Résumé rapide : L'apprentissage profond est une branche spécialisée de l'apprentissage automatique qui utilise des réseaux neuronaux multicouches pour apprendre automatiquement des modèles complexes à partir de données brutes. L'apprentissage automatique est un domaine plus vaste de l'IA qui englobe l'apprentissage profond ainsi que les algorithmes traditionnels nécessitant des caractéristiques conçues manuellement. La principale distinction : l'apprentissage automatique requiert une ingénierie manuelle des caractéristiques et fonctionne bien avec des ensembles de données de petite taille, tandis que l'apprentissage profond extrait automatiquement les caractéristiques, mais exige de grandes quantités de données et une puissance de calcul importante.
Dans le milieu technologique, les termes « apprentissage automatique » et « apprentissage profond » sont souvent utilisés indifféremment. Pourtant, il est important de comprendre cette distinction, que l'on développe des systèmes d'IA ou que l'on cherche simplement à comprendre le fonctionnement des technologies modernes.
Toutes deux relèvent de l'intelligence artificielle. Toutes deux apprennent à partir de données. Pourtant, leur approche des problèmes, leur traitement de l'information et leur manière de produire des résultats diffèrent fondamentalement.
Selon Stanford HAI, l'apprentissage profond est une branche de l'apprentissage automatique qui utilise de vastes réseaux neuronaux multicouches pour apprendre automatiquement des modèles complexes à partir de données. Au lieu qu'une personne programme manuellement les caractéristiques à rechercher, ces modèles découvrent par eux-mêmes des représentations de plus en plus abstraites.
Cela vous semble familier ? C’est parce que l’apprentissage profond alimente l’assistant vocal de votre téléphone, le moteur de recommandation des plateformes de streaming et les modèles de langage qui redéfinissent notre façon de travailler.
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique est une méthodologie de l'intelligence artificielle où les systèmes apprennent à partir de données sans être explicitement programmés pour chaque scénario. Plutôt que d'écrire des règles pour chaque entrée possible, les développeurs entraînent des modèles à reconnaître des schémas et à faire des prédictions à partir d'exemples.
Cette approche repose sur des algorithmes qui s'améliorent grâce à l'expérience. Il suffit de fournir à un modèle d'apprentissage automatique suffisamment de données étiquetées (par exemple, des courriels marqués comme spam ou non spam) pour qu'il apprenne à classer lui-même les nouveaux courriels.
Mais il y a un hic. L'apprentissage automatique traditionnel nécessite une ingénierie des caractéristiques : un processus où les humains sélectionnent et conçoivent manuellement les caractéristiques des données que le modèle doit examiner. Pour la reconnaissance d'images, cela peut impliquer de programmer le système pour qu'il recherche des contours, des angles ou des motifs de couleur spécifiques.
Cette intervention humaine influence l'apprentissage du modèle. Un mauvais choix de caractéristiques nuit aux performances. Un choix judicieux permet même à des algorithmes relativement simples d'obtenir d'excellents résultats sur des données structurées.
Types d'apprentissage automatique
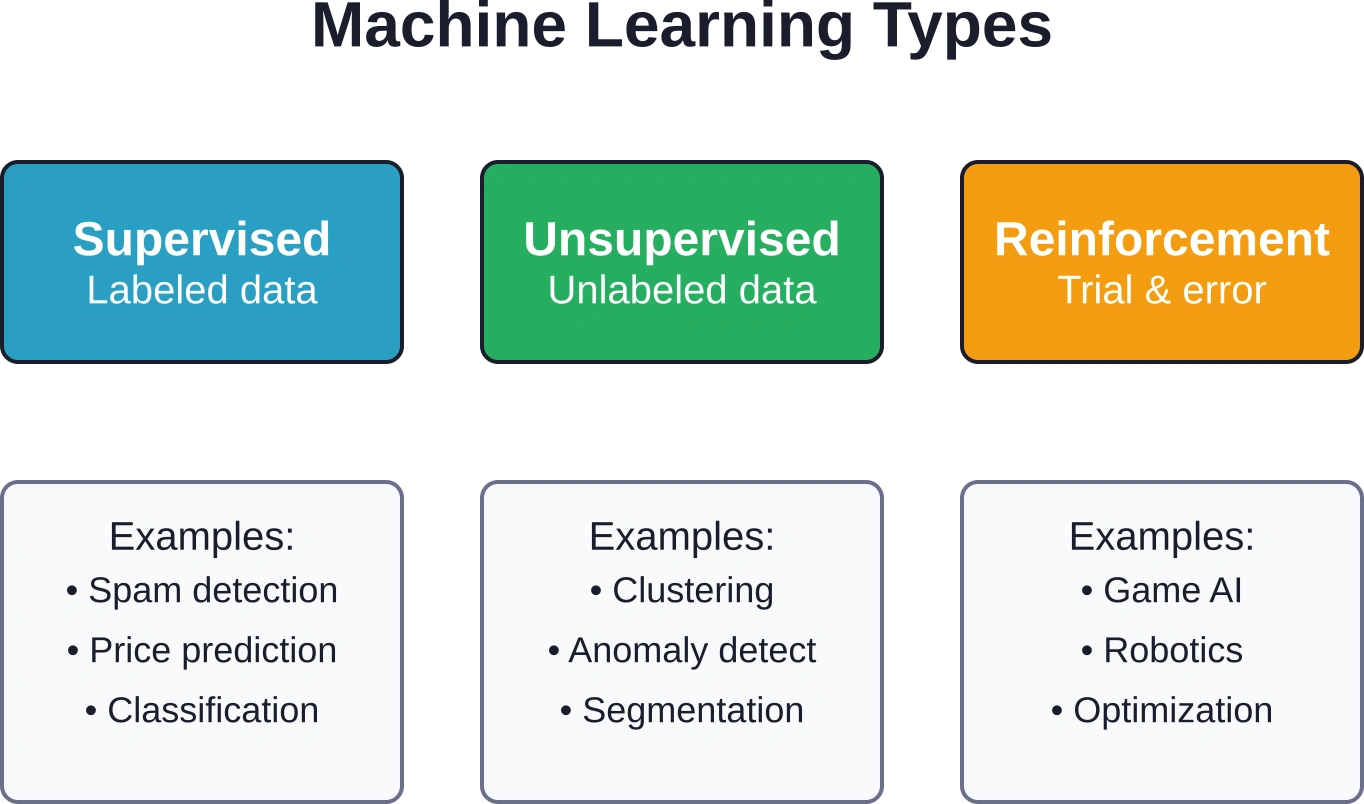
L'apprentissage automatique se divise en trois grandes catégories selon la façon dont l'algorithme apprend :
- L'apprentissage supervisé s'appuie sur des données étiquetées dont la réponse correcte est connue. Le modèle apprend à associer des entrées à des sorties, par exemple pour prédire le prix d'une maison en fonction de sa superficie, de son emplacement et de son ancienneté. La plupart des applications commerciales relèvent de cette catégorie.
- L'apprentissage non supervisé fonctionne avec des données non étiquetées, décelant des tendances cachées sans catégories prédéfinies. Le regroupement des clients selon leurs comportements d'achat ou la détection d'anomalies dans le trafic réseau illustrent cette approche.
- L'apprentissage par renforcement repose sur la méthode des essais et erreurs, avec des récompenses ou des sanctions selon les actions entreprises. Les systèmes d'IA et les robots utilisés dans les jeux vidéo ont souvent recours à cette méthode, bien qu'elle soit moins courante dans les contextes commerciaux traditionnels.
Qu'est-ce que l'apprentissage profond ?
L'apprentissage profond pousse l'apprentissage automatique plus loin en utilisant des réseaux neuronaux à plusieurs couches, d'où le terme “ profond ”. Ces réseaux sont constitués de nœuds interconnectés (neurones) organisés en couches qui traitent les données séquentiellement, chaque couche extrayant des caractéristiques de plus en plus complexes.
L'architecture reflète la manière dont les chercheurs comprennent le fonctionnement du cerveau humain, même si l'analogie biologique a ses limites. Concrètement, l'important est que les modèles d'apprentissage profond puissent découvrir automatiquement, à partir de données brutes, les représentations nécessaires à la détection de caractéristiques.
Aucune ingénierie manuelle des caractéristiques n'est requise. Il suffit d'alimenter un système d'apprentissage profond avec des images brutes ; il apprendra de lui-même à reconnaître les contours dans les premières couches, les formes dans les couches intermédiaires et les objets complets dans les couches profondes.
Cet apprentissage automatique des caractéristiques rend l'apprentissage profond particulièrement puissant pour les données non structurées (images, audio, texte, vidéo). Des tâches qui ont déconcerté l'apprentissage automatique traditionnel pendant des décennies sont soudainement devenues réalisables.
Explication des réseaux neuronaux
Au cœur de l'apprentissage profond se trouve le réseau neuronal. On peut le considérer comme une série de couches de traitement, chacune contenant plusieurs nœuds qui effectuent des opérations mathématiques sur les données entrantes.
L'information circule dans le réseau. Chaque connexion entre les nœuds possède un poids qui est ajusté lors de l'apprentissage. Le réseau apprend en ajustant ces poids afin de minimiser les erreurs de prédiction — un processus appelé rétropropagation.
Les réseaux de neurones superficiels peuvent comporter une ou deux couches cachées entre l'entrée et la sortie. Les réseaux profonds, quant à eux, empilent des dizaines, voire des centaines de couches, ce qui leur permet de modéliser des relations extrêmement complexes.
Cette profondeur a un prix : une forte intensité de calcul. L'entraînement des réseaux neuronaux profonds exige une puissance de calcul considérable, ce qui explique l'essor fulgurant de ce domaine parallèlement aux progrès du calcul sur GPU.
Principales différences entre l'apprentissage automatique et l'apprentissage profond
C’est là que ça devient intéressant. Bien que l’apprentissage profond fasse partie de l’apprentissage automatique, plusieurs différences fondamentales les distinguent en pratique.
Exigences en matière de données
Les algorithmes d'apprentissage automatique traditionnels sont performants même avec des ensembles de données restreints, parfois de simples milliers d'exemples. Les méthodes statistiques telles que les arbres de décision, les forêts aléatoires ou les machines à vecteurs de support permettent d'extraire des tendances significatives à partir de données limitées.
L'apprentissage profond exige de grandes quantités de données. Les réseaux neuronaux contiennent des millions de paramètres qui nécessitent un réglage précis, ce qui requiert des ensembles de données massifs pour un entraînement efficace. Si l'on fournit trop peu de données à un modèle d'apprentissage profond, il surapprend : il mémorise alors les exemples d'entraînement au lieu d'apprendre des schémas généralisables.
Les rapports de l'industrie indiquent que l'apprentissage profond nécessite généralement des dizaines de milliers, voire des millions d'exemples étiquetés pour atteindre des performances optimales, bien que les techniques d'apprentissage par transfert puissent réduire ce besoin.
Ingénierie des fonctionnalités
C’est à ce moment que la charge de travail change radicalement. Les spécialistes du machine learning consacrent un temps considérable à l’ingénierie des caractéristiques : la sélection, la transformation et la création des variables d’entrée que leurs modèles utiliseront.
Vous disposez de données clients ? Les développeurs peuvent créer des fonctionnalités telles que “ jours écoulés depuis le dernier achat ”, “ valeur moyenne des commandes ” ou “ fréquence d’achat ” avant le début de l’entraînement. Cette expertise du domaine influence les performances du modèle.
L'apprentissage profond automatise ce processus. Les couches du réseau neuronal apprennent les caractéristiques de manière hiérarchique pendant l'entraînement. Cela réduit l'effort humain, mais implique un compromis : un contrôle moindre sur ce que le modèle apprend réellement.
Ressources informatiques
Exécuter un modèle d'apprentissage automatique sur votre ordinateur portable ? Absolument. De nombreux algorithmes traditionnels s'entraînent rapidement sur du matériel standard, ce qui les rend accessibles et pratiques pour les environnements aux ressources limitées.
Les modèles d'apprentissage profond sont extrêmement gourmands en ressources de calcul. L'entraînement des réseaux les plus performants nécessite du matériel spécialisé (GPU ou TPU) et peut prendre des jours, voire des semaines, même sur des systèmes puissants. Les coûts d'exploitation s'en trouvent donc majorés.
L'inférence (à l'aide d'un modèle entraîné) diffère également. Les modèles d'apprentissage automatique fournissent généralement des prédictions en quelques millisecondes sur du matériel standard. Les grands modèles d'apprentissage profond peuvent nécessiter une infrastructure dédiée pour répondre aux exigences de latence en temps réel.
Interprétabilité
Les modèles d'apprentissage automatique, notamment les plus simples comme les arbres de décision ou la régression linéaire, offrent une grande transparence. Les développeurs peuvent ainsi retracer précisément le raisonnement derrière une prédiction donnée, ce qui est essentiel dans les secteurs réglementés ou pour les décisions à forts enjeux.
L'apprentissage profond fonctionne comme une boîte noire. Avec des millions de poids répartis sur des dizaines de couches, comprendre pourquoi un réseau neuronal a fait un choix particulier devient quasiment impossible. La recherche sur l'IA explicable tente de remédier à ce problème, mais l'interprétabilité demeure un défi persistant.
Une étude du MIT publiée en décembre 2021 a mis en lumière un problème : les réseaux neuronaux entraînés sur des ensembles de données comme CIFAR-10 effectuaient des prédictions fiables même lorsque 95 % des images d'entrée étaient manquantes, les images restantes étant inintelligibles pour l'humain. Cette surinterprétation soulève des questions quant à la fiabilité des prédictions dans les applications critiques.
Compromis en matière de performance
Pour les données structurées et tabulaires (comme les feuilles de calcul avec des lignes et des colonnes), l'apprentissage automatique traditionnel s'avère souvent plus performant. Les arbres de décision, le gradient boosting et les méthodes similaires surpassent fréquemment les réseaux de neurones pour ces tâches, tout en s'entraînant plus rapidement et en nécessitant moins de données.
L'apprentissage profond domine le traitement des données non structurées. La reconnaissance d'images, le traitement automatique du langage naturel et la reconnaissance vocale ont connu des progrès révolutionnaires grâce à la maturité de l'apprentissage profond. Les recherches indiquent que l'apprentissage profond peut atteindre une précision supérieure pour les tâches d'imagerie par rapport à l'apprentissage automatique traditionnel, certaines études montrant des différences de performance de cet ordre de grandeur.
L'écart se creuse à mesure que la complexité de la tâche augmente. Une classification simple peut se prêter aux approches traditionnelles. La reconnaissance de formes complexes dans des données de grande dimension s'oriente plutôt vers l'apprentissage profond.

Choisissez la bonne approche en IA avec AI Superior
La question de l'opposition entre apprentissage profond et apprentissage automatique ne se limite pas à un aspect technique. Elle influe sur les besoins en données, le temps de développement, la complexité du modèle et l'utilisation concrète de la solution. IA supérieure Nous aidons les entreprises à comparer les approches d'IA grâce à nos services de conseil, d'apprentissage automatique, d'apprentissage profond, d'analyse prédictive, de traitement automatique du langage naturel (TALN), de vision par ordinateur et de développement de logiciels d'IA sur mesure. Avant toute mise en œuvre, nos équipes peuvent analyser le cas d'usage, les données disponibles et les résultats attendus. Cela permet aux entreprises d'éviter un modèle trop complexe tout en conservant la possibilité d'intégrer des solutions d'IA plus avancées lorsque le problème l'exige.
AI Superior peut aider à évaluer :
- Que l'apprentissage automatique ou l'apprentissage profond convienne à la tâche
- Exigences en matière de données pour différents types de modèles
- Cas d'utilisation et options de modélisation de l'analyse prédictive
- Applications de l'apprentissage profond dans les flux de travail de vision ou de langage
- Intégration de modèles d'IA sélectionnés dans un logiciel personnalisé
👉Contactez l'IA supérieure pour discuter de l'approche d'IA la mieux adaptée à votre projet, à vos données ou aux exigences de votre produit.
Applications pratiques et cas d'utilisation
Soyons francs : choisir entre l’apprentissage automatique et l’apprentissage profond ne consiste pas à déterminer lequel est “ meilleur ”, mais à adapter l’outil au problème.
Quand l'apprentissage automatique brille
Les problèmes liés aux données structurées se prêtent mieux à l'apprentissage automatique traditionnel. Prédire le taux de désabonnement des clients, détecter la fraude à la carte de crédit, prévoir les ventes ou recommander des produits en fonction de l'historique d'achat : ces scénarios impliquent généralement des données tabulaires où les relations sont relativement directes.
Les situations où les données sont limitées plaident également en faveur de l'apprentissage automatique. Comment entraîner un modèle avec seulement quelques centaines d'exemples ? L'apprentissage profond aura du mal. Des algorithmes comme les forêts aléatoires ou le gradient boosting peuvent extraire des tendances significatives à partir de petits ensembles de données.
Besoin d'interprétabilité ? L'apprentissage automatique apporte la solution. Les institutions financières utilisent des arbres de décision pour l'octroi de prêts, car les organismes de réglementation exigent des explications concernant les décisions de crédit. Le diagnostic médical en tire un avantage similaire : les médecins souhaitent comprendre pourquoi un modèle a identifié un risque particulier.
Quand l'apprentissage profond domine
La reconnaissance d'images a été transformée par la maturation de l'apprentissage profond. Reconnaissance faciale, analyse d'images médicales, systèmes de vision pour véhicules autonomes, contrôle qualité en production : les réseaux neuronaux convolutifs ont révolutionné ces domaines.
Le traitement automatique du langage naturel a connu des progrès similaires. La traduction automatique, l'analyse des sentiments, les chatbots et la synthèse de documents ont tous bénéficié d'améliorations spectaculaires grâce aux architectures d'apprentissage profond telles que les transformeurs. Les modèles de langage qui redéfiniront les communications d'entreprise en 2026 reposent entièrement sur des réseaux neuronaux profonds.
La reconnaissance vocale, autrefois d'une imprécision frustrante, est devenue fiable grâce à l'apprentissage profond. Les assistants vocaux, les services de transcription et les outils d'accessibilité exploitent tous des réseaux récurrents ou convolutionnels entraînés sur d'immenses ensembles de données audio.
L'analyse vidéo, la détection d'anomalies dans les systèmes complexes et l'IA générative (création de nouvelles images, de textes ou d'audio) dépendent toutes de la capacité de l'apprentissage profond à modéliser des schémas complexes dans des données multidimensionnelles.
Choisir la bonne approche
Comment les praticiens font-ils leur choix ? Plusieurs facteurs guident cette décision :
- Le volume de données est le facteur le plus important : Vous avez des millions d'exemples ? L'apprentissage profond devient une option viable. Vous travaillez avec des centaines ou des milliers d'exemples ? Privilégiez l'apprentissage automatique traditionnel.
- Le type de données influence la décision : Les données structurées et tabulaires se prêtent davantage à l'apprentissage automatique. Les images, le texte, l'audio ou la vidéo orientent quant à eux vers l'apprentissage profond.
- Les contraintes liées aux ressources ne peuvent être ignorées : Un budget et une puissance de calcul limités favorisent l'efficacité de l'apprentissage automatique. L'accès aux GPU et le temps nécessaire à des entraînements longs ouvrent la voie à l'apprentissage profond.
- Les exigences de précision face à l'interprétabilité créent une tension : Besoin d'une précision maximale pour une tâche complexe ? L'apprentissage profond, malgré son côté opaque, peut justifier son fonctionnement. Besoin de transparence et d'explicabilité ? Les modèles plus simples de l'apprentissage automatique offrent une meilleure clarté.
- La disponibilité d'experts du domaine influence la faisabilité de l'ingénierie des fonctionnalités : Les experts du domaine peuvent concevoir des fonctionnalités efficaces pour l'apprentissage automatique. En l'absence de connaissances approfondies du domaine, il est préférable de laisser l'apprentissage profond découvrir automatiquement les fonctionnalités.
| Considération | Apprentissage automatique | L'apprentissage en profondeur |
|---|---|---|
| Taille de l'ensemble de données | Des centaines, voire des milliers | Des milliers à des millions |
| Type de données | Structuré/tabulaire | Non structuré (image/texte/audio) |
| Temps d'entraînement | Quelques minutes à quelques heures | De quelques heures à plusieurs semaines |
| Besoins en matériel | Processeur standard | GPU/TPU préféré |
| Ingénierie des fonctionnalités | Manuel, piloté par le domaine | Automatique, appris |
| Interprétabilité | Élevée (surtout les modèles simples) | Faible (boîte noire) |
La relation avec l'intelligence artificielle
L'apprentissage automatique et l'apprentissage profond s'inscrivent tous deux dans le vaste domaine de l'intelligence artificielle. L'IA englobe toute technique permettant aux ordinateurs d'imiter l'intelligence humaine, y compris les systèmes à base de règles qui n'apprennent pas du tout.
L'apprentissage automatique représente un sous-ensemble de l'IA axé sur l'apprentissage à partir des données. L'apprentissage profond, quant à lui, est un sous-ensemble de l'apprentissage automatique utilisant des réseaux neuronaux à plusieurs couches.
La hiérarchie est la suivante : l’IA englobe l’apprentissage automatique, qui englobe l’apprentissage profond. Tout apprentissage profond est une forme d’apprentissage automatique, mais l’inverse n’est pas vrai. Tout apprentissage automatique est une forme d’IA, mais l’inverse n’est pas vrai.
D'après une étude du MIT Sloan, environ 351 millions d'entreprises dans le monde utilisaient l'IA lors de récentes enquêtes, tandis que 421 millions d'autres exploraient cette technologie. Le développement de l'IA générative, qui s'appuie sur de puissants modèles d'apprentissage profond, a accéléré son adoption depuis 2022.
Mais attention ! Cela ne signifie pas que l’apprentissage profond a remplacé l’apprentissage automatique. Chaque outil a ses propres objectifs. De nombreux systèmes de production combinent les deux approches, utilisant l’apprentissage automatique traditionnel pour les pipelines de données structurées et l’apprentissage profond pour les données non structurées.
Tendances actuelles et orientations futures
Le domaine est en constante évolution. L'apprentissage par transfert réduit la consommation de données de l'apprentissage profond en utilisant des modèles pré-entraînés et en les affinant pour des tâches spécifiques, ne nécessitant parfois que quelques centaines d'exemples au lieu de millions.
Les techniques de compression de modèles rendent l'apprentissage profond plus accessible, en réduisant la taille des réseaux pour qu'ils fonctionnent sur des appareils mobiles ou du matériel informatique de périphérie sans surcharge de calcul massive.
Les plateformes AutoML automatisent la sélection des modèles et le réglage des hyperparamètres pour l'apprentissage automatique et l'apprentissage profond, réduisant ainsi la barrière d'expertise nécessaire à leur mise en œuvre.
Les approches hybrides combinent l'interprétabilité de l'apprentissage automatique traditionnel avec la puissance de reconnaissance de formes de l'apprentissage profond. Les chercheurs explorent des réseaux neuronaux capables d'expliquer leurs décisions ou d'intégrer des connaissances du domaine grâce à des architectures structurées.
L'IA générative, technologie à la base d'outils comme ChatGPT, représente la dernière frontière de l'apprentissage profond. Elle crée du contenu entièrement nouveau au lieu de se contenter de classifier ou de prédire. Ce sous-ensemble utilise des architectures de type Transformer et d'immenses ensembles de données pour générer du texte, des images, du code, et bien plus encore.
Questions fréquemment posées
L'apprentissage profond est-il meilleur que l'apprentissage automatique ?
Aucune des deux n'est universellement supérieure ; elles excellent dans des domaines différents. L'apprentissage profond est plus performant sur les données non structurées complexes, comme les images et le texte, lorsque de grands ensembles de données sont disponibles. L'apprentissage automatique traditionnel l'emporte souvent sur les données structurées, les petits ensembles de données et les scénarios exigeant une interprétabilité ou des ressources de calcul limitées.
L'apprentissage profond nécessite-t-il des connaissances en programmation ?
La création de modèles d'apprentissage profond à partir de zéro exige des compétences en programmation, généralement en Python avec des frameworks comme TensorFlow ou PyTorch. Cependant, des plateformes sans code et à faible code existent désormais, permettant l'entraînement et le déploiement de modèles via des interfaces visuelles, rendant ainsi l'apprentissage profond plus accessible aux non-programmeurs.
De combien de données l'apprentissage profond a-t-il besoin par rapport à l'apprentissage automatique ?
L'apprentissage automatique traditionnel fonctionne efficacement avec des centaines, voire des milliers, d'exemples d'entraînement. L'apprentissage profond, quant à lui, requiert généralement au moins des dizaines de milliers d'exemples, les modèles les plus performants étant souvent entraînés sur des millions, voire des milliards, de points de données. Les techniques d'apprentissage par transfert permettent de réduire considérablement ces exigences.
L'apprentissage automatique et l'apprentissage profond peuvent-ils fonctionner ensemble ?
Absolument. De nombreux systèmes de production combinent ces deux approches de manière complémentaire. Les équipes peuvent utiliser l'apprentissage automatique traditionnel pour les caractéristiques des données structurées tout en appliquant l'apprentissage profond au traitement des images ou du texte, puis combiner les prédictions des deux modèles pour les décisions finales.
Que devrais-je apprendre en premier en tant que débutant ?
Commencer par l'apprentissage automatique traditionnel offre des bases plus solides. Les concepts mathématiques, les méthodes d'évaluation et les principes de fonctionnement s'appliquent aux deux domaines. Une fois les fondamentaux de l'apprentissage automatique maîtrisés, la transition vers l'apprentissage profond devient plus intuitive, car elle repose sur les mêmes idées de base.
Les réseaux neuronaux sont-ils toujours plus performants que les algorithmes traditionnels ?
Absolument pas. Sur des données tabulaires structurées, des algorithmes comme le gradient boosting ou les forêts aléatoires égalent, voire surpassent, les performances des réseaux de neurones, tout en étant plus rapides à entraîner et en nécessitant moins de données. Les réseaux de neurones démontrent leur efficacité sur les données non structurées, là où les méthodes traditionnelles peinent.
Combien de temps faut-il pour entraîner un modèle d'apprentissage profond ?
Le temps d'entraînement varie énormément en fonction de la taille du modèle, de la taille de l'ensemble de données et du matériel utilisé. Les réseaux simples peuvent s'entraîner en quelques minutes sur un ordinateur portable. Les grands modèles de langage ou les systèmes de vision par ordinateur peuvent nécessiter des jours, voire des semaines, sur des clusters de GPU spécialisés. Les modèles d'apprentissage automatique traditionnels s'entraînent généralement beaucoup plus rapidement, souvent en quelques minutes ou quelques heures.
Aller de l'avant
Comprendre la différence entre l'apprentissage automatique et l'apprentissage profond permet de déterminer quelle approche convient le mieux à chaque problème. L'apprentissage automatique offre polyvalence, efficacité et interprétabilité pour les données structurées et les environnements aux ressources limitées. L'apprentissage profond, quant à lui, permet d'atteindre des performances exceptionnelles sur des données non structurées complexes lorsque des ressources de calcul importantes et de vastes ensembles de données sont disponibles.
Il ne s'agit pas de suivre les tendances, mais d'adapter les capacités aux besoins. Certaines équipes se lancent dans l'apprentissage profond parce qu'il est à la pointe de la technologie, puis découvrent que l'apprentissage automatique traditionnel aurait permis d'obtenir de meilleurs résultats plus rapidement. D'autres s'en tiennent à des méthodes familières alors que l'apprentissage profond pourrait résoudre des problèmes auparavant insolubles.
Ces deux domaines continuent de progresser rapidement. Se tenir informé de leurs points forts respectifs aide les développeurs, les data scientists et les dirigeants d'entreprise à prendre des décisions technologiques plus éclairées.
Prêt à mettre ces concepts en pratique ? Commencez par analyser votre cas d’usage spécifique : type de données, volume, exigences de précision et contraintes de ressources. L’outil le plus adapté deviendra évident une fois que vous aurez compris les avantages réels de chaque approche.