Korte samenvatting: Natuurlijke taalverwerking (NLP) stelt bedrijven in staat om klantfeedback te analyseren, klantenservice te automatiseren, inzichten uit ongestructureerde data te halen en betere beslissingen te nemen. Van sentimentanalyse en chatbots tot documentverwerking en concurrentieanalyse: NLP-toepassingen transformeren de manier waarop organisaties werken, verlagen de kosten en verbeteren de klantervaring in alle sectoren.
Natuurlijke taalverwerking is geëvolueerd van een academische curiositeit naar een zakelijke noodzaak. Organisaties verwerken tegenwoordig dagelijks miljoenen tekstdocumenten: klantrecensies, supporttickets, berichten op sociale media, juridische contracten en marktrapporten. Handmatige analyse is niet langer schaalbaar.
Maar het punt is: slechts 181.300.000 organisaties analyseren ongestructureerde data, zoals natuurlijke tekst, om zakelijke inzichten te verkrijgen, blijkt uit onderzoek van Deloitte. Dat is een enorme kans die gemist wordt.
Bedrijven die NLP inzetten, blijven niet alleen bij, maar lopen voorop met snellere besluitvorming, een dieper klantinzicht en operationele efficiëntie die concurrenten met traditionele methoden niet kunnen evenaren.
Dit artikel beschrijft de meest impactvolle NLP-toepassingen die momenteel de bedrijfsvoering transformeren. Het behandelt concrete voorbeelden, meetbare voordelen en praktische implementatieoverwegingen.
Wat is natuurlijke taalverwerking in het bedrijfsleven?
Natuurlijke taalverwerking bevindt zich op het snijvlak van kunstmatige intelligentie, taalkunde en computerwetenschappen. Het stelt machines in staat om menselijke taal te begrijpen, te interpreteren en te genereren op manieren die zakelijke waarde creëren.
De technologie verwerkt zowel gestructureerde als ongestructureerde tekstgegevens. Dat omvat alles, van klantmails en chattranscripten tot productrecensies, gesprekken op sociale media en interne documenten.
Moderne NLP-systemen matchen niet alleen trefwoorden. Ze begrijpen context, sentiment, intentie en zelfs subtiele taalkundige nuances zoals sarcasme of regionale dialecten. Deze mogelijkheid verandert de manier waarop organisaties inzichten halen uit de enorme hoeveelheid tekstdata die dagelijks wordt gegenereerd.
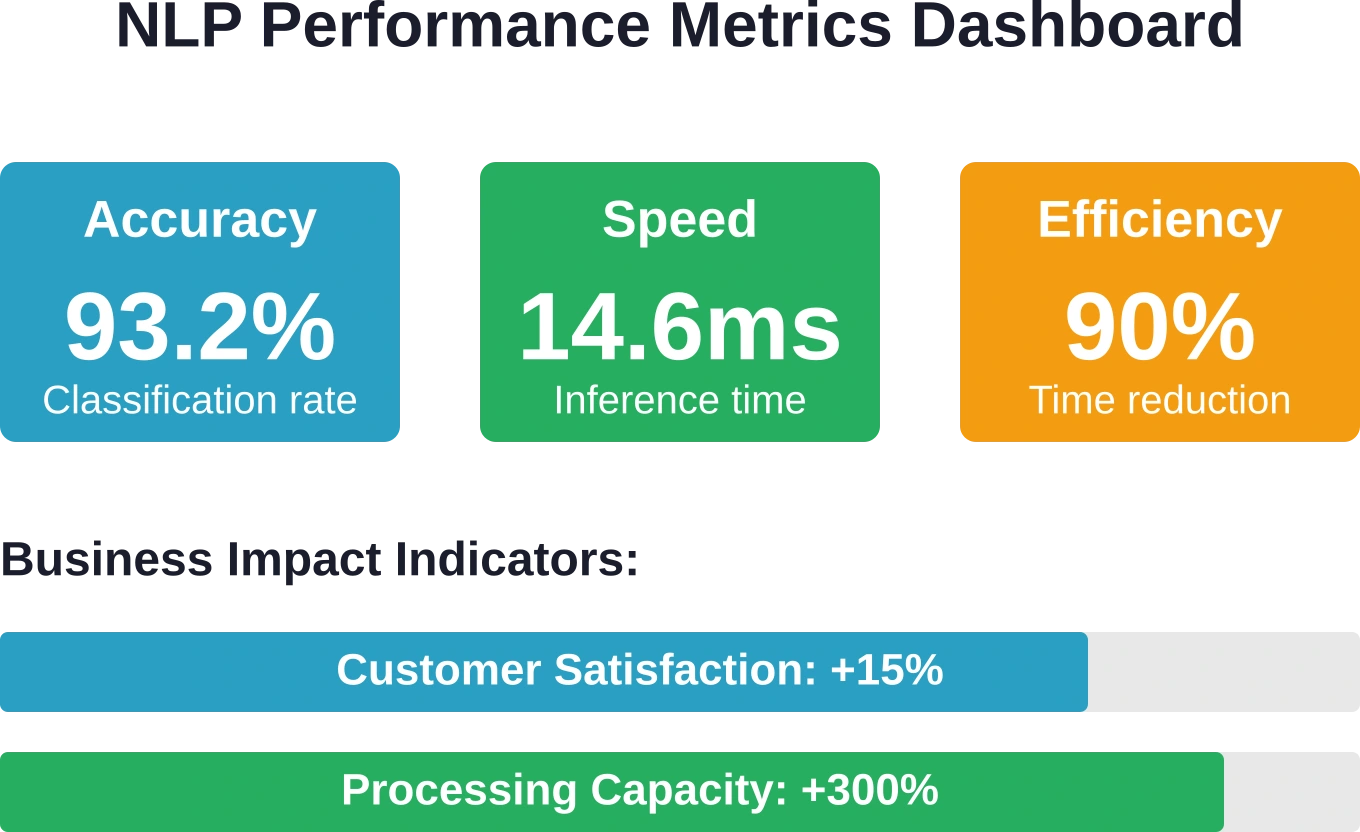
Voor implementatie in bedrijfsomgevingen is efficiëntie net zo belangrijk als nauwkeurigheid. Lichtgewicht transformer-architecturen hebben realtime NLP-verwerking haalbaar gemaakt voor zakelijke toepassingen. DistilBERT bijvoorbeeld, realiseert een reductie van 40% in bestandsgrootte door kennisdestillatie, terwijl de prestaties vergelijkbaar blijven en de inferentie-efficiëntie verbetert.
Dit maakt een praktische implementatie mogelijk met geoptimaliseerde inferentietijden en compacte modelgroottes die geschikt zijn voor standaard bedrijfsinfrastructuren.
Kernvoordelen van NLP voor bedrijfsvoering
Organisaties die NLP-oplossingen implementeren, melden meetbare verbeteringen op meerdere operationele gebieden. Dit zijn geen theoretische voordelen, maar aantoonbare effecten op de bedrijfsresultaten.
Kostenbesparing door automatisering
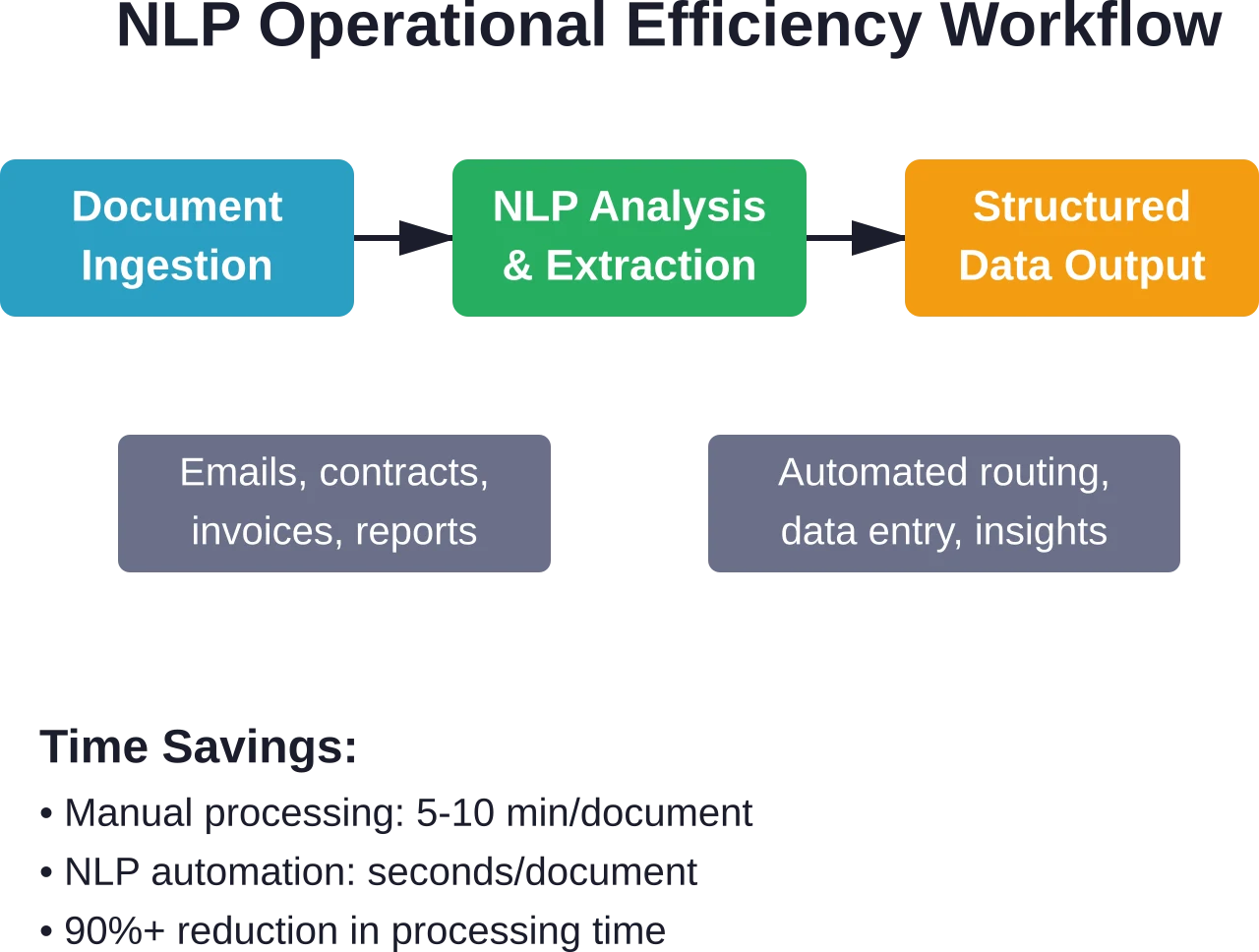
Bedrijfsprocessen die veel tekst vereisen, kosten enorm veel tijd van werknemers. Contractbeoordeling, het beantwoorden van klantvragen, documentclassificatie en gegevensinvoer vereisen allemaal menselijke taalverwerking, processen die met behulp van NLP kunnen worden versneld of volledig geautomatiseerd.
Het Tough Mudder-team heeft de tijd die nodig was voor het handmatig coderen van enquêtes met 90% verminderd door tekstanalyses te gebruiken om feedback na het evenement te verwerken. Dat heeft honderden uren opgeleverd die nu besteed kunnen worden aan strategisch werk in plaats van het categoriseren van open antwoorden op enquêtes.
Automatisering van de klantenservice levert vergelijkbare voordelen op. Chatbots behandelen routinematige vragen zonder menselijke tussenkomst, waardoor supportteams zich kunnen concentreren op complexe problemen die empathie en creatieve probleemoplossing vereisen.
Snel naar inzicht
De marktomstandigheden veranderen snel. Organisaties die sneller inzichten verkrijgen uit feedback van klanten, aankondigingen van concurrenten en marktrapporten, behalen een doorslaggevend concurrentievoordeel.
Amazon heeft onlangs tekstanalyse ingezet om miljoenen productrecensies te analyseren en zo de belangrijkste kenmerken te identificeren die de klanttevredenheid verhogen. Dit leidde tot gerichte productverbeteringen en een stijging van 15% in positieve beoordelingen – een concurrentievoordeel dat werd behaald door snellere feedbackanalyse dan concurrenten handmatig konden uitvoeren.
Verbeterd klantinzicht
Klanten uiten voortdurend hun behoeften, frustraties en voorkeuren via supporttickets, reviews, sociale media en enquêtes. Het grootste deel van deze kwalitatieve feedback blijft ongeanalyseerd omdat handmatige beoordeling niet schaalbaar is.
NLP-sentimentanalyse verwerkt deze feedback op grote schaal en identificeert opkomende trends voordat ze duidelijk worden. Organisaties signaleren productproblemen vroegtijdig, begrijpen functieverzoeken beter en stemmen hun aanbod af op de daadwerkelijke taal van de klant in plaats van op interne aannames.
Risicobeperking en naleving
Regelgeving leidt tot een enorme documentatielast. De financiële dienstverlening, de gezondheidszorg en de juridische sector staan voor bijzondere uitdagingen bij het waarborgen van naleving van de regelgeving, met duizenden documenten en communicaties als gevolg.
NLP-systemen scannen contracten, communicatie en rapporten op nalevingsproblemen en signaleren potentiële overtredingen voordat ze escaleren tot problemen met de regelgeving. Deze geautomatiseerde monitoring zorgt voor consistent toezicht, wat met handmatige controle onmogelijk te realiseren is.

Toepassingen voor het verbeteren van de klantervaring
NLP-toepassingen die direct met klanten te maken hebben, beïnvloeden de klanttevredenheid, klantbehoud en de levenslange klantwaarde. Deze toepassingen richten zich op de interacties in de frontlinie die de klantperceptie vormgeven.
Intelligente chatbots en virtuele assistenten
Moderne conversationele AI is verder gegaan dan rigide beslissingsbomen. De huidige systemen begrijpen de intentie, gaan om met de context in gesprekken die meerdere beurten omvatten en schakelen op een elegante manier over naar menselijke medewerkers wanneer dat nodig is.
Deze assistenten zijn 24/7 beschikbaar via verschillende kanalen: websitechat, mobiele apps, berichtenplatforms en spraakinterfaces. Klanten krijgen direct antwoord op veelgestelde vragen over de orderstatus, accountgegevens, productspecificaties en stappen voor probleemoplossing.
De impact op de bedrijfsvoering reikt verder dan alleen beschikbaarheid. Chatbots kunnen een onbeperkt aantal gelijktijdige gesprekken afhandelen zonder wachttijden, waardoor de frustratie van wachtrijen in traditionele callcenters verdwijnt. Ook de consistentie van de reacties verbetert: elke klant ontvangt accurate, merkgerichte informatie in plaats van wisselende kwaliteit, afhankelijk van welke medewerker ze spreken.
Implementatie vereist training op basis van daadwerkelijke klantgesprekken. Generieke chatbots frustreren gebruikers. Effectieve systemen leren de bedrijfsspecifieke terminologie, productnamen, veelvoorkomende problemen en de gesprekspatronen die klanten daadwerkelijk gebruiken.
Sentimentanalyse voor klantfeedback
Klanttevredenheid is overal terug te vinden: in recensies, enquêtes, sociale media en supporttickets. Door deze feedback op grote schaal te verzamelen, komen patronen aan het licht die bij individuele interacties onzichtbaar zijn.
Sentimentanalyse classificeert tekst als positief, negatief of neutraal, vaak met gedetailleerde emotiedetectie (gefrustreerd, verheugd, verward). Organisaties volgen sentimenttrends in de loop van de tijd, leggen een verband tussen sentiment en productkenmerken of servicewijzigingen, en signaleren opkomende problemen voordat ze escaleren.
Delta Air Lines gebruikte tekstanalyses om klantfeedback via verschillende kanalen te verwerken en zo specifieke knelpunten in de reiservaring te identificeren. Dit gedetailleerde inzicht in de klantsensatie maakte gerichte verbeteringen mogelijk voor de meest storende elementen.
De analyse gaat verder dan binaire goed/slecht-classificaties. Aspectgebaseerde sentimentanalyse onthult welke specifieke kenmerken klanten wel of niet waarderen. Een product kan bijvoorbeeld over het algemeen positieve feedback krijgen, maar negatieve feedback specifiek over de verpakking of documentatie – bruikbare inzichten die algemene sterrenbeoordelingen missen.
Voice of Customer Intelligence
Organisaties verzamelen enorme hoeveelheden kwalitatieve feedback die nooit wordt geanalyseerd. Open vragen in enquêtes, transcripten van supportgesprekken, gebruikersinterviews en discussies op communityforums bevatten waardevolle inzichten, maar lenen zich niet voor traditionele kwantitatieve analyse.
NLP haalt thema's, trends en patronen uit deze ongestructureerde feedback. Topic modeling ontdekt automatisch waar klanten het meest over praten. Feature extraction identificeert welke functionaliteiten het belangrijkst zijn voor gebruikers. Pain point analysis brengt de obstakels aan het licht die klanten frustreren voordat ze afhaken.
Deze inzichten vormen de basis voor productroadmaps, marketingboodschappen en klantstrategieën, waarbij gebruik wordt gemaakt van de daadwerkelijke taal van de klant in plaats van interne aannames over wat belangrijk is.
Toepassingen voor operationele efficiëntie
Interne processen genereren net zoveel tekst als klantinteracties: e-mails, rapporten, documentatie, contracten, notulen van vergaderingen. NLP-toepassingen stroomlijnen deze tekstintensieve processen.
Documentverwerking en informatie-extractie
Zakelijke documenten bevatten gestructureerde informatie die verborgen zit in ongestructureerde formaten. Facturen, contracten, cv's, verzekeringsclaims en inkooporders vereisen allemaal menselijke controle om de belangrijkste gegevens eruit te halen.
Door NLP aangedreven documentverwerking worden relevante informatie – zoals datums, bedragen, namen, adressen, voorwaarden en bepalingen – automatisch geïdentificeerd en geëxtraheerd. Deze gestructureerde gegevens worden direct in bedrijfssystemen ingevoerd zonder handmatige invoer.
Factuurverwerking is een goed voorbeeld van de impact. Organisaties die duizenden facturen van diverse leveranciers in verschillende formaten ontvangen, kunnen het extraheren van leveranciersnaam, factuurnummer, regelitems, bedragen en betalingsvoorwaarden automatiseren. De verwerkingstijd per factuur daalt van minuten naar seconden, met een nauwkeurigheid die die van vermoeide menselijke controleurs overtreft.
Contractanalyse volgt vergelijkbare patronen. Juridische teams gebruiken NLP om contracten te controleren op specifieke clausules, verplichtingen, data en niet-standaard bepalingen. Deze geautomatiseerde eerste controle identificeert punten die de aandacht van een jurist vereisen, terwijl routinematige contracten sneller worden verwerkt.
E-mailbeheer en -routering
Medewerkers worden overspoeld met e-mails van het bedrijf. Klantvragen komen terecht in algemene inboxen die doorgestuurd moeten worden naar de juiste teams. Interne communicatie zorgt ervoor dat belangrijke verzoeken verdwijnen in de ruis.
NLP classificeert binnenkomende e-mails op onderwerp, urgentie en vereiste actie. E-mails van de klantenservice worden automatisch doorgestuurd naar teams op basis van het type probleem: facturering, technische ondersteuning, accountwijzigingen. Dringende verzoeken worden gemarkeerd voor onmiddellijke aandacht in plaats van in de wachtrij te wachten.
Geautomatiseerde e-mailclassificatie zorgt ervoor dat vragen direct bij de juiste persoon terechtkomen in plaats van dat ze tussen verschillende afdelingen worden doorgestuurd. De reactietijden verbeteren omdat de juiste expert het probleem meteen ziet.
Samenvatting van de vergadering en het extraheren van actiepunten
Organisaties besteden talloze uren aan vergaderingen. De waarde hiervan hangt af van duidelijke documentatie en de opvolging van beslissingen en actiepunten.
NLP-systemen verwerken transcripten van vergaderingen om samenvattingen te genereren waarin belangrijke beslissingen, actiepunten en verantwoordelijken worden belicht. Deelnemers ontvangen duidelijke documentatie zonder dat ze een notulist hoeven aan te wijzen, en er gaat niets verloren omdat iemand vergeten is iets op te schrijven.
Deze mogelijkheid geldt ook voor opgenomen gesprekken, webinars en presentaties. De inhoud wordt doorzoekbaar en scanbaar, in plaats van dat het tijdrovend is om alles opnieuw af te spelen om specifieke discussies terug te vinden.
Interne werving en kennismanagement
Medewerkers verspillen veel tijd aan het zoeken naar informatie op SharePoint-sites, wiki's, documentatiearchieven en gedeelde schijven. Traditioneel zoeken op trefwoorden levert irrelevante resultaten op, omdat het geen rekening houdt met context en intentie.
Semantisch zoeken, mogelijk gemaakt door NLP, begrijpt de betekenis achter zoekopdrachten, niet alleen overeenkomsten met trefwoorden. Zoeken naar 'hoe om te gaan met ontevreden klanten' levert relevante klantenserviceprotocollen op, zelfs als in die documenten de term 'ontevreden klanten' niet voorkomt.“
Het systeem begrijpt synoniemen, verwante concepten en context. De resultaten verbeteren doordat de zoekfunctie herkent dat 'cliënt', 'klant' en 'account' in zakelijke contexten vaak hetzelfde betekenen.
Marktinformatie en concurrentieanalyse
Om de marktdynamiek en de bewegingen van concurrenten te begrijpen, is het nodig om enorme hoeveelheden openbare informatie te verwerken: nieuwsartikelen, persberichten, sociale media, winstpresentaties, octrooiaanvragen en wettelijke documenten.
Concurrentie-informatie verzamelen
NLP-systemen monitoren vermeldingen van concurrenten in nieuwsbronnen, sociale media, recensiesites en branchepublicaties. Organisaties volgen productlanceringen van concurrenten, prijswijzigingen, klanttevredenheid, personeelswervingspatronen en strategische aankondigingen.
Deze geautomatiseerde monitoring brengt concurrentiebedreigingen en -kansen sneller aan het licht dan handmatig onderzoek. Wanneer concurrenten nieuwe mogelijkheden aankondigen, waarschuwt NLP de relevante teams onmiddellijk, in plaats van te wachten tot iemand de informatie per toeval ontdekt.
De analyse gaat verder dan alleen vermeldingen. Sentimentanalyse onthult hoe markten reageren op aankondigingen van concurrenten. Onderwerpmodellering identificeert welke kenmerken van concurrenten de meeste discussie genereren. Marktaandeelstatistieken tonen de relatieve marktinteresse in de verschillende concurrenten.
Analyse van markttrends
Trends in de sector komen naar voren uit patronen die zich herhalen in duizenden artikelen, rapporten en discussies. Afzonderlijke stukken onthullen weinig, maar een geaggregeerde analyse brengt terugkerende thema's aan het licht.
NLP analyseert vakpublicaties, analistenrapporten, congresverslagen en sociale media om opkomende thema's, afnemende interesses en veranderende terminologie te identificeren. Organisaties signaleren marktkansen vroegtijdig en vermijden investeringen in achterhaalde benaderingen.
Deze trenddetectie werkt over verschillende tijdsperioden. Detectie van kortetermijnpieken identificeert onmiddellijke marktreacties op gebeurtenissen. Analyse van langetermijntrends onthult geleidelijke verschuivingen in de focus van de sector, klantprioriteiten en de acceptatie van technologie.
Merkbewaking en reputatiemanagement
Merkvermeldingen verspreiden zich razendsnel over verschillende platforms: sociale media, recensiesites, forums, nieuwsartikelen en blogs. Handmatige monitoring mist de meeste vermeldingen en reageert te traag op nieuwe problemen.
Merkmonitoring op basis van NLP volgt vermeldingen in realtime, analyseert sentiment, identificeert trending topics en waarschuwt teams voor potentiële reputatieproblemen. Organisaties reageren snel wanneer negatief sentiment toeneemt en betrekken klanten voordat geïsoleerde klachten uitgroeien tot virale problemen.
De monitoring maakt onderscheid tussen verschillende contexten. Een vermelding in een klacht vereist een andere aanpak dan een vermelding in een positieve recensie of een neutraal brancheartikel. Classificatie van de intentie zorgt voor een passende prioritering van de reacties.
Risicomanagement- en compliance-applicaties
Wettelijke vereisten en risicobeheer leiden tot uitgebreide documentatie- en monitoringbehoeften. NLP automatiseert een groot deel van deze nalevingslast.
Toezicht op naleving van regelgeving
De financiële dienstverlening, de gezondheidszorg en andere gereguleerde sectoren moeten ervoor zorgen dat communicatie en documenten voldoen aan complexe regelgeving. Handmatige controle van elke e-mail, elk rapport en elk document is niet schaalbaar.
NLP-systemen scannen communicatie op waarschuwingssignalen voor mogelijke overtredingen van de regelgeving, zoals verboden terminologie, verplichte openbaarmakingen, voorkennis en schendingen van de regels voor eerlijke kredietverlening. Potentiële problemen worden door een mens beoordeeld voordat ze daadwerkelijk tot overtredingen leiden.
De monitoring past zich aan naarmate de regelgeving verandert. Wanneer er nieuwe compliance-eisen ontstaan, actualiseren organisaties hun NLP-modellen om nieuwe patronen te detecteren, in plaats van complete compliance-teams opnieuw te trainen.
Fraudedetectie in tekstcommunicatie
Frauduleuze activiteiten laten taalkundige sporen na. Verzekeringsclaims, leningaanvragen en financiële overzichten bevatten taalpatronen die legitieme documenten onderscheiden van frauduleuze documenten.
NLP analyseert tekst op fraude-indicatoren, zoals inconsistenties, verdachte patronen en taalgebruik dat kenmerkend is voor bekende fraudeschema's. Deze geautomatiseerde screening geeft prioriteit aan zaken die de aandacht van onderzoekers verdienen, waardoor de beperkte middelen voor fraudeonderzoek worden ingezet voor de zaken met het hoogste risico.
Analyse van juridische documenten
Juridische afdelingen verwerken duizenden contracten, overeenkomsten en wettelijke documenten. De tijd die advocaten aan hen besteden, kost honderden dollars per uur – duur voor een routinematige beoordeling van documenten.
NLP voert een eerste contractanalyse uit, waarbij de belangrijkste bepalingen worden geëxtraheerd, standaardclausules van niet-standaardclausules worden onderscheiden, ongebruikelijke bepalingen worden gemarkeerd en contracten worden vergeleken met sjablonen. Advocaten kunnen zich richten op werkelijk complexe juridische kwesties in plaats van op routinematige beoordelingen.
Onderzoek naar jurisprudentie biedt vergelijkbare voordelen. In plaats van handmatig honderden zaken te lezen om relevante precedenten te vinden, zoekt NLP op basis van juridische concepten en feitenpatronen, waardoor de meest toepasbare zaken snel naar voren komen.
Sollicitaties voor personeelszaken
HR-afdelingen verwerken enorme hoeveelheden tekst: cv's, functiebeschrijvingen, functioneringsgesprekken, feedback van medewerkers, exitgesprekken. NLP maakt deze tekstgegevens bruikbaar.
CV-screening en kandidaatmatching
Populaire vacatures trekken honderden sollicitaties aan. Handmatige beoordeling van cv's zorgt voor knelpunten en het risico bestaat dat gekwalificeerde kandidaten over het hoofd worden gezien in de grote hoeveelheid sollicitaties.
Door NLP aangedreven applicant tracking systems analyseren cv's om vaardigheden, ervaring, opleiding en kwalificaties te extraheren. Kandidaten worden automatisch vergeleken met de functie-eisen, waarbij sollicitanten worden gerangschikt op basis van geschiktheid in plaats van op volgorde van binnenkomst.
De analyse gaat verder dan het matchen van trefwoorden. Semantisch begrip erkent dat "Python-ontwikkelaar" en "software engineer met Python-ervaring" vergelijkbare kwalificaties beschrijven, ook al is de formulering anders.
Analyse van werknemerssentiment en -betrokkenheid
Enquêtes onder medewerkers, feedbackplatforms en exitgesprekken bieden openhartige inzichten in de bedrijfscultuur, de effectiviteit van het management en organisatorische problemen. Deze feedback bevordert het behoud van medewerkers als er actie op wordt ondernomen – maar alleen als iemand de feedback analyseert.
NLP verwerkt feedback van medewerkers op grote schaal en identificeert terugkerende thema's, opkomende zorgen en sentimenttrends binnen teams en afdelingen. Organisaties signaleren betrokkenheidsproblemen vroegtijdig en kunnen de impact van cultuurinitiatieven meten aan de hand van kwantitatieve gegevens.
Prestatiebeoordelingsanalyse
Functioneringsgesprekken leveren waardevolle kwalitatieve gegevens op over de sterke punten, ontwikkelingsbehoeften en carrière-interesses van medewerkers. Deze informatie wordt doorgaans in individuele documenten bewaard in plaats van gebruikt te worden voor de talentstrategieën van de organisatie.
NLP extraheert patronen uit prestatiebeoordelingen: vaardigheden die vaak voorkomen in beoordelingen van topmedewerkers, gemeenschappelijke ontwikkelingsbehoeften binnen teams en indicatoren voor promotiebereidheid. Talentmanagement wordt zo datagedreven in plaats van gebaseerd op anekdotes.
Implementatieoverwegingen voor Business NLP
Een succesvolle implementatie van NLP vereist meer dan alleen het kiezen van een algoritme. Organisaties moeten aandacht besteden aan datakwaliteit, modeltraining, integratie en doorlopend onderhoud.
Gegevensvereisten en -voorbereiding
NLP-modellen leren van voorbeelden. De kwaliteit van een model hangt direct af van de kwaliteit en de hoeveelheid trainingsdata. Organisaties hebben representatieve voorbeelden nodig van de tekst die ze willen verwerken – voldoende voorbeelden om terminologie, formaten en uitzonderlijke gevallen te dekken.
Het voorbereiden van data vergt veel inspanning. Tekstdata moeten worden opgeschoond, gestandaardiseerd en gelabeld. Het verwijderen van opmaakfouten, het verwerken van speciale tekens en het normaliseren van afkortingen hebben allemaal invloed op de modelprestaties.
Voor taken met begeleid leren, zoals classificatie, moet iemand de trainingsvoorbeelden labelen. Een sentimentanalysemodel heeft honderden of duizenden tekstvoorbeelden nodig die handmatig geclassificeerd moeten worden als positief, negatief of neutraal. Deze labeling vereist domeinexpertise en duidelijke richtlijnen om consistentie te waarborgen.
Modelselectie en aanpassing
Voorgeprogrammeerde taalmodellen bieden een sterke basis, maar vereisen aanpassing aan de specifieke zakelijke context. Generieke modellen begrijpen geen bedrijfsspecifieke terminologie, productnamen of vakjargon.
Fine-tuning past voorgegetrainde modellen aan specifieke bedrijfsbehoeften aan. Deze transfer learning-aanpak vereist veel minder trainingsdata dan het bouwen van modellen vanaf nul, terwijl de prestaties beter zijn dan die van generieke modellen.
Modelselectie is een afweging tussen nauwkeurigheid en efficiëntie. De meest nauwkeurige modellen vereisen meer rekenkracht, wat leidt tot vertraging en infrastructuurkosten. Lichtgewicht architecturen zoals DistilBERT bieden een hoge nauwkeurigheid op zakelijke datasets en voldoen tegelijkertijd aan de eisen voor realtime verwerking.
Integratie met bestaande systemen
NLP-toepassingen moeten naadloos aansluiten op bestaande workflows en systemen. Losstaande analysetools bieden beperkte waarde als de inzichten de besluitvormers niet bereiken of niet leiden tot de juiste acties.
API-gebaseerde integratie verbindt NLP-functionaliteiten met CRM-systemen, supportplatformen, documentbeheersystemen en business intelligence-tools. Sentimentscores worden in klantgegevens opgenomen, documenten worden geëxtraheerd en databasevelden worden gevuld, en chatbotgesprekken worden geïntegreerd met ticketsystemen.
De integratie omvat workflows waarbij mensen betrokken zijn bij taken die menselijk oordeel vereisen. NLP verzorgt de initiële verwerking en routering, maar complexe gevallen worden doorverwezen naar medewerkers met de juiste context uit de geautomatiseerde analyse.
Privacy- en beveiligingsaspecten
Zakelijke tekstdata bevatten gevoelige informatie, zoals klantgegevens, financiële gegevens, bedrijfseigen data en personeelsdossiers. NLP-systemen moeten deze informatie tijdens de verwerking beschermen.
Beleid voor gegevensbeheer definieert welke tekst verwerkt mag worden, wie toegang heeft tot de resultaten en hoe lang gegevens worden bewaard. Organisaties moeten ervoor zorgen dat NLP-verwerking voldoet aan privacyregelgeving zoals de AVG, de CCPA en branchespecifieke vereisten.
Modeltraining brengt extra privacyrisico's met zich mee. Trainingsgegevens mogen niet in de modeluitvoer terechtkomen. Organisaties die gebruikmaken van cloudgebaseerde NLP-diensten moeten inzicht hebben in waar gegevens worden verwerkt en opgeslagen, met name in gereguleerde sectoren met vereisten voor gegevensopslaglocatie.
| Implementatiefase | Belangrijkste activiteiten | Typische tijdlijn | Succesfactoren |
|---|---|---|---|
| Ontdekking en planning | Gebruiksscenariodefinitie, gegevensanalyse, eisenverzameling | 2-4 weken | Duidelijke bedrijfsdoelstellingen, steun van het management |
| Data voorbereiding | Gegevensverzameling, opschoning, etikettering, kwaliteitscontroles | 4-8 weken | Domeinexpertise, richtlijnen voor etikettering, gegevensvolume |
| Modelontwikkeling | Modelselectie, training, validatie, afstemming | 6-12 weken | Representatieve trainingsgegevens, evaluatiemetrieken |
| Integratie en testen | Systeemintegratie, UAT, workflowontwerp | 4-6 weken | Duidelijke werkprocessen, betrokkenheid van belanghebbenden |
| Implementatie en monitoring | Productie-uitrol, prestatiebewaking, iteratie | Lopend | Monitoringinfrastructuur, feedbackloops |

Ontwikkel NLP-tools rondom echte zakelijke taken met superieure AI.
NLP wordt nuttig wanneer het een specifiek tekstgerelateerd probleem oplost – zoals sorteren, zoeken, extraheren, classificeren, samenvatten of vragen beantwoorden in zakelijke content. AI Superieur Wij werken met NLP-ontwikkeling, LLM-consulting, generatieve AI-ontwikkeling, AI-chatbotontwikkeling, AI-softwareontwikkeling en AI-integratie. Voor bedrijven kan dit van toepassing zijn op klantberichten, supporttickets, rapporten, interne documenten, beoordelingen, contracten, kennisbanken en andere tekstrijke databronnen.
De NLP-diensten van AI Superior kunnen onder meer het volgende omvatten:
- Het in kaart brengen van bedrijfstaken die afhankelijk zijn van tekstgegevens.
- Hulpmiddelen voor documentverwerking en -classificatie
- Het ontwikkelen van op LLM gebaseerde assistenten of zoekfuncties.
- NLP toepassen ter ondersteuning van beoordelingen, rapporten of interne content.
- Integratie van AI in taalverwerking in bedrijfssoftware
👉Neem contact op met AI Superior om NLP-toepassingen te verkennen voor uw documenten, klantcommunicatie of digitale producten.
Het meten van de impact en ROI van NLP
Om investeringen in NLP te rechtvaardigen, is het essentieel om meetbare zakelijke impact aan te tonen. Organisaties dienen vóór de implementatie succesindicatoren te definiëren en deze consistent te monitoren.
Kwantitatieve meetwaarden
Tijdsbesparing levert de meest eenvoudige ROI-berekening op. De tijd die nodig is voor documentverwerking, het oplossen van klantvragen en handmatige analyses, vertaalt zich direct in kostenbesparingen wanneer dit geautomatiseerd wordt.
Volumecijfers tonen de impact van schaalvergroting aan. Het aantal verwerkte documenten, afgehandelde klantgesprekken of geanalyseerde contracten laat capaciteitsvergrotingen zien die met handmatige methoden onmogelijk zijn.
Kwaliteitsverbeteringen komen tot uiting in nauwkeurigheidspercentages, consistentiemetrieken en foutreductie. De nauwkeurigheid van NLP-classificatie, de extractieprecisie en de routeringscorrectheid geven aan of geautomatiseerde systemen vergelijkbaar presteren met menselijke referentiewaarden.
Bedrijfsresultaatmetrieken
De uiteindelijke impact blijkt uit de bedrijfsresultaten, niet uit de processtatistieken. Klanttevredenheidsscores, retentiepercentages, omzet per klant en de tijd die nodig is om problemen op te lossen, verbinden NLP-mogelijkheden met resultaten die er echt toe doen.
Een chatbot voor klantenservice kan maandelijks 10.000 vragen afhandelen, maar de zakelijke impact is de verbetering van de klanttevredenheid en de verlaging van de ondersteuningskosten per klant.
Organisaties dienen deze resultaatindicatoren te volgen vóór en na de implementatie van NLP, waarbij de impact zoveel mogelijk wordt geïsoleerd van andere veranderingen.
Continue verbetering
NLP-systemen vereisen voortdurende monitoring en verfijning. Taal evolueert, zakelijke contexten veranderen en er ontstaan nieuwe uitzonderingen. De prestaties van modellen nemen af zonder onderhoud.
Regelmatige hertraining met nieuwe voorbeelden zorgt ervoor dat de modellen actueel blijven. Monitoringdashboards houden trends in nauwkeurigheid, foutpatronen en uitzonderlijke gevallen die aandacht vereisen bij. Feedbackloops koppelen gebruikerscorrecties terug aan de trainingsdata, waardoor de modellen continu worden verbeterd.
Toekomstige trends in zakelijke NLP
De mogelijkheden van NLP blijven zich in hoog tempo ontwikkelen. Organisaties die implementaties plannen, moeten rekening houden met opkomende mogelijkheden die naar verwachting in de komende jaren de standaard zullen worden.
Generatieve AI-integratie
Grote taalmodellen genereren nu tekst van menselijke kwaliteit, in plaats van deze alleen te analyseren. Zakelijke toepassingen gaan verder dan alleen begrijpen en omvatten ook creëren: e-mails opstellen, rapporten samenvatten, productbeschrijvingen genereren, documentatie maken.
Deze generatieve capaciteit verandert werkprocessen. In plaats van puur geautomatiseerde of puur handmatige processen ontstaat er een samenwerking tussen mens en AI. Systemen genereren concepten en suggesties; mensen beoordelen, verfijnen en keuren deze goed.
Multimodale begrip
Zakelijke communicatie combineert steeds vaker tekst, afbeeldingen, audio en video. Toekomstige NLP-systemen verwerken deze modaliteiten gezamenlijk in plaats van afzonderlijk.
Een klantenservicesysteem kan tegelijkertijd gespreksaudio, schermopnames en chattranscripten analyseren, waardoor het probleem vollediger wordt begrepen dan met elk afzonderlijk kanaal. Marketinganalyse kan berichten op sociale media, inclusief afbeeldingen, bijschriften en reacties, als één geheel verwerken.
Low-code NLP-tools
De implementatie van NLP vereist momenteel expertise op het gebied van datawetenschap. Opkomende platforms democratiseren de toegang met low-code interfaces, waardoor zakelijke gebruikers eenvoudige NLP-toepassingen kunnen bouwen zonder te programmeren.
Deze tools verlagen de drempel voor experimenteren en implementeren voor eenvoudige toepassingen, hoewel complexere toepassingen nog steeds baat hebben bij de betrokkenheid van experts.
Verklaarbare AI
Blackbox-modellen wekken zorgen over vertrouwen en naleving van regelgeving. Verklaarbare AI-technieken laten zien waarom modellen specifieke voorspellingen doen en tonen aan welke tekstkenmerken de classificatiebeslissingen hebben beïnvloed.
Deze transparantie is belangrijk voor gereguleerde sectoren, belangrijke beslissingen en het opsporen van fouten in modellen. Organisaties kunnen zo controleren of modellen de juiste signalen gebruiken in plaats van onterechte correlaties.
Veelvoorkomende implementatie-uitdagingen
Organisaties stuiten op voorspelbare obstakels bij de implementatie van NLP-toepassingen. Door op deze uitdagingen te anticiperen, kan beter worden gepland en kunnen risico's worden beperkt.
Problemen met de datakwaliteit
Tekstdata uit de praktijk zijn vaak rommelig. Typfouten, afkortingen, inconsistenties in de opmaak en onvolledige gegevens verminderen allemaal de prestaties van modellen. Organisaties onderschatten vaak de inspanning die nodig is om trainingsdata te schonen en voor te bereiden.
Domeinspecifieke terminologie zorgt voor extra uitdagingen. Vakjargon, productnamen en bedrijfstaal komen niet voor in algemene trainingsdata. Modellen moeten deze gespecialiseerde woordenschat leren aan de hand van bedrijfsspecifieke voorbeelden.
Verandermanagement
NLP-implementaties veranderen werkprocessen en functieverantwoordelijkheden. Werknemers kunnen zich verzetten tegen automatisering die ze als bedreigend ervaren, of ze kunnen algoritmes minder vertrouwen dan menselijk oordeel.
Succesvolle implementaties omvatten verandermanagement dat deze aandachtspunten aanpakt. De communicatie legt de nadruk op aanvulling in plaats van vervanging, en laat zien hoe automatisering vervelend werk elimineert en tegelijkertijd de menselijke rol voor complexe besluitvorming behoudt.
Het managen van verwachtingen
De mogelijkheden van NLP worden vaak overdreven. Stakeholders verwachten soms perfect menselijk begrip bij de eerste implementaties. Het stellen van realistische verwachtingen ten aanzien van de nauwkeurigheid voorkomt teleurstelling.
Organisaties zouden NLP moeten beschouwen als een continu verbeteringsproces in plaats van een eenmalige implementatie. De aanvankelijke nauwkeurigheid kan overeenkomen met of iets achterblijven bij de menselijke prestaties, maar systemen verbeteren door feedback en behouden tegelijkertijd een consistentie die voor mensen moeilijk te bereiken is.
Het omgaan met uitzonderlijke gevallen
Geen enkel model behandelt elk scenario correct. Randgevallen, ongebruikelijke invoer en nieuwe situaties zullen zich voordoen. Systemen hebben een soepele afhandeling van storingen en escalatiepaden nodig voor situaties waarin de betrouwbaarheid laag is.
Het ontwerp met menselijke tussenkomst pakt deze beperking aan. Onzekere voorspellingen worden doorgestuurd naar menselijke beoordelaars in plaats van automatisch verder te gaan. Na verloop van tijd verrijken deze uitzonderlijke gevallen de trainingsdata, waardoor modellen leren omgaan met voorheen onbekende situaties.
Veelgestelde vragen
Wat is het verschil tussen NLP en traditionele tekstanalyse?
Traditionele tekstanalyse is gebaseerd op het matchen van trefwoorden en eenvoudige patroonherkenning. NLP begrijpt context, intentie en betekenis door middel van machine learning-modellen die getraind zijn op taalpatronen. NLP herkent dat "niet slecht" een positieve betekenis heeft, ondanks het negatieve woord "slecht", terwijl trefwoordanalyse dit ten onrechte als negatief zou classificeren. NLP gaat om met synoniemen, ambiguïteit en context op manieren die op regels gebaseerde systemen niet kunnen.
Hoeveel trainingsdata heeft een NLP-model nodig?
De benodigde trainingsdata varieert afhankelijk van de complexiteit van de taak en de architectuur van het model. Transfer learning-methoden met behulp van voorgegetrainde modellen zoals BERT kunnen goede resultaten behalen met honderden gelabelde voorbeelden voor eenvoudige classificatietaken. Complexe domeinspecifieke toepassingen vereisen mogelijk duizenden gelabelde voorbeelden. De sleutel ligt in de kwaliteit en representativiteit van de data, niet zozeer in de hoeveelheid – diverse voorbeelden die ook de randgevallen bestrijken, zijn belangrijker dan redundante, vergelijkbare voorbeelden.
Kan NLP meerdere talen aan voor internationale bedrijven?
Moderne NLP-modellen ondersteunen tientallen talen, hoewel de prestaties per taal verschillen. Talen met veel beschikbare bronnen, zoals Engels, Spaans en Chinees, beschikken over uitgebreide trainingsdata en volwassen modellen. Talen met minder beschikbare bronnen vereisen mogelijk meer maatwerk. Meertalige modellen kunnen meerdere talen met één model verwerken, hoewel taalspecifieke modellen doorgaans beter presteren voor bedrijfskritische toepassingen. Organisaties zouden de modelprestaties specifiek voor hun doeltalen moeten evalueren.
Hoe lang duurt een NLP-implementatie doorgaans?
De implementatietijd varieert van weken tot maanden, afhankelijk van de complexiteit, de beschikbaarheid van data en de integratievereisten. Een eenvoudige implementatie van sentimentanalyse met bestaande tools en schone data kan binnen 4-6 weken worden afgerond. Complexe, op maat gemaakte modellen die uitgebreide trainingsdataverzameling, labeling en integratie met bedrijfssystemen vereisen, kunnen 4-6 maanden in beslag nemen. De meeste zakelijke NLP-projecten duren 2-4 maanden, inclusief datavoorbereiding, modelontwikkeling, testen en implementatie.
Wat zijn de doorlopende kosten voor het onderhouden van NLP-systemen?
Onderhoudskosten omvatten infrastructuur voor modelhosting en inferentie, dataopslag, monitoringsystemen en periodieke hertraining. Cloudgebaseerde NLP-diensten verschuiven de infrastructuurkosten naar gebruiksgebaseerde prijsstelling. Organisaties moeten ook budgetteren voor periodieke modelupdates naarmate taal- en zakelijke contexten evolueren. De doorlopende kosten bedragen doorgaans 15-251 ton aan initiële implementatiekosten per jaar, hoewel dit aanzienlijk varieert afhankelijk van de schaal en complexiteit.
Hoe zorg je ervoor dat NLP-modellen geen vooroordelen in stand houden?
Het tegengaan van bias begint met het beoordelen van de trainingsdata, waarbij ervoor gezorgd wordt dat de voorbeelden representatief zijn voor diverse bevolkingsgroepen en contexten zonder stereotypen te bevatten. Evaluatiecriteria moeten de eerlijkheid ten opzichte van verschillende demografische groepen meten, niet alleen de algehele nauwkeurigheid. Regelmatige audits controleren op bevooroordeelde voorspellingen in de productieomgeving. Diverse teams die NLP-systemen ontwikkelen, helpen bij het identificeren van potentiële biasproblemen. Organisaties moeten duidelijke beleidsregels opstellen voor het omgaan met geconstateerde bias en zich committeren aan continue monitoring in plaats van het als een eenmalige controle te beschouwen.
Welke nauwkeurigheidsgraad mogen bedrijven verwachten van NLP-toepassingen?
De verwachte nauwkeurigheid hangt af van de moeilijkheidsgraad van de taak en de basisprestaties van mensen. Documentclassificatie behaalt vaak een nauwkeurigheid van 90-95% voor goed gedefinieerde categorieën. Sentimentanalyse ligt doorgaans tussen de 80-90%, afhankelijk van de domeinspecificiteit en de vereiste nuances. Named entity extraction behaalt een nauwkeurigheid van 85-95% voor veelvoorkomende entiteitstypen. Organisaties zouden hun prestaties moeten vergelijken met die van mensen bij dezelfde taak – als getrainde medewerkers een overeenstemming van 85% bereiken, is het onrealistisch om van NLP een overeenstemming van 95% te verwachten. De belangrijkste vraag is of de nauwkeurigheid van NLP voldoet aan de zakelijke eisen, niet of het perfectie bereikt.
Conclusie
Natuurlijke taalverwerking transformeert bedrijfsvoering door tekstintensieve processen te automatiseren, inzichten te halen uit ongestructureerde data en de klantervaring op grote schaal te verbeteren. De toepassingen omvatten klantenservice, operationele processen, marktonderzoek, compliance en personeelszaken – in principe elke bedrijfsfunctie die met menselijke taal te maken heeft.
Organisaties die NLP succesvol implementeren, behalen meetbare voordelen: lagere operationele kosten door automatisering, snellere besluitvorming dankzij realtime analyses, beter klantinzicht door grootschalige verwerking van kwalitatieve feedback en risicobeperking door consistente nalevingscontrole.
De technologie is verder geëvolueerd dan onderzoeksprojecten en biedt nu productieklare systemen. Lichtgewicht modellen zoals DistilBERT leveren sterke prestaties met praktische implementatievereisten. Cloudplatforms en voorgeprogrammeerde modellen verlagen de implementatiedrempels. De zakelijke waarde is in diverse sectoren bewezen.
Maar succes vereist meer dan alleen de juiste technologiekeuze. Organisaties moeten investeren in kwalitatief hoogwaardige trainingsdata, modellen aanpassen aan de specifieke bedrijfscontext, integreren met bestaande workflows en systemen onderhouden naarmate de taal en de bedrijfsbehoeften veranderen. Verandermanagement dat ingaat op de zorgen van medewerkers en realistische verwachtingen ten aanzien van de nauwkeurigheid, voorkomt teleurstelling.
De vraag is niet langer of NLP zakelijke waarde oplevert – het bewijsmateriaal bevestigt dit overtuigend. De vraag is welke toepassingen de grootste impact hebben op specifieke organisatorische behoeften en hoe deze effectief kunnen worden geïmplementeerd.
Organisaties die nog volledig afhankelijk zijn van handmatige tekstverwerking, komen steeds vaker in een concurrentienadeel terecht, omdat concurrenten NLP inzetten voor snelheid, schaalbaarheid en inzichten. Het is nu het moment om de toepassingen van NLP voor uw bedrijf te onderzoeken.
Begin met een gerichte use case die een duidelijk pijnpunt aanpakt, investeer in datavoorbereiding en modelaanpassing, meet de impact met concrete metrics en bouw voort op bewezen successen. Deze pragmatische aanpak bouwt NLP-capaciteit op die een duurzaam concurrentievoordeel oplevert.