimiento del modelo.
- Paso 7: Calcula el punto de equilibrio. Determina el volumen de tokens en el que los costos totales de la infraestructura autogestionada igualan los costos de las API comerciales. La mayoría de las organizaciones sitúan este umbral entre 500 millones y 1.000 millones de tokens mensuales.

Reduzca los costos de implementación de software LLM de código abierto antes de que se expandan.
Las soluciones LLM de código abierto parecen económicas al principio, pero los costes de implementación suelen aumentar rápidamente una vez que entran en juego la infraestructura, la monitorización, la escalabilidad y la integración. IA superior Trabaja en el aspecto técnico de los sistemas LLM: diseña arquitecturas de modelos, configura la infraestructura e integra los modelos en entornos existentes para que funcionen de manera eficiente en producción.
Si va a implementar sistemas LLM de código abierto en 2026, le conviene revisar la arquitectura y el proceso de implementación con anticipación. Contacto IA superior para evaluar la configuración de su implementación e identificar dónde se pueden reducir los costos de infraestructura e inferencia.
La realidad de 2026
Los costes de implementación de LLM de código abierto están disminuyendo, pero no de forma tan drástica como la mejora de las capacidades de los modelos.
Los precios de las GPU se mantienen persistentemente altos debido a la demanda constante. Los salarios de los ingenieros especialistas en IA siguen aumentando: los ingenieros de aprendizaje automático con máster en derecho (LLM) tienen una gran demanda y un crecimiento salarial competitivo.
Mientras tanto, los precios de las API comerciales están bajando. Según un análisis de Hugging Face sobre las tendencias del panorama informático, los precios de las API comerciales han disminuido significativamente con respecto a las tarifas de 2024. Claude y Gemini muestran trayectorias similares. La economía favorece cada vez más a las API para la mayoría de los casos de uso.
Mira, el código abierto dominará nichos específicos: industrias reguladas, aplicaciones críticas en cuanto a latencia, organizaciones que procesan miles de millones de tokens al mes y empresas que desarrollan productos diferenciados basados en IA. ¿Y para el resto? Las API son una opción más rentable.
El modelo de código abierto "gratuito" cuesta como mínimo $125 000 y probablemente más de $500 000 para cualquier cosa que se asemeje a una producción a escala. Esto no es una crítica al código abierto, simplemente son matemáticas.
Preguntas frecuentes
¿Cuál es el presupuesto mínimo realista para implementar un programa de Maestría en Derecho (LLM) de código abierto?
Las implementaciones mínimas de herramientas internas requieren entre 125 000 y 190 000 TPM anuales, lo que cubre la infraestructura básica de GPU, la asignación parcial de recursos de ingeniería, la monitorización y los gastos operativos. Cualquier cifra inferior a este umbral indica un proyecto con financiación insuficiente y con altas probabilidades de fracasar.
¿Cuántos tokens al mes hacen que el alojamiento propio sea rentable?
Según los estudios, entre 500 millones y 1.000 millones de tokens mensuales representan el punto de equilibrio, donde los costos de alojamiento propio se aproximan a la paridad con las API comerciales. Por debajo de los 500 millones de tokens mensuales, las API casi siempre resultan más económicas si se tienen en cuenta los gastos de ingeniería y operación.
¿Pueden los modelos más pequeños reducir significativamente los costes de implementación?
Sí. Un modelo de 7 mil millones de parámetros bien optimizado cuesta entre 85 y 901 TP3T menos de operar que un modelo de 70 mil millones. Al combinarse con un ajuste fino específico para cada tarea, los modelos más pequeños suelen igualar o superar el rendimiento de los modelos más grandes en aplicaciones específicas, lo que reduce drásticamente los requisitos de infraestructura.
¿Cuál es el mayor coste oculto en la implementación de software LLM de código abierto?
El talento en ingeniería suele representar una parte significativa de los costos totales de implementación, siendo el mayor costo oculto en la mayoría de las implementaciones organizacionales. Los ingenieros de aprendizaje automático, los especialistas en operaciones de aprendizaje automático y los desarrolladores de integración perciben salarios anuales de entre 140 000 y 250 000 £. Una implementación moderada requiere entre 7 y 10 especialistas, lo que genera entre 1 y 2 millones de £ en costos laborales anuales.
¿Las técnicas de cuantización realmente ahorran dinero sin perjudicar la calidad?
Las técnicas de cuantificación como Q4_0 pueden reducir los costos de infraestructura entre 50 y 751 TP3T con una mínima degradación de la precisión para muchas tareas. Las investigaciones demuestran que los modelos cuantificados alcanzan más de 20 tokens por segundo en hardware de consumo. Sin embargo, el impacto en la precisión varía según la tarea; es fundamental realizar pruebas exhaustivas antes de la implementación en producción.
¿Deberían las startups usar sistemas de gestión de aprendizaje de código abierto o API comerciales?
La mayoría de las startups deberían empezar con API comerciales. La flexibilidad, los costes predecibles y la ausencia de gastos operativos permiten una iteración y un desarrollo de productos más rápidos. El autoalojamiento solo tiene sentido al alcanzar una escala masiva, gestionar datos regulados o desarrollar capacidades de IA altamente diferenciadas, fundamentales para la ventaja competitiva.
¿Cuánto cuesta perfeccionar un modelo de código abierto?
Los costos de ajuste fino varían drásticamente según el tamaño del modelo y el conjunto de datos. Un ajuste fino mínimo de un modelo de 7 mil millones de dólares cuesta entre 5000 y 15 000 dólares, incluyendo el tiempo de GPU y el esfuerzo de ingeniería. Un ajuste fino exhaustivo de modelos de 70 mil millones de dólares con grandes conjuntos de datos puede superar los 100 000-300 000 dólares. Algunos ejemplos notables lograron resultados impresionantes con una inversión reducida: modelos más pequeños han demostrado un rendimiento comparable a una fracción del costo.
Conclusión: Haz los cálculos antes de comprometerte.
La implementación de software LLM de código abierto no es gratuita. Requiere una inversión sustancial en ingeniería e infraestructura, y solo resulta rentable a escalas específicas y para casos de uso concretos.
Las API comerciales son la opción económicamente más racional para la mayoría de las aplicaciones que procesan menos de 500 millones de tokens al mes. Sin duda, son más económicas para herramientas internas, aplicaciones para empleados y funcionalidades para clientes de escala moderada.
El autoalojamiento justifica la inversión al procesar volúmenes masivos de tokens (más de mil millones mensuales), manejar datos regulados o sensibles que requieren implementación local, cumplir con requisitos de latencia extremos o crear modelos altamente personalizados que son fundamentales para la diferenciación del producto.
Calcula con honestidad el costo total de propiedad. Incluye infraestructura, talento de ingeniería, gastos operativos, costos ocultos y costos de oportunidad. Compara esa cifra con los precios de las API comerciales para un uso equivalente. Las matemáticas rara vez mienten.
¿Y si las cifras siguen favoreciendo el autoalojamiento en tu caso particular? Presupuesta el doble de tu estimación inicial. Los despliegues en producción siempre cuestan más de lo previsto.
¿Listo para calcular con precisión los costos de implementación de LLM? Comience con proyecciones de volumen de tokens y, a partir de ahí, determine los requisitos de infraestructura y talento. El análisis del punto de equilibrio revelará si las API de código abierto o comerciales son financieramente viables para las necesidades específicas de su organización.