ملخص سريع: التعلم العميق هو فرع متخصص من التعلم الآلي، يستخدم الشبكات العصبية متعددة الطبقات لتعلم الأنماط المعقدة تلقائيًا من البيانات الخام. أما التعلم الآلي فهو مجال أوسع في الذكاء الاصطناعي، يشمل التعلم العميق بالإضافة إلى الخوارزميات التقليدية التي تتطلب خصائص مصممة يدويًا. والفرق الأساسي هو أن التعلم الآلي يحتاج إلى هندسة يدوية للخصائص، ويعمل بكفاءة مع مجموعات البيانات الصغيرة، بينما يستخرج التعلم العميق الخصائص تلقائيًا، ولكنه يتطلب كميات هائلة من البيانات وقدرة حاسوبية كبيرة.
يُستخدم مصطلحا "التعلم الآلي" و"التعلم العميق" بشكل متبادل في الأوساط التقنية. لكن في الحقيقة، ليسا متطابقين، وفهم هذا الفرق مهمٌّ سواءً كنتَ تُنشئ أنظمة ذكاء اصطناعي أو تحاول فهم ما يُشغّل التكنولوجيا الحديثة.
كلاهما يندرج تحت مظلة الذكاء الاصطناعي. وكلاهما يتعلم من البيانات. ومع ذلك، فإن طريقة معالجتهما للمشاكل، وتعاملهما مع المعلومات، وتقديمهما للنتائج تختلف اختلافاً جوهرياً.
بحسب معهد ستانفورد للذكاء الاصطناعي البشري، يُعدّ التعلّم العميق فرعاً من فروع التعلّم الآلي، يستخدم شبكات عصبية متعددة الطبقات ضخمة لتعلم الأنماط المعقدة من البيانات تلقائياً. فبدلاً من أن يقوم شخص ما ببرمجة الميزات التي يبحث عنها يدوياً، تكتشف هذه النماذج تمثيلات أكثر تجريداً من تلقاء نفسها.
هل يبدو هذا مألوفاً؟ ذلك لأن التعلم العميق هو ما يشغل المساعد الصوتي على هاتفك، ومحرك التوصيات على منصات البث، ونماذج اللغة التي تعيد تشكيل طريقة عملنا.
ما هو التعلم الآلي؟
التعلم الآلي هو منهجية ضمن الذكاء الاصطناعي، حيث تتعلم الأنظمة من البيانات دون الحاجة إلى برمجتها بشكل صريح لكل سيناريو. فبدلاً من كتابة قواعد لكل مدخل محتمل، يقوم المطورون بتدريب النماذج على التعرف على الأنماط والتنبؤ بناءً على الأمثلة.
يعتمد هذا النهج على خوارزميات تتحسن من خلال التجربة. قم بتزويد نموذج التعلم الآلي بكمية كافية من البيانات المصنفة - على سبيل المثال، رسائل البريد الإلكتروني المصنفة على أنها بريد مزعج أو غير مزعج - وسيتعلم تصنيف رسائل البريد الإلكتروني الجديدة بنفسه.
لكن ثمة مشكلة. يتطلب التعلم الآلي التقليدي هندسة الميزات، وهي عملية يقوم فيها البشر باختيار وتصميم خصائص البيانات التي يجب على النموذج فحصها يدويًا. بالنسبة للتعرف على الصور، قد يعني ذلك برمجة النظام للبحث عن الحواف أو الزوايا أو أنماط ألوان محددة.
يُؤثر هذا التدخل البشري على ما يتعلمه النموذج. فإذا تم اختيار السمات الخاطئة، يتأثر الأداء سلبًا. أما إذا تم اختيارها بشكل صحيح، فيمكن حتى للخوارزميات البسيطة نسبيًا أن تُحقق نتائج جيدة على البيانات المنظمة.
أنواع التعلم الآلي
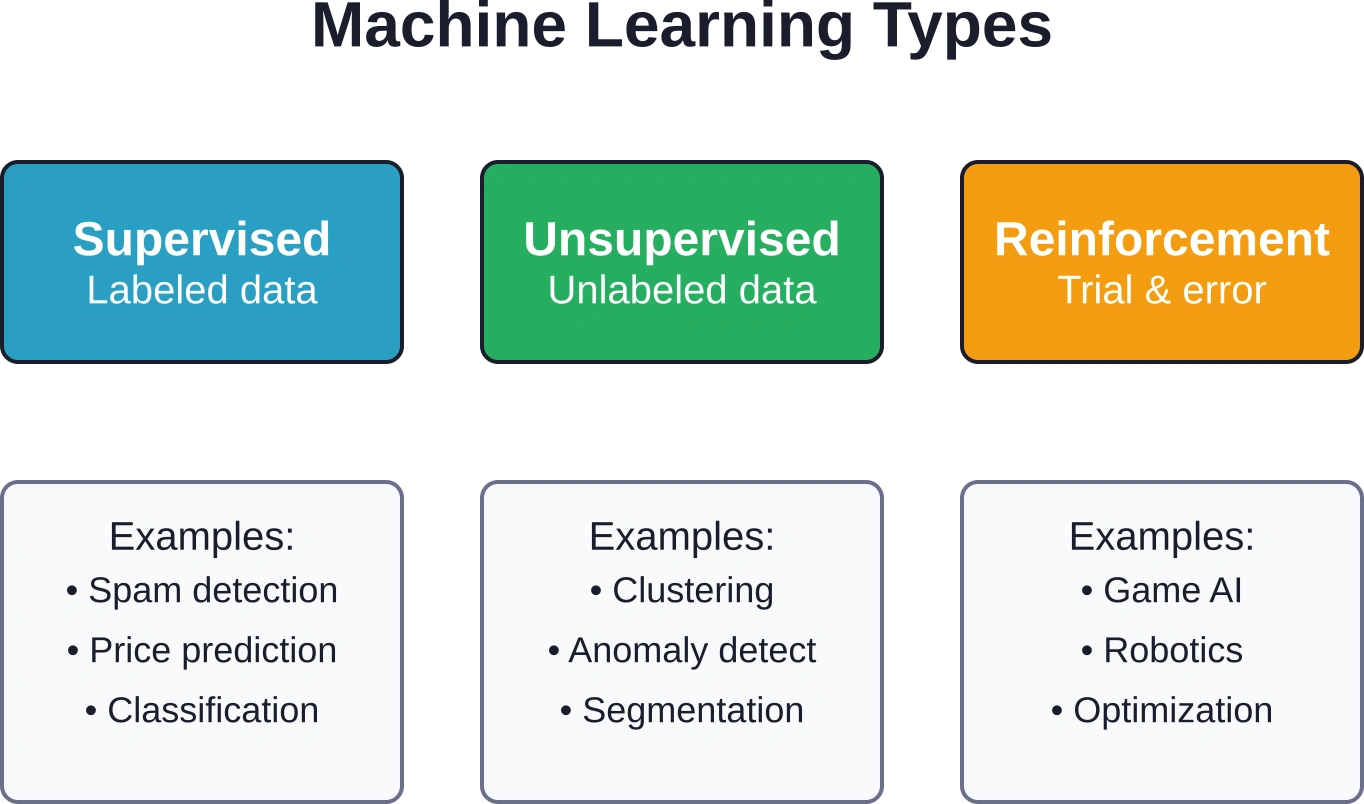
ينقسم التعلم الآلي إلى ثلاث فئات رئيسية بناءً على كيفية تعلم الخوارزمية:
- يعتمد التعلم الخاضع للإشراف على بيانات مصنفة حيث تكون الإجابة الصحيحة معروفة. ويتعلم النموذج ربط المدخلات بالمخرجات، مثل التنبؤ بأسعار المنازل بناءً على المساحة والموقع والعمر. وتندرج معظم تطبيقات الأعمال ضمن هذه الفئة.
- يعتمد التعلم غير الخاضع للإشراف على البيانات غير المصنفة، حيث يكتشف أنماطًا خفية دون وجود فئات محددة مسبقًا. ويُعدّ تجميع العملاء حسب سلوك الشراء أو اكتشاف الحالات الشاذة في حركة مرور الشبكة مثالًا على هذا النهج.
- يعتمد التعلم المعزز على التجربة والخطأ، حيث يتلقى المتعلم مكافآت أو عقوبات بناءً على الإجراءات المتخذة. غالبًا ما تستخدم تطبيقات الذكاء الاصطناعي والروبوتات التي تلعب الألعاب هذه الطريقة، على الرغم من أنها أقل شيوعًا في سياقات الأعمال التقليدية.
ما هو التعلم العميق؟
يأخذ التعلم العميق التعلم الآلي إلى أبعد من ذلك باستخدام الشبكات العصبية ذات الطبقات المتعددة - ومن هنا جاءت تسميتها بـ "العميقة". تتكون هذه الشبكات من عقد مترابطة (خلايا عصبية) منظمة في طبقات تعالج البيانات بشكل متسلسل، حيث تستخرج كل طبقة ميزات أكثر تعقيدًا.
يعكس هذا التصميم المعماري فهم الباحثين لكيفية معالجة الدماغ البشري للمعلومات، مع أن التشبيه البيولوجي له حدود. والأهم عمليًا هو قدرة نماذج التعلم العميق على اكتشاف التمثيلات اللازمة لاستخلاص السمات من البيانات الخام تلقائيًا.
لا حاجة إلى هندسة الميزات اليدوية. قم بتغذية نظام التعلم العميق بالصور الخام، وسيتعلم النظام بنفسه التعرف على الحواف في الطبقات المبكرة، والأشكال في الطبقات المتوسطة، والأجسام الكاملة في الطبقات العميقة.
يُضفي هذا التعلم التلقائي للميزات قوةً هائلةً على التعلم العميق، خاصةً مع البيانات غير المهيكلة - كالصور والصوت والنصوص والفيديو. أصبحت المهام التي عجزت عنها تقنيات التعلم الآلي التقليدية لعقودٍ من الزمن قابلةً للتنفيذ فجأةً.
شرح الشبكات العصبية
يكمن جوهر التعلم العميق في الشبكة العصبية. تخيلها كسلسلة من طبقات المعالجة، تحتوي كل منها على عقد متعددة تقوم بإجراء عمليات حسابية على البيانات الواردة.
تتدفق المعلومات للأمام عبر الشبكة. لكل اتصال بين العقد وزن يتم تعديله أثناء التدريب. تتعلم الشبكة من خلال ضبط هذه الأوزان لتقليل أخطاء التنبؤ - وهي عملية تسمى الانتشار العكسي.
قد تحتوي الشبكات العصبية السطحية على طبقة أو طبقتين مخفيتين بين المدخلات والمخرجات. أما الشبكات العميقة فتتكون من عشرات أو حتى مئات الطبقات، مما يُمكّنها من نمذجة العلاقات المعقدة للغاية.
يأتي العمق بتكلفة: كثافة حسابية عالية. يتطلب تدريب الشبكات العصبية العميقة قدرة معالجة كبيرة، ولهذا السبب ازدهر هذا المجال بالتزامن مع التطورات في الحوسبة باستخدام وحدات معالجة الرسومات (GPU).
الاختلافات الرئيسية بين التعلم الآلي والتعلم العميق
وهنا تبدأ الأمور تصبح مثيرة للاهتمام. فبينما يندرج التعلم العميق تحت مظلة التعلم الآلي، إلا أن هناك عدة اختلافات جوهرية تفصل بينهما عملياً.
متطلبات البيانات
تستطيع خوارزميات التعلم الآلي التقليدية العمل بكفاءة مع مجموعات بيانات أصغر حجماً، والتي قد لا تتجاوز أحياناً بضعة آلاف من الأمثلة. أما الأساليب الإحصائية مثل أشجار القرار، والغابات العشوائية، وآلات المتجهات الداعمة، فتستخلص أنماطاً ذات دلالة من بيانات محدودة.
يتطلب التعلم العميق كميات هائلة من البيانات. تحتوي الشبكات العصبية على ملايين المعاملات التي تحتاج إلى ضبط، مما يستلزم مجموعات بيانات ضخمة للتدريب الفعال. إذا تم تزويد نموذج التعلم العميق ببيانات قليلة جدًا، فإنه يُفرط في التخصيص، أي أنه يحفظ أمثلة التدريب بدلًا من تعلم أنماط قابلة للتعميم.
تشير التقارير الصناعية إلى أن التعلم العميق يحتاج عادةً إلى عشرات الآلاف إلى ملايين الأمثلة المصنفة للوصول إلى ذروة الأداء، على الرغم من أن تقنيات التعلم النقل يمكن أن تقلل من هذا المطلب.
هندسة الميزات
هنا يتغير عبء العمل بشكل كبير. يقضي ممارسو التعلم الآلي وقتاً طويلاً في هندسة الميزات - اختيار وتحويل وإنشاء متغيرات الإدخال التي ستستخدمها نماذجهم.
هل لديك بيانات عملاء؟ قد يقوم المطورون بإنشاء ميزات مثل "عدد الأيام منذ آخر عملية شراء" أو "متوسط قيمة الطلب" أو "تكرار الشراء" قبل بدء التدريب. هذه الخبرة في المجال تُؤثر على أداء النموذج.
تعمل تقنيات التعلم العميق على أتمتة هذه العملية. تتعلم طبقات الشبكة العصبية الميزات بشكل هرمي أثناء التدريب. هذا يقلل من الجهد البشري، ولكنه يخلق أيضاً مفاضلة: تحكم أقل فيما يتعلمه النموذج فعلياً.
الموارد الحاسوبية
هل يمكنك تشغيل نموذج تعلم آلي على جهاز الكمبيوتر المحمول الخاص بك؟ بالتأكيد. يتم تدريب العديد من الخوارزميات التقليدية بسرعة على الأجهزة القياسية، مما يجعلها متاحة وعملية في السيناريوهات ذات الموارد المحدودة.
تُعدّ نماذج التعلّم العميق من أكثر التقنيات تعقيداً من الناحية الحسابية. ويتطلب تدريب الشبكات المتطورة أجهزة متخصصة - مثل وحدات معالجة الرسومات (GPUs) أو وحدات معالجة الموتر (TPUs) - وقد يستغرق الأمر أياماً أو أسابيع حتى على الأنظمة القوية. وترتفع تكاليف التشغيل تبعاً لذلك.
يختلف الاستدلال (باستخدام نموذج مُدرَّب) أيضًا. عادةً ما تُعيد نماذج التعلّم الآلي التنبؤات في غضون أجزاء من الثانية على أجهزة أساسية. أما نماذج التعلّم العميق الكبيرة فقد تحتاج إلى بنية تحتية مُخصصة لتلبية متطلبات زمن الاستجابة في الوقت الفعلي.
قابلية التفسير
توفر نماذج التعلم الآلي، وخاصة النماذج الأبسط مثل أشجار القرار أو الانحدار الخطي، الشفافية. إذ يمكن للمطورين تتبع السبب الدقيق وراء قيام النموذج بتنبؤ معين، وهو أمر بالغ الأهمية في الصناعات الخاضعة للتنظيم أو القرارات المصيرية.
يعمل التعلم العميق كصندوق أسود. فمع وجود ملايين الأوزان عبر عشرات الطبقات، يصبح فهم سبب اتخاذ الشبكة العصبية خيارًا معينًا شبه مستحيل. وتسعى الأبحاث في مجال الذكاء الاصطناعي القابل للتفسير إلى معالجة هذه المشكلة، لكن قابلية التفسير لا تزال تشكل تحديًا مستمرًا.
أبرز بحثٌ أجراه معهد ماساتشوستس للتكنولوجيا في ديسمبر 2021 مشكلةً مثيرةً للقلق: فقد قدّمت الشبكات العصبية المُدرَّبة على مجموعات بيانات مثل CIFAR-10 تنبؤاتٍ موثوقةً حتى عندما كانت 95% من الصور المُدخلة مفقودة، بينما كانت النسبة المتبقية غير مفهومةٍ للبشر. هذا التفسير المُفرط يُثير تساؤلاتٍ حول موثوقية هذه الشبكات في التطبيقات الحساسة.
المفاضلات في الأداء
بالنسبة للبيانات المنظمة والجدولية - مثل جداول البيانات ذات الصفوف والأعمدة - غالبًا ما تتفوق أساليب التعلم الآلي التقليدية. تتفوق أشجار القرار، وتعزيز التدرج، والأساليب المشابهة في كثير من الأحيان على الشبكات العصبية في هذه المهام، مع سرعة تدريب أعلى واحتياج أقل للبيانات.
يهيمن التعلم العميق على البيانات غير المهيكلة. فقد شهدت مجالات التعرف على الصور، ومعالجة اللغة الطبيعية، والتعرف على الكلام تحسينات ثورية مع نضوج التعلم العميق. وتشير الأبحاث إلى أن التعلم العميق قادر على تحقيق دقة أعلى في مهام معالجة الصور مقارنةً بالتعلم الآلي التقليدي، مع وجود بعض الدراسات التي تُظهر اختلافات في الأداء ضمن هذا النطاق.
تتسع الفجوة مع ازدياد تعقيد المهمة. قد يفضل التصنيف البسيط الأساليب التقليدية، بينما يتجه التعرف على الأنماط المعقدة عبر البيانات عالية الأبعاد نحو التعلم العميق.

اختر النهج الأمثل للذكاء الاصطناعي مع AI Superior
إن مسألة التعلم العميق مقابل التعلم الآلي ليست مسألة تقنية فحسب، بل تؤثر أيضاً على احتياجات البيانات، ووقت التطوير، وتعقيد النموذج، وكيفية استخدام الحل عملياً. متفوقة الذكاء الاصطناعي تساعد هذه الخدمة الشركات على مقارنة مناهج الذكاء الاصطناعي من خلال الاستشارات المتخصصة، والتعلم الآلي الأساسي، والتعلم العميق، والتحليلات التنبؤية، ومعالجة اللغات الطبيعية، ورؤية الحاسوب، وتطوير برمجيات الذكاء الاصطناعي المخصصة. قبل البدء بالتنفيذ، يمكن لفريق الشركة مراجعة حالة الاستخدام، والبيانات المتاحة، والمخرجات المتوقعة. وهذا يُمكّن الشركات من تجنب اختيار نموذج مُعقّد أكثر من اللازم، مع إتاحة المجال لاستخدام تقنيات ذكاء اصطناعي أكثر تطورًا عند الحاجة الفعلية.
يمكن لبرنامج AI Superior المساعدة في التقييم:
- هل التعلم الآلي أم التعلم العميق هو الأنسب للمهمة؟
- متطلبات البيانات لأنواع النماذج المختلفة
- حالات استخدام التحليلات التنبؤية وخيارات النموذج
- تطبيقات التعلم العميق في عمليات معالجة الرؤية أو معالجة اللغة
- دمج نماذج الذكاء الاصطناعي المختارة في برامج مخصصة
👉تواصل مع شركة AI Superior لمناقشة أي نهج من مناهج الذكاء الاصطناعي يناسب مشروعك أو بياناتك أو متطلبات منتجك.
التطبيقات العملية وحالات الاستخدام
بصراحة: الاختيار بين التعلم الآلي والتعلم العميق لا يتعلق بأيهما "أفضل" - بل يتعلق بمطابقة الأداة مع المشكلة.
عندما يتألق التعلم الآلي
تُفضل مشاكل البيانات المنظمة التعلم الآلي التقليدي. فالتنبؤ بتسرب العملاء، والكشف عن الاحتيال في بطاقات الائتمان، والتنبؤ بالمبيعات، أو التوصية بالمنتجات بناءً على سجل الشراء - تتضمن هذه السيناريوهات عادةً بيانات جدولية حيث تكون العلاقات مباشرة نسبيًا.
تشير سيناريوهات البيانات المحدودة أيضًا إلى أهمية التعلم الآلي. فتدريب نموذج باستخدام بضع مئات من الأمثلة فقط؟ سيواجه التعلم العميق صعوبة. بينما تستطيع خوارزميات مثل الغابات العشوائية أو تعزيز التدرج استخلاص أنماط ذات دلالة من مجموعات بيانات أصغر.
هل تحتاج إلى قابلية التفسير؟ يوفرها التعلم الآلي. تستخدم المؤسسات المالية أشجار القرار للموافقة على القروض لأن الجهات التنظيمية تشترط وجود تفسيرات لقرارات الائتمان. وتستفيد التشخيصات الطبية بالمثل، إذ يرغب الأطباء في فهم سبب إشارة النموذج إلى خطر معين.
عندما يهيمن التعلم العميق
لقد أحدثت تقنيات التعرف على الصور ثورةً بعد نضوج التعلم العميق. فقد أحدثت الشبكات العصبية الالتفافية ثورةً في مجالات التعرف على الوجوه، وتحليل الصور الطبية، وأنظمة الرؤية في المركبات ذاتية القيادة، ومراقبة الجودة في التصنيع.
شهدت معالجة اللغة الطبيعية قفزات مماثلة. فقد تحسّنت الترجمة الآلية، وتحليل المشاعر، وبرامج الدردشة الآلية، وتلخيص المستندات بشكل ملحوظ بفضل بنى التعلم العميق مثل المحولات. وتعتمد نماذج اللغة التي ستعيد تشكيل اتصالات الأعمال في عام 2026 كلياً على الشبكات العصبية العميقة.
أصبح التعرف على الكلام، الذي كان في السابق غير دقيق بشكل محبط، موثوقاً بفضل التعلم العميق. وتستفيد المساعدات الصوتية وخدمات النسخ وأدوات تسهيل الوصول من الشبكات العصبية المتكررة أو الالتفافية المدربة على مجموعات بيانات صوتية ضخمة.
يعتمد تحليل الفيديو، واكتشاف الشذوذ في الأنظمة المعقدة، والذكاء الاصطناعي التوليدي - إنشاء صور أو نصوص أو ملفات صوتية جديدة - على قدرة التعلم العميق على نمذجة الأنماط المعقدة في البيانات عالية الأبعاد.
اختيار النهج الصحيح
فكيف يتخذ الممارسون قرارهم؟ هناك عدة عوامل توجه هذا الاختيار:
- حجم البيانات هو الأهم: هل لديك ملايين الأمثلة؟ يصبح التعلم العميق خياراً قابلاً للتطبيق. هل تعمل مع مئات أو آلاف الأمثلة؟ التزم بالتعلم الآلي التقليدي.
- يؤثر نوع البيانات على القرار: تميل البيانات المنظمة والجدولية إلى التعلم الآلي. أما الصور والنصوص والصوت والفيديو فتشير إلى التعلم العميق.
- لا يمكن تجاهل قيود الموارد: تُسهم الميزانية المحدودة وقدرات الحوسبة المحدودة في تعزيز كفاءة التعلم الآلي. بينما يتيح توفر وحدات معالجة الرسومات (GPUs) والوقت الكافي للتدريب المطول إمكانيات التعلم العميق.
- تُؤدي متطلبات الدقة مقابل قابلية التفسير إلى خلق توتر: هل تحتاج إلى أعلى دقة ممكنة في مهمة معقدة؟ قد يكون التعلم العميق خيارًا يستحق التضحية ببعض جوانبه المعقدة. هل تحتاج إلى الشفافية وقابلية التفسير؟ توفر نماذج التعلم الآلي الأبسط وضوحًا أكبر.
- يؤثر توافر الخبرة في المجال على جدوى هندسة الميزات: يستطيع الخبراء المتمكنون في مجال تخصصهم تصميم خصائص فعّالة للتعلم الآلي. أما نقص المعرفة المتخصصة فيؤدي إلى ترك التعلم العميق يكتشف الخصائص تلقائيًا.
| اعتبار | التعلم الالي | تعلم عميق |
|---|---|---|
| حجم قاعدة البيانات | من مئات إلى آلاف | من الآلاف إلى الملايين |
| نوع البيانات | منظم/جدولي | غير منظم (صورة/نص/صوت) |
| وقت التدريب | من دقائق إلى ساعات | من ساعات إلى أسابيع |
| متطلبات الأجهزة | وحدة المعالجة المركزية القياسية | يفضل استخدام وحدة معالجة الرسومات/وحدة معالجة الموتر |
| هندسة الميزات | يدوي، موجه بالمجال | تلقائي، متعلم |
| قابلية التفسير | عالية (خاصة النماذج البسيطة) | منخفض (صندوق أسود) |
العلاقة بالذكاء الاصطناعي
يُعد كل من التعلم الآلي والتعلم العميق جزءًا من مجال الذكاء الاصطناعي الأوسع. ويشمل الذكاء الاصطناعي أي تقنية تمكّن أجهزة الكمبيوتر من محاكاة الذكاء البشري، بما في ذلك الأنظمة القائمة على القواعد التي لا تتعلم على الإطلاق.
يمثل التعلم الآلي فرعاً من فروع الذكاء الاصطناعي يركز على التعلم من البيانات. أما التعلم العميق، فيُعدّ فرعاً آخر من فروع التعلم الآلي يستخدم الشبكات العصبية متعددة الطبقات.
يبدو التسلسل الهرمي كالتالي: يشمل الذكاء الاصطناعي التعلّم الآلي، الذي يشمل التعلّم العميق. كل تعلّم عميق هو تعلّم آلي، ولكن ليس كل تعلّم آلي هو تعلّم عميق. كل تعلّم آلي هو ذكاء اصطناعي، ولكن ليس كل ذكاء اصطناعي هو تعلّم آلي.
بحسب دراسة أجرتها كلية سلون للإدارة بمعهد ماساتشوستس للتكنولوجيا، استخدمت حوالي 351% من الشركات حول العالم الذكاء الاصطناعي في استطلاعات حديثة، بينما استكشفت 421% أخرى هذه التقنية. وقد ساهم تطوير الذكاء الاصطناعي التوليدي - الذي يعتمد على نماذج أساسية قوية للتعلم العميق - في تسريع تبني هذه التقنية منذ عام 2022.
لكن مهلاً. هذا لا يعني أن التعلم العميق قد حل محل التعلم الآلي. فلكل أداة غرضها الخاص. وتجمع العديد من أنظمة الإنتاج بين كلا النهجين، حيث تستخدم التعلم الآلي التقليدي لمعالجة البيانات المنظمة، بينما تطبق التعلم العميق على المدخلات غير المنظمة.
الاتجاهات الحالية والتوجهات المستقبلية
يستمر هذا المجال في التطور. يقلل التعلم بالنقل من حاجة التعلم العميق إلى البيانات من خلال البدء بنماذج مدربة مسبقًا وضبطها بدقة لمهام محددة - مما يتطلب أحيانًا مئات الأمثلة فقط بدلاً من ملايين الأمثلة.
تُسهّل تقنيات ضغط النماذج الوصول إلى التعلم العميق، مما يُقلّص حجم الشبكات لتشغيلها على الأجهزة المحمولة أو أجهزة الحوسبة الطرفية دون تكاليف حسابية هائلة.
تعمل منصات AutoML على أتمتة اختيار النموذج وضبط المعلمات الفائقة لكل من التعلم الآلي والتعلم العميق، مما يقلل من حاجز الخبرة اللازم للتنفيذ.
تجمع الأساليب الهجينة بين قابلية تفسير التعلم الآلي التقليدي وقدرة التعلم العميق على تمييز الأنماط. ويستكشف الباحثون الشبكات العصبية التي يمكنها تفسير قراراتها أو دمج المعرفة المتخصصة من خلال بنى هيكلية محددة.
يمثل الذكاء الاصطناعي التوليدي -التقنية الكامنة وراء أدوات مثل ChatGPT- أحدث آفاق التعلم العميق، حيث يقوم بإنشاء محتوى جديد كليًا بدلاً من مجرد تصنيفه أو التنبؤ به. يستخدم هذا النوع من الذكاء الاصطناعي بنى المحولات ومجموعات البيانات الضخمة لتوليد النصوص والصور والبرمجيات وغيرها.
الأسئلة الشائعة
هل التعلم العميق أفضل من التعلم الآلي؟
لا يُعدّ أيٌّ منهما أفضل بشكلٍ مطلق، فهما يتفوّقان في مهامّ مختلفة. يتفوّق التعلّم العميق على البيانات غير المهيكلة المعقدة، مثل الصور والنصوص، عند توفّر مجموعات بيانات كبيرة. بينما يتفوّق التعلّم الآلي التقليدي غالبًا على البيانات المهيكلة، ومجموعات البيانات الأصغر حجمًا، والسيناريوهات التي تتطلّب قابلية للتفسير أو موارد حاسوبية محدودة.
هل يتطلب التعلم العميق معرفة بالبرمجة؟
يتطلب بناء نماذج التعلم العميق من الصفر مهارات برمجية، عادةً باستخدام لغة بايثون وأطر عمل مثل TensorFlow أو PyTorch. ومع ذلك، توجد الآن منصات بدون كتابة أكواد أو بكتابة أكواد قليلة، تتيح تدريب النماذج ونشرها عبر واجهات مرئية، مما يجعل التعلم العميق في متناول غير المبرمجين.
ما مقدار البيانات التي يحتاجها التعلم العميق مقارنة بالتعلم الآلي؟
يمكن لتقنيات التعلم الآلي التقليدية أن تعمل بكفاءة مع مئات إلى آلاف الأمثلة التدريبية. أما التعلم العميق، فيتطلب عادةً عشرات الآلاف من الأمثلة على الأقل، وغالبًا ما تُدرَّب أحدث النماذج على ملايين أو مليارات من نقاط البيانات. ويمكن لتقنيات التعلم بالنقل أن تقلل هذه المتطلبات بشكل كبير.
هل يمكن للتعلم الآلي والتعلم العميق أن يعملا معاً؟
بالتأكيد. تجمع العديد من أنظمة الإنتاج بين كلا النهجين بطرق تكاملية. قد تستخدم الفرق التعلم الآلي التقليدي لخصائص البيانات المنظمة، بينما تطبق التعلم العميق لمعالجة الصور أو النصوص، ثم تجمع التنبؤات من كلا النموذجين لاتخاذ القرارات النهائية.
ما الذي يجب أن أتعلمه أولاً كمبتدئ؟
يُوفّر البدء بالتعلم الآلي التقليدي أساسًا أقوى. فالمفاهيم الرياضية، وأساليب التقييم، ومبادئ سير العمل تنطبق على كلا المجالين. وبمجرد إتقان أساسيات التعلم الآلي، يصبح الانتقال إلى التعلم العميق أكثر سهولةً وبديهيةً، لأنه يبني على نفس الأفكار الأساسية.
هل تتفوق الشبكات العصبية دائماً على الخوارزميات التقليدية؟
ليس الأمر كذلك على الإطلاق. ففي حالة البيانات الجدولية المنظمة، غالبًا ما تضاهي خوارزميات مثل تعزيز التدرج أو الغابات العشوائية أداء الشبكات العصبية أو تتفوق عليه، مع سرعة تدريب أعلى واستهلاك أقل للبيانات. أما الشبكات العصبية فتُظهر قوتها في البيانات غير المنظمة حيث تعجز الطرق التقليدية.
كم من الوقت يستغرق تدريب نموذج التعلم العميق؟
يختلف وقت التدريب اختلافًا كبيرًا بناءً على حجم النموذج وحجم مجموعة البيانات والأجهزة. قد يتم تدريب الشبكات البسيطة في دقائق على جهاز كمبيوتر محمول. أما نماذج اللغة الكبيرة أو أنظمة رؤية الحاسوب فقد تتطلب أيامًا أو أسابيع على مجموعات وحدات معالجة الرسومات المتخصصة. عادةً ما يتم تدريب نماذج التعلم الآلي التقليدية بشكل أسرع بكثير، غالبًا في غضون دقائق إلى ساعات.
المضي قدماً
يُساعد فهم الفرق بين التعلّم الآلي والتعلّم العميق على تحديد النهج الأنسب لكل مشكلة. يوفر التعلّم الآلي مرونة وكفاءة وقابلية تفسير للبيانات المنظمة وفي بيئات محدودة الموارد. أما التعلّم العميق، فيُتيح أداءً غير مسبوق على البيانات غير المنظمة المعقدة عند توفر موارد حاسوبية ومجموعات بيانات ضخمة.
لا يتعلق الاختيار بمواكبة التوجهات السائدة، بل بمواءمة القدرات مع المتطلبات. بعض الفرق تتجه مباشرةً إلى التعلم العميق لكونه تقنية متطورة، ثم تكتشف أن التعلم الآلي التقليدي كان سيحقق نتائج أفضل وأسرع. بينما يفضل البعض الآخر التمسك بالأساليب المألوفة رغم قدرة التعلم العميق على حل مشكلات كانت مستعصية.
يواصل كلا المجالين التطور بوتيرة متسارعة. ويساعد الاطلاع على نقاط قوتهما النسبية المطورين وعلماء البيانات وقادة الأعمال على اتخاذ قرارات تقنية أكثر ذكاءً.
هل أنت مستعد لتطبيق هذه المفاهيم؟ ابدأ بدراسة حالة استخدامك الخاصة: نوع البيانات، وحجمها، ومتطلبات الدقة، وقيود الموارد. ستتضح لك الأداة المناسبة بمجرد فهمك لما يقدمه كل نهج على وجه التحديد.