Overzicht: De hostingkosten voor LLM's variëren sterk, afhankelijk van het implementatiemodel. Ze lopen uiteen van 1 TP4T0,025 per miljoen tokens voor API-services zoals OpenAI's GPT-5-nano tot 1 TP4T1.500-1 TP4T5.000 per maand voor zelfgehoste infrastructuur. Organisaties met meer dan 50.000 dagelijkse aanvragen realiseren vaak kostenbesparingen van 25-501 TP3T door zelf te hosten, terwijl kleinere organisaties profiteren van API-tarieven op basis van gebruik. De hardwarevereisten schalen mee met de modelgrootte: modellen met 7 miljard parameters hebben ongeveer 3,5 GB VRAM nodig met 4-bits kwantisering, terwijl modellen met 70 miljard parameters 35 GB of een multi-GPU-configuratie vereisen.
De uitgaven van bedrijven aan grote taalmodellen zijn explosief gestegen. Alleen al de kosten voor model-API's zijn verdubbeld tot 1 TP4 T8,4 miljard in 2025, en de meeste bedrijven zijn van plan hun AI-budgetten dit jaar verder te verhogen.
Maar er is iets belangrijks om te onthouden: niet elke organisatie hoeft op dezelfde manier te betalen. De kosten van LLM-hosting hangen volledig af van de schaal, het gebruikspatroon en de technische vereisten. API-diensten bieden enorm veel gemak, maar zelfhosting kan de kosten met 50% of meer verlagen bij voldoende schaal.
Deze gids geeft een overzicht van de werkelijke kosten van alle belangrijke hostingopties, van commerciële API's tot volledig zelfbeheerde infrastructuren.
API-gebaseerde LLM-kosten: prijs per token
Commerciële API-diensten werken met een pay-per-use-model, waarbij kosten in rekening worden gebracht op basis van verwerkte input- en outputtokens. Volgens de prijsdocumentatie van OpenAI uit 2026 variëren de kosten sterk tussen de verschillende modellen.
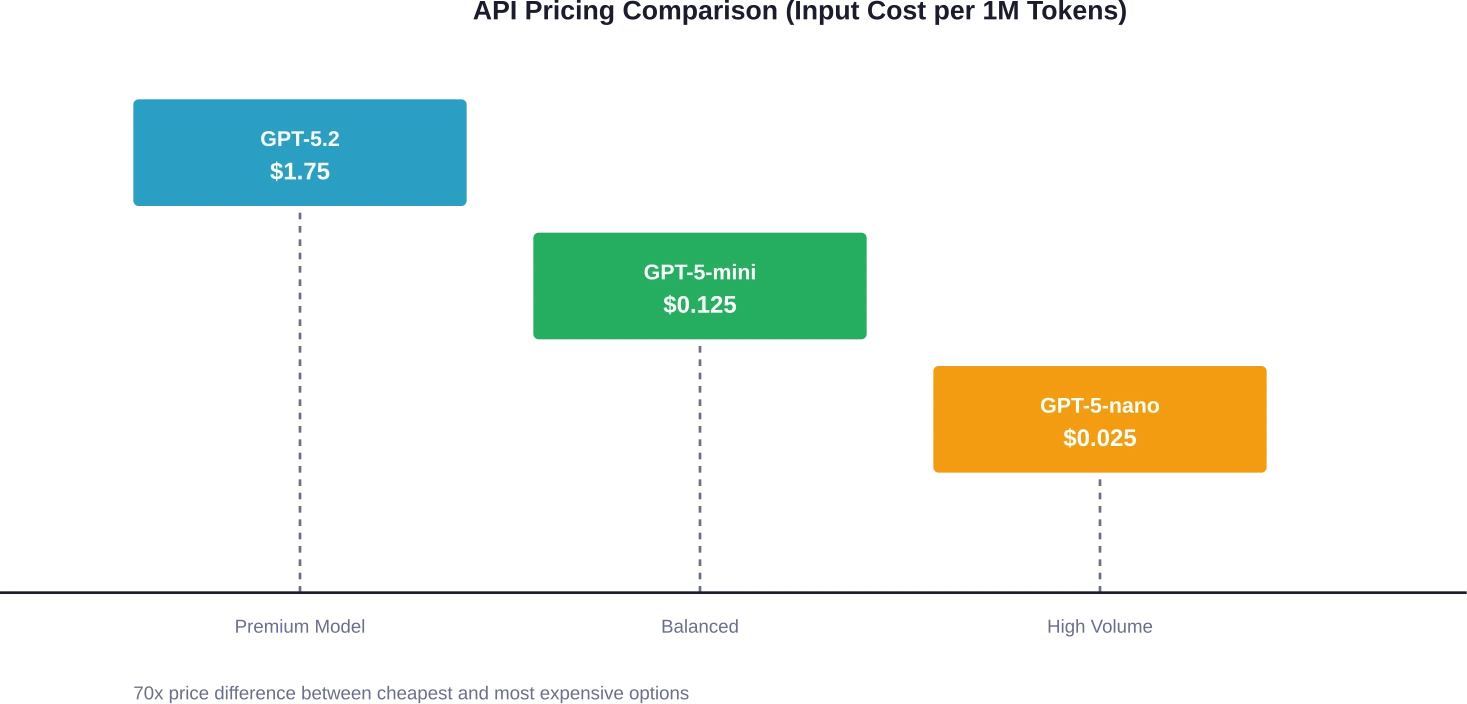
GPT-5.2 verbruikt $1,75 per miljoen invoertokens en $14,00 per miljoen uitvoertokens. Dit is het topmodel, ontworpen voor complexe redeneer- en codeertaken. Ter vergelijking: GPT-5-mini kost slechts $0,125 per miljoen invoertokens en $1,00 per miljoen uitvoertokens – 14 keer goedkoper voor invoer en 14 keer goedkoper voor uitvoer.
De nieuwste toevoeging, GPT-5-nano, verlaagde de prijs nog verder naar $0.025 per miljoen inputtokens en $0.20 per miljoen outputtokens. Voor teams die grote volumes aan eenvoudige taken uitvoeren, betekent dit een kostenbesparing van 80% ten opzichte van GPT-5-mini.
Opgeslagen invoerbesparingen
OpenAI introduceerde een prijsmodel voor gecachede invoer waarbij slechts 10% aan standaardtarieven wordt gerekend voor herhaalde inhoud. GPT-5.2 gecachede invoer kost $0,175 per miljoen tokens in plaats van $1,75. Voor toepassingen met consistente systeemprompts of referentiedocumenten is deze optimalisatie van belang.
De Batch API verlaagt de kosten met 50% voor niet-realtime workloads die asynchroon binnen 24 uur worden verwerkt.
Anthropic en Google-prijzen
De prijsstelling van Google Vertex AI voor Gemini 3-modellen (vanaf februari 2026) vertoont vergelijkbare tokengebaseerde structuren. Standaardprijzen gelden voor verzoeken met minder dan 200.000 invoertokens, met aparte tarieven voor grotere contexten en in de cache opgeslagen invoer.
Deze commerciële diensten brengen alleen kosten in rekening voor succesvolle verzoeken die een 200-responscode retourneren. Mislukte verzoeken brengen geen kosten met zich mee, wat voorkomt dat er onnodig gefactureerd wordt voor fouten.
Kosten voor cloudplatformhosting
AWS SageMaker, Google Vertex AI en Azure Foundry bieden beheerde LLM-hosting met meer controle dan pure API-services. Deze platforms rekenen kosten voor rekenkracht in plaats van tokens.
AWS SageMaker-prijsstructuur
Volgens de AWS-documentatie die in februari 2026 is bijgewerkt, brengt SageMaker kosten in rekening voor instantie-uren, opslag en gegevensoverdracht. De AWS Free Tier omvat 250 uur aan ml.t3.medium-instanties gedurende de eerste twee maanden, plus 4.000 gratis API-aanvragen per maand.
Voor productieworkloads schalen de instantieprijzen mee met de GPU-kracht. Organisaties die inferentie uitvoeren op ml.g5.xlarge-instanties (NVIDIA A10G GPU's) betalen verschillende tarieven, afhankelijk van de regio en het contractniveau.
AWS-gereserveerde instanties bieden aanzienlijke besparingen ten opzichte van on-demand tarieven. Gereserveerde contracten van één jaar kunnen de kosten voor voorspelbare workloads aanzienlijk verlagen.
Google Vertex AI Economie
De prijsdocumentatie van Google Vertex AI toont kosten gebaseerd op rekenuren, de implementatietijd van het model en het aantal voorspellingsaanvragen. Modellen die niet succesvol geïmplementeerd kunnen worden, brengen geen kosten met zich mee, en trainingsfouten (met uitzondering van annuleringen door de gebruiker) worden niet gefactureerd.
Dit op verbruik gebaseerde model beschermt tegen het betalen voor mislukte bewerkingen, wat belangrijk is bij het experimenteren met modelconfiguraties.
Infrastructuurkosten voor een zelfgehoste LLM-opleiding
Door zelf te hosten, verschuiven de kosten van variabele gebruikskosten naar vaste investeringen in infrastructuur. Voor organisaties met meer dan 50.000 dagelijkse aanvragen is dit vaak economisch aantrekkelijk.
De hardwarevereisten zijn volledig afhankelijk van de modelgrootte. Als vuistregel geldt: ongeveer 0,5 GB VRAM per miljard parameters bij gebruik van 4-bits kwantisering. Volledige precisie (FP16) verdubbelt die vereiste.
| Modelmaat | Parameters | VRAM (4-bit) | VRAM (FP16) | Typische hardware |
|---|---|---|---|---|
| Klein | 7B-13B | 3,5-6,5 GB | 14-26 GB | Enkele A100/H100 |
| Medium | 30B-40B | 15-20 GB | 60-80 GB | A100 80GB |
| Groot | 70 miljard+ | 35 GB+ | 140 GB+ | Multi-GPU-configuratie |
Als het model niet in het VRAM past, schakelt het systeem over op CPU-verwerking, wat 10 tot 100 keer trager is. Dat is niet haalbaar voor productie.
Maandelijkse infrastructuurkosten per niveau
Onderzoek van Carnegie Mellon University naar de economische aspecten van LLM-implementaties op locatie laat duidelijk verschillende kostencategorieën zien:
| Laag | Modelmaat | Hardwareconfiguratie | Maandelijkse kostenbereik | Het beste voor |
|---|---|---|---|---|
| Invoer | 7B-13B | 1x A100/H100 | $1,500-$5,000 | Prototypes, interne tools |
| Midden | 30B-70B | 4-8 GPU-cluster | $8,000-$20,000 | Productie-apps, middelgrote schaal |
| Onderneming | 70 miljard+ | 8+ GPU-cluster | $20,000-$50,000+ | Productie op grote schaal |
Deze cijfers omvatten de afschrijving van hardware, stroomverbruik, koeling en basisonderhoud. Het onderzoeksartikel op arxiv.org over kosten-batenanalyse vermeldt dat de uurkosten voor GPU's van de A800 80G-serie onder gangbare aannames ongeveer $0,79/uur bedragen, en doorgaans tussen de $0,51 en $0,99/uur liggen.
AWS EC2 Reserved Instance Savings
Uit een analyse van LinkedIn's uitgebreide kostenoverzicht voor LLM-hosting blijkt dat gereserveerde AWS EC2-instances aanzienlijke besparingen opleveren ten opzichte van on-demand tarieven. Voor g5.xlarge-instances (geschikt voor modellen met 8 miljard parameters) kunnen reserveringen van een jaar de maandelijkse kosten verlagen van ongeveer $530 naar veel lagere tarieven.
De goedkoopste optie voor 8B-modellen was Deep Infra met $5,40 per maand, terwijl AWS SageMaker de duurste was met $529,92 per maand. De mediane kosten liggen rond de $237 per maand.

Ken de kosten voor het hosten van uw LLM-opleiding.
Het hosten van LLM-cursussen brengt keuzes met zich mee op het gebied van latentie, schaalbaarheid, beveiliging en budget. AI Superieur Het helpt u bij het kiezen van een geschikt hostingmodel (cloud, edge of hybride), het inschatten van het resourcegebruik en het berekenen van terugkerende kosten op basis van verkeer en prestaties. Hun evaluatie omvat overwegingen met betrekking tot opslag, monitoring, schaalbaarheid en doorlopend onderhoud. Dit geeft u een betrouwbare prognose van uw hostingkosten.
Bent u klaar om uw budget voor de organisatie van uw LLM-opleiding vast te stellen?
Praat met AI die superieur is aan:
- Kies de juiste hostingarchitectuur.
- schat de benodigde middelen en operationele kosten in.
- ontvang een duidelijke specificatie van de hostingkosten
👉 Vraag een kosten voor het hosten van een LLM-programma schatting van AI Superior.
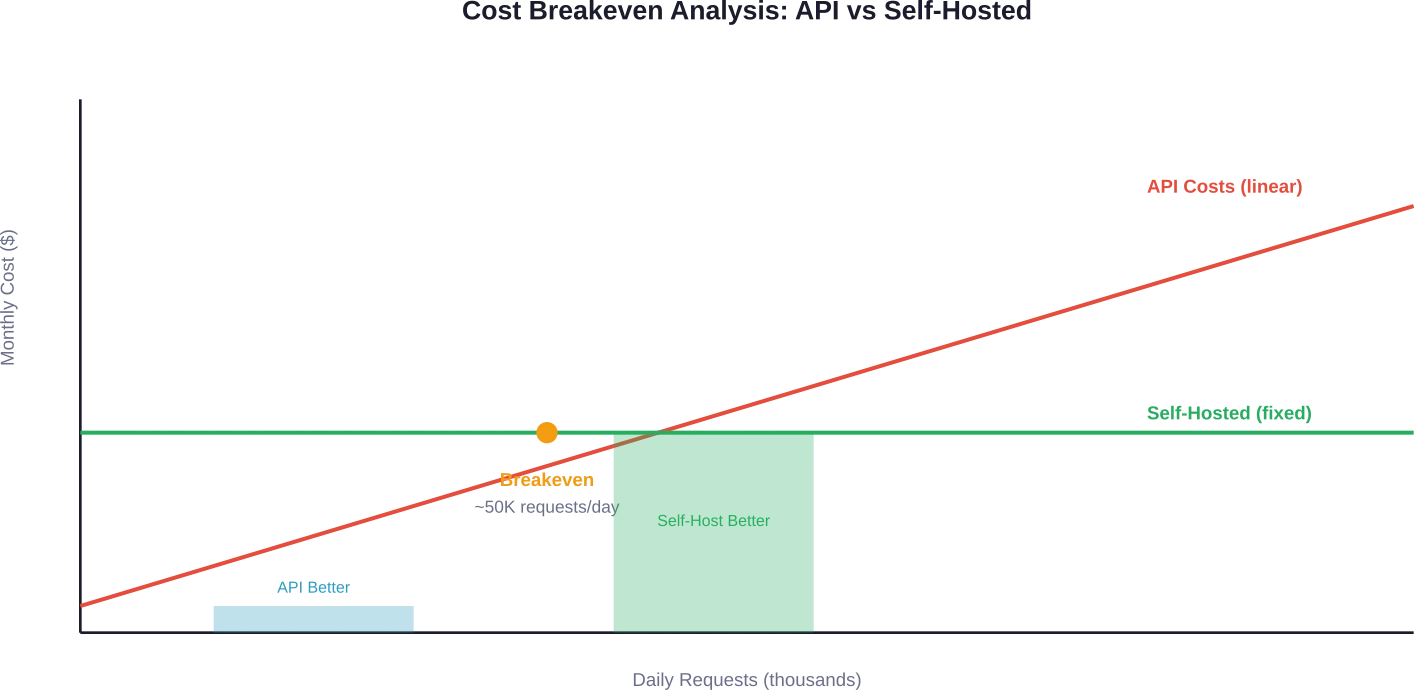
Break-evenpunt: Wanneer zelfhosting zinvol is
Het omslagpunt hangt af van het aantal aanvragen. Discussies binnen de community en kostenanalyses wijzen er steevast op dat zelfhosting economisch aantrekkelijk wordt bij meer dan 50.000 dagelijkse aanvragen.
Dit is waarom: API-kosten schalen lineair met het gebruik. Vaste infrastructuurkosten blijven constant, ongeacht het aanvraagvolume (binnen de capaciteitslimieten).
Een organisatie die dagelijks 50.000 verzoeken verwerkt met 500 input-tokens en 500 output-tokens per verzoek met behulp van GPT-5-mini, zou maandelijks ongeveer $3.125 uitgeven aan API-aanroepen. En dat is nog zonder rekening te houden met applicatie-infrastructuur, cachinglagen of monitoring.
Een zelfgehost 7B-model op instaphardware ($1.500-$5.000/maand) verwerkt vergelijkbare volumes en biedt volledige controle over de gegevens. De kostenbesparingen nemen aanzienlijk toe bij meer dan 100.000 dagelijkse aanvragen.
Verborgen kosten waar niemand over praat
De prijs op het prijskaartje vertelt slechts een deel van het verhaal. Zowel API- als zelfgehoste oplossingen brengen verborgen kosten met zich mee die de totale eigendomskosten beïnvloeden.
Verborgen kosten van API-services
Snelheidslimieten dwingen tot architectuurkeuzes. Wanneer de doorvoerlimieten worden bereikt, hebben applicaties wachtrijsystemen, herhalingslogica en terugvalmechanismen nodig. Dat brengt ontwikkeltijd en infrastructuurkosten met zich mee.
De kosten voor data-uitvoer kunnen oplopen bij applicaties met een hoog volume. Hoewel de verwerking van het token zelf $X kost, brengt het verplaatsen van grote datasets van en naar API-providers aparte kosten met zich mee.
Vendor lock-in brengt overstapkosten met zich mee. Applicaties die gebouwd zijn rond specifieke API-responsformaten, toolintegraties of snelle ontwikkeltechnieken kunnen niet zomaar van provider wisselen.
Verborgen kosten bij zelfhosting
De overheadkosten van DevOps zijn aanzienlijk. Iemand moet verantwoordelijk zijn voor modelupdates, beveiligingspatches, monitoring en incidentafhandeling. Volgens het Enterprise AI-rapport van Kong uit 2025 noemt 441.000 tot 300.000 organisaties gegevensprivacy en -beveiliging als de grootste obstakels. Zelfhosting vereist specifieke resources om deze problemen adequaat aan te pakken.
Stroomverbruik en koeling zijn duurder dan de pure rekenkracht. Datacenters melden dat het werkelijke stroomverbruik 1,5 tot 2 keer zo hoog is als het nominale stroomverbruik van de GPU, rekening houdend met de inefficiënties van koeling en voeding.
Schalen gebeurt niet automatisch. Het toevoegen van capaciteit brengt levertijden voor hardware, ruimte in serverracks en planning van de netwerkinfrastructuur met zich mee. API-services schalen direct.
Optimalisatiestrategieën die echt werken
Ongeacht de gekozen hostingmethode, zijn er verschillende technieken die de LLM-kosten consequent verlagen zonder dat dit ten koste gaat van de prestaties.
Modelselectie en kwantisering
Kleinere modellen presteren vaak beter dan verwacht bij domeinspecifieke taken. Volgens onderzoek van Together AI kan het finetunen van een open-source model van 27B voor gespecialiseerde taken Claude Sonnet 4 met 60% overtreffen, terwijl het 10 tot 100 keer goedkoper is.
4-bits kwantisering halveert de geheugenbehoefte met minimale impact op de kwaliteit voor de meeste toepassingen. Deze techniek maakt het mogelijk om grotere modellen op dezelfde hardware te draaien of hetzelfde model op goedkopere hardware uit te voeren.
Batchverwerking
De Batch API van OpenAI bespaart 50% aan input en output met asynchrone verwerking over een periode van 24 uur. De documentatie van de Batch API van TogetherAI laat vergelijkbare besparingen zien: taken die geen realtime respons vereisen, moeten altijd gebruikmaken van batch-endpoints.
AWS-onderzoek naar SageMaker-optimalisatie toont aan dat het bundelen van inferentieverzoeken het GPU-gebruik aanzienlijk verbetert, waardoor de kosten per voorspelling dalen.
Caching en het verwijderen van dubbele aanvragen
Systeemprompts, referentiedocumenten en herhaalde zoekopdrachten leiden tot geldverspilling. Door promptcaching op applicatieniveau te implementeren, wordt overbodige tokenverwerking geëlimineerd.
Bij zelfgehoste implementaties kan middleware voor het dedupliceren van verzoeken identieke query's onderscheppen voordat ze het model bereiken, waardoor in plaats daarvan antwoorden uit de cache worden aangeboden.
Verkeersvoorspelling en automatische schaling
Onderzoek van Microsoft naar de efficiëntie van LLM-servers (SageServe) heeft een besparing van maximaal 251 TP3T aan GPU-uren opgeleverd door middel van voorspellingsgestuurde automatische schaling, met potentiële maandelijkse kostenbesparingen tot 1 TP4T2,5 miljoen. Het systeem analyseert historische aanvraagpatronen en past de capaciteit proactief aan.
Dit vermindert de verspilling van GPU-uren als gevolg van inefficiënte automatische schaling met maximaal 80% in vergelijking met reactieve schaalmethoden.
Regionale kostenverschillen
De hostingkosten voor LLM-systemen variëren aanzienlijk per geografische regio. AWS, Google Cloud en Azure hanteren allemaal regionale prijsstelling die de lokale infrastructuurkosten, energieprijzen en marktomstandigheden weerspiegelt.
Analyse van 10 miljoen aanvragen uit verschillende regio's op basis van echte productiedata laat regionale kostenverschillen zien. Voor API-diensten worden deze verschillen doorgaans geabstraheerd. Maar voor zelfgehoste infrastructuur heeft de keuze van de juiste regio een aanzienlijke invloed op de maandelijkse kosten.
Bij API-services worden deze verschillen meestal geabstraheerd. Maar bij zelfgehoste infrastructuur heeft de keuze van de juiste regio een aanzienlijke invloed op de maandelijkse kosten.
Kostentrends in 2026
Verschillende factoren zorgen ervoor dat de kosten voor het organiseren van een LLM-programma dit jaar dalen.
Verbeteringen in algoritmische efficiëntie zijn belangrijker dan vooruitgang in hardware. Volgens onderzoek van MIT FutureTech naar algoritmische efficiëntie hebben verbeteringen in de ruimtecomplexiteit voor grote problemen (n=1 miljard) de verbeteringen in DRAM in 20% van de geanalyseerde gevallen overtroffen.
Nieuwe modelarchitecturen zoals Mixture-of-Experts (MoE) creëren andere kostenprofielen. Onderzoek naar de belasting van MoE-modellen laat zien dat deze modellen unieke inefficiënties kennen, zoals een onevenwichtige belasting tijdens het voorvullen en een toename van geheugentransfers tijdens het decoderen. Geoptimaliseerde MoE-implementaties kunnen echter een betere prijs-prestatieverhouding bieden dan dense modellen.
AWS kondigde in 2023 nieuwe Large Model Inference-containers aan die de latentie met 331 TP3T verlaagden voor Llama-2 70B-workloads. Bijgewerkte versies blijven de efficiëntie verbeteren. Voor Llama-2 70B bij een gelijktijdigheid van 16 processen werd de latentie met 281 TP3T verlaagd en de doorvoer met 441 TP3T verhoogd met TensorRT-LLM-containers.
Veelgestelde vragen
Wat is de goedkoopste manier om in 2026 een LLM-opleiding te organiseren?
Voor kleinschalig gebruik (minder dan 10.000 aanvragen per dag) biedt OpenAI's GPT-5-nano met $0,025 per miljoen invoertokens de laagste instapdrempel zonder infrastructuurkosten. Voor grootschalige productie (meer dan 50.000 aanvragen per dag) is het zelf hosten van modellen met 7 tot 13 miljard parameters op instaphardware ($1.500-$5.000 per maand) doorgaans goedkoper dan een vergelijkbaar API-gebruik.
Hoeveel VRAM heb ik nodig om een model met 70 miljard parameters te draaien?
Een model met 70B parameters vereist ongeveer 35 GB VRAM met 4-bits kwantisering of 140 GB met volledige FP16-precisie. Dit betekent doorgaans een A100 GPU van 80 GB (krap met kwantisering) of een configuratie met meerdere GPU's voor een soepele werking. Zonder voldoende VRAM schakelt het model over op CPU-verwerking, wat 10 tot 100 keer trager is.
Zijn AWS reserved instances de investering waard voor LLM-hosting?
Gereserveerde instanties zijn zinvol voor voorspelbare, continue workloads die 24/7 draaien. AWS EC2-reserveringen van één jaar laten aanzienlijke besparingen zien ten opzichte van de prijsstelling op aanvraag voor GPU-instanties. De reservering legt echter capaciteit vast, waardoor organisaties met wisselende gebruikspatronen mogelijk te veel betalen tijdens perioden met weinig vraag.
Kunnen kleine organisaties zich een zelf georganiseerde LLM-opleiding veroorloven?
Zelfhosting begint bij de instapversie met kosten van ongeveer 1.500 tot 5.000 euro per maand voor modellen met 7 tot 13 miljard parameters. Organisaties die dagelijks meer dan 50.000 aanvragen verwerken, draaien vaak quitte in vergelijking met API-kosten op deze schaal. Onder die drempel zijn API-diensten doorgaans goedkoper als rekening wordt gehouden met de overheadkosten voor DevOps, onderhoud en beheer.
Wat is het werkelijke kostenverschil tussen de GPT-5.2 en de GPT-5-mini?
Volgens de prijsstelling van OpenAI voor 2026 kost GPT-5.2 $1,75 per miljoen inputtokens en $14,00 per miljoen outputtokens, terwijl GPT-5-mini $0,125 per input en $1,00 per output kost – een verschil van 14x voor zowel input als output. Voor een typische applicatie die dagelijks 1 miljoen tokens verwerkt (500.000 input, 500.000 output), kost GPT-5.2 ongeveer $7.875 per maand, tegenover $562,50 voor GPT-5-mini.
Bespaart caching echt geld op LLM-kosten?
Ja, absoluut. OpenAI's prijsbeleid voor gecachede invoer bedraagt slechts 10% aan standaardtarieven voor herhaalde content. Voor applicaties met consistente systeemprompts of referentiedocumenten betekent dit dat gecachede GPT-5.2-invoer $0,175 per miljoen tokens kost in plaats van $1,75. Applicaties met 50% aan cachebare content kunnen de API-kosten met ongeveer 45% verlagen.
Hoe weet ik wanneer ik van een API naar een zelfgehoste oplossing moet overstappen?
Bereken de huidige maandelijkse API-kosten en de projectgroei. Vergelijk dit met een instapmodel self-hosting infrastructuur ($1.500-$5.000/maand) plus DevOps overhead (doorgaans 0,25-0,5 FTE engineeringtijd). Als de API-kosten meer dan $5.000 per maand bedragen en het gebruik voorspelbaar is, is self-hosting meestal economisch aantrekkelijk. Naast de pure kosten spelen ook andere factoren een rol bij de beslissing, zoals vereisten op het gebied van gegevensprivacy, compliance en aanpassingsmogelijkheden.
Slotgedachten
De kosten voor LLM-hosting zijn niet voor iedereen hetzelfde. De juiste keuze hangt af van het aanvraagvolume, de prestatie-eisen, de gevoeligheid van de gegevens en de technische mogelijkheden.
API-services zijn ideaal om snel aan de slag te gaan, wisselende werkbelastingen aan te kunnen en infrastructuurbeheer te vermijden. Ze zijn vrijwel altijd goedkoper bij minder dan 50.000 dagelijkse aanvragen.
Zelfhosting is economisch aantrekkelijk op grote schaal, vooral wanneer gegevensprivacy belangrijk is of wanneer domeinspecifieke optimalisatie betere resultaten oplevert dan algemene modellen. Het vereist echter wel een DevOps-aanpak en een initiële investering in infrastructuur.
De beste aanpak? Begin met API's om de product-marktfit te valideren en evalueer vervolgens zelfhosting zodra de gebruikspatronen stabiel zijn en de kosten de investering in infrastructuur rechtvaardigen. Veel organisaties hanteren hybride implementaties: API's voor experimenten en overloopcapaciteit, en zelfgehoste infrastructuur voor de belangrijkste productieworkloads.
Kies de aanpak die het meest geschikt is voor de huidige behoeften en bouw flexibel. De economische aspecten en mogelijkheden van LLM-hosting blijven zich snel ontwikkelen.