Korte samenvatting: De inferentiekosten van LLM zijn sinds 2021 jaarlijks vertienvoudigd. Prestaties op GPT-4-niveau kosten nu $0,40 per miljoen tokens, vergeleken met $30 per miljoen inputtokens en $60 per miljoen outputtokens in maart 2023. Redeneermodellen kunnen echter intern 100 keer meer tokens verbruiken dan ze produceren, wat een kostenparadox creëert waarbij lagere prijzen per token leiden tot hogere totale kosten. Inzicht in de werkelijke infrastructuurkosten, optimalisatietechnieken en de keuze tussen API-services en zelfgehoste implementaties is essentieel voor een duurzame AI-economie.
De economie van kunstmatige intelligentie is een fase ingegaan die alle conventionele logica tart. Terwijl krantenkoppen de kelderende tokenprijzen toejuichen, ontdekken AI-bedrijven een ongemakkelijke waarheid: hun kosten blijven stijgen.
Wat in november 2021 $60 per miljoen tokens kostte, kost nu $0,06-0,40 per miljoen tokens voor een vergelijkbare GPT-4-prestatie, wat een reductie van 150-1000 keer betekent, afhankelijk van het model. Toch melden veel startups die bouwen op grote taalmodellen dat de infrastructuurkosten 40-60% van hun omzet opslokken.
De boosdoener? Een fundamentele verschuiving in de manier waarop moderne AI-modellen reacties genereren, en een patroon in het gebruik van tokens dat niemand had zien aankomen.
De dramatische daling van de LLM-inferentieprijs
De inferentiekosten van LLM zijn sneller gedaald dan die van vrijwel elke andere computercomponent in de geschiedenis. Volgens onderzoek naar prijstrends varieert de snelheid waarmee de kosten dalen sterk, afhankelijk van de prestatiemijlpaal, van 9 tot 900 keer per jaar.
De mate van daling verschilt sterk, afhankelijk van de taak. Voor sommige benchmarks daalden de prijzen met een factor 9 per jaar. Voor andere liep de daling op tot een factor 900 per jaar – hoewel deze extreme dalingen zich voornamelijk in 2024 voordeden en mogelijk niet aanhouden.
Zo ziet dat er in de praktijk uit. Toen GPT-3 in november 2021 publiekelijk beschikbaar kwam, was het het enige model met een MMLU-score van 42. De kosten? $60 per miljoen tokens. Tegen maart 2026 overtreffen meerdere modellen die benchmark met $0,06 per miljoen tokens of minder.
Google's Gemini Flash-Lite 3.1 voert de lijst aan met budgetvriendelijke prijzen van $0,25 per miljoen inputtokens en $1,50 per miljoen outputtokens. Open-source modellen van aanbieders zoals Together.ai gaan nog een stap verder: Llama 3.2 3B werkt op $0,06 per miljoen tokens voor input.
Waarom de prijzen zo snel daalden
Verschillende factoren dragen bij aan deze kostenverlagingen. Modellen worden kleiner met behoud van prestaties, dankzij verbeterde trainingstechnieken. Een model met 13 miljard parameters kan nu een MMLU-score van 95% van GPT-3 behalen met een aanzienlijk kleinere inferentievoetafdruk.
De hardwarekosten per rekeneenheid blijven dalen. De prijzen voor Cloud H100 stabiliseerden zich op $2,85-$3,50 per uur na een daling ten opzichte van de pieken in 2023. Volgens onderzoek van arXiv bedragen de basiskosten per uur voor een A800 80G-kaart ongeveer $0,79/uur, met een gemiddelde prijs tussen $0,51 en $0,99/uur.
Optimalisatietechnieken zoals kwantisering, continue batchverwerking en PagedAttention hebben de doorvoercapaciteit aanzienlijk verhoogd. Systemen in de MLPerf Inference v5.1-benchmark presteerden tot wel 501 TP3T beter dan het beste systeem in de 5.0-release van zes maanden eerder (september 2025).
Maar er zit een addertje onder het gras.
De paradox van tokenconsumptie
Een lagere prijs per token vertelt slechts de helft van het verhaal. De andere helft heeft te maken met hoeveel tokens moderne modellen daadwerkelijk verbruiken.
Traditionele taalmodellen genereren antwoorden lineair. Stel een vraag, krijg een antwoord. Het tokenverbruik komt ruwweg overeen met de lengte van de uitvoer. Een antwoord van 200 woorden verbruikt ongeveer 250-300 tokens.
Redeneermodellen werken anders. Ze "denken" intern over problemen voordat ze een resultaat produceren. Dit interne redeneerproces verbruikt tokens – heel veel tokens.
Praktische voorbeelden laten de omvang van deze verschuiving zien. Een simpele vraag kan intern 10.000 redeneertokens gebruiken, terwijl het antwoord slechts 200 tokens bevat. Dat zijn 50 keer meer tokens dan de zichtbare uitvoer doet vermoeden.
In extreme gevallen, zoals gedocumenteerd door gebruikers, verbruikten sommige redeneermodellen meer dan 600 tokens om slechts twee woorden als uitvoer te genereren. Een eenvoudige zoekopdracht die met een standaardmodel 50 tokens zou gebruiken, kan met een agressief redeneermodel ingeschakeld oplopen tot meer dan 30.000 tokens.
De impact op het bedrijfsleven
Dit leidt tot wat sommigen de "LLM-kostenparadox" noemen. De prijs per token daalde met een factor 10, maar het tokenverbruik steeg met een factor 100 voor bepaalde workloads. De cijfers spreken niet in het voordeel van AI-bedrijven.
Startups die prijsmodellen hebben gebouwd rond traditionele tokeneconomieën, zien hun marges onder druk komen te staan. Een klant die 1 TP4T20 per maand betaalt, kan tijdens complexe redeneertaken 1 TP4T18-25 aan inferentiekosten genereren. De eenheidseconomie klopt gewoon niet.
Sommige aanbieders reageerden door het aantal redeneertokens te beperken, waardoor de hoeveelheid intern denkwerk die een model kan uitvoeren, wordt ingeperkt. Anderen implementeerden getrapte prijzen waarbij verzoeken die veel redeneerwerk vereisen, meer kosten. Maar deze oplossingen creëren wrijving en complexiteit.
Inzicht in de werkelijke infrastructuurkosten
Naast de API-prijzen moeten teams die een zelfgehoste implementatie overwegen, de volledige kostenstructuur begrijpen. De cijfers laten zien wanneer zelfhosting economisch zinvol is en wanneer niet.
GPU-infrastructuureconomie
Volgens de benchmarkrichtlijnen van NVIDIA, gepubliceerd in juni 2025, vereist de berekening van de werkelijke inferentiekosten dat rekening wordt gehouden met de aanschaf van hardware, stroomverbruik, koeling, netwerkbandbreedte en operationele overhead.
Cloud H100-instances kosten $2,85-$3,50 per uur, afhankelijk van de provider en de contractduur. Zelf gehoste H100's vereisen een investering plus doorlopende kosten. De break-evenberekening is afhankelijk van de bezettingsgraad.
Onderzoek toont aan dat zelfgehoste infrastructuur rendabel wordt wanneer het GPU-gebruik duurzaam de 50% overschrijdt. Onder die drempel bieden API-diensten doorgaans een betere prijs-kwaliteitverhouding.
| Kostencomponent | Cloudprovider | Zelf gehost |
|---|---|---|
| GPU-kosten | $2.85-3.50/uur | $30.000-40.000 (H100) |
| Vermogen (per GPU) | Inbegrepen | $0.40-0.60/uur |
| Koeling | Inbegrepen | $0.15-0.25/uur |
| Netwerk | $0.08-0.12/GB uitgaand | Vaste maandelijkse |
| Operaties | Minimaal | 1-2 FTE-ingenieurs |
| Break-evenpunt | — | 50%+ gebruik |
De gebruiksvergelijking
Het gebruik is doorslaggevend. Een GPU die op 30% draait, kost 3,3 keer meer per inferentie dan een GPU die op 100% draait. Maar om een hoog gebruik te bereiken, zijn een constant werkvolume en geavanceerde batchstrategieën nodig.
Batchverwerking kan de kosten per uitvoertoken met maximaal 30% verlagen in vergelijking met de verwerking van individuele verzoeken. Technieken zoals continue batchverwerking, waarbij de inferentie-engine verzoeken dynamisch combineert zodra ze binnenkomen, maximaliseren de doorvoer.
Efficiëntieverbeteringen in modellen door middel van kwantisatie, Mixture of Experts-architecturen en data-pruning kunnen de kosten met een factor 2 tot 5 verlagen zonder kwaliteitsverlies. Volgens informatie van Together.ai is de MoE-architectuur van DeepSeek in staat om kosteneffectief prestaties van GPT-4-niveau te leveren.
Kostenstructuur per modelgrootte
De modelgrootte heeft een directe invloed op de inferentiekosten, maar de relatie is niet lineair. Kleinere modellen betekenen niet altijd proportioneel lagere kosten, en grotere modellen bieden soms een betere prijs-kwaliteitverhouding voor complexe taken.
Kleine modellen (3B-7B parameters)
Modellen in deze prijsklasse blinken uit in kostenefficiëntie voor eenvoudige taken. Llama 3.2 3B kost ongeveer $0.06 per miljoen tokens. Deze modellen kunnen classificatie, eenvoudige vraagbeantwoording en gestructureerde data-extractie effectief uitvoeren.
De afweging zit hem in de mogelijkheden. Kleine modellen hebben moeite met complexe redeneringen, genuanceerd taalbegrip en taken die uitgebreide wereldkennis vereisen. Voor veel productieworkloads is dat acceptabel.
Middelgrote modellen (13B-70B parameters)
Dit bereik vertegenwoordigt de ideale situatie voor veel toepassingen. Een model van 13 miljard tokens dat een MMLU-score van 95% van GPT-3 behaalt, zou $0,25 per miljoen tokens kunnen kosten – hoger dan kleine modellen, maar met aanzienlijk betere redeneermogelijkheden.
De 70B-klasse modellen zoals Llama 3.1 70B bieden prestaties die de grens van het gemiddelde benaderen, met een kostprijs van ongeveer $0,80 per miljoen tokens. Voor toepassingen die een sterke onderbouwing vereisen zonder absolute toptechnologie, bieden deze modellen een uitstekende prijs-kwaliteitverhouding.
Grote modellen (175 miljard+ parameters)
Frontier-modellen zoals GPT-4, Claude en Gemini Ultra kosten 1 TP4 TP2-15 per miljoen tokens, afhankelijk van het specifieke model en de aanbieder. Ze blinken uit in complexe redeneringen, creatieve taken en problemen die diepgaande domeinkennis vereisen.
De hogere kosten per token worden economisch verantwoord wanneer het model taken in minder iteraties voltooit, nauwkeurigere antwoorden levert of gebruiksscenario's mogelijk maakt die kleinere modellen simpelweg niet aankunnen.

Heeft u hulp nodig bij het ontwerpen en implementeren van een LLM-systeem?
Als je van plan bent een groot taalmodel in productie te nemen, is het handig om samen te werken met een team dat dagelijks AI-systemen bouwt en implementeert. AI Superieur Ze ontwikkelen maatwerk AI-applicaties op basis van machine learning en LLM-modellen, van de eerste haalbaarheidsstudies tot de implementatie en integratie. Hun team van datawetenschappers en engineers werkt aan modelontwikkeling, NLP-systemen, datapijplijnen en de implementatie in productieomgevingen. Ze helpen ook bij het beoordelen of een use case daadwerkelijk een LLM vereist en hoe het systeem zo gestructureerd kan worden dat het efficiënt werkt.
Bent u klaar om de implementatie van uw LLM-programma te plannen?
Praat met AI die superieur is aan:
- Evalueer uw LLM-gebruiksscenario en technische vereisten.
- Het ontwerpen en bouwen van op maat gemaakte AI- of NLP-systemen.
- modellen implementeren en integreren in bestaande software.
👉 Vraag een AI-consult aan bij AI Superieur om je LLM-project te bespreken.
API-services versus zelfgehoste oplossingen
De keuze tussen API-services en zelfgehoste infrastructuur hangt af van de schaal, het gebruikspatroon en de technische mogelijkheden. Geen van beide opties is universeel superieur.
Wanneer API-services winnen
API-diensten van OpenAI, Anthropic, Google en aanbieders zoals Together.ai bieden aantrekkelijke economische voordelen voor veel scenario's. Doordat er geen infrastructuurbeheer nodig is, kunnen teams zich richten op de applicatielogica in plaats van op GPU-orkestratie.
De kosten schalen lineair met het gebruik. Maanden met weinig gebruik kosten naar verhouding minder dan maanden met veel gebruik. Er zijn geen kapitaaluitgaven, geen ongebruikte capaciteit tijdens perioden met weinig vraag en geen operationele overheadkosten voor de infrastructuur die het model ondersteunt.
Voor toepassingen met wisselende verkeerspatronen, seizoensgebonden vraag of onvoorspelbare groeitrajecten bieden API's doorgaans een betere economische oplossing, tenzij de continue doorvoer een vrij hoge drempel overschrijdt.
Wanneer zelfhosting zinvol is
Zelfhosting wordt economisch haalbaar wanneer het GPU-gebruik duurzaam de 50% kan overschrijden. Volgens benchmarkgegevens vereist dit een constant werkvolume – ongeveer 10 miljoen tokens per dag voor een configuratie met één GPU.
Naast puur economische overwegingen kiezen sommige organisaties ervoor om hun systemen zelf te hosten vanwege privacyoverwegingen, aanpassingsmogelijkheden of specifieke behoeften op het gebied van latentie. Financiële dienstverleners, zorginstellingen en overheidsinstanties kunnen vaak geen gegevens naar API's van derden verzenden, ongeacht de kostenvoordelen.
Open-source inferentie-engines zoals vLLM maken krachtige, zelfgehoste implementaties mogelijk. De PagedAttention- en continue batchverwerkingstechnieken van vLLM maximaliseren het GPU-gebruik, waardoor zelfhosting economisch aantrekkelijker wordt.
| Factor | Geeft de voorkeur aan API's | Geeft de voorkeur aan zelfhosting |
|---|---|---|
| Volume | <10 miljoen tokens per dag | >50 miljoen tokens per dag |
| Verkeerspatroon | Variabel/stekelig | Consistent/voorspelbaar |
| Latentiebehoeften | Flexibele | Ultra-lage vereiste |
| Gegevensgevoeligheid | Standaard | Zeer gevoelig |
| Maatwerk | Standaardmodellen OK | Aangepaste modellen nodig |
| Technische capaciteit | Beperkte ML-operaties | Sterk ML-operatieteam |
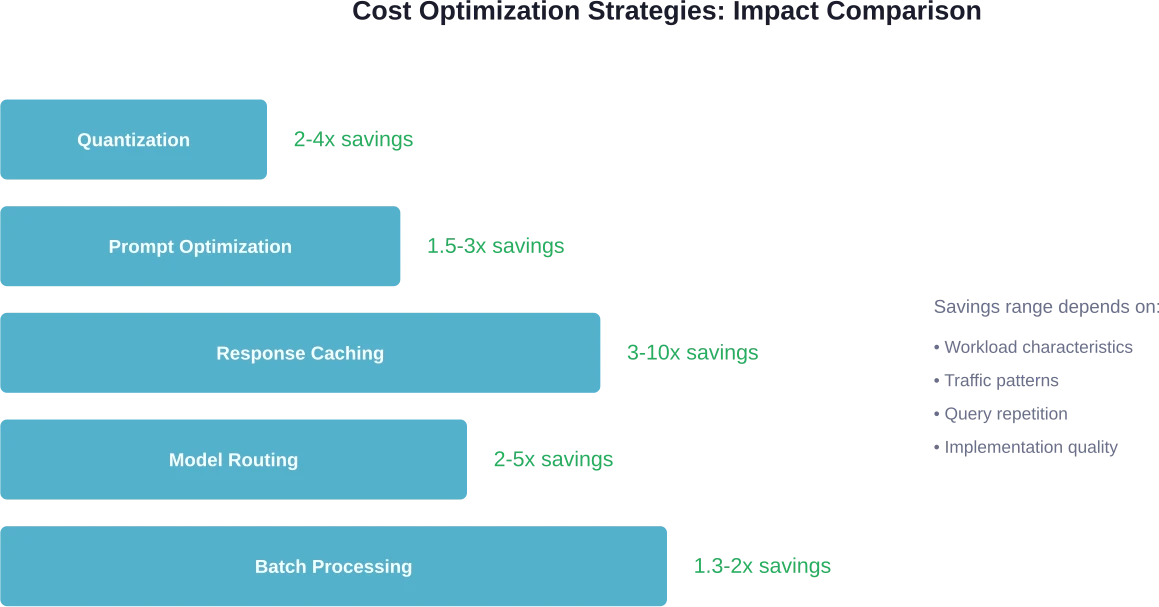
Optimalisatietechnieken die de economie transformeren
Verschillende technieken kunnen de inferentiekosten met een factor 2 tot 10 verlagen zonder kwaliteitsverlies. Deze optimalisaties werken zowel bij gebruik van API's als bij zelfhosting.
Kwantisatie
Kwantisatie verlaagt de precisie van het model van 16-bits of 32-bits drijvende-kommagetallen naar 8-bits of zelfs 4-bits gehele getallen. Dit verkleint het geheugenverbruik en versnelt de inferentie.
Moderne kwantiseringsmethoden behouden de kwaliteit opmerkelijk goed. Volgens onderzoek naar FP8-training kunnen de meeste variabelen in LLM-training en -inferentie gebruikmaken van formaten met lage precisie zonder dat de nauwkeurigheid in het gedrang komt. Aanbieders zoals Together.ai bieden gekwantiseerde modellen aan tegen lagere prijzen en beweren de kwaliteit te behouden.
Snelle optimalisatie
De lengte van een prompt heeft direct invloed op de kosten. Een prompt van 5.000 tokens die 1.000 keer wordt verwerkt, kost evenveel als 5 miljoen tokens aan inferentie. Door prompts te optimaliseren zodat ze beknopt zijn zonder in te leveren op effectiviteit, worden de kosten direct verlaagd.
Onderzoek toont aan dat promptoptimalisatie de nauwkeurigheid van taken kan verbeteren en tegelijkertijd het tokenverbruik kan verminderen. Goed gestructureerde prompts sturen modellen efficiënter aan, waardoor er minder redeneertokens nodig zijn om tot de juiste antwoorden te komen.
Reactiecaching
Veel applicaties doen herhaaldelijk vergelijkbare of identieke verzoeken. Door reacties op veelvoorkomende vragen in de cache op te slaan, worden overbodige inferentiekosten volledig geëlimineerd.
Slimme cachingstrategieën houden rekening met de gelijkenis van de prompt, niet alleen met exacte overeenkomsten. Semantische caching vergelijkt de betekenis van verzoeken en retourneert gecachede antwoorden voor voldoende vergelijkbare zoekopdrachten, zelfs als de formulering verschilt.
Modelroutering
Niet elke aanvraag vereist het krachtigste model. Door eenvoudige query's naar kleine, snelle modellen te routeren en complexe query's naar grotere modellen, wordt de afweging tussen kosten en kwaliteit geoptimaliseerd.
Dit vereist voorafgaande logica om de complexiteit van verzoeken te classificeren, maar de economische voordelen rechtvaardigen de investering vaak. Het routeren van 70% aan verkeer naar een model met $0,10/miljoen tokens en 30% naar een model met $3/miljoen tokens levert een gecombineerde kostprijs op van $0,97/miljoen – aanzienlijk lager dan het gebruik van het dure model voor alles.
Aanbiederslandschap in 2026
De markt voor inferentieproviders is aanzienlijk geëvolueerd. Verschillende categorieën providers voorzien nu in verschillende behoeften.
Frontier Model API's
OpenAI, Anthropic en Google bieden geavanceerde mogelijkheden tegen een premium prijs. GPT-4-modellen kosten 1 TP4T2 tot 15 per miljoen tokens, afhankelijk van de specifieke modelvariant. Deze aanbieders investeren fors in veiligheid, betrouwbaarheid en geavanceerde technologieën.
De o3- en o4-mini-modellen van OpenAI, die in 2025 zijn uitgebracht, vertegenwoordigen een vooruitgang in redeneervermogen. Volgens evaluaties van OpenAI maakt o3 20% minder grote fouten dan o1 bij moeilijke taken uit de praktijk, en blinkt het met name uit in programmeer- en bedrijfsadviesapplicaties.
Open-source modelplatformen
Aanbieders zoals Together.ai, Fireworks en Replicate bieden open-source modellen aan met aanzienlijk lagere prijzen. DeepSeek-modellen op Together.ai bieden een kostenbesparing van 70-901 TP3T ten opzichte van closed-source alternatieven, terwijl ze tegelijkertijd topprestaties leveren.
Deze platforms combineren standaard open-source modellen met eigen, gepatenteerde infrastructuur. Het resultaat: uitstekende prestaties tegen aanzienlijk lagere prijzen, hoewel soms met minder uitgebreide veiligheidsfiltering en contentmoderatie.
AI-diensten van cloudproviders
AWS, Azure en Google Cloud bieden zowel eigen modellen als modellen van derden aan via uniforme API's. De prijzen variëren, maar cloudproviders rekenen doorgaans een hogere marge dan bij directe API-toegang en bieden daarnaast zakelijke functies zoals SLA's, compliance-certificeringen en integratie met bestaande cloudinfrastructuur.
Gespecialiseerde inferentieproviders
Bedrijven zoals Groq richten zich specifiek op inferentieoptimalisatie. Groq zet zich in voor inferentieoptimalisatie door middel van op maat gemaakte chips voor prestaties met lage latentie.
Toekomstige kostenontwikkeling
Hoe zullen de inferentiekosten zich verder ontwikkelen? Verschillende trends beïnvloeden de verwachtingen.
De kostenreducties van 10x per jaar die tussen 2021 en 2025 werden gerealiseerd, zullen waarschijnlijk niet in hetzelfde tempo aanhouden. De gemakkelijk te behalen optimalisaties zijn al doorgevoerd. Hardwareverbeteringen gaan door, maar in een gematigder tempo. Innovaties in modelarchitectuur vinden nog steeds plaats, maar minder vaak dan tijdens de explosieve periode van 2022-2024.
Een realistischer verwachting is een jaarlijkse reductie van 3-5 keer tot en met 2027, waarna deze afneemt tot 1,5-2 keer per jaar. Dit is nog steeds een aanzienlijke verbetering, maar niet in het buitengewone tempo van de afgelopen jaren.
De uitdaging rond het verbruik van redeneer-tokens zal leiden tot architectonische innovaties. Modellen die krachtige redeneringen realiseren met lagere tokenkosten zullen een groter marktaandeel veroveren. Verwacht voortdurend onderzoek naar efficiënte redeneermechanismen.
De concurrentie blijft hevig. De intrede van DeepSeek heeft de prijsvorming in de hele markt verstoord, waardoor gevestigde spelers gedwongen werden hun prijzen te verlagen of zich op andere vlakken te onderscheiden. Verdere verstoring zal waarschijnlijk komen van onverwachte hoeken: startups met nieuwe architecturen of regionale spelers met andere economische structuren.
Duurzame AI-economie opbouwen
Organisaties die voortbouwen op LLM's hebben strategieën nodig die werken ongeacht specifieke prijsschommelingen. Verschillende principes maken een duurzame economie mogelijk.
- Ten eerste, ontwerp het model met het oog op flexibiliteit. Leg geen afhankelijkheden van specifieke providers of modellen vast in de code. Abstracteer inferentie achter interfaces die het mogelijk maken om providers te wisselen naarmate de economische omstandigheden veranderen.
- Ten tweede: meet alles. Meet het tokenverbruik, de kosten per aanvraag en de kosten per bedrijfsresultaat. Veel organisaties ontdekken dat 201 TP3T aan gebruiksscenario's 801 TP3T aan kosten met zich meebrengen, en dat sommige dure gebruiksscenario's minimale waarde opleveren.
- Ten derde, investeer in optimalisatie. De eerder besproken technieken – kwantisering, caching, routing, promptoptimalisatie – hebben een cumulatief effect op de lange termijn. Een verdubbeling van de verbetering lijkt misschien bescheiden, totdat je beseft dat dit een kostenbesparing van 50% per maand betekent.
- Ten vierde, stem de mogelijkheden van het model af op de taakvereisten. Het gebruik van grensmodellen voor elke taak is geldverspilling. Het bouwen van classificatielogica die verzoeken op de juiste manier doorstuurt, levert veel voordelen op.
- Zorg tot slot voor inzicht in het tokenverbruik. Het probleem met de redeneertokens overvalt teams vaak wanneer ze het interne tokenverbruik niet monitoren. Aanbieders bieden steeds vaker telemetrie aan die verborgen tokengebruik inzichtelijk maakt – maak daar gebruik van.
Veelgestelde vragen
Wat zijn de kosten van LLM-inferentie per aanvraag?
De inferentiekosten van LLM variëren enorm, afhankelijk van de modelgrootte en de complexiteit van de aanvraag. Eenvoudige aanvragen aan kleine modellen (3 tot 7 miljard parameters) kosten een fractie van een cent – ongeveer 1 TP4T0,01-0,05 per 1.000 aanvragen. Middelgrote modellen (13 tot 70 miljard) kosten 1 TP4T0,10-0,80 per 1.000 aanvragen. Grote grensmodellen (175 miljard of meer) kosten 1 TP4T2-15 per 1.000 aanvragen. Redeneringsmodellen kunnen echter 50 tot 100 keer meer tokens verbruiken dan de lengte van de uitvoer doet vermoeden, waardoor de werkelijke kosten aanzienlijk hoger uitvallen.
Is zelfhosting goedkoper dan het gebruik van API-diensten?
Zelfhosting wordt goedkoper dan API's wanneer het GPU-gebruik consistent boven de 501 TP3T uitkomt. Dit vereist doorgaans de verwerking van meer dan 10 miljoen tokens per GPU per dag. Onder die drempel bieden API's meestal een betere prijs-kwaliteitverhouding, omdat je kapitaaluitgaven vermijdt en niet betaalt voor ongebruikte capaciteit. Zelfhosting vereist echter ook expertise op het gebied van machine learning en brengt overheadkosten met zich mee voor het beheer van de infrastructuur.
Waarom zijn redeneermodellen zo duur?
Redeneermodellen genereren uitgebreide interne 'denk'-tokens voordat ze een output produceren. Een reactie met 200 zichtbare tokens kan tijdens het redeneerproces 10.000 tot 30.000 tokens verbruiken. Dit interne tokenverbruik wordt gefactureerd, maar blijft onzichtbaar in de output. Dit leidt tot situaties waarin de prijs per token laag lijkt, maar de totale kosten hoog zijn. Sommige redeneervragen verbruiken meer dan 600 tokens om antwoorden van twee woorden te genereren.
Hoe kan ik de inferentiekosten van LLM verlagen?
Vijf belangrijke strategieën verlagen de inferentiekosten: kwantisering (besparing van 2-4x), caching van responsen voor herhaalde query's (besparing van 3-10x), promptoptimalisatie om het tokengebruik te verminderen (besparing van 1,5-3x), modelroutering om kleinere modellen te gebruiken voor eenvoudige taken (besparing van 2-5x) en batchverwerking voor doorvoergerichte workloads (besparing van 1,3-2x). Deze technieken versterken elkaar wanneer ze effectief worden gecombineerd.
Wat zijn de huidige kosten voor prestaties op GPT-4-niveau?
Vanaf maart 2026 kost het behalen van GPT-4-prestaties ongeveer 1 TP4T0,40-0,80 per miljoen tokens met behulp van concurrerende alternatieven zoals DeepSeek V3 of modellen uit het middensegment van grote aanbieders. De werkelijke kosten van OpenAI's GPT-4 liggen tussen de 1 TP4T2 en 15 per miljoen tokens, afhankelijk van de specifieke variant. Dit vertegenwoordigt een enorme deflatie ten opzichte van eind 2022, toen vergelijkbare prestaties meer dan 1 TP4T20 per miljoen tokens kostten.
Hoe verhouden de kosten van cloud-GPU's zich tussen de verschillende aanbieders?
De prijsstelling voor Cloud H100 GPU's is begin 2026 gestabiliseerd op $2,85-3,50 per uur bij de belangrijkste providers. Regionale cloudproviders bieden soms lagere tarieven ($2,20-2,60 per uur) met minder gunstige SLA's. A800-kaarten, die in bepaalde regio's veel voorkomen, kosten ongeveer $0,79 per uur, gebaseerd op de economische aspecten van de infrastructuur. Multi-GPU-configuraties bieden doorgaans volumekortingen van 10-20%.
Zullen de inferentiekosten van LLM blijven dalen?
De inferentiekosten zullen naar verwachting blijven dalen, maar in een langzamer tempo dan de jaarlijkse reducties van factor 10 die tussen 2021 en 2025 werden waargenomen. Realistische verwachtingen liggen in een jaarlijkse reductie van factor 3 tot 5 tot 2027, waarna deze zal afnemen tot factor 1,5 tot 2 per jaar naarmate de mogelijkheden voor optimalisatie schaarser worden. Hardwareverbeteringen en architectonische innovaties zullen de verdere deflatie stimuleren, maar het buitengewone tempo van de afgelopen jaren zal waarschijnlijk niet oneindig aanhouden.
Strategische lessen voor AI-gestuurde toepassingen
Inzicht in de economische aspecten van LLM-inferentie is nu belangrijker dan ooit. Het verschil tussen een naïeve implementatie en een geoptimaliseerde implementatie kan 5 tot 10 keer zo groot zijn qua kosten – genoeg om te bepalen of de kosten per eenheid überhaupt haalbaar zijn.
De prijs van tokens vertelt slechts een deel van het verhaal. Het totale tokenverbruik, inclusief de tokens voor verborgen redenering, bepaalt de werkelijke kosten. Het monitoren en beheersen van dit verbruik is essentieel voor een duurzame bedrijfsvoering.
De keuze tussen API-services en zelfhosting hangt af van de schaal, het gebruikspatroon en de mogelijkheden van de organisatie. Geen van beide opties is universeel superieur. Analyseer uw specifieke situatie in plaats van blindelings branchetrends te volgen.
Optimalisatietechnieken versterken elkaar. Kwantisatie, caching, prompt engineering en model routing kunnen samen de kosten met een factor 10 of meer verlagen ten opzichte van standaardimplementaties. Investeren in deze optimalisaties levert op de lange termijn rendement op.
De markt blijft zich snel ontwikkelen. Nieuwe aanbieders, modellen en prijsstructuren verschijnen regelmatig. Het bouwen van flexibele architecturen die zich kunnen aanpassen aan veranderende economische omstandigheden beschermt zowel tegen kosteninflatie als tegen gemiste kansen door betere alternatieven.
Eerlijk gezegd: de inferentiekosten van LLM zijn drastisch gedaald, maar dat betekent niet dat AI-infrastructuur goedkoop is. Het betekent dat de economische situatie is verschoven van "onbetaalbaar" naar "beheersbaar met zorgvuldige optimalisatie". De teams die deze economische aspecten begrijpen en hun architectuur daarop afstemmen, zullen duurzame AI-bedrijven opbouwen. Degenen die inferentie als een commodity beschouwen zonder de onderliggende kostenfactoren te begrijpen, zullen het moeilijk krijgen.
Bent u klaar om uw LLM-inferentiekosten te optimaliseren? Begin met het meten van uw huidige tokenverbruikspatronen, inclusief eventuele verborgen redeneertokens. Identificeer uw meest kostbare use cases en evalueer of modelroutering of promptoptimalisatie de kosten kan verlagen. Vergelijk uw huidige volume met de break-even drempel voor zelfhosting om te bepalen of het zinvol is om de infrastructuur zelf te beheren. De inzichten die u hiermee verkrijgt, hebben een directe impact op uw bedrijfsresultaten.