Résumé rapide : L'analyse exploratoire des données (AED) est le processus d'investigation des ensembles de données par la visualisation et des méthodes statistiques afin de révéler des tendances, de repérer les anomalies et de tester les hypothèses avant la modélisation formelle. Elle implique l'examen des distributions de données, des relations entre les variables et l'identification des valeurs aberrantes pour comprendre la structure et la qualité des données. L'AED constitue une première étape cruciale dans tout projet de science des données, permettant aux équipes de prendre des décisions éclairées quant aux techniques analytiques à appliquer.
Les données ne révèlent pas immédiatement leurs secrets. Les ensembles de données brutes dissimulent souvent des tendances, des valeurs aberrantes et des relations sous des couches de chiffres et de texte. C'est là qu'intervient l'analyse exploratoire des données : une approche systématique permettant de comprendre le contenu réel de vos données avant de vous lancer dans la modélisation ou les prédictions.
Selon le site Statistics Online de l'Université d'État de Pennsylvanie, l'analyse exploratoire des données (EDA) peut être décrite comme une génération d'hypothèses fondée sur les données. Plutôt que de partir de suppositions, les analystes laissent les données guider leur compréhension grâce à un examen attentif des structures susceptibles de révéler des relations plus profondes entre les cas ou les variables.
Ce guide complet aborde tous les aspects, de l'inspection de base des jeux de données aux techniques multivariées avancées. Qu'il s'agisse de traiter des données réelles complexes ou de préparer des projets d'apprentissage automatique, la maîtrise des techniques d'analyse exploratoire des données (EDA) garantit un travail analytique de qualité dès le départ.
Qu'est-ce que l'analyse exploratoire des données ?
L'analyse exploratoire des données est une approche d'analyse des ensembles de données qui privilégie la compréhension à la modélisation immédiate. L'objectif n'est pas de tester d'emblée des hypothèses, mais de les formuler en examinant ce que les données révèlent par la visualisation et la synthèse statistique.
L'analyse exploratoire des données (EDA) repose essentiellement sur deux aspects fondamentaux : la synthèse numérique et la visualisation des données. Ces techniques complémentaires fonctionnent de concert pour révéler des tendances qui pourraient autrement rester cachées dans des tableurs ou des bases de données.
L'EPA décrit l'EDA comme une approche analytique permettant d'identifier les tendances générales dans les données, notamment les valeurs aberrantes et les caractéristiques potentiellement inattendues. Cette investigation initiale jette les bases de tous les travaux analytiques ultérieurs.
Objectif de l'EDA
Pourquoi consacrer du temps à l'exploration avant l'analyse ? Parce que les hypothèses concernant les données s'avèrent souvent erronées. Une variable supposée suivre une loi normale peut présenter une forte asymétrie. Les relations attendues entre les caractéristiques peuvent être inexistantes, tandis que des corrélations inattendues peuvent apparaître.
L'analyse exploratoire des données (EDA) permet d'éviter des efforts inutiles liés à des techniques analytiques inappropriées. La découverte de valeurs manquantes importantes ou de valeurs aberrantes extrêmes dans un jeu de données modifie le choix des méthodes qui produiront des résultats valides. La présence de colinéarité entre les variables explicatives influence les approches de modélisation par régression.
Cette phase exploratoire permet également de mieux comprendre le domaine des données. La connaissance des plages de valeurs typiques, des tendances saisonnières ou de la distribution des catégories aide à contextualiser les résultats ultérieurs et à repérer les erreurs de modélisation qui produisent des résultats invraisemblables.
Composants essentiels de l'EDA
Selon des sources universitaires de Penn State, une analyse exploratoire des données (EDA) efficace combine plusieurs éléments clés qui fonctionnent ensemble pour construire une compréhension globale des données.
Collecte de données et évaluation de la qualité
Avant de commencer l'analyse, il est primordial de comprendre la provenance des données. Selon le guide d'initiation de Georgia Tech, la première phase de l'analyse exploratoire des données (EDA) consiste à vérifier la structure de l'ensemble de données : nombre de lignes et de colonnes, sources des fichiers et périodes couvertes.
À ce stade, les signaux d'alerte incluent des ensembles de données anormalement petits ou grands, des sources mixtes sans étiquetage approprié ou une couverture temporelle imprécise. L'enregistrement d'instantanés de données avec les décomptes, les chemins d'accès aux sources et les dates de collecte garantit la reproductibilité dès le départ.
La vérification de la cohérence du schéma suit, examinant les types de données, les problèmes d'analyse syntaxique et les niveaux de catégorie. La présence d'identifiants stockés sous forme de nombres à virgule flottante ou de dates représentées sous forme de chaînes de caractères signale des problèmes qui doivent être corrigés avant que toute analyse pertinente puisse être effectuée.
Modèles de manque
Les données manquantes apparaissent rarement de manière aléatoire. L'examen des pourcentages de données manquantes par colonne et par ligne révèle si l'absence de données suit des schémas liés à des sous-groupes ou des conditions spécifiques.
Les schémas de données manquantes non aléatoires, ou blocs “ tout ou rien ” où des enregistrements entiers sont dépourvus d'informations, suggèrent des problèmes de collecte systématiques plutôt que des lacunes aléatoires. La compréhension de ces schémas influence les stratégies d'imputation et détermine si certaines variables restent utilisables.
Types d'analyse exploratoire des données
Les techniques d'analyse exploratoire des données (EDA) se répartissent en catégories selon le nombre de variables examinées simultanément et selon que les méthodes graphiques ou quantitatives prédominent.
Analyse univariée
L'exploration univariée examine une variable à la fois, établissant une compréhension de base des caractéristiques individuelles avant d'étudier les relations.
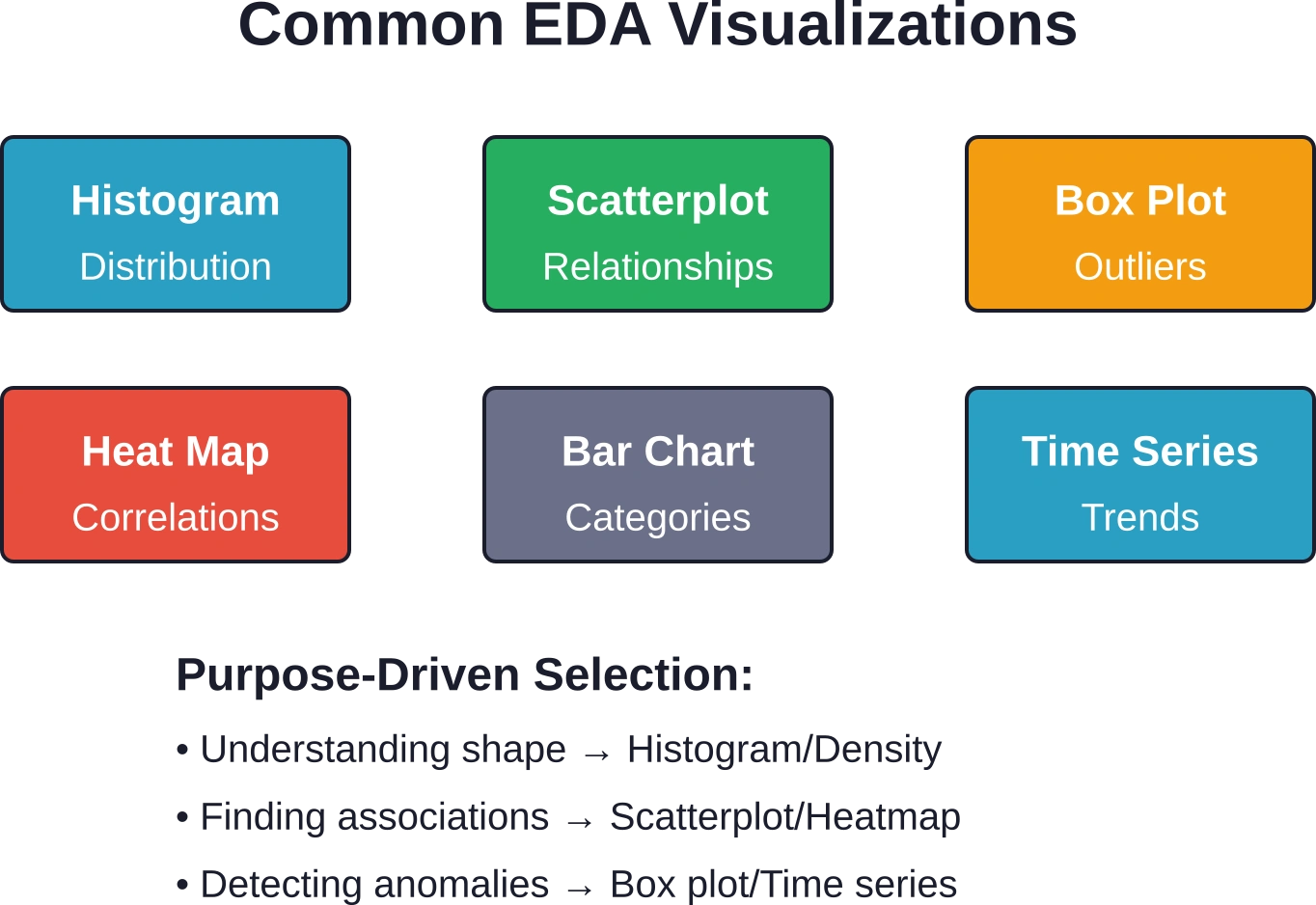
Pour les variables numériques, cela implique le calcul de mesures de tendance centrale (moyenne, médiane, mode) et de dispersion (écart type, variance, étendue). Les histogrammes révèlent la forme de la distribution : les données suivent-elles une loi normale, asymétrique, bimodale ou uniforme ?.
D'après la présentation de l'EPA, les histogrammes résument les distributions en classant les observations par intervalles et en comptant les occurrences dans chaque intervalle. L'axe des ordonnées peut représenter le nombre d'observations, le pourcentage du total, la fraction du total (probabilité) ou la densité.
Les variables catégorielles nécessitent des tableaux de fréquences et des diagrammes à barres illustrant la répartition des observations entre les catégories. L'identification des catégories dominantes et rares permet d'orienter les décisions de modélisation ultérieures concernant le regroupement ou le traitement particulier des données.
Analyse bivariée
Les techniques bivariées explorent les relations entre deux variables. Les nuages de points visualisent les associations entre variables continues, révélant des relations linéaires, des courbes, des regroupements ou l'absence de schéma apparent.
L'analyse de corrélation quantifie la force des relations linéaires. Cependant, corrélation n'implique pas causalité, et se concentrer uniquement sur les coefficients de corrélation masque les relations non linéaires visibles sur les graphiques.
Le tableau croisé examine les associations entre les variables catégorielles, tandis que les diagrammes en boîte regroupés par catégories comparent les distributions entre les sous-groupes — par exemple, en examinant les distributions de revenus séparément pour différents niveaux d'éducation.
Analyse multivariée
Les problèmes concrets impliquent de multiples variables interagissant simultanément. Les techniques d'analyse exploratoire multivariée traitent trois variables ou plus, révélant des schémas complexes invisibles lors de comparaisons par paires.
Les matrices de nuages de points affichent toutes les relations par paires dans une grille, offrant une vue d'ensemble des structures de corrélation. Le codage couleur des points selon une variable catégorielle ajoute une troisième dimension aux nuages de points classiques.
Les cartes thermiques permettent de visualiser les matrices de corrélation, facilitant ainsi le repérage des groupes de variables liées. L'analyse en composantes principales (plus complexe) réduit la dimensionnalité tout en préservant la variance, aidant à identifier les combinaisons de variables qui expliquent la plus grande part de la variation.
Techniques et outils essentiels de CAO électronique
Un travail exploratoire efficace nécessite une combinaison adéquate de méthodes statistiques et d'approches de visualisation.
Techniques de synthèse statistique
Les statistiques descriptives constituent le socle quantitatif de l'analyse exploratoire des données (AED). Au-delà des moyennes et des médianes, l'examen des quartiles révèle la dispersion des données. Le résumé à cinq chiffres (minimum, premier quartile, médiane, troisième quartile, maximum) offre une vision complète de la forme de la distribution.
D'après les exemples de Penn State, un jeu de données contenant 10 objets et 4 attributs (ID, Sexe, Niveau d'études, Revenu) pourrait présenter des revenus allant de $0 à $100 000. Ces limites définissent l'échelle de la variable et permettent de déterminer si les valeurs se situent dans les plages attendues.
L'asymétrie et l'aplatissement quantifient l'asymétrie de la distribution et l'épaisseur des queues. Une asymétrie positive indique une longue queue à droite, tandis qu'un aplatissement négatif suggère des queues plus fines que celles d'une distribution normale.
Méthodes de visualisation
Les graphiques révèlent des tendances que les seuls résumés statistiques pourraient ne pas mettre en évidence. Différents types de graphiques servent des objectifs distincts dans le processus exploratoire.
Les histogrammes et les graphiques de densité illustrent la forme des distributions. Les diagrammes en boîte présentent efficacement les médianes, les quartiles et les valeurs aberrantes, tout en facilitant la comparaison entre les groupes. Les diagrammes en violon combinent les informations des diagrammes en boîte avec l'estimation de densité par noyau.
Les nuages de points demeurent essentiels pour examiner les relations entre variables continues. L'ajout de courbes de tendance permet d'évaluer si les modèles linéaires s'ajustent bien aux données.
Les graphiques à barres comparent les catégories, tandis que les graphiques chronologiques révèlent les tendances temporelles : les tendances, la saisonnalité et les périodes anormales.
Environnements logiciels et de programmation
D'après les supports de cours de Penn State, le logiciel R offre plusieurs fonctionnalités intéressantes pour l'analyse exploratoire des données (EDA). Python, avec des bibliothèques comme Pandas, Matplotlib et Seaborn, offre des capacités tout aussi puissantes.
Les deux environnements permettent une analyse reproductible grâce à la programmation, ce qui permet aux analystes de documenter chaque étape de transformation et de visualisation. Cette reproductibilité s'avère essentielle lors de la mise à jour des jeux de données ou lorsque des collègues doivent vérifier les résultats.
Les notebooks Jupyter et R Markdown combinent code, visualisations et explications narratives en documents cohérents qui communiquent les résultats exploratoires aux parties prenantes qui ne lisent pas le code brut.
Processus EDA étape par étape
Si le travail exploratoire fait appel à la créativité, le respect d'une approche structurée garantit une couverture exhaustive sans négliger les points critiques.
Phase 1 : Inspection initiale des données
Commencez par charger l'ensemble de données et examinez ses propriétés de base. Combien de lignes et de colonnes ? Quels types de données apparaissent dans chaque colonne ? Y a-t-il des erreurs d'analyse ou des problèmes d'encodage évidents ?
Imprimez les premières et dernières lignes pour vérifier que les données ont été correctement chargées. Recherchez les enregistrements en double qui pourraient fausser les résultats de l'analyse. Assurez-vous que les colonnes d'identifiants contiennent bien des valeurs uniques.
Cette inspection initiale permet de déceler les problèmes techniques (fichiers corrompus, délimiteurs incorrects, incompatibilités d'encodage) avant d'investir du temps dans une analyse plus approfondie.
Phase 2 : Nettoyage et préparation des données
Conformément aux directives de Cornell en sciences de l'information, la documentation relative à la collecte et au nettoyage des données doit consigner chaque étape de transformation. Cela peut inclure la gestion des valeurs manquantes, la correction des types de données, la normalisation des libellés de catégories ou la suppression des enregistrements invalides.
Les stratégies de gestion des valeurs manquantes dépendent de la nature de ces données. Des données manquantes totalement aléatoires peuvent justifier une simple suppression ou une imputation par la moyenne. Des données manquantes systématiques nécessitent des approches plus sophistiquées ou l'acceptation d'échantillons de taille réduite.
Les valeurs aberrantes nécessitent une analyse approfondie. Certaines représentent des valeurs extrêmes légitimes contenant des informations importantes. D'autres reflètent des erreurs de mesure ou de saisie de données qu'il convient de supprimer ou de corriger.
Phase 3 : Exploration univariée
Analysez chaque variable individuellement. Pour les variables numériques, calculez les statistiques descriptives et créez des graphiques de distribution. Notez la tendance centrale, la dispersion et les caractéristiques de forme.
Pour les variables catégorielles, générez des tableaux de fréquences. Déterminez si les catégories semblent relativement équilibrées ou s'il existe un déséquilibre important — une situation qui affecte de nombreux algorithmes d'apprentissage automatique.
Documentez les résultats inattendus. Une variable supposément continue ne contenant que quelques valeurs discrètes, ou une variable catégorielle avec des centaines de niveaux uniques, signale des problèmes potentiels de qualité des données ou des difficultés de modélisation.
Phase 4 : Exploration bivariée et multivariée
Analysez les relations entre les variables, notamment entre les prédicteurs potentiels et les variables cibles. Les matrices de corrélation offrent un aperçu rapide des relations linéaires entre les variables numériques.
Créez des nuages de points pour les paires de variables prometteuses. Ajoutez des courbes de lissage pour déterminer si les relations sont linéaires ou nécessitent une transformation.
Pour les problèmes de classification, examinez comment les distributions des prédicteurs diffèrent selon les classes cibles. Une forte séparation suggère des caractéristiques prédictives utiles, tandis qu'un chevauchement complet indique des prédicteurs faibles.
Phase 5 : Génération d'hypothèses
À partir des tendances observées, formulez des hypothèses sur les facteurs à l'origine des variations dans les données. Ces hypothèses orienteront les modélisations ultérieures.
Il se peut que certains segments de clientèle présentent des comportements d'achat très différents. Les variations saisonnières peuvent également influencer fortement le cours du temps. L'analyse exploratoire des données (EDA) permet de faire émerger ces informations, qui sont ensuite testées et quantifiées par une modélisation formelle.
| Phase EDA | Activités clés | Sorties communes | Durée typique |
|---|---|---|---|
| Inspection initiale | Charger les données, vérifier la structure, vérifier le chargement | Instantané des données, nombre de dimensions | 10-15% de temps EDA |
| Nettoyage | Gérer les valeurs manquantes, corriger les types, supprimer les doublons | Jeu de données nettoyé, journal de transformation | 25-35% de temps EDA |
| Univarié | Analyse des variables individuelles, distributions | Statistiques descriptives, histogrammes | 20-25% de temps EDA |
| Multivarié | Relations, corrélations, modèles | Nuages de points, matrices de corrélation | 25-30% du temps EDA |
| Documentation | Consigner les résultats, formuler des hypothèses | Rapport EDA, tableau de bord de visualisation | 10-15% de temps EDA |

Optimisez l'analyse exploratoire des données grâce à l'IA supérieure
L'analyse exploratoire des données est souvent la première étape avant qu'une entreprise puisse décider quel type de projet d'IA ou d'analyse est pertinent. IA supérieure AI Superior peut accompagner cette étape grâce à des services de conseil en IA, des stratégies de données et d'IA, de veille stratégique, d'analyse de données, d'apprentissage automatique et d'analyse prédictive. Son expertise aide les entreprises à examiner leurs données disponibles, à identifier les tendances, à repérer les lacunes et à déterminer si elles sont prêtes pour une modélisation plus poussée ou le développement de logiciels d'IA. Cette approche est particulièrement utile pour les équipes qui ont collecté des données métier mais qui ne savent pas encore ce qu'elles peuvent révéler. Au lieu de se lancer directement dans la modélisation, AI Superior peut les aider à concrétiser l'exploration des données par des cas d'usage précis, à obtenir des rapports plus clairs et à préparer le terrain pour le développement futur de l'IA.
Pour les travaux d'exploration de données, AI Superior peut vous aider avec :
- Analyse des données commerciales disponibles
- Détecter des tendances, des lacunes et des signaux utiles
- Préparation des données pour l'analyse ou l'apprentissage automatique
- Création d'outils de veille stratégique et d'analyse
- Définir des cas d'utilisation pratiques de l'IA à partir des données recueillies
👉Contactez l'IA supérieure pour discuter de la manière dont l'analyse exploratoire des données peut soutenir votre prochain projet d'analyse, de BI ou d'IA.
Identification des schémas et des anomalies
L'un des principaux objectifs de l'EDA consiste à détecter les schémas qui suggèrent des relations dignes d'être étudiées et les anomalies qui pourraient indiquer des problèmes ou des cas limites intéressants.
Reconnaissance des formes
Les schémas se manifestent sous diverses formes. Les schémas temporels comprennent les tendances (augmentations ou diminutions à long terme), la saisonnalité (fluctuations périodiques régulières) et les cycles (schémas répétitifs irréguliers).
Des regroupements apparaissent lorsque les observations se regroupent naturellement en segments distincts. Les clients peuvent se regrouper selon leur comportement d'achat, les patients selon des combinaisons de symptômes, ou les régions géographiques selon des caractéristiques environnementales.
Les schémas d'association révèlent que certaines caractéristiques ont tendance à apparaître ensemble. Dans l'analyse du panier d'achat, les produits fréquemment achetés ensemble présentent de fortes associations, même en l'absence de lien de causalité.
Détection des valeurs aberrantes
Les valeurs aberrantes méritent une attention particulière lors de l'exploration. Elles peuvent représenter des problèmes de qualité des données nécessitant une correction, ou de véritables cas extrêmes contenant des informations précieuses sur des scénarios rares mais importants.
Les méthodes statistiques, comme la règle de l'écart interquartile (EIQ), identifient les valeurs aberrantes comme les points situés à plus de 1,5 fois l'EIQ au-delà des quartiles. Les scores Z signalent les observations s'écartant de plusieurs écarts-types de la moyenne, sous réserve toutefois de l'hypothèse d'une distribution approximativement normale.
L'inspection visuelle à l'aide de diagrammes en boîte ou de nuages de points s'avère souvent plus instructive que l'application de règles purement statistiques. Le contexte détermine s'il convient de supprimer, de transformer ou d'analyser séparément les valeurs aberrantes.
Corrélation versus causalité
L'analyse exploratoire des données (EDA) révèle fréquemment des corrélations, c'est-à-dire des variables qui évoluent de concert. Cependant, corrélation n'implique pas causalité. Deux variables peuvent être corrélées parce que l'une est la cause de l'autre, parce qu'elles réagissent toutes deux à une cause commune, ou par pure coïncidence.
Les ventes de crèmes glacées sont corrélées aux décès par noyade, non pas parce que la crème glacée provoque les noyades, mais parce que les deux augmentent durant l'été. Distinguer corrélation et causalité exige une connaissance approfondie du domaine et souvent des protocoles expérimentaux ou quasi-expérimentaux qui dépassent le cadre de l'analyse exploratoire des données.
Cela dit, l'identification de fortes corrélations lors de l'exploration oriente l'attention vers des relations qui méritent d'être étudiées par des méthodes d'inférence causale.
Exemples concrets d'EDA
Des exemples concrets illustrent comment les techniques d'analyse exploratoire des données (EDA) s'appliquent à des ensembles de données et à des problèmes réels.
Exemple d'analyse de régression
D'après le programme du cours STAT 508 de Penn State, un modèle de régression a été utilisé pour étudier la relation entre le salaire et l'ancienneté. Le modèle ajusté a obtenu un coefficient de détermination (R²) de 93,71, un R² ajusté de 91,61 et un R² prédit de 85,94.
L'équation de régression a révélé un coefficient constant de 24,8 et un coefficient de pente de 15,2 pour les années d'expérience, avec une valeur F de 44,78 et une valeur p de 0,007. Ces résultats suggèrent que les années d'expérience prédisent fortement le salaire dans cet ensemble de données, expliquant la majeure partie de la variation salariale.
Lors de l'analyse exploratoire des données (AED) d'un tel problème, les nuages de points permettraient d'abord de déterminer si une relation linéaire semble plausible. Les graphiques de résidus permettraient de vérifier la présence de schémas suggérant des violations des hypothèses : non-linéarité, hétéroscédasticité ou valeurs aberrantes influentes.
Exemple d'ANOVA
Les documents de Penn State comprennent des exemples d'analyses ANOVA à un facteur qui examinent les différences entre les groupes, démontrant comment interpréter les valeurs F et les valeurs p pour évaluer si les variables catégorielles prédisent de manière significative les résultats.
La valeur p élevée (0,184) suggère des preuves insuffisantes pour conclure à des différences entre les sexes dans cet ensemble de données. Une analyse exploratoire préalable inclurait des diagrammes en boîte comparant les distributions selon les catégories de sexe et vérifiant des hypothèses telles que l'homogénéité des variances.

Erreurs courantes à éviter lors de l'analyse exploratoire des données (EDA)
Même les analystes expérimentés tombent parfois dans des pièges lors de leur travail exploratoire, ce qui peut mener à des conclusions erronées ou à un gaspillage d'efforts.
Ignorer la validation des données
Se précipiter sur la visualisation sans valider la qualité des données est certes tentant, mais dangereux. Des données erronées produisent des résultats erronés : de beaux graphiques basés sur des données corrompues donnent des résultats trompeurs.
Vérifiez toujours que les données sont correctement chargées, que les types sont cohérents et que les plages de valeurs sont plausibles. Une personne affichée comme ayant 250 ans ou une température de 500 degrés Celsius signalent des problèmes nécessitant une investigation.
Dépendance excessive aux statistiques récapitulatives automatisées
Les statistiques descriptives fournissent des informations précieuses, mais elles ne permettent pas de déceler des tendances importantes. Le célèbre quatuor d'Anscombe illustre parfaitement ce phénomène : quatre ensembles de données présentant des moyennes, des variances et des corrélations identiques apparaissent pourtant très différents une fois représentés graphiquement.
Visualisez toujours vos données plutôt que de vous fier uniquement aux chiffres récapitulatifs. Les graphiques révèlent l'asymétrie, la multimodalité, les valeurs aberrantes et les relations non linéaires que les statistiques ne permettent pas de déceler.
Ignorer les connaissances du domaine
Les statistiques, lorsqu'elles sont déconnectées du contexte spécifique, peuvent induire en erreur. Une anomalie apparente peut représenter un comportement normal dans ce contexte, tandis que des tendances apparemment typiques peuvent en réalité indiquer des problèmes graves.
Consulter des experts du domaine lors de l'analyse exploratoire des données (EDA) permet d'interpréter correctement les résultats et d'orienter l'attention vers des tendances réellement importantes plutôt que vers des artefacts statistiques.
Biais de confirmation
Chercher des schémas qui confirment des croyances préexistantes tout en ignorant les preuves contradictoires compromet le travail exploratoire. L'objectif de l'analyse exploratoire des données (EDA) est de découvrir ce que les données révèlent réellement, et non de valider des hypothèses.
Une exploration systématique suivant des étapes structurées permet de contrer le biais de confirmation. Il est important de documenter les résultats inattendus, même s'ils contredisent les attentes ; ils pourraient s'avérer très précieux.
Considérations avancées en matière de CAO électronique
Au-delà des techniques fondamentales, plusieurs sujets avancés méritent d'être pris en compte pour les projets analytiques complexes.
Gestion des données multidimensionnelles
Les jeux de données comportant des centaines, voire des milliers de variables, mettent à l'épreuve les approches exploratoires traditionnelles. La création de nuages de points pour chaque paire de variables devient impraticable, et les matrices de corrélation deviennent trop volumineuses pour être interprétées visuellement.
Les techniques de réduction de dimensionnalité, comme l'analyse en composantes principales, permettent d'identifier les combinaisons linéaires de caractéristiques qui capturent la plus grande partie de la variation. Ceci permet la visualisation et l'exploration dans des espaces de dimension réduite tout en conservant la majeure partie de l'information.
Les scores d'importance des caractéristiques issus de modèles arborescents offrent une autre approche, classant les variables selon leur pouvoir prédictif et permettant aux analystes de se concentrer sur le sous-ensemble le plus pertinent.
Considérations particulières relatives aux séries chronologiques
Les données temporelles nécessitent des techniques d'analyse exploratoire des données (EDA) spécialisées. Les graphiques d'autocorrélation révèlent si les observations sont corrélées avec leurs propres valeurs passées, un élément clé pour les modèles de prévision.
La décomposition sépare les séries temporelles en composantes de tendance, saisonnières et résiduelles, ce qui permet de clarifier les schémas dominants et de suggérer des approches de modélisation appropriées.
La détection des points de rupture permet d'identifier les moments où les processus sous-jacents de génération de données changent, ce qui est essentiel pour comprendre si les tendances historiques restent pertinentes pour les prédictions futures.
Exploration des données spatiales
Les jeux de données géographiques bénéficient de la cartographie en tant que technique d'analyse exploratoire des données (EDA). Les cartes choroplèthes révèlent des schémas spatiaux — regroupements, gradients ou points chauds isolés — que les tableaux et les graphiques standard ne permettent pas de déceler.
Les mesures d'autocorrélation spatiale quantifient si des emplacements proches présentent des valeurs similaires, testant ainsi si la proximité géographique a une incidence sur le phénomène étudié.
Communication des résultats de l'analyse exploratoire des données
L'exploration génère des idées, mais ces idées ne créent de la valeur que si elles sont communiquées efficacement aux parties prenantes et aux membres de l'équipe.
Création de rapports EDA
Les rapports d'analyse exploratoire des données (EDA) complets documentent le processus exploratoire et ses résultats. Ces rapports doivent inclure la description des sources de données, les étapes de transformation effectuées, la visualisation des tendances clés et un résumé des conclusions et hypothèses formulées.
Selon les directives de Cornell, les rapports doivent énoncer clairement les objectifs dès le départ, documenter minutieusement la collecte et le nettoyage des données, calculer les statistiques descriptives pertinentes et présenter des graphiques applicables aux objectifs énoncés.
La reproductibilité est primordiale. Il est essentiel que d'autres puissent suivre la procédure documentée et parvenir aux mêmes conclusions, afin de vérifier que les résultats ne sont pas dus à des erreurs ou à des interprétations non documentées.
Meilleures pratiques de visualisation
Les visualisations EDA efficaces privilégient la clarté à l'esthétique. Chaque élément du graphique doit avoir une fonction précise : transmettre des informations plutôt que simplement impressionner.
Indiquez clairement les unités des axes. Ajoutez des titres informatifs décrivant le graphique. Choisissez des échelles appropriées qui ne déforment pas les relations ni ne masquent les variations importantes.
Pour les présentations destinées à un public non spécialisé, des visualisations simples sont souvent plus efficaces que des graphiques multidimensionnels complexes. Un diagramme à barres clair communique plus efficacement qu'une visualisation sophistiquée nécessitant de longues explications.
L'analyse exploratoire des données (EDA) dans le flux de travail élargi de la science des données
Le travail exploratoire n'est pas isolé ; il s'inscrit dans le cadre des efforts de collecte de données précédents et des phases de modélisation ultérieures.
EDA et collecte de données
Les enseignements tirés de l'exploration permettent souvent d'améliorer la collecte de données. Le manque d'informations essentielles pour répondre aux questions clés peut justifier la collecte de données supplémentaires. Les problèmes de qualité mis en évidence peuvent indiquer la nécessité de modifier les processus de traitement des données.
Cette boucle de rétroaction entre l'exploration et la collecte améliore de manière itérative les données au fil du temps, rendant ainsi les futurs travaux analytiques plus productifs.
EDA et ingénierie des fonctionnalités
Les modèles découverts lors de l'exploration orientent l'ingénierie des caractéristiques, en créant de nouvelles variables à partir de variables existantes afin de mieux saisir les relations d'intérêt.
L'observation de relations non linéaires peut suggérer la présence de termes polynomiaux ou d'interaction. Le constat que l'impact d'une variable diffère selon les sous-groupes peut justifier la création de caractéristiques distinctes pour chaque sous-groupe.
Sélection de modèles et analyse exploratoire des données (EDA)
Les résultats exploratoires orientent les choix de modélisation. Des relations linéaires entre les prédicteurs et les variables cibles suggèrent qu'une régression linéaire pourrait convenir. Des tendances non linéaires indiquent la nécessité d'utiliser des termes polynomiaux, des splines ou des méthodes non paramétriques.
La découverte d'interactions entre les fonctionnalités lors de l'analyse exploratoire des données (EDA) indique que les modèles capables de capturer ces interactions, comme les méthodes arborescentes, pourraient être plus performants que les modèles additifs.
L'identification des valeurs aberrantes permet de prendre des décisions concernant les approches de modélisation robustes par rapport à la suppression des valeurs extrêmes. La compréhension des schémas de données manquantes oriente les choix de stratégie d'imputation.
| Caractéristiques des données | Indicateur EDA | Approche de modélisation suggérée |
|---|---|---|
| relations linéaires | Diagrammes de dispersion linéaires | Régression linéaire, GLM |
| Motifs non linéaires | Relations courbes dans les graphiques | Termes polynomiaux, splines, modèles d'arbres |
| Valeurs aberrantes importantes | moustaches extrêmes du diagramme en boîte | Régression robuste, suppression des valeurs aberrantes |
| Colinéarité élevée | Matrice de corrélation > 0,9 | Régression Ridge, ACP, sélection de caractéristiques |
| Interactions complexes | Évolution des relations par sous-groupe | Modèles arborescents, termes d'interaction |
| Dominant catégorique | Variables principalement catégorielles | Régression logistique, Naïve Bayes |
Outils et technologies pour l'EDA
Le choix des outils appropriés accélère le travail exploratoire et permet une analyse plus poussée.
Langages de programmation
Python et R dominent l'analyse exploratoire des données (EDA) en science des données. La bibliothèque Pandas de Python offre de puissantes fonctionnalités de manipulation des données, tandis que Matplotlib, Seaborn et Plotly répondent aux besoins de visualisation.
R excelle dans le calcul statistique grâce à ses fonctions intégrées pour la plupart des tâches d'analyse exploratoire des données (EDA) courantes. Le package ggplot2 permet de créer des graphiques de qualité professionnelle en respectant une grammaire graphique rigoureuse.
Les deux langages prennent en charge les environnements de type notebook (Jupyter pour Python, R Markdown pour R) qui combinent code, résultats et texte explicatif en documents cohérents.
Logiciel EDA spécialisé
Tableau et Power BI offrent des interfaces intuitives pour la visualisation des données, rendant les graphiques sophistiqués accessibles aux utilisateurs moins techniques. Ces outils excellent dans la création de tableaux de bord interactifs qui permettent aux parties prenantes d'explorer les données sans écrire de code.
Cependant, elles sacrifient la reproductibilité et la personnalisation par rapport aux approches basées sur la programmation. Les modifications apportées aux graphiques nécessitent des clics manuels plutôt que la réexécution de scripts documentés.
Bibliothèques open source
Des bibliothèques comme pandas-profiling et sweetviz automatisent de nombreuses tâches d'analyse exploratoire des données (EDA), générant des rapports complets en une seule commande. Elles s'avèrent utiles pour une évaluation initiale rapide, mais ne sauraient remplacer une exploration manuelle approfondie.
Les rapports automatisés peuvent parfois passer à côté de tendances spécifiques à un domaine ou signaler des résultats erronés. Ils sont plus efficaces en complément – et non en remplacement – d'un travail exploratoire délibéré guidé par des questions de recherche.
Questions fréquemment posées
Quelle est la différence entre l'analyse exploratoire des données (EDA) et l'analyse confirmatoire des données ?
L'analyse exploratoire des données (AED) génère des hypothèses en explorant les données sans idées préconçues, en se concentrant sur la découverte de tendances et la formulation de questions. L'analyse confirmatoire teste des hypothèses spécifiques à l'aide de statistiques inférentielles, afin de déterminer si les tendances observées reflètent vraisemblablement des phénomènes réels ou le fruit du hasard. L'AED précède l'analyse, en identifiant ce qui mérite d'être testé formellement, tandis que l'analyse confirmatoire intervient ensuite avec des tests statistiques rigoureux.
Combien de temps doit durer la phase EDA dans un projet de science des données ?
L'expérience du secteur suggère de consacrer entre 20 et 30 % du temps total du projet à l'analyse exploratoire des données (AED), bien que cette proportion varie selon la complexité et la familiarité avec les données. Pour les nouveaux jeux de données ou domaines, une exploration plus approfondie s'avère judicieuse. Avec des sources de données familières, une exploration plus rapide suffit. L'essentiel est de trouver un juste équilibre entre la rigueur de l'AED et les délais du projet : une AED insuffisante conduit à des erreurs de modélisation, tandis qu'une exploration excessive retarde la création de valeur.
L'automatisation complète de la CAO est-elle possible ?
Les outils d'analyse exploratoire automatisée (EDA) génèrent rapidement des rapports de synthèse utiles et des visualisations standardisées, mais l'automatisation complète demeure problématique. Une exploration efficace requiert une connaissance du domaine pour interpréter les tendances, un discernement quant aux résultats pertinents et de la créativité pour examiner les observations inattendues. L'automatisation gère efficacement les tâches routinières, permettant aux analystes de se concentrer sur l'interprétation et la formulation d'hypothèses qui nécessitent une expertise humaine.
Quelle est la technique EDA la plus importante à maîtriser en premier ?
Les principes fondamentaux de la visualisation offrent le meilleur retour sur investissement en matière d'apprentissage. Savoir créer et interpréter des histogrammes, des diagrammes en boîte et des nuages de points permet de découvrir les tendances les plus importantes. Ces visualisations de base révèlent des distributions, des valeurs aberrantes et des relations que les statistiques descriptives seules ne permettent pas de déceler. Maîtrisez les graphiques simples avant de passer à des techniques multivariées complexes ou à des méthodes statistiques spécialisées.
Comment gérez-vous les données manquantes lors de l'analyse exploratoire des données (EDA) ?
Premièrement, quantifiez les données manquantes : quel est le pourcentage de chaque variable et combien d’enregistrements complets restent ? Deuxièmement, recherchez les tendances : les données manquantes sont-elles corrélées à d’autres variables ou semblent-elles aléatoires ? Troisièmement, choisissez une stratégie : la suppression est appropriée lorsque les données manquantes sont véritablement aléatoires et que l’échantillon restant est suffisant ; l’imputation (moyenne, médiane ou basée sur un modèle) convient aux petits écarts aléatoires ; des techniques spécialisées comme l’imputation multiple traitent les tendances complexes. Documentez tous les choix et évaluez la sensibilité.
Faut-il supprimer les valeurs aberrantes lors de l'analyse exploratoire des données (EDA) ?
Pas automatiquement. Il convient d'abord de déterminer si les valeurs aberrantes représentent des erreurs (mesures incorrectes, erreurs de saisie) ou des valeurs extrêmes légitimes. Supprimez ou corrigez les erreurs, mais conservez les valeurs aberrantes légitimes, sauf si elles sont sans rapport avec les questions de recherche. Pour la modélisation, privilégiez les méthodes robustes qui atténuent l'influence des valeurs aberrantes plutôt que de supprimer des données. Lors de la suppression de valeurs aberrantes, documentez les observations exclues et les raisons de cette exclusion, afin de garantir la transparence et la reproductibilité.
En quoi l'analyse exploratoire des données (EDA) diffère-t-elle pour l'apprentissage automatique par rapport aux statistiques traditionnelles ?
L'analyse exploratoire des données (EDA) statistique traditionnelle met l'accent sur la vérification des hypothèses de tests spécifiques : normalité, homoscédasticité, indépendance. L'EDA en apprentissage automatique se concentre davantage sur les relations entre les caractéristiques, les modèles prédictifs et les problèmes de qualité des données qui affectent les performances du modèle. L'exploration en apprentissage automatique examine également les distributions des ensembles d'entraînement et de test pour garantir leur représentativité, tandis que les approches traditionnelles s'intéressent moins à la prédiction sur de nouvelles données. Les deux approches nécessitent la compréhension des distributions et des relations, mais les priorités diffèrent selon les objectifs analytiques.
Conclusion
L'analyse exploratoire des données constitue le fondement essentiel de tout travail sérieux sur les données. Négliger ou précipiter cette exploration conduit à des modélisations erronées, à des informations manquées et à un gaspillage de ressources à la recherche de tendances inexistantes ou à l'omission de tendances existantes.
Les techniques présentées ici, des vérifications de distribution de base aux méthodes multivariées avancées, constituent un ensemble d'outils complet pour la compréhension des jeux de données avant toute analyse formelle. Cependant, les outils seuls ne garantissent pas une exploration pertinente. Une analyse exploratoire efficace des données (AED) exige de la curiosité quant à ce que révèlent les données, un esprit critique face aux tendances apparentes et la volonté d'explorer les résultats inattendus, quelles qu'en soient les conclusions.
D'après les ressources pédagogiques de Penn State, l'analyse exploratoire des données (EDA) fournit des pistes initiales pour diverses techniques d'apprentissage en examinant des observations complexes afin d'y déceler des structures révélant des relations plus profondes. Cette génération d'hypothèses à partir des données transforme les chiffres bruts en informations exploitables qui orientent les décisions commerciales, les découvertes scientifiques et les innovations technologiques.
Pour démarrer votre prochain projet de données, consacrez suffisamment de temps à une exploration approfondie. Documentez vos découvertes. Visualisez les données avant de les modéliser. Remettez en question vos hypothèses. Les enseignements tirés d'une analyse exploratoire rigoureuse vous permettront de prendre de meilleures décisions tout au long du processus analytique et, au final, d'obtenir des résultats plus pertinents et fiables.
Prêt à appliquer ces techniques ? Commencez par un jeu de données qui vous tient à cœur, suivez les étapes structurées de manière systématique et découvrez ce que vos données ont toujours essayé de vous révéler.