Résumé rapide : Les pipelines de données pour l'IA combinent apprentissage automatique et ingénierie des données afin d'automatiser le mappage des schémas, le traitement et les contrôles qualité. Ils transforment ainsi des informations brutes et non structurées en ensembles de données exploitables par l'IA, avec une intervention manuelle minimale. Contrairement aux processus ETL traditionnels, ils itèrent en continu à travers les étapes d'ingestion, de transformation, d'ingénierie des caractéristiques, d'entraînement et de surveillance. Les frameworks déclaratifs modernes permettent des gains d'efficacité de développement de 50%, une amélioration de la scalabilité de 500× et une réduction des coûts de calcul jusqu'à 80%.
Chaque projet d'IA ambitieux se heurte au même obstacle : des montagnes de données désordonnées stockées dans des systèmes déconnectés, loin du format propre et structuré qu'exigent les modèles.
Les outils ETL traditionnels peinent à traiter les journaux non structurés, les images et les champs de texte libre. Ils nécessitent une armée d'ingénieurs pour cartographier manuellement les schémas à chaque modification d'une source. De plus, lorsque les clusters GPU restent inactifs avec un taux d'utilisation de 10 à 151 TP3T en attente du prochain lot, les ressources de calcul sont épuisées.
C’est précisément le problème que résolvent les pipelines de données d’IA. Ils ne se contentent pas de déplacer des données : ils apprennent d’elles, s’adaptent automatiquement aux dérives de schéma et maintiennent l’infrastructure d’entraînement saturée.
Qu'est-ce qui différencie les pipelines de données d'IA ?
Les pipelines de données traditionnels suivent un chemin linéaire : extraction des données brutes, transformation selon des règles fixes, chargement dans un entrepôt de données. Le flux de travail est prévisible. Une fois exécuté, c’est terminé.
Les pipelines de données d'IA fonctionnent en boucle continue : ingestion → préparation → ingénierie des caractéristiques → entraînement des modèles → prédiction → surveillance → réentraînement. Chaque étape transmet des informations au pipeline en amont.
Mais voilà le hic : ces solutions gèrent aussi ce que les outils ETL traditionnels ne peuvent pas : les données non structurées à grande échelle. Documents, images, fichiers audio, commentaires clients en texte libre : autant de formats qui représentent la majorité des informations d’entreprise, mais qui restent inaccessibles aux outils classiques.
| Dimension | Pipeline de données traditionnel | Pipeline de données IA |
|---|---|---|
| Objectif principal | Rapports et veille stratégique | Entraînement, inférence et prédiction du modèle |
| Sortir | Tableaux de bord, rapports, indicateurs agrégés | Modèles entraînés, prédictions, magasins de fonctionnalités |
| Flux de travail | Linéaire : Extraction → Transformation → Chargement | Itératif : Ingestion → Préparation → Entraînement → Prédiction → Surveillance → Réentraînement |
| Gestion des schémas | Cartographie manuelle, interruptions dues à la dérive du schéma | Cartographie automatique basée sur l'apprentissage automatique, s'adapte aux changements |
| Types de données | Principalement structuré (bases de données, CSV) | Données structurées et non structurées (texte, images, journaux) |
| Gouvernance | Contrôle d'accès au niveau de l'entrepôt | Traçabilité de bout en bout, gestion des versions des modèles, journaux d'audit |
Franchement, c'est la couche d'automatisation qui fait toute la différence. Les modèles d'apprentissage automatique intégrés au pipeline détectent les modifications de schéma, suggèrent des transformations et signalent les anomalies avant qu'elles n'affectent les modèles en aval.
Les cinq étapes fondamentales des pipelines de données de l'IA moderne
Ingestion : Tout connecter
Les données proviennent de sources très diverses : API, bases de données, flux d’événements, compartiments S3, entrepôts de données sur site. L’ingestion permet de les rassembler dans un environnement unifié.
Les connecteurs modernes gèrent simultanément le traitement par lots et le traitement en flux continu. Un framework déclaratif peut spécifier les sources une seule fois, puis paralléliser automatiquement l'ingestion sur des centaines de partitions.
Apache Spark est largement utilisé pour l'ingestion distribuée de données dans les pipelines d'entreprise. Cependant, les plateformes propriétaires masquent de plus en plus la complexité de Spark derrière une syntaxe déclarative de type SQL.
Transformation : Nettoyage et structuration
Les données brutes contiennent des doublons, des valeurs nulles, un formatage incohérent et des horodatages manquants. La logique de transformation supprime les doublons, impute les valeurs manquantes, normalise les horodatages et convertit les types de données.
Les processus ETL traditionnels exigent que les ingénieurs écrivent et maintiennent manuellement les scripts de transformation. Les plateformes basées sur l'IA utilisent des modèles de détection d'anomalies pour signaler automatiquement les enregistrements suspects et suggérer des règles de correction.
Les recherches issues d'études universitaires sur la gestion des données montrent que la validation pilotée par l'IA réduit les enregistrements en double de 75% et améliore la précision des données de 18%.
Ingénierie des fonctionnalités : Entrées du modèle de construction
Les modèles ne se contentent pas d'exploiter les données brutes ; ils ont besoin de caractéristiques préparées. L'encodage catégoriel, la mise à l'échelle, le fenêtrage, le décalage temporel et l'agrégation sur plusieurs périodes constituent autant de prétraitements qui transforment les attributs bruts en signaux prédictifs.
Les outils d'ingénierie des caractéristiques automatisés testent des milliers de transformations candidates, les classent par pouvoir prédictif et versionnent l'ensemble final de caractéristiques en parallèle des points de contrôle du modèle.
Cette étape est itérative. Les modèles échouent, les ingénieurs ajoutent de nouvelles fonctionnalités, les pipelines sont réentraînés. Des boucles de rétroaction rapides permettent de condenser des semaines d'expérimentation en quelques jours.
Formation et validation
Les données préparées sont divisées en ensembles d'entraînement et de validation, généralement 80/20. Le sous-ensemble d'entraînement permet au modèle d'apprendre des modèles ; le sous-ensemble de validation permet de vérifier si ces modèles se généralisent.
Le réglage des hyperparamètres (taux d'apprentissage, tailles de lots, coefficients de régularisation) s'effectue ici. Les outils de recherche automatisée comme MLFlow ou les plateformes AutoML propriétaires testent des centaines de configurations en parallèle.
Les tests de performance réalisés sur des implémentations à grande échelle montrent des temps d'entraînement complets d'environ 60 heures. L'optimisation des modèles de base pré-entraînés réduit ce temps à 8 heures et 47 minutes, avec une durée d'exécution moyenne de 1 minute et 45 secondes par session.
Déploiement et surveillance
Les modèles entraînés sont ensuite déployés dans des environnements d'inférence : API REST, traitements par lots, dispositifs embarqués. La surveillance permet de suivre la latence de prédiction, le débit, les taux d'erreur et la dérive des données.
Lorsque la distribution des données d'entrée évolue (changements saisonniers, lancements de nouveaux produits, mises à jour de schémas), les performances se dégradent. Des alertes automatisées déclenchent des processus de réentraînement avant même que les utilisateurs ne constatent une baisse de précision.
Les couches de gouvernance appliquent le contrôle d'accès, les pistes d'audit et les politiques de conformité, de l'ingestion à la sortie du modèle. Une gouvernance centralisée évite aux équipes de réinventer la logique de sécurité dans chaque pipeline.
Comment l'IA transforme les performances des pipelines de données
Éliminer la saturation du GPU
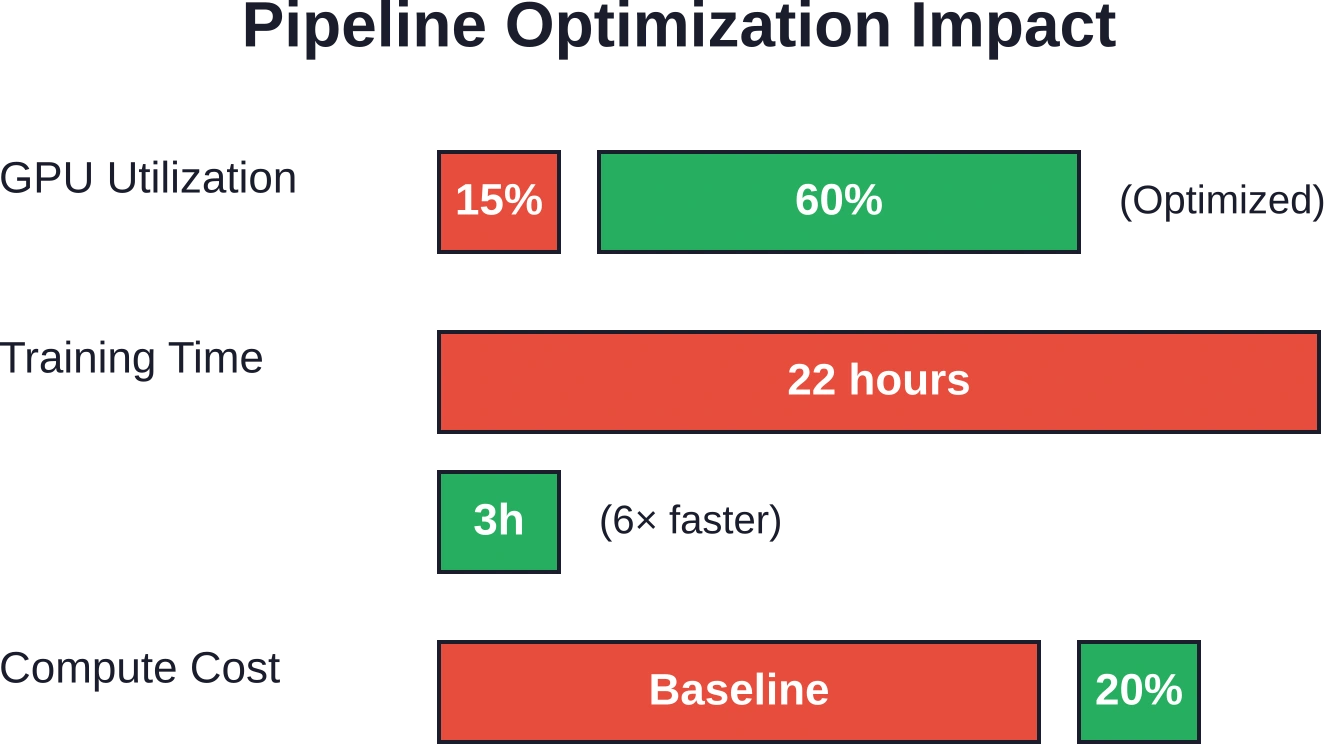
Les GPU hautes performances restent inactifs lorsque le chargement des données ne suit pas le rythme de la puissance de calcul. Dans les pipelines d'apprentissage profond industriels de base, les chercheurs ont observé que les GPU restaient utilisés entre 10 et 151 TP3T en attente de lots.
L'optimisation des pipelines de données grâce à des chargeurs distribués comme Petastorm a permis d'atteindre une utilisation du GPU de 601 TP3T et un gain de vitesse global de 6x. Le temps d'entraînement de bout en bout est passé de 22 heures à 3 heures. La réduction des coûts de calcul a atteint 801 TP3T grâce à l'élimination des cycles inutiles.
Le goulot d'étranglement n'était pas le modèle, mais les entrées/sorties. Améliorez le flux de travail, et l'investissement matériel sera rentable.
Cadres déclaratifs pour la mise à l'échelle
Le code de pipeline impératif (enchaînement de scripts Python pour exécuter des tâches Spark) devient ingérable à grande échelle. Le débogage nécessite la lecture de milliers de lignes. La collaboration est compromise lorsque la logique est dispersée dans plusieurs dépôts.
Les frameworks déclaratifs permettent aux ingénieurs de spécifier *quelles* transformations appliquer, et non *comment* les exécuter. La plateforme optimise automatiquement les plans d'exécution.
Les études de cas d'entreprises utilisant des pipelines déclaratifs font état d'une meilleure efficacité de développement, d'efforts de collaboration compressés de semaines à jours, d'améliorations de l'évolutivité de 500x et de gains de débit de 10x par rapport aux implémentations impératives.
Les évaluations académiques ont confirmé des gains de débit de 5,7× par rapport au code hors framework et une utilisation du processeur de 99% lors du traitement distribué.
Auto-réparation et évolution des schémas
Les systèmes de production sont soumis à des changements constants. Les API en amont ajoutent des champs, renomment des colonnes ou modifient les types de données sans préavis. Les pipelines traditionnels s'interrompent et nécessitent une intervention manuelle pour être corrigés.
L'évolution de schéma guidée par l'IA détecte automatiquement les incohérences, déduit les correspondances correctes à partir des modèles historiques et applique les transformations en temps réel. Des agents d'IA explicables fournissent des recommandations – par exemple : ” Colonne `user_id` renommée `userId` ; correspondance automatique appliquée ” – permettant ainsi aux ingénieurs d'auditer les modifications sans avoir à consulter les journaux.
Des couches d'amélioration de la qualité des données en temps réel valident les enregistrements lors de leur ingestion, signalent les valeurs aberrantes et acheminent les données suspectes vers des tables de quarantaine pour analyse. Les modèles poursuivent leur entraînement sur des sous-ensembles sains pendant que les ingénieurs examinent les anomalies de manière asynchrone.

Préparer les pipelines de données IA pour le développement de modèles réels
Les projets d'IA ne se limitent pas à un modèle. Les données doivent être collectées, structurées, préparées et reliées à l'usage réel du système. IA supérieure Nous intervenons dans les domaines de l'IA et de la stratégie de données, du développement de logiciels d'IA, de l'apprentissage automatique, de la veille stratégique et de l'intégration de l'IA. Pour les pipelines de données d'IA, cela peut inclure la préparation des données pour les modèles d'apprentissage automatique, la création d'applications basées sur les données, la prise en charge des flux de travail analytiques et la garantie de la compatibilité des systèmes d'IA avec les sources de données métier existantes.
Les travaux d'AI Superior peuvent couvrir :
- Besoins en données de planification pour les projets d'IA
- Préparation des données d'entreprise pour les modèles d'apprentissage automatique
- Développement de logiciels d'IA connectés aux sources de données existantes
- Prise en charge des flux de travail analytiques et de BI
- Intégrer les systèmes d'IA aux processus métier actuels
👉Contactez AI Superior pour discuter de la manière dont vos données peuvent être préparées pour les modèles d'IA, les outils d'analyse ou les logiciels d'IA personnalisés.
Défis courants et comment les surmonter
Défi : Dégradation de la qualité des données
Les performances du modèle chutent sans modification du code. Les tableaux de bord en aval affichent une précision en baisse. Cause principale : des sources de données en amont ont introduit des valeurs nulles, des doublons ou des incohérences de formatage il y a plusieurs semaines.
Solution : Contrôles qualité continus à l’ingestion. Des modèles de profilage statistique établissent les distributions de référence (moyenne, variance, cardinalité) et alertent lorsque de nouveaux lots dépassent les seuils prédéfinis. L’amélioration automatisée de la précision des données (18%) et la réduction des doublons (75%) sont possibles grâce à la validation par IA.
Défi : Infrastructure fragmentée
Les systèmes traditionnels stockent les données en silos : bases de données sur site, entrepôts de données dans le cloud, lacs de données, applications SaaS. Le déplacement des données entre ces environnements nécessite des scripts personnalisés, des VPN et une coordination manuelle.
Solution : Plateformes d’ingestion unifiées avec connecteurs préconfigurés pour plus de 100 sources. La configuration déclarative centralise l’authentification, la limitation de débit et la logique de synchronisation incrémentale. Les équipes définissent les sources une seule fois ; la plateforme se charge du reste.
Défi : Passer à l'échelle sans effondrement de la maintenabilité
Le code du pipeline impératif atteint des milliers de lignes. Chaque nouvelle fonctionnalité ajoute des branches conditionnelles. Le débogage prend des jours. L'intégration de nouveaux membres dans l'équipe est impossible.
Solution : Adoptez des frameworks déclaratifs. Spécifiez les transformations sous forme de fichiers de configuration ou de requêtes de type SQL. Le moteur d’exécution optimise automatiquement le parallélisme, les tentatives de recalcul et l’allocation des ressources. Les équipes en entreprise constatent une réduction de la taille de leur code (code 40%) et un temps de résolution des problèmes passé de plusieurs semaines à quelques jours grâce à la compression.
Meilleures pratiques d'architecture pour les systèmes de production
Séparer le stockage et le calcul
Les architectures étroitement couplées imposent une mise à l'échelle conjointe du stockage et de la puissance de calcul. Un surdimensionnement gaspille les ressources ; un sous-dimensionnement limite le nombre de tâches.
Les architectures natives du cloud découplent les deux. Les données sont stockées dans un stockage objet (S3, GCS, Azure Blob). Des clusters de calcul éphémères (Spark, Dask, Ray) sont lancés uniquement lors de l'exécution des tâches, puis arrêtés.
Version Tout
Le code, les données, les modèles et les configurations évoluent tous avec le temps. Sans système de versionnage, reproduire un résultat obtenu il y a trois mois relève de l'archéologie.
Les plateformes MLOps modernes intègrent Git pour le code, DVC pour les jeux de données et des registres de modèles pour les artefacts d'entraînement. Chaque exécution d'entraînement est liée à des instantanés précis des données d'entrée et aux configurations des hyperparamètres. Les restaurations s'effectuent en une seule commande.
Mise en œuvre d'une traçabilité de bout en bout
Les organismes de réglementation et les auditeurs demandent : “ Comment le modèle est-il parvenu à cette prédiction ? ” Les ingénieurs demandent : “ Quelle table en amont a causé ce bug ? ”
Le suivi de la lignée enregistre chaque transformation : table source → variable intermédiaire → entrée du modèle → prédiction. Les métadonnées conservent les horodatages, les versions de schéma et les actions des utilisateurs. Les interfaces de requête permettent aux équipes de remonter à l’origine de chaque résultat.
Intégrez l'observabilité dès le premier jour
Les pipelines tombent en panne silencieusement. Les tâches s'exécutent correctement mais produisent des données inutiles. Les alertes sont déclenchées trop tard.
Instrumentation à chaque étape : nombre de lignes ingérées, taux d’erreur de transformation, variations de la distribution des caractéristiques, latence de prédiction du modèle. Des tableaux de bord signalent les anomalies en temps réel. Des équipes d’astreinte détectent les problèmes avant même que les utilisateurs ne les signalent.
Cas d'utilisation dans différents secteurs d'activité
Détection de la fraude en temps réel (Services financiers)
Les transactions s'effectuent en quelques millisecondes. Des modèles évaluent le risque de fraude pour chaque transaction et bloquent les activités suspectes avant le règlement.
Les pipelines ingèrent les flux d'événements (Kafka, Kinesis), les associent aux caractéristiques des profils clients et invoquent des points de terminaison d'inférence à faible latence. La surveillance suit les taux de faux positifs et adapte dynamiquement les seuils.
Maintenance prédictive (Fabrication)
Les capteurs installés sur les équipements de l'usine émettent des données télémétriques (température, vibrations, pression). Des modèles prévoient les pannes plusieurs jours à l'avance, permettant ainsi de planifier la maintenance pendant les arrêts programmés.
Les pipelines agrègent les données de séries temporelles en fenêtres glissantes (horaires, quotidiennes), conçoivent des caractéristiques de décalage et réentraînent les modèles chaque semaine à mesure que de nouveaux schémas de défaillance apparaissent.
Recommandations personnalisées (commerce électronique)
Les parcours de navigation et l'historique d'achats des utilisateurs alimentent les modèles de filtrage collaboratif. Les recommandations sont mises à jour en quasi temps réel en fonction de l'évolution des préférences.
Les pipelines par lots reconstruisent les représentations vectorielles des éléments chaque nuit. Les pipelines de flux mettent à jour les profils utilisateur à chaque interaction. Les architectures hybrides offrent un équilibre entre la fraîcheur des données et le coût de calcul.
Aide à la décision clinique (soins de santé)
Les dossiers médicaux électroniques contiennent des résultats de laboratoire structurés, des notes médicales non structurées, des images médicales et l'historique des prescriptions. Des modèles synthétisent les signaux provenant de différentes modalités afin d'identifier les patients à risque.
Les pipelines gèrent l'ingestion multimodale, appliquent le NLP pour extraire les entités des notes, normalisent les unités de laboratoire et appliquent un contrôle d'accès conforme à la loi HIPAA tout au long du processus.
Fonctionnalités clés de la plateforme à évaluer
Lors de l'évaluation des plateformes de pipelines, privilégiez les capacités suivantes :
- Connecteurs préfabriqués : Bases de données, applications SaaS, stockage cloud, sources de streaming
- Inférence de schémas : Détection et mappage automatiques des types de données
- Bibliothèques de transformation : SQL, Python, générateurs de DAG visuels
- Orchestration: Planification, dépendances, nouvelles tentatives, remplissages
- Surveillance et alertes : Indicateurs de qualité des données, tableaux de bord de santé du pipeline
- Gouvernance : Contrôle d'accès, journaux d'audit, suivi de la traçabilité
- Évolutivité : Moteurs d'exécution distribués (Spark, Dask, Ray)
- Intégration: Registres de modèles, magasins de fonctionnalités, suivi des expériences
Les plateformes propriétaires simplifient la complexité mais engendrent une dépendance vis-à-vis du fournisseur. Les outils open source (Airflow, Prefect, Dagster) offrent de la flexibilité mais nécessitent une charge opérationnelle plus importante.

Stratégie d'adoption : Commencez petit, développez rapidement
N’entreprenez pas une refonte complète de votre pipeline d’entreprise dès le premier jour. Commencez par un projet pilote avec un seul cas d’usage à fort impact – détection de la fraude, prédiction du taux de désabonnement, prévision de la demande – où les parties prenantes rencontrent déjà des difficultés.
Mettez en place un flux de bout en bout : ingestion depuis une source critique, transformations minimales, un modèle, une cible de déploiement. Démontrez rapidement sa valeur. Puis, étendez-le.
Documentez les enseignements tirés. Standardisez les pratiques qui fonctionnent. Partagez les réussites entre les équipes. À mesure que l'adoption se généralise, centralisez les composants partagés (modules d'authentification, tableaux de bord de surveillance, politiques de gouvernance) dans des modèles réutilisables.
Investissez dans la formation. Les ingénieurs en pipelines ont besoin de compétences en ingénierie des données (SQL, systèmes distribués) et de fondamentaux en apprentissage automatique (biais, surapprentissage, métriques d'évaluation). Le travail en binôme interfonctionnel accélère le transfert de connaissances.
La voie à suivre : les pipelines d’IA en 2026 et au-delà
Les frameworks déclaratifs deviennent incontournables. Les équipes qui continuent d'écrire des scripts Spark impératifs auront du mal à être compétitives en termes de rapidité.
Les outils automatisés d'ingénierie des fonctionnalités vont démocratiser ce qui exige aujourd'hui une expertise pointue du domaine. Les modèles proposeront des fonctionnalités candidates ; les ingénieurs les sélectionneront et les approuveront.
La gouvernance et l'explicabilité passeront du statut de considérations secondaires à celui d'exigences fondamentales. La pression réglementaire – loi européenne sur l'IA, lois nationales sur la protection de la vie privée – oblige les organisations à prouver que leurs modèles sont équitables, transparents et auditables. Les processus intégrant la gouvernance dès la collecte des données s'adapteront plus rapidement que ceux qui se contentent d'une mise en conformité a posteriori.
Le déploiement en périphérie va s'accélérer. À mesure que les modèles se miniaturisent (quantification, distillation) et que le matériel périphérique s'améliore, l'inférence se rapproche des sources de données. Les pipelines devront orchestrer l'entraînement dans le cloud et le déploiement sur des milliers de points de terminaison distribués.
Le principe fondamental demeure : l'IA ne vaut que par la qualité des données qui l'alimentent. Les processus qui automatisent l'ingestion, la transformation et les contrôles qualité permettent aux équipes de se concentrer sur ce que les machines ne peuvent pas faire : poser de meilleures questions.
Questions fréquemment posées
Qu'est-ce qu'un pipeline de données d'IA ?
Un pipeline de données IA est un flux de travail automatisé qui ingère des données brutes provenant de sources multiples, les transforme en formats structurés et propres, conçoit des caractéristiques pour les modèles d'apprentissage automatique, entraîne et valide ces modèles, les déploie pour l'inférence et surveille en continu leurs performances. Contrairement aux processus ETL traditionnels, les pipelines IA fonctionnent par boucles de rétroaction : ils réentraînent les modèles en fonction de l'évolution des données et adaptent automatiquement les schémas grâce à l'apprentissage automatique intégré.
En quoi les pipelines de données IA diffèrent-ils des processus ETL traditionnels ?
Les processus ETL traditionnels suivent une séquence linéaire d'extraction, de transformation et de chargement pour la production de rapports et l'analyse décisionnelle. Les pipelines de données basés sur l'IA fonctionnent en boucle continue, traitant les données structurées et non structurées (texte, images, journaux), utilisant l'apprentissage automatique pour mapper automatiquement les schémas et réinjectant les informations de surveillance en amont afin de déclencher un réentraînement. Ils privilégient l'entraînement des modèles et les résultats d'inférence aux tableaux de bord statiques.
Quelles améliorations de performance les pipelines d'IA peuvent-ils apporter ?
Les tests de performance en production montrent que les pipelines optimisés pour l'IA atteignent une utilisation du GPU de 601 TP3T (contre 10 à 151 TP3T en référence), offrent une accélération globale de 6x, réduisent le temps d'entraînement de 22 heures à 3 heures et diminuent les coûts de calcul de 801 TP3T. Les frameworks déclaratifs affichent des gains d'efficacité de développement de 501 TP3T, une évolutivité améliorée de 500x et un débit multiplié par 10 par rapport aux implémentations impératives.
Quels sont les outils couramment utilisés pour les pipelines de données d'IA ?
Parmi les outils open source populaires, on trouve Apache Spark (traitement distribué), Apache Airflow et Prefect (orchestration), MLFlow (suivi des expériences) et DVC (gestion des versions de données). Les plateformes propriétaires telles que Databricks, Snowflake et les services ETL IA spécialisés offrent des environnements gérés avec connecteurs intégrés, gouvernance et supervision. Le choix de l'outil dépend de l'expertise de l'équipe, de l'échelle du projet et de sa tolérance aux coûts opérationnels.
Quels sont les principaux défis liés à la construction de pipelines de données pour l'IA ?
Les obstacles courants incluent la dégradation de la qualité des données (les modifications en amont introduisant des valeurs nulles ou des doublons), la fragmentation de l'infrastructure (données cloisonnées dans des systèmes incompatibles), la dérive des schémas (les modifications d'API interrompant les pipelines) et la difficulté de maintenance liée à l'expansion du code impératif. Les solutions consistent en des contrôles qualité continus, des plateformes d'ingestion unifiées, une évolution des schémas pilotée par l'apprentissage automatique et l'adoption de frameworks déclaratifs séparant la logique de l'exécution.
Quelle importance revêt la gouvernance dans les pipelines de données d'IA ?
La gouvernance est essentielle pour la conformité réglementaire, la traçabilité des processus et la confiance. Le suivi complet de la lignée enregistre chaque transformation, de la source à la prédiction, permettant aux équipes de retracer les anomalies et aux organismes de réglementation de vérifier l'équité. Le contrôle d'accès, les permissions basées sur les rôles et les journaux d'audit automatisés empêchent la divulgation non autorisée de données. Les organisations qui intègrent la gouvernance à leurs processus dès leur conception s'adaptent plus rapidement à l'évolution des lois sur la protection de la vie privée et des réglementations en matière d'IA.
Les pipelines d'IA peuvent-ils traiter des données non structurées ?
Oui, la gestion des données non structurées (documents, images, audio, texte libre) est l'un de leurs principaux atouts par rapport aux méthodes ETL traditionnelles. Les pipelines d'IA utilisent des modèles de traitement automatique du langage naturel (TALN) pour extraire les entités du texte, des modèles de vision par ordinateur pour classifier les images et des plongements lexicaux pour convertir les entrées non structurées en caractéristiques numériques exploitables par les modèles. Cette capacité permet d'exploiter la majeure partie des données d'entreprise que les outils conventionnels ignorent.
Conclusion : Mettez en place des pipelines qui apprennent
Les modèles d'IA font la une des journaux. Mais ce sont les processus de production qui déterminent si ces modèles seront un jour mis en production.
Les organisations qui réussiront en 2026 ne seront pas forcément celles qui possèdent les plus grandes équipes de science des données. Ce seront celles qui auront automatisé les processus métier (ingestion, transformation, surveillance) afin que leurs ingénieurs puissent se concentrer sur la résolution des problèmes commerciaux plutôt que sur le débogage des scripts ETL.
Commencez par un cas d'usage à fort impact. Démontrez la valeur du mappage automatisé des schémas, des contrôles qualité en temps réel et de la formation continue. Ensuite, déployez ces modèles à l'échelle des équipes.
L'avantage concurrentiel ne réside pas dans l'architecture du modèle, mais dans l'infrastructure de traitement qui assure sa mise à jour et sa fiabilité. Développez cette infrastructure, et l'IA cessera d'être un projet scientifique pour devenir un véritable moteur de croissance pour l'entreprise.