Korte samenvatting: Exploratory Data Analysis (EDA) is het proces waarbij datasets worden onderzocht door middel van visualisatie en statistische methoden om patronen te ontdekken, afwijkingen op te sporen en aannames te testen voordat formele modellen worden ontwikkeld. Het omvat het onderzoeken van datadistributies, relaties tussen variabelen en het identificeren van uitschieters om de structuur en kwaliteit van de data te begrijpen. EDA is een cruciale eerste stap in elk data science-project en stelt teams in staat om weloverwogen beslissingen te nemen over welke analytische technieken ze moeten toepassen.
Data geeft niet meteen zijn geheimen prijs. Ruwe datasets verbergen vaak patronen, uitschieters en verbanden onder lagen van cijfers en tekst. Dat is waar Exploratory Data Analysis (EDA) van pas komt: een systematische aanpak om te begrijpen wat je data daadwerkelijk bevat voordat je begint met modelleren of voorspellingen doen.
Volgens Statistics Online van Penn State University kan EDA worden omschreven als datagestuurde hypothesegeneratie. In plaats van te beginnen met aannames, laten analisten zich leiden door de data via een zorgvuldige analyse van structuren die mogelijk wijzen op diepere verbanden tussen gevallen of variabelen.
Deze uitgebreide handleiding behandelt alles, van basisinspectie van datasets tot geavanceerde multivariate technieken. Of u nu te maken hebt met ongestructureerde data uit de praktijk of zich voorbereidt op machine learning-projecten, het beheersen van EDA-technieken zorgt ervoor dat analytisch werk op een solide basis begint.
Wat is verkennende data-analyse?
Exploratieve data-analyse is een benadering voor het analyseren van datasets waarbij begrip prioriteit krijgt boven directe modellering. Het doel is niet om meteen hypotheses te testen, maar om ze te genereren door te onderzoeken wat de data onthult via visualisatie en statistische samenvatting.
In de kern richt EDA zich op twee fundamentele aspecten: numerieke samenvatting en datavisualisatie. Deze complementaire technieken werken samen om patronen bloot te leggen die anders verborgen zouden blijven in spreadsheets of databases.
De EPA omschrijft EDA als een analysemethode die algemene patronen in gegevens identificeert, inclusief uitschieters en kenmerken die onverwacht kunnen zijn. Dit eerste onderzoek legt de basis voor al het daaropvolgende analytische werk.
Het doel van EDA
Waarom tijd besteden aan verkennen vóór analyseren? Omdat aannames over data vaak onjuist blijken. Een variabele waarvan wordt aangenomen dat deze normaal verdeeld is, kan een sterke scheefheid vertonen. Verwachte verbanden tussen kenmerken bestaan mogelijk niet, terwijl er onverwachte correlaties ontstaan.
Exploratieve data-analyse (EDA) voorkomt verspilling van tijd en moeite aan ongeschikte analysemethoden. De ontdekking dat een dataset significante ontbrekende waarden of extreme uitschieters bevat, beïnvloedt welke methoden valide resultaten opleveren. Het vinden van collineariteit tussen voorspellende variabelen heeft invloed op de regressiemodellering.
Deze verkennende fase draagt ook bij aan het ontwikkelen van intuïtie over het domein van de dataset. Inzicht in typische waardebereiken, seizoenspatronen of categorieverdelingen helpt latere bevindingen in context te plaatsen en modelleringsfouten op te sporen die tot onwaarschijnlijke resultaten leiden.
Kerncomponenten van EDA
Volgens academische bronnen van Penn State combineert effectieve EDA verschillende belangrijke elementen die samenwerken om een alomvattend begrip van de gegevens te creëren.
Gegevensverzameling en kwaliteitsbeoordeling
Voordat de analyse begint, is het enorm belangrijk om te begrijpen waar de data vandaan komt. Volgens de beginnershandleiding van Georgia Tech controleert de eerste fase van de verkennende data-analyse (EDA) de structuur van de dataset: het aantal rijen en kolommen, de bronbestanden en de tijdsperioden die worden bestreken.
In dit stadium zijn er bijvoorbeeld alarmsignalen zoals vreemd kleine of juist enorme datasets, gemengde bronnen zonder de juiste labels, of een onduidelijke tijdsperiode. Door datamomentopnamen vast te leggen met tellingen, bronpaden en verzameldata, wordt de reproduceerbaarheid vanaf het begin gewaarborgd.
De schemacontrole volgt, waarbij gegevenstypen, parseerproblemen en categorieniveaus worden onderzocht. Het aantreffen van ID's die zijn opgeslagen als drijvende-kommagetallen of datums die als tekenreeksen worden weergegeven, wijst op problemen die moeten worden gecorrigeerd voordat een zinvolle analyse kan worden uitgevoerd.
Patronen van ontbrekende gegevens
Ontbrekende gegevens komen zelden willekeurig voor. Door de percentages ontbrekende gegevens per kolom en per rij te onderzoeken, kan worden vastgesteld of er patronen zijn die verband houden met specifieke subgroepen of omstandigheden.
Patronen waarbij gegevens niet willekeurig ontbreken, of 'alles-of-niets'-blokken waarin complete records geen informatie bevatten, wijzen op systematische problemen met de gegevensverzameling in plaats van willekeurige hiaten. Inzicht in deze patronen is van invloed op imputatiestrategieën en bepaalt of bepaalde variabelen bruikbaar blijven.
Soorten verkennende data-analyse
EDA-technieken worden onderverdeeld in categorieën op basis van het aantal variabelen dat gelijktijdig wordt onderzocht en of grafische of kwantitatieve methoden de overhand hebben.
Univariate analyse
Univariate analyse onderzoekt één variabele tegelijk, waarbij een basisinzicht in individuele kenmerken wordt verkregen alvorens relaties te onderzoeken.
Voor numerieke variabelen houdt dit in dat maten voor centrale tendentie (gemiddelde, mediaan, modus) en spreiding (standaarddeviatie, variantie, bereik) worden berekend. Histogrammen laten de vorm van de verdeling zien – of de gegevens een normale, scheve, bimodale of uniforme verdeling volgen.
Volgens het overzicht van de EPA vatten histogrammen verdelingen samen door waarnemingen in intervallen te plaatsen en het aantal voorkomende waarden in elk interval te tellen. De y-as kan het aantal waarnemingen, het percentage van het totaal, de fractie van het totaal (waarschijnlijkheid) of de dichtheid weergeven.
Categorische variabelen vereisen frequentietabellen en staafdiagrammen die laten zien hoe de waarnemingen over de categorieën verdeeld zijn. Het identificeren van dominante categorieën versus zeldzame categorieën is van belang voor latere modelleringsbeslissingen over groepering of speciale behandeling.
Bivariate analyse
Bivariate technieken onderzoeken de relatie tussen twee variabelen. Spreidingsdiagrammen visualiseren de verbanden tussen continue variabelen en onthullen lineaire relaties, krommen, clusters of geen duidelijk patroon.
Correlatieanalyse kwantificeert de sterkte van lineaire verbanden. Maar correlatie is geen causaliteit, en door alleen te focussen op correlatiecoëfficiënten worden niet-lineaire verbanden die in grafieken zichtbaar zijn, over het hoofd gezien.
Kruistabellen onderzoeken de verbanden tussen categorische variabelen, terwijl boxplots, gegroepeerd per categorie, de verdelingen tussen subgroepen vergelijken – bijvoorbeeld door de inkomensverdelingen afzonderlijk voor verschillende opleidingsniveaus te bekijken.
Multivariate analyse
Problemen uit de praktijk omvatten meerdere variabelen die tegelijkertijd op elkaar inwerken. Multivariate EDA-technieken verwerken drie of meer variabelen en brengen complexe patronen aan het licht die onzichtbaar zijn bij paarsgewijze vergelijkingen.
Spreidingsdiagrammen tonen alle paarsgewijze relaties in een raster, wat een uitgebreid overzicht geeft van correlatiestructuren. Door punten te kleuren op basis van een categorische variabele wordt een derde dimensie toegevoegd aan standaard spreidingsdiagrammen.
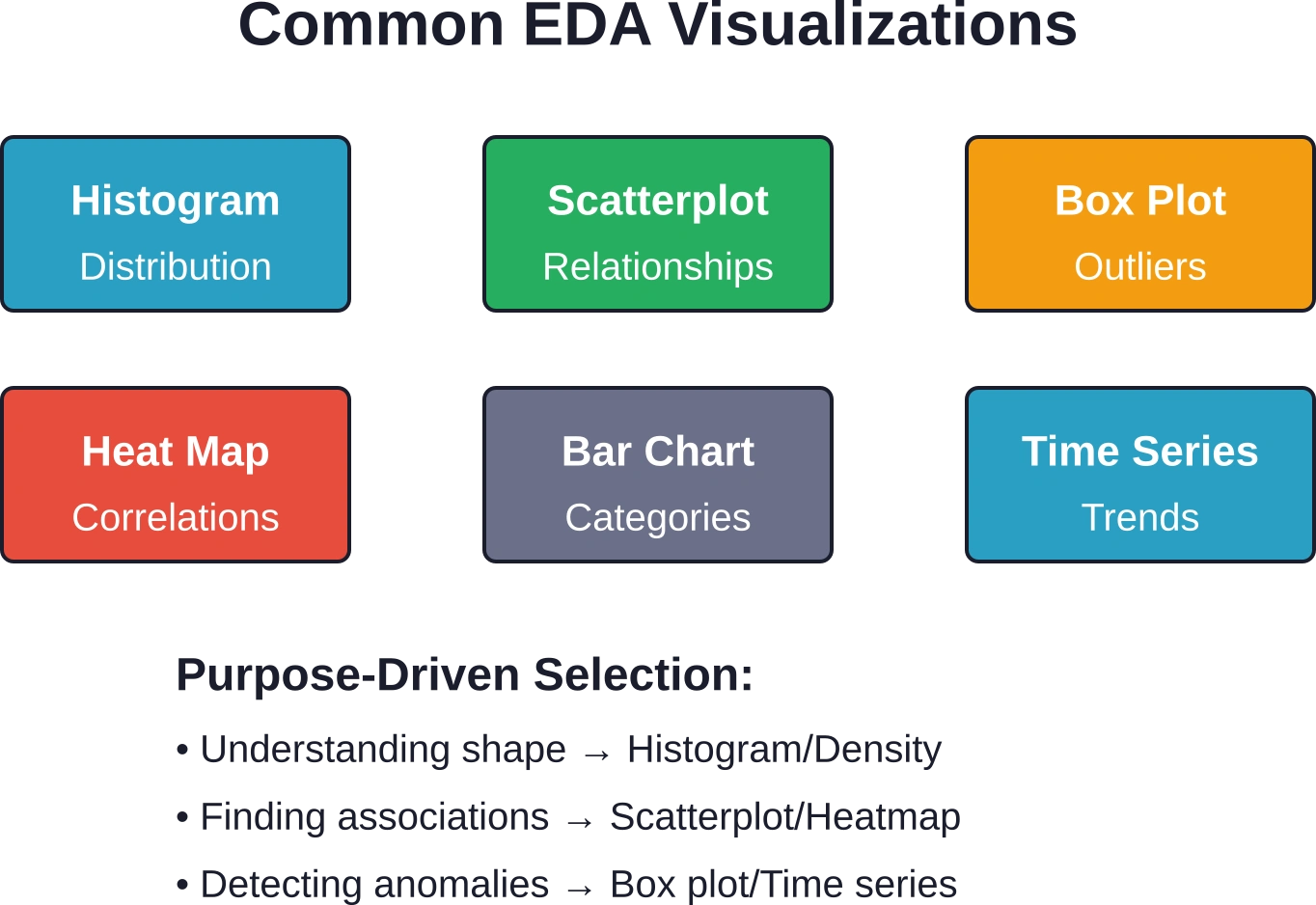
Hittekaarten visualiseren correlatiematrices, waardoor het gemakkelijk is om clusters van gerelateerde variabelen te herkennen. Hoofdcomponentenanalyse (hoewel geavanceerder) reduceert de dimensionaliteit met behoud van variantie, waardoor kan worden vastgesteld welke combinaties van variabelen de meeste variatie veroorzaken.
Essentiële EDA-technieken en -tools
Effectief verkennend onderzoek vereist de juiste combinatie van statistische methoden en visualisatietechnieken.
Statistische samenvattingstechnieken
Beschrijvende statistieken vormen de kwantitatieve basis van EDA. Naast basisgemiddelden en medianen, onthult het onderzoeken van kwartielen hoe de data zich over het bereik verspreidt. De vijfpunts samenvatting (minimum, eerste kwartiel, mediaan, derde kwartiel, maximum) geeft een compleet beeld van de vorm van de verdeling.
Volgens voorbeelden van Penn State kan een dataset met 10 objecten en 4 attributen (ID, geslacht, opleiding, inkomen) inkomens laten zien die variëren van minimaal $0 tot maximaal $100.000. Deze grenzen bepalen de schaal van de variabele en helpen vaststellen of waarden binnen de verwachte bereiken vallen.
Scheefheid en kurtosis kwantificeren de asymmetrie van de verdeling en de zwaarte van de staart. Een positieve scheefheid duidt op een lange rechterstaart, terwijl een negatieve kurtosis wijst op lichtere staarten dan bij een normale verdeling.
Visualisatiemethoden
Grafieken onthullen patronen die statistische samenvattingen alleen mogelijk niet zouden weergeven. Verschillende grafiektypen dienen verschillende doelen in het verkenningsproces.
Histogrammen en dichtheidsgrafieken tonen de vorm van de verdeling. Boxplots geven op efficiënte wijze medianen, kwartielen en uitschieters weer en maken eenvoudige vergelijkingen tussen groepen mogelijk. Vioolplots combineren de informatie van boxplots met kernel-dichtheidsschatting.
Spreidingsdiagrammen blijven essentieel voor het onderzoeken van relaties tussen continue variabelen. Het toevoegen van trendlijnen helpt bij het beoordelen of lineaire modellen de gegevens goed zouden kunnen beschrijven.
Staafdiagrammen vergelijken categorieën, terwijl tijdreeksgrafieken temporele patronen onthullen: trends, seizoensinvloeden en afwijkende perioden.
Software- en programmeeromgevingen
Volgens het cursusmateriaal van Penn State biedt de R-software verschillende aantrekkelijke functies voor EDA-werk. Python, met bibliotheken zoals Pandas, Matplotlib en Seaborn, biedt even krachtige mogelijkheden.
Beide omgevingen ondersteunen reproduceerbare analyses door middel van scripting, waardoor analisten elke transformatie- en visualisatiestap kunnen documenteren. Deze reproduceerbaarheid is essentieel wanneer datasets worden bijgewerkt of collega's bevindingen moeten verifiëren.
Jupyter notebooks en R Markdown combineren code, visualisaties en beschrijvende uitleg tot samenhangende documenten die onderzoeksresultaten communiceren aan belanghebbenden die geen ruwe code lezen.
Stapsgewijs EDA-proces
Hoewel verkennend onderzoek creativiteit vereist, zorgt een gestructureerde aanpak voor een volledig overzicht zonder cruciale kwesties over het hoofd te zien.
Fase 1: Initiële gegevensinspectie
Begin met het laden van de dataset en bekijk de basiseigenschappen ervan. Hoeveel rijen en kolommen? Welke gegevenstypen komen in elke kolom voor? Zijn er duidelijke parseerfouten of coderingsproblemen?
Print de eerste en laatste paar rijen om te controleren of de gegevens correct zijn geladen. Controleer op dubbele records die de analyseresultaten kunnen vertekenen. Controleer of de identificatiekolommen daadwerkelijk unieke waarden bevatten.
Deze eerste inspectie spoort technische problemen op – beschadigde bestanden, onjuiste scheidingstekens, inconsistenties in de codering – voordat er tijd wordt geïnvesteerd in een diepere analyse.
Fase 2: Gegevens opschonen en voorbereiden
Volgens de richtlijnen voor informatiewetenschappen van Cornell moet de documentatie voor gegevensverzameling en -opschoning elke transformatiestap vastleggen. Dit kan onder meer het omgaan met ontbrekende waarden, het corrigeren van gegevenstypen, het standaardiseren van categorielabels of het verwijderen van ongeldige records omvatten.
Strategieën voor het omgaan met ontbrekende waarden zijn afhankelijk van het patroon van de ontbrekende waarden. Volledig willekeurige ontbrekende waarden kunnen volstaan met eenvoudige verwijdering van gegevens of imputatie met het gemiddelde. Systematische patronen vereisen meer geavanceerde benaderingen of het accepteren van kleinere steekproefgroottes.
Uitschieters vereisen een zorgvuldige beoordeling. Sommige vertegenwoordigen legitieme extreme waarden die belangrijke informatie bevatten. Andere weerspiegelen meetfouten of invoerfouten die het waard zijn om te verwijderen of te corrigeren.
Fase 3: Univariate exploratie
Onderzoek elke variabele afzonderlijk. Bereken voor numerieke kenmerken samenvattende statistieken en maak verdelingsgrafieken. Let op de centrale tendens, spreiding en vormkenmerken.
Genereer frequentietabellen voor categorische variabelen. Bepaal of de categorieën ongeveer in evenwicht zijn of dat er sprake is van een ernstige onbalans – een situatie die veel machine learning-algoritmen beïnvloedt.
Documenteer onverwachte bevindingen. Een ogenschijnlijk continue variabele die slechts enkele discrete waarden bevat, of een categorische variabele met honderden unieke niveaus, duidt op mogelijke problemen met de datakwaliteit of uitdagingen bij het modelleren.
Fase 4: Bivariate en multivariate exploratie
Onderzoek de verbanden tussen variabelen, met name tussen potentiële voorspellende variabelen en doelvariabelen. Correlatiematrices bieden een snel overzicht van lineaire verbanden tussen numerieke kenmerken.
Maak spreidingsdiagrammen voor veelbelovende paren variabelen. Voeg gladmakende lijnen toe om te beoordelen of de verbanden lineair lijken of een transformatie vereisen.
Bij classificatieproblemen is het belangrijk te onderzoeken hoe de verdeling van de voorspellende variabelen verschilt tussen de doelklassen. Een sterke scheiding duidt op bruikbare voorspellende kenmerken, terwijl volledige overlapping wijst op zwakke voorspellende variabelen.
Fase 5: Hypothesegeneratie
Formuleer op basis van de waargenomen patronen hypothesen over de oorzaken van de variatie in de data. Deze hypothesen dienen als leidraad voor latere modelleringsinspanningen.
Wellicht vertonen bepaalde klantsegmenten dramatisch verschillend koopgedrag. Misschien domineren seizoenspatronen de tijdelijke variatie. De EDA-fase brengt deze inzichten aan het licht, die vervolgens door middel van formele modellering worden getest en gekwantificeerd.
| EDA-fase | Belangrijkste activiteiten | Gemeenschappelijke uitgangen | Typische duur |
|---|---|---|---|
| Eerste inspectie | Gegevens laden, structuur controleren, laden verifiëren | Gegevensmomentopname, aantal dimensies | 10-15% EDA-tijd |
| Schoonmaak | Ontbrekende waarden verwerken, gegevenstypen corrigeren, duplicaten verwijderen | Opgeschoonde dataset, transformatielogboek | 25-35% EDA-tijd |
| Univariaat | Analyse van individuele variabelen, verdelingen | Samenvattende statistieken, histogrammen | 20-25% EDA-tijd |
| Multivariaat | Relaties, correlaties, patronen | Spreidingsdiagrammen, correlatiematrices | 25-30% EDA-tijd |
| Documentatie | Bevindingen vastleggen, hypothesen formuleren | EDA-rapport, visualisatiedashboard | 10-15% EDA-tijd |

Maak verkennende data-analyse nuttig met superieure AI.
Een verkennende data-analyse is vaak de eerste stap voordat een bedrijf kan beslissen welk type AI- of analyseproject zinvol is. AI Superieur AI Superior kan deze fase ondersteunen met AI-consultancy, AI- en datastrategie, business intelligence, data-analyse, machine learning en voorspellende analyses. Hun werk kan bedrijven helpen beschikbare data te beoordelen, patronen te begrijpen, hiaten te vinden en te bepalen of de data klaar is voor diepgaandere modellering of AI-softwareontwikkeling. Dit is nuttig voor teams die bedrijfsdata hebben verzameld, maar niet zeker weten wat deze data daadwerkelijk kunnen aantonen. In plaats van direct te beginnen met modelbouw, kan AI Superior helpen data-exploratie te koppelen aan praktische toepassingen, duidelijkere rapportages en toekomstige AI-ontwikkeling.
Voor verkennend dataonderzoek kan AI Superior u helpen met:
- Het beoordelen van beschikbare bedrijfsgegevens
- Patronen, hiaten en bruikbare signalen vinden
- Gegevens voorbereiden voor analyses of machine learning.
- Het ontwikkelen van tools voor business intelligence en analyses.
- Het definiëren van praktische AI-toepassingen op basis van dataresultaten.
👉Neem contact op met AI Superior Om te bespreken hoe verkennende data-analyse uw volgende analyse-, BI- of AI-project kan ondersteunen.
Patronen en afwijkingen herkennen
Een van de belangrijkste doelstellingen van EDA is het opsporen van patronen die wijzen op verbanden die het onderzoeken waard zijn, en afwijkingen die kunnen duiden op problemen of interessante uitzonderlijke gevallen.
Patroonherkenning
Patronen manifesteren zich in verschillende vormen. Tijdelijke patronen omvatten trends (langetermijnstijgingen of -dalingen), seizoenspatronen (regelmatige periodieke schommelingen) en cycli (onregelmatige, herhaalde patronen).
Clusterpatronen ontstaan wanneer waarnemingen zich op natuurlijke wijze groeperen in afzonderlijke segmenten. Klanten kunnen zich groeperen op basis van hun koopgedrag, patiënten op basis van combinaties van symptomen, of geografische regio's op basis van omgevingskenmerken.
Associatiepatronen laten zien dat bepaalde kenmerken vaak samen voorkomen. Bij marktmandanalyse vertonen producten die vaak samen worden gekocht sterke associaties, zelfs zonder causale verbanden.
Uitschieterdetectie
Uitschieters verdienen speciale aandacht tijdens het onderzoek. Ze kunnen duiden op problemen met de datakwaliteit die gecorrigeerd moeten worden, of op echte extreme gevallen die waardevolle informatie bevatten over zeldzame maar belangrijke scenario's.
Statistische methoden zoals de interkwartielafstandregel (IQR-regel) identificeren uitschieters als punten die meer dan 1,5 keer de IQR buiten de kwartielen vallen. Z-scores signaleren waarnemingen die vele standaarddeviaties van het gemiddelde verwijderd zijn, hoewel dit uitgaat van ruwweg normale verdelingen.
Visuele inspectie aan de hand van boxplots of spreidingsdiagrammen blijkt vaak informatiever dan puur statistische regels. De context bepaalt of uitschieters verwijderd, getransformeerd of afzonderlijk geanalyseerd moeten worden.
Correlatie versus causaliteit
Exploratieve data-analyse (EDA) onthult vaak correlaties – variabelen die samen bewegen. Maar correlatie impliceert geen causaliteit. Twee variabelen kunnen correleren omdat de ene de andere veroorzaakt, omdat beide reageren op een gemeenschappelijke oorzaak, of puur door toeval.
De verkoop van ijs correleert met het aantal verdrinkingsdoden, niet omdat ijs verdrinking veroorzaakt, maar omdat beide toenemen in de zomer. Het onderscheiden van correlatie en causaliteit vereist domeinkennis en vaak experimentele of quasi-experimentele onderzoeksopzetten die buiten het bereik van EDA vallen.
Desondanks leidt het identificeren van sterke correlaties tijdens het verkennende onderzoek de aandacht naar relaties die het waard zijn om te onderzoeken met behulp van methoden voor causale inferentie.
Praktische voorbeelden van EDA
Concrete voorbeelden illustreren hoe EDA-technieken kunnen worden toegepast op daadwerkelijke datasets en problemen.
Voorbeeld van regressieanalyse
Volgens het cursusmateriaal van STAT 508 van Penn State, bekijk een regressiemodel dat onderzoekt hoe salaris samenhangt met het aantal jaren ervaring. Het aangepaste model behaalde een R-kwadraatwaarde van 93,7%, met een aangepast R-kwadraat van 91,6% en een voorspeld R-kwadraat van 85,94%.
De regressievergelijking toonde een constante coëfficiënt van 24,8 en een hellingscoëfficiënt van 15,2 voor het aantal jaren ervaring, met een F-waarde van 44,78 en een p-waarde van 0,007. Deze resultaten suggereren dat het aantal jaren ervaring een sterke voorspellende factor is voor het salaris in deze dataset en het grootste deel van de salarisvariatie verklaart.
Tijdens een verkennende data-analyse (EDA) voor een dergelijk probleem zouden spreidingsdiagrammen eerst uitwijzen of een lineair verband aannemelijk lijkt. Residuplots zouden vervolgens patronen opsporen die wijzen op schendingen van de aannames, zoals niet-lineariteit, heteroscedasticiteit of invloedrijke uitschieters.
ANOVA-voorbeeld
Het lesmateriaal van Penn State bevat voorbeelden van eenweg-ANOVA-analyses die verschillen tussen groepen onderzoeken, en laat zien hoe F-waarden en p-waarden geïnterpreteerd moeten worden om te bepalen of categorische variabelen de uitkomsten significant voorspellen.
De hoge p-waarde (0,184) suggereert dat er onvoldoende bewijs is voor genderverschillen in deze dataset. Een verkennende data-analyse (EDA) voorafgaand aan deze analyse zou boxplots moeten omvatten om de verdelingen over de gendercategorieën te vergelijken en aannames zoals homogeniteit van variantie te controleren.

Veelvoorkomende fouten bij EDA die je moet vermijden
Zelfs ervaren analisten trappen soms in valkuilen tijdens verkennend onderzoek, wat leidt tot onjuiste conclusies of verspilde moeite.
Gegevensvalidatie overslaan
Direct overgaan tot visualisatie zonder de datakwaliteit te controleren, is verleidelijk maar gevaarlijk. Onjuiste invoer leidt tot onjuiste uitvoer: prachtige grafieken van corrupte data leveren misleidende inzichten op.
Controleer altijd of de gegevens correct zijn geladen, of de gegevenstypen kloppen en of de waardebereiken binnen plausibele grenzen vallen. Een persoon die als 250 jaar oud wordt vermeld of een temperatuur van 500 graden Celsius duidt op problemen die nader onderzoek vereisen.
Te veel vertrouwen op geautomatiseerde samenvattende statistieken
Samenvattende statistieken bieden waardevolle informatie, maar missen belangrijke patronen. Anscombe's kwartet is een bekend voorbeeld van vier datasets met identieke gemiddelden, varianties en correlaties die er compleet anders uitzien wanneer ze in een grafiek worden weergegeven.
Visualiseer data altijd in plaats van alleen op samenvattende cijfers te vertrouwen. Grafieken onthullen scheefheid, multimodaliteit, uitschieters en niet-lineaire verbanden die statistische methoden over het hoofd zien.
Domeinkennis negeren
Statistische patronen die losstaan van domeinkennis kunnen vaak misleidend zijn. Een ogenschijnlijke anomalie kan normaal gedrag in die specifieke context vertegenwoordigen, terwijl patronen die typisch lijken in werkelijkheid op ernstige problemen kunnen wijzen.
Het raadplegen van vakdeskundigen tijdens de verkennende data-analyse (EDA) helpt bij het correct interpreteren van de bevindingen en richt de aandacht op werkelijk belangrijke patronen in plaats van statistische artefacten.
Bevestigingsbias
Het zoeken naar patronen die bestaande overtuigingen bevestigen en tegelijkertijd tegenstrijdig bewijs negeren, ondermijnt verkennend onderzoek. Het doel van EDA is ontdekken wat de data daadwerkelijk laten zien, niet het valideren van aannames.
Systematisch onderzoek volgens gestructureerde stappen helpt de confirmation bias tegen te gaan. Documenteer onverwachte bevindingen, zelfs als ze in tegenspraak zijn met de verwachtingen – ze kunnen immers zeer waardevol blijken.
Geavanceerde EDA-overwegingen
Naast fundamentele technieken verdienen diverse geavanceerde onderwerpen aandacht bij complexe analytische projecten.
Het verwerken van hoogdimensionale gegevens
Datasets met honderden of duizenden kenmerken vormen een uitdaging voor traditionele EDA-benaderingen. Het maken van scatterplots voor elk variabelenpaar wordt onpraktisch en correlatiematrices worden te groot om visueel te interpreteren.
Technieken voor dimensionaliteitsreductie, zoals principale componentenanalyse, helpen door lineaire combinaties van kenmerken te identificeren die de meeste variatie vastleggen. Dit maakt visualisatie en exploratie in lagere-dimensionale ruimtes mogelijk, terwijl de meeste informatie behouden blijft.
Scores voor de belangrijkheid van kenmerken uit op bomen gebaseerde modellen bieden een andere benadering, waarbij variabelen worden gerangschikt op basis van hun voorspellende kracht, waardoor analisten zich kunnen concentreren op de meest relevante subset.
Speciale aandachtspunten voor tijdreeksen
Temporele data vereisen gespecialiseerde EDA-technieken. Autocorrelatieplots laten zien of waarnemingen correleren met hun eigen waarden uit het verleden – een belangrijke overweging voor voorspellingsmodellen.
Door middel van decompositie worden tijdreeksen opgesplitst in trend-, seizoens- en restcomponenten, waardoor duidelijk wordt welke patronen dominant zijn en geschikte modelleringsmethoden worden voorgesteld.
Het detecteren van veranderingspunten identificeert momenten waarop de onderliggende processen voor gegevensgeneratie verschuiven. Dit is cruciaal om te begrijpen of historische patronen relevant blijven voor toekomstige voorspellingen.
Ruimtelijke dataverkenning
Geografische datasets profiteren van het gebruik van kaarten als een techniek voor verkennende data-analyse (EDA). Choropleth-kaarten onthullen ruimtelijke patronen – clusters, gradiënten of geïsoleerde hotspots – die tabellen en standaardgrafieken volledig over het hoofd zien.
Ruimtelijke autocorrelatiemetingen kwantificeren of nabijgelegen locaties vergelijkbare waarden vertonen, en testen of geografische nabijheid van belang is voor het bestudeerde fenomeen.
Communicatie van EDA-bevindingen
Onderzoek levert inzichten op, maar die inzichten creëren pas waarde als ze effectief worden gecommuniceerd naar belanghebbenden en teamleden.
EDA-rapporten maken
Uitgebreide EDA-rapporten documenteren het verkenningsproces en de bevindingen ervan. Deze rapporten moeten beschrijvingen van de gegevensbronnen, de uitgevoerde transformatiestappen, visualisaties van belangrijke patronen en een samenvatting van de gegenereerde inzichten en hypothesen bevatten.
Volgens de richtlijnen van Cornell moeten rapporten de doelstellingen vanaf het begin duidelijk vermelden, de gegevensverzameling en -verwerking grondig documenteren, relevante samenvattende statistieken berekenen en grafieken tonen die relevant zijn voor de gestelde doelstellingen.
Reproduceerbaarheid is van enorm belang. Anderen moeten de gedocumenteerde stappen kunnen volgen en tot dezelfde conclusies komen, waarmee wordt geverifieerd dat de bevindingen niet het gevolg zijn van fouten of niet-gedocumenteerde beoordelingen.
Beste praktijken voor visualisatie
Effectieve EDA-visualisaties geven prioriteit aan duidelijkheid boven vormgeving. Elk grafiekelement moet een doel dienen: informatie overbrengen in plaats van er alleen maar indrukwekkend uit te zien.
Label de assen duidelijk met de bijbehorende eenheden. Voeg informatieve titels toe die beschrijven wat de grafiek weergeeft. Kies geschikte schalen die de relaties niet vertekenen en belangrijke variaties niet verbergen.
Voor presentaties aan een niet-technisch publiek werken eenvoudigere visualisaties vaak beter dan complexe, multidimensionale grafieken. Een duidelijke staafgrafiek communiceert effectiever dan een geavanceerde visualisatie die uitgebreide uitleg vereist.
EDA in de bredere data science-workflow
Verkennend onderzoek staat niet op zichzelf; het is verbonden met voorafgaande gegevensverzameling en daaropvolgende modelleringsfasen.
Exploratieve data-analyse (EDA) en gegevensverzameling
Inzichten uit verkennend onderzoek leiden vaak tot verbeteringen in de gegevensverzameling. Ontbrekende informatie die cruciaal is voor het beantwoorden van belangrijke vragen, kan aanleiding geven tot het verzamelen van aanvullende gegevens. Ontdekte kwaliteitsproblemen kunnen wijzen op noodzakelijke aanpassingen in de dataverwerkingsprocessen.
Deze feedbacklus tussen exploratie en verzameling verbetert de data in de loop van de tijd op iteratieve wijze, waardoor toekomstig analytisch werk productiever wordt.
EDA en Feature Engineering
De patronen die tijdens het verkennende proces worden ontdekt, vormen de basis voor feature engineering: het creëren van nieuwe variabelen uit bestaande variabelen om de relaties van belang beter in kaart te brengen.
Het waarnemen van niet-lineaire verbanden kan wijzen op polynomiale of interactietermen. De constatering dat de impact van een variabele verschilt tussen subgroepen kan aanleiding geven tot het creëren van afzonderlijke kenmerken voor elke subgroep.
EDA en modelselectie
Verkennende bevindingen sturen de modelkeuze. Lineaire verbanden tussen voorspellende variabelen en doelvariabelen suggereren dat lineaire regressie goed zou kunnen werken. Niet-lineaire patronen duiden op de noodzaak van polynomiale termen, splines of niet-parametrische methoden.
Het ontdekken van interacties tussen kenmerken tijdens EDA wijst erop dat modellen die interacties kunnen vastleggen – zoals op bomen gebaseerde methoden – mogelijk beter presteren dan additieve modellen.
Geïdentificeerde uitschieters geven inzicht in de keuze tussen robuuste modelleringstechnieken en het verwijderen van extreme waarden. Inzicht in patronen van ontbrekende gegevens is bepalend voor de imputatiestrategie.
| Gegevenskenmerk | EDA-indicator | Voorgestelde modelleringsaanpak |
|---|---|---|
| Lineaire verbanden | Spreidingsdiagrammen met rechte lijnen | Lineaire regressie, GLM's |
| Niet-lineaire patronen | Gebogen relaties in grafieken | Polynoomtermen, splines, boommodellen |
| Sterke uitschieters | Extreme boxplot snorharen | Robuuste regressie, verwijdering van uitschieters |
| Hoge collineariteit | Correlatiematrix >0,9 | Ridge-regressie, PCA, featureselectie |
| Complexe interacties | Relaties veranderen per subgroep | Boommodellen, interactietermen |
| Categorisch dominant | Voornamelijk categorische variabelen | Logistische regressie, Naïeve Bayes |
Hulpmiddelen en technologieën voor EDA
Het selecteren van de juiste instrumenten versnelt het verkennend onderzoek en maakt een meer geavanceerde analyse mogelijk.
Programmeertalen
Python en R domineren het werk op het gebied van verkennende data-analyse (EDA) in de datawetenschap. De Pandas-bibliotheek van Python biedt krachtige mogelijkheden voor datamanipulatie, terwijl Matplotlib, Seaborn en Plotly de visualisatiebehoeften vervullen.
R blinkt uit in statistische berekeningen met ingebouwde functies voor de meest voorkomende EDA-taken. Het ggplot2-pakket creëert grafieken van publicatiekwaliteit volgens een principiële grammatica van grafieken.
Beide talen ondersteunen notebookomgevingen (Jupyter voor Python, R Markdown voor R) die code, uitvoer en verklarende tekst combineren tot samenhangende documenten.
Gespecialiseerde EDA-software
Tableau en Power BI bieden gebruiksvriendelijke interfaces voor datavisualisatie, waardoor geavanceerde grafieken toegankelijk worden voor minder technisch onderlegde gebruikers. Deze tools blinken uit in interactieve dashboards waarmee belanghebbenden data kunnen verkennen zonder code te hoeven schrijven.
Maar ze offeren reproduceerbaarheid en aanpassingsmogelijkheden op in vergelijking met programmeergebaseerde benaderingen. Wijzigingen in grafieken vereisen handmatige klikken in plaats van het opnieuw uitvoeren van gedocumenteerde scripts.
Open Source Bibliotheken
Bibliotheken zoals pandas-profiling en sweetviz automatiseren veel taken voor verkennende data-analyse (EDA) en genereren uitgebreide rapporten met één commando. Deze zijn nuttig voor een snelle eerste beoordeling, maar mogen een zorgvuldige handmatige analyse niet vervangen.
Geautomatiseerde rapporten missen soms domeinspecifieke patronen of signaleren onjuiste bevindingen. Ze werken het best als aanvulling op – en niet als vervanging van – doelgericht, verkennend onderzoek dat wordt geleid door onderzoeksvragen.
Veelgestelde vragen
Wat is het verschil tussen EDA en confirmatieve data-analyse?
Exploratieve data-analyse (EDA) genereert hypothesen door data te onderzoeken zonder vooropgezette ideeën, met de focus op het ontdekken van patronen en het formuleren van vragen. Bevestigende analyse toetst specifieke hypothesen met behulp van inferentiële statistiek, waarbij wordt bepaald of waargenomen patronen waarschijnlijk echte verschijnselen of toeval weerspiegelen. EDA komt eerst, waarbij wordt vastgesteld wat de moeite waard is om formeel te testen, terwijl bevestigende analyse volgt met rigoureuze statistische toetsen.
Hoe lang duurt de EDA-fase in een data science-project?
Ervaring in de sector wijst uit dat 20 tot 301 TP3T van de totale projecttijd aan EDA moet worden besteed, hoewel dit varieert afhankelijk van de complexiteit en bekendheid met de data. Voor nieuwe datasets of domeinen is een uitgebreidere verkenning de moeite waard. Bij bekende databronnen volstaat een snellere verkenning. De sleutel is het vinden van een balans tussen grondigheid en projecttijdlijn: onvoldoende EDA leidt tot modelleerfouten, terwijl overmatige verkenning de waardecreatie vertraagt.
Kan EDA volledig geautomatiseerd worden?
Geautomatiseerde EDA-tools genereren snel nuttige samenvattende rapporten en standaardvisualisaties, maar volledige automatisering blijft problematisch. Effectief onderzoek vereist domeinkennis om patronen te interpreteren, inzicht in welke bevindingen relevant zijn en creativiteit bij het onderzoeken van onverwachte waarnemingen. Automatisering neemt routinetaken goed voor zijn rekening, waardoor analisten zich kunnen concentreren op interpretatie en het formuleren van hypothesen, taken die menselijk inzicht vereisen.
Wat is de belangrijkste EDA-techniek om als eerste onder de knie te krijgen?
De basisprincipes van visualisatie leveren het meeste rendement op bij het leren. Inzicht in het maken en interpreteren van histogrammen, boxplots en scatterplots maakt het mogelijk om de belangrijkste patronen te ontdekken. Deze basisvisualisaties onthullen verdelingen, uitschieters en verbanden die met samenvattende statistieken alleen niet zichtbaar zijn. Beheers eenvoudige grafieken voordat u zich verdiept in complexe multivariate technieken of gespecialiseerde statistische methoden.
Hoe ga je om met ontbrekende gegevens tijdens een verkennende data-analyse (EDA)?
Ten eerste, kwantificeer de ontbrekende gegevens: welk percentage van elke variabele en hoeveel complete records zijn er nog over? Ten tweede, onderzoek patronen: correleert het ontbreken van gegevens met andere variabelen of lijkt het willekeurig? Ten derde, bepaal een strategie: verwijdering werkt wanneer het ontbreken van gegevens echt willekeurig is en de resterende steekproef voldoende groot is; imputatie (gemiddelde, mediaan of modelgebaseerd) is geschikt voor kleine willekeurige hiaten; gespecialiseerde technieken zoals meervoudige imputatie zijn geschikt voor complexe patronen. Documenteer alle keuzes en beoordeel de gevoeligheid.
Moeten uitschieters tijdens de EDA worden verwijderd?
Niet automatisch. Bepaal eerst of uitschieters fouten (onjuiste metingen, invoerfouten) of legitieme extreme waarden vertegenwoordigen. Verwijder of corrigeer fouten, maar behoud echte uitschieters, tenzij ze irrelevant zijn voor de onderzoeksvragen. Overweeg bij het modelleren robuuste methoden die uitschieters minder gewicht toekennen in plaats van informatie te verwijderen. Documenteer bij het verwijderen van uitschieters welke waarnemingen zijn uitgesloten en waarom, om transparantie en reproduceerbaarheid te waarborgen.
Hoe verschilt EDA voor machine learning van traditionele statistiek?
Traditionele statistische EDA legt de nadruk op het controleren van aannames voor specifieke tests, zoals normaliteit, homoscedasticiteit en onafhankelijkheid. Machine learning EDA richt zich meer op de relaties tussen kenmerken, voorspellende patronen en de kwaliteit van de data die de modelprestaties beïnvloedt. ML-exploratie onderzoekt ook de verdeling van de trainings- en testsets om representativiteit te garanderen, terwijl traditionele benaderingen zich minder richten op voorspellingen op nieuwe data. Beide vereisen inzicht in verdelingen en relaties, maar de prioriteiten verschillen afhankelijk van de analytische doelen.
Conclusie
Exploratieve data-analyse vormt de essentiële basis voor al het serieuze dataonderzoek. Het overslaan of afraffelen van deze fase leidt tot misleidende modelleringspogingen, gemiste inzichten en verspilde middelen aan het najagen van patronen die niet bestaan of het missen van patronen die er wel zijn.
De hier besproken technieken – van eenvoudige distributiecontroles tot geavanceerde multivariate methoden – bieden een uitgebreide toolkit voor het begrijpen van datasets voordat de formele analyse begint. Maar tools alleen garanderen geen goede exploratie. Effectieve EDA vereist nieuwsgierigheid naar wat de data onthult, scepsis ten aanzien van ogenschijnlijke patronen en de bereidheid om onverwachte bevindingen te volgen, waar ze ook toe leiden.
Volgens het academisch materiaal van Penn State biedt EDA (Exploratory Data Analysis) eerste aanknopingspunten voor diverse leertechnieken door complexe observaties te onderzoeken op structuren die diepere verbanden aangeven. Deze datagestuurde hypothesegeneratie transformeert ruwe cijfers in bruikbare inzichten die zakelijke beslissingen, wetenschappelijke ontdekkingen en technologische innovaties stimuleren.
Begin uw volgende data-project door voldoende tijd te besteden aan grondig onderzoek. Documenteer uw bevindingen. Visualiseer voordat u gaat modelleren. Stel vragen bij aannames. De inzichten die u opdoet tijdens een zorgvuldige verkennende data-analyse (EDA) zullen leiden tot betere beslissingen gedurende het hele analyseproces en uiteindelijk waardevollere en betrouwbaardere resultaten opleveren.
Ben je klaar om deze technieken toe te passen? Begin met een dataset die je interesseert, doorloop de gestructureerde fasen systematisch en ontdek wat je data je al die tijd al probeerde te vertellen.