Korte samenvatting: Deep learning is een gespecialiseerde subcategorie van machine learning die gebruikmaakt van meerlaagse neurale netwerken om automatisch complexe patronen uit ruwe data te leren. Machine learning is een breder vakgebied binnen AI dat deep learning combineert met traditionele algoritmen die door mensen ontworpen kenmerken vereisen. Het belangrijkste verschil: machine learning vereist handmatige feature engineering en werkt goed met kleinere datasets, terwijl deep learning automatisch kenmerken extraheert, maar grote hoeveelheden data en rekenkracht vereist.
De termen machine learning en deep learning worden in de techwereld vaak door elkaar gebruikt. Maar het is belangrijk om het verschil te begrijpen, of je nu AI-systemen bouwt of gewoon wilt begrijpen hoe moderne technologie werkt.
Beide vallen onder de noemer kunstmatige intelligentie. Beide leren van data. Toch verschillen ze fundamenteel in de manier waarop ze problemen aanpakken, informatie verwerken en resultaten leveren.
Volgens Stanford HAI is deep learning een subset van machine learning die gebruikmaakt van grote, meerlaagse neurale netwerken om automatisch complexe patronen uit data te leren. In plaats van dat iemand handmatig kenmerken programmeert waarnaar gezocht moet worden, ontdekken deze modellen zelf steeds abstractere representaties.
Klinkt dat bekend? Dat komt omdat deep learning de basis vormt voor de spraakassistent op je telefoon, de aanbevelingssystemen op streamingplatforms en de taalmodellen die onze manier van werken veranderen.
Wat is machine learning?
Machine learning is een methodologie binnen de kunstmatige intelligentie waarbij systemen leren van data zonder expliciet geprogrammeerd te worden voor elk scenario. In plaats van regels te schrijven voor elke mogelijke invoer, trainen ontwikkelaars modellen om patronen te herkennen en voorspellingen te doen op basis van voorbeelden.
De aanpak is gebaseerd op algoritmen die door ervaring verbeteren. Voer een machine learning-model voldoende gelabelde data – bijvoorbeeld e-mails die als spam of niet-spam zijn gemarkeerd – en het leert zelfstandig nieuwe e-mails te classificeren.
Maar er is een addertje onder het gras. Traditionele machine learning vereist feature engineering – het proces waarbij mensen handmatig de data-eigenschappen selecteren en ontwerpen die het model moet onderzoeken. Voor beeldherkenning kan dat betekenen dat het systeem geprogrammeerd moet worden om te zoeken naar randen, hoeken of specifieke kleurpatronen.
Deze menselijke tussenkomst bepaalt wat het model leert. Kies je de verkeerde kenmerken, dan lijdt de prestatie eronder. Kies je goed, dan kunnen zelfs relatief eenvoudige algoritmen solide resultaten leveren op gestructureerde data.
Soorten machinaal leren
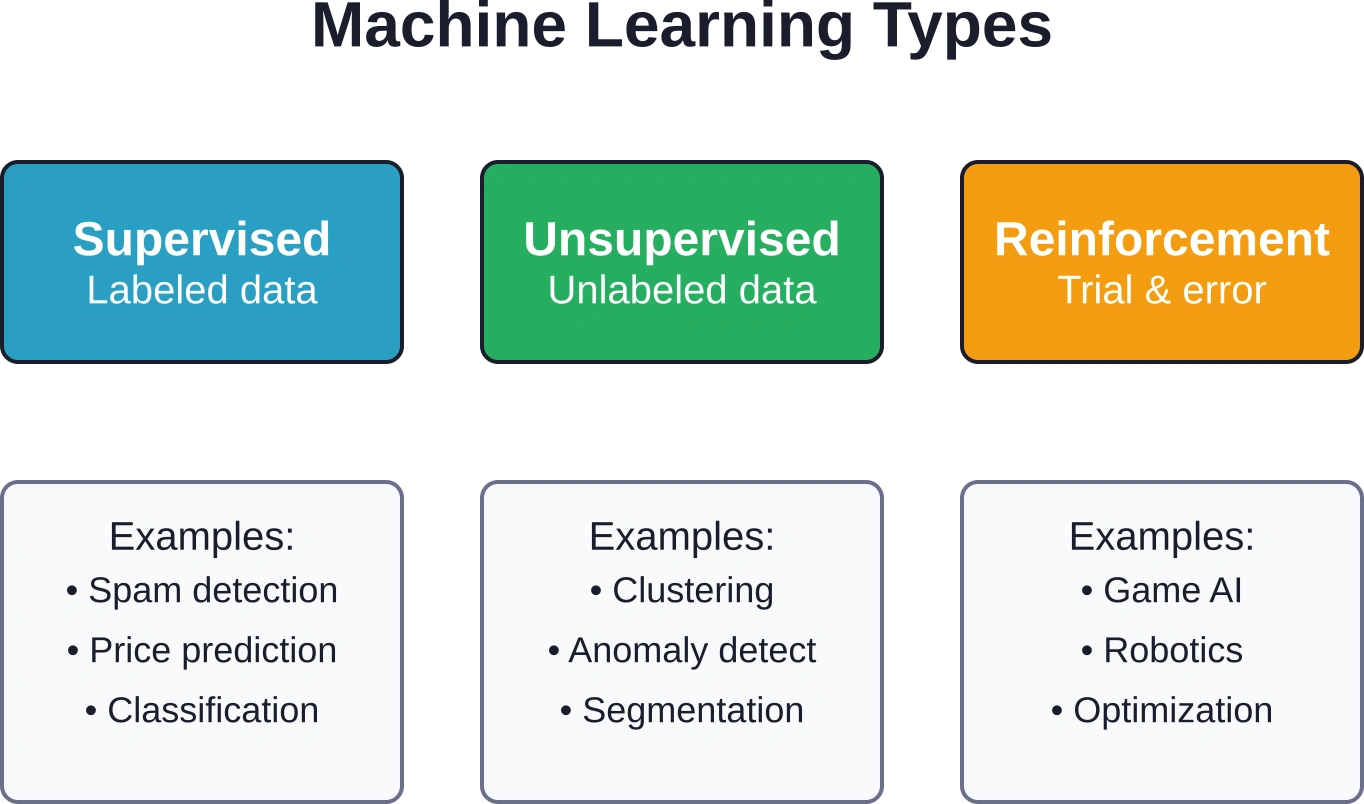
Machine learning kan worden onderverdeeld in drie hoofdcategorieën op basis van de manier waarop het algoritme leert:
- Bij supervised learning wordt getraind op gelabelde data waarvan het juiste antwoord bekend is. Het model leert inputs te koppelen aan outputs, bijvoorbeeld door huizenprijzen te voorspellen op basis van oppervlakte, locatie en leeftijd. De meeste zakelijke toepassingen vallen in deze categorie.
- Ongecontroleerd leren werkt met ongelabelde data en vindt verborgen patronen zonder vooraf gedefinieerde categorieën. Het groeperen van klanten op basis van koopgedrag of het detecteren van afwijkingen in netwerkverkeer is een voorbeeld van deze aanpak.
- Reinforcement learning traint door middel van vallen en opstaan, waarbij beloningen of straffen worden gegeven op basis van de uitgevoerde acties. AI die games speelt en robotica maken vaak gebruik van deze methode, hoewel het minder gebruikelijk is in traditionele zakelijke contexten.
Wat is deep learning?
Deep learning tilt machine learning naar een hoger niveau door gebruik te maken van neurale netwerken met meerdere lagen – vandaar de naam "deep". Deze netwerken bestaan uit onderling verbonden knooppunten (neuronen) die in lagen zijn georganiseerd en gegevens sequentieel verwerken, waarbij elke laag steeds complexere kenmerken extraheert.
De architectuur weerspiegelt hoe onderzoekers begrijpen dat het menselijk brein informatie verwerkt, hoewel de biologische analogie beperkingen heeft. Wat praktisch belangrijk is: deep learning-modellen kunnen automatisch de representaties ontdekken die nodig zijn voor het detecteren van kenmerken uit ruwe data.
Handmatige feature engineering is niet nodig. Voer ruwe afbeeldingen in een deep learning-systeem en het leert zelfstandig randen te herkennen in de eerste lagen, vormen in de middelste lagen en complete objecten in de diepere lagen.
Deze automatische feature learning maakt deep learning bijzonder krachtig voor ongestructureerde data – afbeeldingen, audio, tekst, video. Taken die traditionele machine learning decennialang voor een raadsel stelden, werden plotseling haalbaar.
Neurale netwerken uitgelegd
De kern van deep learning wordt gevormd door het neurale netwerk. Zie het als een reeks verwerkingslagen, elk met meerdere knooppunten die wiskundige bewerkingen uitvoeren op binnenkomende gegevens.
Informatie stroomt voorwaarts door het netwerk. Elke verbinding tussen knooppunten heeft een gewicht dat tijdens de training wordt aangepast. Het netwerk leert door deze gewichten bij te stellen om voorspellingsfouten te minimaliseren – een proces dat backpropagatie wordt genoemd.
Ondiepe neurale netwerken hebben mogelijk één of twee verborgen lagen tussen invoer en uitvoer. Diepe netwerken stapelen tientallen of zelfs honderden lagen op elkaar, waardoor ze extreem complexe relaties kunnen modelleren.
Die diepgang heeft een prijs: rekenkracht. Het trainen van diepe neurale netwerken vereist aanzienlijke verwerkingskracht, waardoor het vakgebied een enorme vlucht nam parallel aan de vooruitgang in GPU-computing.
Belangrijkste verschillen tussen machine learning en deep learning
Nu wordt het interessant. Hoewel deep learning onder de noemer machine learning valt, zijn er in de praktijk een aantal fundamentele verschillen.
Gegevensvereisten
Traditionele machine learning-algoritmen kunnen goed presteren met kleinere datasets, soms slechts duizenden voorbeelden. Statistische methoden zoals beslissingsbomen, willekeurige bossen of ondersteunende vectormachines halen betekenisvolle patronen uit beperkte data.
Diep leren vereist grote hoeveelheden data. Neurale netwerken bevatten miljoenen parameters die moeten worden afgesteld, waardoor enorme datasets nodig zijn om effectief te trainen. Als een diep leermodel te weinig data krijgt, treedt overfitting op – het model onthoudt trainingsvoorbeelden in plaats van generaliseerbare patronen te leren.
Uit brancherapporten blijkt dat deep learning doorgaans tienduizenden tot miljoenen gelabelde voorbeelden nodig heeft om optimale prestaties te bereiken, hoewel transfer learning-technieken deze behoefte kunnen verminderen.
Functietechniek
Hier verschuift de werkdruk aanzienlijk. Machine learning-experts besteden veel tijd aan feature engineering: het selecteren, transformeren en creëren van de invoervariabelen die hun modellen zullen gebruiken.
Beschikt u over klantgegevens? Ontwikkelaars kunnen vóór de training functies creëren zoals 'aantal dagen sinds laatste aankoop', 'gemiddelde orderwaarde' of 'aankoopfrequentie'. Deze domeinexpertise is bepalend voor de prestaties van het model.
Deep learning automatiseert dit proces. De lagen van het neurale netwerk leren tijdens de training hiërarchisch kenmerken. Dit vermindert de menselijke inspanning, maar brengt ook een nadeel met zich mee: minder controle over wat het model daadwerkelijk leert.
Computationele bronnen
Een machine learning-model op je laptop uitvoeren? Absoluut. Veel traditionele algoritmen trainen snel op standaard hardware, waardoor ze toegankelijk en praktisch zijn voor situaties met beperkte middelen.
Deep learning-modellen zijn rekenintensieve machines. Het trainen van geavanceerde netwerken vereist gespecialiseerde hardware – GPU's of TPU's – en kan zelfs op krachtige systemen dagen of weken duren. De operationele kosten stijgen navenant.
Inferentie (met behulp van een getraind model) verschilt ook. Machine learning-modellen leveren doorgaans binnen milliseconden voorspellingen op basis van eenvoudige hardware. Grote deep learning-modellen hebben mogelijk speciale infrastructuur nodig om te voldoen aan de realtime latency-vereisten.
Interpreteerbaarheid
Machine learning-modellen, met name de eenvoudigere modellen zoals beslissingsbomen of lineaire regressie, bieden transparantie. Ontwikkelaars kunnen precies nagaan waarom een model een bepaalde voorspelling heeft gedaan, wat van belang is in gereguleerde sectoren of bij beslissingen met grote gevolgen.
Deep learning werkt als een black box. Met miljoenen gewichten verdeeld over tientallen lagen is het vrijwel onmogelijk om te begrijpen waarom een neuraal netwerk een bepaalde keuze heeft gemaakt. Onderzoek naar verklaarbare AI probeert dit probleem aan te pakken, maar interpreteerbaarheid blijft een hardnekkige uitdaging.
Onderzoek van MIT uit december 2021 bracht een zorgwekkende kwestie aan het licht: neurale netwerken die getraind waren op datasets zoals CIFAR-10 maakten zelfverzekerde voorspellingen, zelfs wanneer 95 procent van de invoerbeelden ontbrak, terwijl de resterende beelden voor mensen betekenisloos waren. Deze overinterpretatie roept vragen op over de betrouwbaarheid in kritische toepassingen.
Afwegingen ten aanzien van prestaties
Voor gestructureerde, tabelvormige data – denk aan spreadsheets met rijen en kolommen – wint traditionele machine learning vaak. Beslissingsbomen, gradient boosting en vergelijkbare methoden presteren bij deze taken vaak beter dan neurale netwerken, terwijl ze sneller trainen en minder data vereisen.
Deep learning domineert ongestructureerde data. Beeldherkenning, natuurlijke taalverwerking, spraakherkenning – deze domeinen hebben revolutionaire verbeteringen ondergaan sinds deep learning volwassen is geworden. Onderzoek wijst uit dat deep learning een hogere nauwkeurigheid kan bereiken bij beeldverwerkingstaken in vergelijking met traditionele machine learning, waarbij sommige studies prestatieverschillen in deze orde van grootte aantonen.
Het verschil wordt groter naarmate de complexiteit van de taak toeneemt. Bij eenvoudige classificatie zijn traditionele methoden wellicht geschikter. Complexe patroonherkenning in hoogdimensionale data neigt daarentegen naar deep learning.

Kies de juiste AI-aanpak met AI Superior.
De vraag of je deep learning of machine learning moet kiezen, is niet alleen technisch van aard. Het heeft gevolgen voor de benodigde data, de ontwikkeltijd, de complexiteit van het model en hoe de oplossing in de praktijk zal worden toegepast. AI Superieur Helpt bedrijven AI-benaderingen te vergelijken door middel van AI-consultancy, kerntechnieken voor machine learning, deep learning, voorspellende analyses, NLP, computervisie en de ontwikkeling van maatwerk AI-software. Voordat ze met de bouw beginnen, kan hun team de use case, de beschikbare data en de verwachte output beoordelen. Dit helpt bedrijven te voorkomen dat ze een complexer model kiezen dan nodig, terwijl er nog steeds ruimte overblijft voor geavanceerdere AI wanneer het probleem dit daadwerkelijk vereist.
AI Superior kan helpen bij het beoordelen van:
- Of machine learning of deep learning geschikt is voor deze taak.
- Gegevensvereisten voor verschillende modeltypen
- Toepassingsvoorbeelden en modelopties voor voorspellende analyses
- Toepassingen van deep learning in beeldverwerkings- of taalworkflows
- Integratie van geselecteerde AI-modellen in maatwerksoftware
👉Neem contact op met AI Superior om te bespreken welke AI-aanpak het beste aansluit bij uw project, data of productvereisten.
Praktische toepassingen en gebruiksvoorbeelden
Eerlijk gezegd: de keuze tussen machine learning en deep learning draait niet om welke "beter" is, maar om het juiste instrument voor het probleem.
Wanneer machine learning zijn waarde bewijst
Problemen met gestructureerde data lenen zich goed voor traditionele machine learning. Het voorspellen van klantverloop, het opsporen van creditcardfraude, het voorspellen van verkopen of het aanbevelen van producten op basis van aankoopgeschiedenis: deze scenario's hebben doorgaans betrekking op tabulaire data waarin de relaties relatief direct zijn.
Scenario's met beperkte data wijzen ook in het voordeel van machine learning. Een model trainen met slechts een paar honderd voorbeelden? Dan zal deep learning het moeilijk hebben. Algoritmen zoals random forests of gradient boosting kunnen betekenisvolle patronen uit kleinere datasets halen.
Interpretatie nodig? Machine learning biedt de oplossing. Financiële instellingen gebruiken beslissingsbomen voor het goedkeuren van leningen, omdat toezichthouders uitleg eisen voor kredietbeslissingen. Ook medische diagnostiek profiteert hiervan: artsen willen begrijpen waarom een model een bepaald risico heeft gesignaleerd.
Wanneer Deep Learning de overhand krijgt
Beeldherkenning onderging een transformatie toen deep learning volwassen werd. Gezichtsherkenning, medische beeldanalyse, visiesystemen voor autonome voertuigen, kwaliteitscontrole in de productie – convolutionele neurale netwerken zorgden voor een revolutie in deze domeinen.
Natuurlijke taalverwerking kende vergelijkbare sprongen voorwaarts. Machinevertaling, sentimentanalyse, chatbots en documentsamenvatting verbeterden allemaal aanzienlijk dankzij deep learning-architecturen zoals transformers. De taalmodellen die de zakelijke communicatie in 2026 zullen hervormen, zijn volledig gebaseerd op diepe neurale netwerken.
Spraakherkenning, ooit frustrerend onnauwkeurig, is dankzij deep learning betrouwbaar geworden. Spraakassistenten, transcriptiediensten en toegankelijkheidstools maken allemaal gebruik van terugkerende of convolutionele netwerken die getraind zijn op enorme audio-datasets.
Videoanalyse, anomaliedetectie in complexe systemen en generatieve AI – het creëren van nieuwe afbeeldingen, tekst of audio – zijn allemaal afhankelijk van het vermogen van deep learning om ingewikkelde patronen in hoogdimensionale data te modelleren.
De juiste aanpak kiezen
Hoe maken professionals dan een beslissing? Verschillende factoren spelen een rol bij die keuze:
- Het datavolume is het belangrijkst: Heb je miljoenen voorbeelden? Dan wordt deep learning een haalbare optie. Werk je met honderden of duizenden voorbeelden? Blijf dan bij traditionele machine learning.
- Het gegevenstype is bepalend voor de beslissing: Gestructureerde, tabelvormige data leent zich goed voor machine learning. Afbeeldingen, tekst, audio of video wijzen op deep learning.
- Beperkingen qua middelen kunnen niet worden genegeerd: Beperkt budget en rekenkracht bevorderen de efficiëntie van machine learning. Toegang tot GPU's en voldoende tijd voor langdurige training openen de mogelijkheden van deep learning.
- De spanning tussen nauwkeurigheidseisen en interpreteerbaarheid zorgt voor een conflict: Wil je de hoogst mogelijke nauwkeurigheid bij een complexe taak? Dan is deep learning wellicht de moeite waard, ondanks de 'black box'-aspecten. Heb je behoefte aan transparantie en verklaarbaarheid? De eenvoudigere modellen van machine learning bieden dan meer duidelijkheid.
- De beschikbaarheid van domeinexpertise beïnvloedt de haalbaarheid van feature engineering: Sterke vakdeskundigen kunnen effectieve kenmerken voor machine learning ontwikkelen. Gebrek aan domeinkennis leidt ertoe dat deep learning de kenmerken automatisch ontdekt.
| Overweging | Machinaal leren | Diep leren |
|---|---|---|
| Omvang van de dataset | Honderden tot duizenden | Duizenden tot miljoenen |
| Gegevenstype | Gestructureerd/tabelvormig | Ongestructureerd (afbeelding/tekst/audio) |
| Trainingstijd | Minuten tot uren | Uren tot weken |
| Hardwarebehoeften | Standaard CPU | GPU/TPU heeft de voorkeur. |
| Functietechniek | Handmatig, domein-gestuurd | Automatisch, aangeleerd |
| Interpreteerbaarheid | Hoog (vooral bij eenvoudige modellen) | Laag (zwarte doos) |
De relatie met kunstmatige intelligentie
Zowel machine learning als deep learning vallen binnen het bredere landschap van kunstmatige intelligentie. AI omvat elke techniek waarmee computers menselijke intelligentie kunnen nabootsen, inclusief op regels gebaseerde systemen die helemaal niet leren.
Machine learning is een subset van AI die zich richt op het leren van data. Deep learning is een nog specifiekere subset van machine learning die gebruikmaakt van neurale netwerken met meerdere lagen.
De hiërarchie ziet er als volgt uit: AI omvat machine learning, dat weer deep learning omvat. Alle deep learning is machine learning, maar niet alle machine learning is deep learning. Alle machine learning is AI, maar niet alle AI is machine learning.
Volgens onderzoek van MIT Sloan gebruikten ongeveer 351.000 tot 300.000 bedrijven wereldwijd AI in recente enquêtes, terwijl nog eens 421.000 tot 300.000 bedrijven de technologie onderzochten. De ontwikkeling van generatieve AI – die gebruikmaakt van krachtige deep learning-modellen – heeft de adoptie sinds 2022 versneld.
Maar wacht even. Dit betekent niet dat deep learning machine learning heeft vervangen. Verschillende tools dienen verschillende doelen. Veel productiesystemen combineren beide benaderingen, waarbij traditionele machine learning wordt gebruikt voor gestructureerde datapipelines en deep learning wordt toegepast op ongestructureerde input.
Huidige trends en toekomstige ontwikkelingen
Het vakgebied blijft zich ontwikkelen. Transfer learning vermindert de databehoefte van deep learning door te beginnen met voorgegetrainde modellen en deze te verfijnen voor specifieke taken – soms met slechts honderden in plaats van miljoenen voorbeelden.
Modelcompressietechnieken maken deep learning toegankelijker, doordat netwerken kleiner worden gemaakt zodat ze op mobiele apparaten of edge computing-hardware kunnen draaien zonder enorme rekenkracht.
AutoML-platformen automatiseren de modelselectie en hyperparameteroptimalisatie voor zowel machine learning als deep learning, waardoor de drempel voor expertise bij de implementatie wordt verlaagd.
Hybride benaderingen combineren de interpreteerbaarheid van traditionele machine learning met de patroonherkenningskracht van deep learning. Onderzoekers verkennen neurale netwerken die hun beslissingen kunnen verklaren of domeinkennis kunnen integreren via gestructureerde architecturen.
Generatieve AI – de technologie achter tools zoals ChatGPT – vertegenwoordigt de nieuwste grens van deep learning. Het creëert volledig nieuwe content in plaats van alleen te classificeren of te voorspellen. Deze subcategorie maakt gebruik van transformer-architecturen en enorme datasets om tekst, afbeeldingen, code en meer te genereren.
Veelgestelde vragen
Is deep learning beter dan machine learning?
Geen van beide is universeel beter; ze blinken uit in verschillende taken. Deep learning presteert beter op complexe, ongestructureerde data zoals afbeeldingen en tekst, mits er grote datasets beschikbaar zijn. Traditionele machine learning wint vaak op gestructureerde data, kleinere datasets en in scenario's die interpreteerbaarheid vereisen of waar de rekenkracht beperkt is.
Vereist deep learning programmeerkennis?
Het bouwen van deep learning-modellen vanaf nul vereist programmeervaardigheden, doorgaans in Python met frameworks zoals TensorFlow of PyTorch. Er bestaan echter nu ook no-code- en low-code-platformen die modeltraining en -implementatie via visuele interfaces mogelijk maken, waardoor deep learning toegankelijker wordt voor niet-programmeurs.
Hoeveel data heeft deep learning nodig in vergelijking met machine learning?
Traditionele machine learning kan effectief werken met honderden tot duizenden trainingsvoorbeelden. Deep learning vereist doorgaans minstens tienduizenden voorbeelden, waarbij de meest geavanceerde modellen vaak getraind worden op miljoenen of miljarden datapunten. Transfer learning-technieken kunnen deze vereisten aanzienlijk verminderen.
Kunnen machine learning en deep learning samenwerken?
Absoluut. Veel productiesystemen combineren beide benaderingen op complementaire wijze. Teams kunnen traditionele machine learning gebruiken voor gestructureerde data-eigenschappen, terwijl ze deep learning toepassen om afbeeldingen of tekst te verwerken. Vervolgens combineren ze de voorspellingen van beide modellen voor de uiteindelijke beslissing.
Wat moet ik als beginner als eerste leren?
Beginnen met traditionele machine learning biedt een sterkere basis. De wiskundige concepten, evaluatiemethoden en workflowprincipes zijn van toepassing op beide vakgebieden. Zodra je vertrouwd bent met de basisprincipes van machine learning, wordt de overstap naar deep learning intuïtiever, omdat het voortbouwt op dezelfde kernideeën.
Presteren neurale netwerken altijd beter dan traditionele algoritmen?
Helemaal niet. Bij gestructureerde tabeldata evenaren of overtreffen algoritmen zoals gradient boosting of random forests vaak de prestaties van neurale netwerken, terwijl ze sneller trainen en minder data nodig hebben. Neurale netwerken tonen hun kracht juist bij ongestructureerde data, waar traditionele methoden tekortschieten.
Hoe lang duurt het om een deep learning-model te trainen?
De trainingstijd varieert enorm, afhankelijk van de grootte van het model, de omvang van de dataset en de hardware. Eenvoudige netwerken kunnen in enkele minuten op een laptop getraind worden. Grote taalmodellen of computervisiessystemen kunnen dagen of weken in beslag nemen op gespecialiseerde GPU-clusters. Traditionele machine learning-modellen trainen doorgaans veel sneller, vaak in minuten tot uren.
Vooruitkijken
Het onderscheid tussen machine learning en deep learning begrijpen, maakt duidelijk welke aanpak het meest geschikt is voor specifieke problemen. Machine learning biedt veelzijdigheid, efficiëntie en interpreteerbaarheid voor gestructureerde data en scenario's met beperkte resources. Deep learning maakt ongekende prestaties mogelijk op complexe, ongestructureerde data wanneer er voldoende rekenkracht en grote datasets beschikbaar zijn.
De keuze draait niet om het volgen van trends, maar om het afstemmen van mogelijkheden op de behoeften. Sommige teams stappen over op deep learning omdat het de nieuwste technologie is, maar ontdekken vervolgens dat traditionele machine learning sneller betere resultaten had opgeleverd. Anderen blijven vasthouden aan vertrouwde methoden, terwijl deep learning voorheen onoplosbare problemen zou kunnen oplossen.
Beide vakgebieden blijven zich snel ontwikkelen. Door op de hoogte te blijven van hun relatieve sterke punten, kunnen ontwikkelaars, datawetenschappers en bedrijfsleiders slimmere technologische beslissingen nemen.
Klaar om deze concepten toe te passen? Begin met het analyseren van uw specifieke gebruikssituatie: gegevenstype, volume, nauwkeurigheidseisen en beschikbare resources. De juiste tool wordt vanzelf duidelijk zodra u begrijpt wat elke aanpak werkelijk te bieden heeft.