Résumé rapide : Le traitement automatique du langage naturel (TALN) permet aux entreprises d'analyser les retours clients, d'automatiser le service client, d'extraire des informations pertinentes à partir de données non structurées et d'améliorer la prise de décision. De l'analyse des sentiments aux chatbots, en passant par le traitement de documents et la veille concurrentielle, les applications TALN transforment le fonctionnement des organisations, réduisent leurs coûts et optimisent l'expérience client dans tous les secteurs d'activité.
Le traitement automatique du langage naturel est passé du statut de curiosité académique à celui de nécessité pour les entreprises. Celles-ci traitent désormais quotidiennement des millions de documents textuels : avis clients, tickets d’assistance, publications sur les réseaux sociaux, contrats juridiques et études de marché. L’analyse manuelle n’est plus viable à grande échelle.
Or, selon une étude de Deloitte, seules 181 millions d'organisations analysent des données non structurées, comme du texte brut, pour en tirer des enseignements commerciaux. C'est un énorme manque à gagner.
Les entreprises qui tirent parti du traitement automatique du langage naturel (TALN) ne se contentent pas de suivre le rythme. Elles prennent une longueur d'avance grâce à une prise de décision plus rapide, une compréhension client plus approfondie et une efficacité opérationnelle que leurs concurrents ne peuvent égaler avec les méthodes traditionnelles.
Cet article analyse les applications NLP les plus performantes qui transforment actuellement les opérations commerciales. Cas d'utilisation concrets, avantages mesurables et considérations pratiques pour leur mise en œuvre.
Qu’est-ce que le traitement automatique du langage naturel en entreprise ?
Le traitement automatique du langage naturel se situe à la croisée de l'intelligence artificielle, de la linguistique et de l'informatique. Il permet aux machines de comprendre, d'interpréter et de générer du langage humain de manière à créer de la valeur ajoutée pour les entreprises.
Cette technologie traite les données textuelles structurées et non structurées. Cela inclut tout, des courriels clients et des transcriptions de conversations en ligne aux avis sur les produits, aux conversations sur les réseaux sociaux et aux documents internes.
Les systèmes de traitement automatique du langage naturel (TALN) modernes ne se contentent pas de faire correspondre des mots-clés. Ils comprennent le contexte, le sentiment, l'intention et même des nuances linguistiques subtiles comme le sarcasme ou les dialectes régionaux. Cette capacité transforme la manière dont les organisations exploitent les volumes massifs de données textuelles générées quotidiennement.
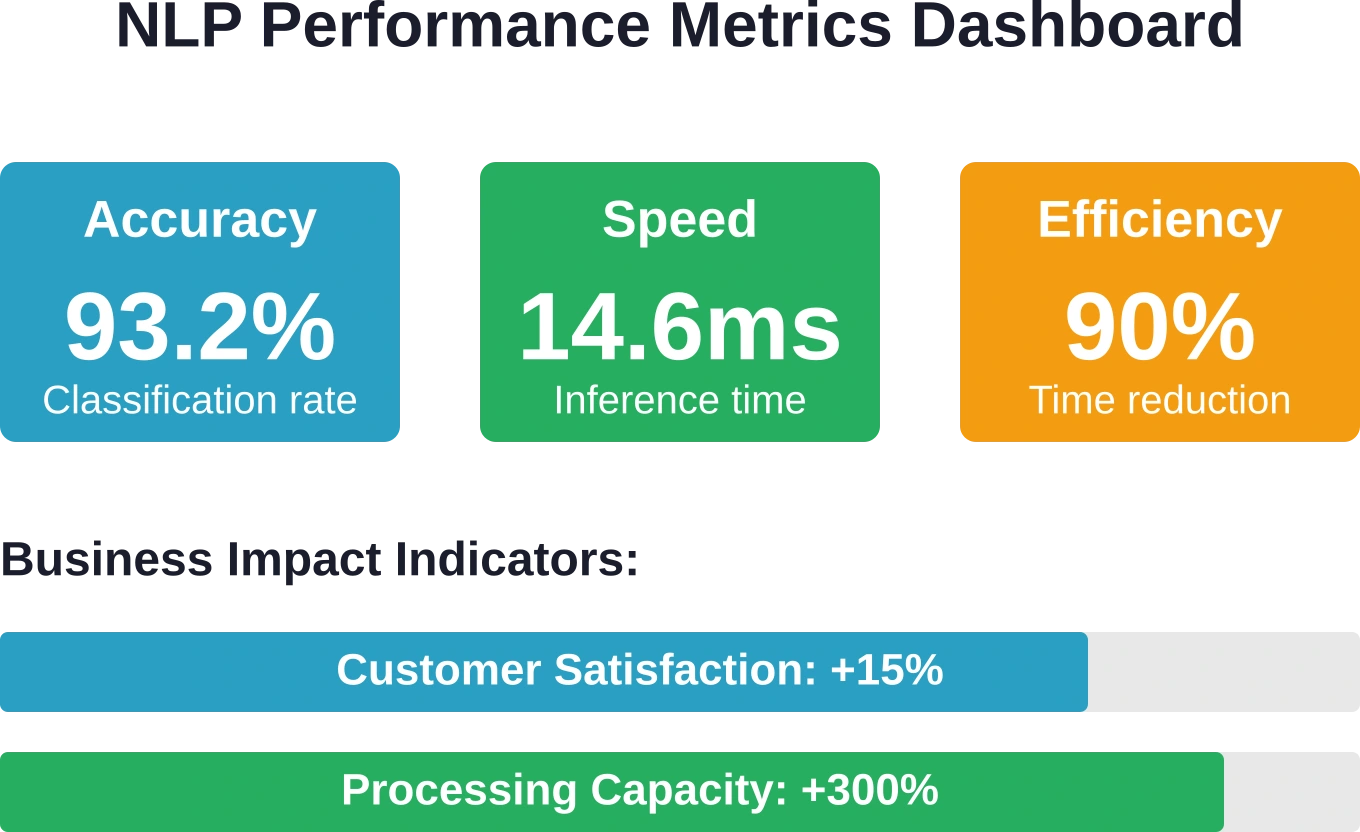
Pour les déploiements en entreprise, l'efficacité est aussi importante que la précision. Les architectures de transformateurs légères ont rendu possible le traitement du langage naturel en temps réel pour les applications métier. DistilBERT, par exemple, atteint une réduction de taille de 40% grâce à la distillation des connaissances, tout en conservant des performances comparables et en améliorant l'efficacité de l'inférence.
Cela permet un déploiement pratique avec des temps d'inférence optimisés et des tailles de modèles compactes adaptées à l'infrastructure d'entreprise standard.
Principaux avantages du NLP pour les opérations commerciales
Les organisations qui mettent en œuvre des solutions de traitement automatique du langage naturel (TALN) constatent des améliorations quantifiables dans de nombreux domaines opérationnels. Il ne s'agit pas d'avantages théoriques, mais d'impacts concrets et mesurables sur leurs résultats financiers.
Réduction des coûts grâce à l'automatisation
Les processus métier à forte composante textuelle absorbent un nombre considérable d'heures de travail des employés. La révision des contrats, les réponses aux demandes des clients, la classification des documents et la saisie de données impliquent toutes un traitement du langage humain que le traitement automatique du langage naturel (TALN) peut accélérer ou automatiser entièrement.
L'équipe de Tough Mudder a réduit de 901 000 le temps consacré au codage manuel des questionnaires grâce à l'analyse textuelle des retours post-événement. Cela représente des centaines d'heures récupérées pour des tâches stratégiques plutôt que pour la catégorisation des réponses ouvertes.
L'automatisation du service client offre des avantages similaires. Les chatbots traitent les demandes courantes sans intervention humaine, permettant ainsi aux équipes d'assistance de se concentrer sur les problèmes complexes nécessitant de l'empathie et une résolution créative des problèmes.
Rapidité d'accès à la connaissance
Les conditions du marché évoluent rapidement. Les organisations qui tirent le meilleur parti des commentaires des clients, des annonces des concurrents et des rapports de marché acquièrent des avantages décisifs.
Amazon a récemment mis en œuvre l'analyse textuelle pour analyser des millions d'avis clients et identifier les facteurs clés de satisfaction. Cette analyse a permis d'améliorer les produits de manière ciblée et d'augmenter de 151 millions le nombre d'évaluations positives, un avantage concurrentiel acquis grâce à une analyse des commentaires plus rapide que celle effectuée manuellement par ses concurrents.
Meilleure compréhension du client
Les clients expriment constamment leurs besoins, leurs frustrations et leurs préférences via les tickets d'assistance, les avis, les réseaux sociaux et les enquêtes. La plupart de ces retours qualitatifs restent inexploités, car l'analyse manuelle est impossible à grande échelle.
L'analyse des sentiments par traitement automatique du langage naturel (TALN) traite ces retours à grande échelle, identifiant les tendances émergentes avant même qu'elles ne deviennent évidentes. Les entreprises repèrent ainsi plus tôt les problèmes liés à leurs produits, comprennent mieux les demandes de fonctionnalités et adaptent leurs offres au langage réel des clients plutôt qu'à des suppositions internes.
Atténuation des risques et conformité
Les exigences réglementaires engendrent une charge documentaire considérable. Les secteurs des services financiers, de la santé et du droit sont confrontés à des défis particuliers pour garantir la conformité de milliers de documents et de communications.
Les systèmes de traitement automatique du langage naturel (TALN) analysent les contrats, les communications et les rapports afin de détecter les problèmes de conformité et de signaler les infractions potentielles avant qu'elles ne deviennent des problèmes réglementaires. Cette surveillance automatisée assure un contrôle constant impossible à maintenir par une vérification manuelle.

Applications d'amélioration de l'expérience client
Les applications de traitement automatique du langage naturel (TALN) destinées aux clients ont un impact direct sur leur satisfaction, leur fidélisation et la valeur client à vie. Ces cas d'utilisation gèrent les interactions de première ligne qui façonnent la perception du client.
Chatbots intelligents et assistants virtuels
L'IA conversationnelle moderne a dépassé le stade des arbres de décision rigides. Les systèmes actuels comprennent l'intention, gèrent le contexte des conversations à plusieurs tours et font appel à des agents humains de manière fluide en cas de besoin.
Ces assistants sont disponibles 24h/24 et 7j/7 sur différents canaux : chat en ligne, applications mobiles, messageries instantanées et interfaces vocales. Les clients obtiennent des réponses immédiates à leurs questions courantes concernant le statut de leurs commandes, leurs informations de compte, les caractéristiques des produits et le dépannage.
L'impact commercial va bien au-delà de la simple disponibilité. Les chatbots gèrent un nombre illimité de conversations simultanées sans temps d'attente, éliminant ainsi la frustration liée aux files d'attente des centres d'appels traditionnels. La cohérence des réponses s'en trouve également améliorée : chaque client reçoit des informations précises et conformes à l'image de marque, au lieu d'une qualité variable selon l'agent contacté.
La mise en œuvre nécessite une formation sur les conversations réelles avec les clients. Les chatbots génériques frustrent les utilisateurs. Les systèmes efficaces apprennent la terminologie spécifique à l'entreprise, les noms de produits, les problèmes courants et les schémas de conversation réellement utilisés par les clients.
Analyse des sentiments des commentaires clients
Les sentiments des clients sont omniprésents : avis, enquêtes, réseaux sociaux, tickets d’assistance. L’agrégation de ces sentiments à grande échelle révèle des tendances invisibles dans les interactions individuelles.
L'analyse des sentiments classe un texte comme positif, négatif ou neutre, souvent avec une détection fine des émotions (frustration, satisfaction, confusion). Les entreprises suivent l'évolution des sentiments au fil du temps, les mettent en corrélation avec les fonctionnalités des produits ou les changements de service, et identifient les problèmes émergents avant qu'ils ne s'aggravent.
Delta Air Lines a utilisé l'analyse textuelle pour traiter les commentaires clients provenant de différents canaux, identifiant ainsi les points de friction spécifiques liés à l'expérience de voyage. Cette compréhension fine des sentiments a permis d'apporter des améliorations ciblées aux principaux points de friction.
L'analyse va au-delà des classifications binaires bon/mauvais. L'analyse des sentiments par aspect révèle les caractéristiques spécifiques que les clients apprécient ou non. Un produit peut recevoir un avis globalement positif, mais un avis négatif concernant spécifiquement son emballage ou sa documentation — des informations exploitables que les notes globales ne permettent pas d'obtenir.
Intelligence de la voix du client
Les organisations recueillent une quantité considérable de données qualitatives qui ne sont jamais analysées. Les réponses aux enquêtes ouvertes, les transcriptions des appels au support, les entretiens avec les utilisateurs et les discussions sur les forums communautaires recèlent de précieuses informations, mais résistent aux analyses quantitatives traditionnelles.
Le traitement automatique du langage naturel (TALN) extrait les thèmes, les tendances et les schémas de ces retours non structurés. La modélisation thématique identifie automatiquement les sujets de conversation les plus fréquents chez les clients. L'extraction de fonctionnalités détermine les fonctionnalités les plus importantes pour les utilisateurs. L'analyse des points de friction met en évidence les obstacles qui frustrent les clients avant qu'ils ne se désabonnent.
Ces informations permettent d'orienter les feuilles de route des produits, les messages marketing et les stratégies de réussite client en utilisant le langage réel des clients plutôt que des suppositions internes sur ce qui compte.
Applications d'efficacité opérationnelle
Les opérations internes génèrent autant de texte que les interactions avec les clients : courriels, rapports, documentation, contrats, comptes rendus de réunion. Les applications de traitement automatique du langage naturel (TALN) rationalisent ces processus à forte intensité de texte.
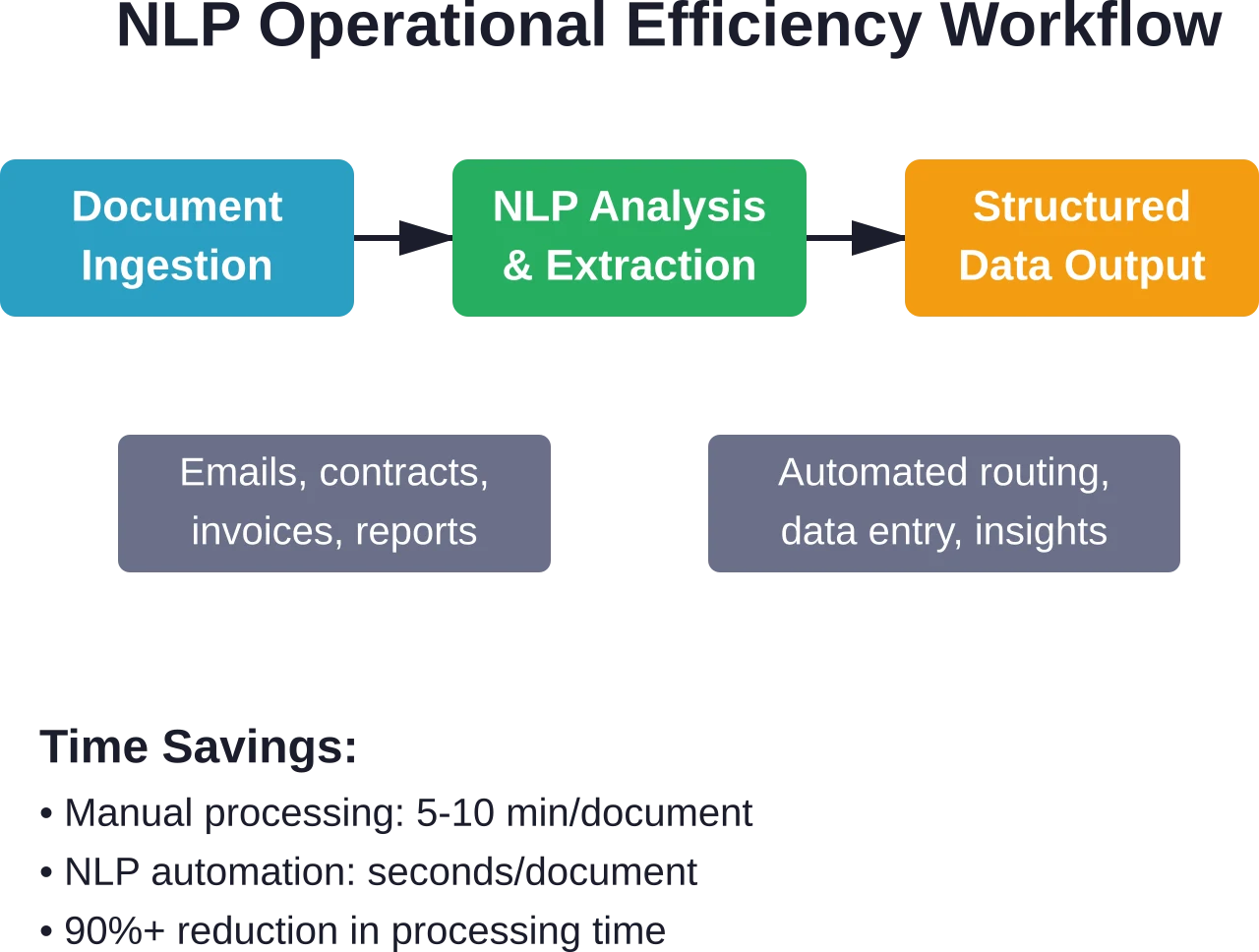
Traitement de documents et extraction d'informations
Les documents commerciaux contiennent des informations structurées, mais présentées dans des formats non structurés. Factures, contrats, CV, déclarations de sinistre et bons de commande nécessitent tous une intervention humaine pour en extraire les données clés.
Le traitement de documents par NLP identifie et extrait automatiquement les informations pertinentes : dates, montants, noms, adresses, conditions générales. Ces données structurées sont ensuite intégrées directement aux systèmes d’information de l’entreprise, sans saisie manuelle.
Le traitement des factures illustre parfaitement cet impact. Les entreprises qui reçoivent des milliers de factures de fournisseurs variés et dans différents formats peuvent automatiser l'extraction du nom du fournisseur, du numéro de facture, des lignes de commande, des montants et des conditions de paiement. Le temps de traitement passe de plusieurs minutes par facture à quelques secondes, avec une précision supérieure à celle des vérificateurs humains.
L'analyse contractuelle suit des schémas similaires. Les équipes juridiques utilisent le traitement automatique du langage naturel (TALN) pour examiner les contrats et identifier les clauses, obligations, dates et conditions non standard. Cette première analyse automatisée permet de repérer les points nécessitant l'intervention d'un avocat, tandis que les contrats courants sont traités plus rapidement.
Gestion et routage des courriels
Les volumes de courriels d'entreprise submergent les employés. Les demandes des clients arrivent dans des boîtes de réception génériques qui doivent être acheminées vers les équipes concernées. Les communications internes noient les demandes importantes sous un flot de messages.
Le traitement automatique du langage naturel (TALN) classe les courriels entrants par sujet, urgence et action requise. Les courriels du service client sont automatiquement acheminés vers les équipes concernées en fonction du type de problème : facturation, assistance technique, modifications de compte. Les demandes urgentes sont traitées immédiatement et ne sont pas mises en attente.
La classification automatisée des courriels garantit que les demandes parviennent dès le premier contact aux personnes compétentes, évitant ainsi les transferts entre services. Les délais de réponse sont améliorés car l'expert adéquat prend immédiatement en charge le problème.
Résumé de réunion et extraction des points d'action
Les organisations consacrent d'innombrables heures aux réunions. Leur efficacité repose sur une documentation claire et un suivi rigoureux des décisions et des actions entreprises.
Les systèmes de traitement automatique du langage naturel (TALN) analysent les transcriptions de réunions pour générer des résumés mettant en évidence les décisions clés, les actions à entreprendre et les responsables. Les participants reçoivent une documentation claire sans avoir à désigner de preneur de notes, et rien n'est oublié parce que quelqu'un a oublié de le noter.
Cette fonctionnalité s'étend aux appels enregistrés, aux webinaires et aux présentations. Le contenu devient consultable et navigable rapidement, évitant ainsi de devoir le revoir longuement pour retrouver des discussions spécifiques.
Recherche interne et gestion des connaissances
Les employés perdent un temps considérable à rechercher des informations sur les sites SharePoint, les wikis, les référentiels de documentation et les lecteurs partagés. La recherche par mots-clés traditionnelle renvoie des résultats non pertinents car elle ignore le contexte et l'intention.
La recherche sémantique, optimisée par le traitement automatique du langage naturel (TALN), comprend le sens des requêtes, et pas seulement la correspondance des mots clés. Par exemple, la recherche “ comment gérer les clients mécontents ” renvoie des protocoles de service client pertinents, même si ces documents n'utilisent jamais l'expression “ clients mécontents ”.”
Le système comprend les synonymes, les concepts apparentés et le contexte. Les résultats sont améliorés car la recherche reconnaît que “ client ”, “ consommateur ” et “ compte ” désignent souvent la même chose dans un contexte commercial.
Veille concurrentielle et analyse du marché
Comprendre la dynamique du marché et les mouvements des concurrents nécessite de traiter une quantité massive d'informations publiques : articles de presse, communiqués de presse, médias sociaux, conférences téléphoniques sur les résultats, dépôts de brevets et documents réglementaires.
Collecte de renseignements concurrentiels
Les systèmes de traitement automatique du langage naturel (TALN) surveillent les mentions des concurrents dans les sources d'information, les médias sociaux, les sites d'avis et les publications spécialisées. Les entreprises suivent les lancements de produits, les changements de prix, le ressenti des clients, les tendances de recrutement et les annonces stratégiques de leurs concurrents.
Cette surveillance automatisée permet de déceler plus rapidement les menaces et les opportunités concurrentielles qu'une recherche manuelle. Lorsque les concurrents annoncent de nouvelles fonctionnalités, le traitement automatique du langage naturel (TALN) alerte immédiatement les équipes concernées, sans attendre que quelqu'un découvre l'information par hasard.
L'analyse va au-delà des simples mentions. L'analyse des sentiments révèle comment les marchés perçoivent les annonces des concurrents. La modélisation thématique identifie les fonctionnalités concurrentes qui suscitent le plus de discussions. Les indicateurs de part de voix montrent l'attention relative du marché portée aux différents concurrents.
Analyse des tendances du marché
Les tendances sectorielles se dégagent de l'analyse de milliers d'articles, de rapports et de discussions. Pris individuellement, ces éléments sont peu révélateurs, mais une analyse globale permet de mettre en évidence les thèmes émergents.
Le traitement automatique du langage naturel (TALN) analyse les publications sectorielles, les rapports d'analystes, les actes de conférences et les médias sociaux afin d'identifier les sujets en plein essor, les sujets en déclin et l'évolution de la terminologie. Les entreprises repèrent ainsi les opportunités de marché en amont et évitent d'investir dans des approches obsolètes.
Cette détection de tendances fonctionne sur différentes périodes. La détection des pics à court terme identifie les réactions immédiates du marché aux événements. L'analyse des tendances à long terme révèle les évolutions progressives des priorités sectorielles, des clients et de l'adoption technologique.
Surveillance de la marque et gestion de la réputation
Les mentions de marques se multiplient sur différentes plateformes : réseaux sociaux, sites d’avis, forums, articles de presse, blogs. La surveillance manuelle ne détecte pas la plupart des mentions et réagit trop lentement aux problèmes émergents.
La surveillance de marque basée sur le traitement automatique du langage naturel (TALN) suit les mentions en temps réel, analyse les sentiments, identifie les sujets tendance et alerte les équipes en cas de problèmes de réputation potentiels. Les entreprises réagissent rapidement en cas de pic de sentiments négatifs et interagissent avec les clients avant que des plaintes isolées ne deviennent virales.
Le système de surveillance tient compte des différents contextes. Une mention dans une plainte nécessite un traitement différent d'une mention dans un avis positif ou un article neutre du secteur. La classification de l'intention garantit une priorisation appropriée des réponses.
Applications de gestion des risques et de conformité
Les exigences réglementaires et la gestion des risques engendrent d'importants besoins en matière de documentation et de surveillance. Le traitement automatique du langage naturel (TALN) automatise une grande partie de ces tâches de conformité.
Surveillance de la conformité réglementaire
Les secteurs des services financiers, de la santé et autres industries réglementées doivent veiller à ce que leurs communications et documents soient conformes à une réglementation complexe. L'examen manuel de chaque courriel, rapport et document n'est pas envisageable à grande échelle.
Les systèmes de traitement automatique du langage naturel (TALN) analysent les communications afin de détecter les anomalies de conformité : terminologie interdite, mentions obligatoires, informations privilégiées, infractions aux règles de prêt équitables. Les problèmes potentiels sont signalés pour vérification humaine avant d’être considérés comme des infractions.
Le système de surveillance s'adapte à l'évolution de la réglementation. Lorsque de nouvelles exigences de conformité apparaissent, les organisations mettent à jour leurs modèles de traitement automatique du langage naturel (TALN) pour détecter les nouvelles tendances, évitant ainsi de former à nouveau l'ensemble de leurs équipes de conformité.
Détection des fraudes dans les communications textuelles
Les activités frauduleuses laissent des traces linguistiques. Les demandes d'indemnisation, les demandes de prêt et les relevés financiers contiennent des schémas linguistiques qui permettent de distinguer les documents légitimes des documents frauduleux.
Le traitement automatique du langage naturel (TALN) analyse les textes à la recherche d'indicateurs de fraude : incohérences, schémas suspects et langage caractéristique des techniques de fraude connues. Ce filtrage automatisé permet de prioriser les cas nécessitant l'attention des enquêteurs et d'orienter les ressources limitées d'enquête vers les affaires les plus à risque.
Analyse de documents juridiques
Les services juridiques traitent des milliers de contrats, d'accords et de documents réglementaires. Le coût des honoraires d'un avocat s'élève à plusieurs centaines de dollars de l'heure, ce qui représente un coût important pour un simple examen de documents.
Le traitement automatique du langage naturel (TALN) effectue une première analyse contractuelle, en extrayant les termes clés, en identifiant les clauses standard et non standard, en signalant les dispositions inhabituelles et en comparant les contrats à des modèles. Les avocats se concentrent sur les questions juridiques véritablement complexes plutôt que sur les tâches de routine.
La recherche jurisprudentielle bénéficie d'avantages similaires. Au lieu de lire manuellement des centaines de décisions pour trouver des précédents pertinents, le traitement automatique du langage naturel (TALN) effectue des recherches basées sur des concepts juridiques et des schémas factuels, faisant ainsi rapidement ressortir les décisions les plus pertinentes.
Applications des ressources humaines
Les services RH traitent d'énormes volumes de texte : CV, descriptions de poste, évaluations de performance, retours des employés, entretiens de départ. Le traitement automatique du langage naturel (TALN) permet de rendre ces données textuelles exploitables.
Sélection des CV et mise en relation des candidats
Les offres d'emploi les plus populaires attirent des centaines de candidatures. L'examen manuel des CV crée des goulots d'étranglement et risque de faire passer à côté de candidats qualifiés noyés sous un flot de candidatures.
Les systèmes de suivi des candidatures basés sur le traitement automatique du langage naturel (TALN) analysent les CV pour en extraire les compétences, l'expérience, la formation et les qualifications. Les candidats sont automatiquement comparés aux exigences du poste, classés selon leur adéquation au poste plutôt que par ordre d'arrivée.
L'analyse va au-delà de la simple correspondance de mots-clés. La compréhension sémantique reconnaît que “ développeur Python ” et “ ingénieur logiciel ayant une expérience en Python ” décrivent des qualifications similaires, même si la formulation diffère.
Analyse du ressenti et de l'engagement des employés
Les enquêtes auprès des employés, les plateformes de feedback et les entretiens de départ fournissent des informations précieuses sur la culture d'entreprise, l'efficacité du management et les problématiques organisationnelles. Ces retours d'information favorisent la fidélisation lorsqu'ils sont exploités, mais seulement s'ils font l'objet d'une analyse.
Le traitement automatique du langage naturel (TALN) analyse les retours des employés à grande échelle, identifiant les thèmes communs, les préoccupations émergentes et les tendances en matière de sentiments au sein des équipes et des départements. Les organisations repèrent ainsi rapidement les problèmes d'engagement et mesurent l'impact de leurs initiatives culturelles grâce à des indicateurs quantitatifs.
Analyse de l'évaluation des performances
Les évaluations de performance génèrent de précieuses données qualitatives sur les points forts, les besoins de développement et les aspirations professionnelles des employés. Ces informations sont généralement consignées dans des documents individuels plutôt que d'être intégrées aux stratégies de gestion des talents de l'organisation.
Le traitement automatique du langage naturel (TALN) extrait des tendances des évaluations de performance : compétences récurrentes chez les employés les plus performants, besoins de développement communs aux équipes, indicateurs de potentiel de promotion. La gestion des talents s’appuie ainsi sur les données plutôt que sur des observations anecdotiques.
Considérations relatives à la mise en œuvre du traitement automatique du langage naturel en entreprise
La réussite de la mise en œuvre du traitement automatique du langage naturel (TALN) ne se limite pas au choix d'un algorithme. Les organisations doivent prendre en compte la qualité des données, l'entraînement du modèle, l'intégration et la maintenance continue.
Exigences et préparation des données
Les modèles de traitement automatique du langage naturel (TALN) apprennent à partir d'exemples. La qualité d'un modèle dépend directement de la qualité et du volume des données d'entraînement. Les organisations ont besoin d'échantillons représentatifs du texte qu'elles souhaitent traiter : suffisamment d'exemples pour couvrir la terminologie, les formats et les cas particuliers.
La préparation des données exige un effort considérable. Les données textuelles nécessitent un nettoyage, une normalisation et un étiquetage. La suppression des artefacts de formatage, la gestion des caractères spéciaux et la normalisation des abréviations influent toutes sur les performances du modèle.
Pour les tâches d'apprentissage supervisé comme la classification, il est nécessaire d'étiqueter les exemples d'entraînement. Un modèle d'analyse des sentiments requiert des centaines, voire des milliers, d'échantillons de texte classés manuellement comme positifs, négatifs ou neutres. Cet étiquetage exige une expertise du domaine et des directives claires garantissant la cohérence.
Sélection et personnalisation du modèle
Les modèles de langage pré-entraînés offrent une base solide, mais nécessitent une personnalisation pour s'adapter au contexte métier. Les modèles génériques ne comprennent pas la terminologie spécifique à l'entreprise, les noms de produits ni le jargon sectoriel.
Le fine-tuning adapte les modèles pré-entraînés aux besoins spécifiques d'une entreprise. Cette approche d'apprentissage par transfert nécessite beaucoup moins de données d'entraînement que la création de modèles à partir de zéro, tout en offrant de meilleures performances que les modèles génériques.
Le choix du modèle repose sur un équilibre entre précision et efficacité. Les modèles les plus précis nécessitent davantage de ressources de calcul, ce qui engendre de la latence et des coûts d'infrastructure. Les architectures légères comme DistilBERT offrent une grande précision sur les jeux de données d'entreprise tout en répondant aux exigences de traitement en temps réel.
Intégration avec les systèmes existants
Les applications de traitement automatique du langage naturel (TALN) doivent s'intégrer aux flux de travail et aux systèmes existants. Les outils d'analyse autonomes n'ont qu'une valeur limitée si les informations recueillies ne parviennent pas aux décideurs ou ne déclenchent pas les actions appropriées.
L'intégration via API connecte les fonctionnalités de traitement automatique du langage naturel (TALN) aux systèmes CRM, aux plateformes de support, aux systèmes de gestion documentaire et aux outils de veille stratégique. Les scores de sentiment sont intégrés aux fiches clients, l'extraction de documents alimente les champs de la base de données et les conversations du chatbot s'intègrent aux systèmes de gestion des tickets.
L'intégration comprend des flux de travail nécessitant une intervention humaine pour les tâches exigeant un jugement humain. Le traitement automatique du langage naturel (TALN) assure le traitement et l'acheminement initiaux, mais les cas complexes sont transmis aux employés disposant du contexte approprié grâce à l'analyse automatisée.
Considérations relatives à la confidentialité et à la sécurité
Les données textuelles commerciales contiennent des informations sensibles : coordonnées clients, données financières, données confidentielles, dossiers des employés. Les systèmes de traitement automatique du langage naturel (TALN) doivent protéger ces informations tout au long du traitement.
Les politiques de gouvernance des données définissent les textes pouvant être traités, les personnes autorisées à accéder aux résultats et la durée de conservation des données. Les organisations doivent s'assurer que le traitement du langage naturel est conforme aux réglementations en matière de protection de la vie privée, telles que le RGPD, le CCPA et les exigences spécifiques à leur secteur d'activité.
L'entraînement des modèles soulève des problèmes de confidentialité supplémentaires. Les données d'entraînement ne doivent pas être utilisées pour générer les résultats des modèles. Les organisations utilisant des services de traitement automatique du langage naturel (TALN) dans le cloud doivent savoir où les données sont traitées et stockées, notamment pour les secteurs réglementés soumis à des exigences de résidence des données.
| Phase de mise en œuvre | Activités clés | Chronologie typique | Facteurs de succès |
|---|---|---|---|
| Découverte et planification | Définition des cas d'utilisation, évaluation des données, recueil des besoins | 2 à 4 semaines | Objectifs commerciaux clairs, soutien de la direction |
| Préparation des données | Collecte, nettoyage, étiquetage et contrôles de qualité des données | 4 à 8 semaines | Expertise du domaine, directives d'étiquetage, volume de données |
| Développement de modèles | Sélection, entraînement, validation et optimisation du modèle | 6 à 12 semaines | Données d'entraînement représentatives, indicateurs d'évaluation |
| Intégration et tests | Intégration de systèmes, tests d'acceptation utilisateur (UAT), conception des flux de travail | 4 à 6 semaines | Des flux de travail clairs, l'implication des parties prenantes |
| Déploiement et surveillance | Déploiement de la production, suivi des performances, itération | En cours | Infrastructure de surveillance, boucles de rétroaction |

Créez des outils de traitement automatique du langage naturel (TALN) adaptés aux tâches commerciales réelles grâce à une IA supérieure.
Le traitement automatique du langage naturel (TALN) devient utile lorsqu'il résout un problème spécifique lié au texte : trier, rechercher, extraire, classer, résumer ou répondre à des questions à partir de contenu d'entreprise. IA supérieure Nous collaborons avec les services de développement en traitement automatique du langage naturel (TALN), de conseil en gestion de projets d'intelligence artificielle (GIA), de développement d'IA générative, de développement de chatbots, de développement de logiciels et d'intégration d'IA. Pour les entreprises, cela peut concerner les messages clients, les tickets d'assistance, les rapports, les documents internes, les avis, les contrats, les bases de connaissances et autres sources de données textuelles.
Les travaux de NLP d'AI Superior peuvent inclure :
- Cartographie des tâches métier qui dépendent des données textuelles
- Outils de traitement et de classification des documents de construction
- Développement d'assistants ou de fonctionnalités de recherche basés sur le LLM
- Application du traitement automatique du langage naturel (TALN) au support, aux évaluations, aux rapports ou au contenu interne
- Intégration de l'IA linguistique dans les logiciels d'entreprise
👉Contactez l'IA supérieure pour explorer les applications du traitement automatique du langage naturel (TALN) pour vos documents, vos communications clients ou vos produits numériques.
Mesurer l'impact et le retour sur investissement du traitement automatique du langage naturel
Pour justifier les investissements dans le traitement automatique du langage naturel (TALN), il est nécessaire de démontrer un impact commercial mesurable. Les organisations doivent définir des indicateurs de succès avant la mise en œuvre et en assurer un suivi régulier.
Métriques quantitatives
Le gain de temps constitue le calcul de retour sur investissement le plus simple. Le temps de traitement des documents, le temps de résolution des demandes clients et les heures d'analyse manuelle se traduisent directement par des économies une fois automatisés.
Les indicateurs de volume mettent en évidence l'impact de l'échelle. Le nombre de documents traités, de conversations clients gérées ou de contrats analysés démontre des gains de capacité impossibles à obtenir avec des méthodes manuelles.
Les améliorations de la qualité se manifestent par des taux de précision plus élevés, des indicateurs de cohérence plus solides et une réduction des erreurs. La précision de la classification en traitement automatique du langage naturel (TALN), la précision de l'extraction et l'exactitude du routage permettent de déterminer si les systèmes automatisés sont aussi performants que les systèmes humains de référence.
Indicateurs de résultats commerciaux
L'impact final se manifeste dans les résultats commerciaux plutôt que dans les indicateurs de processus. Les scores de satisfaction client, les taux de fidélisation, le revenu par client et le délai de résolution des problèmes permettent de relier les capacités du traitement automatique du langage naturel (TALN) à des résultats concrets.
Un chatbot de service client peut traiter 10 000 demandes par mois, mais son impact commercial se traduit par une amélioration des scores de satisfaction client et une réduction des coûts de support par client.
Les organisations devraient suivre ces indicateurs de résultats avant et après la mise en œuvre du traitement automatique du langage naturel (TALN), en isolant si possible l'impact des autres changements.
Amélioration continue
Les systèmes de traitement automatique du langage naturel (TALN) nécessitent une surveillance et une amélioration continues. Le langage évolue, les contextes métiers changent et de nouveaux cas particuliers apparaissent. Sans maintenance, les performances du modèle se dégradent.
Un réentraînement régulier avec de nouveaux exemples permet de maintenir les modèles à jour. Des tableaux de bord de surveillance suivent les tendances de précision, les schémas d'erreur et les cas limites nécessitant une attention particulière. Des boucles de rétroaction relient les corrections des utilisateurs aux données d'entraînement, améliorant ainsi les modèles en continu.
Tendances futures du traitement automatique du langage naturel en entreprise
Les capacités en traitement automatique du langage naturel (TALN) continuent de progresser rapidement. Les organisations qui envisagent de les mettre en œuvre devraient prendre en compte les nouvelles fonctionnalités susceptibles de devenir la norme dans les années à venir.
Intégration générative de l'IA
Les grands modèles de langage génèrent désormais des textes de qualité humaine, et non plus seulement les analysent. Les applications métier s'étendent de la compréhension à la création : rédaction d'e-mails, synthèse de rapports, génération de descriptions de produits, création de documentation.
Cette capacité générative transforme les flux de travail. Au lieu de processus purement automatisés ou purement manuels, une collaboration homme-IA émerge. Les systèmes génèrent des ébauches et des suggestions ; les humains les examinent, les peaufinent et les approuvent.
Compréhension multimodale
La communication d'entreprise combine de plus en plus texte, images, audio et vidéo. Les futurs systèmes de traitement automatique du langage naturel (TALN) traiteront ces modalités simultanément plutôt que séparément.
Un système de support client peut analyser simultanément l'audio des appels, la vidéo du partage d'écran et la transcription des conversations, ce qui lui permet de comprendre le problème plus en détail que ne le révèle un seul canal. L'analyse marketing peut traiter les publications sur les réseaux sociaux, y compris les images, les légendes et les commentaires, comme un contenu unifié.
Outils NLP à faible code
La mise en œuvre du traitement automatique du langage naturel (TALN) requiert actuellement une expertise en science des données. Les plateformes émergentes démocratisent l'accès grâce à des interfaces low-code permettant aux utilisateurs métiers de créer des applications TALN simples sans programmation.
Ces outils réduisent les obstacles à l'expérimentation et au déploiement pour les cas d'utilisation simples, même si les applications complexes bénéficient toujours de l'intervention d'experts.
IA explicable
Les modèles opaques soulèvent des problèmes de confiance et de conformité. Les techniques d'IA explicable révèlent pourquoi les modèles font des prédictions spécifiques, en montrant quelles caractéristiques textuelles ont influencé les décisions de classification.
Cette transparence est essentielle pour les secteurs réglementés, les décisions à forts enjeux et la correction des erreurs de modélisation. Les organisations peuvent ainsi vérifier que leurs modèles utilisent des signaux pertinents plutôt que des corrélations fallacieuses.
Défis courants de mise en œuvre
Les organisations rencontrent des obstacles prévisibles lors du déploiement d'applications de traitement automatique du langage naturel (TALN). Anticiper ces difficultés permet une meilleure planification et une atténuation des risques.
Problèmes de qualité des données
Les données textuelles réelles sont souvent complexes. Les fautes de frappe, les abréviations, les incohérences de mise en forme et les données incomplètes nuisent aux performances des modèles. Les organisations sous-estiment souvent l'effort nécessaire pour nettoyer et préparer les données d'entraînement.
La terminologie spécifique au domaine pose des difficultés supplémentaires. Le jargon industriel, les noms de produits et le langage propre à l'entreprise n'apparaissent pas dans les données d'entraînement généralistes. Les modèles doivent apprendre ce vocabulaire spécialisé à partir d'exemples propres au secteur d'activité.
Gestion du changement
La mise en œuvre du traitement automatique du langage naturel (TALN) modifie les flux de travail et les responsabilités professionnelles. Les employés peuvent résister à l'automatisation qu'ils perçoivent comme menaçante ou se méfier des décisions algorithmiques au profit du jugement humain.
Les déploiements réussis intègrent une gestion du changement qui prend en compte ces préoccupations. La communication met l'accent sur l'augmentation des capacités plutôt que sur le remplacement, en démontrant comment l'automatisation élimine les tâches fastidieuses tout en préservant le rôle humain pour les jugements complexes.
Gérer les attentes
Les capacités du traitement automatique du langage naturel sont souvent surestimées. Les parties prenantes s'attendent parfois à une compréhension parfaite, équivalente à celle d'un humain, dès les premiers déploiements. Définir des attentes réalistes en matière de précision permet d'éviter les déceptions.
Les organisations devraient considérer le traitement automatique du langage naturel (TALN) comme un processus d'amélioration continue plutôt que comme une mise en œuvre ponctuelle. La précision initiale peut égaler, voire légèrement dépasser, les performances humaines, mais les systèmes s'améliorent grâce aux retours d'information tout en maintenant une constance que les humains peinent à atteindre.
Gestion des cas limites
Aucun modèle ne peut gérer correctement tous les scénarios. Des cas limites, des entrées inhabituelles et des situations inédites surviendront inévitablement. Les systèmes nécessitent des mécanismes de défaillance progressifs et des procédures d'escalade lorsque la confiance est faible.
La conception avec intervention humaine permet de pallier cette limitation. Les prédictions incertaines sont soumises à des relecteurs humains au lieu d'être traitées automatiquement. Au fil du temps, ces cas limites enrichissent les données d'entraînement, apprenant ainsi aux modèles à gérer des situations inédites.
Questions fréquemment posées
Quelle est la différence entre le NLP et l'analyse de texte traditionnelle ?
L'analyse textuelle traditionnelle repose sur la correspondance de mots-clés et la reconnaissance de formes simples. Le traitement automatique du langage naturel (TALN) comprend le contexte, l'intention et le sens grâce à des modèles d'apprentissage automatique entraînés sur des structures linguistiques. Le TALN reconnaît que “ pas mal ” exprime un sentiment positif malgré la présence du mot négatif “ mauvais ”, alors qu'une analyse de mots-clés le classerait à tort comme négatif. Le TALN gère les synonymes, l'ambiguïté et le contexte d'une manière impossible pour les systèmes à base de règles.
De combien de données d'entraînement un modèle NLP a-t-il besoin ?
Les données d'entraînement nécessaires varient selon la complexité de la tâche et l'architecture du modèle. Les approches d'apprentissage par transfert utilisant des modèles pré-entraînés comme BERT peuvent donner de bons résultats avec quelques centaines d'exemples étiquetés pour des tâches de classification simples. Les applications complexes et spécifiques à un domaine peuvent nécessiter des milliers d'exemples étiquetés. L'essentiel réside dans la qualité et la représentativité des données plutôt que dans leur volume : des exemples diversifiés couvrant les cas limites sont plus importants que des exemples similaires redondants.
Le traitement automatique du langage naturel (TALN) peut-il gérer plusieurs langues pour les entreprises internationales ?
Les modèles de traitement automatique du langage naturel (TALN) modernes prennent en charge des dizaines de langues, mais leurs performances varient selon la langue. Les langues disposant de ressources importantes, comme l'anglais, l'espagnol et le chinois, bénéficient de vastes ensembles de données d'entraînement et de modèles éprouvés. Les langues disposant de moins de ressources peuvent nécessiter une personnalisation plus poussée. Les modèles multilingues peuvent traiter plusieurs langues avec un seul modèle, mais les modèles spécifiques à une langue sont généralement plus performants pour les applications critiques. Les organisations doivent évaluer les performances des modèles en fonction de leurs langues cibles.
Combien de temps prend généralement la mise en œuvre du traitement automatique du langage naturel (TALN) ?
Les délais de mise en œuvre varient de quelques semaines à plusieurs mois selon la complexité du projet, la disponibilité des données et les exigences d'intégration. Le déploiement d'une analyse de sentiments simple, utilisant des outils existants et des données propres, peut être réalisé en 4 à 6 semaines. Les modèles personnalisés complexes, nécessitant une collecte importante de données d'entraînement, un étiquetage précis et une intégration au système d'entreprise, peuvent prendre de 4 à 6 mois. La plupart des projets de traitement automatique du langage naturel (TALN) en entreprise durent entre 2 et 4 mois, incluant la préparation des données, le développement du modèle, les tests et le déploiement.
Quels sont les coûts récurrents liés à la maintenance des systèmes de traitement automatique du langage naturel (TALN) ?
Les coûts de maintenance comprennent l'infrastructure d'hébergement et d'inférence des modèles, le stockage des données, les systèmes de surveillance et le réentraînement périodique. Les services de traitement automatique du langage naturel (TALN) dans le cloud proposent une tarification à l'usage. Les organisations doivent également prévoir un budget pour les mises à jour régulières des modèles, en fonction de l'évolution du langage et du contexte métier. En général, les coûts récurrents représentent entre 15 et 250 milliards de dollars des coûts initiaux de mise en œuvre, mais ce pourcentage varie considérablement selon l'échelle et la complexité du modèle.
Comment s'assurer que les modèles de TAL ne perpétuent pas les biais ?
La réduction des biais commence par l'examen des données d'entraînement, afin de garantir que les exemples représentent des populations et des contextes diversifiés, sans véhiculer de stéréotypes. Les indicateurs d'évaluation doivent mesurer l'équité entre les groupes démographiques, et non la seule précision globale. Des audits réguliers permettent de détecter les prédictions biaisées en production. La diversité des équipes de développement des systèmes de traitement automatique du langage naturel (TALN) contribue à identifier les problèmes de biais potentiels. Les organisations doivent établir des politiques claires pour la gestion des biais détectés et s'engager dans une surveillance continue, plutôt que de se contenter d'un contrôle ponctuel.
Quel taux de précision les entreprises peuvent-elles attendre des applications de traitement automatique du langage naturel (TALN) ?
Les attentes en matière de précision dépendent de la difficulté de la tâche et des performances humaines de référence. La classification de documents atteint souvent une précision de 90 à 95 % (TP3T) pour des catégories bien définies. L'analyse des sentiments se situe généralement entre 80 et 90 % (TP3T) selon la spécificité du domaine et les nuances requises. L'extraction d'entités nommées atteint 85 à 95 % (TP3T) pour les types d'entités courants. Les organisations devraient comparer leurs performances à celles d'humains sur la même tâche : si des employés formés atteignent un niveau de concordance de 85 % (TP3T), il est irréaliste d'attendre 95 % (TP3T) du traitement automatique du langage naturel (TALN). L'essentiel est de savoir si la précision du TALN répond aux besoins de l'entreprise, et non de rechercher la perfection.
Conclusion
Le traitement automatique du langage naturel (TALN) transforme les opérations commerciales en automatisant les processus textuels, en extrayant des informations pertinentes à partir de données non structurées et en améliorant l'expérience client à grande échelle. Ses applications couvrent le service client, les opérations, l'intelligence de marché, la conformité et les ressources humaines – en bref, toute fonction commerciale impliquant le langage humain.
Les organisations qui mettent en œuvre avec succès le NLP bénéficient d'avantages mesurables : réduction des coûts opérationnels grâce à l'automatisation, prise de décision plus rapide grâce à l'analyse en temps réel, meilleure compréhension des clients grâce au traitement à grande échelle des commentaires qualitatifs et atténuation des risques grâce à une surveillance constante de la conformité.
Cette technologie a dépassé le stade de la recherche pour devenir un système opérationnel en production. Des modèles légers comme DistilBERT offrent d'excellentes performances tout en répondant aux exigences de déploiement les plus pratiques. Les plateformes cloud et les modèles pré-entraînés facilitent la mise en œuvre. Sa valeur ajoutée pour les entreprises est avérée dans de nombreux secteurs.
Mais le succès ne se résume pas au choix de la technologie. Les organisations doivent investir dans des données de formation de qualité, adapter les modèles aux contextes métiers, les intégrer aux flux de travail existants et assurer la maintenance des systèmes en fonction de l'évolution des besoins linguistiques et commerciaux. Une gestion du changement qui prend en compte les préoccupations des employés et des attentes réalistes en matière de précision permet d'éviter toute déception.
La question n'est plus de savoir si le traitement automatique du langage naturel (TALN) apporte une valeur ajoutée aux entreprises – les preuves sont accablantes. Il s'agit plutôt de déterminer quelles applications offrent le meilleur impact pour répondre aux besoins spécifiques des organisations et comment les mettre en œuvre efficacement.
Les organisations qui s'appuient encore exclusivement sur le traitement manuel du texte se retrouvent de plus en plus désavantagées face à la concurrence, leurs rivales tirant parti du traitement automatique du langage naturel (TALN) pour gagner en rapidité, en envergure et en perspicacité. Il est temps d'explorer les applications du TALN pour votre entreprise.
Commencez par un cas d'usage ciblé répondant à un besoin précis, investissez dans la préparation des données et la personnalisation du modèle, mesurez l'impact à l'aide d'indicateurs concrets et capitalisez sur vos succès avérés. Cette approche pragmatique permet de développer des compétences en traitement automatique du langage naturel (TALN) qui offrent un avantage concurrentiel durable.