Kurzzusammenfassung: Deep Learning ist ein spezialisierter Teilbereich des maschinellen Lernens, der mehrschichtige neuronale Netze nutzt, um komplexe Muster automatisch aus Rohdaten zu lernen. Maschinelles Lernen ist ein umfassenderes Feld der KI, das neben Deep Learning auch traditionelle Algorithmen mit manuell definierten Merkmalen umfasst. Der entscheidende Unterschied: Maschinelles Lernen erfordert manuelle Merkmalsentwicklung und eignet sich gut für kleinere Datensätze, während Deep Learning Merkmale automatisch extrahiert, aber große Datenmengen und Rechenleistung benötigt.
Die Begriffe maschinelles Lernen und Deep Learning werden in Technologiekreisen oft synonym verwendet. Fakt ist aber: Sie sind nicht dasselbe, und das Verständnis dieses Unterschieds ist wichtig, wenn man KI-Systeme entwickelt oder einfach nur die Funktionsweise moderner Technologien verstehen möchte.
Beide fallen unter den Begriff der künstlichen Intelligenz. Beide lernen aus Daten. Doch die Art und Weise, wie sie Probleme angehen, Informationen verarbeiten und Ergebnisse liefern, unterscheidet sich grundlegend.
Laut Stanford HAI ist Deep Learning ein Teilgebiet des maschinellen Lernens, das große, mehrschichtige neuronale Netze nutzt, um automatisch komplexe Muster aus Daten zu lernen. Anstatt dass eine Person die zu suchenden Merkmale manuell programmiert, entdecken diese Modelle selbstständig zunehmend abstrakte Repräsentationen.
Kommt Ihnen das bekannt vor? Das liegt daran, dass Deep Learning die Grundlage für den Sprachassistenten auf Ihrem Smartphone, die Empfehlungsalgorithmen auf Streaming-Plattformen und die Sprachmodelle bildet, die unsere Arbeitsweise verändern.
Was ist maschinelles Lernen?
Maschinelles Lernen ist eine Methode der künstlichen Intelligenz, bei der Systeme aus Daten lernen, ohne für jedes Szenario explizit programmiert zu werden. Anstatt Regeln für jede mögliche Eingabe zu schreiben, trainieren Entwickler Modelle, Muster zu erkennen und auf Basis von Beispielen Vorhersagen zu treffen.
Dieser Ansatz basiert auf Algorithmen, die sich durch Erfahrung verbessern. Wenn man ein Machine-Learning-Modell mit genügend gekennzeichneten Daten füttert – beispielsweise mit E-Mails, die als Spam oder Nicht-Spam markiert sind –, lernt es, neue E-Mails selbstständig zu klassifizieren.
Doch es gibt einen Haken. Traditionelles maschinelles Lernen erfordert Feature Engineering – den Prozess, bei dem Menschen die Datenmerkmale, die das Modell untersuchen soll, manuell auswählen und gestalten. Bei der Bilderkennung könnte dies bedeuten, das System so zu programmieren, dass es nach Kanten, Ecken oder bestimmten Farbmustern sucht.
Dieser menschliche Eingriff beeinflusst, was das Modell lernt. Wählt man die falschen Merkmale, leidet die Leistung. Wählt man sie richtig, können selbst relativ einfache Algorithmen solide Ergebnisse bei strukturierten Daten liefern.
Arten des maschinellen Lernens
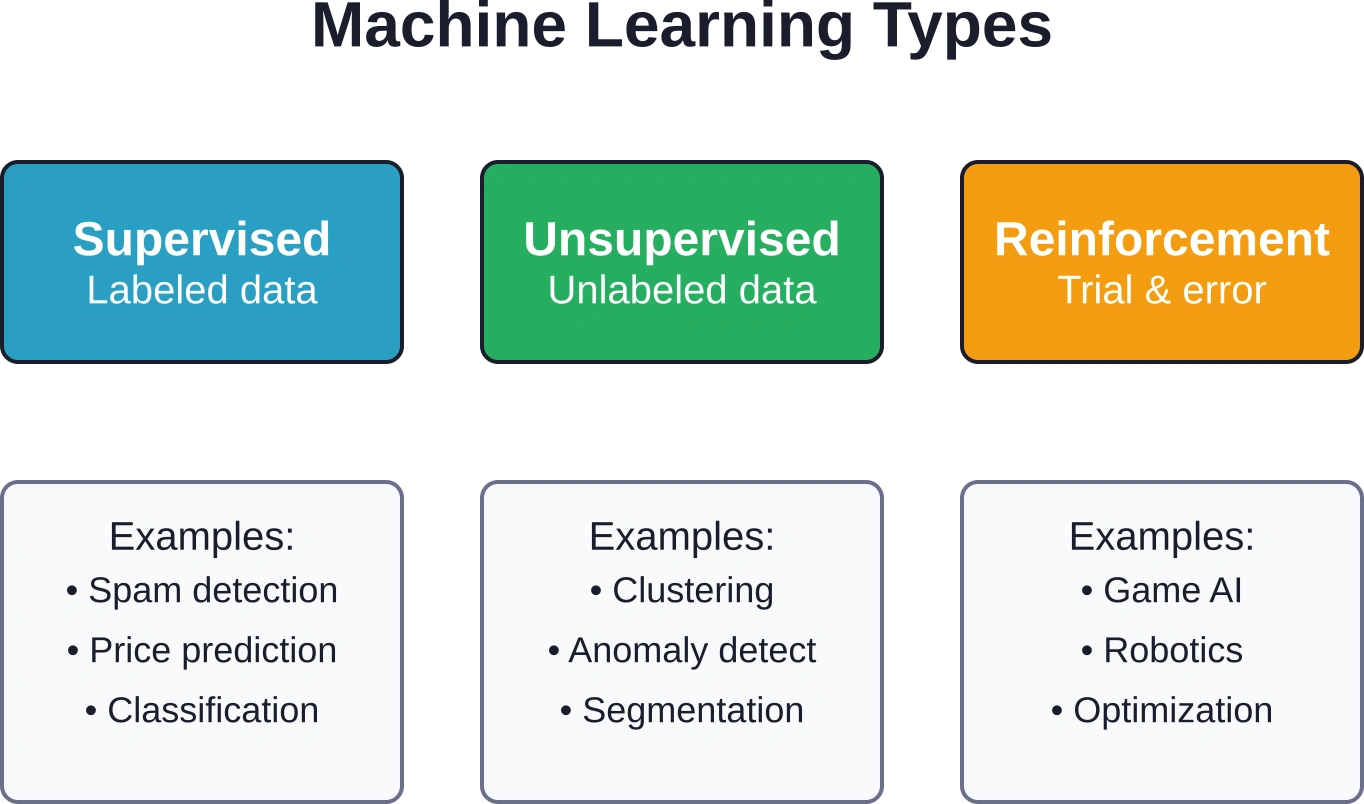
Maschinelles Lernen lässt sich in drei Hauptkategorien unterteilen, je nachdem, wie der Algorithmus lernt:
- Überwachtes Lernen trainiert anhand von gekennzeichneten Daten, bei denen die korrekte Antwort bekannt ist. Das Modell lernt, Eingaben Ausgaben zuzuordnen – beispielsweise die Vorhersage von Hauspreisen basierend auf Wohnfläche, Lage und Alter. Die meisten Geschäftsanwendungen fallen in diese Kategorie.
- Unüberwachtes Lernen arbeitet mit ungelabelten Daten und findet verborgene Muster ohne vordefinierte Kategorien. Die Gruppierung von Kunden anhand ihres Kaufverhaltens oder die Erkennung von Anomalien im Netzwerkverkehr sind Beispiele für diesen Ansatz.
- Beim Reinforcement Learning wird durch Ausprobieren gelernt, wobei die getroffenen Aktionen mit Belohnungen oder Strafen geahndet werden. KI-Systeme in Spielen und Robotern nutzen diese Methode häufig, im traditionellen Geschäftsumfeld ist sie jedoch weniger verbreitet.
Was ist Deep Learning?
Deep Learning geht über das maschinelle Lernen hinaus, indem es neuronale Netze mit mehreren Schichten verwendet – daher der Name “Deep”. Diese Netze bestehen aus miteinander verbundenen Knoten (Neuronen), die in Schichten organisiert sind, welche die Daten sequenziell verarbeiten, wobei jede Schicht zunehmend komplexere Merkmale extrahiert.
Die Architektur spiegelt wider, wie Forscher die Informationsverarbeitung im menschlichen Gehirn verstehen, auch wenn die biologische Analogie ihre Grenzen hat. Praktisch relevant ist: Deep-Learning-Modelle können die für die Merkmalserkennung benötigten Repräsentationen automatisch aus Rohdaten extrahieren.
Manuelle Merkmalsentwicklung ist nicht erforderlich. Man füttert ein Deep-Learning-System mit Rohbildern, und es lernt selbstständig, Kanten in frühen Schichten, Formen in mittleren Schichten und vollständige Objekte in tieferen Schichten zu erkennen.
Dieses automatische Merkmalslernen macht Deep Learning besonders leistungsstark für unstrukturierte Daten – Bilder, Audio, Text, Video. Aufgaben, die das traditionelle maschinelle Lernen jahrzehntelang vor unlösbare Probleme stellten, wurden plötzlich handhabbar.
Neuronale Netze erklärt
Das Herzstück des Deep Learning bildet das neuronale Netzwerk. Man kann es sich als eine Reihe von Verarbeitungsschichten vorstellen, die jeweils mehrere Knoten enthalten, welche mathematische Operationen an den eingehenden Daten durchführen.
Informationen fließen im Netzwerk vorwärts. Jede Verbindung zwischen Knoten hat ein Gewicht, das während des Trainings angepasst wird. Das Netzwerk lernt, indem es diese Gewichte optimiert, um Vorhersagefehler zu minimieren – ein Prozess, der als Backpropagation bezeichnet wird.
Flache neuronale Netze besitzen möglicherweise ein oder zwei verborgene Schichten zwischen Eingabe und Ausgabe. Tiefe Netze hingegen verfügen über Dutzende oder sogar Hunderte von Schichten, wodurch sie extrem komplexe Zusammenhänge modellieren können.
Die Tiefe hat ihren Preis: Rechenintensität. Das Training tiefer neuronaler Netze erfordert erhebliche Rechenleistung, weshalb das Forschungsgebiet parallel zu den Fortschritten im GPU-Computing einen rasanten Aufschwung erlebte.
Wesentliche Unterschiede zwischen maschinellem Lernen und Deep Learning
Und hier wird es interessant. Obwohl Deep Learning unter den Begriff des maschinellen Lernens fällt, gibt es in der Praxis einige grundlegende Unterschiede.
Datenanforderungen
Herkömmliche Algorithmen des maschinellen Lernens erzielen gute Ergebnisse mit kleineren Datensätzen – manchmal nur mit wenigen Tausend Beispielen. Statistische Methoden wie Entscheidungsbäume, Random Forests oder Support Vector Machines extrahieren aussagekräftige Muster aus begrenzten Daten.
Deep Learning erfordert große Datenmengen. Neuronale Netze enthalten Millionen von Parametern, die angepasst werden müssen, weshalb für ein effektives Training massive Datensätze benötigt werden. Werden Deep-Learning-Modellen zu wenige Daten zugeführt, kommt es zu Überanpassung – es merkt sich Trainingsbeispiele, anstatt verallgemeinerbare Muster zu lernen.
Branchenberichte legen nahe, dass Deep Learning typischerweise Zehntausende bis Millionen von gekennzeichneten Beispielen benötigt, um seine Spitzenleistung zu erreichen, wobei Transferlernverfahren diesen Bedarf reduzieren können.
Funktionsentwicklung
Hier verlagert sich die Arbeitsbelastung dramatisch. Experten für maschinelles Lernen verbringen viel Zeit mit Feature Engineering – der Auswahl, Transformation und Erstellung der Eingabevariablen, die ihre Modelle verwenden werden.
Sind Kundendaten vorhanden? Entwickler könnten vor dem Training Merkmale wie “Tage seit dem letzten Kauf”, “durchschnittlicher Bestellwert” oder “Kaufhäufigkeit” erstellen. Dieses Fachwissen beeinflusst die Modellleistung maßgeblich.
Deep Learning automatisiert diesen Prozess. Die neuronalen Netzwerkschichten lernen Merkmale während des Trainings hierarchisch. Dies reduziert den menschlichen Aufwand, bringt aber auch einen Kompromiss mit sich: weniger Kontrolle darüber, was das Modell tatsächlich lernt.
Rechenressourcen
Ein Machine-Learning-Modell auf dem Laptop ausführen? Absolut. Viele traditionelle Algorithmen lassen sich schnell auf Standardhardware trainieren, wodurch sie auch für ressourcenbeschränkte Szenarien zugänglich und praktisch sind.
Deep-Learning-Modelle sind rechenintensive Giganten. Das Training modernster Netzwerke erfordert spezialisierte Hardware – GPUs oder TPUs – und kann selbst auf leistungsstarken Systemen Tage oder Wochen dauern. Entsprechend steigen die Betriebskosten.
Die Inferenz (mithilfe eines trainierten Modells) unterscheidet sich ebenfalls. Modelle des maschinellen Lernens liefern typischerweise Vorhersagen in Millisekunden auf einfacher Hardware. Große Deep-Learning-Modelle benötigen unter Umständen eine dedizierte Infrastruktur, um die Anforderungen an die Echtzeit-Latenz zu erfüllen.
Interpretierbarkeit
Maschinelle Lernmodelle, insbesondere einfachere wie Entscheidungsbäume oder lineare Regression, bieten Transparenz. Entwickler können genau nachvollziehen, warum ein Modell eine bestimmte Vorhersage getroffen hat, was in regulierten Branchen oder bei wichtigen Entscheidungen von Bedeutung ist.
Deep Learning funktioniert wie eine Blackbox. Angesichts von Millionen von Gewichtungen in Dutzenden von Schichten wird es nahezu unmöglich zu verstehen, warum ein neuronales Netzwerk eine bestimmte Entscheidung getroffen hat. Die Forschung im Bereich der erklärbaren KI versucht, dieses Problem zu lösen, doch die Interpretierbarkeit bleibt eine anhaltende Herausforderung.
Eine MIT-Studie vom Dezember 2021 wies auf ein Problem hin: Neuronale Netze, die mit Datensätzen wie CIFAR-10 trainiert wurden, trafen selbst dann zuverlässige Vorhersagen, wenn 95 Prozent der Eingabebilder fehlten und die restlichen für Menschen bedeutungslos waren. Diese Überinterpretation wirft Fragen hinsichtlich der Zuverlässigkeit in kritischen Anwendungen auf.
Leistungsabwägungen
Bei strukturierten, tabellarischen Daten – wie Tabellenkalkulationen mit Zeilen und Spalten – ist traditionelles maschinelles Lernen oft überlegen. Entscheidungsbäume, Gradient Boosting und ähnliche Methoden erzielen bei diesen Aufgaben häufig bessere Ergebnisse als neuronale Netze, trainieren schneller und benötigen weniger Daten.
Deep Learning dominiert die Verarbeitung unstrukturierter Daten. Bilderkennung, Verarbeitung natürlicher Sprache, Spracherkennung – diese Bereiche erlebten revolutionäre Verbesserungen, nachdem Deep Learning ausgereift war. Studien zeigen, dass Deep Learning bei Bildverarbeitungsaufgaben eine höhere Genauigkeit erzielen kann als traditionelles maschinelles Lernen, wobei einige Untersuchungen Leistungsunterschiede in diesem Bereich aufzeigen.
Die Kluft vergrößert sich mit zunehmender Aufgabenkomplexität. Einfache Klassifizierungsverfahren begünstigen möglicherweise traditionelle Ansätze. Komplexe Mustererkennung in hochdimensionalen Daten tendiert hingegen zum Deep Learning.

Wählen Sie den richtigen KI-Ansatz mit AI Superior
Die Frage Deep Learning versus Machine Learning ist nicht nur technischer Natur. Sie beeinflusst den Datenbedarf, die Entwicklungszeit, die Modellkomplexität und die praktische Anwendung der Lösung. AI Superior Wir unterstützen Unternehmen beim Vergleich von KI-Ansätzen durch KI-Beratung, maschinelles Lernen, Deep Learning, prädiktive Analysen, NLP, Computer Vision und die Entwicklung kundenspezifischer KI-Software. Vor der Entwicklung kann das Team den Anwendungsfall, die verfügbaren Daten und die erwarteten Ergebnisse prüfen. So vermeiden Unternehmen die Wahl eines unnötig komplexen Modells und haben gleichzeitig die Möglichkeit, bei Bedarf auf fortgeschrittenere KI zurückzugreifen.
AI Superior kann bei der Beurteilung helfen:
- Ob maschinelles Lernen oder Deep Learning für die Aufgabe geeignet ist
- Datenanforderungen für verschiedene Modelltypen
- Anwendungsfälle und Modelloptionen für prädiktive Analysen
- Anwendungen von Deep Learning in Bildverarbeitungs- oder Sprachverarbeitungsprozessen
- Integration ausgewählter KI-Modelle in kundenspezifische Software
👉Kontaktieren Sie AI Superior um zu besprechen, welcher KI-Ansatz am besten zu Ihrem Projekt, Ihren Daten oder Ihren Produktanforderungen passt.
Praktische Anwendungen und Anwendungsfälle
Mal ehrlich: Bei der Wahl zwischen maschinellem Lernen und Deep Learning geht es nicht darum, welches “besser” ist – sondern darum, das richtige Werkzeug für das jeweilige Problem zu finden.
Wenn maschinelles Lernen seine Stärken ausspielt
Bei Problemen mit strukturierten Daten eignet sich traditionelles maschinelles Lernen. Die Vorhersage von Kundenabwanderung, die Erkennung von Kreditkartenbetrug, die Umsatzprognose oder die Produktempfehlung auf Basis der Kaufhistorie – diese Szenarien beinhalten typischerweise tabellarische Daten, bei denen die Beziehungen relativ direkt sind.
Auch bei begrenzten Datenmengen bietet maschinelles Lernen Vorteile. Ein Modell mit nur wenigen hundert Beispielen zu trainieren, stößt bei Deep Learning an seine Grenzen. Algorithmen wie Random Forests oder Gradient Boosting können jedoch auch aus kleineren Datensätzen aussagekräftige Muster extrahieren.
Sie benötigen Interpretierbarkeit? Maschinelles Lernen liefert die Lösung. Finanzinstitute nutzen Entscheidungsbäume für Kreditgenehmigungen, da Aufsichtsbehörden Erklärungen für Kreditentscheidungen fordern. Auch die medizinische Diagnostik profitiert davon – Ärzte möchten verstehen, warum ein Modell ein bestimmtes Risiko erkannt hat.
Wenn Deep Learning dominiert
Mit der Weiterentwicklung des Deep Learning hat sich die Bilderkennung grundlegend verändert. Gesichtserkennung, medizinische Bildanalyse, Bildverarbeitungssysteme für autonome Fahrzeuge, Qualitätskontrolle in der Fertigung – Convolutional Neural Networks haben diese Bereiche revolutioniert.
Die Verarbeitung natürlicher Sprache erlebte ähnliche Fortschritte. Maschinelle Übersetzung, Stimmungsanalyse, Chatbots und Dokumentenzusammenfassung verbesserten sich dank Deep-Learning-Architekturen wie Transformer-Architekturen dramatisch. Die Sprachmodelle, die die Geschäftskommunikation im Jahr 2026 prägen werden, basieren vollständig auf tiefen neuronalen Netzen.
Die Spracherkennung, die einst frustrierend ungenau war, ist durch Deep Learning zuverlässig geworden. Sprachassistenten, Transkriptionsdienste und Barrierefreiheitstools nutzen allesamt rekurrente oder konvolutionelle neuronale Netze, die mit riesigen Audiodatensätzen trainiert wurden.
Videoanalyse, Anomalieerkennung in komplexen Systemen und generative KI – die Erzeugung neuer Bilder, Texte oder Audiodateien – hängen alle von der Fähigkeit des Deep Learning ab, komplizierte Muster in hochdimensionalen Daten zu modellieren.
Die richtige Herangehensweise wählen
Wie treffen Praktiker also ihre Entscheidung? Mehrere Faktoren beeinflussen die Wahl:
- Das Datenvolumen ist entscheidend: Haben Sie Millionen von Beispielen? Dann ist Deep Learning eine sinnvolle Option. Arbeiten Sie mit Hunderten oder Tausenden? Dann bleiben Sie beim traditionellen maschinellen Lernen.
- Der Datentyp beeinflusst die Entscheidung: Strukturierte, tabellarische Daten eignen sich eher für maschinelles Lernen. Bilder, Texte, Audio- oder Videodaten deuten hingegen auf Deep Learning hin.
- Ressourcenbeschränkungen dürfen nicht ignoriert werden: Begrenzte Budgets und Rechenleistung begünstigen die Effizienz von maschinellem Lernen. Der Zugang zu GPUs und ausreichend Zeit für umfangreiches Training eröffnet Möglichkeiten des Deep Learning.
- Das Spannungsverhältnis zwischen Genauigkeitsanforderungen und Interpretierbarkeit erzeugt einen Konflikt: Benötigen Sie höchste Genauigkeit bei einer komplexen Aufgabe? Dann könnte Deep Learning den Kompromiss der Intransparenz wert sein. Legen Sie Wert auf Transparenz und Erklärbarkeit? Die einfacheren Modelle des maschinellen Lernens bieten Klarheit.
- Die Verfügbarkeit von Domänenexpertise beeinflusst die Machbarkeit des Feature Engineerings: Kompetente Fachexperten können effektive Merkmale für maschinelles Lernen entwickeln. Fehlendes Domänenwissen begünstigt hingegen die automatische Merkmalserkennung durch Deep Learning.
| Rücksichtnahme | Maschinelles Lernen | Tiefes Lernen |
|---|---|---|
| Datensatzgröße | Hunderte bis Tausende | Tausende bis Millionen |
| Datentyp | Strukturiert/tabellarisch | Unstrukturiert (Bild/Text/Audio) |
| Trainingszeit | Minuten bis Stunden | Stunden bis Wochen |
| Hardwareanforderungen | Standard-CPU | GPU/TPU bevorzugt |
| Funktionsentwicklung | Manuell, domänengesteuert | Automatisch, gelernt |
| Interpretierbarkeit | Hoch (insbesondere einfache Modelle) | Niedrig (schwarze Box) |
Die Beziehung zur künstlichen Intelligenz
Maschinelles Lernen und Deep Learning sind beide Teil des umfassenderen Feldes der künstlichen Intelligenz. KI umfasst alle Techniken, die es Computern ermöglichen, menschliche Intelligenz nachzuahmen – einschließlich regelbasierter Systeme, die überhaupt nicht lernen.
Maschinelles Lernen ist ein Teilgebiet der KI, das sich auf das Lernen aus Daten konzentriert. Deep Learning ist ein weiteres Teilgebiet des maschinellen Lernens, das neuronale Netze mit mehreren Schichten nutzt.
Die Hierarchie sieht folgendermaßen aus: Künstliche Intelligenz (KI) umfasst maschinelles Lernen, welches wiederum Deep Learning beinhaltet. Alles Deep Learning ist maschinelles Lernen, aber nicht alles maschinelle Lernen ist Deep Learning. Alles maschinelle Lernen ist KI, aber nicht alles KI ist maschinelles Lernen.
Laut einer Studie des MIT Sloan nutzten in jüngsten Umfragen weltweit rund 351.000 Unternehmen KI, weitere 421.000 Unternehmen erkundeten die Technologie. Die Entwicklung generativer KI – die auf leistungsstarken Deep-Learning-Modellen basiert – beschleunigte die Verbreitung seit 2022.
Aber Moment mal. Das bedeutet nicht, dass Deep Learning maschinelles Lernen ersetzt hat. Unterschiedliche Werkzeuge dienen unterschiedlichen Zwecken. Viele Produktionssysteme kombinieren beide Ansätze: Sie nutzen traditionelles maschinelles Lernen für strukturierte Datenpipelines und wenden Deep Learning auf unstrukturierte Eingaben an.
Aktuelle Trends und zukünftige Entwicklungen
Das Gebiet entwickelt sich ständig weiter. Transferlernen reduziert den Datenhunger des Deep Learning, indem es mit vortrainierten Modellen beginnt und diese für spezifische Aufgaben feinabstimmt – manchmal sind dafür nur Hunderte statt Millionen von Beispielen nötig.
Modellkomprimierungstechniken machen Deep Learning zugänglicher, indem sie Netzwerke verkleinern, die ohne massiven Rechenaufwand auf mobilen Geräten oder Edge-Computing-Hardware laufen können.
AutoML-Plattformen automatisieren die Modellauswahl und die Hyperparameteroptimierung sowohl für maschinelles Lernen als auch für Deep Learning und reduzieren so die erforderliche Expertise für die Implementierung.
Hybride Ansätze kombinieren die Interpretierbarkeit traditioneller maschineller Lernverfahren mit der Mustererkennungsleistung des Deep Learning. Forscher untersuchen neuronale Netze, die ihre Entscheidungen erklären oder Domänenwissen durch strukturierte Architekturen integrieren können.
Generative KI – die Technologie hinter Tools wie ChatGPT – stellt die neueste Entwicklung im Bereich des Deep Learning dar. Sie erzeugt völlig neue Inhalte, anstatt lediglich zu klassifizieren oder vorherzusagen. Diese Teilmenge nutzt Transformer-Architekturen und riesige Datensätze, um Texte, Bilder, Code und mehr zu generieren.
Häufig gestellte Fragen
Ist Deep Learning besser als maschinelles Lernen?
Keine der beiden Methoden ist generell besser – sie eignen sich für unterschiedliche Aufgaben. Deep Learning erzielt bessere Ergebnisse bei komplexen, unstrukturierten Daten wie Bildern und Texten, wenn große Datensätze verfügbar sind. Traditionelles maschinelles Lernen ist hingegen oft bei strukturierten Daten, kleineren Datensätzen und Szenarien, die Interpretierbarkeit erfordern oder nur über begrenzte Rechenressourcen verfügen, im Vorteil.
Benötigt Deep Learning Programmierkenntnisse?
Das Erstellen von Deep-Learning-Modellen von Grund auf erfordert Programmierkenntnisse, typischerweise in Python mit Frameworks wie TensorFlow oder PyTorch. Mittlerweile gibt es jedoch No-Code- und Low-Code-Plattformen, die das Training und die Bereitstellung von Modellen über visuelle Oberflächen ermöglichen und Deep Learning somit auch für Nicht-Programmierer zugänglicher machen.
Wie viele Daten benötigt Deep Learning im Vergleich zu maschinellem Lernen?
Traditionelles maschinelles Lernen kann mit Hunderten bis Tausenden von Trainingsbeispielen effektiv arbeiten. Deep Learning benötigt typischerweise mindestens Zehntausende von Beispielen, wobei hochmoderne Modelle oft mit Millionen oder Milliarden von Datenpunkten trainiert werden. Transferlernverfahren können diese Anforderungen deutlich reduzieren.
Können maschinelles Lernen und Deep Learning zusammenarbeiten?
Absolut. Viele Produktionssysteme kombinieren beide Ansätze auf komplementäre Weise. Teams nutzen beispielsweise traditionelles maschinelles Lernen für strukturierte Datenmerkmale und wenden gleichzeitig Deep Learning zur Verarbeitung von Bildern oder Texten an. Anschließend werden die Vorhersagen beider Modelle für die endgültige Entscheidungsfindung kombiniert.
Was sollte ich als Anfänger zuerst lernen?
Der Einstieg mit traditionellem maschinellem Lernen schafft eine solidere Grundlage. Die mathematischen Konzepte, Evaluierungsmethoden und Arbeitsablaufprinzipien sind in beiden Bereichen anwendbar. Sobald man mit den Grundlagen des maschinellen Lernens vertraut ist, wird der Übergang zum Deep Learning intuitiver, da es auf denselben Kernideen aufbaut.
Sind neuronale Netze traditionellen Algorithmen immer überlegen?
Keineswegs. Bei strukturierten tabellarischen Daten erreichen oder übertreffen Algorithmen wie Gradient Boosting oder Random Forests häufig die Leistung neuronaler Netze, trainieren dabei aber schneller und benötigen weniger Daten. Neuronale Netze zeigen ihre Stärke bei unstrukturierten Daten, wo traditionelle Methoden an ihre Grenzen stoßen.
Wie lange dauert das Training eines Deep-Learning-Modells?
Die Trainingszeit variiert enorm je nach Modellgröße, Datensatzgröße und Hardware. Einfache Netzwerke können auf einem Laptop innerhalb weniger Minuten trainiert werden. Große Sprachmodelle oder Computer-Vision-Systeme benötigen hingegen Tage oder Wochen auf spezialisierten GPU-Clustern. Traditionelle Modelle des maschinellen Lernens trainieren typischerweise deutlich schneller, oft innerhalb von Minuten bis Stunden.
Weiter geht's
Das Verständnis des Unterschieds zwischen maschinellem Lernen und Deep Learning verdeutlicht, welcher Ansatz für welche Probleme geeignet ist. Maschinelles Lernen bietet Vielseitigkeit, Effizienz und Interpretierbarkeit für strukturierte Daten und ressourcenbeschränkte Szenarien. Deep Learning ermöglicht beispiellose Leistungen bei komplexen, unstrukturierten Daten, wenn Rechenressourcen und große Datensätze zur Verfügung stehen.
Die Wahl hängt nicht davon ab, Trends zu folgen, sondern davon, die Fähigkeiten den Anforderungen anzupassen. Manche Teams setzen sofort auf Deep Learning, weil es als zukunftsweisend gilt, und stellen dann fest, dass traditionelles maschinelles Lernen schneller bessere Ergebnisse geliefert hätte. Andere bleiben bei bewährten Methoden, obwohl Deep Learning bisher unlösbare Probleme bewältigen könnte.
Beide Bereiche entwickeln sich rasant weiter. Wer über ihre jeweiligen Stärken informiert ist, kann als Entwickler, Datenwissenschaftler und Unternehmensleiter fundiertere Technologieentscheidungen treffen.
Sind Sie bereit, diese Konzepte anzuwenden? Beginnen Sie mit der Analyse Ihres konkreten Anwendungsfalls: Datentyp, Datenvolumen, Genauigkeitsanforderungen und Ressourcenbeschränkungen. Das richtige Werkzeug wird deutlich, sobald Sie die jeweiligen Vorteile der einzelnen Ansätze verstehen.